知识分享
什么是隐写?
隐写术(Steganography) 这一名词早在文艺复兴时期就已出现。很多同学小时候玩过的秘密写字(紫外线照射使字迹显现)也可以说是隐写的一种。而现在的数字隐写术在是信息安全杂项门类下的一个小分支,主要研究将信息隐藏在数字载体中(一般是公开媒介)。信息隐写不仅要避免信息被接收者以外的人截获,更旨在让他人根本无法知晓信息传递的发生。信息在传递过程中的安全性和秘密性都有所保障。
在考量一种隐写方法时,我们通常从隐蔽性和鲁棒性两个角度来进行评判。其中隐蔽性指让人无法察觉隐藏信息的存在;而鲁棒性则指:在一些干扰或是刻意攻击存在的情况下,隐藏的信息能够复原的程度。采用了隐写技术的电子水印,则更注重鲁棒性的提升,以防止不法分子将版权信息从作品中去除。
而图像隐写则是以图像作为载体,将信息隐藏在图片中。根据信息隐藏的位置的不同,可以将隐写方式分为空间域隐写和变换域隐写两种。
LSB隐写术
网上已经有很多关于LSB(最低有效位)隐写原理的分析了,鉴于作者实在是懒得要死+无限拖延,大家可以直接在下面的链接参考相关内容。
项目实践
在这之前,我写程序还从未有落实到生活中过,基本上都是写解题的代码,最多也只能说是写过一些临时的小脚本,更不用说独立地完成一个有实际作用的小项目了。于是刚好就趁这个学期Python项目作业的机会,来动手试一下从零开始要怎么完成一个项目。
而关于为什么和大家都在做的爬虫、数据可视化背道而驰,选择了一个冷门的选题,大概是源于对信息安全的兴趣。可惜没法在本科有更多的机会接触到这一学科,遂打算在有空的时候自己慢慢研究。
已经完成的项目地址:https://github.com/marshuni/LSB-Steganography
项目构思
项目整体为一个基于Python的使用工具类脚本,可以实现以下两个功能:
- 将文本等信息隐藏入一张图像 :在命令行中使用
hide关键字,并给出载体图像路径、载荷文件路径(可以是图像或文本文件)等信息,将信息隐藏入载体图像。 - 从包含隐藏信息的图像中取出信息:在命令行中使用
extract关键字,并给出含有隐藏信息的图片文件路径,输出文件路径等信息,从而取出隐藏的内容。
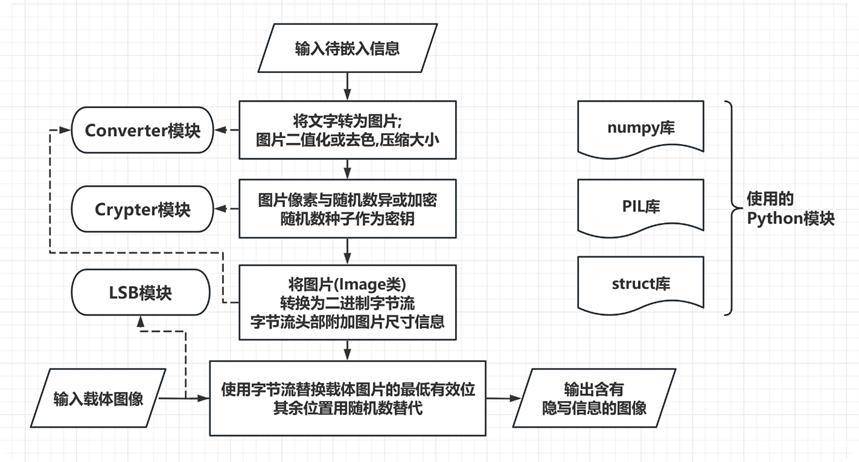
以下是隐藏功能的实现流程图。可以看出程序被封装入了Converter, Crypter, LSB 三个模块,分别实现不同的功能。
除此之外还有主程序main.py 负责处理用户输入的命令,并控制上述模块对数据进行操作。
项目展示
使用《滕王阁序》作为载体文本,将其隐藏入一个图片文件中。


不难发现,两张图片使用肉眼看不出任何区别。

代码实现
以下的代码为编写过程中各部分功能的原型。在项目中,我对这些原型进行了一定重构,并使用类进行了封装,将其分为以上三个模块。如果需要体验项目效果,可以在Github上下载代码并按照Readme配置运行。
将文字渲染为图片
将文字渲染为图片再进行编码,可以增加隐写算法的鲁棒性。保证隐藏信息的图像在经过一定修改后,仍然能够辨识出其中隐藏的信息。
与其说是“渲染”为图片,实际的操作更像是新建一个图片,并在这张图片上面印上文字内容。PIL库中的ImageDraw可以实现这一功能。
但库中的函数并不能根据文本长度和图片宽度进行自动换行,因此添加了一个简易的换行流程。
from PIL import Image, ImageFont, ImageDraw
# 将长段文本按图片宽度进行换行
# 函数存在一定缺陷,即当文本为英文时,到达画布的一半处便会换行
def TextSplit(text, length):
retrn [text[i:i+length] for i in range(0, len(text), length)]
# 将文本渲染为图片
# 传入的参数依次为:源字符串、生成图片高度与宽度、字号大小
def Text2Pic(raw,width,height,size) -> Image:
# 将字符串进行切分,保证每一分段的长度在对应字号下不会超过图片长度
sections = raw.split(sep='\n')
text = ""
for section in sections:
for line in TextSplit(section,int((width-20)/size)):
text += line+'\n'
# 定义生成图像的类型。"1"表示图像类型为非黑即白的二值化图像 第3个参数的1则表示图像默认为全白
# 生成一个ImageDraw对象,从而对图像进行修改
# 指定生成文字的字体,需要在脚本运行目录下存在该文件
image = Image.new("1", (width, height), 1)
draw = ImageDraw.Draw(image)
font = ImageFont.truetype("./YaHeiConsolas.ttf", size)
# 在图像上绘制文字。该函数会根据字符串中的换行符'\n'自动换行
draw.multiline_text((10, 5), text, font=font, fill="#000000")
return image
将图像进行异或处理以加/解密
最基础的LSB隐写并没有使用任何加密手段,也极易被识别出来。而常用的对称加密解决方案又过于庞大,有种杀鸡用牛刀的感觉。同时这种方法对于图像等二进制文件也并不太好用。因此采用了异或加密这一简单的手段。在不知道加密手段的情况下,还是可以提供不错的安全性的。
异或加密的原理很简单,即生成一个和图像信息完全一致的三维随机数组(宽x高x通道数),将每一个数与图像中对应的数值(范围0-255)进行按位异或操作。
在解密时,只需要知道随机数组的值,按原样运行一次算法即可。(异或运算跑两次得到原值)
但由于PIL库的局限性,它仅支持单通道、所有数值为0或1的二值化图像进行异或操作。则此时生成的随机数组为二维的(大小为宽x高),且每一个数为0或1.
在实际的项目中,为解决这一问题,我采用了numpy进行按位异或操作。同时给用户提供了“二值化”与“灰度”两种模式。具体代码可以看项目,原理是一样的。
# 使用种子随机生成一个和图像结构一致的随机数组,并将两者进行异或以加密
# 由于PIL库的局限性,进行异或操作的图像必须是二值化图像,不能够进行按位异或。
# 或许可以先在numpy的array形式下异或完再转换成图像?
def ImgEncrypt_xor_1(img_src,seed):
# 图像二值化
img = img_src.convert("1")
# 获取图像的宽高信息
img_arr = np.array(img)
w,h = img_arr.shape
# 输入随机数种子,生成随机数作为key
# 尽管异或时仅支持二值化图像,这里还是先生成值的范围在0-255的二维数组(对应标准单通道灰度图像)
# 然后再用PIL库,从数组转成二值化图像
np.random.seed(seed)
key=np.random.randint(0,256,size=[w,h],dtype=np.uint8)
keyimg = Image.fromarray(key).convert("1")
# 该步调用了PIL库的对应函数,生成加密后的图像
img_encrypt = ImageChops.logical_xor(img,keyimg)
return img_encrypt
# 使用同样的种子可以对加密的图像解密
# 步骤和上面的函数大同小异,原理一致,就不写注释了
def ImgDecrypt_xor_1(img_encrypt,seed):
img_encrypt = img_encrypt.convert("1")
img_arr = np.array(img_encrypt)
w,h = img_arr.shape
np.random.seed(seed)
key=np.random.randint(0,256,size=[w,h],dtype=np.uint8)
keyimg = Image.fromarray(key).convert("1")
img_decrypt = ImageChops.logical_xor(img_encrypt,keyimg)
return img_decrypt
将图像转换为二进制字节流便于隐写
这一模块在从原型到实际代码的开发过程中遇到了较多难题,所以这里直接使用了Converter.py中的最终代码进行解释。
啊……给自己的代码写注释是一个很费脑子的过程,更何况这个注释还是后期加上的……
如果有不正确或缺漏的地方还望指出,多多包涵。
# 将图像文件分解成二进制流的形式
def ImgDecompose(img,mode):
# data数组用于存储最终的字节流,bytes数组中则是图像对应每一位的值(0-255),需要按位拆开才能存入data
data = []
bytes = []
# 先将图像宽高信息存入。struct模块将int整数打包成字节流的形式,每个整数占用4个字节(每字节8位二进制)
# 由于Py中没有字节流的数据类型,struct.pack()输出的类型实质上是字符串,因此这里是将一个个字符存入数组
# 单个字符的数据范围正好是0-255(1个字节),因此可以和图像数据一起拆分。
for arg in img.size:
bytes += [b for b in struct.pack("i",arg)]
# 如果是灰度模式 就把图像数据也加进去,然后按位拆开成01的形式
if mode == "L":
bytes += [b for b in img.convert("L").getdata()]
# 双重循环,对于bytes数组中每个元素(即一个字节),将其按8位分解并压入data数组
# 先右移再按位或0x1可以得到每一位的值,具体哪一位取决于右移的位数。
for b in bytes:
for i in range(7,-1,-1):
data.append((b >> i) & 0x1)
# 如果图像为二值化图像,直接把01结果加入data数组就行了
if mode == "1":
data += [int(bool(b)) for b in img.convert("1").getdata()]
return data
# 将二进制流重新聚合为图像文件
def ImgAssemble(data,mode,steg_size):
# 取出图像数据大小,由于一个整数占用4字节(4x8=32个二进制位),宽高数据一共占用了64位
# 因此取出前64位二进制即可
size = b""
size_bytes = data[:64]
# 一个idx即代表一个字节 将8个字节存入size后使用unpack()解出对应的整数
for idx in range(0,8):
byte = 0
# 将8位二进制位处理后转换为0-255的整数存入byte
# 每次循环都左移一次,一共8位
for i in range(0,8):
byte = (byte<<1) + size_bytes[idx*8+i]
# chr函数将整数转换为字符类型(二进制流)
# encode()函数在使用默认unicode编码时可能会产生额外的字符'\xc2',需要改换编码
size = size + chr(byte).encode('latin-1')
# 使用unpack()解出整数
width,height = struct.unpack("i",size[:4])[0],struct.unpack("i",size[4:8])[0]
# 加一个判断大小数据有效性的流程。如果得到的size数据不合理,判定文件损坏,并尝试用原图的尺寸数据。
if not 0<width<8192 or not 0<height<8192:
print("[-] File corrupted.Trying to restore.")
width,height = steg_size
img = Image.new("L",(width,height))
# 先将对应的字节取出
# 然后按和上述取出宽高数据类似的方式按位取出图像数据,每8位算在一起
if mode == "L":
img_bytes = data[64:(width*height)*8+64]
imgdata = []
for idx in range(0,int(len(img_bytes)/8)):
byte = 0
for i in range(0,8):
byte = (byte<<1) + img_bytes[idx*8+i]
imgdata.append(byte)
img.putdata(imgdata)
# 如果是二值化模式 直接取出二进制数据即可
elif mode == "1":
img = img.convert("1")
img.putdata(data[64:width*height+64])
return img
将信息存入载体图片的最低有效位
# 函数作用为将var的 第num位 设为value的值
def SetBit(var, num, value):
# mask的哪一位为1,则修改哪一位
# num的值为0表示最低位
mask = 1 << num
# 按位与操作将对应位上的二进制设为0
var &= ~mask
# 如果value是1 就把对应位设为1
if value:
var |= mask
return var
# 嵌入操作
def Embed(imgFile,payload):
src_img = Image.open(imgFile).convert("RGBA")
width,height = src_img.size
# 计算最大能够存入的数据
max_size = width*height*3.0/1024
print ("[*] Input image size: %dx%d pixels." % (width, height))
print ("[*] Usable payload size: %.2f KB." % (max_size))
# 如果二进制数据长度不为3的倍数,就在末尾充入0进行调整
# 因为该方法将数据平均分配到RGB三个通道,需要总二进制位数为3的倍数
while(len(payload)%3):
payload.append(0)
payload_size = len(payload)/1024.0
print ("[+] Payload size: %.3f KB " % payload_size)
if (payload_size > max_size - 4):
print("[-] Cannot embed. File too large")
sys.exit()
steg_img = Image.new('RGBA',(width,height))
index = 0
for h in range(height):
for w in range(width):
(r,g,b,a) = src_img.getpixel((w,h))
if index < len(payload):
r = SetBit(r,0,payload[index])
g = SetBit(g,0,payload[index+1])
b = SetBit(b,0,payload[index+2])
# 超出数据的部分设为随机数,便于隐蔽
else:
r = SetBit(r,0,random.randint(0,1))
g = SetBit(g,0,random.randint(0,1))
b = SetBit(b,0,random.randint(0,1))
steg_img.putpixel((w,h),(r,g,b,a))
index += 3
print ("[+] Embedded successfully!")
return steg_img
# 解出数据
def Extract(imgFile):
src_img = Image.open(imgFile).convert("RGBA")
width,height = src_img.size
print ("[*] Input image size: %dx%d pixels." % (width, height))
data = []
for h in range(height):
for w in range(width):
(r, g, b, a) = src_img.getpixel((w, h))
data.append(r & 1)
data.append(g & 1)
data.append(b & 1)
return data
参考资料
现有项目
在编写代码时尽管没有Ctrl+C/V,但由于能力有限,还是参考了一些大佬的代码和提供的思路。