11.WordCount示例编写
任务目的
- 理解 WordCount 示例的业务逻辑
- 掌握 MapReduce Reduce 端编程规范
- 理解 WordCount 示例 Reduce 端的自定义业务逻辑的编写
- 熟记 MapReduce Driver 端编程规范
任务清单
- 任务1:WordCount Reduce 端程序编写
- 任务2:WordCount Driver 端程序编写
详细任务步骤
首先回顾一下 WordCount 示例的业务逻辑:
MapTask 阶段处理每个数据分块的单词统计分析,思路是将每一行文本拆分成一个个的单词,每遇到一个单词则把其转换成一个 key-value 对,比如单词 Car,就转换成<’Car’,1>发送给 ReduceTask 去汇总。
ReduceTask 阶段将接收 MapTask 的结果,按照 key 对 value 做汇总计数。
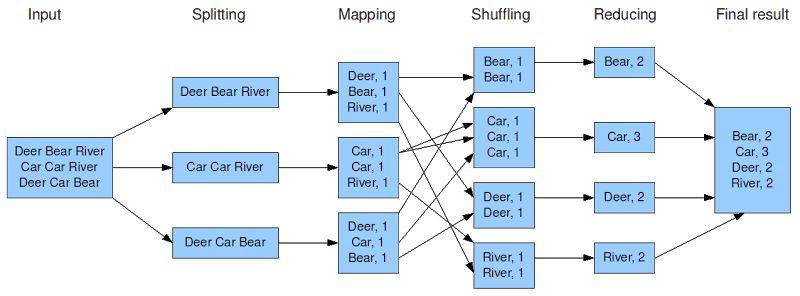
图1
任务1:WordCount Reduce 端程序编写
回顾 MapReduce Reduce 端编码规范:
1. 用户自定义的 Reducer 需要继承父类 Reducer
2. Reducer 的输入数据类型对应 Mapper 的输出数据类型,也是 KV
3. Reducer 的输出数据是 KV 对的形式(KV 的类型可自定义)
4. Reducer 的业务逻辑写在 reduce() 方法中
5. ReduceTask 进程对每一组相同 k 的<k,v>组调用一次 reduce() 方法
接下来进入 WordCount Reduce 端程序的编写,eclipse 成功连接到 Hadoop 集群后,在 com.hongyaa.mr 包下创建名为 WordCountReducer.java 的类,如下图所示:
图2
首先编写 Reduce 端编程框架,自定义的 WordCountReducer 需要继承父类 Reducer,输入数据和输出数据都是KV 对的形式。具体框架代码如下:
public class WordCountReducer extends Reducer<KEYIN,VALUEIN,KEYOUT,VALUEOUT> {
}
- KEYIN:对应 Mapper 端输出的 KEYOUT,即单个单词,所以是 String,对应 Hadoop 中的 Text
- VALUEIN:对应 Mapper 端输出的 VALUEOUT,即单词的数量,所以是Integer,对应 Hadoop 中的 IntWritable
- KEYOUT:用户自定义逻辑方法返回数据中key的类型,由用户业务逻辑决定,在此WordCount程序中,我们输出的key是单词,所以是String,对应 Hadoop 中的 Text
- VALUEOUT:用户自定义逻辑方法返回数据中value的类型,由用户业务逻辑决定,在此WordCount程序中,我们输出的value是单词的出现的总次数,所以是Integer,对应 Hadoop 中的 IntWritable
将框架中的KV对对应的类型修改完成后的代码如下所示:
public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
}
已知 Reducer 中的业务逻辑写在 reduce() 方法中,在此 reduce()方法中我们需要接收 MapTask 的输出结果,然后按照 key(单词) 对 value(数量1) 做汇总计数。具体代码如下所示:
/**
* <Deer,1><Deer,1><Deer,1><Deer,1><Deer,1>
* <Car,1><Car,1><Car,1><Car,1>
* 框架在Map处理完成之后,将所有key-value对缓存起来,进行分组,然后传递一个组<key,values{}>,调用一次reduce()方法
* <Deer,{1,1,1,1,1,1.....}>
* 入参key,是一组相同单词kv对的key
*/
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
//(1)做每个key(单词)的结果汇总
int sum = 0;
for (IntWritable v : values) {
sum += v.get();
}
//(2)输出每个key(单词)和其对应的总次数
context.write(key, new IntWritable(sum));
}
WordCountReducer.java 的完整代码如下所示:
public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
/**
* <Deer,1><Deer,1><Deer,1><Deer,1><Deer,1>
* <Car,1><Car,1><Car,1><Car,1>
* 框架在Map处理完成之后,将所有key-value对缓存起来,进行分组,然后传递一个组<key,values{}>,调用一次reduce()方法
* <Deer,{1,1,1,1,1,1.....}>
* 入参key,是一组相同单词kv对的key
*/
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
//做每个单词的结果汇总
int sum = 0;
for (IntWritable v : values) {
sum += v.get();
}
//写出最后的结果
context.write(key, new IntWritable(sum));
}
}
任务2:WordCount Driver 端程序编写
回顾 MapReduce Driver 端编码规范:整个程序需要一个 Drvier 来进行提交,提交的是一个描述了各种必要信息的 job 对象。
接下来进入 WordCount Driver 端程序的编写,在 com.hongyaa.mr 包下创建名为 WordCount.java 的类,如下图所示:
图3
Driver 端为该 WordCount 程序运行的入口,相当于 YARN 集群(分配运算资源)的客户端,需要创建一个 Job 类对象来管理 MapReduce 程序运行时需要的相关运行参数,最后将该 Job 类对象提交给 YARN。
Job对象指定作业执行规范,我们可以用它来控制整个作业的运行。接下来,我们分步讲述作业从提交到执行的整个过程。
1. 创建 Job
Job 的创建比较容易,其实就是 new 一个实例,先创建一个配置文件的对象,然后将配置文件对象作为参数,构造一个 Job 对象就可以了。不过new实例的方式已经过时,我们可以使用新的API创建Job。具体代码如下:
// 创建配置文件对象
Configuration conf = new Configuration();
// 新建一个 job 任务
Job job = Job.getInstance(conf);
2. 打包作业
我们在 Hadoop 集群上运行这个作业时,要把代码打包成一个Jar文件,只需要在Job对象的setJarByClass()方法中传递一个类即可,Hadoop会利用这个类来查找包含它的Jar文件,进而找到相关的Jar文件。具体代码如下:
// 将 job 所用到的那些类(class)文件,打成jar包
job.setJarByClass(WordCount.class);
3. 设置各个环节的函数
指定我们自定义的 mapper 类和 reducer 类,通过 Job 对象进行设置,将自定义的函数和具体的作业联系起来。具体代码如下:
// 指定 mapper 类和 reducer 类
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
4. 设置输入输出数据类型
分别指定 MapTask 和 ReduceTask 的输出key-value类型。如果 MapTask 的输出的key-value类型与 ReduceTask 的输出key-value类型一致,则可以只指定ReduceTask 的输出key-value类型。具体代码如下:
// 指定 MapTask 的输出key-value类型(可以省略)
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// 指定 ReduceTask 的输出key-value类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
5. 设置输入输出文件目录
在设置输入输出文件目录时,可以选择使用绝对目录,就是直接在语句中写入目录;也可以使用参数输入,即在运行程序时,再在控制台输入目录。具体代码如下:
// 指定该 mapreduce 程序数据的输入和输出路径,此处输入、输出为固定文件目录
Path inPath=new Path("/wordcount/input");
Path outpath=new Path("/wordcount/output");
FileInputFormat.setInputPaths(job,inPath);
FileOutputFormat.setOutputPath(job, outpath);
// 此处为参数
FileInputFormat.setInputPaths(job,new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
6. 提交并运行作业
单个任务的提交可以直接使用如下语句:
job.waitForCompletion(true);
WordCount.java 的完整代码如下所示:
public class WordCount {
/**
* 该MR程序运行的入口,相当于YARN集群(分配运算资源)的客户端
*/
public static void main(String[] args) throws Exception {
// (1)创建配置文件对象
Configuration conf = new Configuration();
// (2)新建一个 job 任务
Job job = Job.getInstance(conf);
// (3)将 job 所用到的那些类(class)文件,打成jar包 (打成jar包在集群运行必须写)
job.setJarByClass(WordCount.class);
// (4)指定 mapper 类和 reducer 类
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
// (5)指定 MapTask 的输出key-value类型(可以省略)
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// (6)指定 ReduceTask 的输出key-value类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// (7)指定该 mapreduce 程序数据的输入和输出路径
Path inPath=new Path("/wordcount/input");
Path outpath=new Path("/wordcount/output");
FileSystem fs=FileSystem.get(conf);
if(fs.exists(outpath)){
fs.delete(outpath,true);
}
FileInputFormat.setInputPaths(job,inPath);
FileOutputFormat.setOutputPath(job, outpath);
// (8)最后给YARN来运行,等着集群运行完成返回反馈信息,客户端退出
boolean waitForCompletion = job.waitForCompletion(true);
System.exit(waitForCompletion ? 0 : 1);
}
}