在B站有许多坤坤的视频,作为一名ikun,让我们写个爬虫研究一下视频的视频的名字、链接、观看次数、弹幕、发布时间以及作者。我们用selenium来实现这个爬虫,由于要获取的数据比较多,我们写几个函数来实现这个爬虫。
先倒入需要用到的库,包括selenium, time ,BeautifulSoup ,ChromeDriverManager。
打开及搜索函数:在这段代码中,我们导入了 `webdriver` 和 `ChromeDriverManager` 模块,以便使用 ChromeDriver 控制 Chrome 浏览器,以及自动下载和安装最新版本的 ChromeDriver。同时,我们还导入了 `time` 模块,以便在代码中添加延迟,以便页面加载完成。最后,我们还导入了 `BeautifulSoup` 模块,以便从网页中提取信息。
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
import time
from bs4 import BeautifulSoup先创建一个 ChromeDriver 实例,打开B站,在这里我们使用ChromeDriverManager().install()方法,他可以自动下载对应版本的chrome,防止因为Chrome版本不正确而报错。(PS:直接用webdriver.Chrome()会使用已下载Chrome游览器,他的版本可能与webdriver需要的版本不匹配这样打开chrome的时候会出现闪退报错)
url="哔哩哔哩 (゜-゜)つロ 干杯~-bilibili"
browser = webdriver.Chrome(ChromeDriverManager().install()) #创建一个 ChromeDriver 实例
browser.set_window_size(1400, 900) #设定页面大小
browser.get(url) #访问B站
我们可以用xpath方法来获取目标操作的位置,chrome浏览器能够自动提取xpath链接。我们使用 `browser.window_handles` 方法获取当前窗口中的所有句柄,并切换到第二个窗口,以便获取搜索结果页面。
在打开B站首页的时候,会出现一个提示登陆的页面干扰我们,因此我们最好点击一下首页,刷新一下。
first_page = browser.find_element_by_xpath("//*[@id='i_cecream']/div[2]/div[1]/div[1]/ul[1]/li[1]/a/span") #取得首页按钮的的位置
first_page.click() #点击首页进行刷新 然后,我们模拟用户在网站上搜索蔡徐坤篮球相关的视频;点击搜索栏,输入"蔡徐坤 篮球",并进行搜索;最后定位到新页面。
input = browser.find_element_by_xpath("//*[@id='nav-searchform']/div[1]/input") #取得搜索栏的位置
input.send_keys('蔡徐坤 篮球') #输入内容
submit = browser.find_element_by_xpath("//*[@id='nav-searchform']/div[2]") #取得搜索按钮的位置
submit.click() #点击搜索
all_h = browser.window_handles #取得新页面的代码
browser.switch_to.window(all_h[1]) #取得新页面的代码打开及搜索函数的完整代码:
def search(url="哔哩哔哩 (゜-゜)つロ 干杯~-bilibili"):
try:
browser = webdriver.Chrome(ChromeDriverManager().install())
browser.set_window_size(1400, 900)
browser.get(url)
first_page = browser.find_element_by_xpath("//*[@id='i_cecream']/div[2]/div[1]/div[1]/ul[1]/li[1]/a/span")
first_page.click()
input = browser.find_element_by_xpath("//*[@id='nav-searchform']/div[1]/input")
input.send_keys('蔡徐坤 篮球')
submit = browser.find_element_by_xpath("//*[@id='nav-searchform']/div[2]")
submit.click()
all_h = browser.window_handles
browser.switch_to.window(all_h[1])
return browser
except TimeoutError:
return search(url)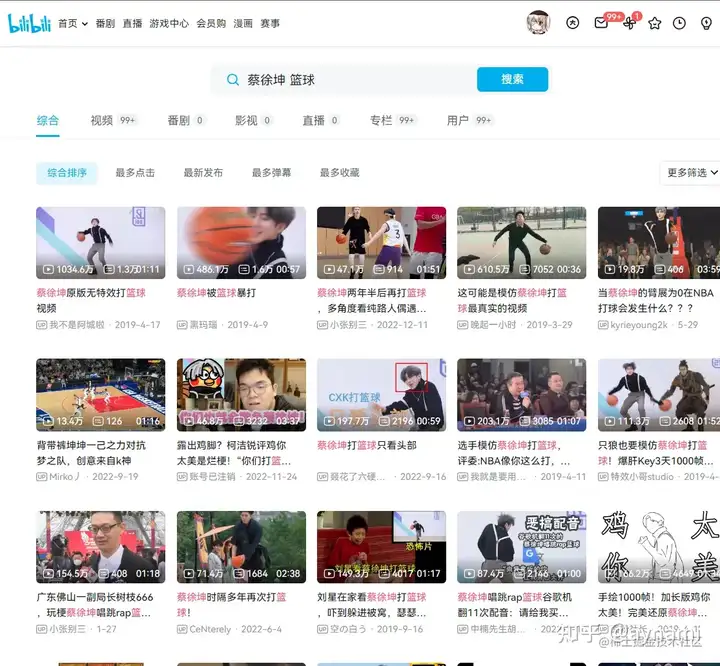
翻页函数:该函数使用 `find_element_by_xpath` 方法查找“下一页”按钮,并使用 `click` 方法单击该按钮。在单击“下一页”按钮之后,该函数使用 `browser.window_handles` 方法获取所有窗口句柄,并使用`browser.switch_to.window` 方法将焦点切换到搜索结果页面,以便我们可以继续提取视频信息,最后返回页面代码信息。如果没有找到“下一页”按钮,该函数会递归调用自身来查找“下一页”按钮,直到找到为止。
这里有一点需要注意,在取得下一页按钮的时候,最好利用“下一页”的文本进行匹配,如果根据浏览器提供的位置信息匹配,在某些页面下会出现位置不匹配而导致程序异常。

`next = browser.find_element_by_xpath("//button[text()='下一页']")这段代码较为简单,直接给出完整代码。
def next_page(browser): #获取下一页
try:
next = browser.find_element_by_xpath("//button[text()='下一页']") #下一页按钮
next.click() #点击按钮
time.sleep(1) #听一秒等待刷新
all_h1 = browser.window_handles #取得新页面的代码
browser.switch_to.window(all_h1[1]) #取得新页面的代码
return browser
except:
next_page(browser)
在这个函数中,我们首先使用 `browser.page_source` 方法获取当前页面的 HTML 代码,然后使用 `BeautifulSoup` 类解析 HTML 代码,以提取视频信息。接着,我们使用 `xlwt` 库将视频信息写入到 Excel 文件中。
我们还需要一个函数来提取页面信息,
先用BeautifulSoup解析页面,用find方法找到\<class\_='video-list'>标签,这里包含我们需要的所有视频,然后用find\_all方法找到每个视频的标签\<class\_='bili-video-card'>,同时find\_all会帮助我们形成一个列表存储数据,也就是我用到的videos:
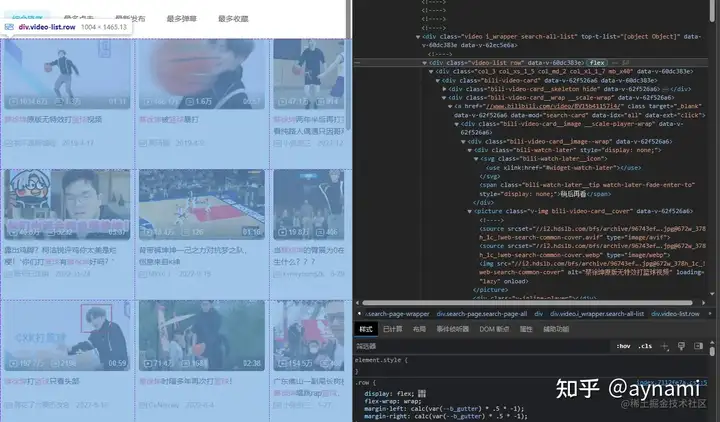
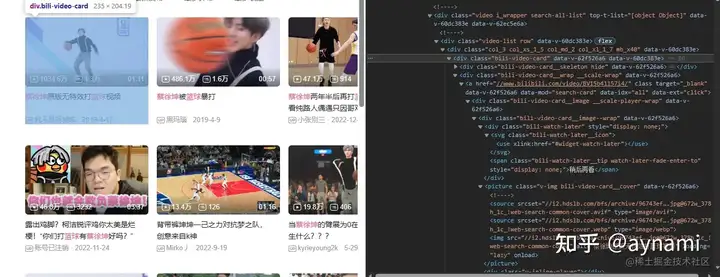
html = browser.page_source
soup = BeautifulSoup(html, "lxml")
videos = soup.find(class_='video-list').find_all(class_='bili-video-card')遍历视频信息列表,提取信息(视频的名字、链接、观看次数、弹幕、发布时间以及作者),这里建议多尝试,多打印几次确保信息准确:
for item in videos:
item_readers = item.find("span", class_="bili-video-card__stats--item").span.string
item_danmu = item.find_all("span", class_="bili-video-card__stats--item")[1].span.string
item_time = item.find("span", class_="bili-video-card__stats__duration").string
item_title = item.find("h3").get("title")
item_author = item.find("span", class_="bili-video-card__info--author").string
item_link = item.find("a").get("href")[2:]
print(item_title)最后一步是储存信息:
sheet.write(n, 0, n)
sheet.write(n, 1, item_title)
sheet.write(n, 2, item_link)
sheet.write(n, 3, item_readers)
sheet.write(n, 4, item_danmu)
sheet.write(n, 5, item_time)
sheet.write(n, 6, item_author)获取信息和储存函数的完整代码:
def save_to_excel(browser,sheet,n,wb):
try:
html = browser.page_source
soup = BeautifulSoup(html, "lxml")
videos = soup.find(class_='video-list').find_all(class_='bili-video-card')
for item in videos:
item_readers = item.find("span", class_="bili-video-card__stats--item").span.string
item_danmu = item.find_all("span", class_="bili-video-card__stats--item")[1].span.string
item_time = item.find("span", class_="bili-video-card__stats__duration").string
item_title = item.find("h3").get("title")
item_author = item.find("span", class_="bili-video-card__info--author").string
item_link = item.find("a").get("href")[2:]
print(item_title)
sheet.write(n, 0, n)
sheet.write(n, 1, item_title)
sheet.write(n, 2, item_link)
sheet.write(n, 3, item_readers)
sheet.write(n, 4, item_danmu)
sheet.write(n, 5, item_time)
sheet.write(n, 6, item_author)
n += 1
wb.save("cxk1.xls")
print(n)
return n
except TimeoutError:
save_to_excel(browser,sheet,n,wb) #存储函数最后写一个主程序调用三个函数,在主程序中,我们要记得先设置一下存储数据用到的EXCEL;
import xlwt
#设置excel
wb = xlwt.Workbook(encoding="utf-8",style_compression=0)
sheet = wb.add_sheet("b站爬去",cell_overwrite_ok=True)
sheet.write(0,0,"序号")
sheet.write(0,1,"名称")
sheet.write(0,2,"链接")
sheet.write(0,3,"观看次数")
sheet.write(0,4,"弹幕")
sheet.write(0,5,"时间")
sheet.write(0,6,"作者")主程序完整代码:
在调用主程序时,当我们进入收索信息的第一页时,可以先爬取第一信息,然后利用一个for循环取得其他页面信息。
#设置excel
wb = xlwt.Workbook(encoding="utf-8",style_compression=0)
sheet = wb.add_sheet("b站爬去",cell_overwrite_ok=True)
sheet.write(0,0,"序号")
sheet.write(0,1,"名称")
sheet.write(0,2,"链接")
sheet.write(0,3,"观看次数")
sheet.write(0,4,"弹幕")
sheet.write(0,5,"时间")
sheet.write(0,6,"作者")
n = 1
browser = search("哔哩哔哩 (゜-゜)つロ 干杯~-bilibili") #进入B站,并完成搜索
all_h = browser.window_handles
browser.switch_to.window(all_h[1]) #获取页面代码
total = browser.find_element_by_xpath("//*[@id='i_cecream']/div/div[2]/div[2]/div/div/div/div[2]/div/div/button[9]").text #获取总页数,给for循环做准备
# n = save_to_excel(browser,sheet,n,wb) #调用函数存储页面数据
# browser = next_page(browser) #翻页
for i in range(1,int(total)+1):
time.sleep(3) #等待加载
n = save_to_excel(browser,sheet,n,wb) # 调用函数存储页面数据
browser = next_page(browser) # 翻页完整代码地址:github.com/zhangaynami…
标签:视频,sheet,获取,write,item,取坤坤,div,find,browser From: https://www.cnblogs.com/zhangzijun2001/p/17458577.html