3 DDPM 的优化
3.1 参数优化
3.1.1 优化 βt
在 "Improved Denoising Diffusion Probabilistic Models". 一文中,作者提出了多种优化 DDPM 的技巧。其中一种就是把 βt 的线性机制改为余弦机制。机制(schedule)函数的实现相对灵活,只要保证在训练的中间过程提供近似-线性的下降并且在 t = 0 和 t = T 附近的变化不大即可。
文中给出的余弦机制为:
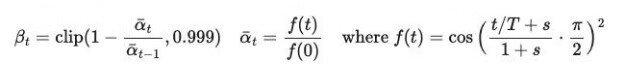
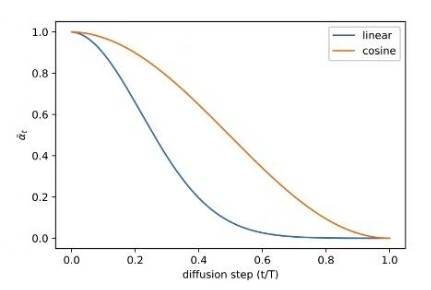
线性机制和余弦机制的对比:
3.1.2 优化 Σθ
同样在 "Improved Denoising Diffusion Probabilistic Models". 一文中。作者提出把 Σθ 设置为可学习参数,作为 βt 和 βt-hat 之间的插值。
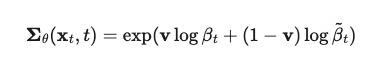
由于在 DDPM("Denoising Diffusion Probabilistic Models") 原文中,Σθ 不是可学习的参数,所以损失函数中并不包含该项。因此,作者提出把损失函数由 Lsimple 改为 Lhybrid = Lsimple + λLvlb,其中 λ = 0.001 来阻止 Lvlb 项中的 μθ 的梯度,因此 Lvlb 仅仅由 Σθ 的学习来引导。
3.2 抽样速度优化
3.2.1 DDIM
由于马尔可夫过程依赖于前一个状态的条件概率,因此 DDPM 的抽样速度很慢。 在 DDIM("Denoising Diffusion Implicit Models")一文中,作者指出:“对 DDPM 来说,需要花费 20 小时来采样 50k 张 32 * 32 大小的图片;但是对于 GAN 来说,只需要不到 1 分钟”。
其中一种优化方式来自 "Improved Denoising Diffusion Probabilistic Models".通过把抽样的步长更新为 [T/S] 使得抽样的步骤从 T 步变为 S 步。因此,新过程的抽样的样本为 {τ1, …, τs},S < T。
另一种优化方式来自 "Denoising Diffusion Implicit Models"。通过重参数化技巧,可以重写 qσ(Xt-1|Xt,X0) 过程为:
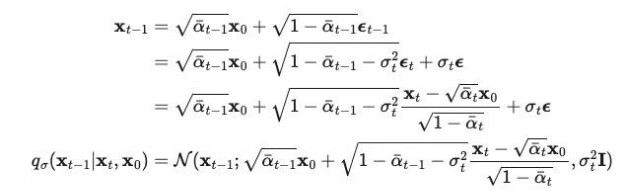
又因为,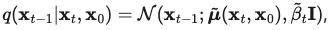 因此,
因此,
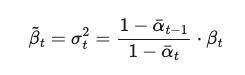
令 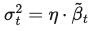 ,可以把 η 作为超参数来控制抽样过程的随机程度。特殊情况为:
,可以把 η 作为超参数来控制抽样过程的随机程度。特殊情况为:
-
η = 1,抽样过程随机,模型为 DDPM(去噪扩散概率模型)
-
η = 0,抽样过程确定,模型为 DDIM(去噪扩散隐模型)
DDIM 有着和 DDPM 相同的边际噪音分布,但是可以确定性地把噪音映射回原始数据样本。
在生成过程中,DDIM 从扩散过程的 S 步骤的子集进行抽样并推断。作者发现:当 S 很小时,使用 DDIM 能产出最好的图像质量,而 DDPM 则表现很差。也就是说:DDIM 可以使用比 DDPM 更少的抽样步骤,生成更好质量的图像。
与 DDPM 相比,DDIM 能够:
-
用更少的步骤生成高质量图像。
-
因为生成过程是确定的,所以 DDIM 有连续性。意思是:在同一个潜变量上进行条件抽样的样本,应该具有类似的高维度特征。
-
因为连续性,DDIM 能够从潜变量中得的有意义的语义插值。
3.2.2 LDM
"High-Resolution Image Synthesis with Latent Diffusion Models" 一文提出了 Stable Diffusion 和潜扩散模型(Latent Diffusion Model / LDM)。LDM 通过在潜空间中运行扩散过程(DDPM 则是在图像像素空间中)减少了训练成本,加快了推断速度。该文的启发来自观察:“在压缩图像后,其语义和概念组成依然极大保留了下来,而且大部分比特贡献了图像的细节”。LDM 通过生成建模学习松散地分解感知压缩和语义压缩,方法是首先使用自编码器去除像素级冗余,然后通过扩散过程对学习到的潜数据进行操作/生成语义概念。
感知压缩过程依赖于自编码器。自编码器的编码器首先把图像输入压缩为 2D 的潜向量,解码器随后根据该 2D 潜向量重建图像。上述文章还探索了两种正则化方法以避免潜空间中的任意高方差。
LDM 的结构如下,扩散和生成过程都在潜空间中进行。使用的自编码器是时间条件的 U-Net,并且利用例如:语义信息、文本、图像等来实行条件控制,这类似于多模态学习。为了处理文本信息,在 U-Net 中的残差块之间还加入了 Cross-Attention 跨注意力模块
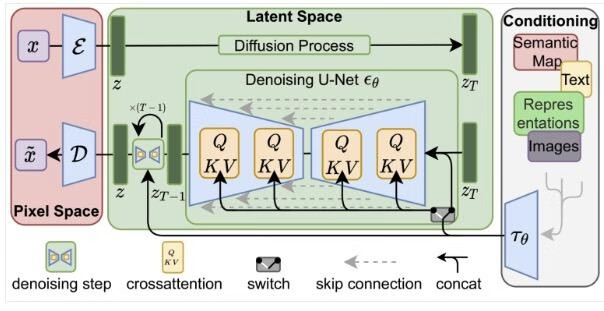
3.3 条件生成
3.3.1 分类器引导
ImageNet 等数据集中不仅包含大量的图片,而且有配对的标签。为了让扩散模型在这样的数据集上训练,需要结合标签信息。
Diffusion "Models Beat GANs on Image Synthesis". 一文通过在噪音图片中训练一个分类器来引导抽样过程朝着目标标签移动。因为 score function 为:
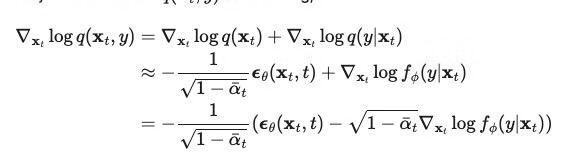
所以分类器可以表示为:
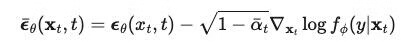
作者对 U-Net 结构也进行了一些修改,包括:网络扩展、注意力扩展等。最终在图像生成任务上使用扩散模型打败了 GAN。
3.3.2 无分类器引导
"Classifier-Free Diffusion Guidance" 一文提出了无分类器引导方法。不使用分类器,可以通过结合有条件的 score 函数和无条件的扩散模型来运行扩散步骤。
方法是把无条件的去噪扩散模型通过 score 预测器重参数化,并把有条件的扩散模也重参数化。这两个模型可以通过一个网络学习。该网络使用带标签的配对数据来训练有条件的模型,并在训练过程中周期性随机丢弃一些条件信息来训练无条件模型。
文章的结果表明,无分类器引导的扩散模型能够取得 FID(分辨原始图片和生成图片)以及 IS(质量和多样性) 之间的平衡。
3.4 渐进蒸馏
"Progressive Distillation for Fast Sampling of Diffusion Models" 一文提出了“渐进蒸馏”来加速扩散模型的抽样过程,方法如下图:
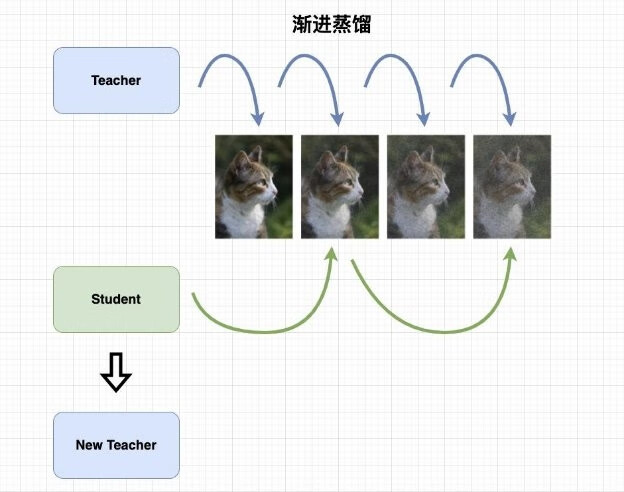
渐进蒸馏的概念来源于知识蒸馏。首先初始化两个模型:教师模型和学生模型,两个模型完全相同(网络结构、参数等)。渐进蒸馏的做法是:教师模型依然按照常规的方式完成抽样过程,学生模型则把教师模型所需的步骤减半,用一步过程来预测教师模型的两步结果。在一轮蒸馏结束后,学生模型复制成为新的教师模型。重复以上步骤。
上述方法的奇怪之处在于:为什么不可以直接使用学生模型来预测两步结果,或者教师模型的作用是什么?
答案是:因为扩散模型的抽样过程具有一定的随机性,所以如果抽样过程的步长过大,那么在某个时刻应该生成的图片其实有多种可能,但是只有其中一种是正确的。例如:在某个时刻 t,确定的是图像中应该包含 3 个噪音块,那么该时刻的生成图像至少有下述可能:
-
噪音块均匀分布
-
噪音块集中分布在某个位置
-
图片边缘
-
图片中央
-
教师模型存在的意义就是引导学生模型做出正确的判断。
作者团队对多个学生模型的步长进行了研究,发现减半是效果最优的。
参考
-
Ling Yang et al. “Diffusion Models: A Comprehensive Survey of Methods and Applications .” arXiv 2023.
-
Jonathan Ho et al. "Denoising Diffusion Probabilistic Models". NeurIPS 2020.
-
Jiaming Song et al. "Denoising Diffusion Implicit Models". ICLR 2021.
-
Alex Nichol et al. "Improved Denoising Diffusion Probabilistic Models". ICML 2021.
-
Robin Rombach et al. "High-Resolution Image Synthesis with Latent Diffusion Models". arXiv 2022.
-
Prafulla Dhariwal et al. Diffusion "Models Beat GANs on Image Synthesis". NeurIPS 2021.
-
Jonathan Ho et al. "Classifier-Free Diffusion Guidance". NeurIPS Workshop 2021.
-
Tim Salimans et al. "Progressive Distillation for Fast Sampling of Diffusion Models". ICLR 2022.
-
Chenlin Meng et al. On Distillation of Guided Diffusion Models”. CVPR 2023.