前言 本文介绍一下最近被 ICML 2023 接收的文章:A Closer Look at Self-Supervised Lightweight Vision Transformers.文章聚焦在轻量级 ViT 的预训练上,相当于为相关方向的研究提供了一个 benchmark,相关的代码与模型也都会开源,方便后续大家在这一方向上继续探索。文章的研究也打破了之前人们对于 ViT 在轻量级赛道上没有竞争优势的惯有印象,只要采用合适的预训练手段,轻量级 ViT 也会表现出足够的竞争力。
本文转载自PaperWeekly
作者 | 王Sr
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【CV技术指南】CV全栈指导班、基础入门班、论文指导班 全面上线!!

论文标题:A Closer Look at Self-Supervised Lightweight Vision Transformers
论文链接:https://arxiv.org/abs/2205.14443
代码链接:https://github.com/wangsr126/mae-lite
导读:最近“预训练大模型”这个概念异常火爆,大家都期待可以通过增加模型尺寸以达到“涌现”的效果。视觉领域也出现了大量的预训练方法和预训练模型,且取得了非常不错的效果。然而,视觉任务又有其独特性,隐私性、实时性等一系列应用场景的限制使得边缘端实际部署的模型多是轻量模型,而这些轻量模型应该怎样预训练却鲜少被研究。
本文即针对这一问题,重点关注轻量级 ViT 的预训练,通过大量的实验与分析为轻量级ViT的预训练提供一个“实践手册”。众多预训练方法中哪种可以在轻量级模型上表现得更好?不同下游任务中这些方法的优劣对比又会有何种不同?各种轻量级预训练模型又是为什么会表现出上述的实验现象?有没有办法获得在各种下游任务中通用的“全能”预训练模型?这些问题都会在本文中一一被解答。
太长不看版:本文首先将论文中的众多实验性结论总结如下,后面会对其进行详细介绍:
- 对于轻量级 ViT(例如 5.7M 的 ViT-Tiny),当下游任务的数据比较充足时,基于 Masked-Image-Modeling(MIM)的自监督预训练方法 [1][2] 表现最好,优于基于Contrastive Learning(CL)的方法 [3][4],甚至比基于 ImageNet-21k 的全监督预训练模型表现得更好;
- 原始的 ViT 结构在轻量模型这个赛道中仍旧具有巨大潜力,而合适的预训练手段就是释放其潜力的一把钥匙,例如:采用合适的基于 MAE(Masked AutoEncoder [1])的预训练并在 ImageNet 上进行微调后,仅包含 5.7M 参数的原始的 ViT-Tiny 就可以取得 79.0% 的 top1 accuracy,超过了一众轻量级 ConvNets 和近两年各种精心设计的 ViT 变种网络;
- 基于 MAE 的预训练轻量级 ViT 并不是万能的,它也有一些缺陷,例如:当下游任务的数据规模比较小时,它的迁移效果就很差,明显弱于全监督的预训练模型,也比基于 CL 的预训练模型差;
- 出现上述现象的原因可能是:基于 MIM 的预训练模型浅层(靠近输入端的若干层)学的非常好,而高层(靠近输出端的若干层)却出现了明显的表征退化;而基于 CL 的预训练模型虽然高层能学到还不错的语义特征,但却无法学习到可能对下游任务更有帮助的一些归纳偏置(inductive bias);
- 通过知识蒸馏,可以借助一个更大规模的基于 MAE 的预训练模型(例如MAE-Base)去帮助轻量级 ViT 的预训练,仅采用基于 attention map 的蒸馏就可以显著改善其在小规模下游任务上的糟糕表现。
接下来会对论文的内容进行具体介绍。

哪种预训练方法表现最好?
文章基于 ViT-Tiny(5.7M)这个采用原始 ViT 结构的轻量级模型,首先采用各种预训练方法得到若干预训练模型(各种方法均针对轻量级模型进行了训练配置调优),测试了它们在 ImageNet-1k 上的微调性能。
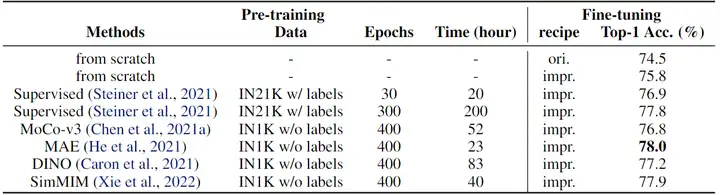
▲ 各种预训练方法在ImageNet上的对比
表中可以看出:对于轻量级 ViT,其同样可以像大模型一样,显著受益于各种预训练方法。其中,基于 MIM 的自监督预训练方法(例如 MAE,SimMIM)表现出优于 CL 的自监督预训练方法(例如 MoCo-v3,DINO)的效果,甚至优于基于更大规模的 ImageNet-21k(IN21K)的全监督预训练;而其中 MAE 的预训练成本最低,且精度最高。
于是,我们便好奇,在合适的预训练手段加持下,ViT-Tiny 这个结构足够原始且简单的模型的性能上限究竟有多高?

预训练加持下的轻量级ViT的性能上限有多高?
我们对 ViT-Tiny 采用 MAE 进行预训练,然后在 ImageNet 上进行微调,其与其他一众轻量级模型的对比如下:
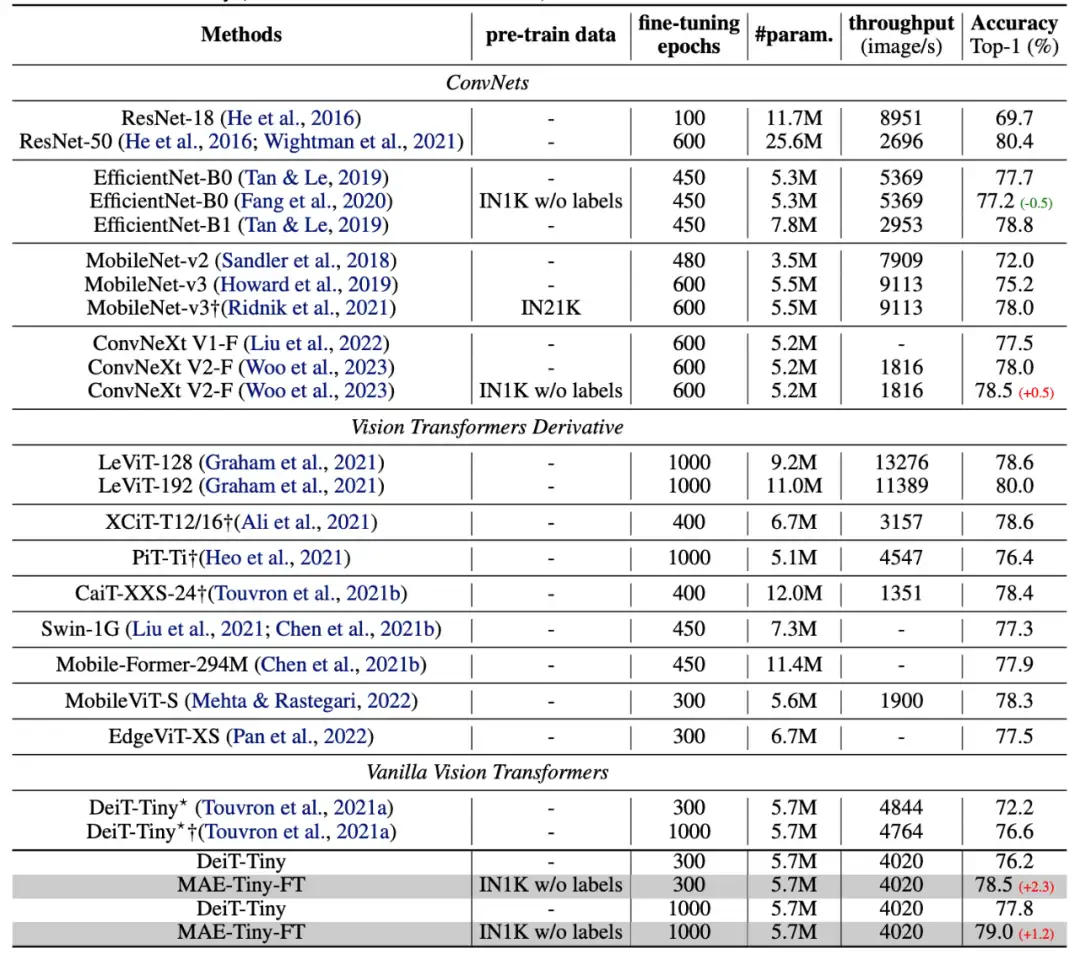
▲ 采用合适的预训练后ViT-Tiny与SOTA轻量级网络的性能对比
表中可见,即使是在足够强的 fine-tuning 的 recipe 下,MAE 的预训练依旧可以带来显著的性能增益(77.8→79.0),且基于 MAE 预训练的模型只微调了 300 epochs 就已超过了从头训练 1000 epochs 的模型(78.5 vs. 77.8)。而与表中的众多 ConvNets 和 ViT 的变种网络相比,ViT-Tiny 依旧表现出非常有竞争力的性能,且具有较高的 throughput。
这说明:一个“普通”的网络结构与 SOTA 的性能之间,差的可能只是一个合适的训练方案,这为轻量级模型的研究提供了一条除人工设计复杂网络结构之外的道路。
除此之外,表中还包括一些采用了全监督、自监督预训练的卷积网络,但是可以看出:预训练对于 ViT 的增益更大(例如:ConvNeXt V2-F 采用基于 MIM 的预训练只能提升 0.5,而 ViT-Tiny 却可以提升 1.2),这个可以理解为:ViT 结构具有更少的人为设计的特性,而预训练可以以数据/任务驱动的模式对其进行补足,因此其增益更大,且表现出比通过人为设计引入inductive bias的网络更强的潜力。
换句话说:基于 naive 的网络结构,通过合适的预训练与数据驱动,使得它变成下游任务需要的模样,可能比人为设计模型应该是什么样子具有更高的性能上限。

预训练方案有哪些缺陷?
首先,我们发现,对于轻量级 ViT 来说,增加预训练数据的规模无法使得其取得更好的迁移性能:
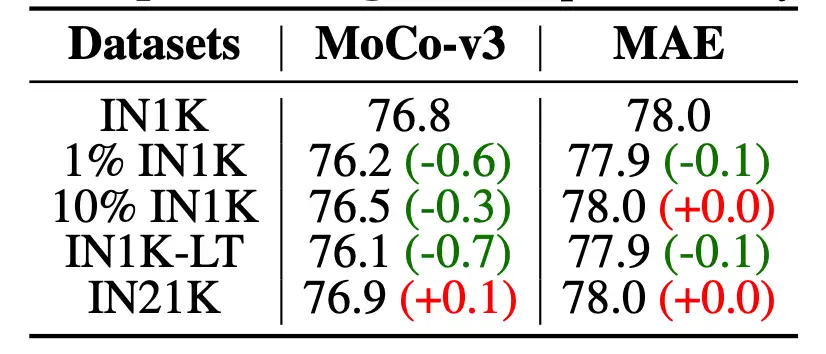
▲ 预训练数据对下游性能的影响
甚至 MAE 对于预训练数据表现出惊人的鲁棒性:只用 1% 的预训练数据依旧可以取得与使用 100%ImageNet-1k(IN1K)相近的性能,且对于预训练数据的类别分布也不太敏感。
其次,我们发现,这些轻量级自监督预训练模型似乎没办法很好的迁移到数据规模较小的下游任务上:
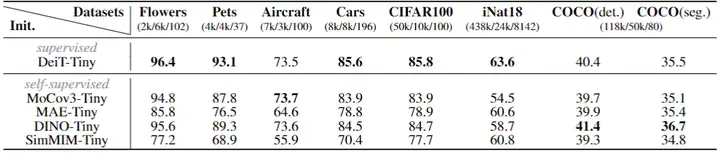
▲ 预训练模型在下游任务中的迁移性能
其中,在各种下游分类任务上,基于 MIM 的预训练模型表现明显弱于全监督预训练模型,而基于 CL 的预训练模型同样如此但差距较小;而在 COCO 检测任务上,基于 CL 的 DINO 预训练模型则表现出更好的迁移性能;这与在 ImageNet 上观察到的现象并不一致。
这说明,不同预训练模型在不同规模的下游数据集上可能表现出不一致的特性,可能需要根据下游数据集的特性选择合适的预训练方案。例如:当下游数据集规模较小且数据集类别分布与预训练数据较为一致时,全监督预训练方案可能更为合适;而当下游数据足够充足时,基于 MIM 的预训练方案可能效果更好。
接下来,我们尝试引入一些模型分析手段,对这些预训练模型进行分析,以期理解出现上述实验现象的原因。

预训练模型逐层表征分析
我们首先以基于 IN1K 全监督训练 ViT 模型(DeiT-Tiny)作为参考模型,研究各种预训练模型(基于 MAE 的 MAE-Tiny,基于 SimMIM 的 SimMIM-Tiny,基于 MoCo v3 的 MoCov3-Tiny 与基于 DINO 的 DINO-Tiny)与其之间的逐层表征相似度 [5]。
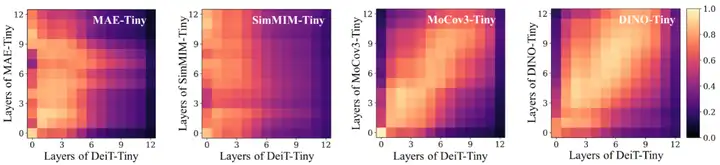
▲ 预训练模型逐层表征分析
我们发现:
- 同类预训练模型具有相似的逐层表征结构,例如:基于 MIM 的 MAE-Tiny 和 SimMIM-Tiny 的相似度 heatmap 比较像,而基于 CL 的 MoCov3-Tiny 和 DINO-Tiny 较为相似;
- 基于 MIM 的预训练模型高层出现了表征退化,即其高层表现出与 DeiT-Tiny 浅层较高的相似度;
- 基于 CL 的预训练模型与 DeiT-Tiny具有较好的逐层对齐关系。
据此我们推测,可能正是这些模型高层的差异导致了上述实验现象。为验证这个猜想,我们进行了如下实验:仅保留预训练模型的若干浅层,测试其在各种规模的下游任务上的迁移性能,已测试预训练模型各层对于迁移性能的贡献度。
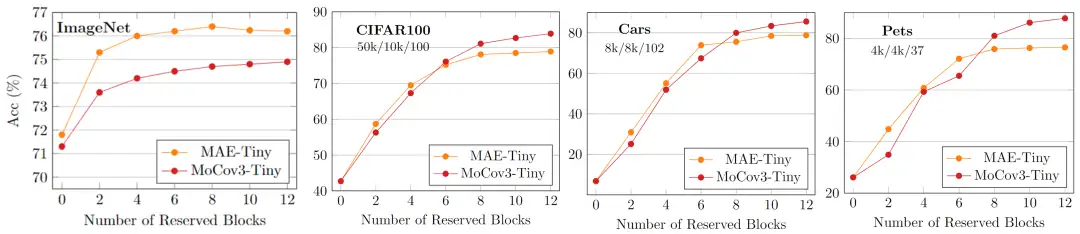
▲ 仅保留若干层的预训练模型的迁移性能评估
图中可以看出:
- 仅保留 MAE-Tiny 的前 4 层即可在 ImageNet 上取得良好的迁移性能,这说明,对于数据充足的下游任务,预训练模型的浅层可能更加重要,而高层的质量则影响较小;
- 随着数据规模减小,MoCov3-Tiny 的高层对于性能的增益越来越大,这也是其在这些数据集上性能超过 MAE 的关键,这说明,对于数据规模较小的下游任务,预训练模型的高层也很重要。
以上分析也说明,想办法改进 MAE-Tiny 的高层表征质量,或许可以提高其在小规模下游任务中的迁移性能。

预训练模型逐层注意力分析
接下来,我们分析预训练模型逐层的 attention map,对于 ViT 来说,它可以反映模型在自注意力机制中信息融合的偏好特性。具体来说,我们选择重点分析 attention distance 与 attention entropy,前者可以反映每个 token 是较多关注到近处(local)的区域还是远处的区域(即 global),后者可以反映每个 token 的关注点是集中到少数几个 token 上(concentrated)还是广泛地关注到众多 token 上(broad)。
我们以箱线图的形式,可视化了预训练模型逐层 attention distance 与 entropy 的分布。
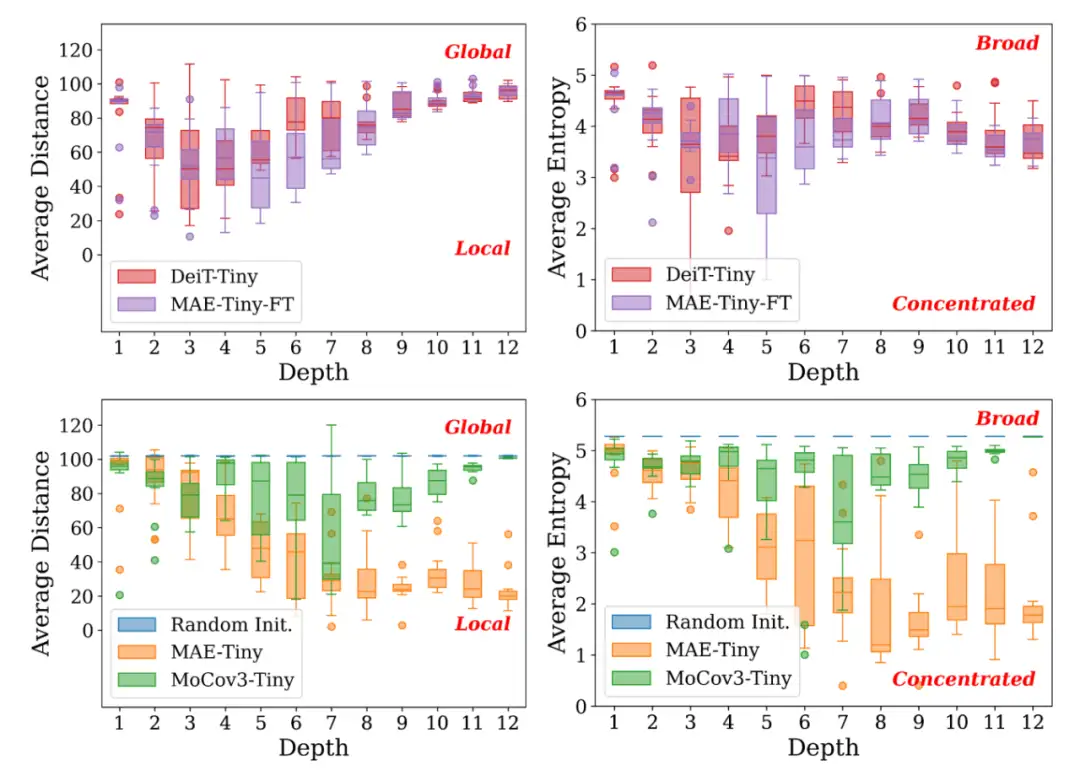
▲ 预训练模型attention分析
我们首先对比了是否采用 MAE-Tiny 作为预训练在 ImageNet-1k 上微调(训练)后的模型(MAE-Tiny-FT vs. DeiT-Tiny),发现采用 MAE-Tiny 作为预训练可以使得模型的 attention 更加 local 与 concentrated,这些可能被作为 inductive bias 被预训练引入到了模型中,使得其在 ImageNet 上取得了更好的性能表现。
而对比 MoCov3-Tiny 与 MAE-Tiny 可以发现,虽然两者相较于随机初始化均可一定程度上引入 local inductive bias,但 MoCov3-Tiny 从浅层到高层仍旧较为 global 且 broad。这种特性可能使得以其为初始化的模型在下游微调时倾向于“走捷径”,直接关注到全局信息而忽视局部细节信息。这对于较为简单的下游任务来说可能是足够的,但却未必适宜难度较高的需要细粒度识别的分类任务(例如 ImageNet)。
最后,文章验证了采用一种简单的知识蒸馏手段,即可显著改善基于MAE的轻量级预训练的质量,并显著改善其下游迁移性能。

蒸馏方法与实验效果
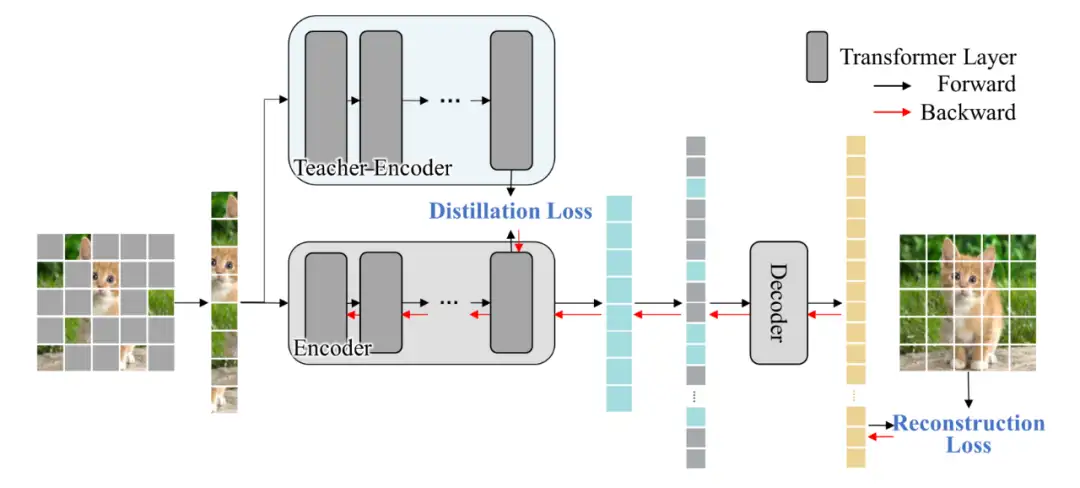
▲ 预训练蒸馏流程图
具体来说,基于 MAE 的框架,引入一个同样采用 MAE 预训练的较大规模的网络(例如 MAE-Base),并基于教师网络与学生网络的 attention map 之间的相似度构建蒸馏损失:
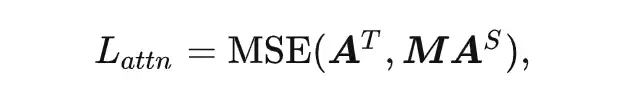
其中 分别表示教师和学生网络的 attention map, 表示均方误差损失, 是一个 adapter,用来对齐师生 attention map的head 数,随着学生网络一起学习。实验发现,仅在师、生网络的最高层的 attention map 应用上述蒸馏损失即可取得良好的效果。这一蒸馏过程可显著改善基于 MAE 的轻量级预训练模型的高层表征质量,弥补此预训练方法无法学习到高质量高层表征的缺陷,进而可显著提高其在多种下游任务中的迁移性能。
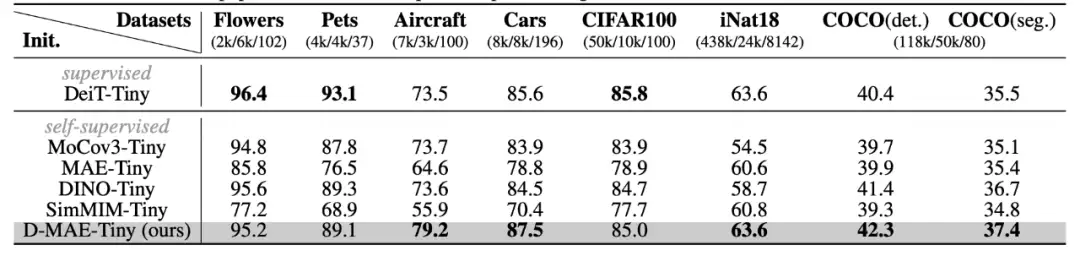
▲ 知识蒸馏可显著改善预训练模型

总结
文章聚焦在轻量级 ViT 的预训练上,相当于为相关方向的研究提供了一个 benchmark,相关的代码与模型也都会开源,方便后续大家在这一方向上继续探索。文章的研究也打破了之前人们对于 ViT 在轻量级赛道上没有竞争优势的惯有印象,只要采用合适的预训练手段,轻量级 ViT 也会表现出足够的竞争力。
同时,文章也相当于为后续轻量级模型结构设计的相关研究提出了一个新的且足够高的 bar,“你的优势未必是因为你足够好,可能只不过是因为你曾经看不上的竞争对手还没有充分发力”。文章首次将知识蒸馏引入基于 MIM 的轻量级 ViT的预训练中,并以极简的形式取得了显著的性能提升。
文章在解决了一些问题的同时也带来了更多的问题,例如:有没有办法可以让轻量级 ViT 吃下更多的预训练数据带来更多的增益?有没有办法高效融合基于 CL 和 MIM 的预训练方法,使得其兼具两者的优势?有没有办法不借助知识蒸馏来提升基于 MIM 的预训练模型的高层表征质量?这些问题可能都值得未来去进一步探索。
参考文献
[1] Masked Autoencoders Are Scalable Vision Learners. https://arxiv.org/abs/2111.06377
[2] SimMIM: A Simple Framework for Masked Image Modeling. https://arxiv.org/abs/2111.09886
[3] An Empirical Study of Training Self-Supervised Vision Transformers. https://arxiv.org/abs/2104.02057
[4] Emerging Properties in Self-Supervised Vision Transformers. https://arxiv.org/abs/2104.14294
[5] Algorithms for Learning Kernels Based on Centered Alignment. https://arxiv.org/abs/1203.0550
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【技术文档】《从零搭建pytorch模型教程》122页PDF下载
QQ交流群:470899183。群内有大佬负责解答大家的日常学习、科研、代码问题。
其它文章
YOLO终结者?百度最新RT-DETR:114FPS实现54.8AP,远超YOLOv8!
全新YOLO模型YOLOCS来啦 | 面面俱到地改进YOLOv5的Backbone/Neck/Head
CVPR 2023 | 神经网络超体?新国立LV lab提出全新网络克隆技术
6G显存玩转130亿参数大模型,仅需13行命令,RTX2060用户发来贺电
libtorch教程(一)开发环境搭建:VS+libtorch和Qt+libtorch
NeRF与三维重建专栏(三)nerf_pl源码部分解读与colmap、cuda算子使用
NeRF与三维重建专栏(二)NeRF原文解读与体渲染物理模型
BEV专栏(一)从BEVFormer深入探究BEV流程(上篇)
可见光遥感图像目标检测(三)文字场景检测之Arbitrary
AI最全资料汇总 | 基础入门、技术前沿、工业应用、部署框架、实战教程学习
标签:Transformer,训练,ICML,模型,Tiny,MAE,ViT,轻量级 From: https://www.cnblogs.com/wxkang/p/17431576.html