关于AI绘画(基于Stable Diffusion Webui),我之前已经写过三篇文章,分别是 软件安装,基本的使用方法,微调模型LoRA的使用。
整体来说还是比简单的,搞个别人的模型,搞个提示词就出图了。今天来一个有些难度的,自己训练一个LoRA微调模型。

添加图片注释,不超过 140 字(可选)
0. LoRA微调模型是什么?
LoRA的全称是Low-Rank Adaptation of Large Language Models,有专门的论文和开源项目。它主要解决“大模型”太大,一般人玩不转的问题。
比如GPT-3 175B的参数,有几个人跑得起来呢?Stable Diffusion V1版模型用了150000 个 A100 GPU Hour,也不是个人玩得起的。
把LoRA应用到AI绘画之后,我们就可以用普通的消费级显卡来微调官方的模型了。
添加图片注释,不超过 140 字(可选)
0. LoRA微调模型是什么?
LoRA的全称是Low-Rank Adaptation of Large Language Models,有专门的论文和开源项目。它主要解决“大模型”太大,一般人玩不转的问题。
比如GPT-3 175B的参数,有几个人跑得起来呢?Stable Diffusion V1版模型用了150000 个 A100 GPU Hour,也不是个人玩得起的。
把LoRA应用到AI绘画之后,我们就可以用普通的消费级显卡来微调官方的模型了。

添加图片注释,不超过 140 字(可选)
微调的意思,就是原先模型的基础上“夹带私货”。最常见的就是,让模型学习指定的风格或者人物。风格这种可能还是有点抽象,而人物这个就比较直观了。比如默认情况下,AI绘画软件无法画出指定的人物,而通过Lora模型就可以做到这一点。
添加图片注释,不超过 140 字(可选)
微调的意思,就是原先模型的基础上“夹带私货”。最常见的就是,让模型学习指定的风格或者人物。风格这种可能还是有点抽象,而人物这个就比较直观了。比如默认情况下,AI绘画软件无法画出指定的人物,而通过Lora模型就可以做到这一点。

添加图片注释,不超过 140 字(可选)
这样一来,你就可以把自己或者你的宠物或者你的女神投射到AI绘画的模型中,然后通过描述词,让这个人物“千变万化”。
添加图片注释,不超过 140 字(可选)
这样一来,你就可以把自己或者你的宠物或者你的女神投射到AI绘画的模型中,然后通过描述词,让这个人物“千变万化”。

添加图片注释,不超过 140 字(可选)
关于LoRA大概就说这些,更多专业的内容,可以看文末。
下面就开始介绍Lora的具体的训练方法了。开始之前简单说一下我的环境:
添加图片注释,不超过 140 字(可选)
关于LoRA大概就说这些,更多专业的内容,可以看文末。
下面就开始介绍Lora的具体的训练方法了。开始之前简单说一下我的环境:
- 操作系统是Windows11
- 显卡是 RTX 3060 12G
- 开源软件 Stable-Diffusion-WebUI
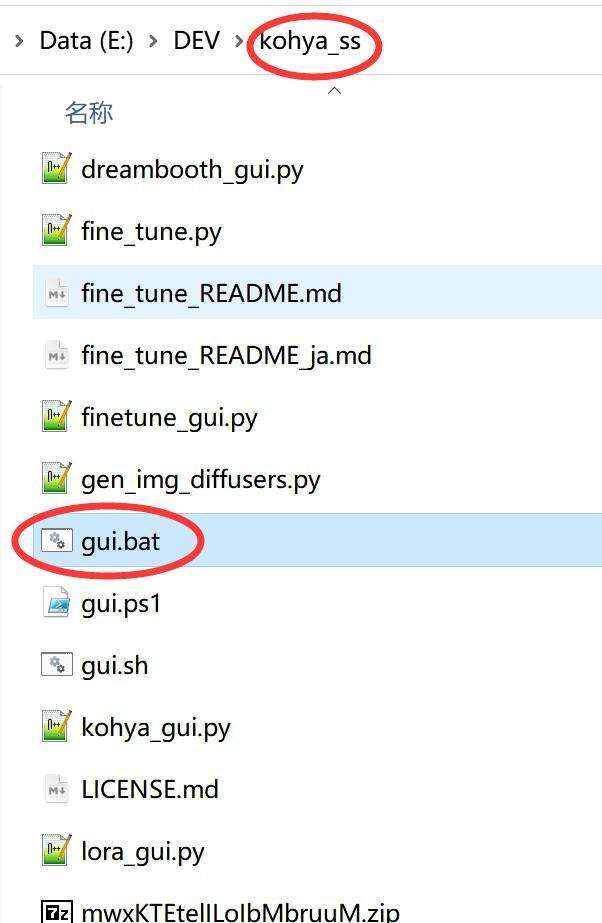
1.软件安装 训练Lora的方法不止一种,我这里选择的是一个叫kohya_ss的项目。这个项目比较独立,整个设计逻辑比较清晰,可以用可视化的方式配置参数,也提供了一些辅助工具,官方提供了详细的视频教程(英文)。 下面就来说一下如何安装。 安装基础软件:
- 安装 Python 3.10 记得添加到环境变量。
- 安装 Git
- 安装VS环境 Visual Studio xxx redistributable
添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
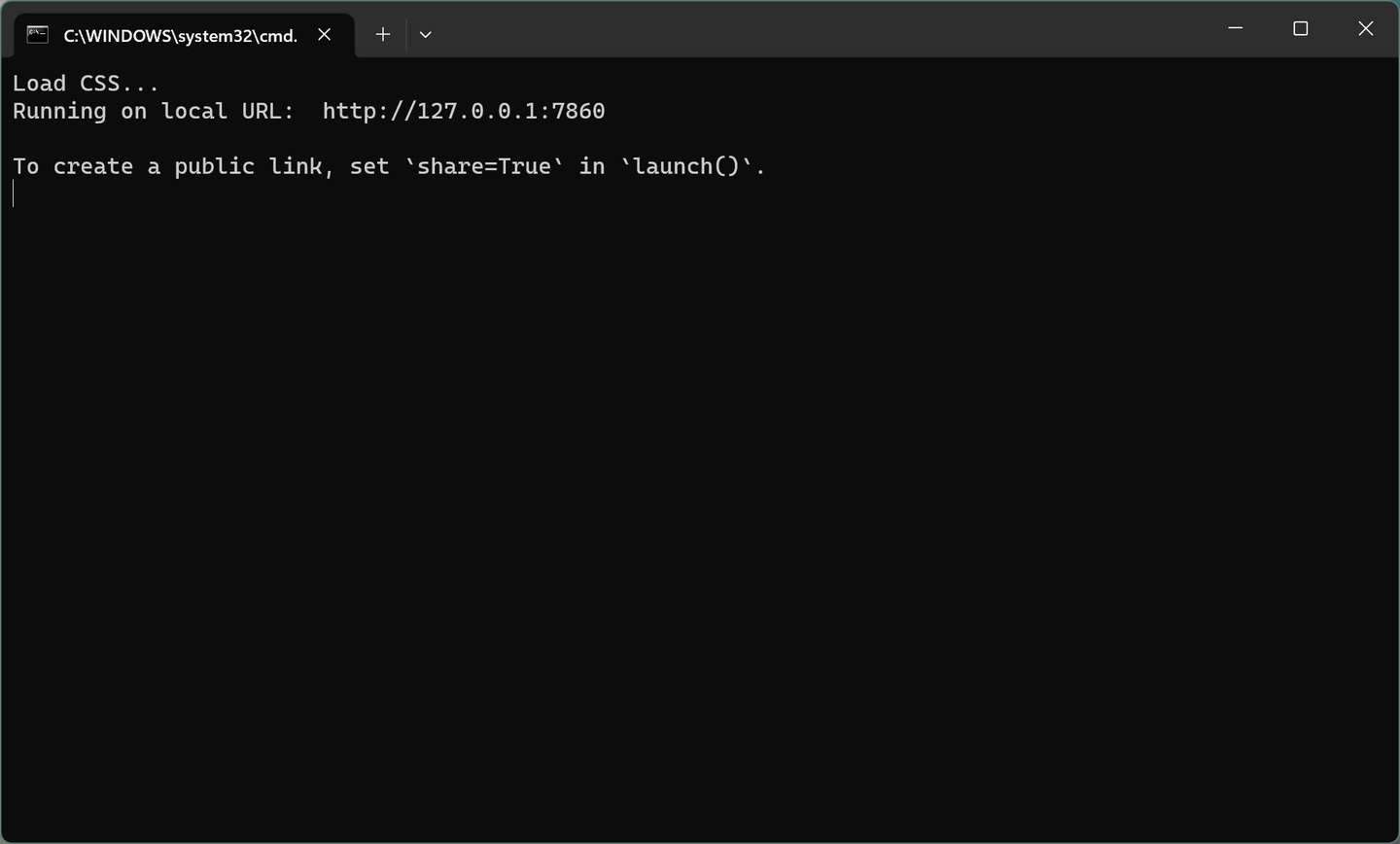
把URL复制到浏览器,就可以看到界面了。
2.素材准备和预处理
所有的模型训练都遵循一个最基本的道理:好进好出。喂得素材好,训练的模型自然好。喂的是垃圾,出来的必然也是垃圾。所以第一步,就是把素材整好了。
素材处理呢,其实也分三个小步骤。
a.找素材
b.切素材
c.生成对应的关键词
素材可以通过不同渠道获取,比如最简单粗暴的方式就是直接在百度图片里面搜索。然后选择高清,或者大尺寸,特大尺寸。点进去之后看看有没有套图。
也可以直接去一些壁纸网站或者专门晒图的网站。比如糖堆,花瓣,Pinterest, Instagram...
添加图片注释,不超过 140 字(可选)
把URL复制到浏览器,就可以看到界面了。
2.素材准备和预处理
所有的模型训练都遵循一个最基本的道理:好进好出。喂得素材好,训练的模型自然好。喂的是垃圾,出来的必然也是垃圾。所以第一步,就是把素材整好了。
素材处理呢,其实也分三个小步骤。
a.找素材
b.切素材
c.生成对应的关键词
素材可以通过不同渠道获取,比如最简单粗暴的方式就是直接在百度图片里面搜索。然后选择高清,或者大尺寸,特大尺寸。点进去之后看看有没有套图。
也可以直接去一些壁纸网站或者专门晒图的网站。比如糖堆,花瓣,Pinterest, Instagram...

添加图片注释,不超过 140 字(可选)
图片的最基本要求是,清晰,清晰,清晰。其次,不要太单一。
图片比例,并没有强制要求。建议用1:1或者其他固定的比例去切。
图片数量方面,一般来说是准备个几十张的样子。太多了整理起来就比较费时间,训练时长也会边长长,训练不充分可能就没那么像。太少就会过拟合,不容易产生变化,描述词一改可能就不像了。
添加图片注释,不超过 140 字(可选)
图片的最基本要求是,清晰,清晰,清晰。其次,不要太单一。
图片比例,并没有强制要求。建议用1:1或者其他固定的比例去切。
图片数量方面,一般来说是准备个几十张的样子。太多了整理起来就比较费时间,训练时长也会边长长,训练不充分可能就没那么像。太少就会过拟合,不容易产生变化,描述词一改可能就不像了。

添加图片注释,不超过 140 字(可选)
从经验来看,聚焦半身或者头部更容易训练,更容易出稳定的效果,除了主体之外,背景尽量简单,减少干扰。
添加图片注释,不超过 140 字(可选)
从经验来看,聚焦半身或者头部更容易训练,更容易出稳定的效果,除了主体之外,背景尽量简单,减少干扰。

添加图片注释,不超过 140 字(可选)
同一个明星的照片其实也是千差万别,有时候甚至P的都不像了一个人了,最好是能找到样貌比较稳定连续的素材。
找到素材之后,你可以用专业的工具进行裁剪。也可以直接用QQ的截图功能。
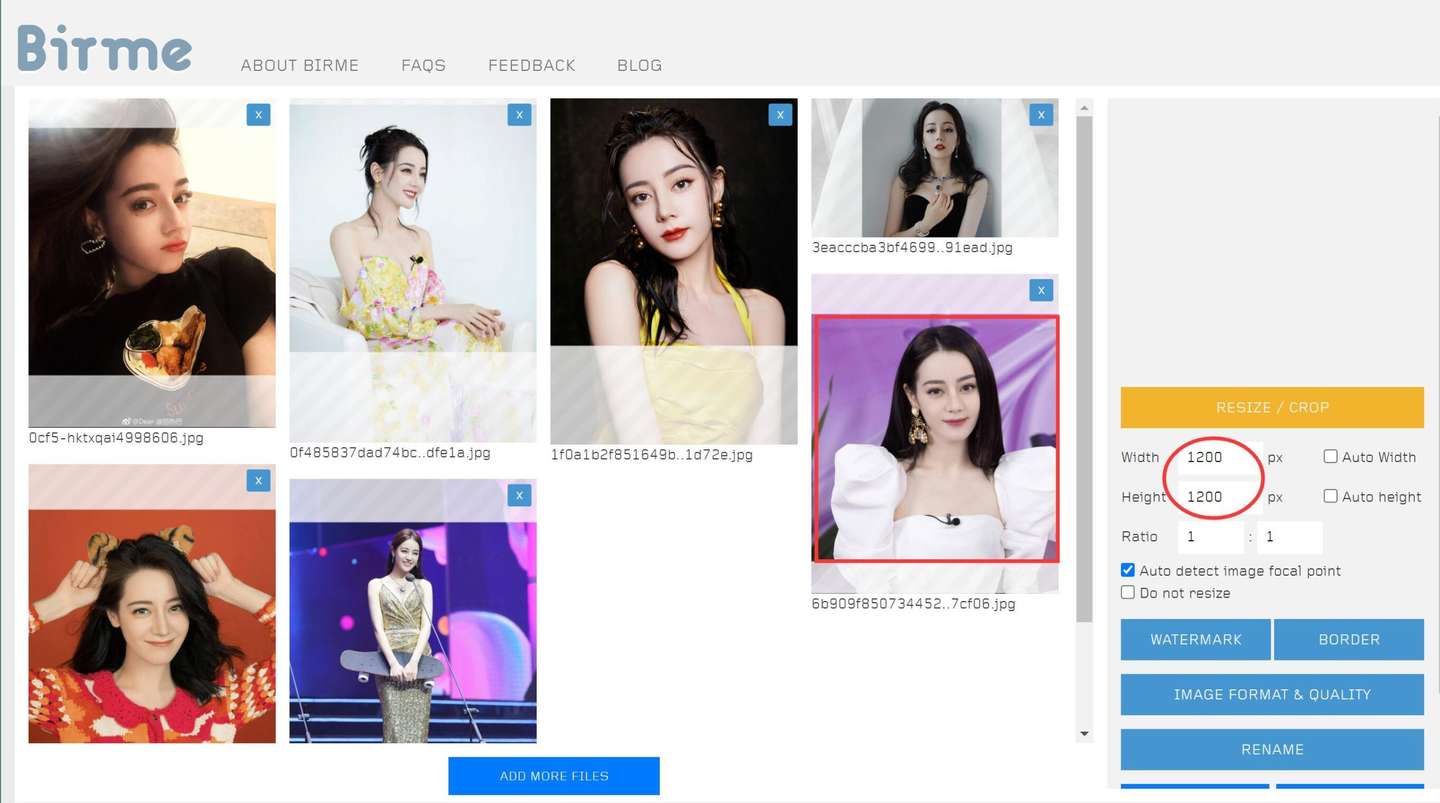
比如用Birme来处理:
添加图片注释,不超过 140 字(可选)
同一个明星的照片其实也是千差万别,有时候甚至P的都不像了一个人了,最好是能找到样貌比较稳定连续的素材。
找到素材之后,你可以用专业的工具进行裁剪。也可以直接用QQ的截图功能。
比如用Birme来处理:
添加图片注释,不超过 140 字(可选)
我这里就遵循能简单就简单的原则,直接用QQ截图,也没有严格1:1 。就是切了个大概,把主体切出来。
图片预处理完成之后,需要创建一个专门的训练文件夹。我是在kohya_ss的根目录创建一个名叫train的文件,然后在这个文件下面又创建一个叫Dilireba的文件夹。
添加图片注释,不超过 140 字(可选)
我这里就遵循能简单就简单的原则,直接用QQ截图,也没有严格1:1 。就是切了个大概,把主体切出来。
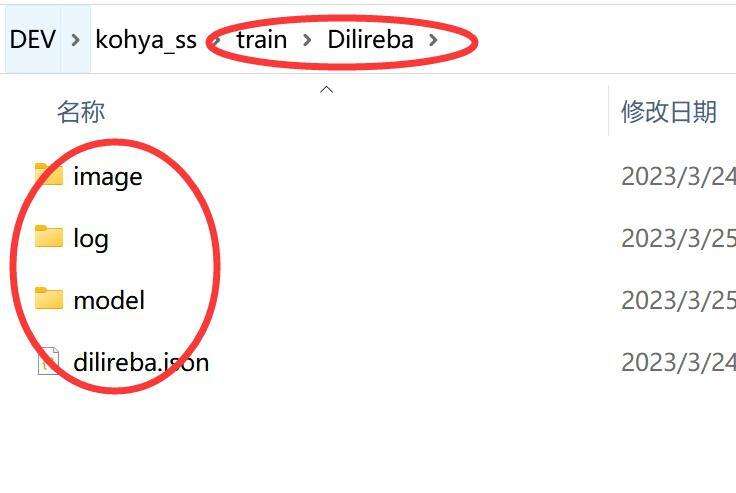
图片预处理完成之后,需要创建一个专门的训练文件夹。我是在kohya_ss的根目录创建一个名叫train的文件,然后在这个文件下面又创建一个叫Dilireba的文件夹。
添加图片注释,不超过 140 字(可选)
里面又分别创建了如下的文件夹:
image : 图片放在这里。
log:训练记录
model:模型保存路径
dilireba.json:配置文件。
image文件夹里面不是直接放图片,而是还有一个子文件夹,名称大概是这样100_dilireba。所有图片这放在这个子文件里面。这里的100不是随便写的,会直接影响训练的步数和效果。
创建好文件,将处理好的图片放在100_dilireba里面,然后就要做关键词生成了。
在网页上找到Utilities->Captioning->BLIP Captioning。
添加图片注释,不超过 140 字(可选)
里面又分别创建了如下的文件夹:
image : 图片放在这里。
log:训练记录
model:模型保存路径
dilireba.json:配置文件。
image文件夹里面不是直接放图片,而是还有一个子文件夹,名称大概是这样100_dilireba。所有图片这放在这个子文件里面。这里的100不是随便写的,会直接影响训练的步数和效果。
创建好文件,将处理好的图片放在100_dilireba里面,然后就要做关键词生成了。
在网页上找到Utilities->Captioning->BLIP Captioning。
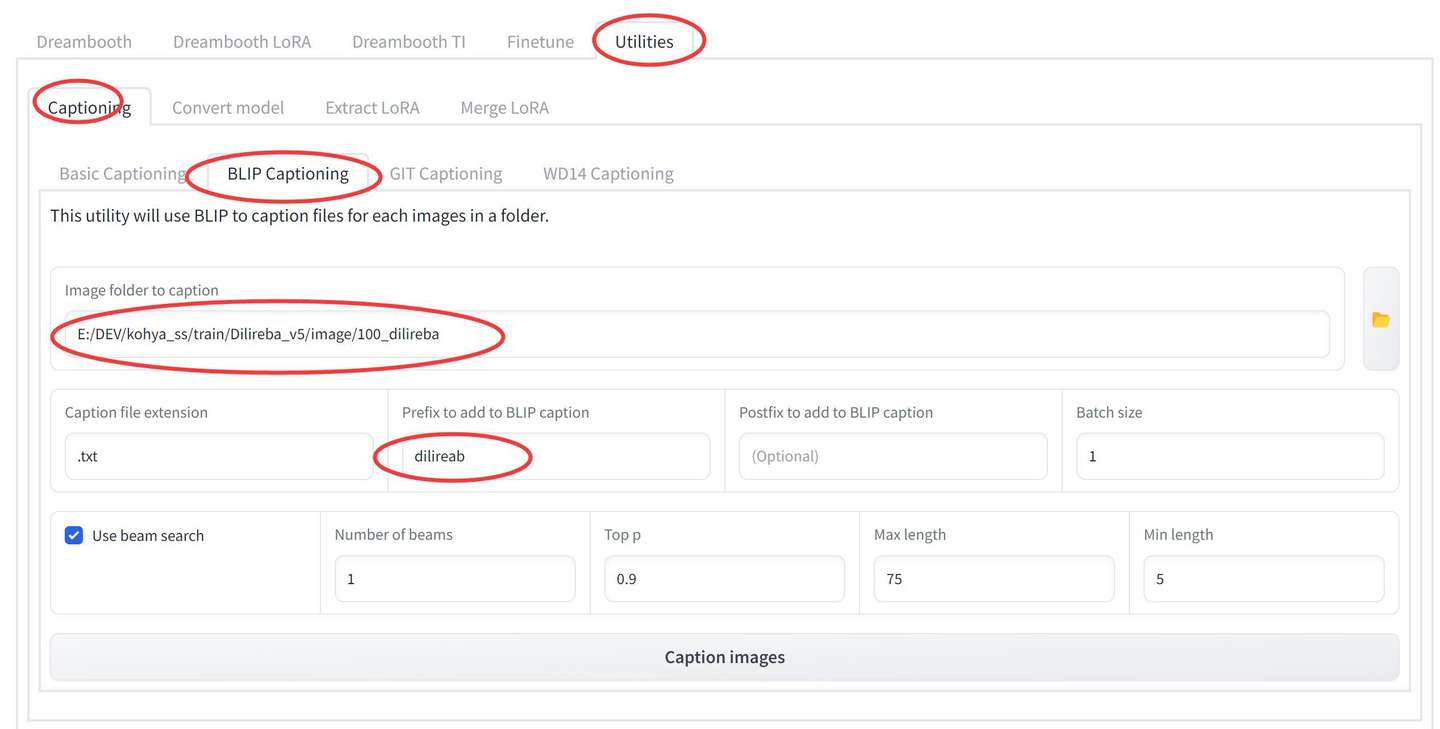
添加图片注释,不超过 140 字(可选)
这里只要设置两个选项。
Image folder to caption : 图片文件夹所在路径。
Prefix to add to BLIP caption : 生成提示词的前缀,训练完成之后可以用在提示词中,唤醒或者加强人物特征。
设置完成之后点击“Caption images” 开始处理。第一次处理应该是需要在线下载一些模型,稍微等待一下。点击按钮之后,界面上没有任何提示,但是在命令行窗口中会有具体的显示。
处理完成之后,在图片文件里面,会多出同名的txt文件。
添加图片注释,不超过 140 字(可选)
这里只要设置两个选项。
Image folder to caption : 图片文件夹所在路径。
Prefix to add to BLIP caption : 生成提示词的前缀,训练完成之后可以用在提示词中,唤醒或者加强人物特征。
设置完成之后点击“Caption images” 开始处理。第一次处理应该是需要在线下载一些模型,稍微等待一下。点击按钮之后,界面上没有任何提示,但是在命令行窗口中会有具体的显示。
处理完成之后,在图片文件里面,会多出同名的txt文件。
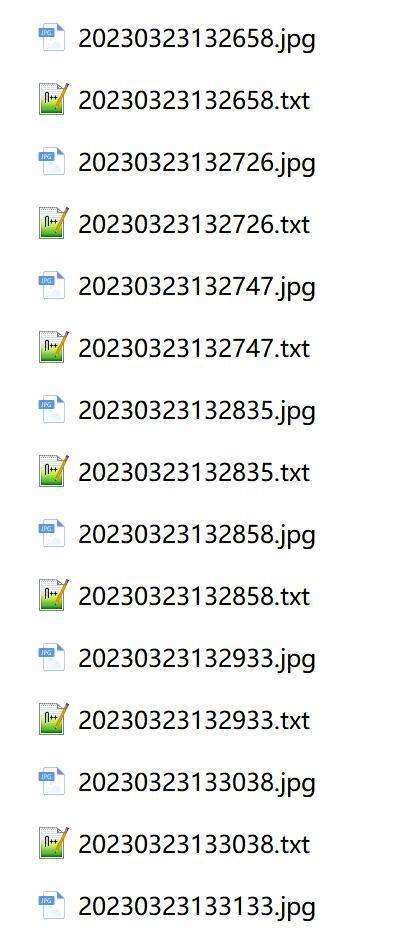
添加图片注释,不超过 140 字(可选)
打开文件之后,可以看到类似的文字描述“dilireba a woman in a black dress with a red lipstick”。作为简单的练手,我们不需要修改任何东西。如果你要提升效果,可以手动加入更加详细,更加精准的描述。
添加图片注释,不超过 140 字(可选)
打开文件之后,可以看到类似的文字描述“dilireba a woman in a black dress with a red lipstick”。作为简单的练手,我们不需要修改任何东西。如果你要提升效果,可以手动加入更加详细,更加精准的描述。
3.模型参数设置和训练 经过上面的处理,素材已经搞定了。接下来就是设置训练参数。如果你已经有参数配置文件,可以直接通过点击Open按钮来导入。 参数设置主要分成了3部分。 第一部分是:预训练模型设置。
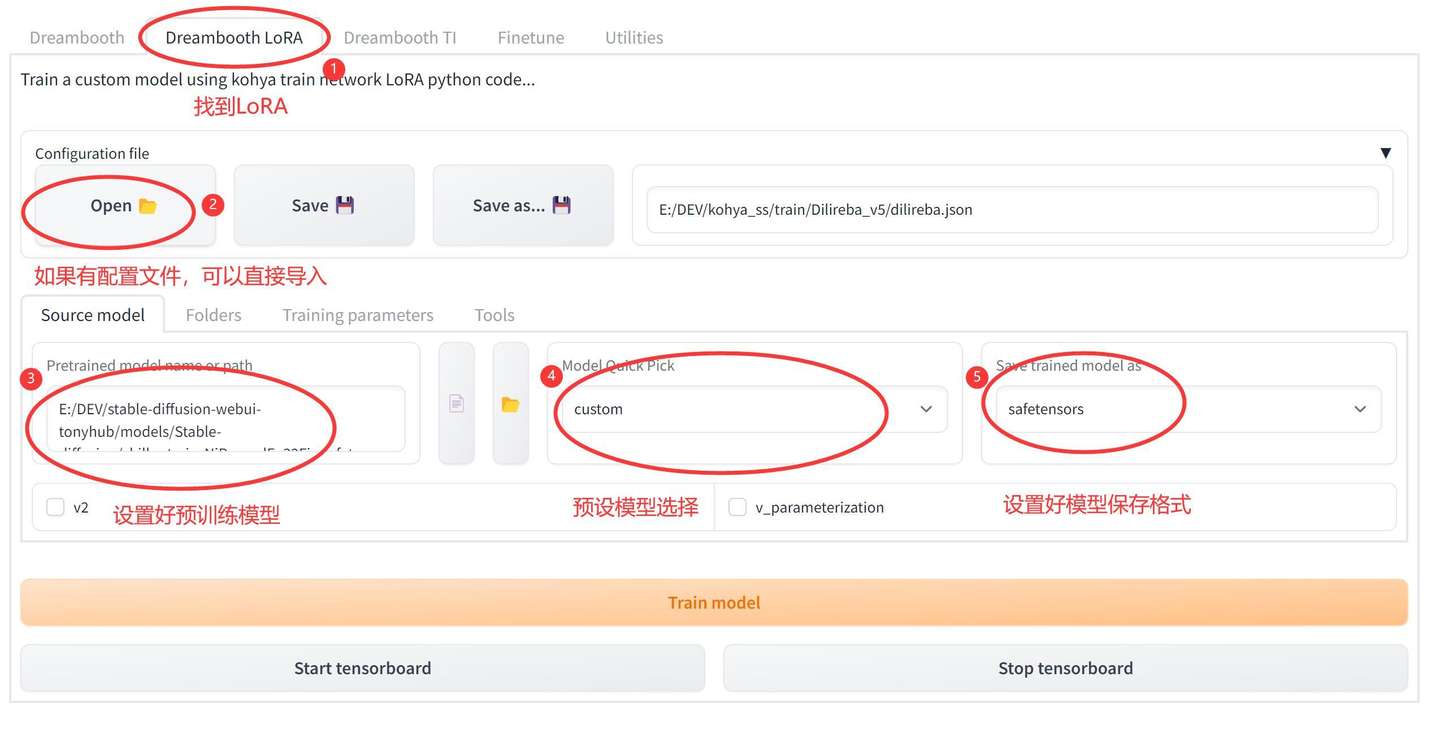
添加图片注释,不超过 140 字(可选)
Lora的训练需要基于标准的SDW模型(Checkpoint),点击Source model选项卡之后就可以进行设置。
先将④处的模型快速选择(Model Quick Pick)设置成自定义(Custom),这里也可以用预设的V1.5,V2.1。但是使用这些预设模型,会需要很长的时间在线下载,而且会占据巨大的C盘空间,不是很推荐。
然后在左边③这里选择具体的本地模型,我这里用的是适合亚洲人的chilloutmix模型。通过点击输入框后面的文件图标,找到具体的模型文件就可以了。
然后右边⑤处的模型保存格式选择safetensors。
第二部分是:文件夹设置。
添加图片注释,不超过 140 字(可选)
Lora的训练需要基于标准的SDW模型(Checkpoint),点击Source model选项卡之后就可以进行设置。
先将④处的模型快速选择(Model Quick Pick)设置成自定义(Custom),这里也可以用预设的V1.5,V2.1。但是使用这些预设模型,会需要很长的时间在线下载,而且会占据巨大的C盘空间,不是很推荐。
然后在左边③这里选择具体的本地模型,我这里用的是适合亚洲人的chilloutmix模型。通过点击输入框后面的文件图标,找到具体的模型文件就可以了。
然后右边⑤处的模型保存格式选择safetensors。
第二部分是:文件夹设置。
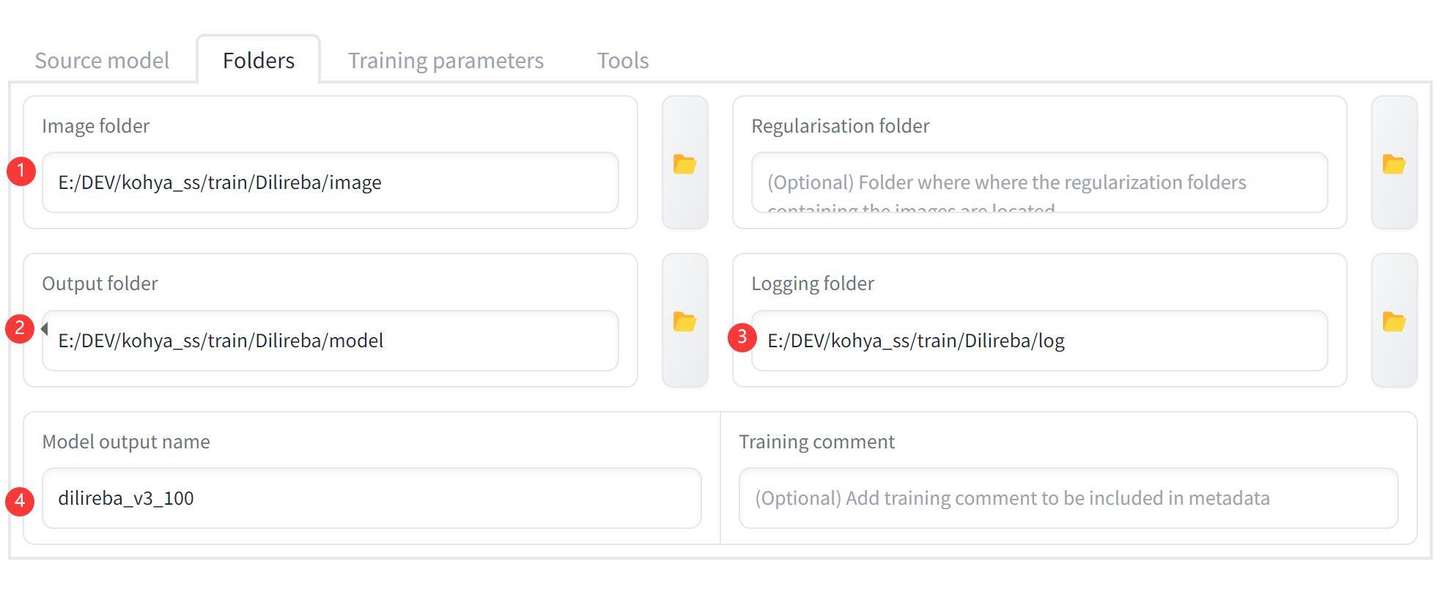
添加图片注释,不超过 140 字(可选)
在素材处理的步骤中,我们已经创建好了具体的文件。这里只需要通过右边的文件夹小图标,选中具体的文件夹就好了。
①Image folder 选择 image 文件夹
②Output folder 选择 model 文件夹
③Logging folder 选择 log 文件夹
④Model output name ,输入一个便于记忆的英文名字,这个名字就是最终生成的模型的名字。我习惯用主体+版本+迭代次数来命名。
第三部分是:训练参数设置。
这里的参数非常多,一般对于这种情况,我们都遵循一个基本原则:“对于新手来说,默认设置就是最佳设置”。
你可以完全不做任何设置,就开始训练了。
添加图片注释,不超过 140 字(可选)
在素材处理的步骤中,我们已经创建好了具体的文件。这里只需要通过右边的文件夹小图标,选中具体的文件夹就好了。
①Image folder 选择 image 文件夹
②Output folder 选择 model 文件夹
③Logging folder 选择 log 文件夹
④Model output name ,输入一个便于记忆的英文名字,这个名字就是最终生成的模型的名字。我习惯用主体+版本+迭代次数来命名。
第三部分是:训练参数设置。
这里的参数非常多,一般对于这种情况,我们都遵循一个基本原则:“对于新手来说,默认设置就是最佳设置”。
你可以完全不做任何设置,就开始训练了。
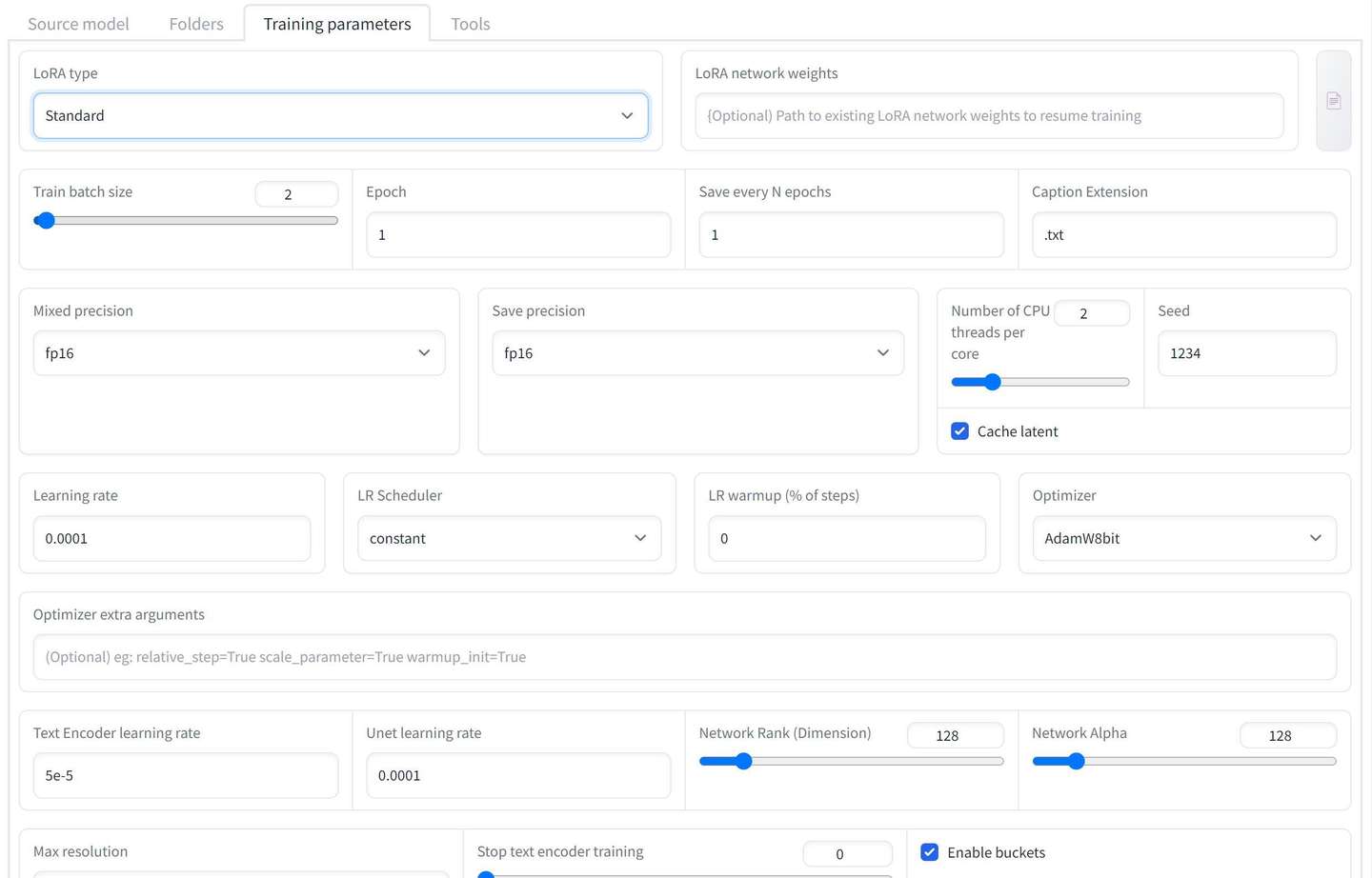
添加图片注释,不超过 140 字(可选)
我的部分参数设置如上图。
网上普遍的教程都是把批量大小(Train batch size)改成了2 。
设置一个种子(Seed)比如1234。
学习率(Learning rate)0.0001
Text Encoder学习率 5e-5
Unet学习率 0.0001
Network : 128和128
模型像素:512x512
添加图片注释,不超过 140 字(可选)
我的部分参数设置如上图。
网上普遍的教程都是把批量大小(Train batch size)改成了2 。
设置一个种子(Seed)比如1234。
学习率(Learning rate)0.0001
Text Encoder学习率 5e-5
Unet学习率 0.0001
Network : 128和128
模型像素:512x512

添加图片注释,不超过 140 字(可选)
参数设置完成之,点击底部的训练按钮①就可以开始训练了。
点击训练按钮之后,界面上没有任何变化,来到命令行窗口会看到一长串命令。
添加图片注释,不超过 140 字(可选)
参数设置完成之,点击底部的训练按钮①就可以开始训练了。
点击训练按钮之后,界面上没有任何变化,来到命令行窗口会看到一长串命令。
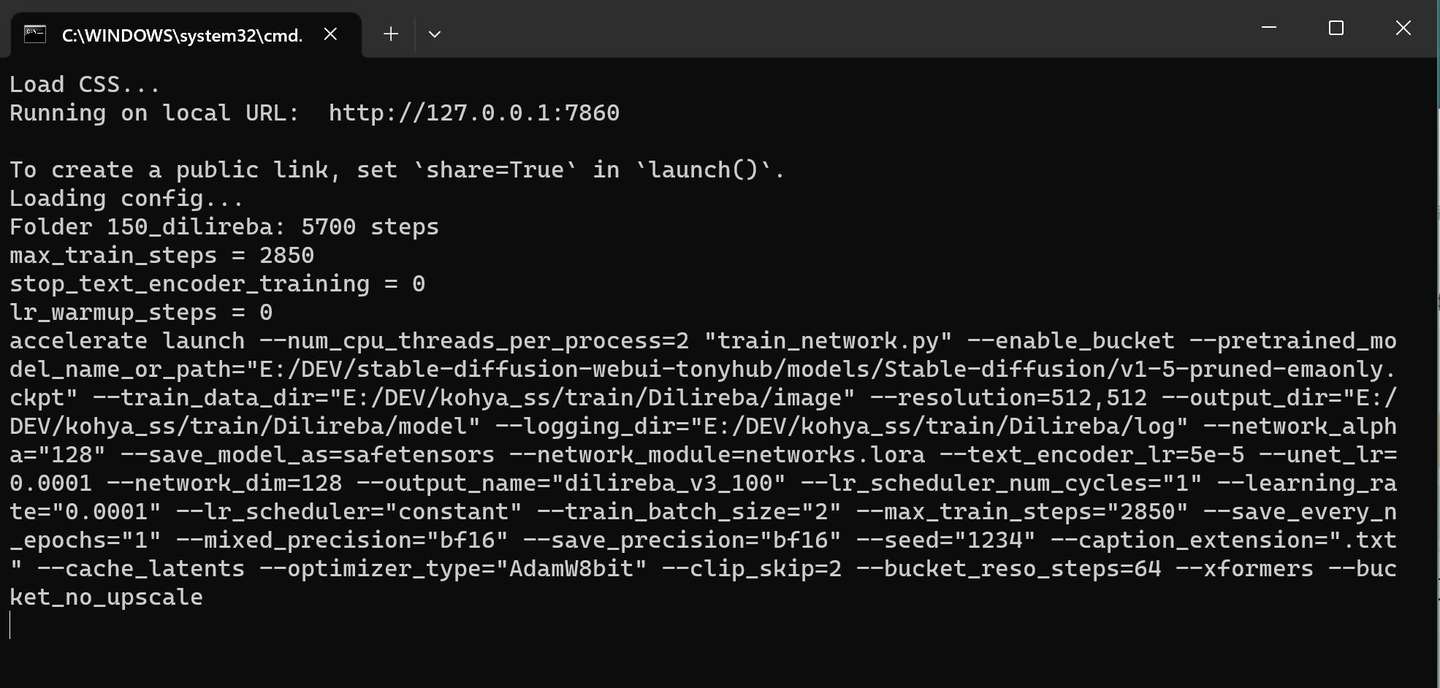
添加图片注释,不超过 140 字(可选)
这个界面会卡一段时间,然后跳出很多英文,最后停留在下面的界面。
添加图片注释,不超过 140 字(可选)
这个界面会卡一段时间,然后跳出很多英文,最后停留在下面的界面。
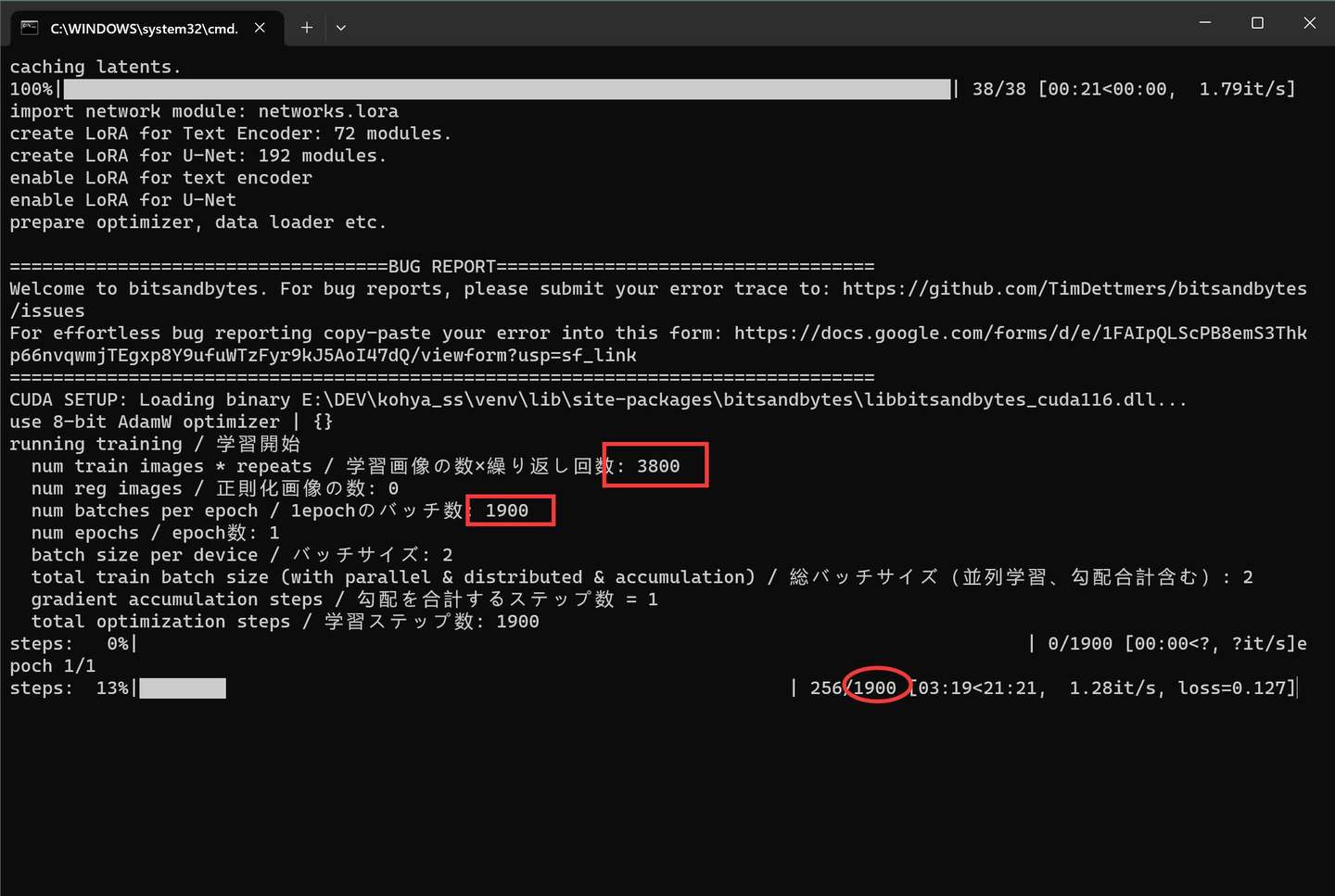
添加图片注释,不超过 140 字(可选)
这里会显示最终需要训练的步数(Step)。Step的值等于图片数量乘以文件中设置的数字,然后除以2 。训练的长短主要却决于单步的时间和总的步数。
关于多少步才比较好的问题,官方教程演示的时候是用了800。但是这个这个数值仅供参考。不同的数据会有不同,比如我后来整理一个图片比较多的数据集,跑了几万步,好像也还有提升的空间。
具体的训练情况,可以通过log来查看。点击上面②处的Start TensorBoard 可以启动一个服务。
添加图片注释,不超过 140 字(可选)
这里会显示最终需要训练的步数(Step)。Step的值等于图片数量乘以文件中设置的数字,然后除以2 。训练的长短主要却决于单步的时间和总的步数。
关于多少步才比较好的问题,官方教程演示的时候是用了800。但是这个这个数值仅供参考。不同的数据会有不同,比如我后来整理一个图片比较多的数据集,跑了几万步,好像也还有提升的空间。
具体的训练情况,可以通过log来查看。点击上面②处的Start TensorBoard 可以启动一个服务。
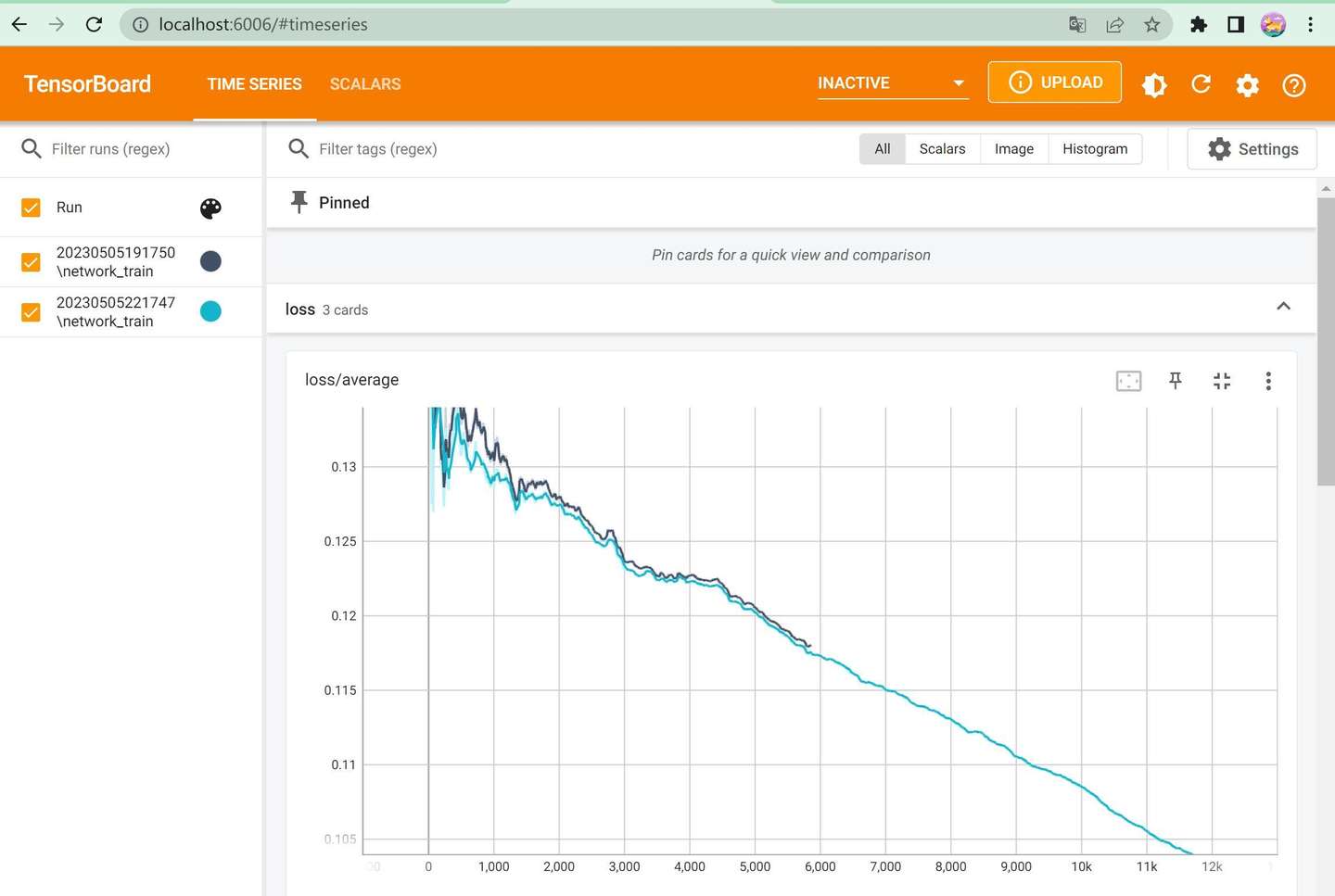
添加图片注释,不超过 140 字(可选)
打开后可以看到具体的Loss变化情况。简单的来说loss慢慢降低就是对的。如果Loss基本没啥变化,训练下去也没太大意义了。
4.模型应用
搞了那么久终于可以用了。
lora模型的使用,我们之前的文章里面已经有详细的介绍了,这里就简单的演示一下。当lora训练结束之后,会在对应的model文件下面生成模型文件。
比如下图:
添加图片注释,不超过 140 字(可选)
打开后可以看到具体的Loss变化情况。简单的来说loss慢慢降低就是对的。如果Loss基本没啥变化,训练下去也没太大意义了。
4.模型应用
搞了那么久终于可以用了。
lora模型的使用,我们之前的文章里面已经有详细的介绍了,这里就简单的演示一下。当lora训练结束之后,会在对应的model文件下面生成模型文件。
比如下图:
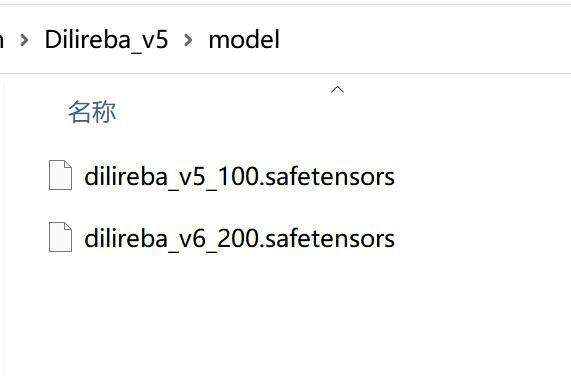
添加图片注释,不超过 140 字(可选)
将图中的Lora模型文件拷贝到Stable-Diffusion-WebUI的对应路路径下。
添加图片注释,不超过 140 字(可选)
将图中的Lora模型文件拷贝到Stable-Diffusion-WebUI的对应路路径下。
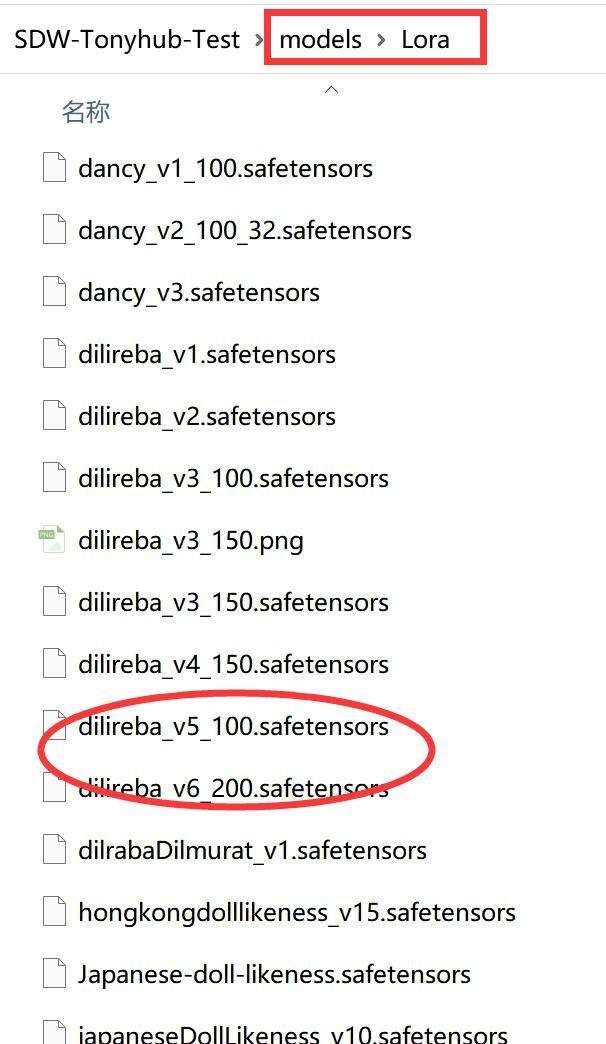
添加图片注释,不超过 140 字(可选)
然后启动AI绘画软件webui 。
添加图片注释,不超过 140 字(可选)
然后启动AI绘画软件webui 。

添加图片注释,不超过 140 字(可选)
然后选择好模型,输入关键词,选择对应的lora,然后点击生成即可。
添加图片注释,不超过 140 字(可选)
然后选择好模型,输入关键词,选择对应的lora,然后点击生成即可。
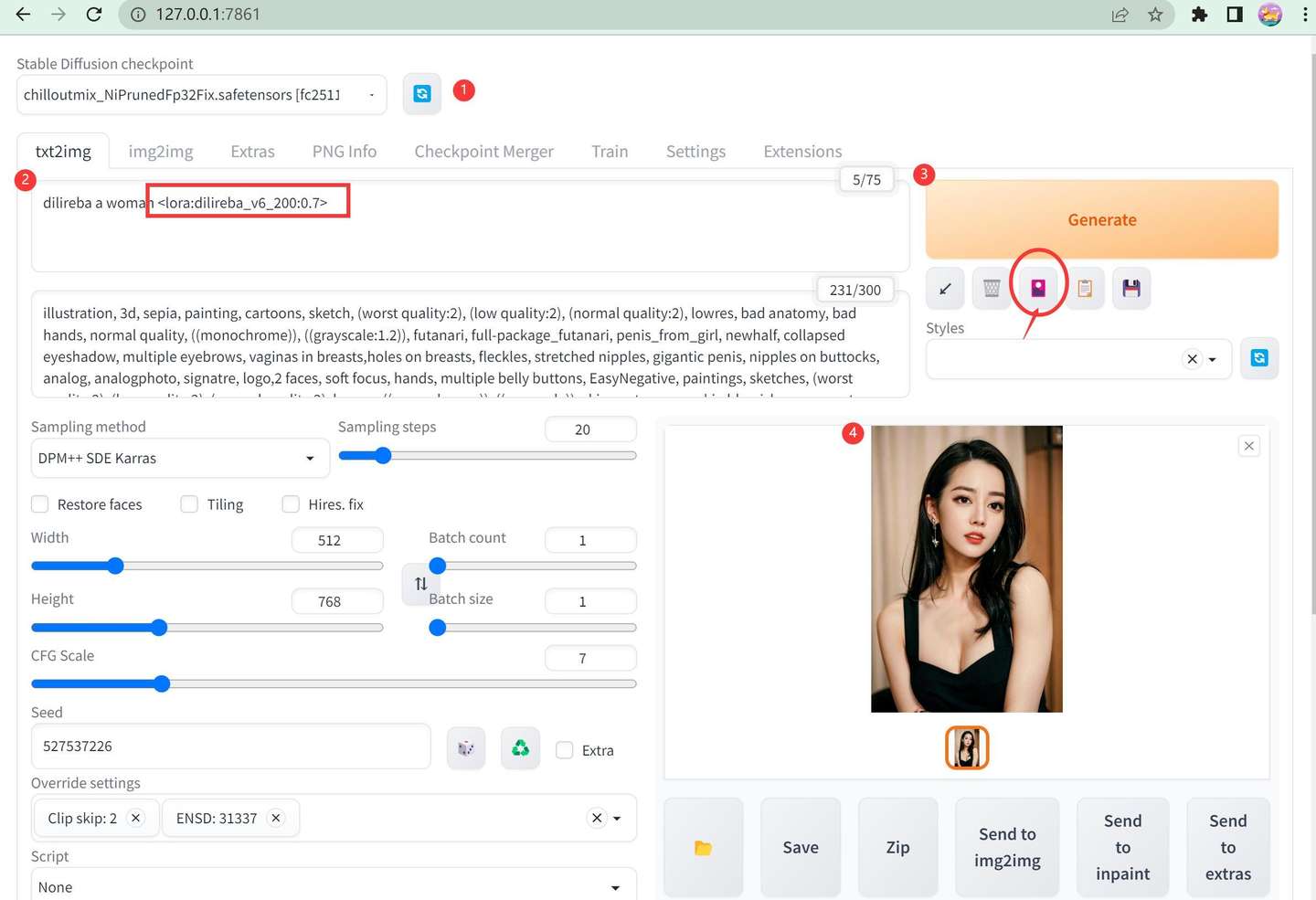
添加图片注释,不超过 140 字(可选)
刚开始不要加任何复杂的关键词,只用最基础的,比如 "a woman dilireba" 然后加上我们自己训练lora。关于Lora字符串,你可以直接输入,也可以通过图中圆圈处找到对应的Lora点击一下导入。导入的时候最右侧的参数默认为1,需要修改一下,改成0.7或者0.8。
如果Lora练的还可以,这个时候出来的图片应该是相识度比较高的。然后就可以在这个基础词语上做一些变化了,比如加一个“wearing a suit” (穿着西装)就可以得到下面的图片了。
添加图片注释,不超过 140 字(可选)
刚开始不要加任何复杂的关键词,只用最基础的,比如 "a woman dilireba" 然后加上我们自己训练lora。关于Lora字符串,你可以直接输入,也可以通过图中圆圈处找到对应的Lora点击一下导入。导入的时候最右侧的参数默认为1,需要修改一下,改成0.7或者0.8。
如果Lora练的还可以,这个时候出来的图片应该是相识度比较高的。然后就可以在这个基础词语上做一些变化了,比如加一个“wearing a suit” (穿着西装)就可以得到下面的图片了。

添加图片注释,不超过 140 字(可选)
如果出图俯角符合预期,这个Lora训练也就算是成功了。如果不满意,就要回过头去调整素材和参数了。目前的AI绘画,并不是每次出图都完美的,需要多少刷几次,多试几个关键词才能找到比较满意的效果。
到这里Lora部分的内容就全部写完了,拖拖拉拉拖了好久了,终于了了一个事儿。基于Lora这种特性,可以自己玩,也可以做成在线产品。比如之前说过的“达芬奇”网站就是把这个过程给集成和简化了。
虽然我已经尽量把过程都写出来了,但是不同的基础的人接受程度肯定不一样。厉害的人觉得太简单,对这个不太熟悉的可能觉得有点复杂。
确实,从零开始话,这里面还是有挺多东西的。
整个流程也还有无数的细节可以优化:
比如 具体的安装过程,异常排除。
比如 图片筛选,裁剪,修复。
比如 关键词生成的多种方式和优化方法。
比如 模型训练参数的调整。
考虑到这些细致的问题专业性比较强,研究需要时间,写起来非常麻烦,写了也不会有多少阅读量,我就不在公开渠道发布了。我会慢慢更新在我的知识星球Tonyhub里面。今天用的素材,参数配置文件,最终Lora模型也会整理好发在里面。
添加图片注释,不超过 140 字(可选)
如果出图俯角符合预期,这个Lora训练也就算是成功了。如果不满意,就要回过头去调整素材和参数了。目前的AI绘画,并不是每次出图都完美的,需要多少刷几次,多试几个关键词才能找到比较满意的效果。
到这里Lora部分的内容就全部写完了,拖拖拉拉拖了好久了,终于了了一个事儿。基于Lora这种特性,可以自己玩,也可以做成在线产品。比如之前说过的“达芬奇”网站就是把这个过程给集成和简化了。
虽然我已经尽量把过程都写出来了,但是不同的基础的人接受程度肯定不一样。厉害的人觉得太简单,对这个不太熟悉的可能觉得有点复杂。
确实,从零开始话,这里面还是有挺多东西的。
整个流程也还有无数的细节可以优化:
比如 具体的安装过程,异常排除。
比如 图片筛选,裁剪,修复。
比如 关键词生成的多种方式和优化方法。
比如 模型训练参数的调整。
考虑到这些细致的问题专业性比较强,研究需要时间,写起来非常麻烦,写了也不会有多少阅读量,我就不在公开渠道发布了。我会慢慢更新在我的知识星球Tonyhub里面。今天用的素材,参数配置文件,最终Lora模型也会整理好发在里面。

添加图片注释,不超过 140 字(可选)
热爱研究的朋友,也完全可以自己去查资料研究,加入交流群交流。我把相关的连接全部放在下面了。
花了3天时间,写了4000多个字,我发现一个密码:点赞不花钱哦!
相关连接
LoRA训练的开源项目:
https://github.com/bmaltais/kohya_ss
图片截取:
https://www.birme.net/
replicate关于Lora的介绍:
https://replicate.com/blog/lora-faster-fine-tuning-of-stable-diffusion
LoRA开源项目地址:
https://github.com/cloneofsimo/lora
LoRA论文地址:
https://arxiv.org/abs/2106.09685
标签:训练,140,AI,流程,注释,添加,Lora,模型,图片
From: https://www.cnblogs.com/wangpg/p/17388960.html
添加图片注释,不超过 140 字(可选)
热爱研究的朋友,也完全可以自己去查资料研究,加入交流群交流。我把相关的连接全部放在下面了。
花了3天时间,写了4000多个字,我发现一个密码:点赞不花钱哦!
相关连接
LoRA训练的开源项目:
https://github.com/bmaltais/kohya_ss
图片截取:
https://www.birme.net/
replicate关于Lora的介绍:
https://replicate.com/blog/lora-faster-fine-tuning-of-stable-diffusion
LoRA开源项目地址:
https://github.com/cloneofsimo/lora
LoRA论文地址:
https://arxiv.org/abs/2106.09685
标签:训练,140,AI,流程,注释,添加,Lora,模型,图片
From: https://www.cnblogs.com/wangpg/p/17388960.html