面试
http的三次握手四次挥手
-
HTTP的三次握手

三次握手(Three-way Handshake)其实就是指建立一个TCP连接时,需要客户端和服务器总共发送3个包。进行三次握手的主要作用就是为了确认双方的接收能力和发送能力是否正常、指定自己的初始化序列号为后面的可靠性传送做准备。实质上其实就是连接服务器指定端口,建立TCP连接,并同步连接双方的序列号和确认号,交换TCP窗口大小信息。
刚开始客户端处于 Closed 的状态,服务端处于 Listen 状态。
第一次握手:客户端给服务端发一个 SYN (同步序列编号 )报文,并指明客户端的(初始化序列号 )ISN,此时客户端处于 SYN_SEND (请求连接 )状态。
首部的同步位SYN=1,初始序号seq=x,SYN=1的报文段不能携带数据,但要消耗掉一个序号。
第二次握手:服务器收到客户端的 SYN 报文之后,会以自己的 SYN 报文作为应答,并且也是指定了自己的初始化序列号 ISN。同时会把客户端的 ISN + 1 作为ACK (确认字符 )的值,表示自己已经收到了客户端的 SYN,此时服务器处于 SYN_RCVD(收到) 的状态。
在确认报文段中SYN=1,ACK=1,确认号ack=x+1,初始序号seq=y
第三次握手:客户端收到 SYN 报文之后,会发送一个 ACK 报文,当然,也是一样把服务器的 ISN + 1 作为 ACK 的值,表示已经收到了服务端的 SYN 报文,此时客户端处于 ESTABLISHED 状态。服务器收到 ACK 报文之后,也处于 ESTABLISHED 状态,此时,双方已建立起了连接。
确认报文段ACK=1,确认号ack=y+1,序号seq=x+1(初始为seq=x,第二个报文段所以要+1),ACK报文段可以携带数据,不携带数据则不消耗序号。
那为什么要三次握手呢?两次不行吗?
为了确认双方的接收能力和发送能力都正常
如果是用两次握手,则会出现下面这种情况:
如客户端发出连接请求,但因连接请求报文丢失而未收到确认,于是客户端再重传一次连接请求。后来收到了确认,建立了连接。数据传输完毕后,就释放了连接,客户端共发出了两个连接请求报文段,其中第一个丢失,第二个到达了服务端,但是第一个丢失的报文段只是在某些网络结点长时间滞留了,延误到连接释放以后的某个时间才到达服务端,此时服务端误认为客户端又发出一次新的连接请求,于是就向客户端发出确认报文段,同意建立连接,不采用三次握手,只要服务端发出确认,就建立新的连接了,此时客户端忽略服务端发来的确认,也不发送数据,则服务端一致等待客户端发送数据,浪费资源。
-
HTTP的四次挥手

刚开始双方都处于 ESTABLISHED(连接成功) 状态,假如是客户端先发起关闭请求。四次挥手的过程如下:
第一次挥手: 客户端会发送一个 FIN 报文,报文中会指定一个序列号。此时客户端处于 FIN_WAIT1 状态。
即发出连接释放报文段(FIN=1,序号seq=u),并停止再发送数据,主动关闭TCP连接,进入FIN_WAIT1(终止等待1)状态,等待服务端的确认。
第二次挥手:服务端收到 FIN 之后,会发送 ACK 报文,且把客户端的序列号值 +1 作为 ACK 报文的序列号值,表明已经收到客户端的报文了,此时服务端处于 CLOSE_WAIT 状态。
即服务端收到连接释放报文段后即发出确认报文段(ACK=1,确认号ack=u+1,序号seq=v),服务端进入CLOSE_WAIT(关闭等待)状态,此时的TCP处于半关闭状态,客户端到服务端的连接释放。客户端收到服务端的确认后,进入FIN_WAIT2(终止等待2)状态,等待服务端发出的连接释放报文段。
第三次挥手:如果服务端也想断开连接了,和客户端的第一次挥手一样,发给 FIN 报文,且指定一个序列号。此时服务端处于 LAST_ACK 的状态。
即服务端没有要向客户端发出的数据,服务端发出连接释放报文段(FIN=1,ACK=1,序号seq=w,确认号ack=u+1),服务端进入LAST_ACK(最后确认)状态,等待客户端的确认。
第四次挥手:客户端收到 FIN 之后,一样发送一个 ACK 报文作为应答,且把服务端的序列号值 +1 作为自己 ACK 报文的序列号值,此时客户端处于 TIME_WAIT 状态。需要过一阵子以确保服务端收到自己的 ACK 报文之后才会进入 CLOSED 状态,服务端收到 ACK 报文之后,就处于关闭连接了,处于 CLOSED 状态。
即客户端收到服务端的连接释放报文段后,对此发出确认报文段(ACK=1,seq=u+1,ack=w+1),客户端进入TIME_WAIT(时间等待)状态。此时TCP未释放掉,需要经过时间等待计时器设置的时间2MSL后,客户端才进入CLOSED状态。
那为什么需要四次挥手呢?
因为当服务端收到客户端的SYN连接请求报文后,可以直接发送SYN+ACK报文。其中ACK报文是用来应答的,SYN报文是用来同步的。但是关闭连接时,当服务端收到FIN报文时,很可能并不会立即关闭SOCKET,所以只能先回复一个ACK报文,告诉客户端,“你发的FIN报文我收到了”。只有等到我服务端所有的报文都发送完了,我才能发送FIN报文,因此不能一起发送,故需要四次挥手。
- HTTPS的三次握手
HTTPS的请求过程如下:
客户端发起HTTPS请求
服务端的配置: 采用HTTPS协议的服务器必须要有一套数字证书,可以是自己制作或者CA证书。区别就是自己颁发的证书需要客户端验证通过,才可以继续访问,而使用CA证书则不会弹出提示页面。这套证书其实就是一对公钥和私钥。公钥给别人加密使用,私钥给自己解密使用。
服务端向客户端传送证书,这个证书其实就是公钥
客户端解析证书: 这部分工作是有客户端的TLS来完成的,首先会验证公钥是否有效,比如颁发机构,过期时间等,如果发现异常,则会弹出一个警告框,提示证书存在问题。如果证书没有问题,那么就生成一个随即值,然后用证书对该随机值进行加密。
客户端向服务端传送加密信息: 这部分传送的是用证书加密后的随机值,目的就是让服务端得到这个随机值,以后客户端和服务端的通信就可以通过这个随机值来进行加密解密了。
服务端解密信息: 服务端用私钥解密后,得到了客户端传过来的随机值(私钥),然后把内容通过该值进行对称加密。
传输加密后的信息: 这部分信息是服务段用私钥加密后的信息,可以在客户端被被解密。
客户端解密信息: 客户端用之前生成的私钥解密服务端传过来的信息,于是获取了解密后的内容。

数据库的四种隔离级别
引言
数据库事务的隔离级别有4种,由低到高分别为Read uncommitted(读未提交) 、Read committed (读已提交)、Repeatable read (重复读)、Serializable (序列化)。读现象是在多个事务并发执行时,在读取数据方面可能碰到的问题。包括脏读、不可重复读、幻读。
脏读:读到了脏数据,即无效数据。
不可重复读:是指在数据库访问中,一个事务内的多次相同查询却返回了不同数据。
幻读:指同一个事务内多次查询返回的结果集不一样,比如增加了行记录。
备注:不可重复读对应的是修改,即update操作。幻读对应的是插入操作。幻读是不可重复读的一种特殊场景。
要想解决脏读、不可重复读、幻读等读现象,那么就需要提高事务的隔离级别。但是随之带来的,隔离级别越高,并发能力越低。所以,需要根据业务去进行衡量,具体场景应该使用哪种隔离级别。
下面通过事例一一阐述它们的概念与联系。
2.事务隔离级别
2.1 Read uncommitted(读未提交)
提供了事务建最小限度的隔离。顾名思义,就是一个事务可以读取另一个未提交事务的数据。
示例:小明去商店买衣服,付款的时候,小明正常付款,钱已经打到商店老板账户,但是小明发起的事务还没有提交。就在这时,商店老板查看自己账户,发现钱已到账,于是小明正常离开。小明在走出商店后,马上回滚差点提交的事务,撤销了本次交易曹邹。
结果:小明未付钱买到了衣服,商店老板实际未收到小明的付款。
分析:商店老板查看自己的资金账户,这个时候看到的是小明还没有提交事务的付款。这就是脏读。
注意:处于该隔离级别的事务A与B,如果事务A使用事务B不提交的变化作为计算的基础,然后哪些未提交的变化被事务A撤销,这就导致了大量的数据错误变化。
2.2 Read committed (读已提交)
处于Read committed (读已提交)级别的事务可以看到其他事务对数据的修改。也就是说,在事务处理期间,如果其他事务修改了相应的表,那么同一个事务的同一sql在其他事务执行前后返回的是不同的结果。一个事务要等另一个事务提交后才能读取数据。
示例:小明卡里有1000元,准备与几个朋友聚餐消费,消费1000元,当他买单时(事务开启),收费系统检测到他卡里有1000元。就在检测完毕的时候,小明女朋友发现小明有私房钱,全部转走并提交。当收费系统准备扣款时,再检查小明卡里的金额,发现已经没钱了,付款不成功。小明此时就会很纳闷,明明有钱的呀,钱呢?
分析:该示例中同一个事务范围内两个相同的查询却返回了不同数据,这就是不可重复读。该隔离级别可以解决脏读问题。
2.3 Repeatable read (重复读)
在开始读取数据(事务开启)时,不再允许修改操作
示例:还是小明有1000元,准备跟朋友聚餐消费这个场景,当他买单(事务开启)时,收费系统检测到他卡里有1000元,这个时候,他的女朋友不能转出金额。接下来,收费系统就可以扣款成功了,小明醉醺醺的回家,准备跪脱衣板。
分析:重复读可以解决不可重复读的问题,这句话有些别扭,大家可以仔细品一下。
写到这里,大家可能会产生疑问,什么情况下产生幻读呢?
示例来了:
小明在公司上班,女朋友告诉他,拿着他的卡去逛街消费。花了一千元,然后小明去查看他银行卡的消费记录(事务开启),看到确实是花了一千元。就在这个时候,小明女朋友又花三千元买了一些化妆品和衣服,即新增了一些消费记录。当小明打印自己银行卡消费记录单的时候(女朋友事务提交),发现花了四千元,似乎出现了幻觉,小明很心疼。这就是幻读
扩展:当我们开启一个事务以后,有如下的程序操作
第一步:更新A表id=1的记录
第二步:查询A表id=1的记录
第三步:使用第二步的查询结果作为依据继续业务逻辑
第四步:提交事务
问题来了:同一个事务中,事务未提交前,第二步的查询结果是第一步执行前的结果还是第一步执行后的结果呢?
答案:事务隔离级别是针对不通事务的,同一事务中的未提交的更新,在后续是可以查询到的。
2.4 Serializable (序列化)
数据库事务的最高隔离级别。在此级别下,事务串行执行。可以避免脏读、不可重复读、幻读等读现象。但是效率低下,耗费数据库性能,不推荐使用。
3.mysql事务隔离级别查询
3.1mysql查看数据库实例默认的全局隔离级别sql
Mysql8以前:SELECT @@GLOBAL.tx_isolation, @@tx_isolation;
Mysql8开始:SELECT @@GLOBAL.transaction_isolation, @@transaction_isolation;
3.2修改隔离级别命令:
SET SESSION TRANSACTION ISOLATION LEVEL READ UNCOMMITTED
建议开发者在修改时,仅修改当前session隔离级别即可。
3.3mysql默认隔离级别
REPEATABLE-READ,可以避免脏读,不可重复读,不可避免幻读
Redis的雪崩、穿透、击穿的原因和解决方案
一、概述
① 缓存穿透:大量请求根本不存在的key(下文详解)
② 缓存雪崩:redis中大量key集体过期(下文详解)
③ 缓存击穿:redis中一个热点key过期(大量用户访问该热点key,但是热点key过期)
穿透解决方案:
对空值进行缓存
设置白名单
使用布隆过滤器
网警
雪崩解决方案:
进行预先的热门词汇的设置,进行key时长的调整
实时调整,监控哪些数据是热门数据,实时的调整key的过期时长
使用锁机制
击穿解决方案:
进行预先的热门词汇的设置,进行key时长的调整
实时调整,监控哪些数据是热门数据,实时的调整key的过期时长
使用锁机制(只有一个线程可以进行热点数据的重构)
下文进行详解
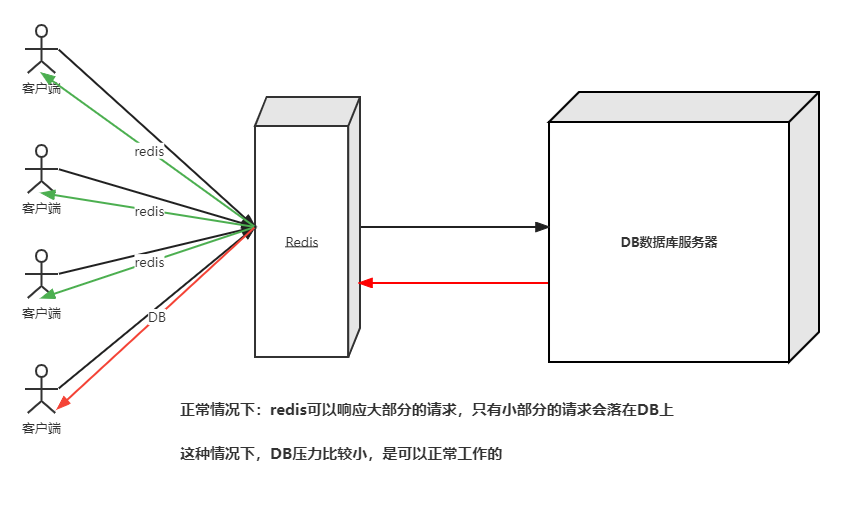
三者出现的根本原因:Redis命中率下降,请求直接打在DB上
正常情况下,大量的资源请求都会被redis响应,在redis得不到响应的小部分请求才会去请求DB,这样DB的压力是非常小的,是可以正常工作的(如下图)
如果大量的请求在redis上得不到响应,那么就会导致这些请求会直接去访问DB,导致DB的压力瞬间变大而卡死或者宕机。如下图:
① 大量的高并发的请求打在redis上
② 这些请求发现redis上并没有需要请求的资源,redis命中率降低
③ 因此这些大量的高并发请求转向DB(数据库服务器)请求对应的资源
④ DB压力瞬间增大,直接将DB打垮,进而引发一系列“灾害”
那么为什么redis会没有需要访问的数据呢?通过分析大致可以总结为三种情况,也就对应着redis的雪崩、穿透和击穿(下文开始进行详解)
| 问题名称 | 缓存穿透 | 缓存击穿 | 缓存雪崩 |
|---|---|---|---|
| 资源是否存在DB数据库服务器中 | x | √ | √ |
| 资源是否存在Redis中 | x | x | x |
| redis没有对应资源的原因 | 根本不存在该资源(DB也没有) | 某个热点key过期 | 大部分key集体过期 |
| 根本原因 |
大量的高并发的请求打在Redis上,但是发现Redis中并没有请求的数据,redis的命令率降低,所以这些请求就只能直接打在DB(数据库服务器)上,在大量的高并发的请求下就会导致DB直接卡死、宕机
二、情景分析 (详解)
缓存穿透
缓存穿透产生的原因:请求根本不存在的资源(DB本身就不存在,Redis更是不存在)
举例(情景在线):客户端发送大量的不可响应的请求(如下图)

当大量的客户端发出类似于:http://localhost:8080/user/19833?id=-3872 的请求,就可能导致出现缓存穿透的情况。因为数据库DB中本身就没有id=-3872的用户的数据,所以Redis也没有对应的数据,那么这些请求在redis就得不到响应,就会直接打在DB上,导致DB压力过大而卡死情景在线或宕机。
缓存穿透很有可能是黑客攻击所为,黑客通过发送大量的高并发的无法响应的请求给服务器,由于请求的资源根本就不存在,DB就很容易被打垮了。
解决方式:
- 对空值进行缓存:
类似于上面的例子,虽然数据库中没有id=-3872的用户的数据,但是在redis中对他进行缓存(key=-3872,value=null),这样当请求到达redis的时候就会直接返回一个null的值给客户端,避免了大量无法访问的数据直接打在DB上
- 实时监控:
对redis进行实时监控,当发现redis中的命中率下降的时候进行原因的排查,配合运维人员对访问对象和访问数据进行分析查询,从而进行黑名单的设置限制服务(拒绝黑客攻击)
- 使用布隆过滤器
使用BitMap作为布隆过滤器,将目前所有可以访问到的资源通过简单的映射关系放入到布隆过滤器中(哈希计算),当一个请求来临的时候先进行布隆过滤器的判断,如果有那么才进行放行,否则就直接拦截
- 接口校验
类似于用户权限的拦截,对于id=-3872这些无效访问就直接拦截,不允许这些请求到达Redis、DB上。
注意事项:
- 使用空值作为缓存的时候,key设置的过期时间不能太长,防止占用太多redis资源
- 对空值缓存是一种被动的防御方式,当遇到黑客暴力请求很多不存在的数据就需要写入大量的null值到Redis中,可能导致Redis内存占用不足的情况
- 使用布隆过滤器,可以在用户访问的时候判断该资源是否存在,不存在则直接拒绝访问
- 布隆过滤器是有一定的误差,所以一般需要配合一些接口流量的限制(规定用户在一段时间内访问的频率)、权限校验、黑名单等来解决缓存穿透的问题
缓存雪崩
缓存雪崩产生的原因:redis中大量的key集体过期
举例:
当redis中的大量key集体过期,可以理解为redis中的大部分数据都被清空了(失效了),那么这时候如果有大量并发的请求来到,那么redis就无法进行有效的响应(命中率急剧下降),请求就都打到DB上了,到时DB直接崩溃
解决方式:
- 将失效时间分散开
通过使用自动生成随机数使得key的过期时间是随机的,防止集体过期
- 使用多级架构
使用nginx缓存+redis缓存+其他缓存,不同层使用不同的缓存,可靠性更强
- 设置缓存标记
记录缓存数据是否过期,如果过期会触发通知另外的线程在后台去跟新实际的key
- 使用锁或者队列的方式
如果查不到就加上排它锁,其他请求只能进行等待
缓存击穿
产生缓存雪崩的原因:redis中的某个热点key过期,但是此时有大量的用户访问该过期key
举例:
类似于“某男明星塌房事件”上了热搜,这时候大量的“粉丝”都在访问该热点事件,但是可能优于某种原因,redis的这个热点key过期了,那么这时候大量高并发对于该key的请求就得不到redis的响应,那么就会将请求直接打在DB服务器上,导致整个DB瘫痪。
解决方案:
- 提前对热点数据进行设置
类似于新闻、某博等软件都需要对热点数据进行预先设置在redis中
- 监控数据,适时调整
监控哪些数据是热门数据,实时的调整key的过期时长
- 使用锁机制
只有一个请求可以获取到互斥锁,然后到DB中将数据查询并返回到Redis,之后所有请求就可以从Redis中得到响应
常见的web框架
Gin
echo
http的几种常见状态码
完整的HTTP 1.1规范说明书来自于RFC 2616,HTTP 1.1的状态码被标记为新特性,因为许多浏览器只支持HTTP 1.0。你应只把状态码发送给支持HTTP 1.1的客户端,支持协议版本可以通过调用request.getRequestProtocol来检查。本部分余下的内容会详细地介绍HTTP 1.1中的状态码。这些状态码被分为五大类:
- 100-199 用于指定客户端应相应的某些动作。
- 200-299 用于表示请求成功。
- 300-399 用于已经移动的文件并且常被包含在定位头信息中指定新的地址信息
- 400-499 用于指出客户端的错误。
- 500-599 用于支持服务器错误。
- 200 OK——客户端发来的请求在服务器端被正常处理
在响应报文中,随状态码返回的信息会因方法的不同而改变。比如,使用GET时对应请求资源的实体会作为响应返回;使用HEAD时,在响应中只返回首部,不返回实体的主体部分。
- 204 No Content——服务器接收的请求已成功处理,但返回的响应报文中不含实体的主体部分,即无资源可返回
一般在只需从客户端往服务器发送信息,而对客户端不需要发送新信息内容的情况下使用。
-
206 Partial Content——服务器成功执行了客户端发来的范围GET请求。
-
301 Moved Permanently——永久重定向(请求的资源已被分配新的URL,以后应使用资源现在所指的URL)。
-
302 Found——临时重定向(请求的资源已被分配新的URL,希望用户本次使用新的URL)。
-
303 See Other——由于请求对应的资源存在着另一个URL,应使用GET方法定向获取请求的资源,与302功能相同,但不同点在于303要求使用GET方法获取资源。
-
304 Not Modified——客户端发送附带条件的请求时,,服务器端允许请求访问资源,但请求未满足条件。
304其实与重定向没有关系。
- 307 Temporary Redirect——临时重定向,但请求方式不会从POST变为GET
与302含义相同,但是302规定的禁止POST变为GET并不被遵守,而307严格遵守不会从POST变为GET。
-
400 Bad Request——请求报文中存在语法错误。
-
401 Unauthorized——发送的请求需有通过HTTP认证的认证信息
当浏览器初次接收401,会弹出认证用的对话窗口;若之前已进行过1次请求,则表示用户认证失败。返回含有401的响应必须包含一个适用于被请求资源的WWW-Authenticate首部用以质询用户信息。
-
403 Forbidden——对请求资源的访问被服务器拒绝了
-
404 Not Found——服务器上无法找到请求的资源
-
500 Internal Server Error——服务器在执行请求时发生错误
-
503 Service Unavailable——服务器暂处于超负载或正在进行停机维护,现在无法处理请求
各语言的区别、mq消息队列的区别
- Kafka 起初是由 LinkedIn 公司采用 Scala 语言开发的一个分布式、多分区、多副本且基于 zookeeper 协调的分布式消息系统,现已捐献给 Apache 基金会。它是一种高吞吐量的分布式发布订阅消息系统,以可水平扩展和高吞吐率而被广泛使用。目前越来越多的开源分布式处理系统如 Cloudera、Apache Storm、Spark、Flink 等都支持与 Kafka 集成,号称一半以上世界500强都是它的客户
- RocketMQ 是阿里开源的消息中间件,目前已经捐献个 Apache 基金会,它是由 Java 语言开发的,具备高吞吐量、高可用性、适合大规模分布式系统应用等特点,积极在Cloud-Native领域发力。
- RabbitMQ 是采用 Erlang 语言实现的 AMQP 协议的消息中间件,最初起源于金融系统,用于在分布式系统中存储转发消息。
- ActiveMQ 是 Apache 出品的、采用 Java 语言编写的完全基于 JMS1.1 规范的面向消息的中间件,为应用程序提供高效的、可扩展的、稳定的和安全的企业级消息通信。不过由于历史原因包袱太重,目前市场份额较小,其最新架构被命名为 Apollo,号称下一代 ActiveMQ
- ZeroMQ 号称史上最快的消息队列,基于 C 语言开发。ZeroMQ 是一个消息处理队列库,可在多线程、多内核和主机之间弹性伸缩,虽然大多数时候我们习惯将其归入消息队列家族之中,但是其和前面的几款有着本质的区别,ZeroMQ 本身就不是一个消息队列服务器,更像是一组底层网络通讯库
grpc和protoc
Protobuf和gRPC是使网络服务与分布式系统编程更容易的两个库。Protobuf 是Protocol Buffers的简称, 它是 Google 开发的一种跨语言、跨平台、可扩展的用于序列化数据协议。gRPC是为了RPC的code generator,生成方便RPC的接口,屏蔽RPC 的底层细节。
Protobufs
Protobuf是一种类似于json的消息格式,与json的human-readable的text格式不同,protobufs可以被编码成节省空间的二进制表示。protobufs message可以包含primitive value, string, enum type和其它protobufs message。 它们被发送者编码,通过网络传送,最后被接收者解码。
Protobufs的方便之处在于,你只用给出数据的high level description,然后protobufs 编译器就能根据你选择的语言,为你生成大量的编码解码逻辑。例如,你可以使用go/java/python等语言实现的client与c++实现的server交流,只要他们都使用protobufs的generated functions来encode/decode protobufs message。
Protobufs定义在.proto文件,它的语法遵循Protocol Buffer definition language。下面是一个简单的例子。
message Person {
string name = 1;
string email = 2;
enum PhoneType {
MOBILE = 0;
HOME = 1;
WORK = 2;
}
message PhoneNumber {
string number = 1;
PhoneType type = 2 [default = HOME];
}
repeated PhoneNumber phone = 3;
}
这里,Person message包含三个域,name, email, phone数组。注意,每个域包含三个部分,类型,名字,还有Unique ID。绝大多数primitive type例如int32, bool, double, string是被支持的,数组也被通过关键字repeated支持。嵌套的message也是支持的。
Protobufs message语法很简单,这是它的全部description。
Language Guide(proto3)developers.google.com/protocol-buffers/docs/proto3
一旦你定义好了protobufs message。就可以运行protobufs 编译器根据你的语言生成相应的class,class包含简单的setter, getter,还有encode/decode message的函数。
例如,如果你选择c++语言。在.proto文件上运行编译器,会生成一个Person类,你可以填充,序列化,反序列化这Person class。
Person p;
p.set_name("John Doe");
p.set_email("jdoe@example.com");
std::string person_str = p.SerializeAsString();
解码过程如下。
std::string person_str = "xxxxxx";
Person person;
person.ParseFromString(&person_str);
printf("Name: %s\n", person.name().c_str());
printf("Email: %s\n", person.email().c_str());
另一个注意的是protobufs是前向-后向兼容的。比如如果server更新了message的格式,client仍然使用旧的message格式。client仍然能够处理server的message, 只不过对于server在新message新增添的field,client会忽略这个field。
gRPC
在gRPC,在不同机器的client可以调用server上的函数,好像调用本地函数一样,这让分布式系统编程变得简单。gRPC是基于service这个概念来实现这些功能。这需要你指定可以让client远程调用的方法,以及这些方法的参数类型和返回类型。
在server端,server实现这些接口并且运行gRPC server处理client的请求。在client端,generated client code暴露这些server方法。
下面是个例子,我们为Person message增添了一个AddressBook service。
service AddressBook {
rpc AddContact(Person) returns (Empty) {}
rpc Search(Name) returns (People) {}
}
message Person {
string name = 1;
string email = 2;
...
}
message People { // an array of 0 or more Persons
repeated Person people = 1;
}
message Name {
string name = 1;
}
message Empty {} // empty message to represent a void response
The gRPC Code You Should (And Shouldn’t) Write
编译我们的proto文件会生成client, server code。这些code依赖于选择的语言,如果选择c++,生成的client stub会是下面这样。
class Stub final : public StubInterface {
public:
...
::grpc::Status AddContact(::grpc::ClientContext* context, const ::protos::Person& request, ::protos::Empty* response) override;
::grpc::Status Search(::grpc::ClientContext* context, const ::protos::Name& request, ::protos::People* response) override;
...
}
这个client stub是具有完全功能的。它实现了StubInterface接口,并且它的方法匹配了定义的service。stub里的方法除了你声明的参数外,还需要ClientContext去包含额外的请求元数据,并且返回status code,就像HTTP response code一样。成功的请求会返回OK,其它status code包括INVALID_ARGUMENT, DEADLINE_EXCEEDED, PERMISSION_DENIED等。
我们的server code,是不完全的。
class Service : public ::grpc::Service {
public:
Service();
virtual ~Service();
virtual ::grpc::Status AddContact(::grpc::ServerContext* context, const ::protos::Person* request, ::protos::Empty* response);
virtual ::grpc::Status Search(::grpc::ServerContext* context, const ::protos::Name* request, ::protos::People* response);
};
你需要定义一个子类去实现Service里的虚方法。一旦你实现了这些虚方法,client和server就可以使用gRPC交流了。
// create a client and connect to the server
std::string srv_addr = "xxxx";
grpc::Channel c = grpc::CreateChannel(srv_addr,grpc::InsecureChannelCredentials());
std::unique_ptr<AddressBook::Stub> client(AddressBook::NewStub(c));
// create a Person, Empty, and ClientContext
grpc::ClientContext ctx;
Empty empty;
Person p;
p.set_name("Jim Bob");
p.set_email("jim@bob.com");
// send an AddContact RPC
client->AddContact(&ctx, p, &empty);
client->AddContact这个函数调用背后有许多步骤。
- client encode message并且通过网络发给server。
- AddressServer获取message并且decode。
- server寻找实现了service的子类实例,执行AddContact函数。
- server encode response并且通过网络返回给client。
- client 解析response并且从AddContact函数返回。
golang的特性问题
golang 语言特性
golang 语言特性主要包括以下几点:
自动垃圾回收
更丰富的内置类型
函数多返回值
错误处理
匿名函数和闭包
类型和接口
并发编程
反射
语言交互性
自动垃圾回收
C语言代码不支持垃圾自动回收,会导致指针存在如下两个问题:
void foo()
{
char* p = new char[128];
... // 对p指向的内存块进行赋值
func1(p); // 使用内存指针
delete[] p;
}
1、各种非预期的原因,比如由于开发者的疏忽导致最后的delete语句没有被调用,都会引发经典而恼人的内存泄露问题。假如该函数被调用得非常频繁,那么我们观察该进程执行时,会发现该进程所占用的内存会一直疯长,直至占用所有系统内存并导致程序崩溃,而如果泄露的是系统资源的话,那么后果还会更加严重,最终很有可能导致系统崩溃。
2、手动管理内存的另外一个问题就是由于指针的到处传递而无法确定何时可以释放该指针所指向的内存块。假如代码中某个位置释放了内存,而另一些地方还在使用指向这块内存的指针,那么这些指针就变成了所谓的“野指针”( wild pointer)或者“悬空指针”( dangling pointer),对这些指针进行的任何读写操作都会导致不可预料的后果。
由于其杰出的效率, C和C++语言在非常长的时间内都作为服务端系统的主要开发语言,比如Apache、 Nginx和MySQL等著名的服务器端软件就是用C和C++开发的。然而,内存和资源管理一直是一个让人非常抓狂的难题。服务器的崩溃十有八九就是因为不正确的内存和资源管理导致,更讨厌的是这种内存和资源管理问题即使被发现了,也很难定位到具体的错误地点,导致无数程序员通宵达旦地调试程序。这个问题在多年里被不同人用不同的方式来试图解决,并诞生了一些非常著名的内存检查工具,比如Rational Purify、 Compuware BoundsChecker和英特尔的Parallel Inspector等。
到目前为止,内存泄露的最佳解决方案是在语言级别引入自动垃圾回收算法( Garbage Collection,简称GC)。所谓垃圾回收,即所有的内存分配动作都会被在运行时记录,同时任何对该内存的使用也都会被记录,然后垃圾回收器会对所有已经分配的内存进行跟踪监测,一旦发现有些内存已经不再被任何人使用,就阶段性地回收这些没人用的内存。当然,因为需要尽量最小化垃圾回收的性能损耗,以及降低对正常程序执行过程的影响,现实中的垃圾回收算法要比这个复杂得多,比如为对象增加年龄属性等,但基本原理都是如此。
自动垃圾回收在C/C++社区一直作为一柄双刃剑看待,虽然到C++0x(后命名为C++11)正式发布时,这个呼声颇高的特性总算是被加入了,但按C++之父的说法,由于C++本身过于强大,导致在C++中支持垃圾收集变成了一个困难的工作。假如C++支持垃圾收集,以下的代码片段在运行时就会是一个严峻的考验:
int* p = new int;
p += 10; // 对指针进行了偏移,因此那块内存不再被引用
// …… 这里可能会发生针对这块int内存的垃圾收集 ……
p -= 10; // 咦,居然又偏移到原来的位置
*p = 10; // 如果有垃圾收集,这里就无法保证可以正常运行了
对于以上的这个C语言例子,如果使用Go语言实现,我们就完全不用考虑何时需要释放之前分配的内存的问题,系统会自动帮我们判断,并在合适的时候(比如CPU相对空闲的时候)进行自动垃圾收集工作。
更丰富的内置类型
golang增加:
数组类型
字符串类型
字典类型(map)
数组切片(slice)
函数多返回值
目前的主流语言中除Python外基本都不支持函数的多返回值功能,例如C语言中如果需要获取多个返回值,那么就需要增加传参参数以便获取其他返回值,或者使用数组的形式获取多个返回值。
Go语言革命性地在静态开发语言阵营中率先提供了多返回值功能。
例如:
func getName()(firstName, middleName, lastName, nickName string){
return "May", "M", "Chen", "Babe"
}
因为返回值都已经有名字,因此各个返回值也可以用如下方式来在不同的位置进行赋值,从
而提供了极大的灵活性:
func getName()(firstName, middleName, lastName, nickName string){
firstName = "May"
middleName = "M"
lastName = "Chen"
nickName = "Babe"
return
}
并不是每一个返回值都必须赋值,没有被明确赋值的返回值将保持默认的空值。而函数的调用相比C/C++语言要简化很多:
fn, mn, ln, nn := getName()
如果开发者只对该函数其中的某几个返回值感兴趣的话,也可以直接用下划线作为占位符来忽略其他不关心的返回值。下面的调用表示调用者只希望接收lastName的值,这样可以避免声明完全没用的变量:
_, _, lastName, _ := getName()
错误处理
Go语言引入了3个关键字用于标准的错误处理流程,这3个关键字分别为defer、 panic和recover
匿名函数和闭包
在Go语言中,所有的函数也是值类型,可以作为参数传递。 Go语言支持常规的匿名函数和闭包,比如下列代码就定义了一个名为f的匿名函数,开发者可以随意对该匿名函数变量进行传递和调用:
f := func(x, y int) int {
return x + y
}
:= 符号代表是先声明变量再使用
类型和接口
Go语言的类型定义非常接近于C语言中的结构( struct),甚至直接沿用了struct关键字。相比而言, Go语言并没有直接沿袭C++和Java的传统去设计一个超级复杂的类型系统,不支持继承和重载,而只是支持了最基本的类型组合功能
并发编程(重要)
Go语言引入了goroutine概念,它使得并发编程变得非常简单。通过使用goroutine而不是裸用操作系统的并发机制,以及使用消息传递来共享内存而不是使用共享内存来通信, Go语言让并发编程变得更加轻盈和安全
通过在函数调用前使用关键字go,我们即可让该函数以goroutine方式执行。 goroutine是一种比线程更加轻盈、更省资源的协程。 Go语言通过系统的线程来多路派遣这些函数的执行,使得每个用go关键字执行的函数可以运行成为一个单位协程。当一个协程阻塞的时候,调度器就会自动把其他协程安排到另外的线程中去执行,从而实现了程序无等待并行化运行。而且调度的开销非常小,一颗CPU调度的规模不下于每秒百万次,这使得我们能够创建大量的goroutine,从而可以很轻松地编写高并发程序,达到我们想要的目的。
Go语言实现了CSP(通信顺序进程, Communicating Sequential Process)模型来作为goroutine间的推荐通信方式。在CSP模型中,一个并发系统由若干并行运行的顺序进程组成,每个进程不能对其他进程的变量赋值。进程之间只能通过一对通信原语实现协作。 Go语言用channel(通道)这个概念来轻巧地实现了CSP模型。 channel的使用方式比较接近Unix系统中的管道( pipe)概念,可以方便地进行跨goroutine的通信。另外,由于一个进程内创建的所有goroutine运行在同一个内存地址空间中,因此如果不同的goroutine不得不去访问共享的内存变量,访问前应该先获取相应的读写锁。 Go语言标准库中的sync包提供了完备的读写锁功能
例程如下:
paracalc.go
package main
import "fmt"
func sum(values [] int, resultChan chan int) {
sum := 0
for _, value := range values {
sum += value
}
resultChan <- sum // 将计算结果发送到channel中
}
func main() {
values := [] int{1, 2, 3, 4, 5, 6, 7, 8, 9, 10}
resultChan := make(chan int, 2)
go sum(values[:len(values)/2], resultChan)
go sum(values[len(values)/2:], resultChan)
sum1, sum2 := <-resultChan, <-resultChan // 接收结果
fmt.Println("Result:", sum1, sum2, sum1 + sum2)
}
反射
反射( reflection)是在Java语言出现后迅速流行起来的一种概念。通过反射,你可以获取对象类型的详细信息,并可动态操作对象。反射是把双刃剑,功能强大但代码可读性并不理想。若非必要,我们并不推荐使用反射。
Go语言的反射实现了反射的大部分功能,但没有像Java语言那样内置类型工厂,故而无法做到像Java那样通过类型字符串创建对象实例。在Java中,你可以读取配置并根据类型名称创建对应的类型,这是一种常见的编程手法,但在Go语言中这并不被推荐
语言交互性
由于Go语言与C语言之间的天生联系, Go语言的设计者们自然不会忽略如何重用现有C模块的这个问题,这个功能直接被命名为Cgo。 Cgo既是语言特性,同时也是一个工具的名称。在Go代码中,可以按Cgo的特定语法混合编写C语言代码,然后Cgo工具可以将这些混合的C代码提取并生成对于C功能的调用包装代码。开发者基本上可以完全忽略这个Go语言和C语言的边界是如何跨越的。与Java中的JNI不同, Cgo的用法非常简单,例如:
cprint.go
package main
/*
include <stdio.h>
*/
import "C"
import "unsafe"
func main() {
cstr := C.CString("Hello, world")
C.puts(cstr)
C.free(unsafe.Pointer(cstr))
}