目录

一、概述
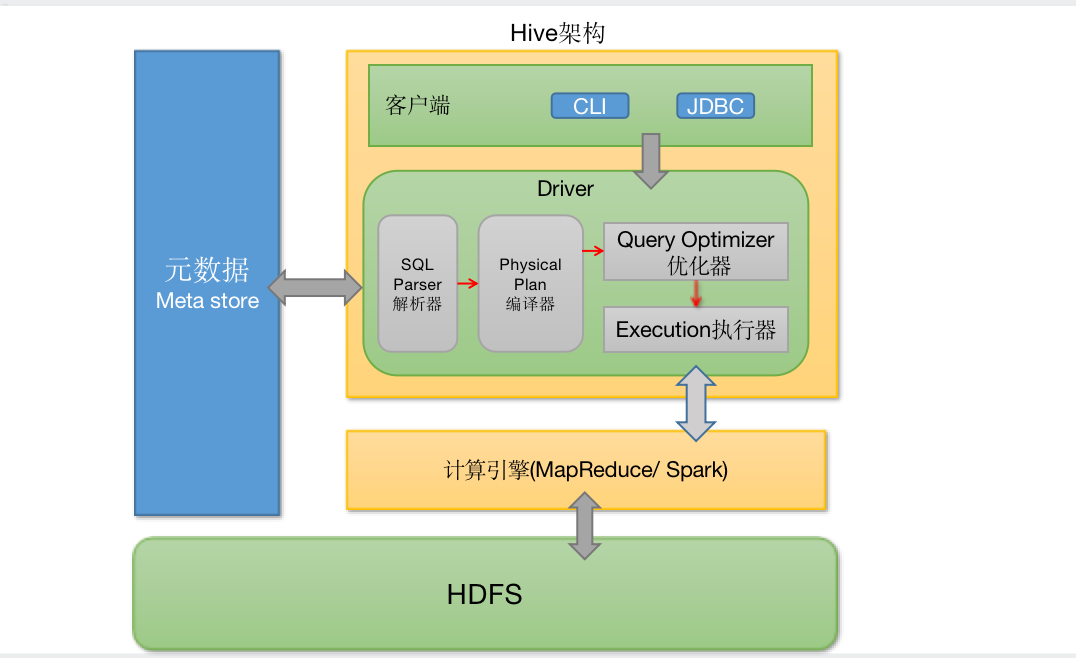
Hive是建立在Hadoop上的数据仓库工具,它允许用户通过类SQL的语法来查询和管理数据。在Hive中,DDL(数据定义语言)和视图操作是非常常见的。
1)表和视图关系
表和视图都是数据存储的逻辑表示方式。它们之间有以下关系:
-
视图可以基于一个或多个表创建,而表不可以基于其他表或视图创建。因此,视图是从一个或多个表的查询结果中获取数据的虚拟表,而表是实际存储数据的物理表。
-
视图通常用于简化查询或隐藏数据的复杂性,可以对基础表进行查询过滤、聚合或连接等操作,从而提供更易于理解的结果。而表则是实际存储和管理数据的物理存储单元。
-
视图在定义时不会实际创建物理表,而是保存了一系列查询语句。在查询视图时,Hive会执行这些查询语句并返回结果。而表则是在定义时就创建了物理存储单元,并在其中存储了数据。
-
视图可以简化数据访问,因为它可以隐藏底层表的复杂性和细节,让用户能够更容易地对数据进行操作和分析。而表可以提供更加灵活和高效的数据存储和访问方式,因为它们直接存储数据并允许对数据进行更广泛的操作和管理。
总之,表和视图都是数据存储和管理的方式,它们有各自的优点和适用场景。在Hive中,用户可以根据实际需要选择使用表还是视图来满足不同的数据访问和管理需求。
2)表与视图的区别
在Hive中,表和视图也是数据存储的逻辑表示方式,但它们之间存在以下区别:
-
存储方式:表是实际存储数据的物理表格,而视图不是存储数据的实体,而是基于查询结果生成的虚拟表格。
-
数据管理:表可以直接存储和管理数据,而视图只是从一个或多个表的查询结果中生成的,它并不实际存储数据。因此,对于大量数据的存储和管理,使用表更为合适;而对于简化查询或隐藏数据的复杂性,使用视图更为合适。
-
数据修改:对于表,用户可以随时对其中的数据进行修改、插入或删除等操作。而对于视图,用户只能对其进行查询,无法对其进行数据修改操作。
-
查询效率:由于视图仅仅是基于查询语句生成的虚拟表格,因此查询视图时的效率比查询表要低。尤其是当视图基于多个表时,查询效率会更低。
总之,在Hive中,表和视图都有各自的优点和适用场景。用户可以根据实际需求选择使用哪种方式来存储和管理数据,以及在查询数据时使用哪种方式来提高效率和简化操作。
二、环境准备
如果已经有了环境了,可以忽略,如果想快速部署环境可以参考我这篇文章:通过 docker-compose 快速部署 Hive 详细教程
# 登录容器
docker exec -it hive-hiveserver2 bash
# 连接hive
beeline -u jdbc:hive2://hive-hiveserver2:10000 -n hadoop
三、Hive 数据类型
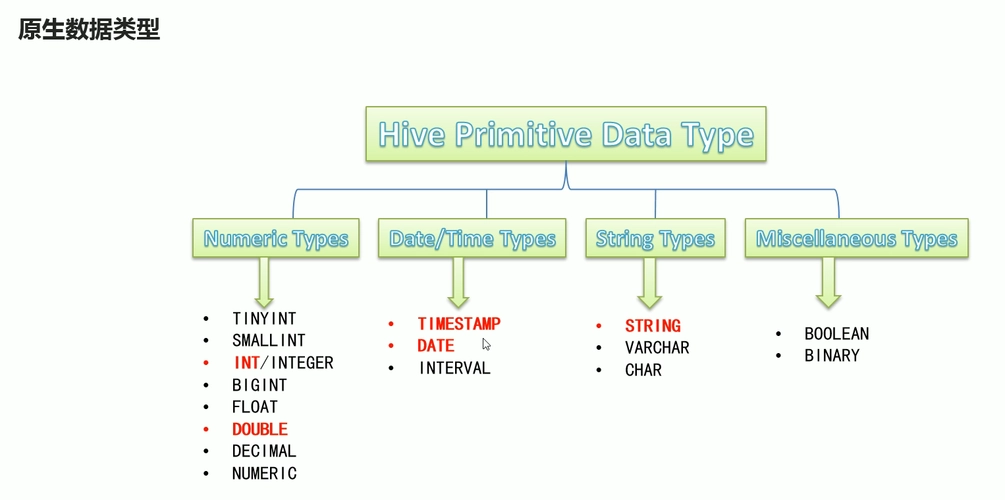
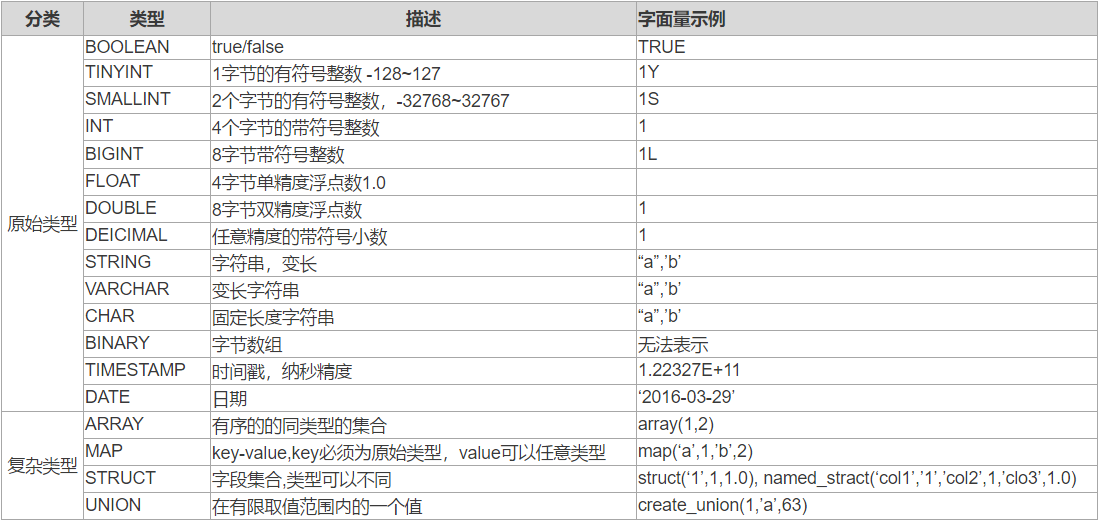
Hive支持原始数据类型和复杂类型,原始类型包括数值型,Boolean,字符串,时间戳。复杂类型包括数组,map,struct。
下面是Hive数据类型汇总:
四、DDL 操作
1)表的基本语法
在Hive中,你可以使用HiveQL语言来创建表。下面是一些创建表的基本语法:
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] table_name
[(col_name data_type [column_constraint_specification] [COMMENT col_comment], ...)]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
[CLUSTERED BY (col_name, col_name, ...) [SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[SKEWED BY (col_name, col_name, ...) ON ((col_value, col_value, ...), (col_value, col_value, ...), ...) [STORED AS DIRECTORIES]]
[ROW FORMAT row_format]
[STORED AS file_format]
[LOCATION hdfs_path]
其中,[] 表示可选项,...表示省略的内容。
以下是一些常见的参数解释:
-
TEMPORARY:表示创建一个临时表。临时表在会话结束时自动删除。 -
EXTERNAL:表示创建一个外部表。外部表的数据不是存储在Hive的数据仓库中,而是存储在Hadoop分布式文件系统中。 -
IF NOT EXISTS:表示如果表已经存在,则不执行创建表操作。 -
table_name:表示表的名称。 -
col_name:表示列的名称。 -
data_type:表示列的数据类型。 -
column_constraint_specification:表示列的约束条件,比如NOT NULL、UNIQUE等。 -
COMMENT:表示列或表的注释。 -
PARTITIONED BY:表示表的分区列。 -
CLUSTERED BY:表示表的分桶列。 -
SORTED BY:表示分桶列的排序方式。 -
num_buckets:表示分桶的数量。 -
SKEWED BY:表示表的倾斜列。 -
STORED AS:表示表的存储格式,比如TEXTFILE、SEQUENCEFILE等。
### hive文件存储格式包括以下几类(STORED AS TEXTFILE):
1.TEXTFILE:按行存储的文本文件格式。默认为TEXTFILE。
2.SEQUENCEFILE:二进制序列文件格式,其中键和值都是可以序列化的任意类型。
3.PARQUET:列式存储文件格式,支持读取和写入列式存储的数据。
4.ORC:高效列式存储文件格式,具有高压缩率和高性能的特点。
5.AVRO:自描述数据序列化格式。
6.JSONFILE:按行存储的JSON文件格式。
#其中TEXTFILE为默认格式,建表时不指定,默认为这个格式,导入数据时会直接把数据文件拷贝到hdfs上不进行处理。
TBLPROPERTIES:指定压缩方式,默认情况下,Hive不会对文件进行压缩。有以下几种压缩方式:
1.SNAPPY:快速压缩技术,具有较快的压缩速度和较高的压缩比。
2.GZIP:广泛使用的压缩算法,具有很高的压缩比,但是较慢。
3.BZIP2:典型的通用文件压缩算法,具有较高的压缩比和较慢的压缩速度。
4.LZO:快速Lempel-Ziv-Oberhumer压缩算法,具有高压缩比和快速的压缩速度。
其中,Hive默认支持的压缩方式只有GZIP、LZO和Snappy。如果要使用其他压缩方式,需要在配置文件中手动添加。
例如,我们可以使用以下命令将一张表存储为ORC文件格式,并使用Snappy压缩:
CREATE TABLE mytable (
column1 INT,
column2 STRING
)
STORED AS ORC
TBLPROPERTIES ("orc.compress"="SNAPPY");
LOCATION:表示表的数据存储路径。只有外部表才能使用LOCATION关键字来指定存储路径。
关于分区和分桶的介绍可以参考我这篇文章:【大数据】Hive 分区和分桶的区别及示例讲解
2)列分隔符和行分隔符
在Hive中,ROW FORMAT DELIMITED 是用于指定表中数据的列分隔符和行分隔符的关键字,默认的列分隔符是制表符(Tab键),默认的行分隔符是换行符(\n)。
通过指定这些分隔符,用户可以将不同格式的数据导入到Hive表中,并在查询表时正确地解析数据。使用 ROW FORMAT DELIMITED,用户可以指定以下参数:
-
FIELDS TERMINATED BY: 用于指定列分隔符。默认情况下,Hive使用制表符作为列分隔符。用户可以使用该选项指定自定义的列分隔符,例如逗号、竖线等。 -
ESCAPED BY: 用于指定转义字符。如果数据中包含列分隔符或行分隔符,则可以使用该选项指定转义字符,以确保这些字符被正确解析。 -
LINES TERMINATED BY: 用于指定行分隔符。默认情况下,Hive使用换行符作为行分隔符。用户可以使用该选项指定自定义的行分隔符,例如换行符、回车符等。
例如,以下是使用 ROW FORMAT DELIMITED 指定逗号作为列分隔符和换行符作为行分隔符来创建一个Hive表的示例:
CREATE TABLE mytable (
id INT,
name STRING,
age INT,
address STRING
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
LINES TERMINATED BY '\n';
3)添加表数据方式
1、INSERT 方式
在Hive中,可以使用 INSERT 语句来向表中添加数据。Hive支持多种数据来源和格式,包括文本文件、CSV文件、JSON文件等。内部表(管理表)的数据只能通过 INSERT INTO 命令进行插入,而不能直接修改原始数据。普通表在被删除时,会将表中的数据一并删除。
以下是使用 INSERT 语句向Hive表中添加数据的基本语法:
INSERT INTO TABLE tablename [PARTITION (partition_column = partition_value, ...)]
[ROW FORMAT row_format]
[STORED AS file_format]
SELECT ...;
- 其中,
tablename是要添加数据的表的名称, partition_column是要添加数据的表的分区列名称,partition_value是要添加数据的表的分区列值,row_format是用于指定输入数据格式的关键字,file_format是用于指定输出数据格式的关键字,SELECT ...是用于指定要添加到表中的数据的查询语句。
下面是向一个Hive表中添加数据的示例:
假设有一个Hive表mytable,其中包含四个字段:id、name、age和gender,用户可以使用以下命令向该表中添加数据:
INSERT INTO mytable VALUES (1, 'Alice', 25, 'F'), (2, 'Bob', 30, 'M'), (3, 'Charlie', 35, 'M');
该命令将向mytable表中插入三行数据,每行数据包含四个字段。
用户也可以从其他表或查询结果中插入数据。例如,以下命令从另一个表yourtable中选择一些数据插入到mytable中:
INSERT INTO mytable (id, name, age, gender)
SELECT id, name, age, gender
FROM yourtable
WHERE age > 25;
该命令将从yourtable表中选择年龄大于25的数据,并将其插入到mytable表中。
【注意】向Hive表中添加数据时,数据格式和分隔符需要与表定义中的一致,否则会导致数据无法正确解析。可以使用
ROW FORMAT和FIELDS TERMINATED BY等关键字来指定数据格式和分隔符。
2、LOAD DATA方式
使用LOAD DATA语句可以将本地或HDFS上的数据加载到Hive表中。具体语法和示例请见下面的示例:
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (partition_column = partition_value, ...)]
[ROW FORMAT row_format]
[FIELDS TERMINATED BY field_delim]
[LINES TERMINATED BY line_delim]
[STORED AS file_format];
- 其中,filepath是要加载的数据文件路径,
- tablename是要加载数据的表的名称,
- partition_column是要加载数据的表的分区列名称,
- partition_value是要加载数据的表的分区列值,
- row_format是用于指定输入数据格式的关键字,
- field_delim是用于指定字段分隔符的字符,
- line_delim是用于指定行分隔符的字符,
- file_format是用于指定输出数据格式的关键字。
【注意】
- 如果使用了
LOCAL关键字,则表示从本地文件系统加载数据,否则从HDFS加载数据。 - 如果使用了
OVERWRITE关键字,则表示将数据加载到表中时会覆盖原有数据。
例如,以下命令从本地文件系统加载数据文件到一个Hive表中:
# 导入本地文件系统文件数据到表,LOCAL
LOAD DATA LOCAL INPATH '/path/to/datafile' INTO TABLE mytable;
3、外部表方式
在Hive中,可以创建外部表,这样可以将数据存储在HDFS或本地文件系统中,并且不会影响到原始数据文件。
- 创建外部表:使用
CREATE EXTERNAL TABLE语句创建外部表,同时指定外部表的表结构和数据存储位置。例如:
CREATE EXTERNAL TABLE mytable (col1 INT, col2 STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
LOCATION '/path/to/datafile';
其中,mytable 是外部表的名称,col1 和 col2 是表的两个列,ROW FORMAT 和 FIELDS TERMINATED BY 关键字指定了数据格式和分隔符,LOCATION 关键字指定了数据存储位置,可以是HDFS或本地文件系统路径。
-
将数据文件复制到指定位置:将数据文件复制到指定的数据存储位置,例如将数据文件复制到
'/path/to/datafile'目录下。 -
查询数据:使用
SELECT语句查询数据。Hive会自动读取外部表的数据文件并将其解析为表格数据,然后返回查询结果。例如:
SELECT * FROM mytable;
【注意】:
- 创建外部表时,表结构和数据存储位置需要与实际数据文件一致,否则查询结果可能会不正确。
- 同时,使用外部表方式导入数据时,Hive不会移动或修改数据文件,因此需要手动将数据文件复制到指定位置,并保证数据文件的完整性。
需要注意的是,向Hive表中添加数据时,数据格式和分隔符需要与表定义中的一致,否则会导致数据无法正确解析。可以使用
ROW FORMAT和FIELDS TERMINATED BY等关键字来指定数据格式和分隔符。
4)DDL 常见操作
1、创建表
使用 CREATE TABLE 语句来创建表。
语法:
CREATE TABLE table_name (col1 data_type, col2 data_type, ...)
示例:
CREATE TABLE employee (id INT, name STRING, age INT, salary FLOAT);
# 添加数据,不建议使用INSERT 效率很低,一般使用LOAD DATA方式导入数据
INSERT INTO employee VALUES (1, 'Alice', 25, 5000.00), (2, 'Bob', 30, 6000.00), (3, 'Charlie', 35, 7000.00);
# 导入数据(HDFS)
LOAD DATA INPATH '/path/to/input/data' INTO TABLE employee;
2、修改表
使用 ALTER TABLE 语句来修改表结构。
语法:
ALTER TABLE table_name ADD COLUMN col_name data_type
ALTER TABLE table_name DROP COLUMN col_name
ALTER TABLE table_name RENAME TO new_table_name
示例:
ALTER TABLE employee ADD COLUMN gender STRING;
3、删除表
使用 DROP TABLE 语句来删除表。
语法:
DROP TABLE table_name
示例:
DROP TABLE employee
4、创建分区表
用 CREATE TABLE ... PARTITIONED BY 语句来创建分区表。
语法:
CREATE TABLE table_name (col1 data_type, col2 data_type, ...)
PARTITIONED BY (partition_col1 data_type, partition_col2 data_type, ...)
示例:
CREATE TABLE employee_partitioned (id INT, name STRING, age INT, salary FLOAT)
PARTITIONED BY (gender STRING);
5、创建外部表
用 CREATE EXTERNAL TABLE 语句来创建外部表。
语法:
CREATE EXTERNAL TABLE table_name (col1 data_type, col2 data_type, ...)
LOCATION '/path/to/table'
示例:
CREATE EXTERNAL TABLE employee_external (id INT, name STRING, age INT, salary FLOAT)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
LOCATION '/user/hive/warehouse/employee_external';
五、视图操作
1)创建视图
用 CREATE VIEW 语句来创建视图。
语法:
CREATE VIEW view_name AS SELECT col1, col2, ... FROM table_name
示例:
CREATE VIEW employee_view AS SELECT id, name, age FROM employee WHERE age > 25;
2)修改视图
用 ALTER VIEW 语句来修改视图。
语法:
ALTER VIEW view_name AS SELECT col1, col2, ... FROM table_name WHERE condition
示例:
ALTER VIEW employee_view AS SELECT id, name, age, salary FROM employee WHERE age > 25;
3)删除视图
用 DROP VIEW 语句来修改视图。
语法:
DROP VIEW view_name
示例:
DROP VIEW employee_view;
4)查看视图定义
用 DESCRIBE VIEW 语句来查看视图定义。
语法:
DESCRIBE VIEW view_name
示例:
DESCRIBE VIEW employee_view;
总之,Hive中的DDL操作和视图操作可以帮助用户定义和管理表、视图等数据结构,从而更加灵活和高效地管理和查询数据。用户可以根据实际需求选择使用哪种操作方式,以达到更好的数据管理和操作效果。
关于Hive DDL 操作与视图操作讲解就先到这里了,有任何疑问欢迎给我留言,后续会持续更新相关文章,也可关注我的公众号号【大数据与云原生技术分享】加群交流或私信咨询问题等等~
