
并查集基础
一、概念及其介绍
并查集是一种树型的数据结构,用于处理一些不相交集合的合并及查询问题。
并查集的思想是用一个数组表示了整片森林(parent),树的根节点唯一标识了一个集合,我们只要找到了某个元素的的树根,就能确定它在哪个集合里。
二、适用说明
并查集用在一些有 N 个元素的集合应用问题中,我们通常是在开始时让每个元素构成一个单元素的集合,然后按一定顺序将属于同一组的元素所在的集合合并,其间要反复查找一个元素在哪个集合中。这个过程看似并不复杂,但数据量极大,若用其他的数据结构来描述的话,往往在空间上过大,计算机无法承受,也无法在短时间内计算出结果,所以只能用并查集来处理。
三、并查集的基本数据表示

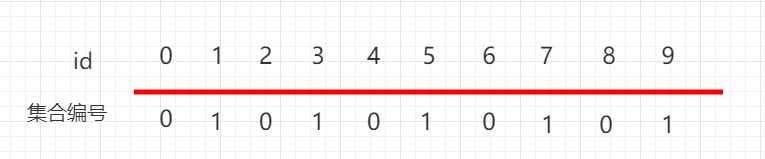
再如上图 0、2、4、6、8 下面都是 0 这个集合,表示 0、2、4、6、8 这五个元素是相连接的,1、3、5、7、9 下面都是 1 这个集合,表示 0,1、3、5、7、9 这五个元素是相连的。
构造一个类 UnionFind,初始化, 每一个id[i]指向自己, 没有合并的元素:
...public UnionFind1(int n) {
count = n;
id = new int[n];
// 初始化, 每一个id[i]指向自己, 没有合并的元素
for (int i = 0; i < n; i++)
id[i] = i;
}
...
Java 实例代码
UnionFind.java 文件代码:
package runoob.union;public class UnionFind{
private int[] id;
// 数据个数
private int count;
public UnionFind1(int n) {
count = n;
id = new int[n];
for (int i = 0; i < n; i++)
id[i] = i;
}
}
并查集快速查找
本小节基于上一小节并查集的结构介绍基础操作,查询和合并和判断是否连接。
查询元素所在的集合编号,直接返回 id 数组值,O(1) 的时间复杂度。
...private int find(int p) {
assert p >= 0 && p < count;
return id[p];
}
...
合并元素 p 和元素 q 所属的集合, 合并过程需要遍历一遍所有元素, 再将两个元素的所属集合编号合并,这个过程是 O(n) 复杂度。
...public void unionElements(int p, int q) {
int pID = find(p);
int qID = find(q);
if (pID == qID)
return;
for (int i = 0; i < count; i++)
if (id[i] == pID)
id[i] = qID;
}
...
Java 实例代码
源码包下载:Download
UnionFind1.java 文件代码:
package runoob.union;/**
* 第一版union-Find
*/
public class UnionFind1 {
// 我们的第一版Union-Find本质就是一个数组
private int[] id;
// 数据个数
private int count;
public UnionFind1(int n) {
count = n;
id = new int[n];
// 初始化, 每一个id[i]指向自己, 没有合并的元素
for (int i = 0; i < n; i++)
id[i] = i;
}
// 查找过程, 查找元素p所对应的集合编号
private int find(int p) {
assert p >= 0 && p < count;
return id[p];
}
// 查看元素p和元素q是否所属一个集合
// O(1)复杂度
public boolean isConnected(int p, int q) {
return find(p) == find(q);
}
// 合并元素p和元素q所属的集合
// O(n) 复杂度
public void unionElements(int p, int q) {
int pID = find(p);
int qID = find(q);
if (pID == qID)
return;
// 合并过程需要遍历一遍所有元素, 将两个元素的所属集合编号合并
for (int i = 0; i < count; i++)
if (id[i] == pID)
id[i] = qID;
}
}
并查集快速合并
对于一组数据,并查集主要支持两个动作:
-
union(p,q) - 将 p 和 q 两个元素连接起来。
-
find(p) - 查询 p 元素在哪个集合中。
-
isConnected(p,q) - 查看 p 和 q 两个元素是否相连接在一起。
在上一小节中,我们用 id 数组的形式表示并查集,实际操作过程中查找的时间复杂度为 O(1),但连接效率并不高。
本小节,我们将用另外一种方式实现并查集。把每一个元素,看做是一个节点并且指向自己的父节点,根节点指向自己。如下图所示,节点 3 指向节点 2,代表 3 和 2 是连接在一起的,节点2本身是根节点,所以指向自己。
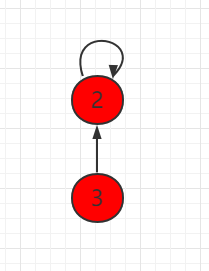
同样用数组表示并查集,但是下面一组元素用 parent 表示当前元素指向的父节点,每个元素指向自己,都是独立的。

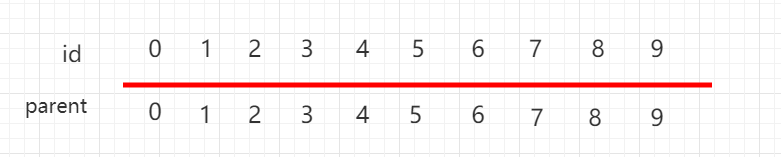
如果此时操作 union(4,3),将元素 4 指向元素 3:
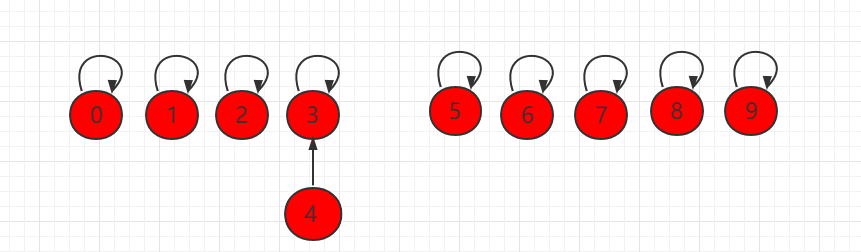
数组也进行相应改变:
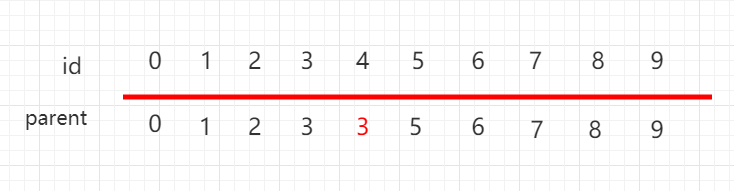
判断两个元素是否连接,只需要判断根节点是否相同即可。
如下图,节点 4 和节点 9 的根节点都是 8,所以它们是相连的。
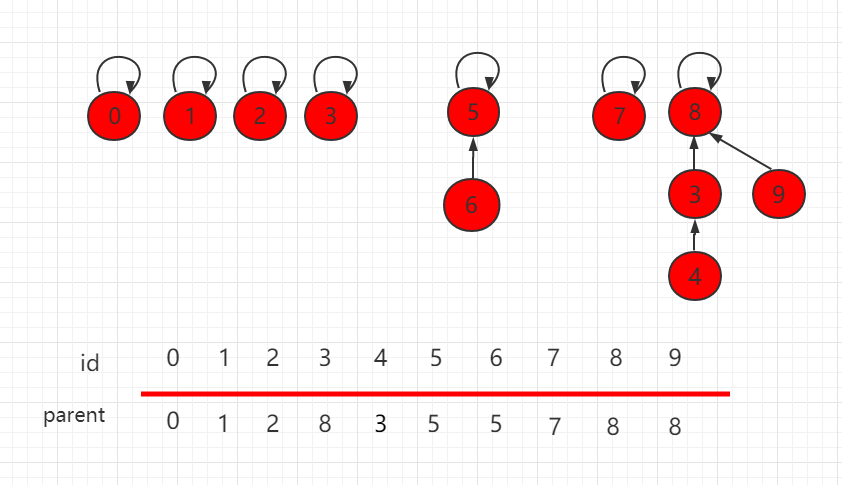
连接两个元素,只需要找到它们对应的根节点,使根节点相连,那它们就是相连的节点。
假设要使上图中的 6 和 4 相连,只需要把 6 的根节点 5 指向 4 的根节点 8 即可。
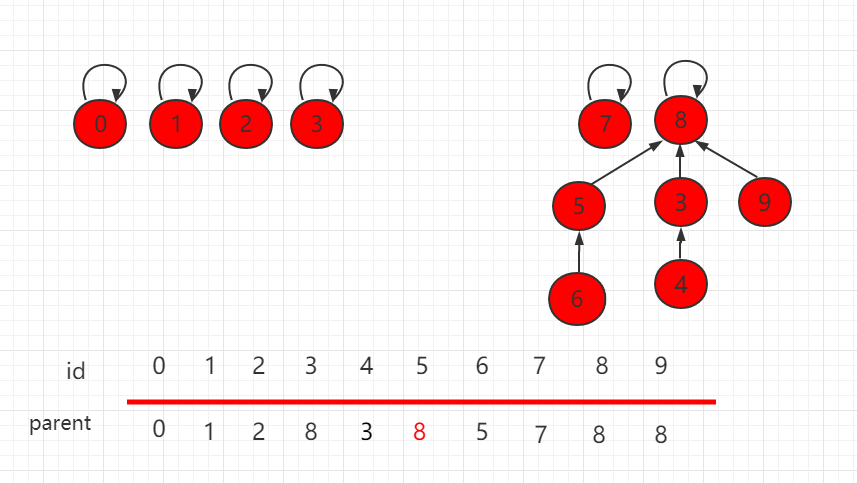
构建这种指向父节点的树形结构, 使用一个数组构建一棵指向父节点的树,parent[i] 表示 i 元素所指向的父节点。
...private int[] parent;
private int count; // 数据个数
...
查找过程, 查找元素 p 所对应的集合编号,不断去查询自己的父亲节点, 直到到达根节点,根节点的特点 parent[p] == p,O(h) 复杂度, h 为树的高度。
...private int find(int p){
assert( p >= 0 && p < count );
while( p != parent[p] )
p = parent[p];
return p;
}
...
合并元素 p 和元素 q 所属的集合,分别查询两个元素的根节点,使其中一个根节点指向另外一个根节点,两个集合就合并了。这个操作是 O(h) 的时间复杂度,h 为树的高度。
public void unionElements(int p, int q){int pRoot = find(p);
int qRoot = find(q);
if( pRoot == qRoot )
return;
parent[pRoot] = qRoot;
}
Java 实例代码
源码包下载:Download
UnionFind2.java 文件代码:
package runoob.union;/**
* 第二版unionFind
*/
public class UnionFind2 {
// 我们的第二版Union-Find, 使用一个数组构建一棵指向父节点的树
// parent[i]表示第一个元素所指向的父节点
private int[] parent;
private int count; // 数据个数
// 构造函数
public UnionFind2(int count){
parent = new int[count];
this.count = count;
// 初始化, 每一个parent[i]指向自己, 表示每一个元素自己自成一个集合
for( int i = 0 ; i < count ; i ++ )
parent[i] = i;
}
// 查找过程, 查找元素p所对应的集合编号
// O(h)复杂度, h为树的高度
private int find(int p){
assert( p >= 0 && p < count );
// 不断去查询自己的父亲节点, 直到到达根节点
// 根节点的特点: parent[p] == p
while( p != parent[p] )
p = parent[p];
return p;
}
// 查看元素p和元素q是否所属一个集合
// O(h)复杂度, h为树的高度
public boolean isConnected( int p , int q ){
return find(p) == find(q);
}
// 合并元素p和元素q所属的集合
// O(h)复杂度, h为树的高度
public void unionElements(int p, int q){
int pRoot = find(p);
int qRoot = find(q);
if( pRoot == qRoot )
return;
parent[pRoot] = qRoot;
}
}
并查集 size 的优化
按照上一小节的思路,我们把如下图所示的并查集,进行 union(4,9) 操作。
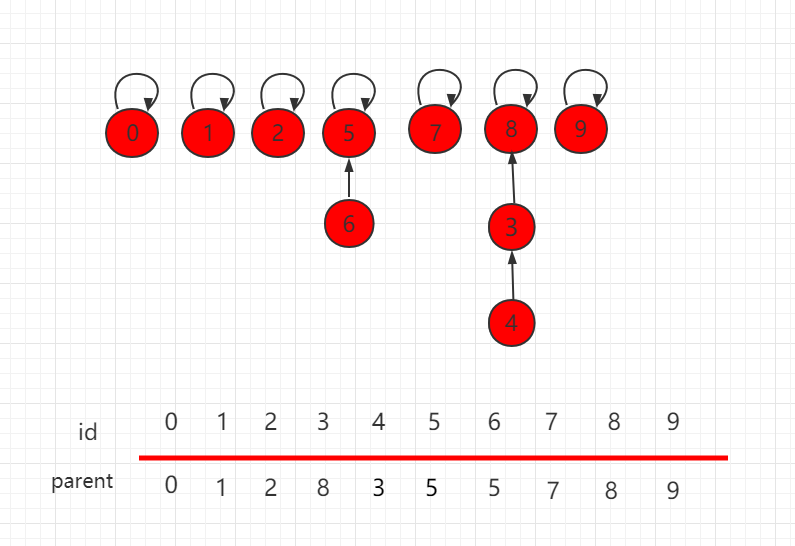
合并操作后的结构为:
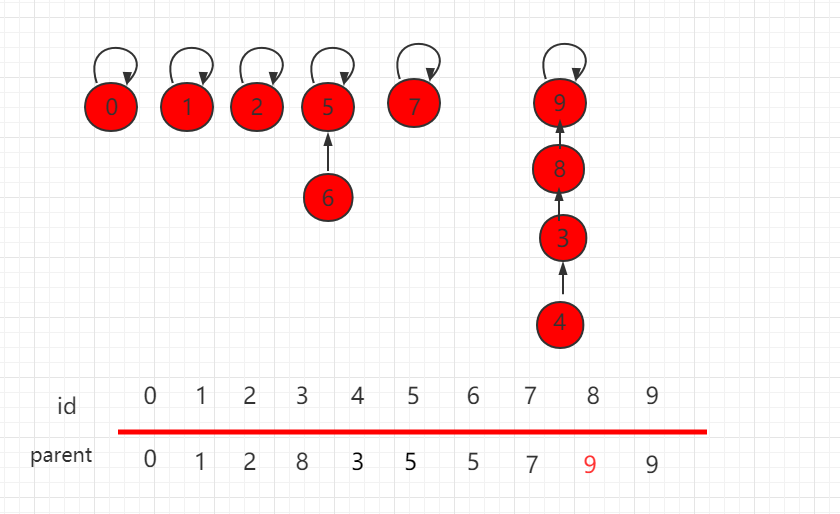
可以发现,这个结构的树的层相对较高,若此时元素数量增多,这样产生的消耗就会相对较大。解决这个问题其实很简单,在进行具体指向操作的时候先进行判断,把元素少的集合根节点指向元素多的根节点,能更高概率的生成一个层数比较低的树。
构造并查集的时候需要多一个参数,sz 数组,sz[i] 表示以 i 为根的集合中元素个数。
// 构造函数public UnionFind3(int count){
parent = new int[count];
sz = new int[count];
this.count = count;
// 初始化, 每一个parent[i]指向自己, 表示每一个元素自己自成一个集合
for( int i = 0 ; i < count ; i ++ ){
parent[i] = i;
sz[i] = 1;
}
}
在进行合并操作时候,根据两个元素所在树的元素个数不同判断合并方向。
public void unionElements(int p, int q){int pRoot = find(p);
int qRoot = find(q);
if( pRoot == qRoot )
return;
if( sz[pRoot] < sz[qRoot] ){
parent[pRoot] = qRoot;
sz[qRoot] += sz[pRoot];
}
else{
parent[qRoot] = pRoot;
sz[pRoot] += sz[qRoot];
}
}
优化后,合并结果如下,9 指向父节点 8。
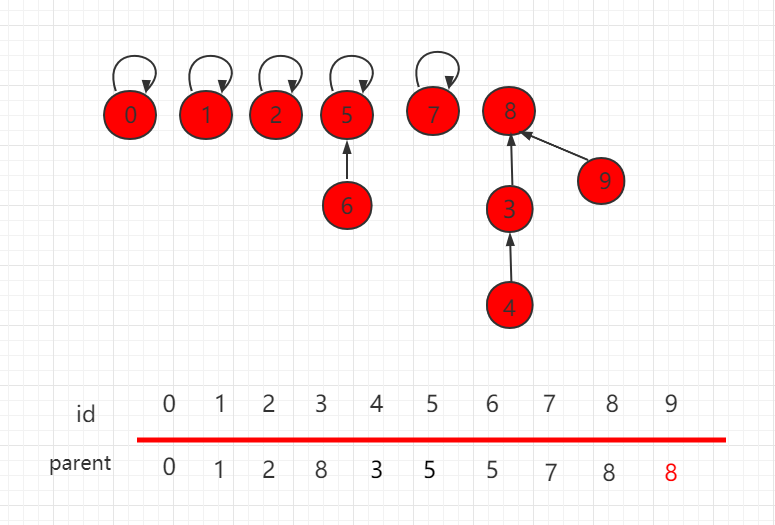
Java 实例代码
源码包下载:Download
UnionFind3.java 文件代码:
package runoob.union;/**
* 并查集size的优化
*/
public class UnionFind3 {
// parent[i]表示第一个元素所指向的父节点
private int[] parent;
// sz[i]表示以i为根的集合中元素个数
private int[] sz;
// 数据个数
private int count;
// 构造函数
public UnionFind3(int count){
parent = new int[count];
sz = new int[count];
this.count = count;
// 初始化, 每一个parent[i]指向自己, 表示每一个元素自己自成一个集合
for( int i = 0 ; i < count ; i ++ ){
parent[i] = i;
sz[i] = 1;
}
}
// 查找过程, 查找元素p所对应的集合编号
// O(h)复杂度, h为树的高度
private int find(int p){
assert( p >= 0 && p < count );
// 不断去查询自己的父亲节点, 直到到达根节点
// 根节点的特点: parent[p] == p
while( p != parent[p] )
p = parent[p];
return p;
}
// 查看元素p和元素q是否所属一个集合
// O(h)复杂度, h为树的高度
public boolean isConnected( int p , int q ){
return find(p) == find(q);
}
// 合并元素p和元素q所属的集合
// O(h)复杂度, h为树的高度
public void unionElements(int p, int q){
int pRoot = find(p);
int qRoot = find(q);
if( pRoot == qRoot )
return;
// 根据两个元素所在树的元素个数不同判断合并方向
// 将元素个数少的集合合并到元素个数多的集合上
if( sz[pRoot] < sz[qRoot] ){
parent[pRoot] = qRoot;
sz[qRoot] += sz[pRoot];
}
else{
parent[qRoot] = pRoot;
sz[pRoot] += sz[qRoot];
}
}
}
并查集 rank 的优化
上一小节介绍了并查集基于 size 的优化,但是某些场景下,也会存在某些问题,如下图所示,操作 union(4,2)。
![]()
根据上一小节,size 的优化,元素少的集合根节点指向元素多的根节点。操完后,层数变为4,比之前增多了一层,如下图所示:
![]()
由此可知,依靠集合的 size 判断指向并不是完全正确的,更准确的是,根据两个集合层数,具体判断根节点的指向,层数少的集合根节点指向层数多的集合根节点,如下图所示,这就是基于 rank 的优化。
![]()
我们在并查集的属性中,添加 rank 数组,rank[i] 表示以 i 为根的集合所表示的树的层数。
...private int[] rank; // rank[i]表示以i为根的集合所表示的树的层数
private int[] parent; // parent[i]表示第i个元素所指向的父节点
private int count; // 数据个数
...
构造函数相应作出修改:
...// 构造函数
public UnionFind4(int count){
rank = new int[count];
parent = new int[count];
this.count = count;
// 初始化, 每一个parent[i]指向自己, 表示每一个元素自己自成一个集合
for( int i = 0 ; i < count ; i ++ ){
parent[i] = i;
rank[i] = 1;
}
}
...
合并两元素的时候,需要比较根节点集合的层数,整个过程是 O(h)复杂度,h为树的高度。
...public void unionElements(int p, int q){
int pRoot = find(p);
int qRoot = find(q);
if( pRoot == qRoot )
return;
if( rank[pRoot] < rank[qRoot] ){
parent[pRoot] = qRoot;
}
else if( rank[qRoot] < rank[pRoot]){
parent[qRoot] = pRoot;
}
else{ // rank[pRoot] == rank[qRoot]
parent[pRoot] = qRoot;
rank[qRoot] += 1; // 此时, 我维护rank的值
}
}
...
Java 实例代码
源码包下载:Download
UnionFind3.java 文件代码:
package runoob.union;/**
* 基于rank的优化
*/
public class UnionFind4 {
private int[] rank; // rank[i]表示以i为根的集合所表示的树的层数
private int[] parent; // parent[i]表示第i个元素所指向的父节点
private int count; // 数据个数
// 构造函数
public UnionFind4(int count){
rank = new int[count];
parent = new int[count];
this.count = count;
// 初始化, 每一个parent[i]指向自己, 表示每一个元素自己自成一个集合
for( int i = 0 ; i < count ; i ++ ){
parent[i] = i;
rank[i] = 1;
}
}
// 查找过程, 查找元素p所对应的集合编号
// O(h)复杂度, h为树的高度
private int find(int p){
assert( p >= 0 && p < count );
// 不断去查询自己的父亲节点, 直到到达根节点
// 根节点的特点: parent[p] == p
while( p != parent[p] )
p = parent[p];
return p;
}
// 查看元素p和元素q是否所属一个集合
// O(h)复杂度, h为树的高度
public boolean isConnected( int p , int q ){
return find(p) == find(q);
}
// 合并元素p和元素q所属的集合
// O(h)复杂度, h为树的高度
public void unionElements(int p, int q){
int pRoot = find(p);
int qRoot = find(q);
if( pRoot == qRoot )
return;
if( rank[pRoot] < rank[qRoot] ){
parent[pRoot] = qRoot;
}
else if( rank[qRoot] < rank[pRoot]){
parent[qRoot] = pRoot;
}
else{ // rank[pRoot] == rank[qRoot]
parent[pRoot] = qRoot;
rank[qRoot] += 1; // 维护rank的值
}
}
}
并查集路径压缩
并查集里的 find 函数里可以进行路径压缩,是为了更快速的查找一个点的根节点。对于一个集合树来说,它的根节点下面可以依附着许多的节点,因此,我们可以尝试在 find 的过程中,从底向上,如果此时访问的节点不是根节点的话,那么我们可以把这个节点尽量的往上挪一挪,减少数的层数,这个过程就叫做路径压缩。
如下图中,find(4) 的过程就可以路径压缩,让数的层数更少。
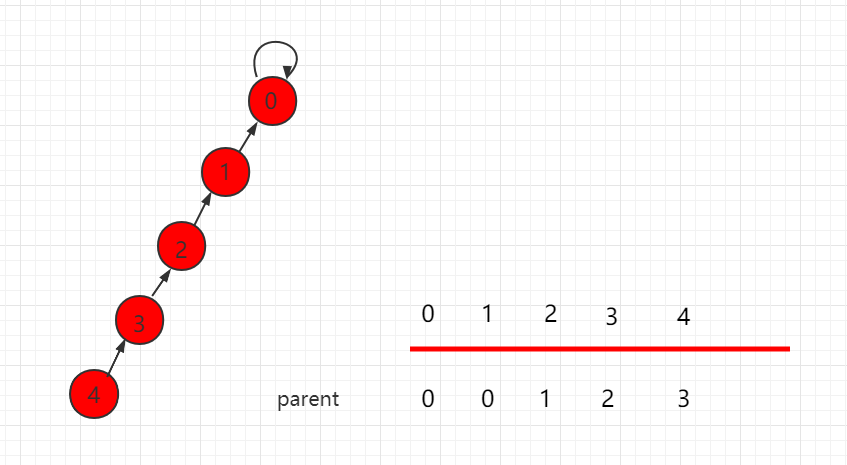
节点 4 往上寻找根节点时,压缩第一步,树的层数就减少了一层:
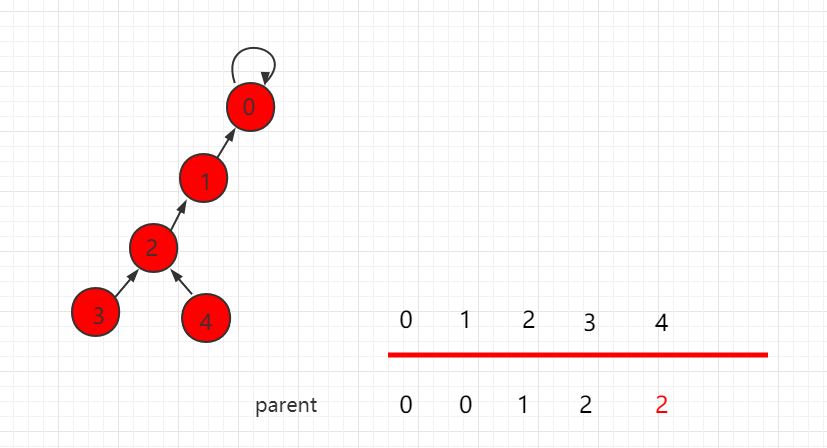
节点 2 向上寻找,也不是根节点,那么把元素 2 指向原来父节点的父节点,操后后树的层数相应减少了一层,同时返回根节点 0。
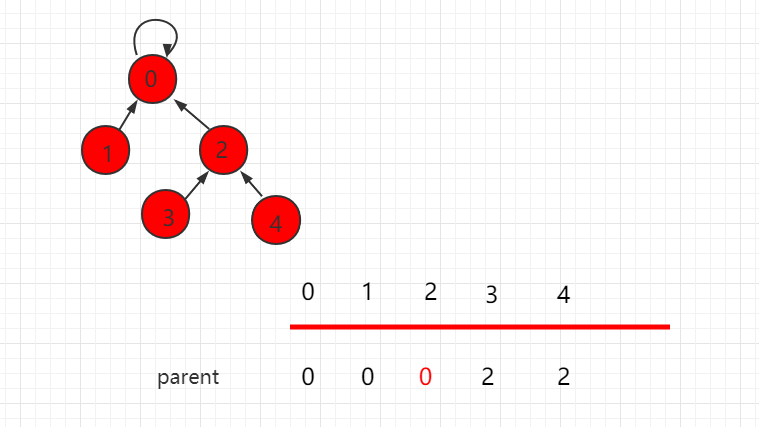
find 过程代码修改为 :
// 查找过程, 查找元素p所对应的集合编号// O(h)复杂度, h为树的高度
private int find(int p){
assert( p >= 0 && p < count );
// path compression 1
while( p != parent[p] ){
parent[p] = parent[parent[p]];
p = parent[p];
}
return p;
}
上述路径压缩并不是最优的方式,我们可以把最初的树压缩成下图所示,层数是最少的。
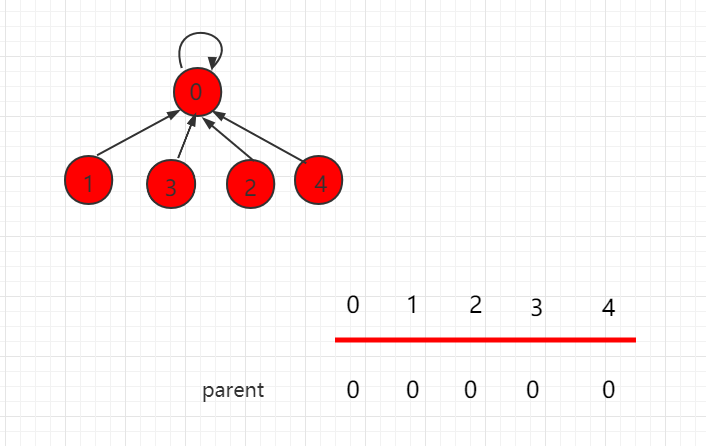
这个 find 过程代表表示为:
...// 查找过程, 查找元素p所对应的集合编号
// O(h)复杂度, h为树的高度
private int find(int p) {
assert (p >= 0 && p < count);
//第二种路径压缩算法
if (p != parent[p])
parent[p] = find(parent[p]);
return parent[p];
}
...
Java 实例代码
源码包下载:Download
UnionFind3.java 文件代码:
package runoob.union;/**
* 基于rank的优化
*/
public class UnionFind4 {
private int[] rank; // rank[i]表示以i为根的集合所表示的树的层数
private int[] parent; // parent[i]表示第i个元素所指向的父节点
private int count; // 数据个数
// 构造函数
public UnionFind4(int count){
rank = new int[count];
parent = new int[count];
this.count = count;
// 初始化, 每一个parent[i]指向自己, 表示每一个元素自己自成一个集合
for( int i = 0 ; i < count ; i ++ ){
parent[i] = i;
rank[i] = 1;
}
}
// 查找过程, 查找元素p所对应的集合编号
// O(h)复杂度, h为树的高度
private int find(int p){
assert( p >= 0 && p < count );
// 不断去查询自己的父亲节点, 直到到达根节点
// 根节点的特点: parent[p] == p
while( p != parent[p] )
p = parent[p];
return p;
//第二种路径压缩算法
//if( p != parent[p] )
//parent[p] = find( parent[p] );
//return parent[p];
}
// 查看元素p和元素q是否所属一个集合
// O(h)复杂度, h为树的高度
public boolean isConnected( int p , int q ){
return find(p) == find(q);
}
// 合并元素p和元素q所属的集合
// O(h)复杂度, h为树的高度
public void unionElements(int p, int q){
int pRoot = find(p);
int qRoot = find(q);
if( pRoot == qRoot )
return;
if( rank[pRoot] < rank[qRoot] ){
parent[pRoot] = qRoot;
}
else if( rank[qRoot] < rank[pRoot]){
parent[qRoot] = pRoot;
}
else{ // rank[pRoot] == rank[qRoot]
parent[pRoot] = qRoot;
rank[qRoot] += 1; // 维护rank的值
}
}
}
标签:查集,parent,int,元素,find,qRoot,概述,节点 From: https://www.cnblogs.com/shoshana-kong/p/17372223.html