作者:京东零售 牛晓光
根据现有调研和实践,由OpenAI提供的ChatGPT/GPT-4模型和CodeX模型能够很好的理解和生成业界大多数编程语言的逻辑和代码,其中尤其擅长Python、JavaScript、TypeScript、Ruby、Go、C# 和 C++等语言。
然而在实际应用中,我们经常会在编码时使用到一些私有框架、包、协议和DSL等。由于相关模型没有学习最新网络数据,且这些私有数据通常也没有发布在公开网络上,OpenAI无法根据这些私有信息生成对应代码。
一、OpenAI知识学习方式
OpenAI提供了几种方式,让OpenAI模型学习私有知识:
1. 微调模型
OpenAI支持基于现有的基础模型,通过提供“prompt - completion”训练数据生成私有的自定义模型。
使用方法
在执行微调工作时,需要执行下列步骤:
1. 准备训练数据:数据需包含prompt/completion,格式支持CSV, TSV, XLSX, JSON等。
- 格式化训练集:
openai tools fine_tunes.prepare_data -f <LOCAL_FILE> LOCAL_FILE:上一步中准备好的训练数据。
2. 训练模型微调:openai api fine_tunes.create -t <LOCAL_FILE> -m <BASE_MODULE> --suffix "<MODEL_SUFFIX>"
LOCAL_FILE:上一步中准备好的训练集。BASE_MODULE:基础模型的名称,可选的模型包括ada、babbage、curie、davinci等。MODEL_SUFFIX:模型名称后缀。
3. 使用自定义模型
使用成本
在微调模型方式中,除了使用自定义模型进行推理时所需支付的费用外,训练模型时所消耗的Tokens也会对应收取费用。根据不同的基础模型,费用如下:
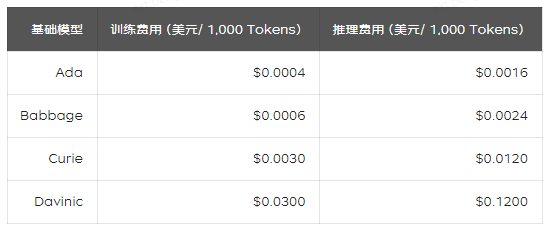
结论
使用微调模型进行私有知识学习,依赖于大量的训练数据,训练数据越多,微调效果越好。
此方法适用于拥有大量数据积累的场景。
2. 聊天补全
GPT模型接收对话形式的输入,而对话按照角色进行整理。对话数据的开始包含系统角色,该消息提供模型的初始说明。可以在系统角色中提供各种信息,如:
-
助手的简要说明
-
助手的个性特征
-
助手需要遵循的指令或规则
-
模型所需的数据或信息
我们可以在聊天中,通过自定义系统角色为模型提供执行用户指令所必要的私有信息。
使用方法
可以在用户提交的数据前,追加对私有知识的说明内容。
openai.createChatCompletion({
model: "gpt-3.5-turbo",
messages: [
{ role: "system", content: "你是一款智能聊天机器人,帮助用户回答有关内容管理系统低代码引擎CCMS的技术问题。智能根据下面的上下文回答问题,如果不确定答案,可以说“我不知道”。\n\n" +
"上下文:\n" +
"- CCMS通过可视化配置方式生成中后台管理系统页面,其通过JSON数据格式描述页面信息,并在运行时渲染页面。\n" +
"- CCMS支持普通列表、筛选列表、新增表单、编辑表单、详情展示等多种页面类型。\n" +
"- CCMS可以配置页面信息、接口定义、逻辑判断、数据绑定和页面跳转等交互逻辑。"
},
{ role: "user", content: "CCMS是什么?" }
]
}).then((response) => response.data.choices[0].message.content);
使用成本
除了用户所提交的内容外,系统角色所提交的关于私有知识的说明内容,也会按照Tokens消耗量进行计费。

结论
使用聊天补全进行私有知识学习,依赖于系统角色的信息输入,且此部分数据的Tokens消耗会随每次用户请求而重复计算。
此方法适用于私有知识清晰准确,且内容量较少的场景。
二、私有知识学习实践
对于私有框架、包、协议、DSL等,通常具备比较完善的使用文档,而较少拥有海量的用户使用数据,所以在当前场景下,倾向于使用聊天补全的方式让GPT学习私有知识。
而在此基础上,如何为系统角色提供少量而精确的知识信息,则是在保障用户使用情况下,节省使用成本的重要方式。
3. 检索-提问解决方案
我们可以在调用OpenAI提供的Chat服务前,使用用户所提交的信息对私有知识进行检索,筛选出最相关的信息,再进行Chat请求,检索Tokens消耗。
而OpenAI所提供的嵌入(Embedding)服务则可以解决检索阶段的工作。
使用方法
1. 准备搜索数据(一次性)
-
收集:准备完善的使用文档。如:https://jd-orion.github.io/docs
-
分块:将文档拆分为简短的、大部分是独立的部分,这通常是文档中的页面或章节。
-
嵌入:为每一个分块分别调用OpenAI API生成Embedding。
await openai.createEmbedding({
model: "text-embedding-ada-002",
input: fs.readFileSync('./document.md', 'utf-8').toString(),
}).then((response) => response.data.data[0].embedding);
- 存储:保存Embedding数据。(对于大型数据集,可以使用矢量数据库)
2. 检索(每次查询一次)
-
为用户的提问,调用OpenAI API生成Embedding。(同1.3步骤)
-
使用提问Embedding,根据与提问的相关性对私有知识的分块Embedding进行排名。
const fs = require('fs');
const { parse } = require('csv-parse/sync');
const distance = require( 'compute-cosine-distance' );
function (input: string, topN: number) {
const knowledge: { text: string, embedding: string, d?: number }[] = parse(fs.readFileSync('./knowledge.csv').toString());
for (const row of knowledge) {
row.d = distance(JSON.parse(row.embedding), input)
}
knowledge.sort((a, b) => a.d - b.d);
return knowledge.slice(0, topN).map((row) => row.text));
}
3. 提问(每次查询一次)
- 给请求的系统角色插入与问题最相关的信息
async function (knowledge: string[], input: string) {
const response = await openai.createChatCompletion({
model: "gpt-3.5-turbo",
messages: [
{
role: 'system',
content: "你是一款智能聊天机器人,帮助用户回答有关内容管理系 统低代码引擎CCMS的技术问题。\n\n" + knowledge.join("\n")
},
{
role: 'user',
content: input
}
]
}).then((response) => response.data.choices[0].message.content);
return response
}
- 返回GPT的答案
使用成本
使用此方法,需要一次性的支付用于执行Embedding的费用。
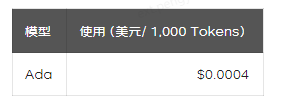
三、低代码自然语言搭建案例
解决了让GPT学习私有知识的问题后,就可以开始使用GPT进行私有框架、库、协议和DSL相关代码的生成了。
本文以低代码自然语言搭建为例,帮助用户使用自然语言对所需搭建或修改的页面进行描述,进而使用GPT对描述页面的配置文件进行修改,并根据返回的内容为用户提供实时预览服务。
使用方法
OpenAI调用组件
const { Configuration, OpenAIApi } = require("openai");
const openai = new OpenAIApi(new Configuration({ /** OpenAI 配置 */ }));
const distance = require('compute-cosine-distance');
const knowledge: { text: string, embedding: string, d?: number }[] = require("./knowledge")
export default function OpenAI (input, schema) {
return new Promise((resolve, reject) => {
// 将用户提问信息转换为Embedding
const embedding = await openai.createEmbedding({
model: "text-embedding-ada-002",
input,
}).then((response) => response.data.data[0].embedding);
// 获取用户提问与知识的相关性并排序
for (const row of knowledge) {
row.d = distance(JSON.parse(row.embedding), input)
}
knowledge.sort((a, b) => a.d - b.d);
// 将相关性知识、原始代码和用户提问发送给GPT-3.5模型
const message = await openai.createChatCompletion({
model: "gpt-3.5-turbo",
messages: [
{
role: 'system',
content: "你是编程助手,需要阅读协议知识,并按照用户的要求修改代码。\n\n" +
"协议知识:\n\n" +
knowledge.slice(0, 10).map((row) => row.text).join("\n\n") + "\n\n" +
"原始代码:\n\n" +
"```\n" + schema + "\n```"
},
{
role: 'user',
content: input
}
]
}).then((response) => response.data.choices[0].message.content);
// 检查返回消息中是否包含Markdown语法的代码块标识
let startIndex = message.indexOf('```');
if (message.substring(startIndex, startIndex + 4) === 'json') {
startIndex += 4;
}
if (startIndex > -1) {
// 返回消息为Markdown语法
let endIndex = message.indexOf('```', startIndex + 3);
let messageConfig;
// 需要遍历所有代码块
while (endIndex > -1) {
try {
messageConfig = message.substring(startIndex + 3, endIndex);
if (
/** messageConfig正确性校验 */
) {
resolve(messageConfig);
break;
}
} catch (e) {
/* 本次失败 */
}
startIndex = message.indexOf('```', endIndex + 3);
if (message.substring(startIndex, startIndex + 4) === 'json') {
startIndex += 4;
}
if (startIndex === -1) {
reject(['OpenAI返回的信息不可识别:', message]);
break;
}
endIndex = message.indexOf('```', startIndex + 3);
}
} else {
// 返回消息可能为代码本身
try {
const messageConfig = message;
if (
/** messageConfig正确性校验 */
) {
resolve(messageConfig);
} else {
reject(['OpenAI返回的信息不可识别:', message]);
}
} catch (e) {
reject(['OpenAI返回的信息不可识别:', message]);
}
}
})
}
低代码渲染
import React, { useState, useEffect } from 'react'
import { CCMS } from 'ccms-antd'
import OpenAI from './OpenAI'
export default function App () {
const [ ready, setReady ] = useState(true)
const [ schema, setSchema ] = useState({})
const handleOpenAI = (input) => {
OpenAI(input, schema).then((nextSchema) => {
setReady(false)
setSchema(nextSchema)
})
}
useEffect(() => {
setReady(true)
}, [schema])
return (
<div style={{ width: '100vw', height: '100vh' }}>
{ready && (
<CCMS
config={pageSchema}
/** ... */
/>
)}
<div style={{ position: 'fixed', right: 385, bottom: 20, zIndex: 9999 }}>
<Popover
placement="topRight"
trigger="click"
content={
<Form.Item label="使用OpenAI助力搭建页面:" labelCol={{ span: 24 }}>
<Input.TextArea
placeholder="请在这里输入内容,按下Shift+回车确认。"
defaultValue={defaultPrompt}
onPressEnter={(e) => {
if (e.shiftKey) {
handleOpenAI(e.currentTarget.value)
}
}}
/>
</Form.Item>
}
>
<Button shape="circle" type="primary" icon={ /** OpenAI icon */ } />
</Popover>
</div>
</div>
)
}
四、信息安全
根据OpenAI隐私政策说明,使用API方式进行数据访问时:
- 除非明确的授权,OpenAI不会使用用户发送的数据进行学习和改进模型。
- 用户发送的数据会被OpenAI保留30天,以用于监管和审查。(有限数量的授权OpenAI员工,以及负有保密和安全义务的专业第三方承包商,可以访问这些数据)
- 用户上传的文件(包括微调模型是提交的训练数据),除非用户删除,否则会一直保留。
另外,OpenAI不提供模型的私有化部署(包括上述微调模型方式所生成的自定义模型),但可以通过联系销售团队购买私有容器。
文中所使用的训练数据、私有框架知识以及低代码框架均源自本团队开发并已开源的内容。用户使用相关服务时也会进行数据安全提示。
标签:代码生成,const,私有,模型,startIndex,OpenAI,message From: https://www.cnblogs.com/Jcloud/p/17370365.html