e-DCC & v-DCC
概述
DCC(双联通分量,Double Connected Component),是 SCC 在有向图中的相对概念,与 SCC 不同的是,DCC 分为两种:e-DCC(边双联通分量,Edge Double Connected Component)与 v-DCC(点双联通分量,Vertex Double Connected Component),其定义分别为图的极大边双联通子图与点双联通子图。
对几个定义做出解释:
桥
对于联通无向图 \(G\) 中的边 \(e\),若删去其后,图不再联通,则称边 \(e\) 为图 \(G\) 的桥。
边双联通
对于联通无向图 \(G\),若其中不含桥,则称图 \(G\) 为边联通的。
边双联通子图
对于联通无向图 \(G\),若其子图 \(G'\) 为边双联通的,则称 \(G'\) 为 \(G\) 的边双联通子图。
极大边双联通子图(边双联通分量)
对于联通无向图 \(G = (V, E)\) 与其点双联通子图 \(G' = (V', E')\),若 \(G'\) 加入任意一条边 \(e = (u, v)\) 满足 \(e \in E \land e \notin E' \land u \in V' \land v \in V'\) 后,\(G'\) 失去其边双连通性,则称 \(G'\) 为 \(G\) 的边双联通分量。
割点
对于联通无向图 \(G\) 中的点 \(u\),若删去其和与其相关的所有边后,图变为不再连通,则称点 \(u\) 为 \(G\) 中的割点。
2 - 点联通
对于联通无向图 \(G\),若其中不含割点,则称图 \(G\) 为 2 - 点联通的。
点双联通
与 2 - 点联通唯一的区别为两个点一条边的联通无向图是点双联通的,但不是 2 - 点联通的。注意区分这两者之间的区别。
点双联通子图
对于联通无向图 \(G\),若其子图 \(G'\) 为点双联通的,则称 \(G'\) 为 \(G\) 的点双联通子图。
极大点双联通子图(点双联通分量)
对于联通无向图 \(G = (V, E)\) 与其点双联通子图 \(G' = (V', E')\),若 \(G'\) 加入任意一个点 \(v \in V \land v \notin V'\) 与其有关的边后,\(G'\) 失去其点双连通性,则称 \(G'\) 为 \(G\) 的点双联通分量。
以下将点双联通分量与边双联通分量分别简称为 v-DCC 与 e-DCC。
桥不属于任意一个 e-DCC,但是一个割点可以属于多个 v-DCC。
与有向图的 SCC 类似,无向图的 DCC 同样可以用于简化图的结构。
求法
由于 DCC 与 SCC 之间的相似性,为了求出 DCC,我们又要祭出伟大的计算机科学家:R. E. Tarjan!
约定
为了应用 Tarjan 的 DFS,我们还是记 \(\operatorname{dfn}(u)\) 为点 \(u\) 的 DFS 时间戳,\(\operatorname{low}(u)\) 为点 \(u\) 在不经过返祖边时能够达到的时间戳最小的祖先。
求割点
割点的定义告诉我们,如果一个点是割点,则一定存在一些点,在不经过割点的情况下无法回到其祖先(因为对于这些点,路径是唯一的)。
于是我们在遍历 DFS 树时,对于当前搜索的点 \(u\),若存在 \(u\) 在 DFS 子树中的直接后代 \(v\) 满足 \(\operatorname{dfn}(u) \le \operatorname{low}(v)\),即 \(v\) 在不经过 \(u\) 的情况下,无法到达 \(u\) 在 DFS 搜索树中的祖先,则可以证明 \(u\) 为割点。
但是这个做法仍然有缺陷。考虑下边的这张图:
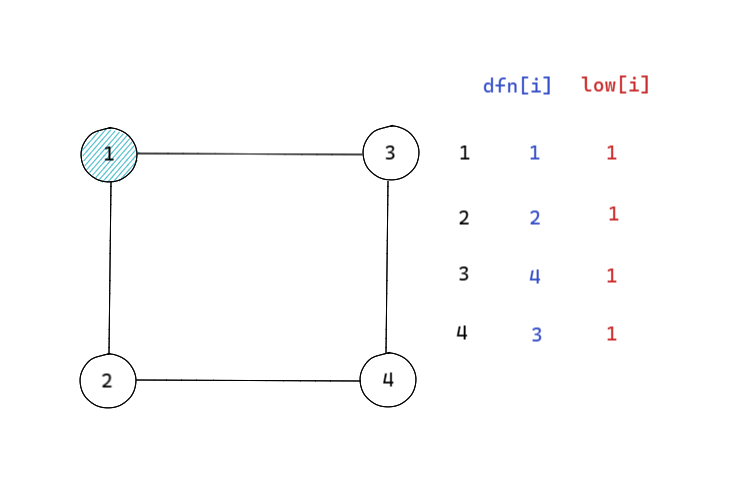
首先可以确定的是,这张图里肯定不会有割点,但是如果单纯地按照上述的算法去求的话,由于 \(\operatorname{low}(2) = 1 \le \operatorname{dfn}(1) = 1\),点 \(1\) 就会被判定为割点,而问题出在这个 \(1\) 点它根本就没有祖先啊,而我们上边算法正确的前提就是一定存在一些点,在不经过割点的情况下无法回到其祖先,既然祖先根本不存在,那就没有割点这一说了。
这告诉我们,当出发点在一个环中时,需要特判。我们记录下当前这棵 DFS 树的根节点 \(\mathrm{root}\),如果有 \(u = \mathrm{root}\) 的话,那么 \(u\) 就不是割点。
这样就完了吗?当然没有!考虑如下的这幅图:
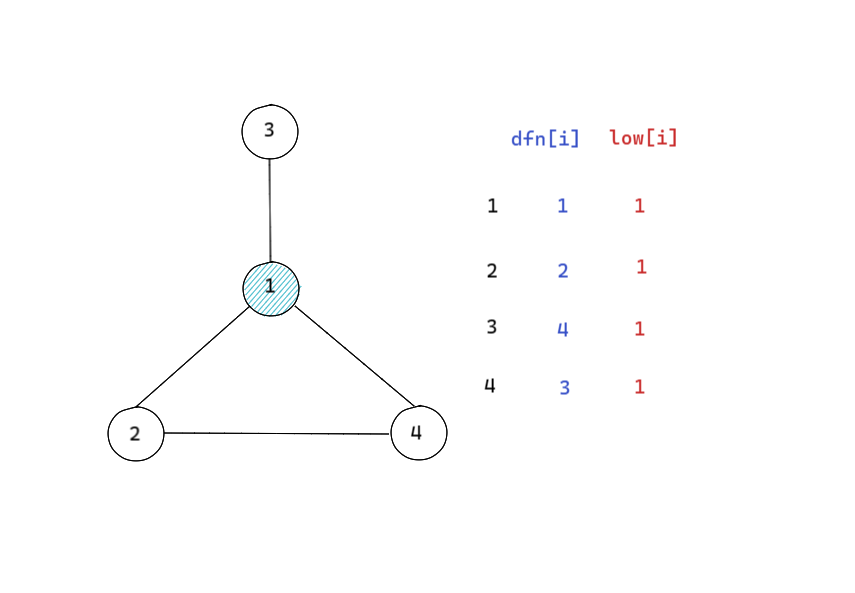
显然,在这张图中,点 \(1\) 是一个割点,但是如果用上边的特判的话,由于 \(1\) 是搜索树的根节点,它会被认为无法成为割点。
问题出在哪呢?就是不一定非得通过割点回到祖先,也有可能是到达搜索树的其他分支。比如在这张图中,虽然 \(1\) 确实没有祖先,但是这棵搜索树有两个分支:\(2\) 所处的分支与 \(3\) 所处的分支,\(2\) 必须要通过 \(1\) 才能到达 \(3\)。
我们发现如果出现这样的情况,则搜索树根节点 \(u\) 在搜索树中的子节点的个数一定大于 1,因为只有这样,才有可能出现其他分支。于是我们加上这个特判,就可以成功地求出割点了。
实现
std::vector<int> findCut() {
std::vector<int> dfn(n), low(n), res;
int clk = 0;
std::function<void(int, int)> tarjan = [&](int u, int inEdge) {
dfn[u] = low[u] = ++clk;
int ch = 0;
for (auto i : e[u]) {
int v = edges[i].v;
if (!dfn[v]) {
tarjan(v, i);
ch++;
low[u] = std::min(low[u], low[v]);
if (low[v] >= dfn[u]) {
res.push_back(u);
}
} else if (i != (inEdge ^ 1)) {
low[u] = std::min(low[u], dfn[v]);
}
}
if (inEdge == -1 && ch == 0) {
res.push_back(u);
}
return;
};
for (int i = 1; i < n; i++) {
if (!dfn[i]) {
tarjan(i, -1);
}
}
return res;
}
v-DCC
Tarjan 算法的核心不仅有 \(\operatorname{dfn}\) 与 \(\operatorname{low}\) 的优美定义,还有对递归栈的巧妙运用。定义一个递归栈 \(s\),在做 DFS 时,考虑把途经的每一条边压入栈中,当我们找到了一个割点时,就把栈中的边弹出去,一直弹到栈顶为当前这条边为止。这样,所弹出的边连接的所有节点就构成一个 v-DCC。
在具体实现中,事实上不需要在栈中存边,仍然可以存点,这是很好理解的,并且如果直接存边的话,由于边可能连接重复节点,还需要去重才能求出真正的 v-DCC,这会使时间复杂度多一个 \(\log\),很不划算。
但是要注意,如果栈中存的是点,不能将当前找到的这个割点弹出,如我们上边所说,一个割点可能属于多个 v-DCC,为了保证把 v-DCC 找全,割点不能出栈。
并且,当当前搜索树中只有一个孤立的节点时,它当然是一个割点,并且自身即构成一个 v-DCC。这个需要特判,因为根本没有子节点来让你比较 \(\operatorname{dfn}\) 与 \(\operatorname{low}\)。
实现
每个点不一定只属于一个 v-DCC,因此,无法像 e-DCC 那样用 bln 与 siz 来还原出每个 e-DCC,只能用二维数组来存每一个 v-DCC 的节点。
int findDCC(std::vector<std::vector<int>> &ans, std::vector<int> &siz) {
ans.clear(), siz.clear();
ans.resize(1), siz.resize(1);
std::vector<int> dfn(n), low(n);
std::stack<int> st;
int clk = 0, dccCnt = 0;
std::function<void(int, int)> tarjan = [&](int u, int rt) {
dfn[u] = low[u] = ++clk;
st.push(u);
if (u == rt && e[u].size() == 0) {
dccCnt++;
ans.emplace_back(1, u);
siz.push_back(1);
}
for (auto i : e[u]) {
int v = edges[i].v;
if (!dfn[v]) {
tarjan(v, rt);
low[u] = std::min(low[u], low[v]);
if (low[v] >= dfn[u]) {
int pivot;
dccCnt++;
siz.push_back(0);
ans.emplace_back(0);
do {
pivot = st.top();
st.pop();
ans[dccCnt].push_back(pivot);
siz[dccCnt]++;
} while (pivot != v);
ans[dccCnt].push_back(u);
siz[dccCnt]++;
}
} else {
low[u] = std::min(low[u], dfn[v]);
}
}
return;
};
for (int i = 1; i < n; i++) {
if (!dfn[i]) {
tarjan(i, i);
}
}
return dccCnt;
}
求桥
与求割点类似,如果一条边 \(e = (u, v)\) 是桥的话,设 \(\operatorname{dfn}(u) \lt \operatorname{dfn}(v)\),则在 \(u\) 的搜索树的这个分支中一定存在不经过这条边就无法到达其祖先的点。但是要注意如果一条边是桥的话,则不经过这条边,\(u\) 搜索树的这个分支中的点无法到达 \(u\)。所以判断桥时,要 \(\operatorname{dfn}(u) \lt \operatorname{low}(v)\) 才行,而不是小于等于。
桥没有什么特殊情况,这个也是很好理解的,边连接的一定是两个节点,而点连接的边的数量则是任意的,因此,求桥比求割点要简单。
实现
std::vector<int> findBridge() {
std::vector<int> dfn(n), low(n), res;
int clk = 0;
std::function<void(int, int)> tarjan = [&](int u, int inEdge) {
dfn[u] = low[u] = ++clk;
for (auto i : e[u]) {
int v = edges[i].v;
if (!dfn[v]) {
tarjan(v, i);
low[u] = std::min(low[u], low[v]);
if (dfn[u] < low[u]) {
res.push_back(i), res.push_back(i ^ 1);
}
} else if (i != (inEdge ^ 1)) {
low[u] = std::min(low[u], dfn[v]);
}
}
};
for (int i = 1; i < n; i++) {
if (!dfn[i]) {
tarjan(i, 0);
}
}
return res;
}
e-DCC
与求 v-DCC 不同,求 e-DCC 有两种方法。
第一种方法比较容易理解。先做一遍 DFS 把所有的桥找出来并打上标记,再做一遍 DFS,但是限制不得通过桥,相当于用桥把原图分割成几个部分,割出来的每一个部分就是一个 e-DCC。
与 v-DCC 相比,e-DCC 与 SCC 更为相似,强调的都是点与点之间的连通性,并且也都满足删去联通分量中的任意一个点,剩下的点仍然两两可达。因此我们还可以用求 SCC 的方法来求 e-DCC。
定义一个递归栈 \(s\),在每搜到一个节点时,就把节点压入栈中,对于节点 \(u\),若搜索结束后满足 \(\operatorname{dfn}(u) = \operatorname{low}(u)\),即 \(u\) 本身即是 \(u\) 的搜索子树可达到的 DFS 序最小的节点,\(u\) 搜索子树中的点都无法到达比 \(u\) 更“浅”的节点,而之前能够构成 e-DCC 的节点都已被弹出,则此时栈中的节点即构成一个 e-DCC。
这种方法的实现几乎与求有向图 SCC 的 Tarjan 算法一模一样。但是要注意的是,由于图中可能存在重边,我们应当用边来表示来时的节点,只有这样才能做到不重复访问某一节点。
实现
由于 Tarjan 法用的更为频繁,且只需要一次 DFS,因此我写的是 Tarjan 的那一种。bln 是每个节点所属 e-DCC 的编号,siz 是每个 e-DCC 的大小。因为每个节点只可能属于一个 e-DCC,有了这两个数组,我们就可以还原出所有 e-DCC 的状态。
int findDCC(std::vector<int> &bln, std::vector<int> &siz) {
bln.clear(), siz.clear();
bln.resize(n), siz.push_back(0);
std::vector<int> dfn(n), low(n);
std::stack<int> st;
int clk = 0, dccCnt = 0;
std::function<void(int, int)> tarjan = [&](int u, int inEdge) {
dfn[u] = low[u] = ++clk;
st.push(u);
for (auto i : e[u]) {
int v = edges[i].v;
if (!dfn[v]) {
tarjan(v, i);
low[u] = std::min(low[u], low[v]);
} else if (i != (inEdge ^ 1)) {
low[u] = std::min(low[u], dfn[v]);
}
}
if (low[u] == dfn[u]) {
int pivot;
++dccCnt;
siz.push_back(0);
do {
pivot = st.top();
st.pop();
bln[pivot] = dccCnt;
siz[dccCnt]++;
} while (pivot != u);
}
};
for (int i = 1; i < n; i++) {
if (!dfn[i]) {
tarjan(i, 0);
}
}
return dccCnt;
}
Epilogue
v-DCC 更多强调的是边的联通关系,而 e-DCC,如上文所说,强调的是点的联通关系。
在实际应用时,v-DCC 使用得更为频繁,因为它有(较于 e-DCC)更好的性质,并且通过圆方树这种神奇的转化方式,可以将部分图(如仙人掌)转化为树来处理,而我们知道,树是比一般的图好处理的。
标签:std,联通,int,DCC,dfn,low From: https://www.cnblogs.com/forgot-dream/p/17367435.html