1 概述
linux内核包括进程管理、内存管理、中断管理、设备驱动、同步机制等各种模块,它们共同运行在一个共享的地址空间中,因此在运行中一旦出现问题,彼此之间可能具有千丝万缕的联系。
而且与用户态不同,内核还需要与形形色色的硬件打交道,因此对于某些较为诡异的问题,除了软件以外还可能受到硬件的影响。如由于射线或电磁辐射的原因造成内存中某个bit翻转,或者某些非法总线地址的访问,导致总线挂死等。
更进一步,内核作为系统的基础服务提供者,若使用软件调试工具,则由于调试工具本身也运行在内核空间,因此有可能会受到其它模块非法操作的干扰。
同时内核挂死以后,其现场抓取也相对比较麻烦,在生产环境下很可能没有抓到出问题时的内存信息,从而给问题定位带来难度。
总之,相对于用户态,内核bug可能受到的影响因素更多,现场抓取更困难,调试手段也更有限,因此有些疑难问题的定位会比较困难。
为此社区也提供了一系列相关的工具,用于辅助分析内核问题,若能用好这些工具,就可以帮助开发人员更加快速、方便地定位问题原因。
由于这些工具种类繁多,适用场景不同,因此有必要对它们的原理和使用方法做一些总结,以帮助更多同学进入内核调试的大门。
当然,这个系列只是笔者在工作和学习中的一些心得体会,并不一定很全面,也可能在某些地方理解不太到位,若在论述中有错误或不严谨的地方,欢迎大家指正。
2 引起内核问题的原因
内核问题主要包括功能问题、内核运行异常和性能问题几种类型。其中功能问题主要指相关模块的运行结果与预期值不同,它可能由于代码逻辑不正确或硬件输出结果不正常等原因导致。
内核运行异常可能由非法指令、内存访问错误或死锁等原因引起。而性能问题则可能由某些低效的程序代码,或cache问题导致。
由于功能问题主要与具体模块的逻辑设计有关,故我们不做过多讨论。而性能问题主要是程序的执行效率达不到预期,严格来说并不属于bug。
因此本系列将分为两个部分,第一部分聚焦于内核运行异常相关的bug调试,而第二部分将介绍一些性能调优相关的工具。众所周知,引起内核bug的原因多种多样,接下来我们将简单介绍一些常见的类型。
2.1 非法内存访问
2.1.1 内存访问越界
用户态每个进程都有自己独立的地址空间,因此即使有进程执行了非法内存访问,最多只影响到进程本身,若其导致进程挂死,则还可以通过重启进程恢复相应的服务。而由于内核所有可用的物理地址都被映射到了线性映射区,且它们是所有模块共享的。
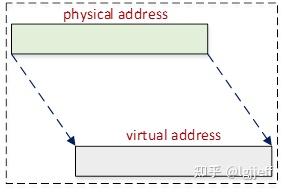
如上图所示,由于线性映射区是分段连续的,因此一旦某个模块在线性映射区的地址访问越界,就可能会破坏另一个与其完全不相关模块的地址空间。且直到受害者模块使用到被破坏的地址之后,该问题才可能被检测到,更糟糕的是内核此时会报告受害者模块的内存访问错误信息,而寻找真正的肇事者却可能并不容易。
内核运行过程中主要需要访问全局数据、栈和动态分配的内存,其中全局数据被定义在内核镜像中,如通过以下命令可查看内核包含的段信息:
readelf -S vmlinux
由于内核段的数量较多,为了方便阅读,下面只列出了一些重要的段:
Section Headers:
[Nr] Name Type Address Offset
Size EntSize Flags Link Info Align
[ 0] NULL 0000000000000000 00000000
0000000000000000 0000000000000000 0 0 0
[ 1] .head.text PROGBITS ffff800010000000 00010000
0000000000010000 0000000000000000 AX 0 0 65536
[ 2] .text PROGBITS ffff800010010000 00020000
00000000006d9868 0000000000000008 AX 0 0 65536
…
[ 4] .rodata PROGBITS ffff8000106f0000 00700000
000000000016eea8 0000000000000000 WA 0 0 4096
…
[13] .init.text PROGBITS ffff8000108b0000 008b0000
000000000003c2dc 0000000000000000 AX 0 0 4
[14] .exit.text PROGBITS ffff8000108ec2dc 008ec2dc
00000000000014d0 0000000000000000 AX 0 0 4
…
[16] .init.data PROGBITS ffff800010900000 00900000
000000000001197d 0000000000000000 WA 0 0 8
[17] .data..percpu PROGBITS ffff800010912000 00912000
000000000000bd18 0000000000000000 WA 0 0 64
readelf: Warning: [18]: Link field (0) should index a symtab section.
…
[19] .data PROGBITS ffff8000109d0000 009d0000
00000000000c2800 0000000000000000 WA 0 0 4096
…
[24] .bss NOBITS ffff800010aa3000 00aa2200
0000000000051eac 0000000000000000 WA 0 0 4096
…
即代码段、全局数据段和bss段都被打包到内核镜像中。其内存在系统启动阶段通过以下流程映射:

在4.x及之前的内核中,这部分内存地址位于线性映射区,因此是通过线性映射的。
而在当前5.14.0内核版本中,其已被修改为通过vmalloc方式映射,即其虚拟地址以0xffff 8xxx开头,在以下的内核虚拟地址布局中正好位于vmalloc区:
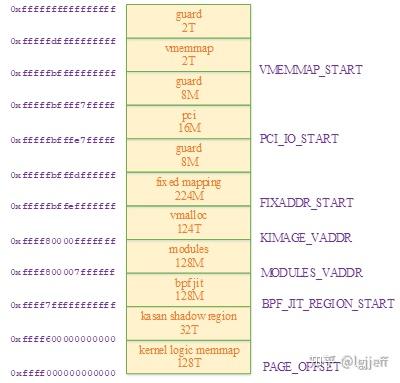
那么这种机制有什么优点呢?从上图可看到vmalloc虚拟地址一共占124T空间,故其虚拟地址空间远远大于实际需求。由于vmalloc是非线性映射,若在每次vmalloc映射的虚拟地址之间保留一些如下图所示的空洞作为guard page。
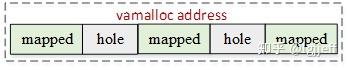
此后一旦cpu访问了超出当前分配空间的内存地址,就会越界到guard page中,显然因为并没有为它们建立页表,此时将会触发内存的abort异常,通过该异常可以很容易地定位到相关的错误位置。
同时每个进程都含有一个独立的内核栈,它用于保存函数的局部变量、传递函数参数以及保存其上一层栈指针和函数返回地址等。它在进程创建时通过以下流程创建:

同样在先前的内核版本中栈地址只能通过线性映射区分配,但在新版本中可通过设置CONFIG_VMAP_STACK配置选项,选择是从vmalloc空间还是线性映射区分配。其主要代码如下:
static unsigned long *alloc_thread_stack_node(struct task_struct *tsk, int node)
{
#ifdef CONFIG_VMAP_STACK
…
stack = __vmalloc_node_range(THREAD_SIZE, THREAD_ALIGN, (1)
VMALLOC_START, VMALLOC_END,
THREADINFO_GFP & ~__GFP_ACCOUNT,
PAGE_KERNEL,
0, node, __builtin_return_address(0));
if (stack) {
tsk->stack_vm_area = find_vm_area(stack);
tsk->stack = stack;
}
return stack;
#else
struct page *page = alloc_pages_node(node, THREADINFO_GFP, (2)
THREAD_SIZE_ORDER);
if (likely(page)) {
tsk->stack = kasan_reset_tag(page_address(page));
return tsk->stack;
}
return NULL;
#endif
}
(1)配置了CONFIG_VMAP_STACK选项,通过vmalloc方式分配栈内存
(2)未配置CONFIG_VMAP_STACK选项,且栈空间大于一个page,通过页分配器分配栈内存
其它的动态内存分配都是通过伙伴系统从动态映射区分配的,因此它们之间的越界访问定位难度会更加大。因此内核也提供了一系列的定位方法,如slub_debug、kasan、kfence等。
另外除了cpu之外,系统中还可能有一些其它硬件需要访问系统内存,如dma,异构系统中的异构核,以及一些硬件加速器等,若它们在内存访问中发生越界,则定位难度将更大
2.1.2 其它内存访问问题
除了访问越界之外,还有一些其它问题可能导致非法内存访问,它们包括:
(1)访问空指针
(2)访问已释放内存
(3)访问未初始化指针
(4)内存访问权限错误,如向一段只读的地址空间中写入数据,或者对不带有执行权限的内存 代码执行操作
2.2 内存泄漏
内存泄漏是指程序中的动态分配内存,由于编码错误或某些原因在使用完成之后,未能正确释放,造成系统内存浪费的问题。它具有隐蔽性和积累性的特点,即在程序执行过程中并不能及时检测到泄漏行为,而且若造成内存泄漏的代码需要重复执行,则随着系统的运行,其泄漏内存会不断累积,最终可能导致系统内存不足而触发oom。内核提供了kmemleak工具,可用于检测内核中的内存泄漏问题
2.3 cache问题
由于cpu的运行速度比主存速度快的多,因此cpu都会通过cache来提升系统的整体性能。若只有cpu执行内存访问操作,则cache对程序员是透明的,硬件会负责维护cache与主存之间数据的一致性。
如通过tag和index进行cache与内存地址的映射,通过cache替换算法执行cache加载与写回/写通操作,以及通过MESI协议执行smp系统中多核之间cache的一致性维护操作等。
除此之外,若某块地址被用于dma操作,或用于和其它异构核之间做通信时的共享内存,则软件需要维护这块地址的cache一致性。它包括在内存分配时需要注意相关内存必须要与cacheline长度对齐,以及在内存操作时,需要在适当的时候执行cache失效和cache刷新操作等
2.4 非法指令
cpu运行时会从pc指针指定的地址处加载指令,然后通过译码器解析其内容,并最终通过控制器和运算器执行。
若加载的指令不合法,显然会导致cpu无法执行该指令,此时cpu会抛出非法指令异常。内核通过异常处理流程接收到该异常后,则会进一步输出该异常相关的详细信息,一般情况下通过这些信息就可以定位到错误的原因
2.5 死锁问题
死锁是一种比较常见的内核卡死原因,它主要包括AB – BA死锁和重复加锁两种类型:
(1)AB – BA死锁:假设有两把锁A和B和两个进程X和Y,此时进程X持有了锁A,进程Y持有了锁B,而且进程X希望继续持有锁B,且进程Y希望继续持有锁A。因此导致它们谁都没办法释放自身持有的锁,从而没办法获取对方持有的锁而形成死锁
(2)内核不允许对spinlock和mutex的递归调用,即一个线程已经持有了一把锁之后,试图再次持有这把锁。一旦出现这种情况,就会导致内核死锁
为此,内核提供了一套死锁检测模块lockdep,可用于检测内核中可能的死锁行为,并在检测到死锁后输出相关的信息,以帮助分析其发生原因
2.6 长时间关抢占或关中断
抢占是调度器工作的基础,若长时间关闭某个cpu的抢占功能,会严重影响系统的实时性。而调度器是通过tick中断驱动的,因此长时间关中断同样会影响系统的实时性,且还使得硬件事件无法得到及时处理。
因此在内核中应该要避免长时间的关闭抢占或中断,为此内核分别为这两种情况实现了softlockup和hardlockup两种检测机制。
需要注意的是由于softlockup用于检测关抢占问题,因此需要通过中断机制来实现,而hardlockup用于监测关中断问题,因此需要非屏蔽中断(NMI)实现。
2.7 线程长时间处于D状态
由于处于D状态(TASK_UNINTERRUPTIBLE)的进程不能接收信号,因此也无法被kill掉。进程被设置为D状态一般是用于等待IO,正常情况下IO执行完成后就会唤醒该进程,使其继续执行。
但可能由于一些编码问题或硬件本身问题,导致某些IO操作无法成功,从而导致与其相关的D状态进程无法被唤醒。
显然这种情况是不正常的,为此内核提供了hungtask机制用于检测处于该状态超过120s的进程,并在检测到之后打印相关警告信息。若内核配置了hung_task_panic选项,则该问题还会触发panic使内核挂死
2.8 硬件问题
硬件问题种类繁多,且有些问题的现象非常诡异,如ddr不稳定可能会导致莫名其妙的死机,且死机时的现象毫无规律。
camera sensor的某些排线信号之间有干扰,可能会导致输出图像间歇性地花屏。访问芯片中处于关闭状态的IP时,可能会导致总线挂死,整个系统无响应等。因此,遇到硬件问题时需要根据实际情况具体分析,逐步缩小问题相关的范围,以定位其根因
标签:映射,--,cache,访问,死锁,内核,panic,内存 From: https://www.cnblogs.com/dongxb/p/17365047.html原文链接:https://www.zhihu.com/column/c_1533871448917118976 版权归原作者所有,如有侵权,请联系作者删除