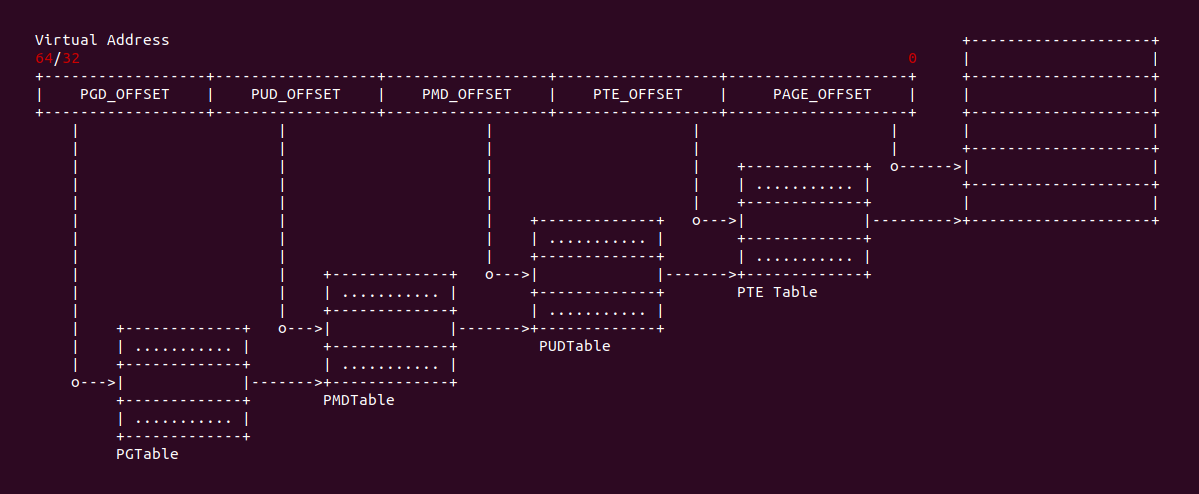
crash简介
crash是redhat的工程师开发的,主要用来离线分析linux内核转存文件,它整合了gdb工具,功能非常强大。可以查看堆栈,dmesg日志,内核数据结构,反汇编等等。
crash支持多种工具生成的转存文件格式,如kdump,LKCD,netdump和diskdump,而且还可以分析虚拟机Xen和Kvm上生成的内核转存文件。同时crash还可以调试运行时系统,直接运行crash即可,ubuntu下内核映象存放在/proc/kcore。
Crash 寄存器约定与函数参数传递
当使用 Crash 工具查看内核转储文件的堆栈时,Crash 工具可能会输出一堆寄存器信息,具体寄存器与架构有关,例如上图的 X86_64 架构,寄存器包含了 EAX/EBX/EDX/ECX/EDI/ESI/RIP/RSP 寄存器等,这些寄存器表示内核转储时寄存器快照。
结合寄存器在不同架构上的使用约定,可以通过这些寄存器信息获得一些利于问题分析的信息,例如,可以通过这些寄存器获得某个函数参数传递的信息。由于寄存器的约定与架构有关,那么接下来对不同的架构进行逐一分析。
X86_64 架构
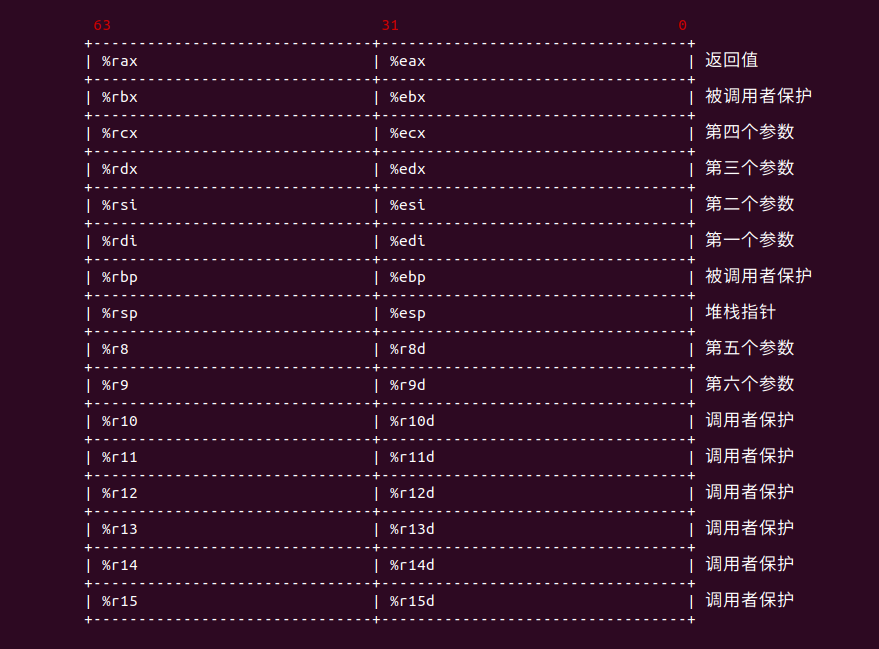
在 X86_64 架构中,寄存器的约定如上,当调用一个函数的时候,RDI 寄存器用于传递第一个参数,RSI 寄存器用于传递第二个寄存器,依次类推,R9 寄存器传递第六个参数, 函数返回值保存在 RAX 寄存器中。
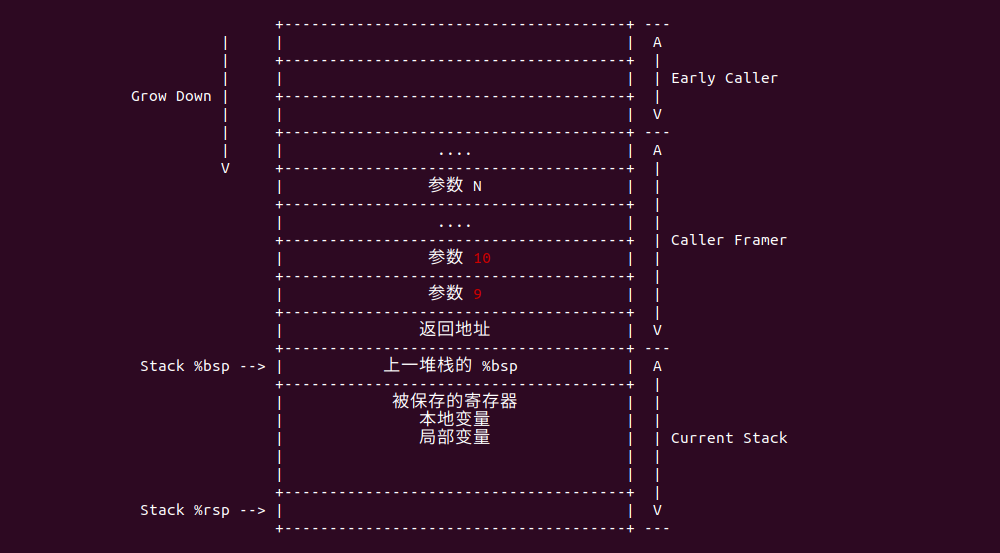
那么如果函数的参数超过六个,那么多余的参数参数如何传递? 在 X86_64 架构中,函数大于 6 个参数的参数通过堆栈进行传输:
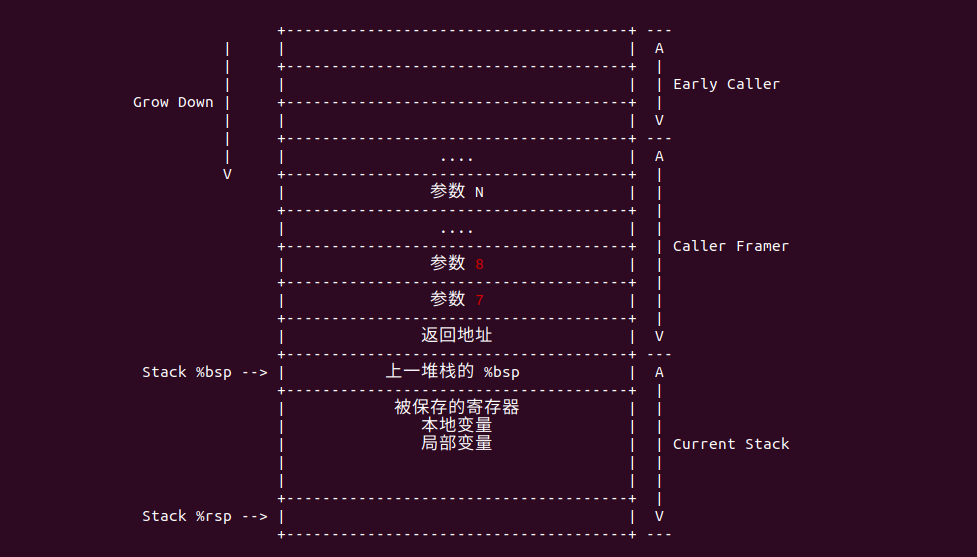
当函数的参数超过六个之后,超过的参数从右到左存储在堆栈中,调用者在调用函数之前,将最后一个参数压缩堆栈,其次将倒数第二个压入堆栈,直到将第七个参数压入堆栈为止。
参数压入完毕之后向堆栈中压入函数的返回地址,其余的第一个参数到第六个参数都按约定存储在寄存器中。接下来通过一个实例来实践整个过程,BiscuitOS 已经支持该实例实践,其在 BiscuitOS 中的部署如下:
cd BiscuitOS
make linux-5.0-x86_64_defconfig
make menuconfig
[*] Package --->
[*] CRASH and BUG Example --->
[*] Example: Function arguments --->
BiscuitOS/output/linux-5.0-x86_64/package/BiscuitOS-crash-register-with-func-argument-default
BiscuitOS-crash-register-with-func-argument-default Source Code
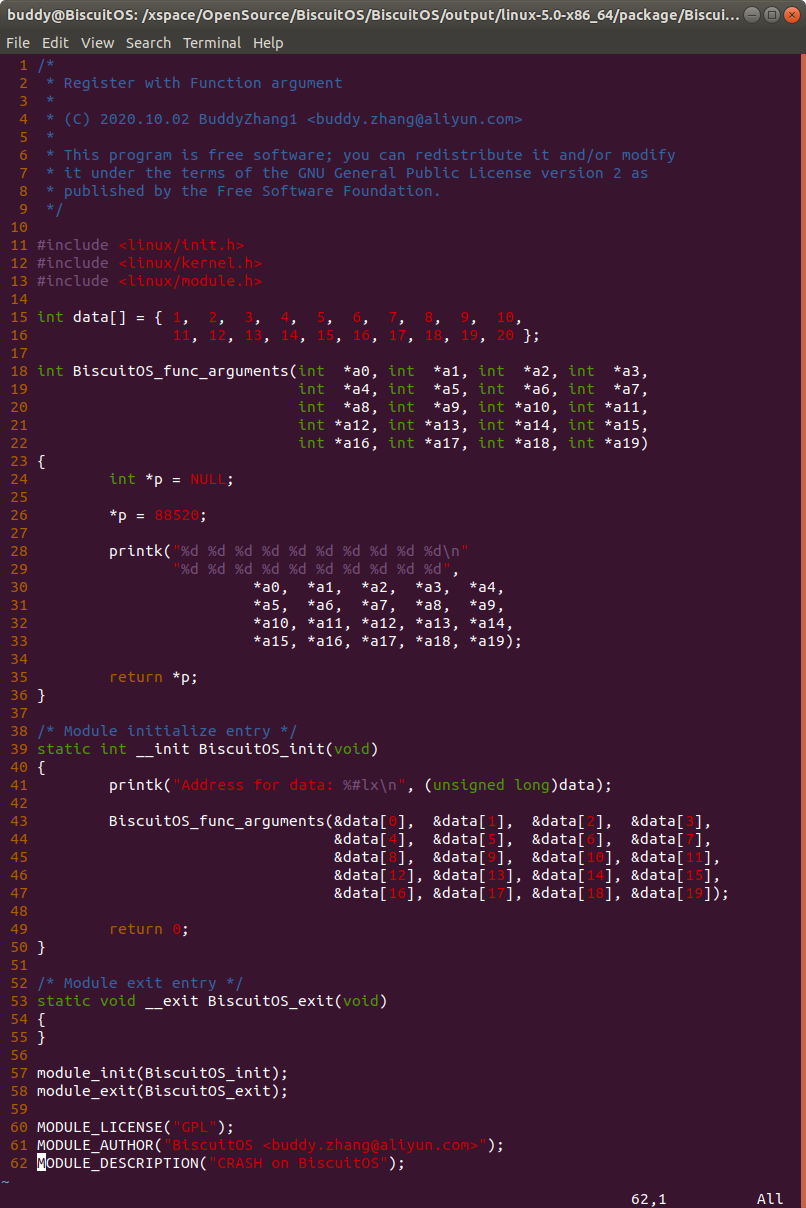
实践案例为一个内核模块,在实践案例中定义了一个函数 BiscuitOS_func_arguments(), 其包含了 20 个参数,并在调用该函数时会触发内核转储,因此可以通过汇编和 CRASH 工具查看函数参数传递过程,首先使用如下命令获得汇编文件:
cd BiscuitOS/output/linux-5.0-x86_64/package/BiscuitOS-crash-register-with-func-argument-default
make
vi BiscuitOS-crash-register-with-func-argument-default/main.s
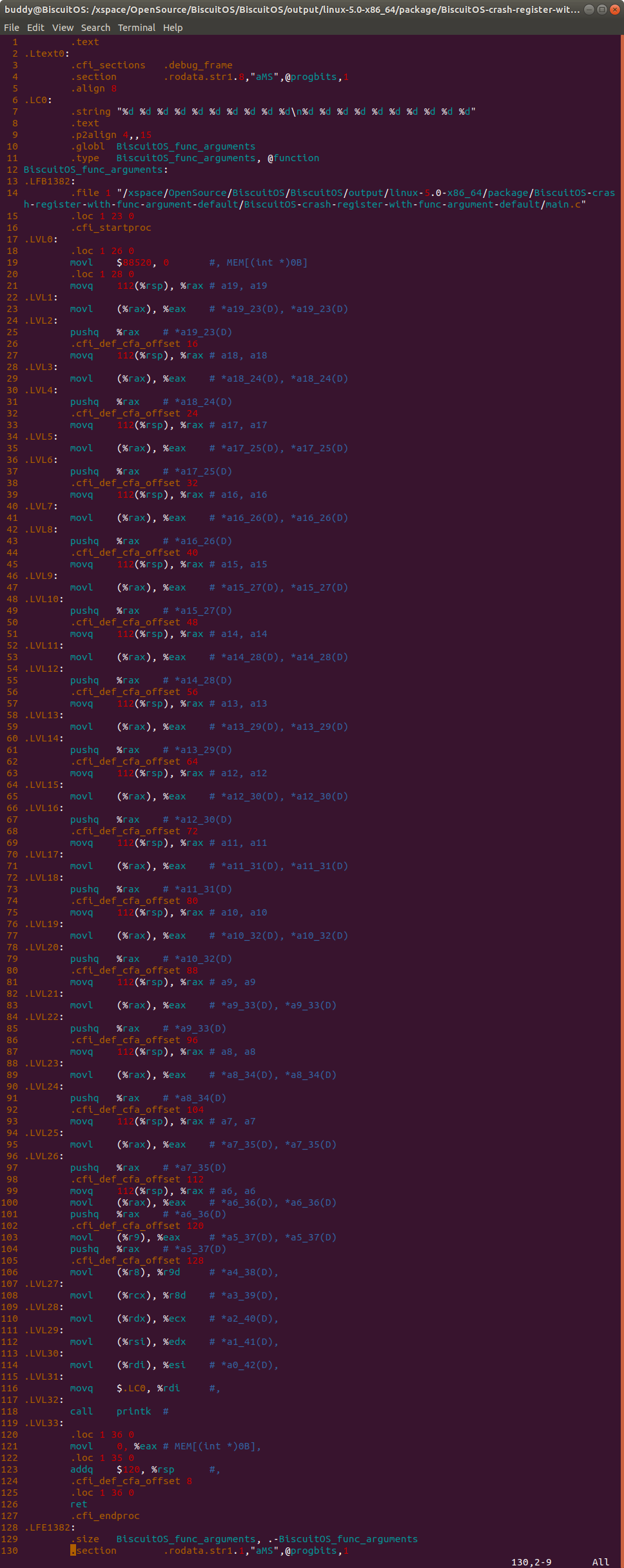
- 114 行第一个参数通过 RDI 寄存器传递
- 112 行第二个参数通过 RSI 寄存器传递
- 110 行第三个参数通过 RDX 寄存器传递
- 108 行第四个参数通过 RCX 寄存器传递
- 106 行第五个参数通过 R8 寄存器传递
- 103 行第六个参数通过 R9 寄存器传递
movq 112(%rsp), %rax
movl (%rax), %eax
pushq %rax
对于第六个之后的参数,函数首先通过上面的方法获得。程序首先通过 “112(%rsp)” 的方式在堆栈中找到最后一个参数的位置,并将参数的地址存储到 RAX 寄存器,接着将 RAX 寄存器对应地址的值进行读取,这样就获得指定参数。
读取完毕之后,程序调用 “pushq” 的方式将 RSP 寄存器的值指向下一帧 (指向更低的地址),然后程序重复上面的代码读取下一个参数,以此类推获得第六个之后的参数. 接着在 BiscuitOS 上运行并获得内核转储文件:
cd BiscuitOS/output/linux-5.0-x86_64/package/BiscuitOS-crash-register-with-func-argument-default
make
make install
make pack
make run
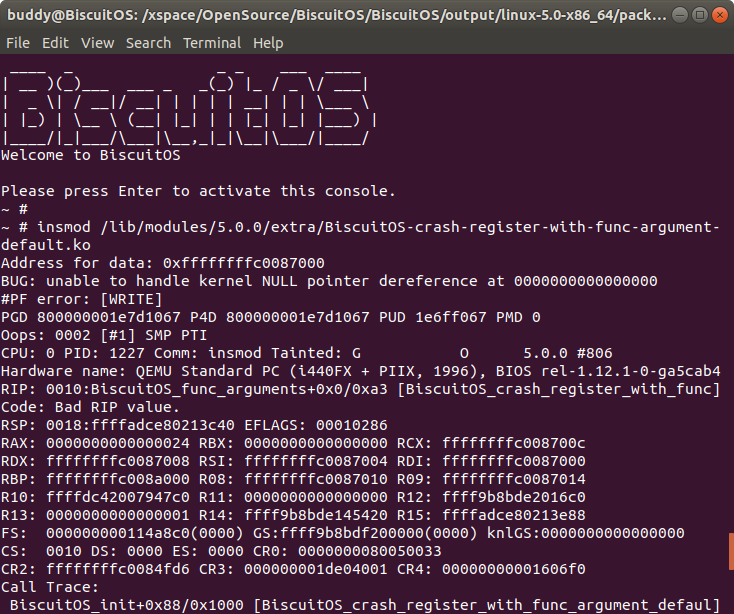
当在 BiscuitOS 中加载模块 BiscuitOS-crash-register-with-func-argument- default.ko,由于代码中对空指针的引用,此时内核触发 panic,此时内核打印出内核转储时寄存器的信息,从运行可知 data 数组的地址为 0xffffffffc0087000, 那么此时 EDI 寄存器中存储了第一个参数,其值也为 0xffffffffc0087000;
同理 ESI 寄存器中存储了第二个参数,其值为 ffffffffc0087004, 正好是函数第二个参数的值,依次类推,RDX/RCX/R8/R9 寄存器均存储函数的参数。实践结果符合预期。
ARM64 架构
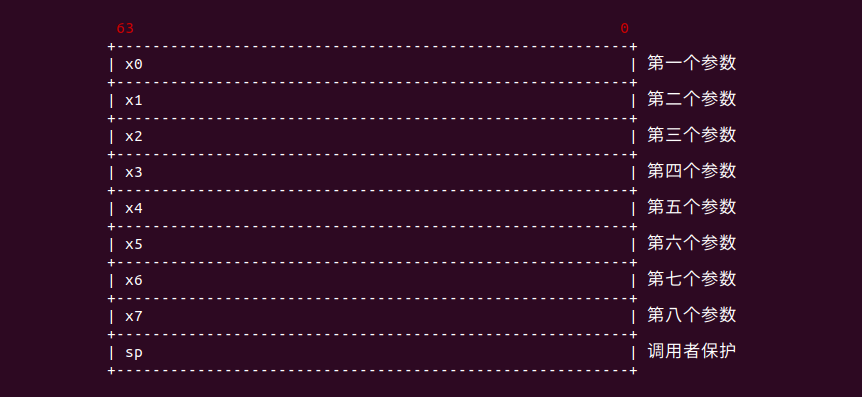
在 ARM64 架构中,使用 X0-X7 寄存器传递参数,第一个参数通过 X0 寄存器传递,第二个参数通过 X1 寄存器传递,以此类推. 返回值存储在 X0 寄存器中.
当函数参数的数量超过 8 个之后,那么多余的参数从右到左依次入栈,被调用者平衡堆栈.接下来通过一个实例来实践整个过程,BiscuitOS 已经支持该实例实践,其在 BiscuitOS 中的部署如下:
cd BiscuitOS
make linux-5.0-aarch_defconfig
make menuconfig
[*] Package --->
[*] CRASH and BUG Example --->
[*] Example: Function arguments --->
BiscuitOS/output/linux-5.0-aarch/package/BiscuitOS-crash-register-with-func-argument-default
BiscuitOS-crash-register-with-func-argument-default Source Code
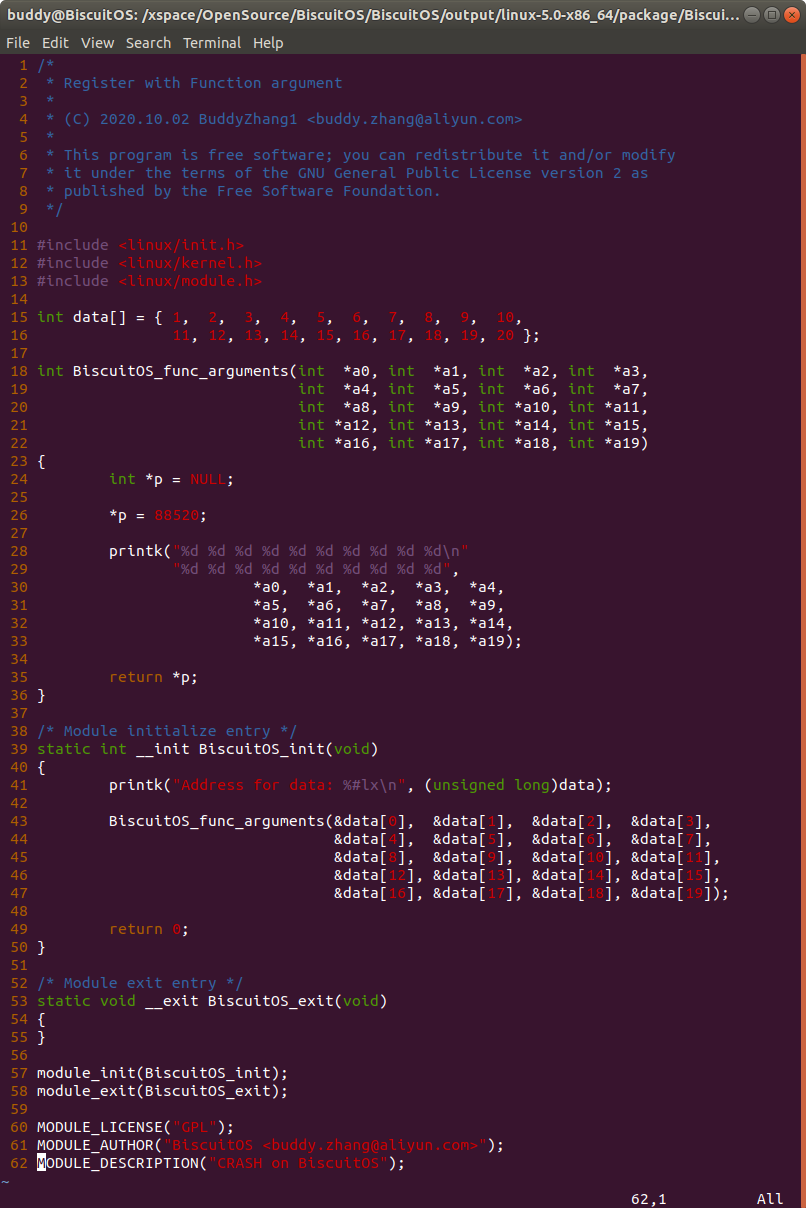
实践案例为一个内核模块,在实践案例中定义了一个函数 BiscuitOS_func_arguments(), 其包含了 20 个参数,并在调用该函数时会触发内核转储,因此可以通过汇编和内核转储信息查看函数参数传递过程,首先使用如下命令获得汇编文件:
cd BiscuitOS/output/linux-5.0-aarch/package/BiscuitOS-crash-register-with-func-argument-default
make
vi BiscuitOS-crash-register-with-func-argument-default/main.s
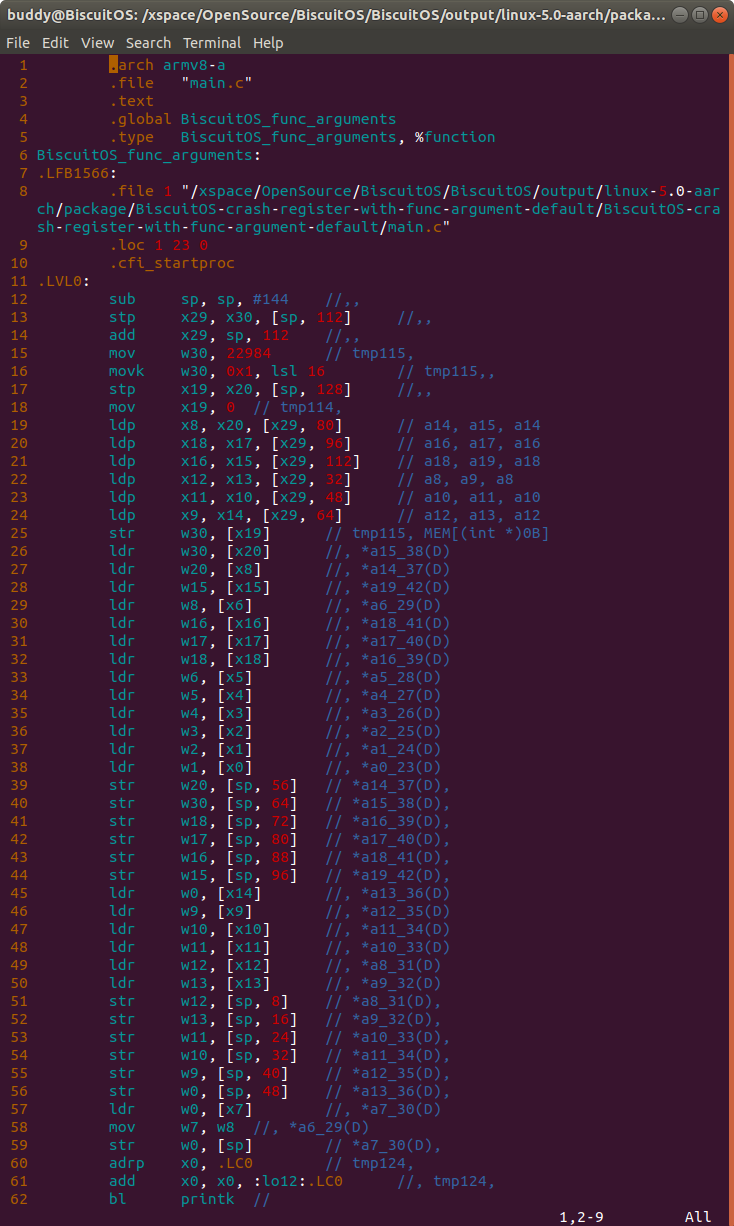
- 38 行第一个参数通过 X0 寄存器传递
- 37 行第二个参数通过 X1 寄存器传递
- 36 行第三个参数通过 X2 寄存器传递
- 35 行第四个参数通过 X3 寄存器传递
- 34 行第五个参数通过 X4 寄存器传递
- 33 行第六个参数通过 X5 寄存器传递
- 29 行第七个参数通过 X6 寄存器传递
- 57 行第八个参数通过 X7 寄存器传递
ldp reg, reg, [x29, offset]
汇编程序在 12 行到 18 行通过将 x29 寄存器指向参数在堆栈中的位置,然后通过寄存器加偏移的方式将参数的内容读出. 汇编源码第 19 行从堆栈中读出第 15 和第 16 个参数; 第 20 行从堆栈中读出第 17 和第 18 个参数; 第 21 行从堆栈中读出第 19 和第 20 个参数; 第 22 行从堆栈中读出第 9 和第 10 个参数; 第 23 行从堆栈中读出第 11 和第 12 个参数; 第 24 行从堆栈中读出第 13 和第 14 个参数. 接着在 BiscuitOS 上运行并获得内核转储文件:
cd BiscuitOS/output/linux-5.0-aarch/package/BiscuitOS-crash-register-with-func-argument-default
make
make install
make pack
make run
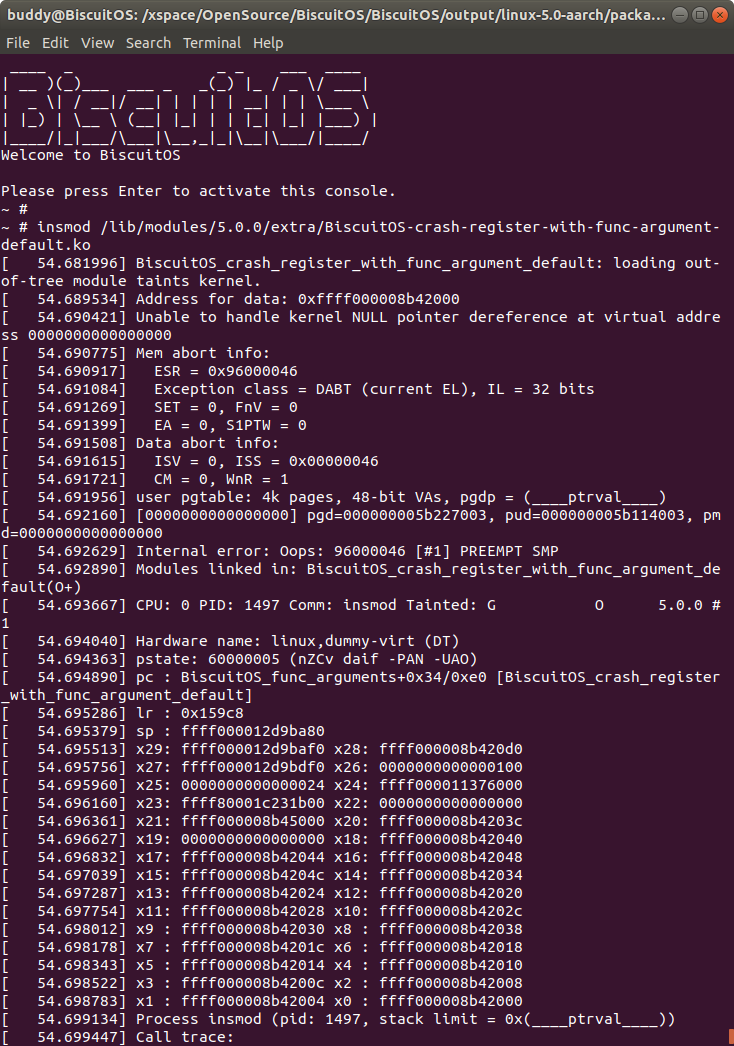
当在 BiscuitOS 中加载模块 BiscuitOS-crash-register-with-func-argument-default.ko,由于代码中对空指针的引用,此时内核触发 panic,此时内核打印出内核转储时寄存器的信息,从运行可知 data 数组的地址为 0xffff000008b42000, 那么寄存器与数组的关系:
- X0: 0xffff000008b42000 DATA[0]: 0xffff000008b42000
- X1: 0xffff000008b42004 DATA[1]: 0xffff000008b42004
- X2: 0xffff000008b42008 DATA[1]: 0xffff000008b42008
- X3: 0xffff000008b4200c DATA[1]: 0xffff000008b4200c
- X4: 0xffff000008b42010 DATA[1]: 0xffff000008b42010
- X5: 0xffff000008b42014 DATA[1]: 0xffff000008b42014
- X6: 0xffff000008b42018 DATA[1]: 0xffff000008b42018
- X7: 0xffff000008b4201c DATA[1]: 0xffff000008b4201c
寄存器的值与分析一致,实践符合预期.
ARM 架构
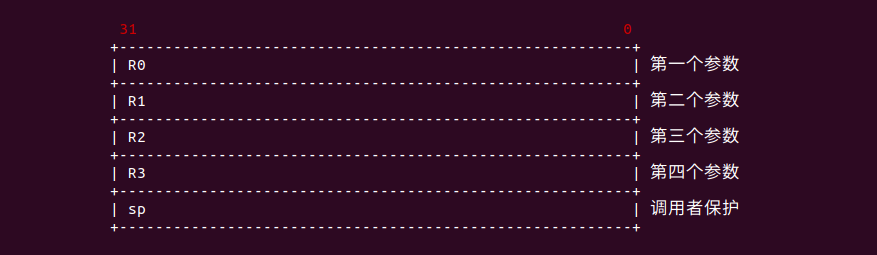
在 ARM32 架构中,使用 R0-R3 寄存器传递参数,第一个参数通过 R0 寄存器传递,第二个参数通过 R1 寄存器传递,以此类推. 返回值存储在 R0 寄存器中.
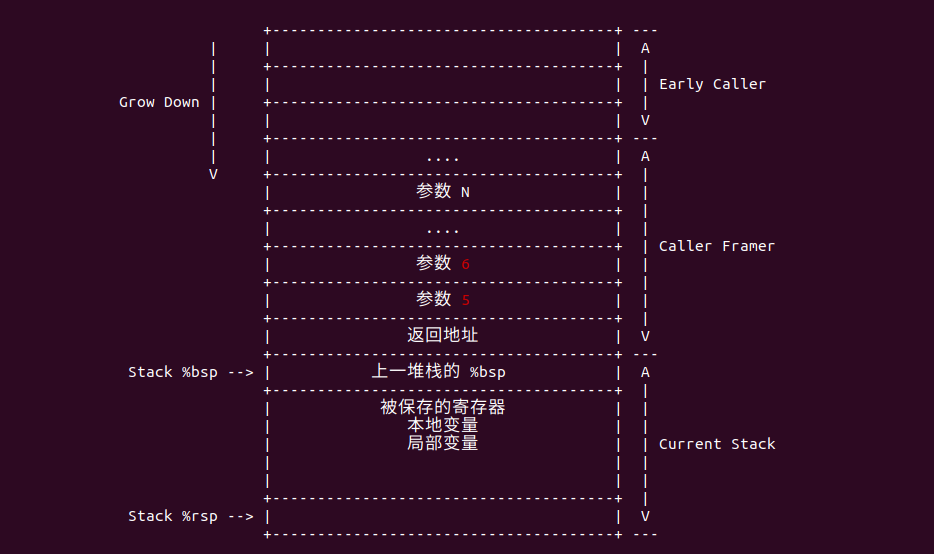
当函数参数的数量超过 4 个之后,那么多余的参数从右到左依次入栈,被调用者平衡堆栈.接下来通过一个实例来实践整个过程,BiscuitOS 已经支持该实例实践,其在 BiscuitOS 中的部署如下:
cd BiscuitOS
make linux-5.0-arm32_defconfig
make menuconfig
[*] Package --->
[*] CRASH and BUG Example --->
[*] Example: Function arguments --->
BiscuitOS/output/linux-5.0-arm32/package/BiscuitOS-crash-register-with-func-argument-default
BiscuitOS-crash-register-with-func-argument-default Source Code
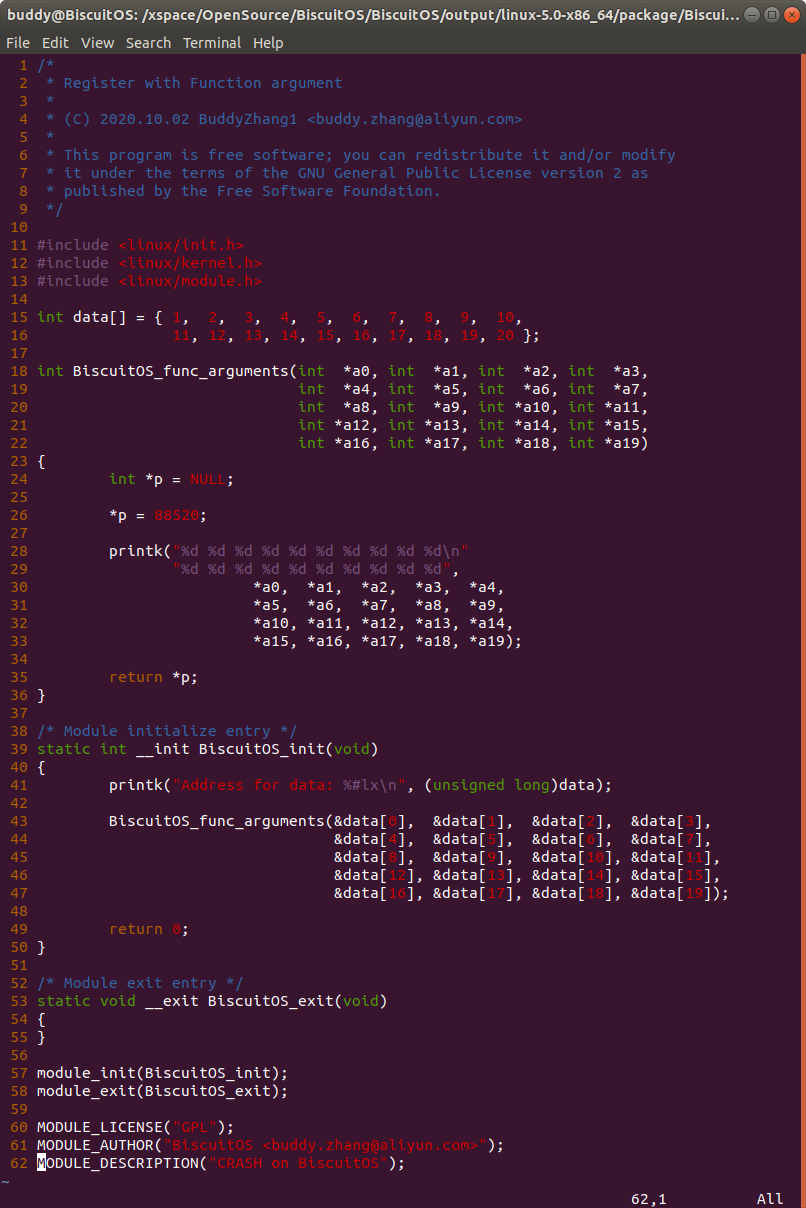
实践案例为一个内核模块,在实践案例中定义了一个函数 BiscuitOS_func_arguments(), 其包含了 20 个参数,并在调用该函数时会触发内核转储,因此可以通过汇编和内核转储信息查看函数参数传递过程,首先使用如下命令获得汇编文件:
cd BiscuitOS/output/linux-5.0-arm32/package/BiscuitOS-crash-register-with-func-argument-default
make
vi BiscuitOS-crash-register-with-func-argument-default/main.s
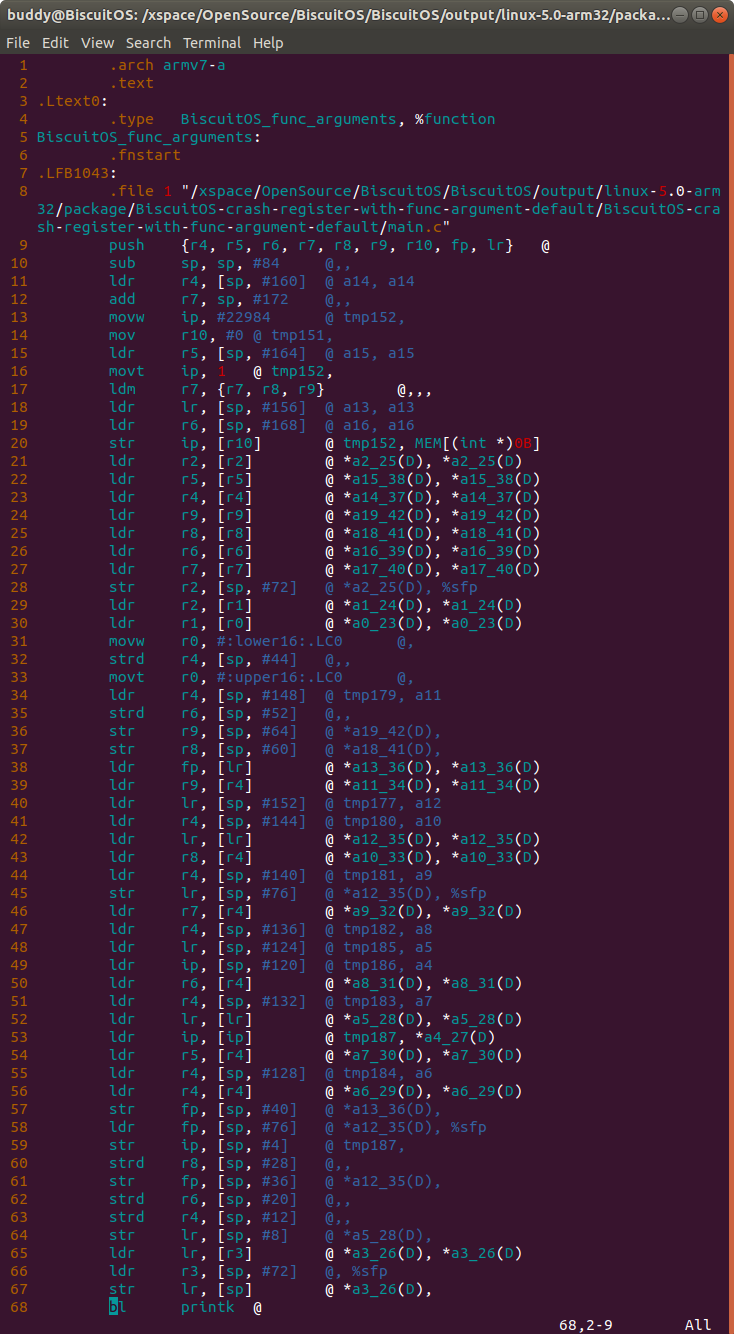
- 30 行第一个参数通过 R0 寄存器传递
- 29 行第二个参数通过 R1 寄存器传递
- 28 行第三个参数通过 R3 寄存器传递
- 65 行第四个参数通过 R4 寄存器传递
lsr reg, [sp, #offset]
汇编程序通过在堆栈加偏移的方式将参数的内容读出. 汇编源码第 36 行从堆栈中读出第 20 个参数; 第 58 行从堆栈中读出第 13 个参数, 以此类推. 接着在 BiscuitOS 上运行并获得内核转储文件:
cd BiscuitOS/output/linux-5.0-arm32/package/BiscuitOS-crash-register-with-func-argument-default
make
make install
make pack
make run
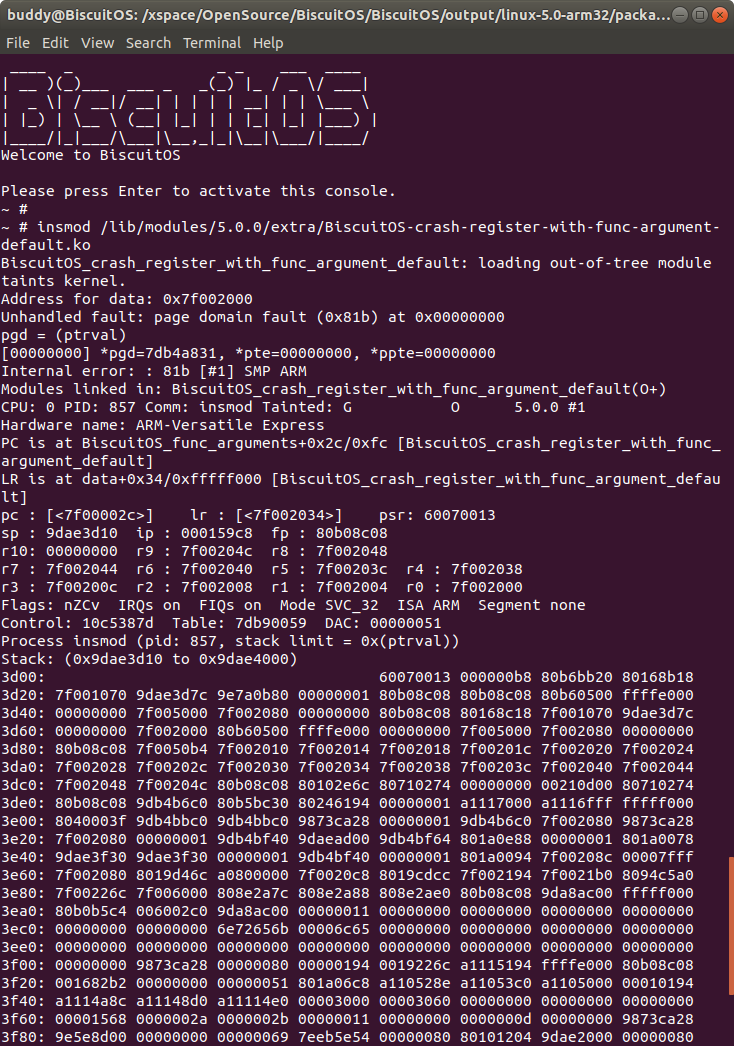
当在 BiscuitOS 中加载模块 BiscuitOS-crash-register-with-func-argument-default.ko,由于代码中对空指针的引用,此时内核触发 panic,此时内核打印出内核转储时寄存器的信息,从运行可知 data 数组的地址为 0xffff000008b42000, 那么寄存器与数组的关系:
- R0: 0x7f002000 DATA[0]: 0x7f002000
- R1: 0x7f002004 DATA[1]: 0x7f002004
- R2: 0x7f002008 DATA[2]: 0x7f002008
- R3: 0x7f00200c DATA[3]: 0x7f00200c
从上图可以看出堆栈从 “0x9dae3d10” 到 “0x9dae4000” 的内容,那么第五个参数的在堆栈中的地址是 “0x9dae3d88”, 具体对应关系如下, 实践结果符合预期:
- Stack 0x9dae3d88: 0x7f002010 DATA[04]: 0x7f002010
- Stack 0x9dae3d8c: 0x7f002014 DATA[05]: 0x7f002014
- Stack 0x9dae3d90: 0x7f002018 DATA[06]: 0x7f002018
- Stack 0x9dae3d94: 0x7f00201c DATA[07]: 0x7f00201c
- Stack 0x9dae3d98: 0x7f002020 DATA[08]: 0x7f002020
- Stack 0x9dae3d9c: 0x7f002024 DATA[09]: 0x7f002024
- Stack 0x9dae3da0: 0x7f002028 DATA[10]: 0x7f002028
- Stack 0x9dae3da4: 0x7f00202c DATA[11]: 0x7f00202c
- Stack 0x9dae3da8: 0x7f002030 DATA[12]: 0x7f002030
- Stack 0x9dae3dac: 0x7f002034 DATA[13]: 0x7f002034
- Stack 0x9dae3db0: 0x7f002038 DATA[14]: 0x7f002038
- Stack 0x9dae3db4: 0x7f00203c DATA[15]: 0x7f00203c
- Stack 0x9dae3db8: 0x7f002040 DATA[16]: 0x7f002040
- Stack 0x9dae3dbc: 0x7f002044 DATA[17]: 0x7f002044
- Stack 0x9dae3dc0: 0x7f002048 DATA[18]: 0x7f002048
- Stack 0x9dae3dc4: 0x7f00204c DATA[19]: 0x7f00204c
Crash 报告信息分析
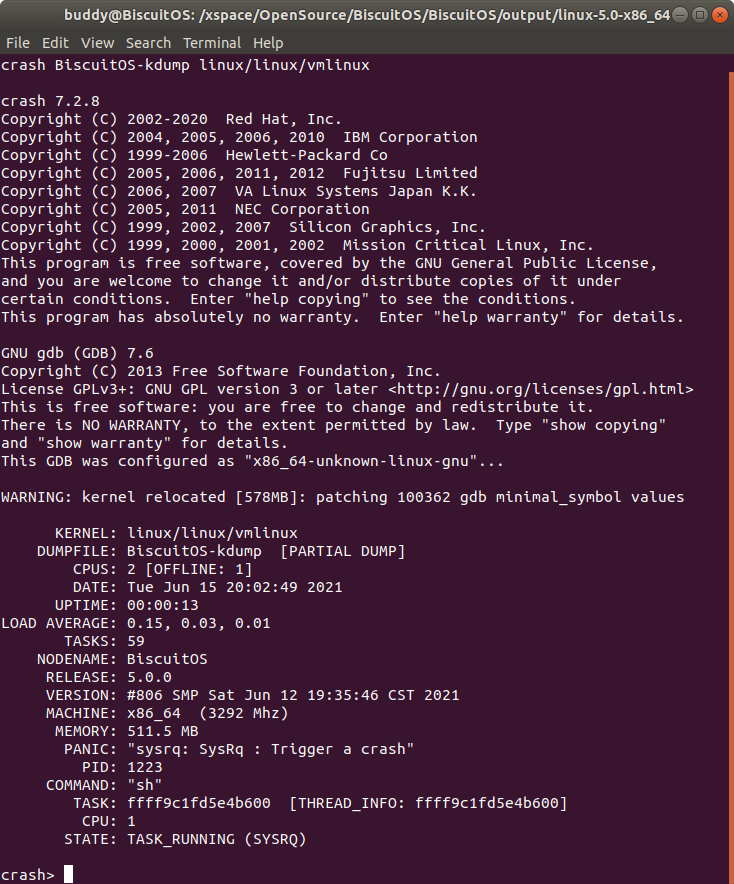
当使用 CRASH 工具分析 VMCORE 的时候,CRASH 工具就会输出一些基本信息,例如所分析内核版本的信息等,那么这些基本信息具体含义如何? 以上图为例进行逐一分析:
- KERNEL: 内核崩溃时运行的 Kernel ELF 文件.
- DUMPFILE: 内核转储文件.
- CPUS: 机器 CPU 的数量.
- DATE: 系统崩溃的时间.
- UPTIME: 系统启动到系统奔溃的时间.
- LOAD AVERAGE:
- TASKS: 系统崩溃时内存中的任务数.
- NODENAME: 崩溃系统的主机名.
- RELEASE: 崩溃内核的版本号.
- VERSION: 崩溃内核的版本号.
- MACHINE: CPU 架构和主频信息.
- MEMORY: 崩溃主机的物理内存.
- PANIC: 崩溃类型.
- PID: 导致内核崩溃的进程号.
- COMMAND: 导致内核崩溃的命令.
- TASK:
- CPU:
- STATE:
CRASH 输出的基本信息处理以上描述之外还包括: CRASH 版本信息以及 GDB 版本信息.
Crash 堆栈使用以及问题定位分析
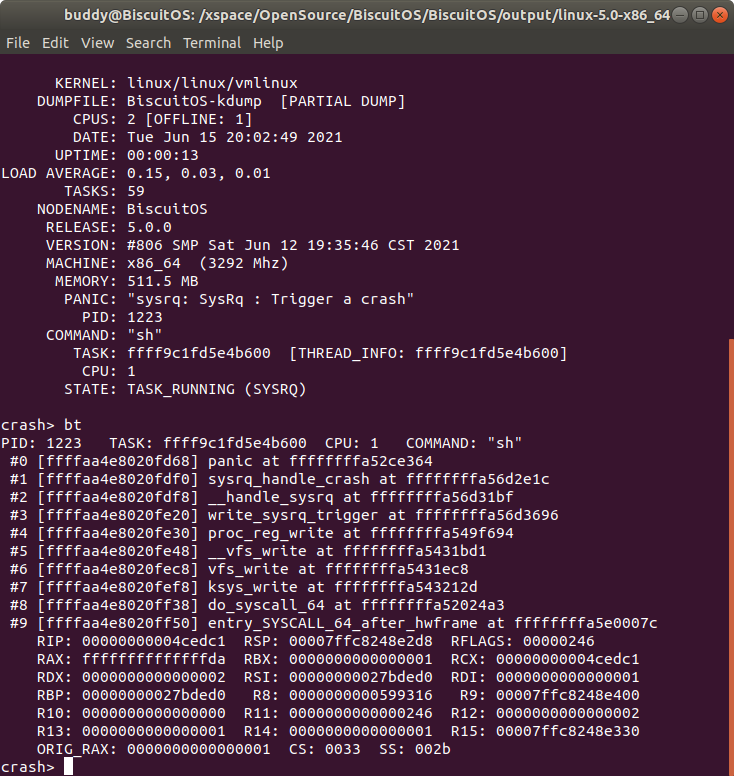
当使用 CRASH 分析内核转储文件时,堆栈的信息对问题排除起到了关键作用,CRASH 也提供了多个堆栈分析的命令,如下:
bt [-a|-g|-r|-t|-T|-l|-e|-E|-f|-F|-o|-O] [-R ref] [-I ip] [-S sp] [pid | task]
本节以手动触发 Panic 为例进行实践讲解。在 BiscuitOS 上通过输入 “echo c > /proc/sysrq-trigger” 来触发内核崩溃,并对转储文件为例进行分析:
CRASH 堆栈基本信息分析
当通过 CRASH 工具的 bt 命令分析内核转储文件的堆栈时,CRASH 将会输出奔溃时进程相关的信息、函数调用栈、以及寄存器快照,其中进程相关的信息描述如下:

- PID: 描述发生内核奔溃 CPU 上正在运行进程的 PID 信息.
- TASK: 描述发生内核奔溃 CPU 上运行进程的描述符的内存地址.
- CPU: 描述发生内核奔溃的 CPU ID.
- COMMAND: 描述发生内核奔溃 CPU 上正在运行的程序.
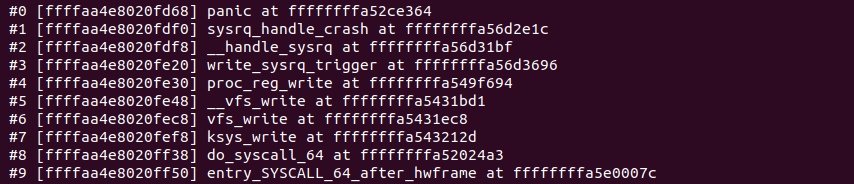
接下来是堆栈内容区域,最左边的 “#数字” 部分表示发生内核奔溃时函数调用栈,数字越小表示最新的调用,可以通过这个信息找到内核奔溃前最后调用函数的信息. 中间的地址部分描述被调用函数的地址在堆栈中的地址,中间函数表示调用栈中函数的名字,紧随名字之后的地址是函数在调用下一个函数的地址.
例如 “#5” 处调用 __vfs_write() 函数,该函数的地址在堆栈的地址是 0xffffaa4e8020fe48, 那么该函数此时在 0xffffffffa5431bd1 处调用了下一个函数 proc_reg_write.

最后一部分是内核发生崩溃时某个时刻的寄存器信息,例如上图当发生内核崩溃时内核调用了 entry_SYSCALL_64_after_hwframe() 函数时的寄存器快照。
该快照根据不同架构打印不同寄存器信息, 在分析问题时结合特定架构寄存器约定信息,对问题的定位起到了不可忽视的作用. 不同架构的寄存器约定可以参考上一节。
进程的内核堆栈
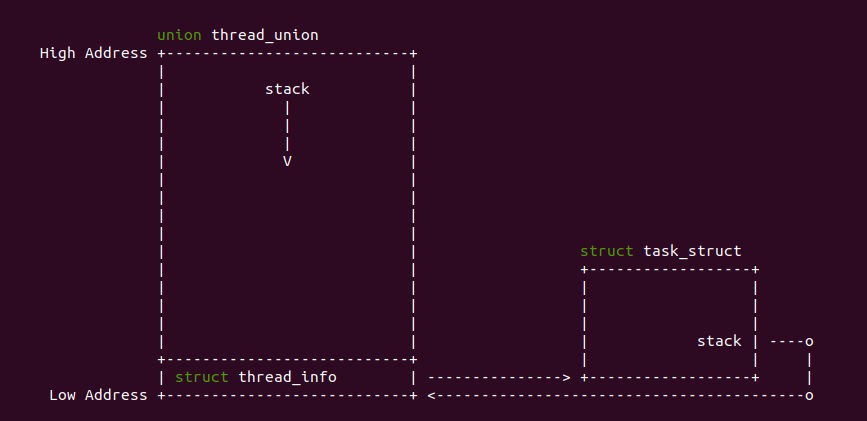
当用户空间程序通过执行系统调用进入内核态时,进程在内核态运行需要自己的堆栈,此时由于是内核态就不能使用进程用户态的堆栈,而是使用进程内核空间的栈,这个栈就是进程的内核栈.
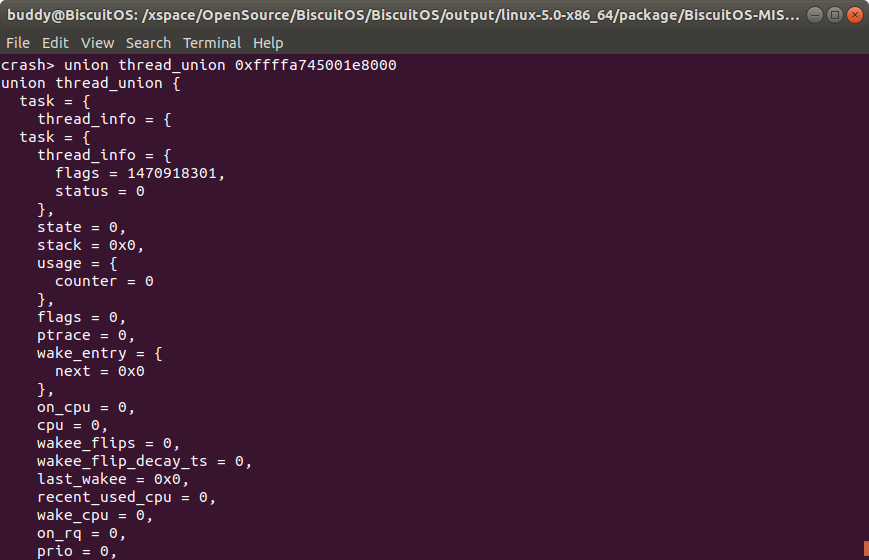
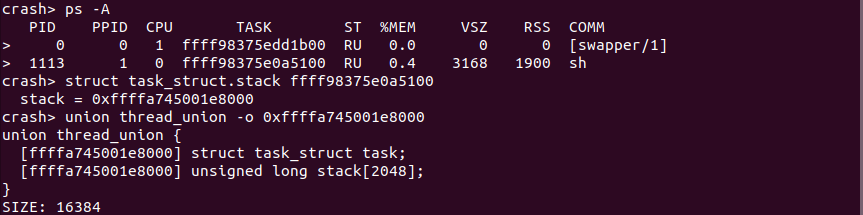
在不同的架构中内核态堆栈可能存在细微差距,当基本如上图所示。Linux 使用 struct task_struct 描述一个进程,其成员 stack 指向进程内核栈地址。进程的内核堆栈使用 union thread_union 进行描述:
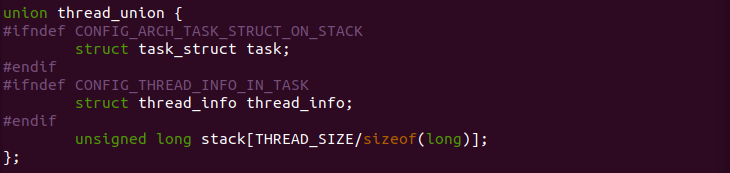
union thread_union 描述一个进程内核堆栈时,采用联合体的方式,将 struct thread_info 和 stack[] 数组进行联合,那么就会出现 stack[] 数组表示进程的内核堆栈,而 struct thread_info 位于堆栈的最顶部. 由于 struct thread_info 的定义与架构有关:
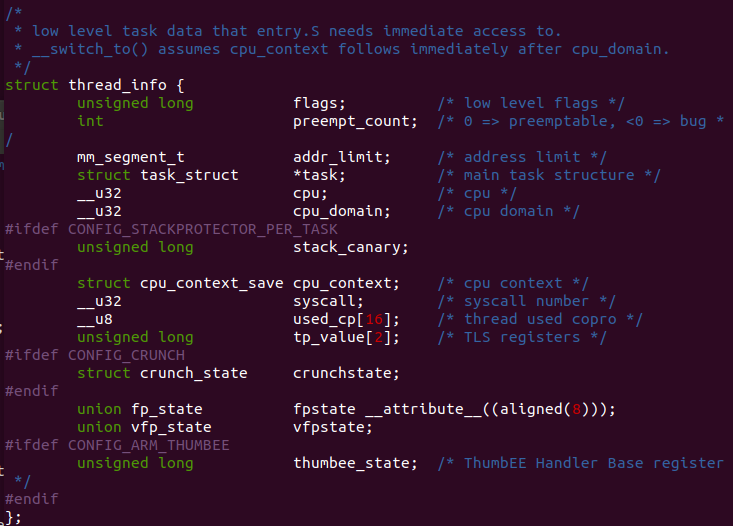
例如在 ARM 架构中 struct thread_info 的定义如上,其成员包含了一个指向进程描述符的成员 task, 因此在 ARM 架构中当获得进程的内核态堆栈,间接就可以获得进程的 struct task_struct 数据结构.
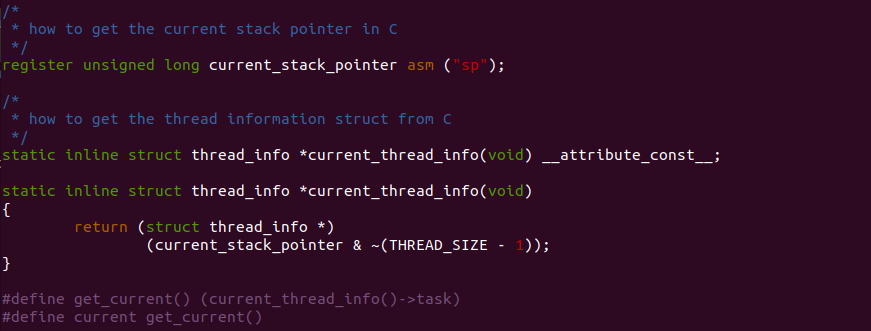
current 变量用于指向当前 CPU 上运行的 TASK,其实现基于进程内核态堆栈。内核定义了一个寄存器变量 current_stack_pointer, 该变量用于反应 SP 寄存器的值,SP 寄存器用于指向堆栈的栈顶位置.
内核定义了 current_thread_info() 函数,该函数就是获得 current_thread_pointer 按 THREAD_SIZE 对齐之后的值,该地址也就是 union thread_union stack[] 数组的起始地址,也是 struct thread_info,那么此时 current 的定义描述为 get_current() 函数,该函数通过获得 struct thread_info 的 task 成员,因此这个逻辑关系也就描述了内核堆栈与 CURRENT 之间的关系.
进程通过 alloc_thread_info() 函数分配内核态堆栈,并通过 free_thread_info() 函数释放内核态堆栈。堆栈的大小为 THREAD_SIZE, 在有的架构上是两个物理页,有的架构则是三个物理页. 当内核崩溃时发生内核核心转储,其打印的堆栈就是发生崩溃 CPU 上 TASK 的内核态堆栈.
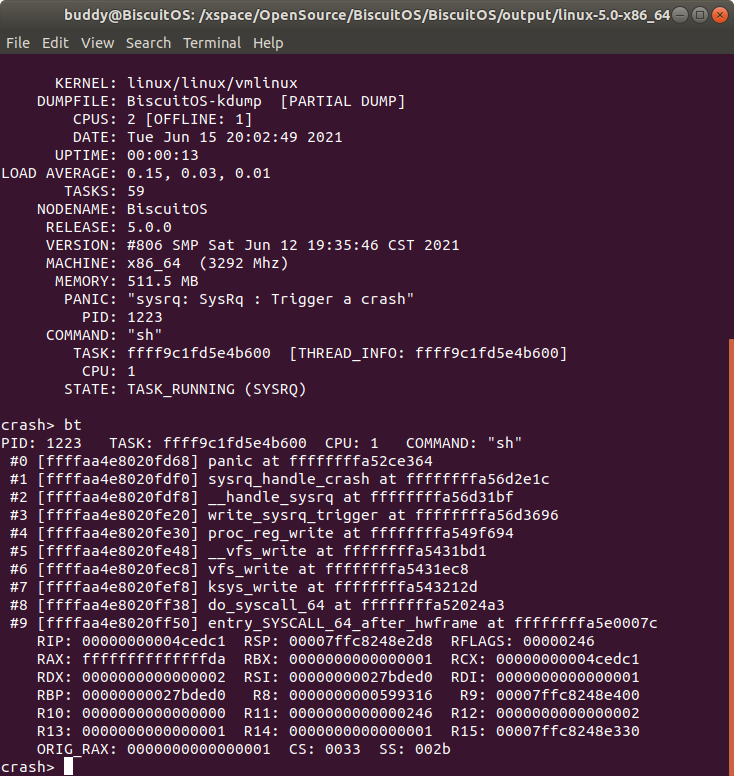
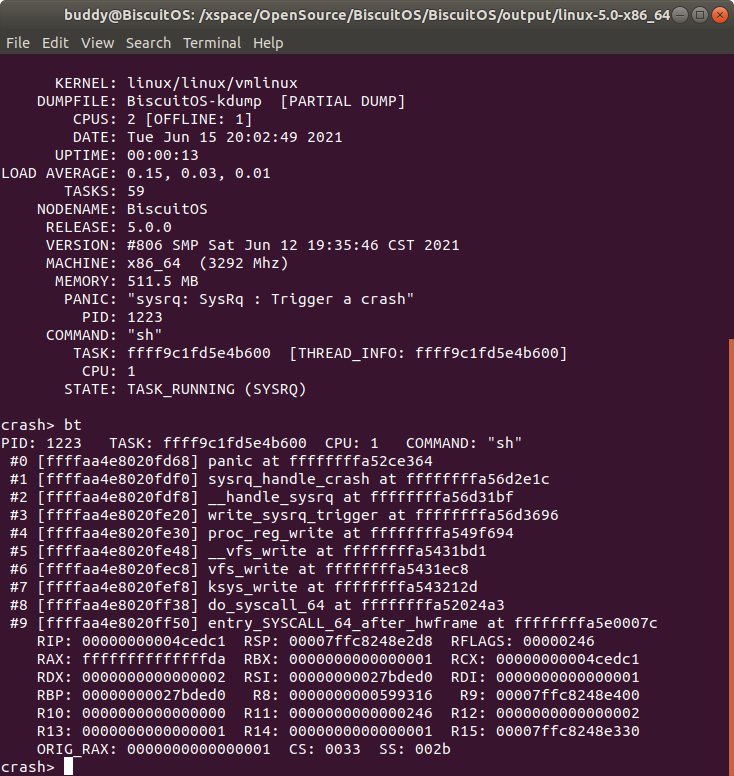
bt 打印内核奔溃 CPU 上运行 TASK 的堆栈
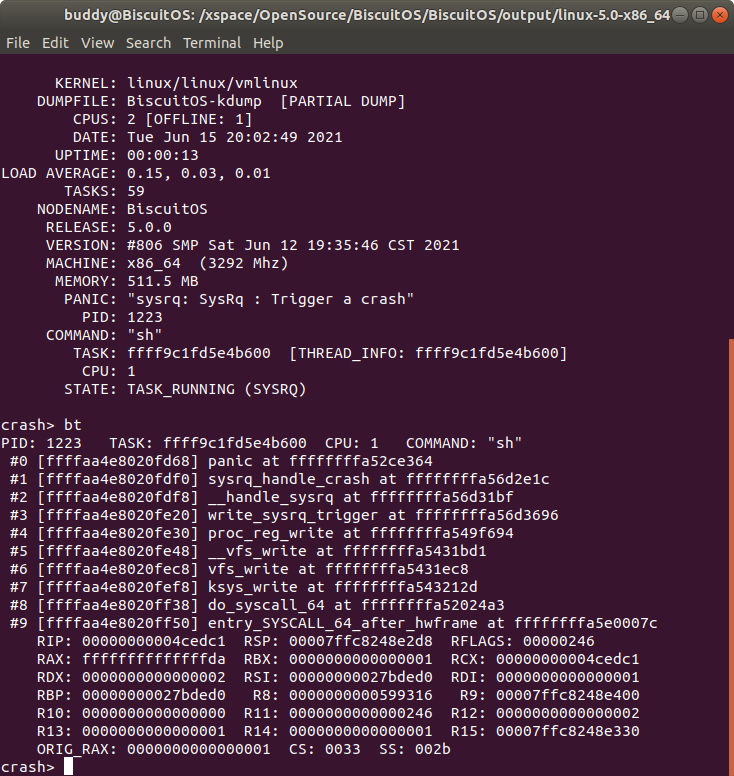
“bt” 命令可以打印引起内核崩溃 CPU 上正在运行 TASK 的堆栈,这里的 TASK 可能是用户进程,也可能是内核线程. 例如在上图的例子中,CPU 1 引发了内核崩溃,此时 CPU 上正在运行一个用户进程 “sh”.
bt -a 打印内核奔溃时所有 CPU 上 TASK 的堆栈
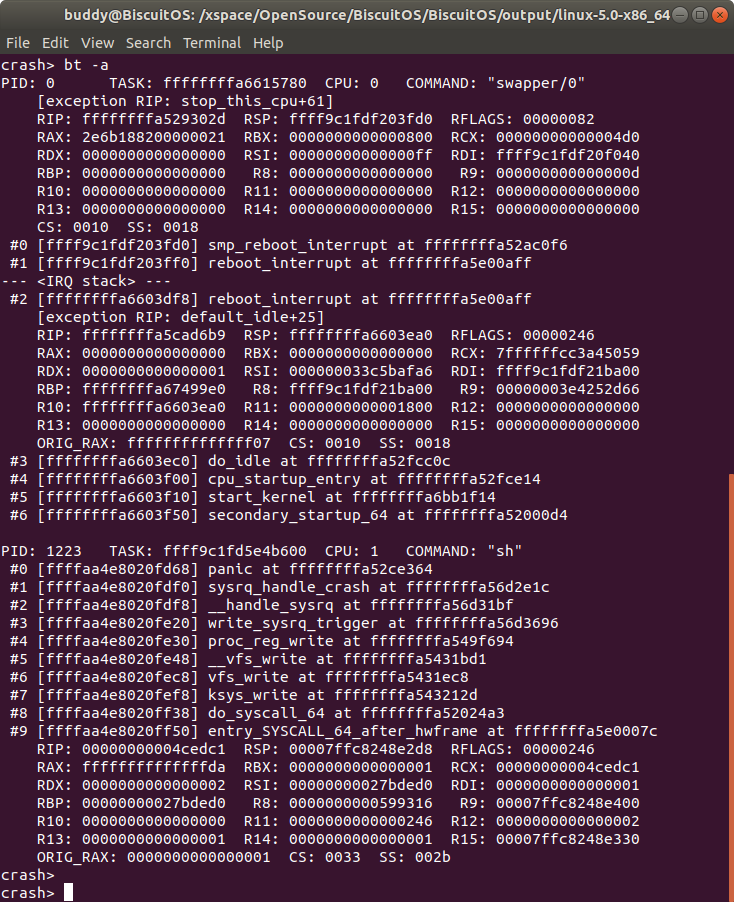
“bt -a” 是以 TASK 为单位显示内核崩溃时每个 CPU 上运行 TASK 的堆栈信息. 这里的 TASK 可以是用户空间进程,也可能是内核线程。
例如在上图系统包含了两 CPU,其中 CPU 0 上运行内核线程 “swapper/0”, 此时打印出 CPU 0 上的堆栈信息. CPU 1 上运行了用户空间程序 “sh”, 内核崩溃发生在该 CPU 上。
bt -r 打印内核奔溃时所有 TASK 的堆栈
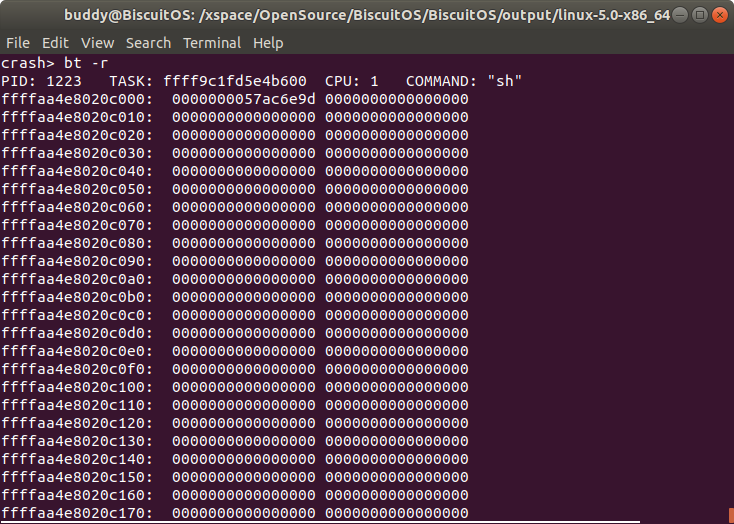
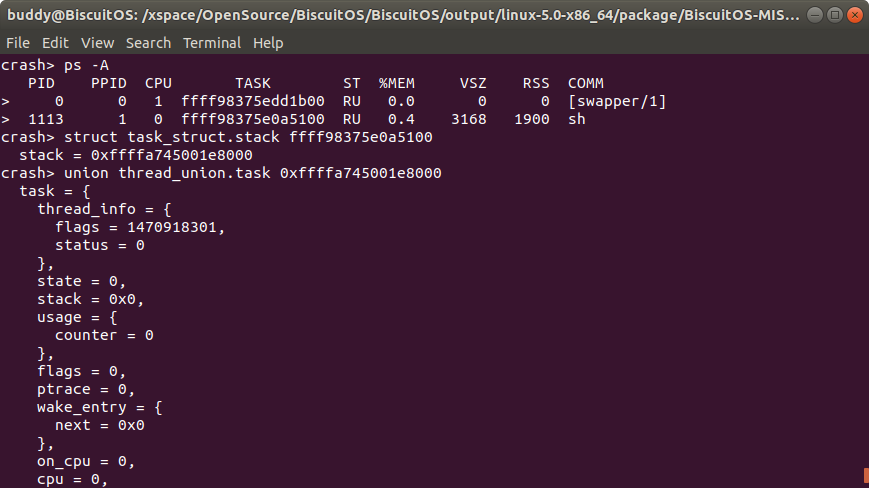
打印发生内核崩溃 CPU 上运行 TASK 内核堆栈的原始内核,即 DUMP 堆栈的内存。当在 CRASH 中使用 bt 的时候就可以获得发生内核崩溃 CPU 上正在运行 TASK 的信息,其中包含了 TASK 对应的 struct task_struct 地址,此时可以打印的 struct task_struct 的值,如下:
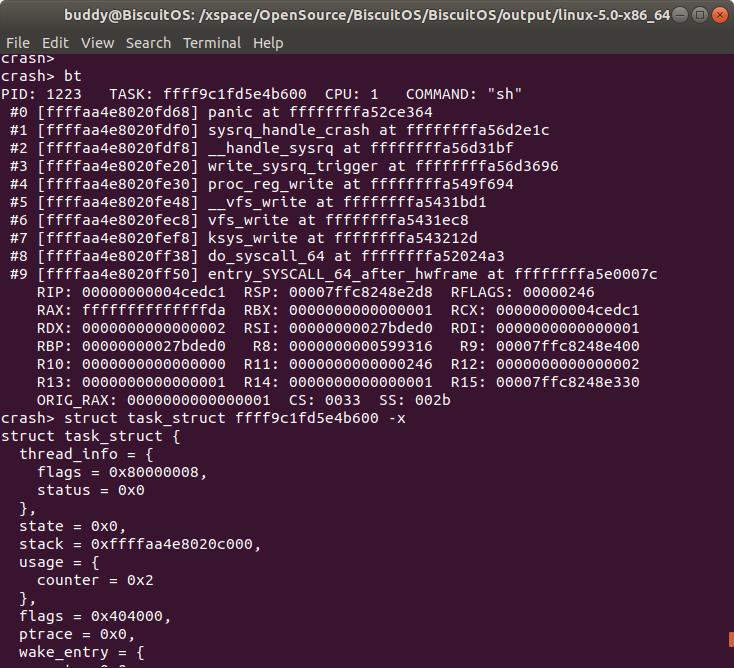
此时 TASK 的 struct task_struct 的地址是 0xffff9c1fd5e4b600, 那么在 CRASH 中打印 struct task_struct 的内容。
在 struct task_struct 的 task 成员指向了 TASK 的内核堆栈,在上图的例子中堆栈的地址是 0xffffaa4e8020c000, 该值正好是 “bt -r” 的地址, 因此可以通过 TASK 的堆栈内容进行问题的分析排除. 此时也可以看一下堆栈中对应内核 panic 处的堆栈内容:
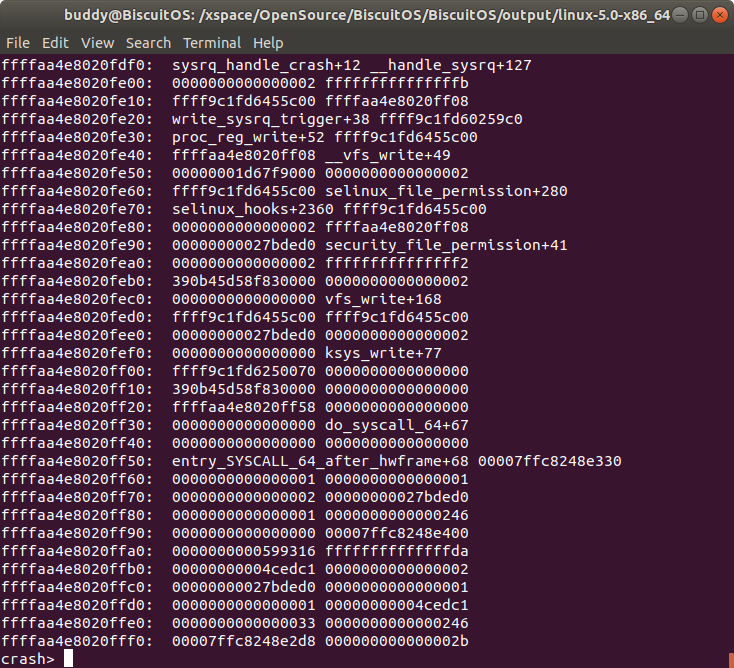
bt -t 打印内核崩溃 CPU 上 TASK 的函数调用栈
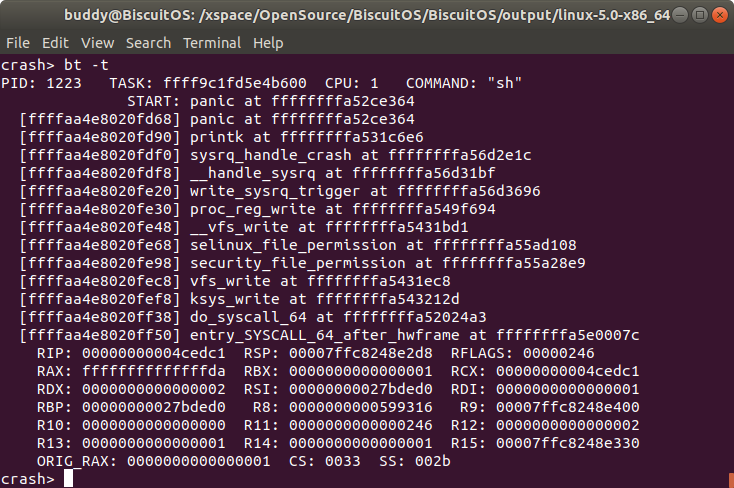
打印发生内核崩溃 CPU 上 TASK 的函数调用调用栈,该函数调用栈从发生内核奔溃的位置一直到堆栈的底部,相比与 “bt -T” 命令,”bt -t” 命令打印的函数调用栈信息更为直观有效.
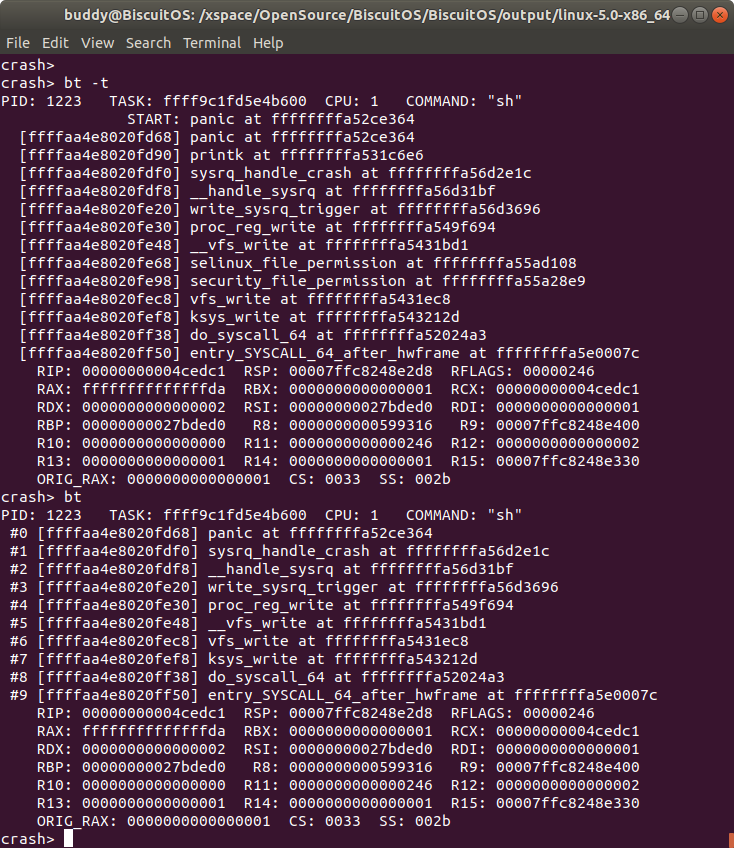
相比 “bt” 命令,”bt -t” 命令的函数调用栈的内容更加详细,并多了 START 信息描述内核最后 panic 的位置.
bt -T 打印内核崩溃 CPU 上 TASK 堆栈中所有的调用函数
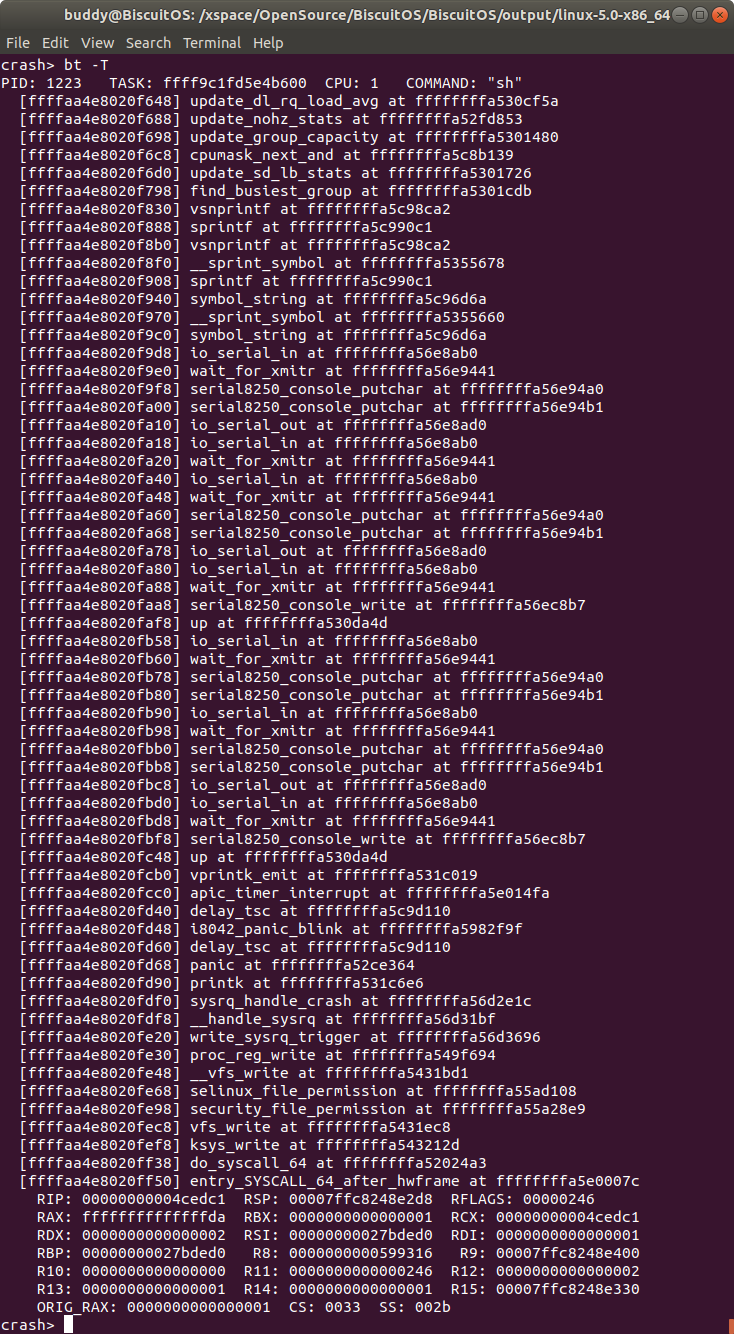
打印发生内核崩溃 CPU 上 TASK 内核堆栈中所有调用函数信息。该命令将 TASK 的 struct task_struct task 指向的内核堆栈 thread_info 到堆栈栈底之间所有的调用函数符号. 相对于 “bt -t” 只打印 TASK 内核堆栈发生崩溃到堆栈栈底的函数调用信息.
bt -l 打印内核崩溃 CPU 上 TASK 堆栈栈帧函数的文件及行号
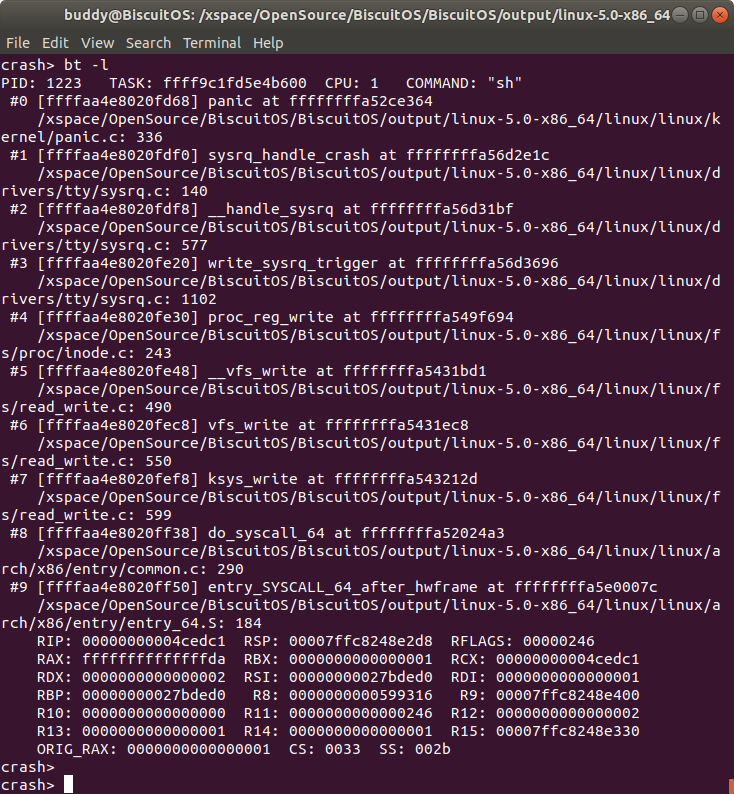
打印发生内核崩溃 CPU 上 TASK 的内核函数调用栈,并把每一个栈帧对应的函数,以及函数来自的源文件和行号信息都打印出来.
bt -e 打印内核崩溃 CPU 上 TASK 堆栈中可能异常的帧
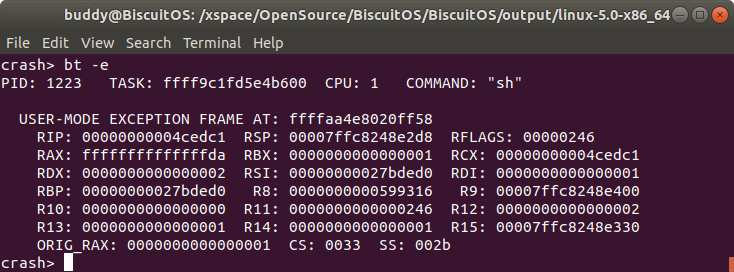
打印发生内核崩溃 CPU 上运行 TASK 的内核堆栈中可能发生异常的帧。如果是应用程序引发了 PANIC,那么可以检测到 USER-MODE EXCEPTION FRAME 的位置.
如果是内核线程引发的 PANIC,那么可以检测到 KERNEL-MODE EXCEPTION FRAME 的位置. 因此可以通过这个信息知道问题出在内核还是应用程序。
bt -E 打印所有 CPU 的中断堆栈
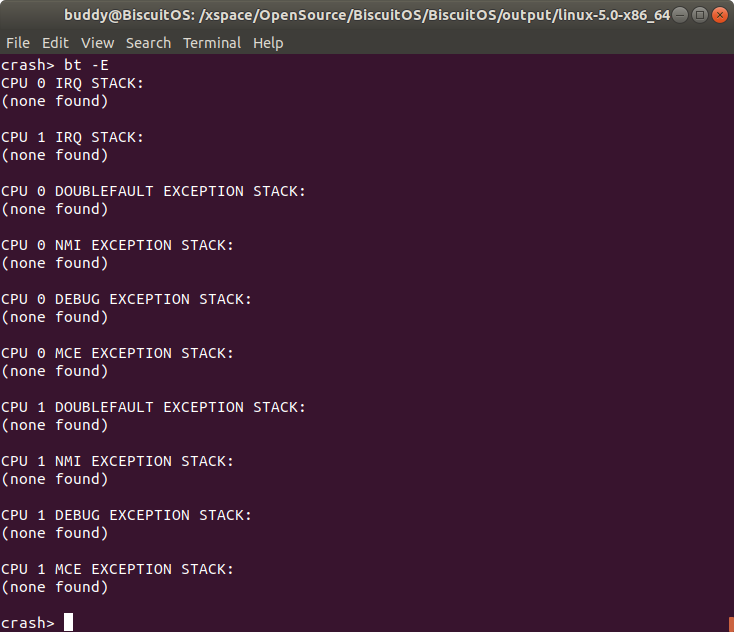
打印所有 CPU 的中断堆栈. 该信息包含了每个 CPU 的 IRQ 的堆栈、DOUBLEFAULT Exception 堆栈、NMI 堆栈、DEBUG 堆栈、以及 MCE 堆栈.
bt -f 打印内核崩溃 CPU 上 TASK 堆栈栈帧的内容
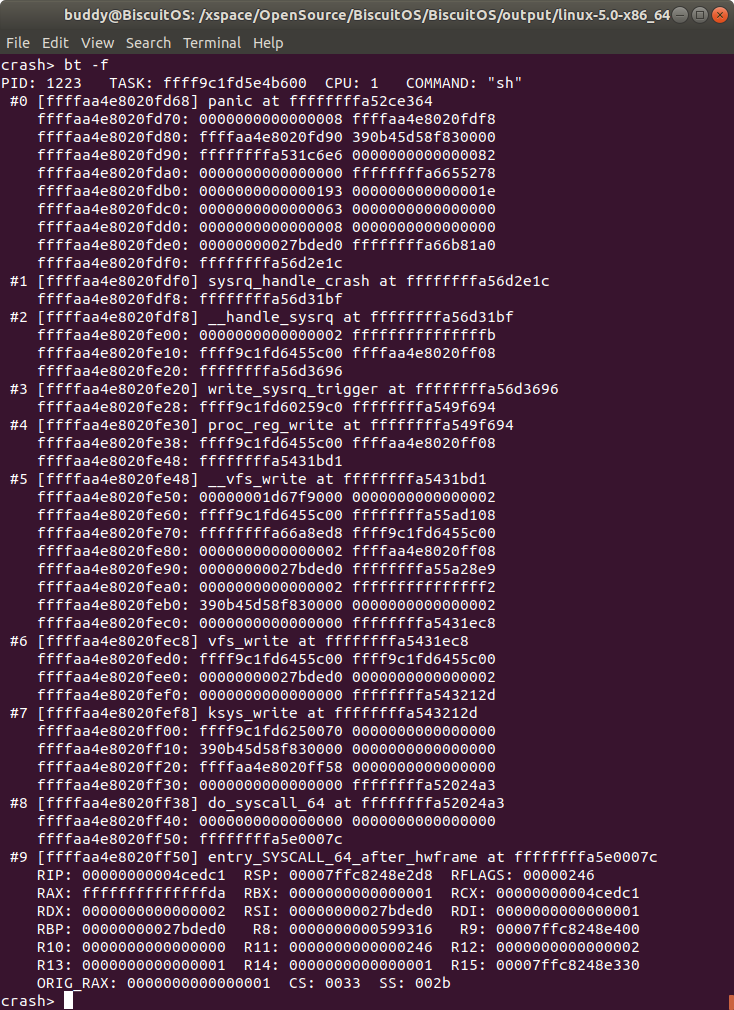
打印内核崩溃 CPU 上运行 TASK 的堆栈栈帧的内容,根据该信息并结合不同架构下函数参数传递规则,可以从栈帧中获得特定参数的地址,并进行参数的分析。
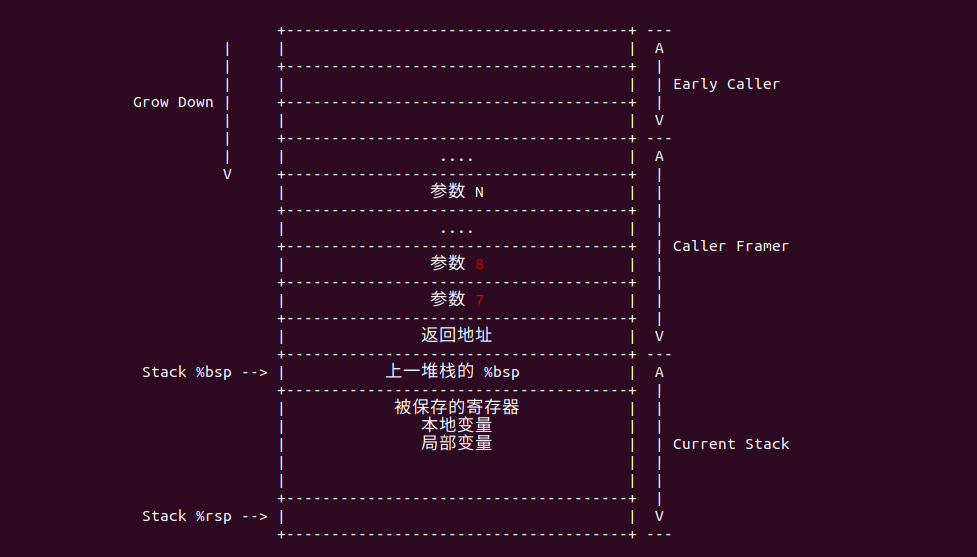
例如上图在 X86_64 架构中,函数参数超过 6 个之后就通过堆栈传递剩余的参数,因此可以通过栈帧来找到指定参数.
bt -F[F] 打印内核崩溃 CPU 上 TASK 栈帧中 SLAB CACHE 对象信息
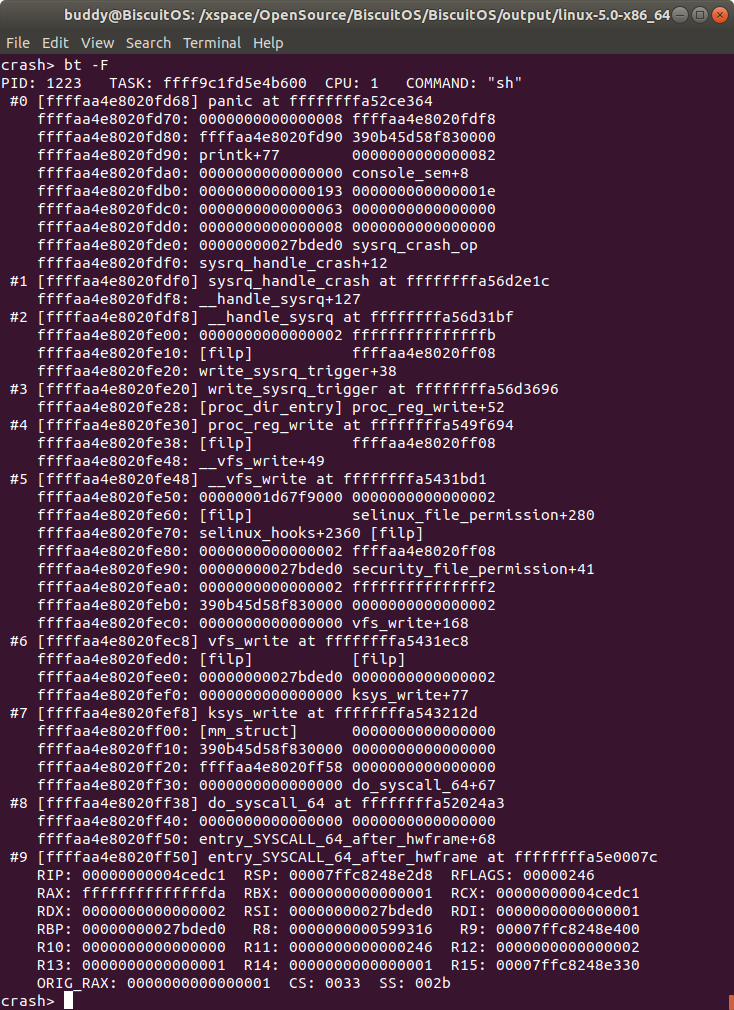
与 “bt -f” 类似,打印内核崩溃 CPU 上 TASK 堆栈栈帧的内容, 根据该信息并结合不同架构下函数参数的传递规则,可以从栈帧中获得特定参数的地址,并进行参数分析。
除此之外,如果栈帧的内容指向 SLAB cache 对象,那么会将堆栈的内容直接显示为 SLAB CACHE 的名字。
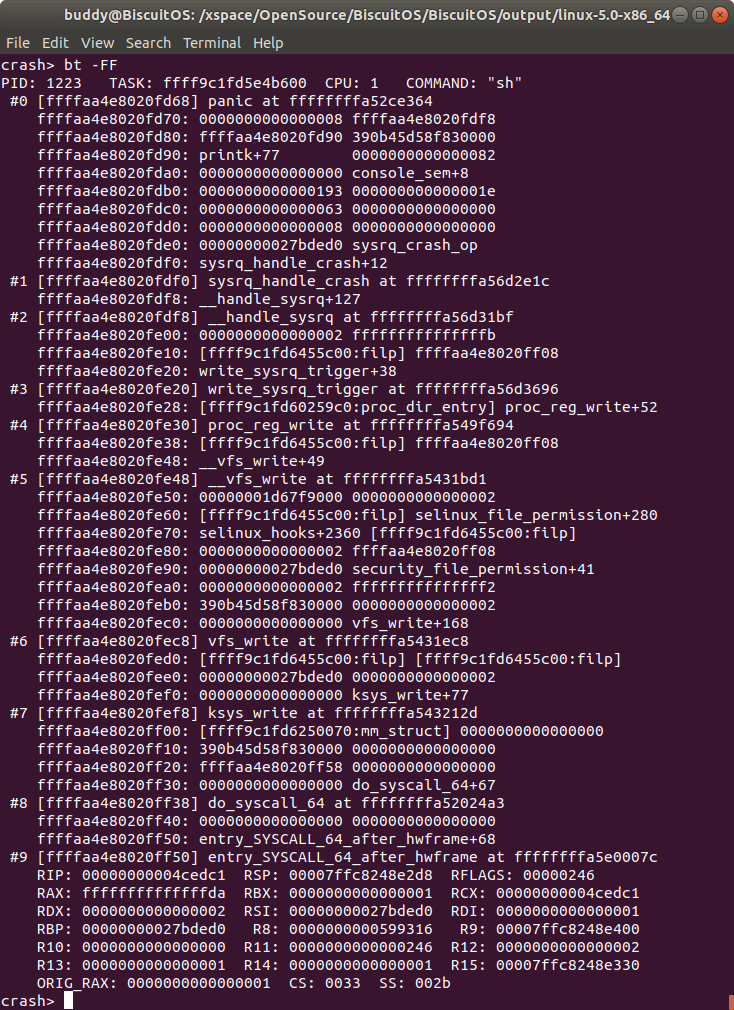
如果输入命令 “bt -FF”, 那么栈帧中的内容如果是指向 SLAB cache 对象的话,那么 CRASH 将会打印地址加 SLAB CACHE 对象的名字. 对比三个类似的命令打印栈帧的内容.
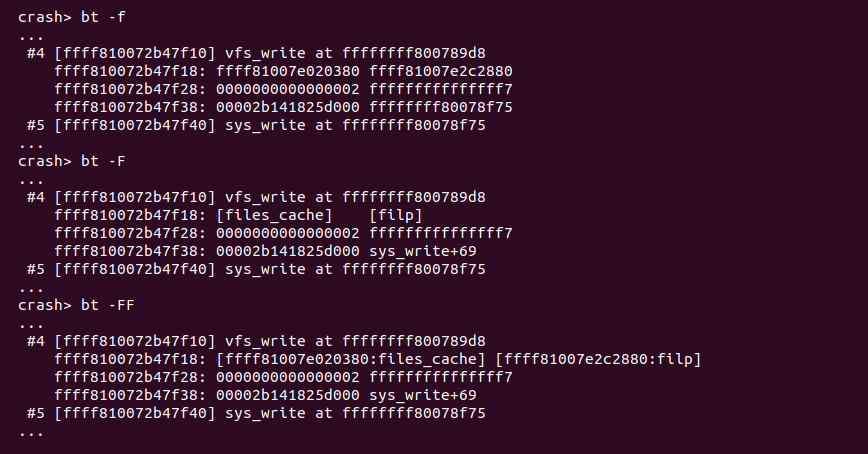
bt -o 以老式堆栈方式打印内核崩溃 CPU 上 TASK 的堆栈
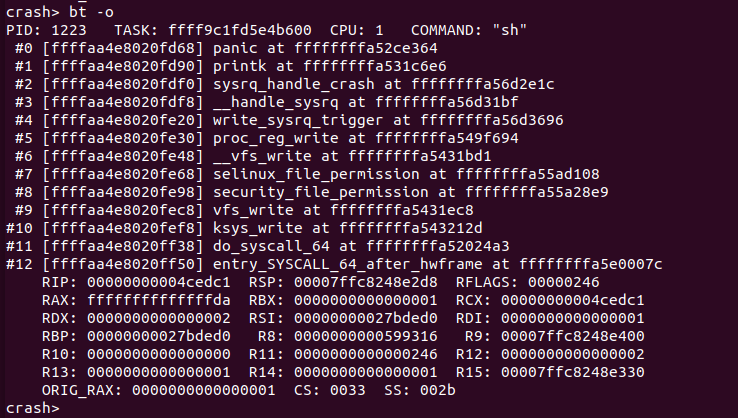
打印老式的堆栈,在有的架构下已经不支持。
在 ARM64 架构下,Linux 4.14 之后的内核不再支持该功能。在 X86 架构下,只有在内核编译时支持 “-fomit-frame_pointer” 才能支持该选项; 在 X86_64 架构下,使用该命令可能打印一个过时的堆栈信息.
bt -O 将 CRASH 堆栈打印模式设置为老式堆栈模式
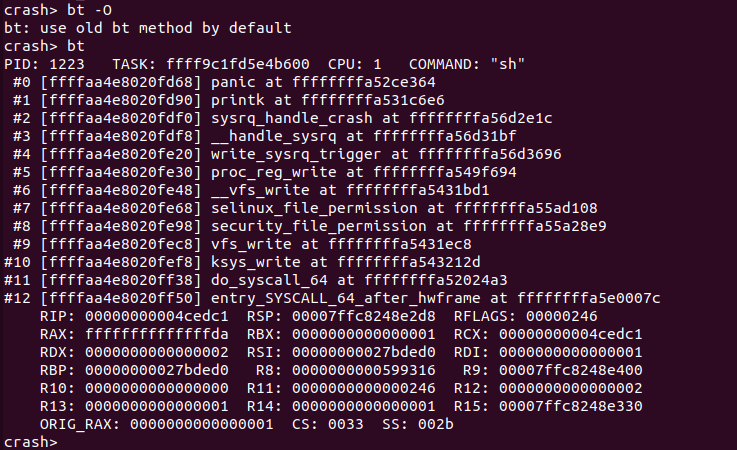
将堆栈的打印模式有可选模式设置为默认模式,后续的堆栈打印时都使用默认模式。
在 X86_64 架构中将堆栈打印模式设置为老版本模式; ARM64 架构则将堆栈打印模式设置为默认模式; X86 架构在内核编译时不带 “-fomit-frame_pointer” 时才能有效将堆栈打印模式设置为老版本模式.
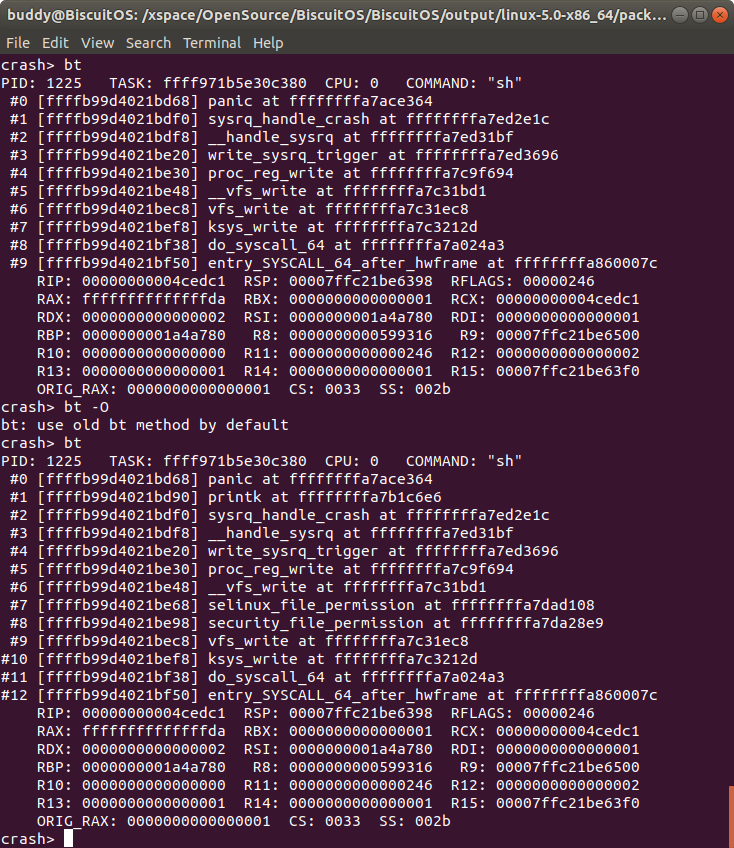
在 X86_64 架构下,两种模式对比发现旧版本堆栈中包含了更多函数调用信息.
bt [-R symbol] 显示包含 symbol 的堆栈信息

打印包含指定 symbol 的堆栈,该命令会在所有的堆栈中查找是否包含 BiscuitOS_hello,如果找到则打印堆栈,没有则不打印堆栈。例如上图中堆栈中包含了 vfs_write 而没有 BiscuitOS_hello, 那么只会打印包含了 vfs_write 的堆栈.
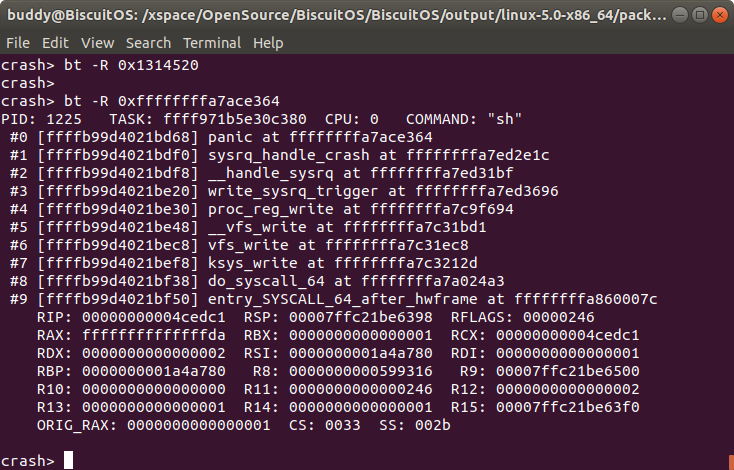
该命令同时页可以查找堆栈是否包含指定的地址或数值, 如果包含则打印对应的堆栈,反之不打印。
例如在上图中没有堆栈中包含 0x1314520,而在堆栈的 #0 中包含了 0xffffffffa7ace364, 因此打印堆栈。
综合来看该命令可以在堆栈中快速查找函数和内容.
bt [-I ip]
bt [-S sp] 从 SP 处开始打印内核崩溃 CPU 上 TASK 的堆栈
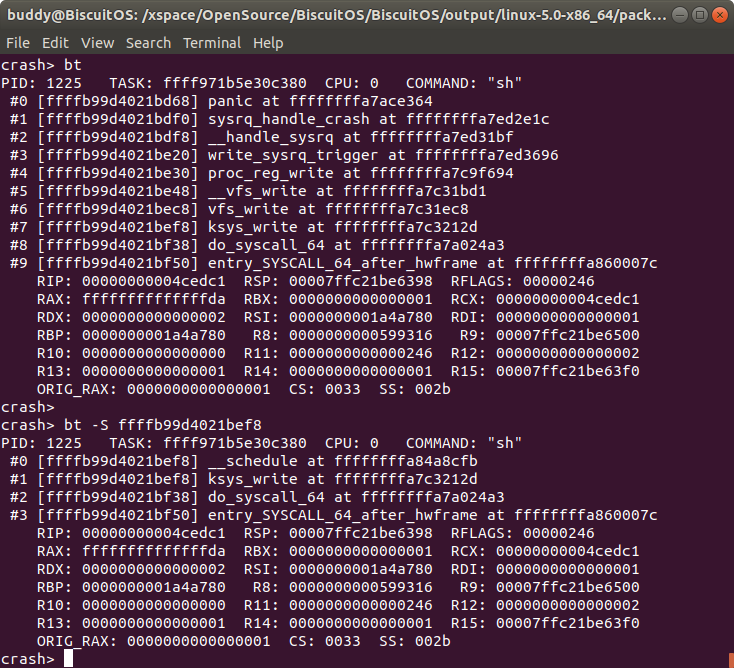
打印内核崩溃 CPU 上 TASK 堆栈,该堆栈从栈顶到 SP 之间的内容。
例如上图,原始的堆栈包含了 #0 到 #9,此时使用该命令将 SP 的值设置为 #8 的地址,即 0xffffb99d4021bf38, 那么此时只显示原始堆栈 #9 到 #7 的内容。因此可以使用该命令来查看堆栈片段.
bt pid 按 PID 打印 TASK 的堆栈
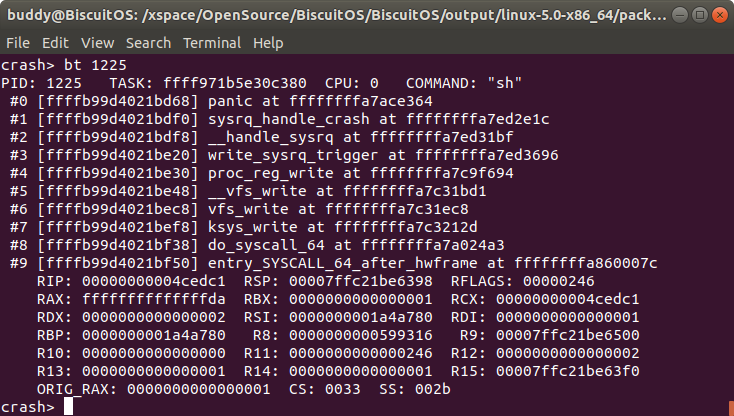
该命令用于按进程或内核线程的 PID 来打印其内核堆栈.
bt taskp 按 TASK 的 task_struct 十六进制值来打印堆栈
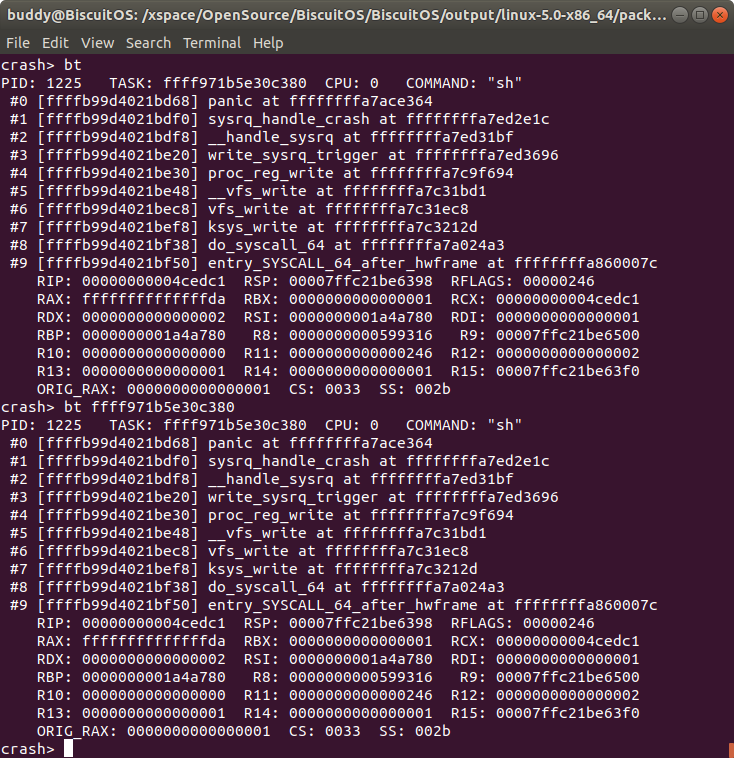
每个 TASK 都通过一个 struct task_struct 数据结构进行描述,可以使用该数据的十六进制值来打印对应的堆栈.
例如发生内核奔溃 CPU 上运行 TASK 的 struct task_struct 数据结构的地址是 0xffff971b5e30c380, 那么可以使用该地址来打印堆栈. 因此只要有 TASK struct task_struct 的地址就可以获得对应的堆栈信息.
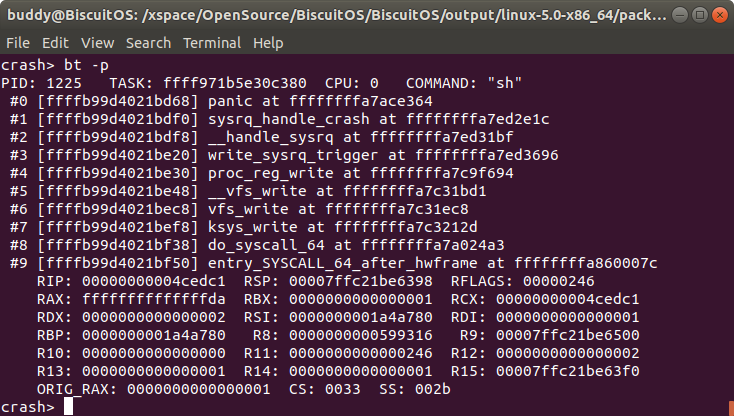
bt -p 只打印发生内核 PANIC CPU 上 TASK 的堆栈
“bt -a” 命令可以打印所有 CPU 上运行 TASK 的堆栈。而 “bt -p” 就只打印发生 PANIC CPU 上 TASK 的堆栈信息.
bt -c cpu 打印指定 CPU 上 TASK 的堆栈
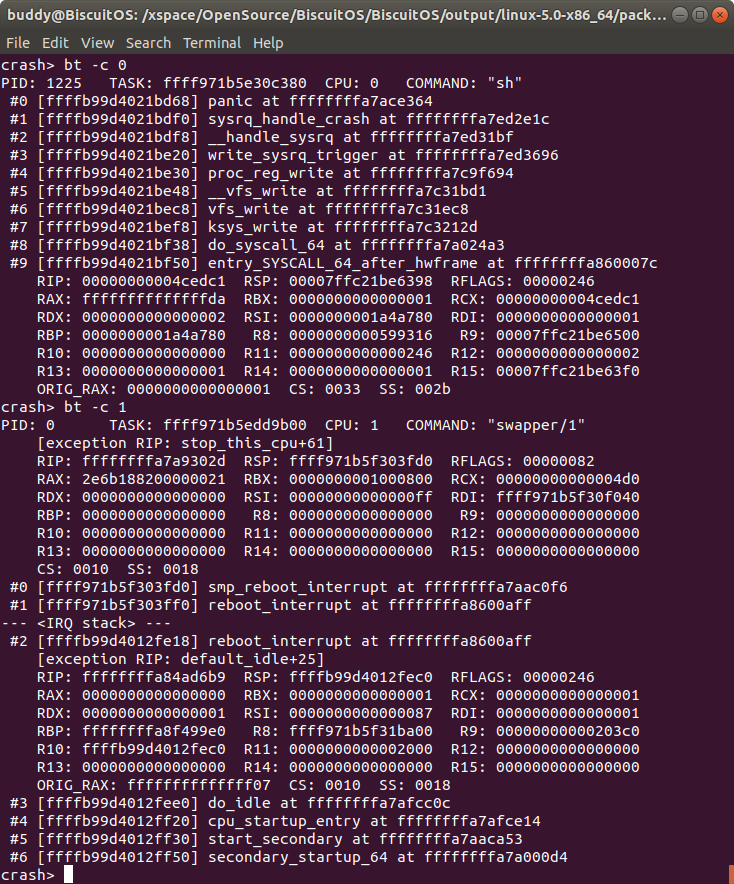
该命令可以打印指定 CPU 上 TASK 的堆栈信息,但不能打印未知 CPU 信息.
Crash 系统日志定位分析
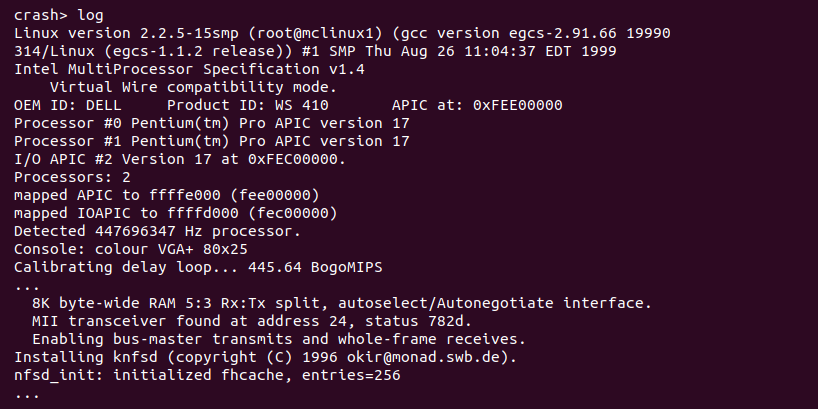
当使用 CRASH 分析内核转储文件时,可以通过 CRASH 工具打印处 system message buffer 中的内核日志,CRASH 支持的日志命令如下:
log [-tdma]
本节以手动触发 Panic 为例进行实践讲解。在 BiscuitOS 上通过输入 “echo c > /proc/sysrq-trigger” 来触发内核崩溃,并对转储文件为例进行分析:
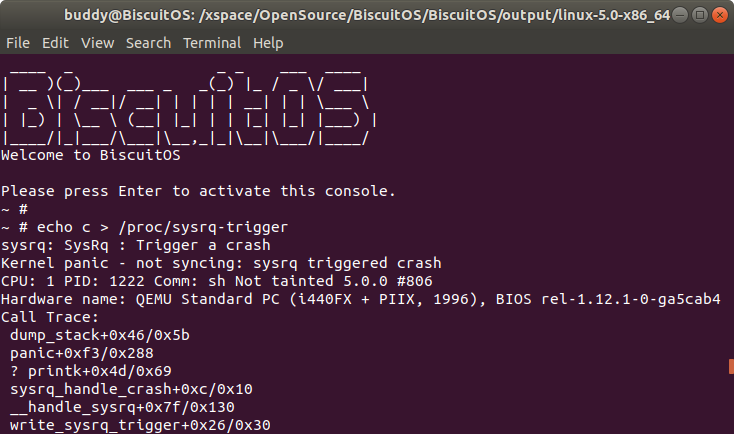
log 打印内核日志
该命令可以查看 system message buffer 中的内核日志,该日志包含了内核崩溃时的信息,可以通过该信息快速查看崩溃的原因。该命令与 dmesg 信息输出的一致。
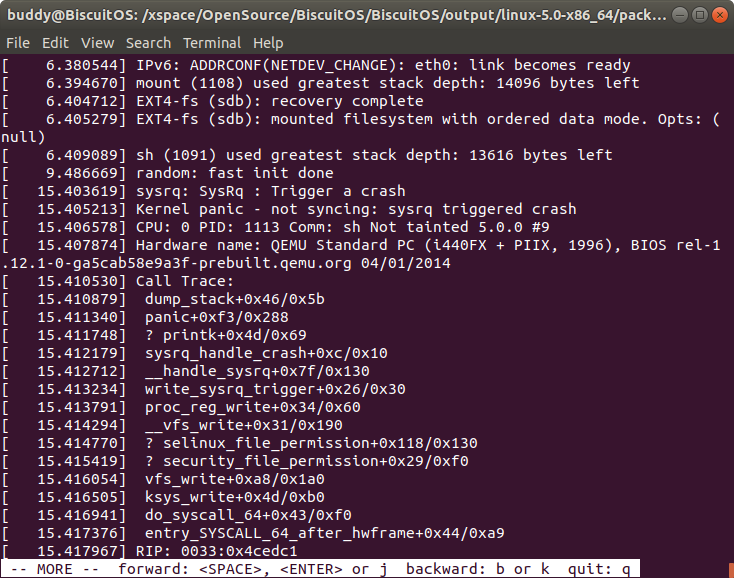
log -t 不包含时间片的模式打印内核日志
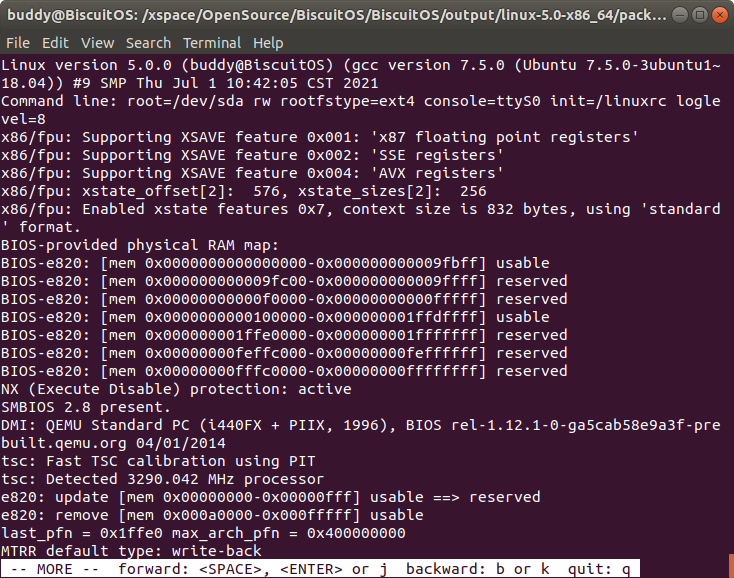
该命令可以在打印内核日志的时候将时间片信息去掉,上图为去掉之后的日志,下图为原始日志,这在某些场景下方面内核日志的查看.
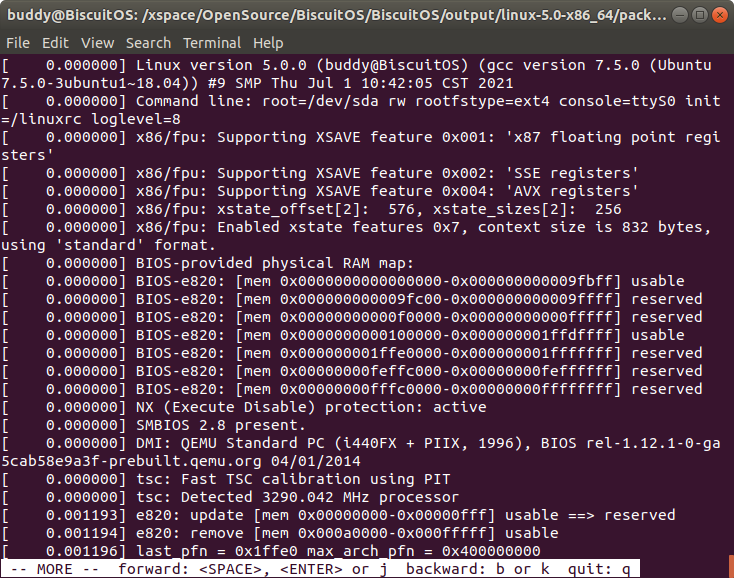
log -m 包含打印等级的模式打印内核日志
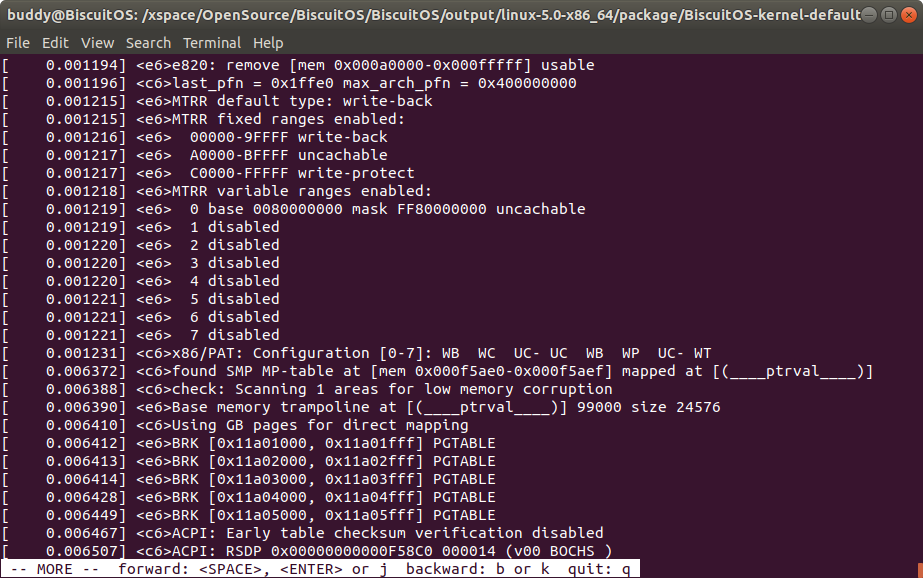
该命令可以将每条信息的打印等级信息打印出来。printk() 中对应关系如下:
KERN_EMERG <06>
KERN_ALERT <26>
KERN_CRIT <46>
KERN_ERR <66>
KERN_WARNING <86>
KERN_NOTICE <a6>
KERN_INFO <c6>
KERN_DEBUG <e6>
KERN_DEFAULT <86>
KERN_CONT <8a>
log -d 对使用 dev_printk() 打印 SUBSYSTEM/DEVICE 信息
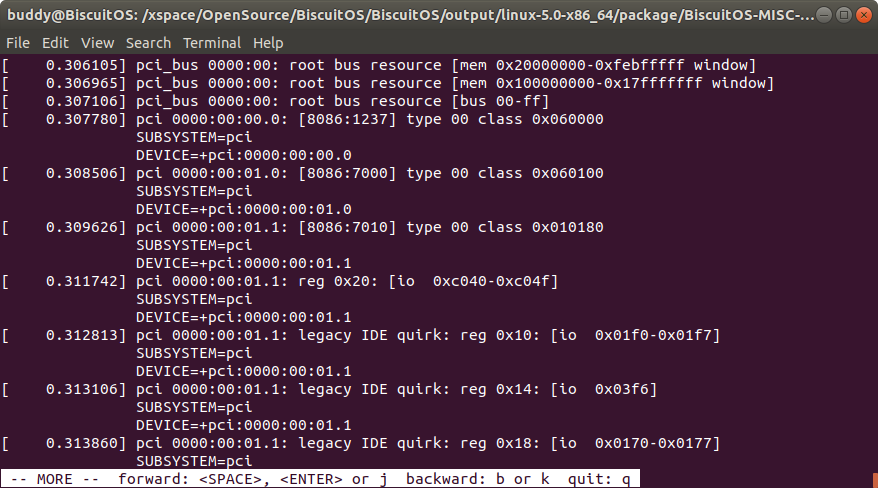
该命令对使用 dev_printk() 打印内核 log 添加了 SUBSYSTEM 和 DEVICE 信息,例如上图,SUBSYSTEM 指明了 log 来自哪个子系统,DEVICE 信息则指明 log 来自哪个设备. 支持该功能的函数包含:
dev_emerg(dev, fmt, ##arg)
dev_alert(dev, fmt, ##arg)
dev_crit(dev, fmt, ##arg)
dev_err(dev, fmt, ##arg)
dev_warn(dev, fmt, ##arg)
dev_notice(dev, fmt, ##arg)
dev_info(&(dev, fmt, ##arg)
dev_dbg(dev, fmt, ##arg)
log -a 打印 内核 audit buffer 中的 audit 日志

该命令可以输出 Audit buffer 中的 Audit logs 信息。
Crash ps 进程信息定位分析
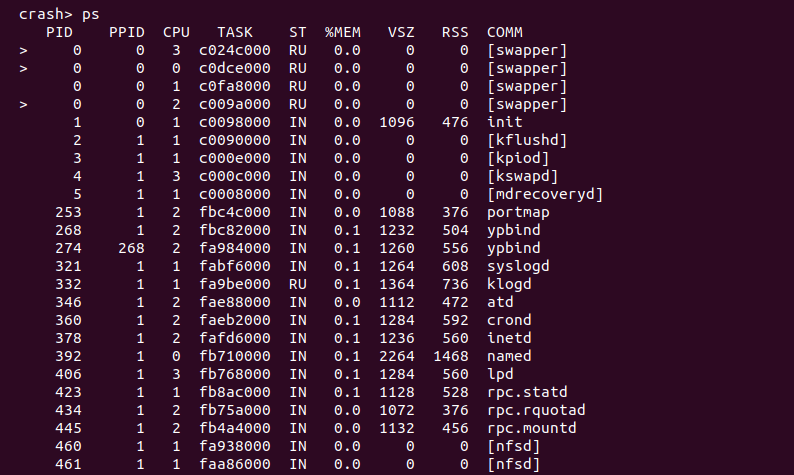
该命令用于打印内核崩溃时进程的状态信息,可以使用该命令选择指定进程或所有进程的状态信息。如果没有任何参数,那么该命令将会打印所有进程的状态信息。对于指定进程 CRASH 支持如下命令:

本节以手动触发 Panic 为例进行实践讲解。在 BiscuitOS 上通过输入 “echo c > /proc/sysrq-trigger” 来触发内核崩溃,并对转储文件为例进行分析:
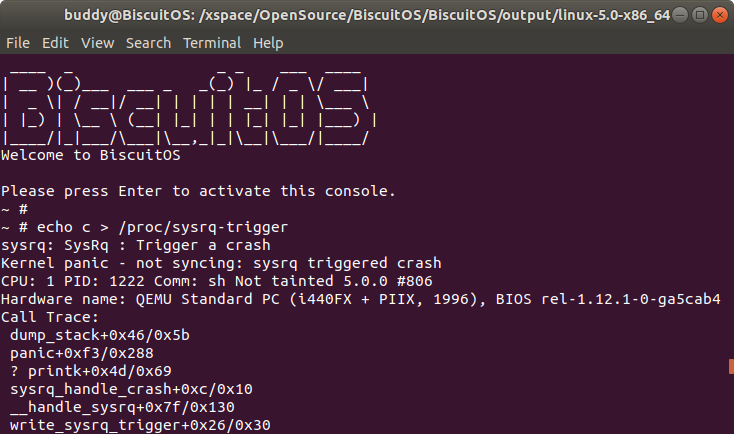
ps 打印内核崩溃时所有进程的状态信息
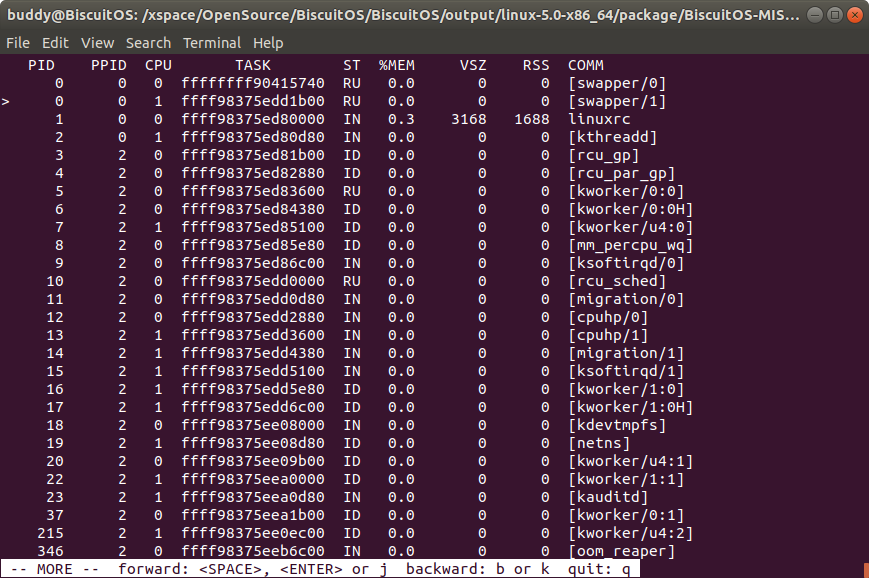
该命令用于输出内核崩溃时所有进程的状态信息。
- PID 表示进程的 PID 信息
- PPID 表示进程的父进程 PID
- CPU 则表示内核崩溃是进程最后运行的 CPU 信息
- TASK 表示进程对应进程描述符在内核中的地址
- ST 则表示进程的状态
- MEM 进程消耗的物理内存百分比
- VSZ 进程以 KB 为单位占用虚拟内存的大小
- RSS 进程以 KB 为单位实际占用物理内存大小
- COMM 进程对应的命令
另外,在使用该命令时,输出信息最左边使用 “>” 指示的进程表示内核崩溃时 CPU 上正在运行的进程,可以从上图中看出 CPU 0 上正在运行的进程是 0 号进程 “swapper/1”.
如果活跃的进程落在下线的 CPU 上,那么其最左边会被用 “-“ 进行标记。目前进程的状态包括 “RU, IN, UN, ZO, ST, TR, DE, SW, WA, PA, ID, NE”.
- > 活跃的进程
- RU 运行中的进程
- IN 可中断的进程
- UN 不可中断的进程
- ZO 僵尸进程
- ST 停止的进程
- TR
- DE
- SW
- WA
- PA
- ID
- NE
ps pid 打印内核奔溃时指定进程的状态信息
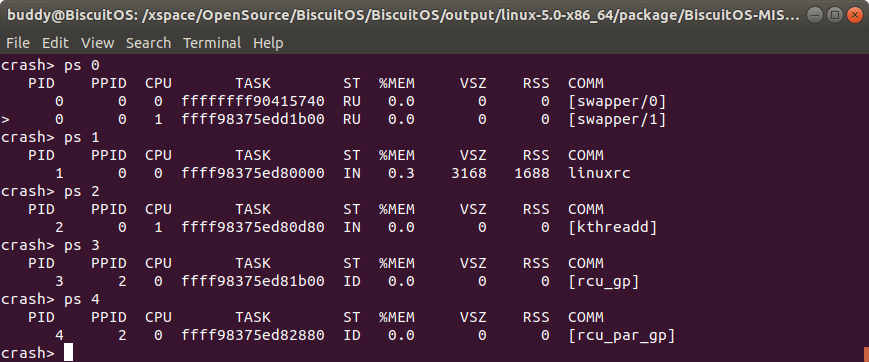
该命令用于打印指定 PID 对应的进程状态信息。
- PID 表示进程的 PID 信息
- PPID 表示进程的父进程 PID
- CPU 则表示内核崩溃是进程最后运行的 CPU 信息
- TASK 表示进程对应进程描述符在内核中的地址
- ST 则表示进程的状态
- MEM 进程消耗的物理内存百分比
- VSZ 进程以 KB 为单位占用虚拟内存的大小
- RSS 进程以 KB 为单位实际占用物理内存大小
- COMM 进程对应的命令
ps task 打印内核崩溃时进程描述符对应的进程状态信息

该命令用于打印内核崩溃时进程描述符对应的进程状态信息。每个进程/TASK 都使用一个 struct task_struct 数据结构进程描述,ps 命令支持 struct task_struct 所在内存地址获得对应进程状态信息.
- PID 表示进程的 PID 信息
- PPID 表示进程的父进程 PID
- CPU 则表示内核崩溃是进程最后运行的 CPU 信息
- TASK 表示进程对应进程描述符在内核中的地址
- ST 则表示进程的状态
- MEM 进程消耗的物理内存百分比
- VSZ 进程以 KB 为单位占用虚拟内存的大小
- RSS 进程以 KB 为单位实际占用物理内存大小
- COMM 进程对应的命令
ps command 打印内核崩溃时进程命令对应的进程状态信息
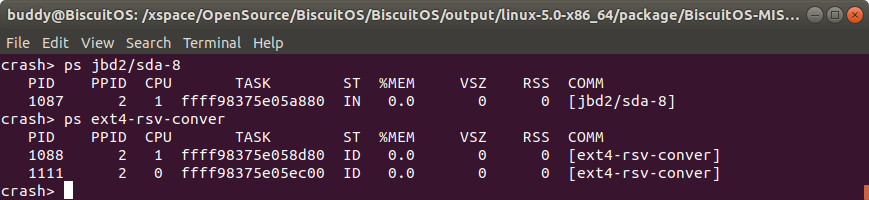
该命令用于打印内核崩溃时进程命令名字对应的进程状态信息。如果进程对应的命令名字全部由数字组成,那么该命令名字需要使用 “" 进程引用。如果进程对应命令名字由字符串构成,但字符串通过 “’” 包住,那么需要使用正则表达式进行引用.
- PID 表示进程的 PID 信息
- PPID 表示进程的父进程 PID
- CPU 则表示内核崩溃是进程最后运行的 CPU 信息
- TASK 表示进程对应进程描述符在内核中的地址
- ST 则表示进程的状态
- MEM 进程消耗的物理内存百分比
- VSZ 进程以 KB 为单位占用虚拟内存的大小
- RSS 进程以 KB 为单位实际占用物理内存大小
- COMM 进程对应的命令

另外可以使用 “’” 号进行进程名字模糊查找,例如在上图的例子中,就可以该种方式包含该 “migration” 的进程.
ps -k 只输出内核崩溃时内核线程的状态信息
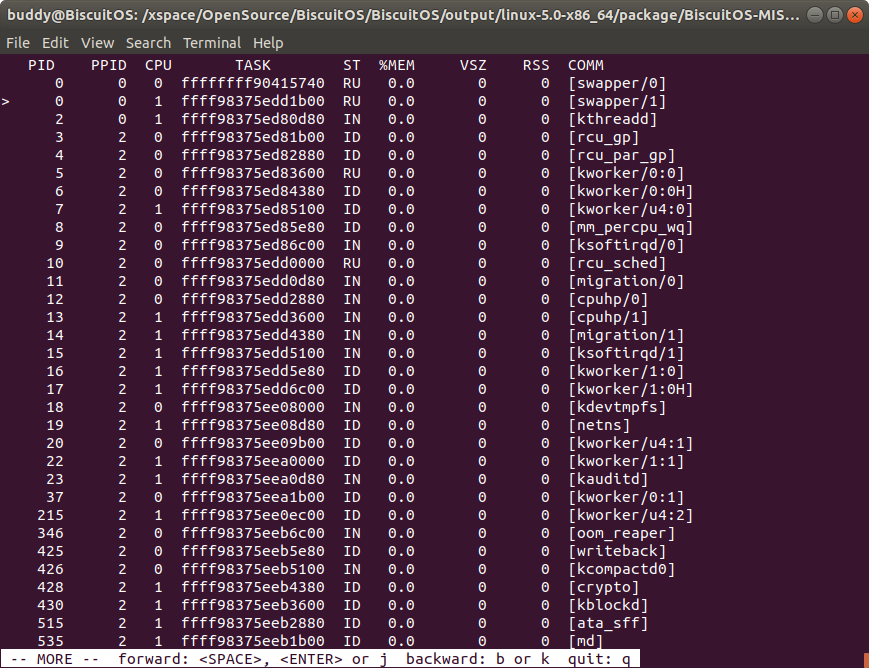
该命令可以限制 ps 命令只输出内核崩溃时内核线程的状态信息。该命令可以和其他命令配合使用限制输出信息:
- PID 表示进程的 PID 信息
- PPID 表示进程的父进程 PID
- CPU 则表示内核崩溃是进程最后运行的 CPU 信息
- TASK 表示进程对应进程描述符在内核中的地址
- ST 则表示进程的状态
- MEM 进程消耗的物理内存百分比
- VSZ 进程以 KB 为单位占用虚拟内存的大小
- RSS 进程以 KB 为单位实际占用物理内存大小
- COMM 进程对应的命令
ps -u 只输出内核崩溃时用户进程的进程状态信息

该命令可以限制 ps 命令只输出内核崩溃时用户进程的进程状态信息。该命令可以和其他命令配合使用限制输出信息:
- PID 表示进程的 PID 信息
- PPID 表示进程的父进程 PID
- CPU 则表示内核崩溃是进程最后运行的 CPU 信息
- TASK 表示进程对应进程描述符在内核中的地址
- ST 则表示进程的状态
- MEM 进程消耗的物理内存百分比
- VSZ 进程以 KB 为单位占用虚拟内存的大小
- RSS 进程以 KB 为单位实际占用物理内存大小
- COMM 进程对应的命令
ps -G 只输出内核崩溃时线程组的 Leader 线程状态信息
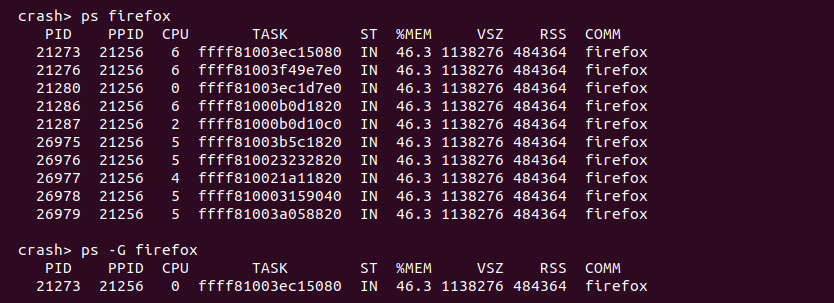
该命令可以限制 ps 命令只输出内核崩溃时线程组的 Leader 线程状态信息。该命令可以和其他命令配合使用限制输出信息:
- PID 表示进程的 PID 信息
- PPID 表示进程的父进程 PID
- CPU 则表示内核崩溃是进程最后运行的 CPU 信息
- TASK 表示进程对应进程描述符在内核中的地址
- ST 则表示进程的状态
- MEM 进程消耗的物理内存百分比
- VSZ 进程以 KB 为单位占用虚拟内存的大小
- RSS 进程以 KB 为单位实际占用物理内存大小
- COMM 进程对应的命令
ps -y policy 只输出内核崩溃时符合特定调度策略的进程状态
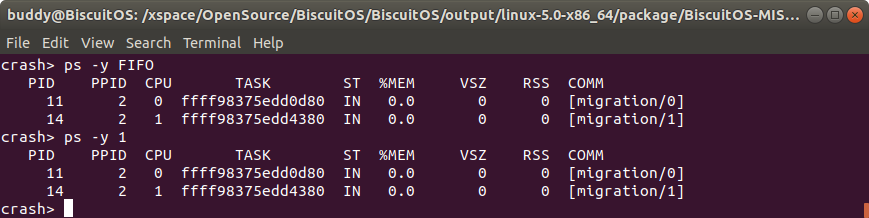
该命令可以限制 ps 命令输出符合指定调度策略的进程状态信息。调度策略可以通过数字或者名字给出,目前支持的调度策略包括:
- 0 or NORMAL
- 1 or FIFO
- 2 or RR
- 3 or BATCH
- 4 or ISO
- 5 or IDLE
- 6 or DEADLINE
例如在上图的例子中,查找当内核崩溃时采用 FIFP 进程调度的进程信息,此时符合要求的进程是 “migration/0” 和 “migration/1”. 该命令可以和其他命令配合使用限制输出信息:
- PID 表示进程的 PID 信息
- PPID 表示进程的父进程 PID
- CPU 则表示内核崩溃是进程最后运行的 CPU 信息
- TASK 表示进程对应进程描述符在内核中的地址
- ST 则表示进程的状态
- MEM 进程消耗的物理内存百分比
- VSZ 进程以 KB 为单位占用虚拟内存的大小
- RSS 进程以 KB 为单位实际占用物理内存大小
- COMM 进程对应的命令
ps -s 输出内核崩溃时进程的内核栈地址
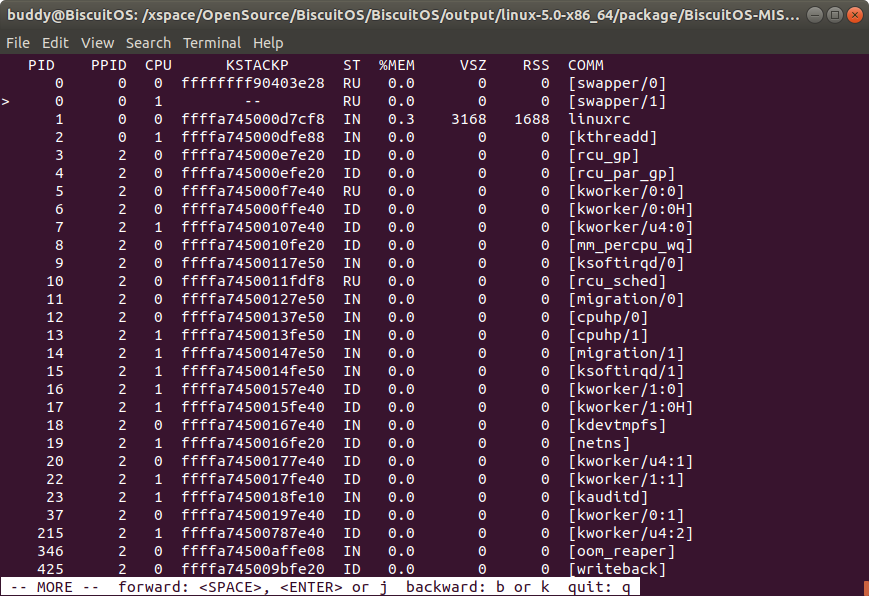
该命令会将 ps 默认输出的进程状态信息中的 TASK 项目替换成 KSTACKP, 该项用于表示进程的内核堆栈地址.
- PID 表示进程的 PID 信息
- PPID 表示进程的父进程 PID
- CPU 则表示内核崩溃是进程最后运行的 CPU 信息
- KSTACKP 表示进程的内核堆栈地址
- ST 则表示进程的状态
- MEM 进程消耗的物理内存百分比
- VSZ 进程以 KB 为单位占用虚拟内存的大小
- RSS 进程以 KB 为单位实际占用物理内存大小
- COMM 进程对应的命令
ps -p 输出内核崩溃时进程的父子关系
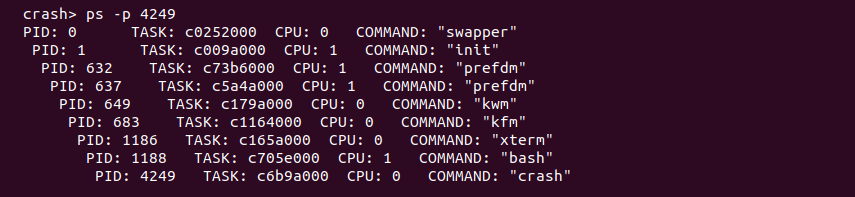
该命令可以输出内核崩溃时进程的父子关系,该关系通过层次体系进行表示,上一层是下一层的父进程。每一层描述进程的基本状态信息:
- PID 表示进程的 PID 信息
- CPU 则表示内核崩溃是进程最后运行的 CPU 信息
- TASK 表示进程对应进程描述符在内核中的地址
- COMM 进程对应的命令
ps -c 打印内核崩溃时某进程的所有子进程
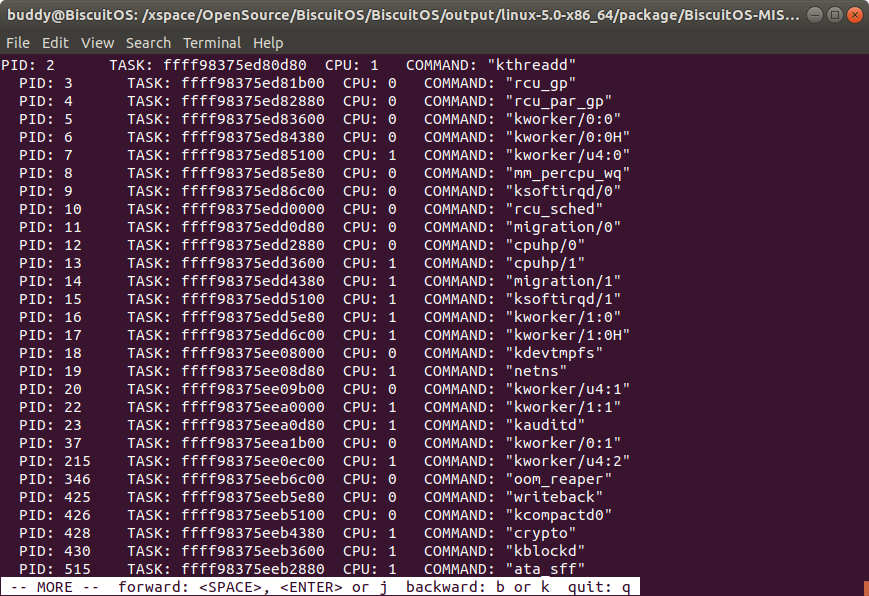
该命令可以打印内核崩溃时指定进程或所有进程的子进程状态。如果要打印指定进程,需要提供指定进程的 PID,否则该命令将打印所有进程的子进程状态.
- PID 表示进程的 PID 信息
- CPU 则表示内核崩溃是进程最后运行的 CPU 信息
- TASK 表示进程对应进程描述符在内核中的地址
- COMM 进程对应的命令
ps -t 打印内核崩溃时进程时间相关的信息
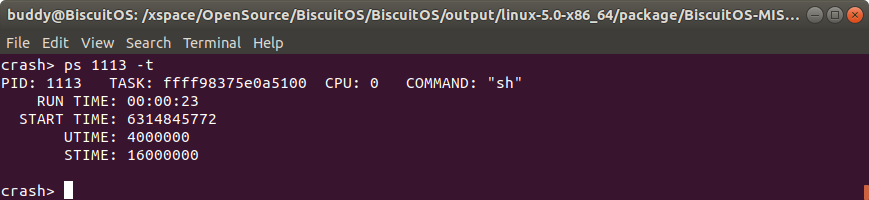
该命令可以打印内核崩溃时指定进程的运行时长、开始运行的时间、用户空间累计运行时长、以及内核空间累计运行时长。
- RUN TIME 进程运行时长
- START TIME 进程开始运行的时间戳
- UTIME 进程在用户空间运行时长
- STIME 进程在内核空间运行时长
- PID 表示进程的 PID 信息
- CPU 则表示内核崩溃是进程最后运行的 CPU 信息
- TASK 表示进程对应进程描述符在内核中的地址
- COMM 进程对应的命令
ps -l 打印内核崩溃时进程最后运行的时间戳
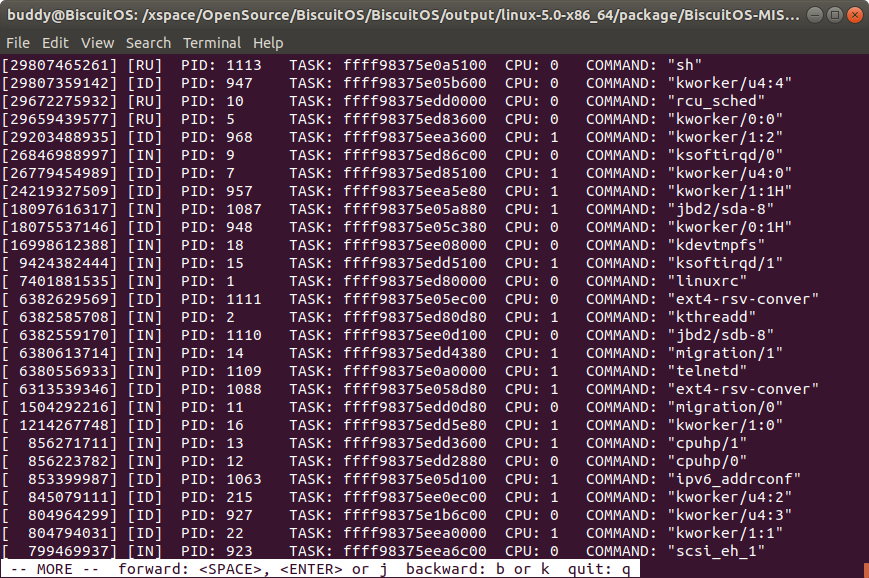
该命令将内核崩溃时所有进程按最后运行时间戳进行排序,最后运行的进程排在最前面。从上图可以看出内核崩溃时最后运行的进程是 1113 进程。该时间戳是通过每个进程描述符 struct task_struct 的 last_run 值进程排序的。因此最后运行的进程其时间戳越大,那么其越排到最前面. 在展示的消息里,最左边的是时间戳,接着是进程 ST 状态信息,后面紧跟着 PID、TASK、CPU 和 COMMAND 信息.
- PID 表示进程的 PID 信息
- CPU 则表示内核崩溃是进程最后运行的 CPU 信息
- TASK 表示进程对应进程描述符在内核中的地址
- ST 则表示进程的状态
- COMM 进程对应的命令
ps -m 打印内核崩溃时进程最后运行的时间日期
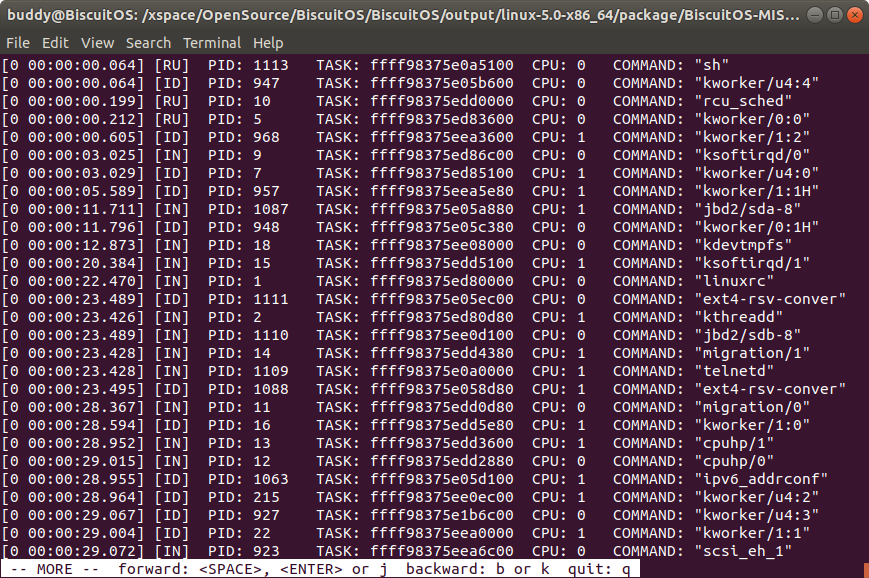
该命令将内核崩溃时所有进程按最后运行时间进行排序,最后运行的进程排在最前面。从上图可以看出内核崩溃时最后运行的进程是 1113 进程。该时间是通过每个进程描述符 struct task_struct 的 last_run 值进程排序的。因此最后运行的进程其时间日期越大,那么其越排到最前面. 在展示的消息里,最左边的是时间信息,其包括了天数和时分秒信息,接着是进程 ST 状态信息,后面紧跟着 PID、TASK、CPU 和 COMMAND 信息.
- PID 表示进程的 PID 信息
- CPU 则表示内核崩溃是进程最后运行的 CPU 信息
- TASK 表示进程对应进程描述符在内核中的地址
- ST 则表示进程的状态
- COMM 进程对应的命令
ps -C cpus [m/l] 打印内核崩溃时指定 CPU 上进程时间信息
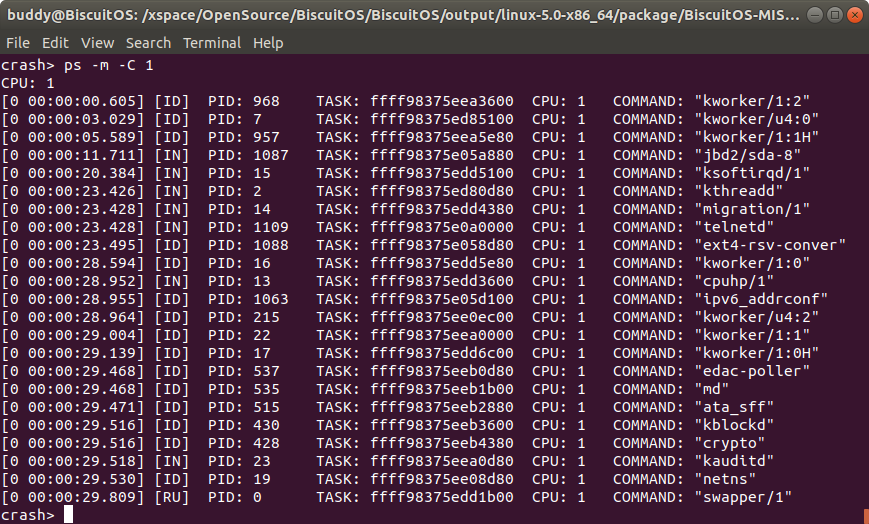
该命令基于 “m/l” 使用,可以显示指定 CPU 上内核崩溃时进程按最后运行时间进行排序,最后运行的进程排在最前面。从上图可以看出内核崩溃时最后运行的进程是 968 进程。该时间是通过每个进程描述符 struct task_struct 的 last_run 值进程排序的。因此最后运行的进程其时间日期越大,那么其越排到最前面. 在展示的消息里,最左边的是时间信息,其包括了天数和时分秒信息,接着是进程 ST 状态信息,后面紧跟着 PID、TASK、CPU 和 COMMAND 信息. 对于 cpus 参数,可以使用 “1,3,5”、”1-3”、”1,3,5-7,10”、”all”、或者 “a” 的方式选择 CPU.
- PID 表示进程的 PID 信息
- CPU 则表示内核崩溃是进程最后运行的 CPU 信息
- TASK 表示进程对应进程描述符在内核中的地址
- ST 则表示进程的状态
- COMM 进程对应的命令
ps -g 打印内核崩溃时包含指定线程的线程组信息

该命令用于打印内核崩溃是包含指定线程的线程组信息。例如上图中用于打印包含该线程 0xc20ab0b0 的线程组,可以看到线程组 leader 是进程 PID 6425, 其包含了 5 个线程,其中 PID 6523 就是 0xc20ab0b0.
- PID 表示进程的 PID 信息
- CPU 则表示内核崩溃是进程最后运行的 CPU 信息
- TASK 表示进程对应进程描述符在内核中的地址
- COMM 进程对应的命令
ps -r 打印内核崩溃时进程的资源限制信息
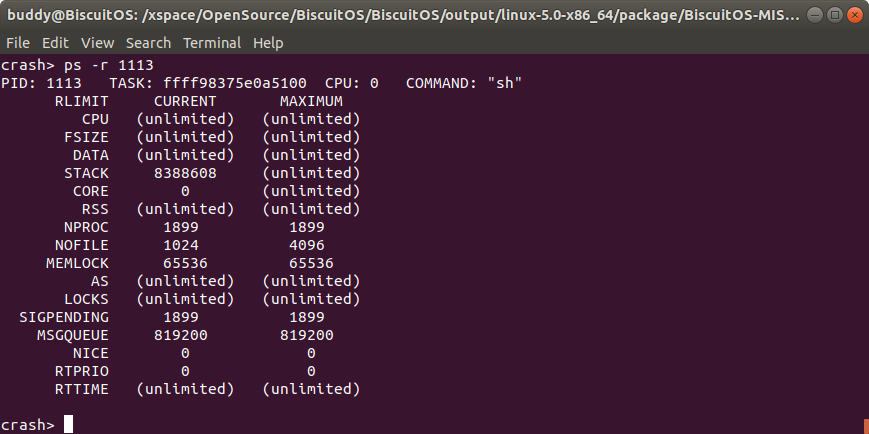
该命令可以打印内核崩溃时进程的资源限制信息。在信息展示时,RLIMIT 代表限制资源项,CURRENT 代表某种资源当前限制值,MAXIMUM 则代表某中资源最大限制值。
- CPU
- FSIZE 限制文件体积的上限
- DATA 限制进程的数据段的上限
- STACK 限制进程的堆栈的上限
- CORE 限制 CORE 文件的最大值
- RSS 限制进程使用物理内存的上限
- NPROC
- NOFILE 限制进程同时打开文件描述符的最大值
- MEMLOCK
- AS
- LOCKS
- SIGPENDING 限制进程阻塞的信号
- MSGQUEUE
- NICE
- PTPRIO 进程实时优先级
- RTTIME
ps -a 打印内核崩溃时进程的参数和环境变量
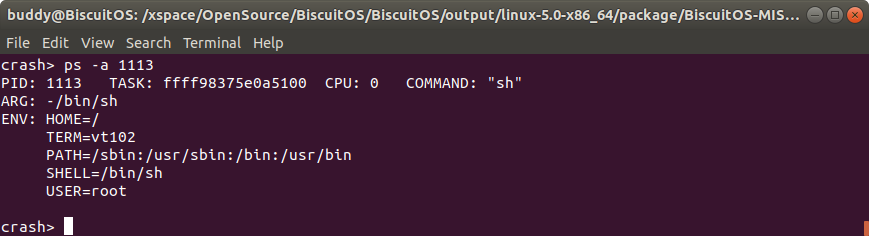
该命令可以打印内核奔溃是进程的参数和环境变量信息。例如上面的例子,ARG 表示进程 1113 其命令行是 “-/bin/sh”, ENV 则表示运行进程时的环境信息.
- PID 表示进程的 PID 信息
- CPU 则表示内核崩溃是进程最后运行的 CPU 信息
- TASK 表示进程对应进程描述符在内核中的地址
- COMM 进程对应的命令
ps -S 打印内核崩溃时不同进程状态的数量信息

该命令用于统计内核崩溃是每种进程状态的数量。当前支持的进程状态包括 “RU, IN, UN, ZO, ST, TR, DE, SW, WA, PA, ID, NE”.
- RU 运行中的进程
- IN 可中断的进程
- UN 不可中断的进程
- ZO 僵尸进程
- ST 停止的进程
- TR
- DE
- SW
- WA
- PA
- ID
- NE
ps -A 打印内核崩溃时各个 CPU 上正在运行的进程状态

该命令用于打印内核崩溃时各个 CPU 上正在运行进程的状态信息。例如上图系统包含了两个 CPU,当内核崩溃时 CPU 0 上正在运行进程 0,此时 CPU 1 上运行进程 1113. 进程状态信息的含义如下:
- PID 表示进程的 PID 信息
- PPID 表示进程的父进程 PID
- CPU 则表示内核崩溃是进程最后运行的 CPU 信息
- TASK 表示进程对应进程描述符在内核中的地址
- ST 则表示进程的状态
- MEM 进程消耗的物理内存百分比
- VSZ 进程以 KB 为单位占用虚拟内存的大小
- RSS 进程以 KB 为单位实际占用物理内存大小
- COMM 进程对应的命令
Crash struct/union 数据结构信息分析
当使用 CRASH 分析内核转储文件时,需要读取某个数据结构或联合体变量的数据时,CRASH 工具提供了 struct 和 union 命令,两个命令都可以将某段地址的内容装换成某个数据结构或联合体的形式,对分析内核崩溃有很大的帮助,命令的格式如下:

本节以手动触发 Panic 为例进行实践讲解。在 BiscuitOS 上通过输入 “echo c > /proc/sysrq-trigger” 来触发内核崩溃, 并对 struct task_struct 和 union thread_union 数据为例进行分析内核核心转储文件:
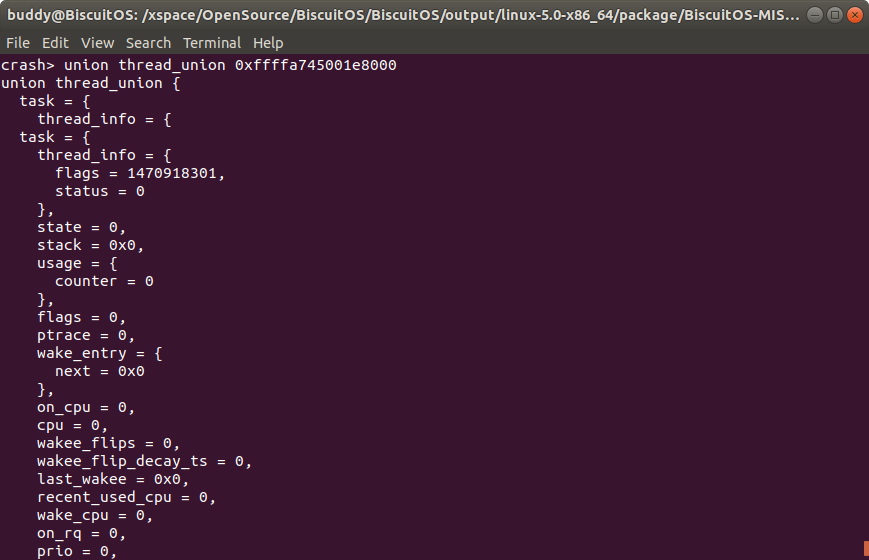
CRASH 获得 struct task_struct/union thread_union 方法
当获得内核核心转储文件之后,想查看内核崩溃现场某些结构体或者联合体的数据时,往往首先要找到这些数据的内存地址,那么如何获得数据的地址呢?
获得方法很多,其中一种就是依据不同架构参数传递规则来获得,例如在调用某个函数过程中,需要使用堆栈或者寄存器传递参数,那么可以通过这个规则获得数据的内存地址; 另外某些数据结构具有全局属性,具有某个已知固定地址;
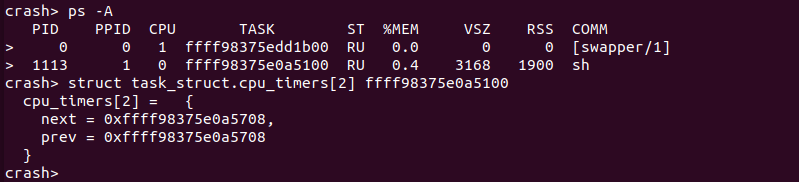
本节以 TASK 的进程描述符 struct task_struct 结构体和 TASK 的内核堆栈 union thread_union 为例进行讲解。当使用 CRASH 工具分析内核核心转储文件时,使用 ps 命令或者 bt 命令都可以获得发生内核崩溃时 CPU 正在运行进程的信息,该信息中就包含了 struct task_struct 的内存地址信息.

从上面可知,CPU 0 上运行的 TASK 的 struct task_struct 数据结构的内存地址是0xffff98375e0a5100 , 而 CPU 1 上运行的 TASK 的 struct task_struct 数据结构的内存地址是 0xffff98375edd1b00, 此时结合 struct task_struct 的地址,查看其数据内容:
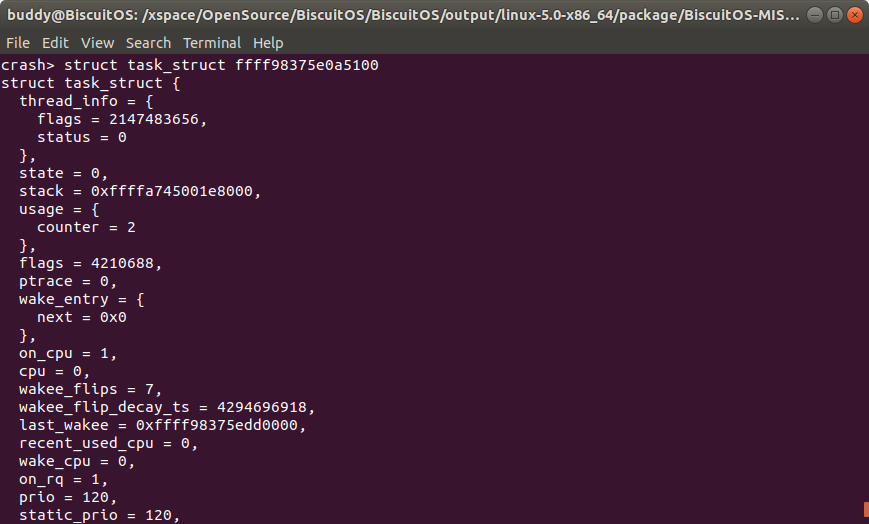
可以看到进程 1113 的 struct task_struct 结构体的数据全部打印出来,可以结合 struct task_struct 结构的定义一一获得所需的数据。另外有些结构体或联合体不能简单的通过上面的方法获得,其需要结合一些原理进行获得,例如 union thread_union,其在不同架构中的布局不同,但大体可以描述为下图:
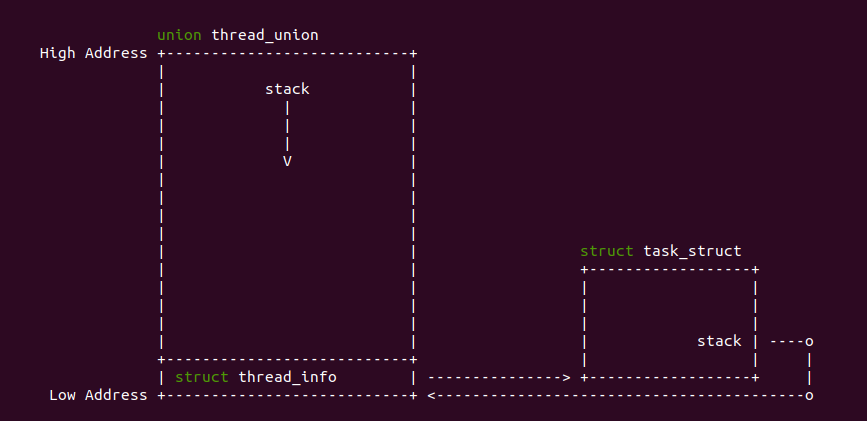
union thread_union 联合体与进程的内核堆栈绑定在一起,位于内核堆栈的顶部,然后进程的内核堆栈通过 struct task_struct 的 stack 成员进行指定,例如在进程 1113 中,struct task_struct 的 task 成员的值是 0xffffa745001e8000, 那么该地址就是进程内核堆栈的地址,在通过转换就可以知道该地址也就是 union thread_info 的地址,因此:
struct struct_name/union union_name.member <addr> 获得指定成员的数据
当在使用 CRASH 分析内核核心转储文件时,可以使用 struct/union 命令配合指定结构体或联合体的内存地址,以此查看结构体或联合体的数据。
struct/union 命令还提供了 “.member” 选项,该选项可以直接输出结构体或联合体中指定成员的数据。
例如在上图中,进程 1113 的进程描述符 struct task_struct 的内存地址是 0xffff98375e0a5100, 因此可以使用 struct task_struct.stack命令直接读取 1113 进程的内存堆栈地址;
同理进程 1113 的内存堆栈的地址正好是联合体 union thread_union 的内存地址,因此对于联合体也可以使用同样的方法读取指定成员的数据。
例如上图中,1113 进程的内核堆栈地址是 0xffffa745001e8000, 那么 union thread_union 的地址页是 0xffffa745001e8000, 那么此时就可以使用命令 union thread_union.task <addr> 直接读取 task 成员的数据.
如果所要查看的成员嵌入在数据结构或数组中,那么可以使用 “.member.member” 或者 “.member[index]” 的方式进行读取,如果嵌入层次很深结构体或联合体中,那么可以使用 “.member.member.member…..”
struct struct_name/union union_name -o 成员偏移值
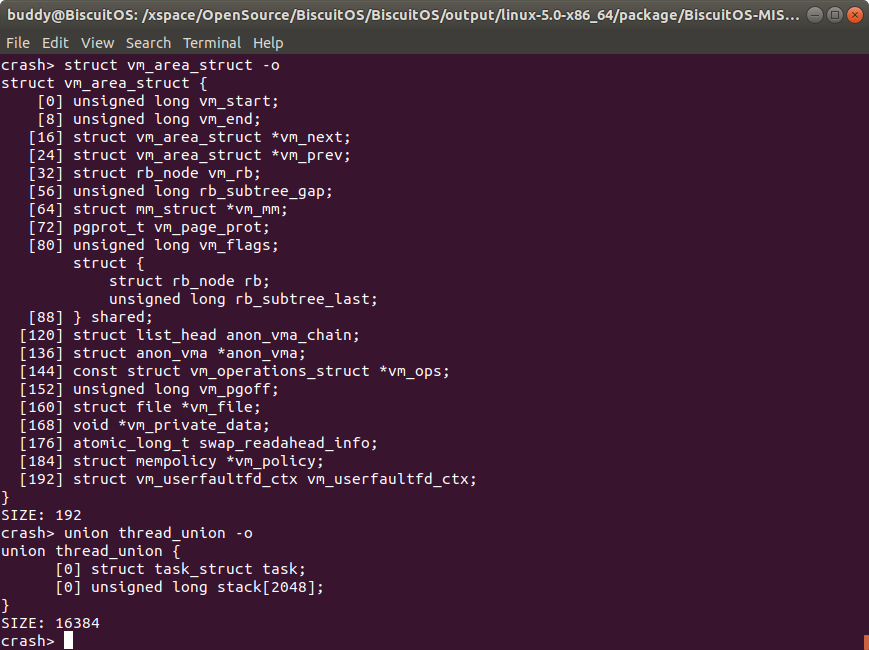
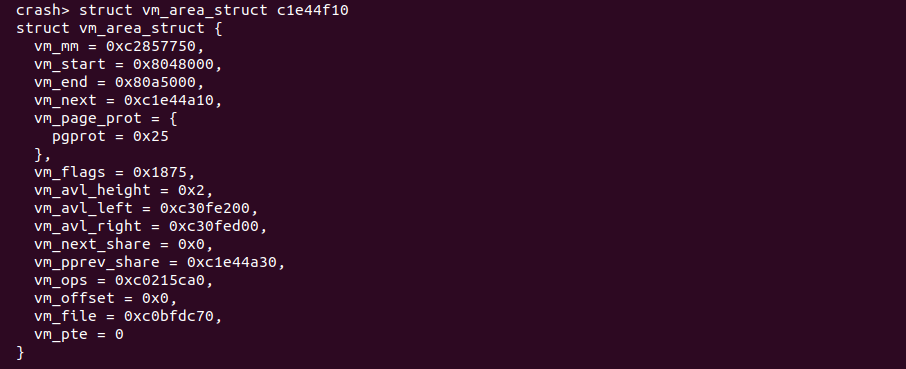
Crash 的 struct 和 union 都提供了类似的命令用于获得成员的偏移值。该命令不仅可以获得各成员的偏移,还可以获得结构体或联合体占用的字节数.
例如在上图中,通过 struct vm_area_struct -o命令获得 struct vm_area_struct 各成员在结构体中的偏移,例如 vm_file 成员在结构体的偏移值是 160 个字节。
在上图中,通过 union thread_union -o 命令获得 union thread_union 各成员在联合体中的偏移。
如果此时各个成员的偏移都是 0,如果此时在命令上附上联合体的内存地址,那么该命令将显示各成员的虚拟地址,如下:
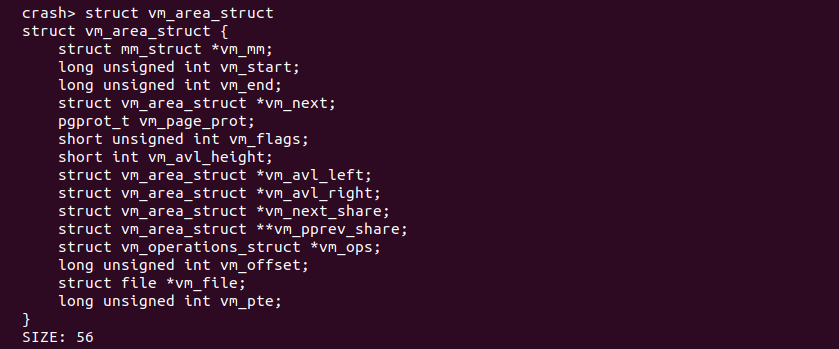
struct/union name 获得结构体/联合体定义

Crash 的 struct 和 union 都提供了类似命令获得结构体/联合体在内核中的定义。该命令可以直观的看到指定结构体或联合体的定义。例如在上图中查看联合体 bdflush_param 的定义。该命令不仅可以查看结构体和联合体的定义,还可以计算其占用的字节数.
struct/union name <addr> 获得结构体/联合体的内容
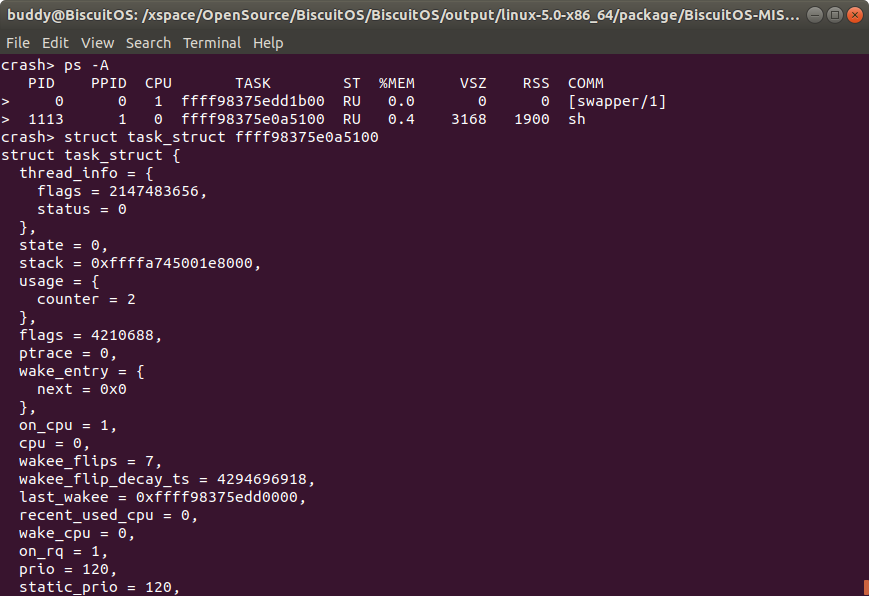
当获得一个结构体或联合体的内存地址之后,可以使用该命令获得结构体中的数据。例如在上图中,当通过 ps 获得进程 1113 的进程描述符 struct task_struct 的内存地址是 ffff98375e0a5100 之后,可以使用struct task_struct ffff98375e0a5100 命令查看 1113 进程的进程描述符内容。
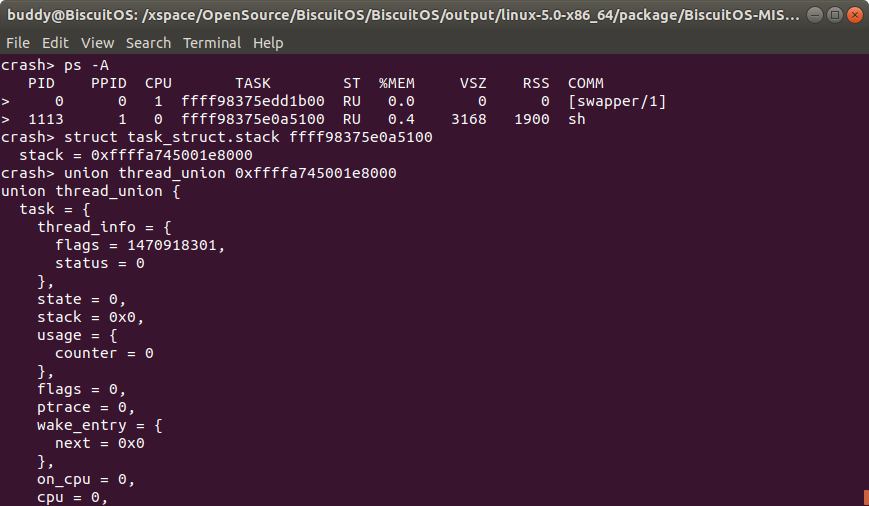
同理当通过 1113 进程的进程描述符获得内核堆栈的地址,从而获得 union thread_union 的内存地址为 0xffffa745001e8000,那么此时使用 union thread_union 0xffffa745001e8000就可以查看 1113 进程对应的 union thread_union 内容.
struct/union name <addr> -r 获得结构体/联合体原始数据
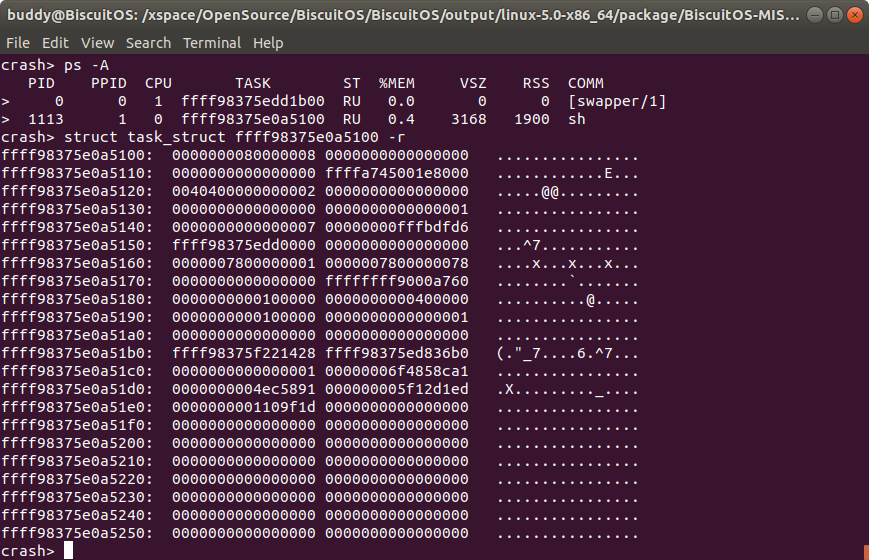
所谓原始数据即内存中的数据。当 struct 或 union 命令配合结构体/联合体的名字和其在内存中的地址时,CRASH 按结构体/联合体的个数输出内容,但添加了 -r 命令则会输出结构体/联合体在内存的数据。
例如上图中进程 1113 的进程描述符的内存地址是 ffff98375e0a5100, 此时在上 “-r” 选项,CRASH 将按原始数据的方式输出 ffff98375e0a5100 开始之后的内存内容.
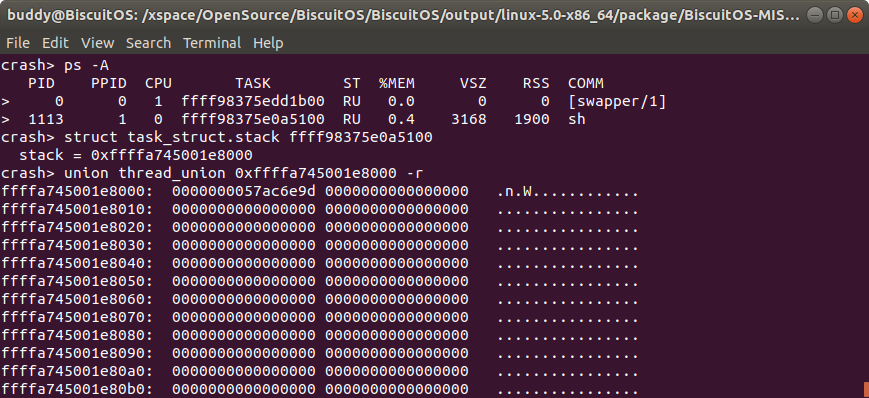
同理联合体也可以使用 “-r” 选项,例如在上图中 1113 进程的内核栈地址是 0xffffa745001e8000,该地址也是 union thread_union 的内存地址,此时加上 “-r” 选项 CRASH 将按原始数据的方式输出 ffffa745001e8000 开始之后的内存内容.
struct/union name <addr> -x/-d 以十六进制/十进制方式输出数据
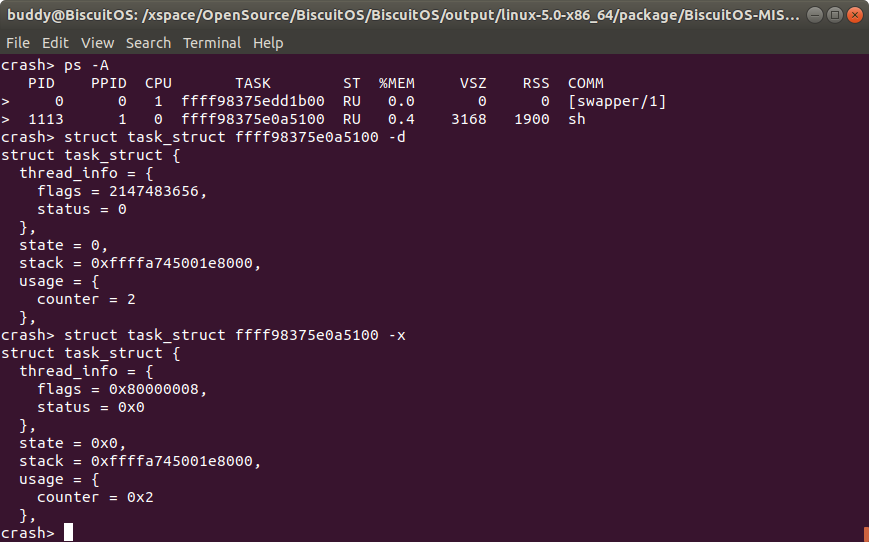
struct name <addr>在输出指定结构体内容时会采用默认的进制进行输出,如果需要指定输出的进制方式,可以添加 “-d/-x” 选项,-d 选项使输出采用十进制方式进行内容输出,而 “-x” 选项使输出采用十六进制方式进行内容输出。
例如在上图案例中,进程 1113 的进程描述符地址为 ffff98375e0a5100, 当想使用十进制方式才看进程描述符的内容,此时加上 “-d” 选项,可以看出进程描述符的内容都是以十进制的方式输出;
同理想以十六进制输出,则添加 “-x” 选项,此时看到进程描述符的内容均按十六进制方式输出。但值得注意的是 “-d” 和 “-x” 选项不能同时使用.
struct/union name <name> -p 打印指针的类型
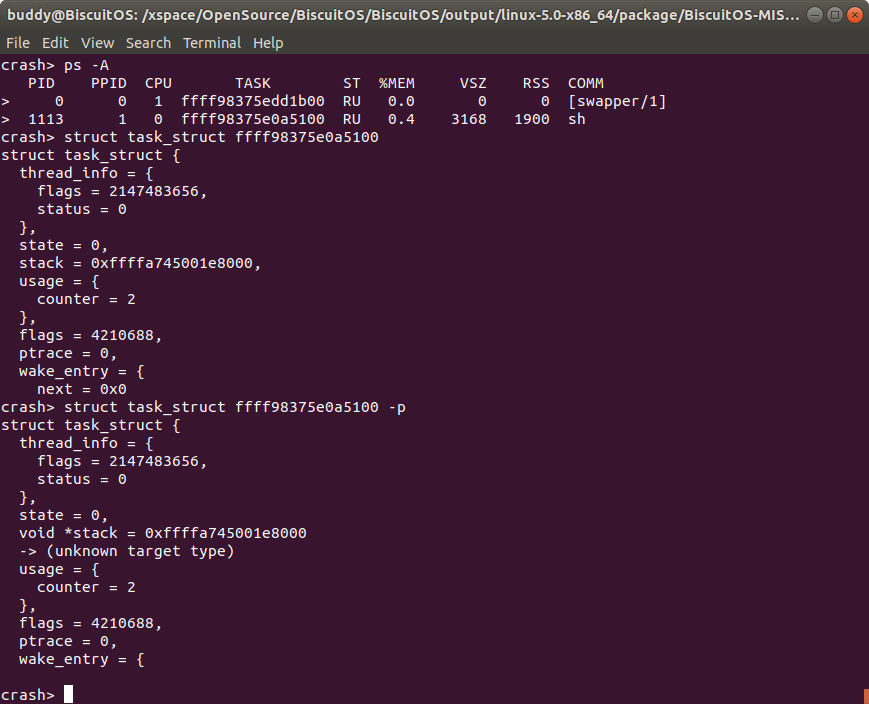
当在 struct 和 union 命令中采用 “-p” 选项,那么其在打印结构体/联合体内容的时候,输出指针的成员的类型。
例如在上面的例子中,进程描述符的 stack 成员是一个指针类型,那么当没有加 “-p” 选项时,其只输出成员的内容; 当加上 -p 选项之后,CRASH 还输出了 stack 的指针类型,该类型为 “void *” 型. 联合体类似.
struct/union name symbol 查看全局 symbol 结构体/联合体内容
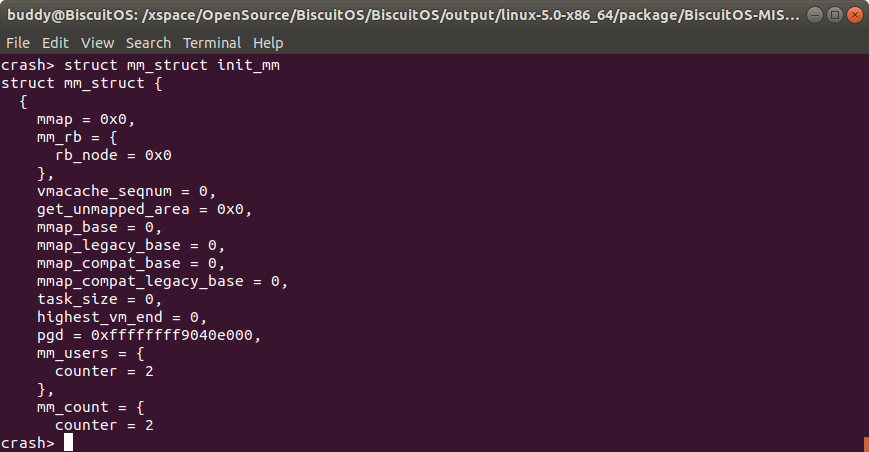
struct 命令可以查看一个全局 symbol 对应结构体的内容。全局 symbol 即一个全局变量,可以在内核源码的 Symtem.map 中查看全局 symbol。
例如在上图案例中,init_mm 是内核 0 号进程的地址空间描述符,其是一个 struct mm_strut 类型的全局变量,因此可以使用 struct mm_struct init_mm命令查看该内核 0 号进程的地址空间描述符内容. union 也有类似的用法.
struct/union name symbol:cpuspec 查看 PERCPU 变量在指定 CPU 上的内容
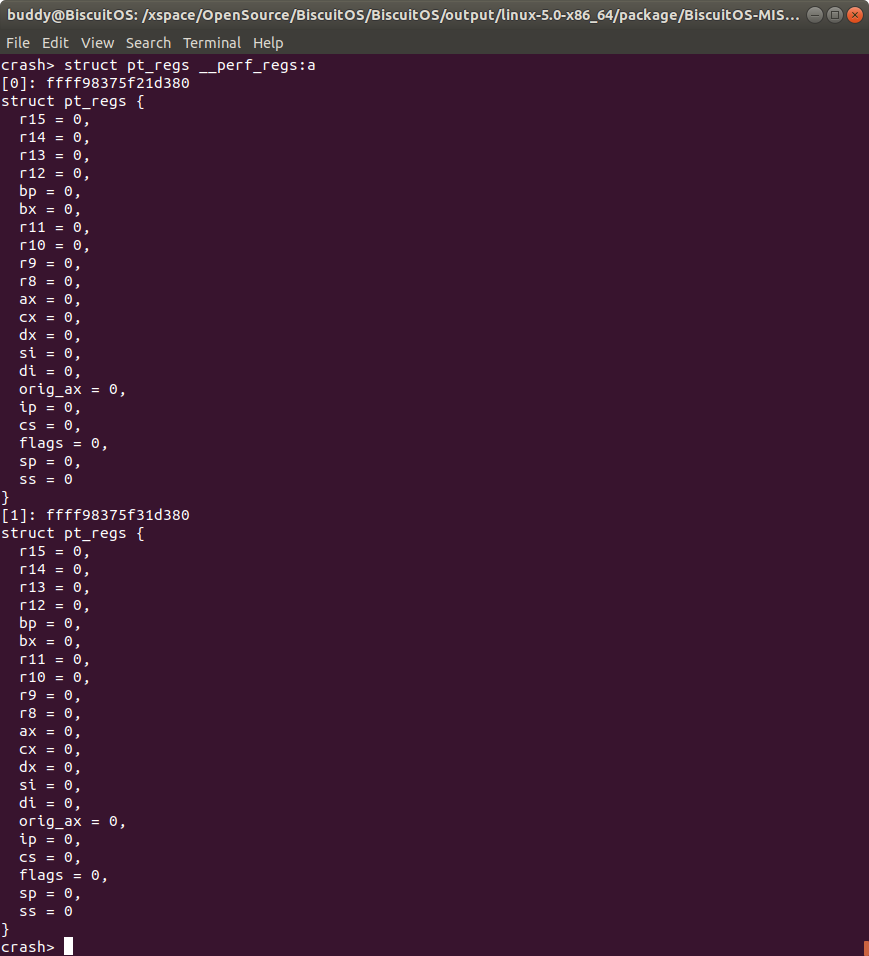
对于结构体或联合体的 PERCPU 变量,其在每个 CPU 上独立维护一套数据,CRASH 的 struct/union 提供了 “:cpuspec” 选项用于输出指定 CPU 上的内容。
”:cpuspec” 可以在全局 symbol 上使用,也可以在一个地址上使用。在上图的案例中,__perf_regs 是一个 PERCPU 变量,其定义如下:

内核定义了一个全局的 PERCPU 变量 __perf_regs, 其数据类型为 struct pt_regs, 那么此时就可以使用命令struct pt_regs __perf_regs:a 查看每个 CPU 上的结构体内容。”:cpuspec” 除了 “a” 选项之外还有:

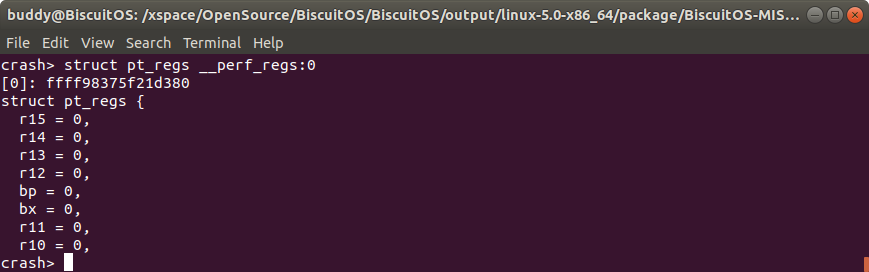
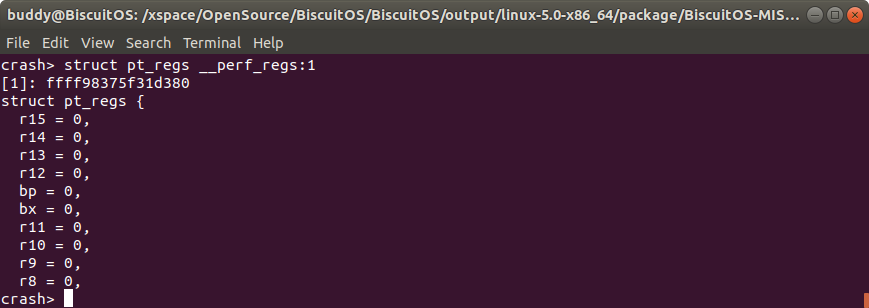
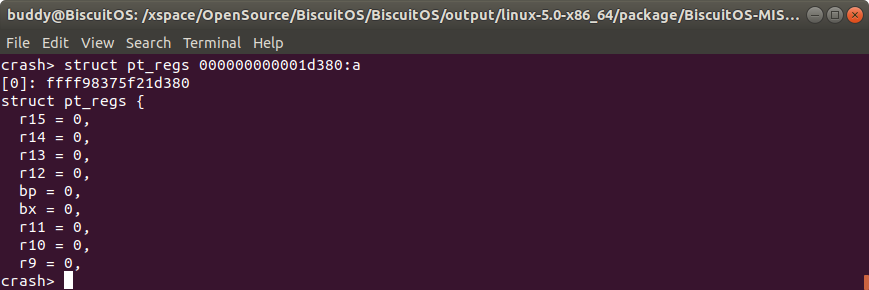
另外 “:cpuspec” 可以配合内存地址使用,例如在上面的例子中,__perf_regs 的内存地址是 000000000001d380,那么当想查看该 PERCPU 在所有 CPU 上的所有结构体内容时,可以按上图的方式使用. 联合体的使用和结构体使用一致.
Crash 物理内存/虚拟内存/页表分析
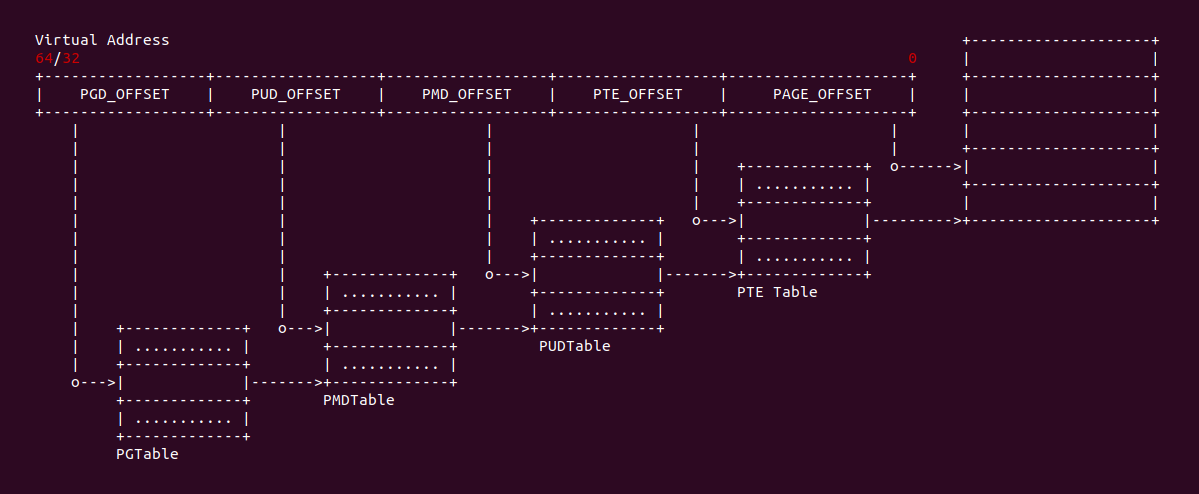
当使用 CRASH 分析内核转储文件时,往往需要对虚拟内存、物理内存、页表内容进行读取分析,有时也需要将物理内存、虚拟内存和页表之间的相互转换,以此分析问题现场。CRASH 提供了多个命令实现以上功能,本节用于介绍相关的命令和实践案例:
ptob 将物理页帧号转化成物理地址
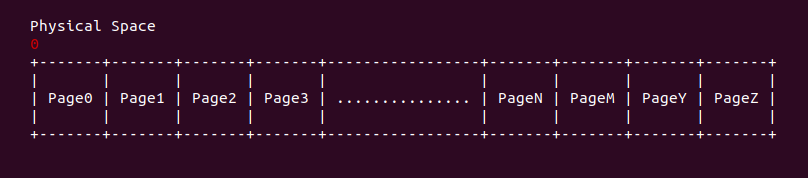
将物理内存按 PAGE_SIZE 的长度划分成多个数据块,每个数据块称为物理页,将这些物理页按顺序进行编号,每个物理页的编号称为物理页帧。物理页通常使用 Page 进行描述,物理页帧号则使用 PFN(pfn) 进行描述,物理地址则使用 PHY(phys) 进行描述。在物理内存起始地址为 0 的架构中,物理内存和物理页帧号之间的关系是:
# 转换关系
PAGE_SIZE = 1 << PAGE_SHIFT
PFN = PHYS >> PAGE_SHIFT
物理页帧号 = 物理地址 >> PAGE_SHIFT
# 内核提供的转换函数
pfn = page_to_pfn(page)
pfn = PHYS_PFN(phys)
page = pfn_to_page(pfn)
page = phys_to_page(phys)
phys = page_to_phys(page)
phys = PFN_PHYS(pfn)
CRASH 提供了 ptob 命令,该命令用于将一个物理页帧号转换成对应的物理地址。在有的架构中物理页帧号 0 对应着物理地址 0,但在有的架构中物理页帧 0 不一定对应物理内存 0,因此该命令可以便捷的将物理页帧号转换成物理地址. 其命令格式如下:
crash> ptob <pfn> ...

ptob 命令可以将一个或多个 PFN 转换成多个物理地址,在 BiscuitOS 中提供了一个实践案例用于介绍该命令的使用,其部署流程如下 (以 linux 5.0 X86_64 为例):
cd BiscuitOS
make linux-5.0-x86_64_defconfig
make menuconfig
[*] Package --->
[*] CRASH and BUG Example --->
[*] Example: ptob --->
BiscuitOS/output/linux-5.0-x86_64/package/BiscuitOS-crash-ptob-default
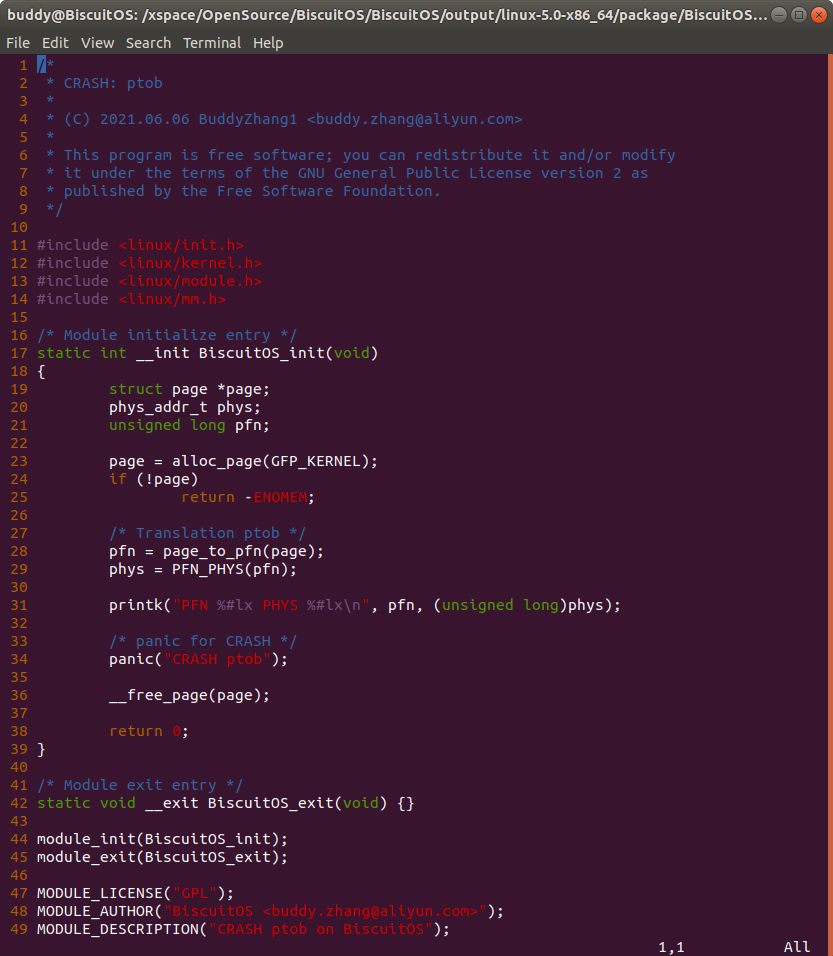
实践例子为一个独立模块,在模块初始化函数 BiscuitOS_init() 内,分配了一个物理页,并通过内核提供的 page_to_pfn() 函数和 PFN_PHYS() 函数分别算出了物理页帧号和物理地址。并在函数执行过程中触发 PANIC 导致内核核心转储,并获得对应的内核核心转储文件. 接着在 BiscuitOS 上实践该案例,并使用 CRASH 进行调试:
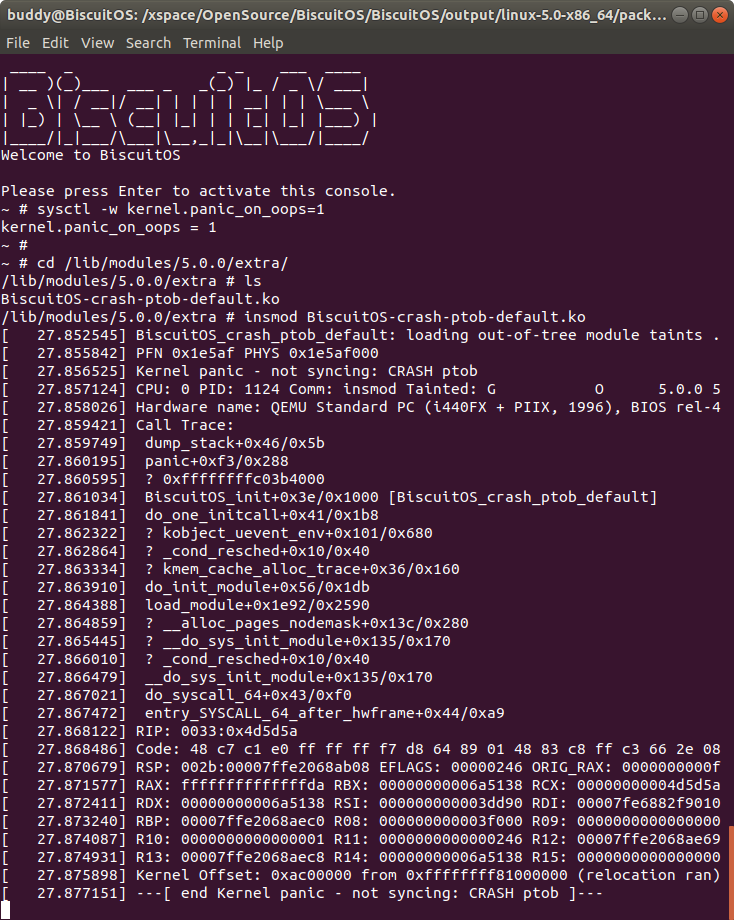
在 BiscuitOS 上运行实例之前,先将 PANIC 的 OOPS 选项设置为 1,以免 OOPS 被 killed,具体命令 “sysctl -w kernel.panic_on_oops=1”. 接着加载模块 “BiscuitOS-crash-ptob-default.ko”, 此时触发内核核心转储,此时通过不同的方法获得内核核心转储文件,并对其进行分析:
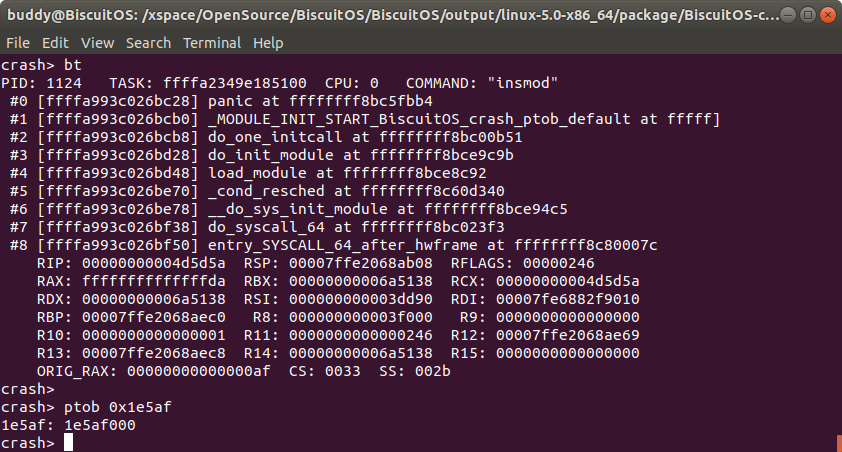
从实践案例的 log 可以看出,物理页的页帧号是 0x1e5af, 那么通过 ptob 工具可以获得其物理内存是 0x1e5af000. 有的童鞋会问这个工具不就是简单的将页帧号左移 PAGE_SHIFT 就行了吗? 在有的架构页帧号 0 正好对应物理内存 0,那么关系就是这么简单。但在有的架构上物理页帧号不对应物理内存 0,那么 ptob 这个工具还是挺有用的.
btop 将物理地址转换成物理页帧号
将物理内存按 PAGE_SIZE 的长度划分成多个数据块,每个数据块称为物理页,将这些物理页按顺序进行编号,每个物理页的编号称为物理页帧。物理页通常使用 Page 进行描述,物理页帧号则使用 PFN(pfn) 进行描述,物理地址则使用 PHY(phys) 进行描述。在物理内存起始地址为 0 的架构中,物理内存和物理页帧号之间的关系是:
# 转换关系
PAGE_SIZE = 1 << PAGE_SHIFT
PFN = PHYS >> PAGE_SHIFT
物理页帧号 = 物理地址 >> PAGE_SHIFT
# 内核提供的转换函数
pfn = page_to_pfn(page)
pfn = PHYS_PFN(phys)
page = pfn_to_page(pfn)
page = phys_to_page(phys)
phys = page_to_phys(page)
phys = PFN_PHYS(pfn)
CRASH 提供了 btop 命令,该命令用于将一个物理地址转换成对应的物理页帧号。在有的架构中物理地址 0 正好对应物理页帧 0,而在有的架构物理地址 0 不一定对应物理页帧 0,因此 btop 命令可以便捷的将物理地址转换成物理页帧号. 其命令格式如下:
crash> btop <phys> ...

btop 命令可以将一个或多个物理地址转换成物理页帧号,在 BiscuitOS 中提供了一个实践案例用于介绍该命令的使用,其部署流程如下 (以 linux 5.0 X86_64 为例):
cd BiscuitOS
make linux-5.0-x86_64_defconfig
make menuconfig
[*] Package --->
[*] CRASH and BUG Example --->
[*] Example: btop --->
BiscuitOS/output/linux-5.0-x86_64/package/BiscuitOS-crash-btop
实践例子为一个独立模块,在模块初始化函数 BiscuitOS_init() 内,分配了一个物理页,并通过内核提供的 page_to_pfn() 函数和 PFN_PHYS() 函数分别算出了物理页帧号和物理地址。并在函数执行过程中触发 PANIC 导致内核核心转储,并获得对应的内核核心转储文件. 接着在 BiscuitOS 上实践该案例,并使用 CRASH 进行调试:
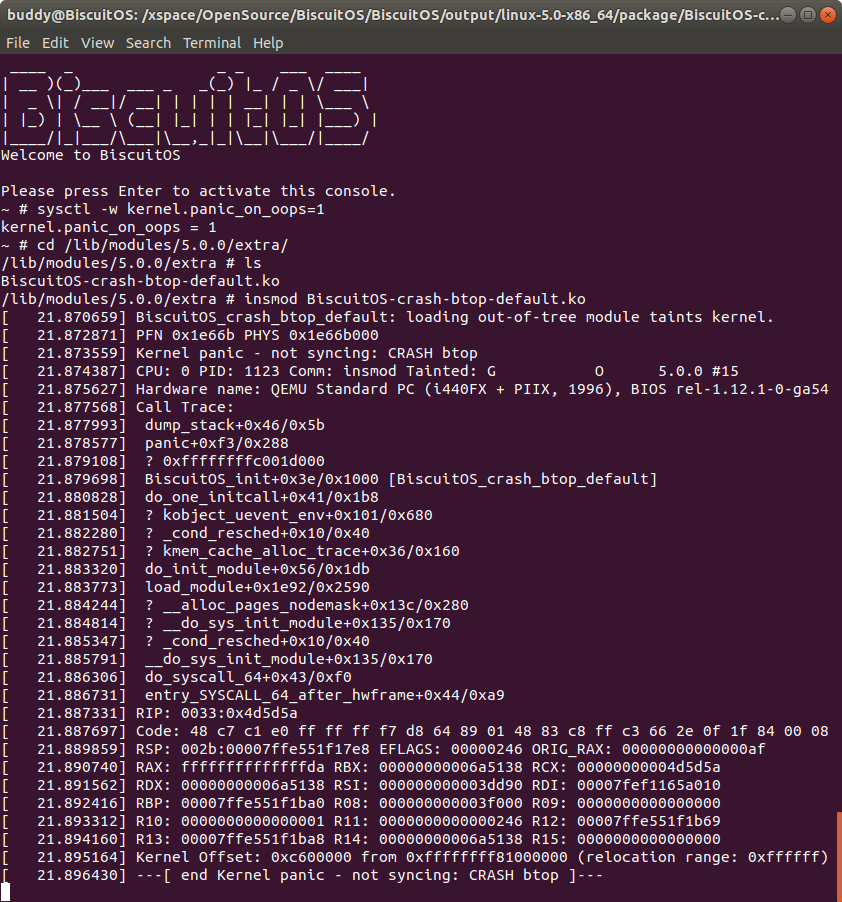
在 BiscuitOS 上运行实例之前,先将 PANIC 的 OOPS 选项设置为 1,以免 OOPS 被 killed,具体命令 “sysctl -w kernel.panic_on_oops=1”. 接着加载模块 “BiscuitOS-crash-ptob-default.ko”, 此时触发内核核心转储,此时通过不同的方法获得内核核心转储文件,并对其进行分析:
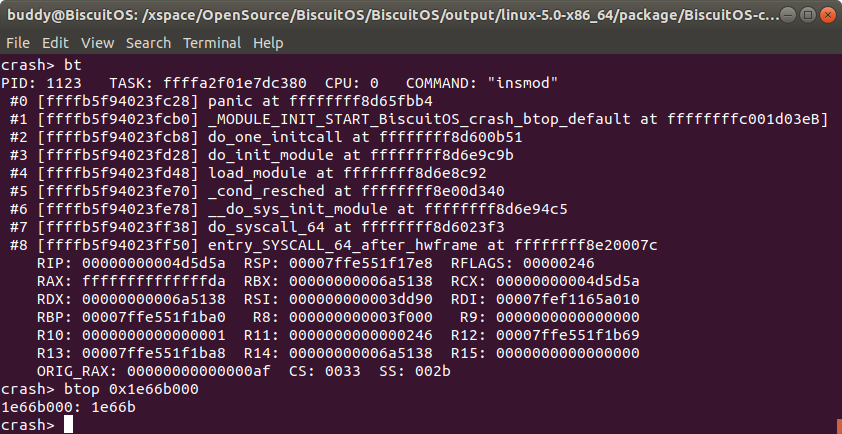
从实践案例的 log 可以看出,物理页地址是 0x1e66b000, 那么通过 btop 工具可以获得其物理页帧号是 0x1e66b. 有的童鞋会问这个工具不就是简单的将物理地址右移 PAGE_SHIFT 就行了吗? 在有的架构页帧号 0 正好对应物理内存 0,那么关系就是这么简单。但在有的架构上物理页帧号不对应物理内存 0,那么 btop 这个工具还是挺有用的.
ptov <address> 将物理内存转换成虚拟内存
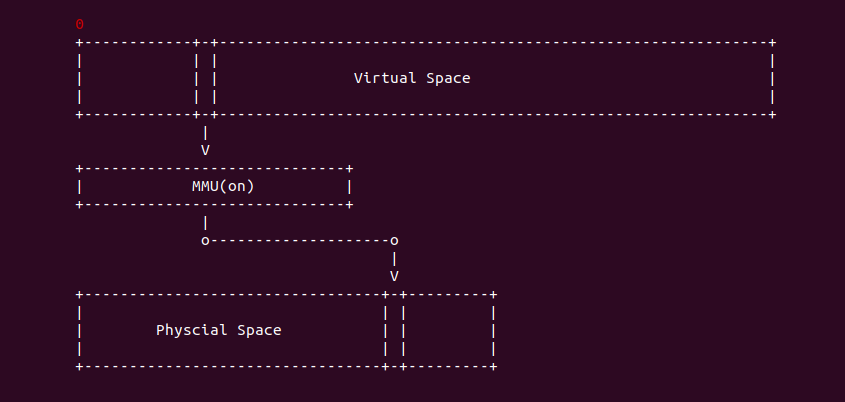
用户进程或内核线程都有自己的地址空间,该地址空间称为线性地址空间,也称为虚拟地址空间,该空间的地址称为虚拟地址。系统硬件上具有的内存空间称为物理内存空间,该空间的地址称为物理地址。当内核真正访问或读写虚拟内存时,内核会对未分配物理内存的虚拟内存建立页表,以此保证用户进程使用自己的内存。物理内存和虚拟内存之间的关系如下:
# 转换关系
PAGE_SIZE = 1 << PAGE_SHIFT
# 内核提供的转换函数
vaddr = phys_to_virt(phys)
vaddr = \_\_va(phys)
phys = virt_to_phys(vaddr)
phys = \_\_pa(virt)
CRASH 提供了 ptob 工具可以建物理地址转换成虚拟地址,该转储可以针对内核转储文件,也可以针对正在运行的系统, 其中 “ptov
” 用于将一个物理地址转换成虚拟地址,其命令格式如下:ptov address

btov 命令可以将一个物理地址转换成虚拟地址,在 BiscuitOS 中提供了一个实践案例用于介绍该命令的使用,其部署流程如下 (以 linux 5.0 X86_64 为例):
cd BiscuitOS
make linux-5.0-x86_64_defconfig
make menuconfig
[*] Package --->
[*] CRASH and BUG Example --->
[*] Example: btov --->
BiscuitOS/output/linux-5.0-x86_64/package/BiscuitOS-crash-btov
实践例子为一个独立模块,在模块初始化函数 BiscuitOS_init() 内,分配了一个物理页和一个 PERCPU 变量,然后通过 page_address() 函数获得物理页对应的虚拟地址,接着使用 page_to_phys() 函数获得物理页对应的物理地址。对于 PERCPU 变量,alloc_percpu() 函数分配并返回了 PERCPU 变量的虚拟地址,并调用 virt_to_phys() 函数获得 PERCPU 变量对应的物理地址。将相应的值打印处理,并在函数执行过程中触发 PANIC 导致内核核心转储,并获得对应的内核核心转储文件. 接着在 BiscuitOS 上实践该案例,并使用 CRASH 进行调试:
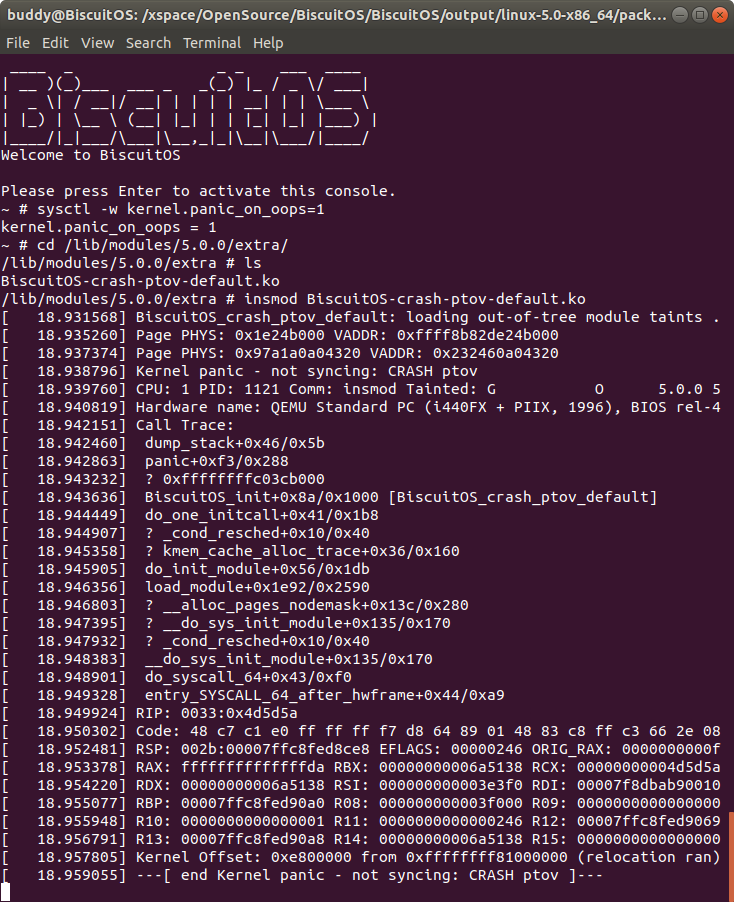
在 BiscuitOS 上运行实例之前,先将 PANIC 的 OOPS 选项设置为 1,以免 OOPS 被 killed,具体命令 “sysctl -w kernel.panic_on_oops=1”. 接着加载模块 “BiscuitOS-crash-ptov-default.ko”, 此时触发内核核心转储,此时通过不同的方法获得内核核心转储文件,并对其进行分析:
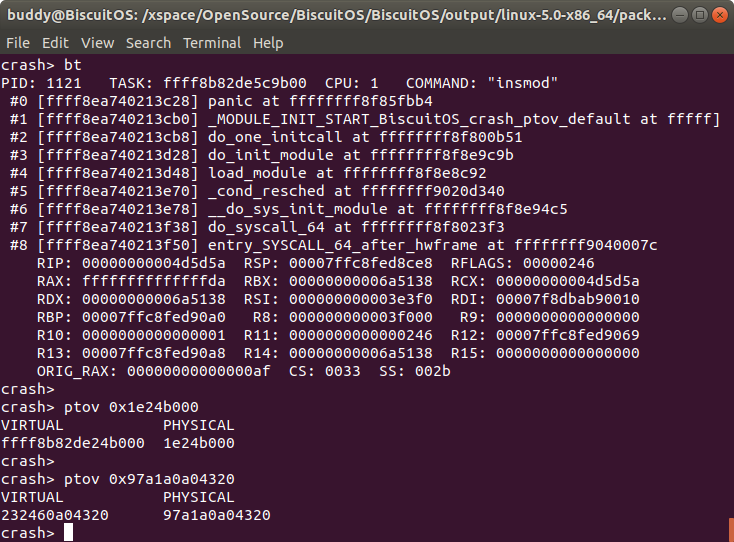
从实践案例的 log 可以看出,物理页的物理地址地址是 0x1e24b000, 那么通过 btov 工具可以获得其虚拟地址是 0xffff8b82de24b000, 与 page_address() 返回的值一致; PERCPU 的物理地址是 0x97a1a0a04320,通过 ptov 工具转换之后虚拟地址是 0x232460a04320, 与 alloc_percpu() 函数返回的值一致. 因此 ptov 工具的转换结果完全正确.
ptov offset:cpuspec 通过 PERCPU 变量物理地址获得在指定 CPU 上的虚拟地址
用户进程或内核线程都有自己的地址空间,该地址空间称为线性地址空间,也称为虚拟地址空间,该空间的地址称为虚拟地址。系统硬件上具有的内存空间称为物理内存空间,该空间的地址称为物理地址。当内核真正访问或读写虚拟内存时,内核会对未分配物理内存的虚拟内存建立页表,以此保证用户进程使用自己的内存。PERCPU 变量是通过 PERCPU 分配器动态分配,或则静态方式定义,每个 CPU 都会有 PERCPU 变量的一个副本,因此 PERCPU 变量会在每个 CPU 上具有一个虚拟地址。PERCPU 变量的定义有如下方式:
static DEFINE_PER_CPU(struct struct_name, percpu_name);
struct struct_name \_\_percpu alloc_percpu(struct struct_name)
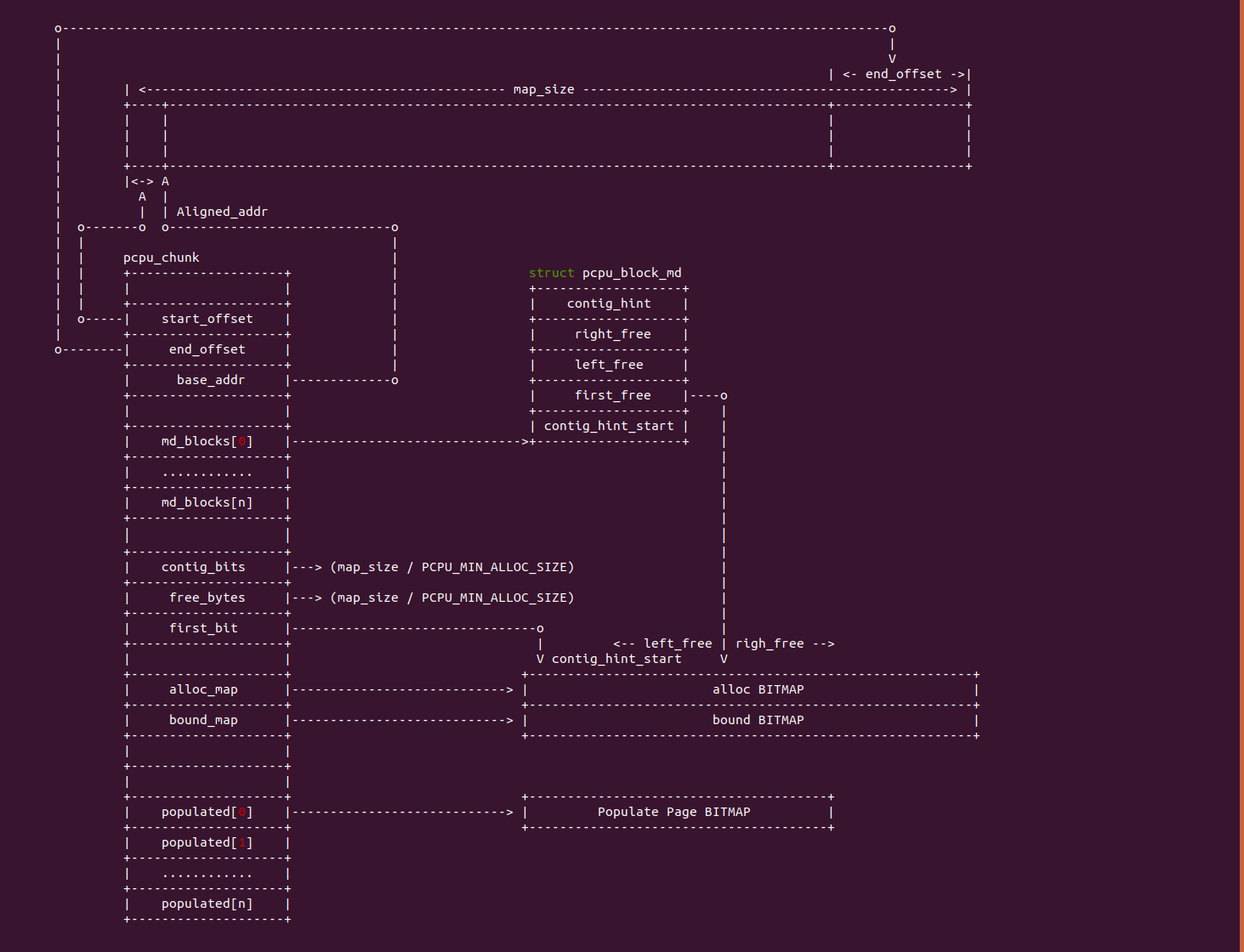
CRASH 提供了 ptob 工具可以建物理地址转换成虚拟地址,该转储可以针对内核转储文件,也可以针对正在运行的系统, 其中 “ptov offset:cpuspec” 用于将一个物理地址转换成虚拟地址,其命令格式如下:
ptov offset:cpuspec a per-cpu offset with a CPU specifier:
: CPU of the currently selected task.
:a[ll] all CPUs.
:#[-#][,...] CPU list(s), e.g. "1,3,5", "1-3",
or "1,3,5-7,10".

对于 PERCPU 变量,其在每个 CPU 上都有副本,因此 PERCPU 在每个 CPU 上会具有不同的虚拟地址,ptov 命令可以便捷获得 PERCPU 在指定 CPU 或者全部 CPU 上的虚拟地址。当 cpuspec 空缺时,ptov 可以获得 PERCPU 变量在当前 CPU 上的虚拟地址; 当 cpuspec 为 a 或者为 all 时,那么 ptov 可以获得 PERCPU 在所有 CPU 上的虚拟地址。ptov 命令也支持获得 PERCPU 在某几个 CPU 上的虚拟地址。 在 BiscuitOS 中提供了一个实践案例用于介绍该命令的使用,其部署流程如下 (以 linux 5.0 X86_64 为例):
cd BiscuitOS
make linux-5.0-x86_64_defconfig
make menuconfig
[*] Package --->
[*] CRASH and BUG Example --->
[*] Example: btov --->
BiscuitOS/output/linux-5.0-x86_64/package/BiscuitOS-crash-btov
实践例子为一个独立模块,在模块初始化函数 BiscuitOS_init() 内,分配了一个物理页和一个 PERCPU 变量,然后通过 page_address() 函数获得物理页对应的虚拟地址,接着使用 page_to_phys() 函数获得物理页对应的物理地址。对于 PERCPU 变量,alloc_percpu() 函数分配并返回了 PERCPU 变量的虚拟地址,并调用 virt_to_phys() 函数获得 PERCPU 变量对应的物理地址。将相应的值打印处理,并在函数执行过程中触发 PANIC 导致内核核心转储,并获得对应的内核核心转储文件. 接着在 BiscuitOS 上实践该案例,并使用 CRASH 进行调试:
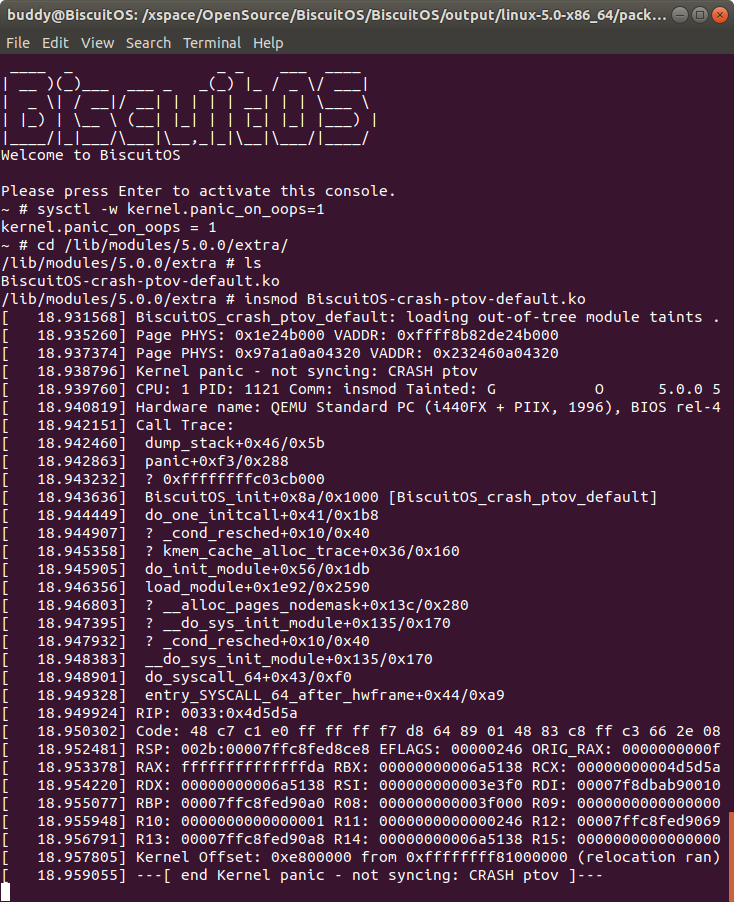
在 BiscuitOS 上运行实例之前,先将 PANIC 的 OOPS 选项设置为 1,以免 OOPS 被 killed,具体命令 “sysctl -w kernel.panic_on_oops=1”. 接着加载模块 “BiscuitOS-crash-ptov-default.ko”, 此时触发内核核心转储,此时通过不同的方法获得内核核心转储文件,并对其进行分析:
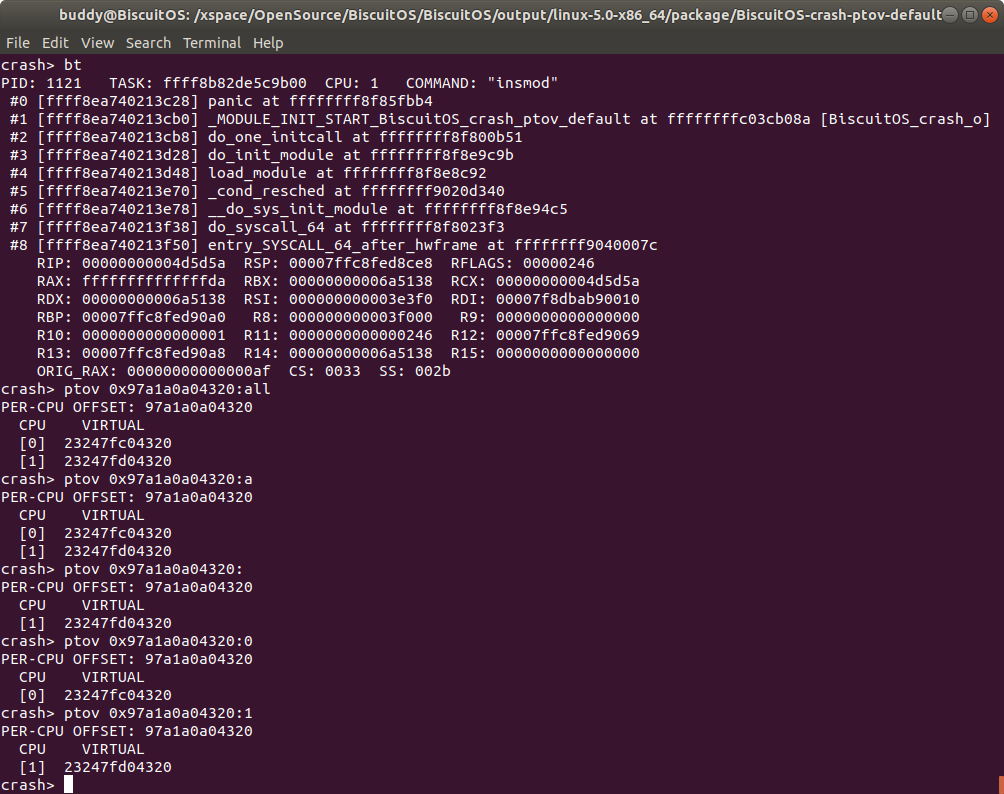
从实践案例的 log 可以看出,PERCPU 的物理地址是 0x97a1a0a04320,通过 ptov 工具转换查看该 PERCPU 在所有 CPU 上的虚拟地址,可以看出 CPU 0 上的虚拟地址是 0x23247fc04320, 而在 CPU 1 上的虚拟地址是 0x23247fd04320. 接着将命令格式中的 cpuspec 设置为其他值进行查看.
vtop <address> 将一个虚拟地址转换成物理地址
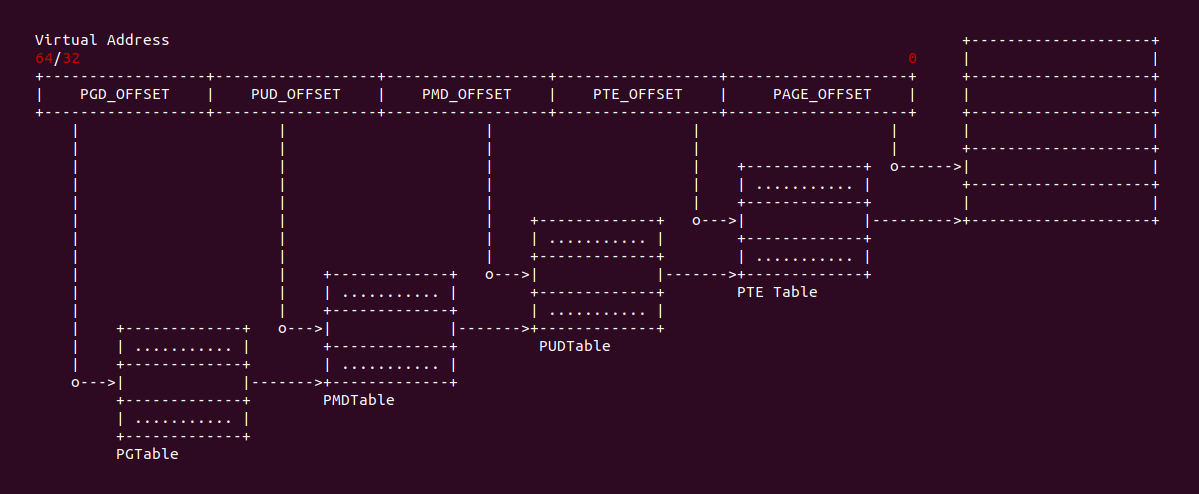
进程的地址空间分为两部分,一部分是进程使用的用户虚拟地址空间,另外一部分是内核使用的虚拟地址空间。用户空间的的虚拟地址只有与物理内存建立页表之后才能进行使用,通常页表时在对虚拟地址访问发生缺页时建立。CRASH 提供的 vtop 工具通过可以基于页表等信息将一个虚拟地址转换成物理地址,并输出 VMA 和各级页表的值,以及 PTE 页表内容。该命令的格式如下:
crash> vtop address
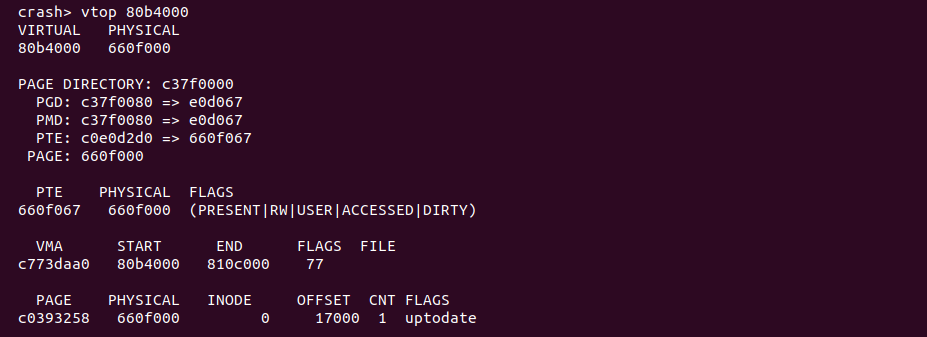
当 vtop 使用上面的命令在转换一个虚拟地址时,vtop 会基于当前进程自动判断该地址是内核空间虚拟地址还有用户空间虚拟地址,如果页表存在,那么 vtop 就会输出上图的内容,首先是虚拟地址和物理地址的内容,接着是 PGD/PMD/PTE/PAGE 的地址以及内容,然后是 PTE 页表的内容、PTE 包含的物理地址以及 PTE 页表的置位信息。vtop 还输出了包含当前进程包含该虚拟地址的 struct vm_area_struct 的地址、起始和结束地址、VMA 的 flags 信息、以及 VMA 对应的文件信息。vtop 最后还会输出物理地址对应的物理页信息,包含了物理页 struct page 的地址、物理地址、物理页所在的 NUMA NODE 等信息. 当当前进程的虚拟地址没有绑定物理内存,那么 vtop 将显示该虚拟地址没有被访问过:

vtop -u <address> 将一个用户空间的虚拟地址转换成物理地址
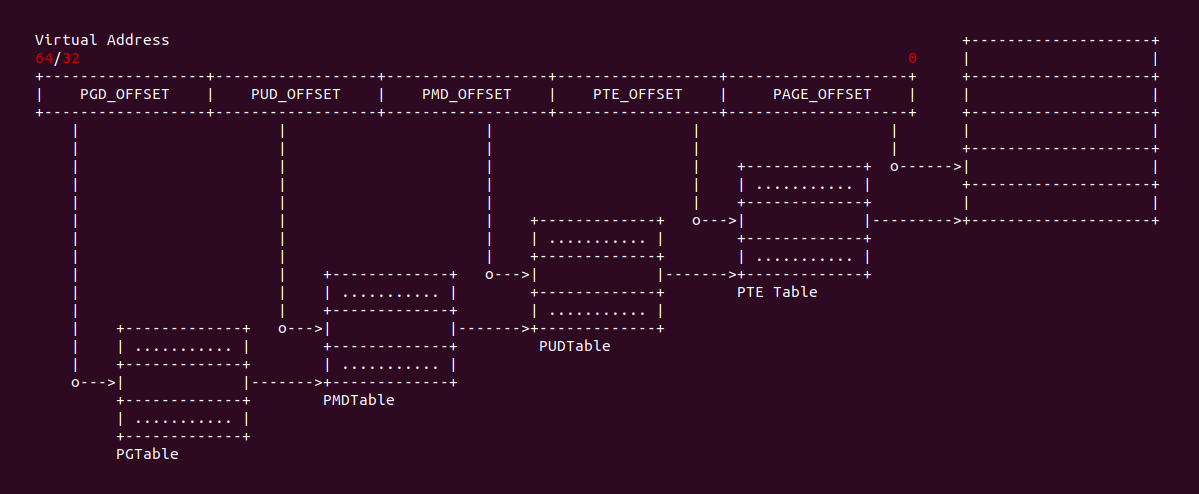
进程的地址空间分为两部分,一部分是进程使用的用户虚拟地址空间,另外一部分是内核使用的虚拟地址空间。用户空间的的虚拟地址只有与物理内存建立页表之后才能进行使用,通常页表时在对虚拟地址访问发生缺页时建立。CRASH 提供的 vtop 工具通过可以基于页表等信息将一个虚拟地址转换成物理地址,并输出 VMA 和各级页表的值,以及 PTE 页表内容。该命令的格式如下:
crash> vtop -u address
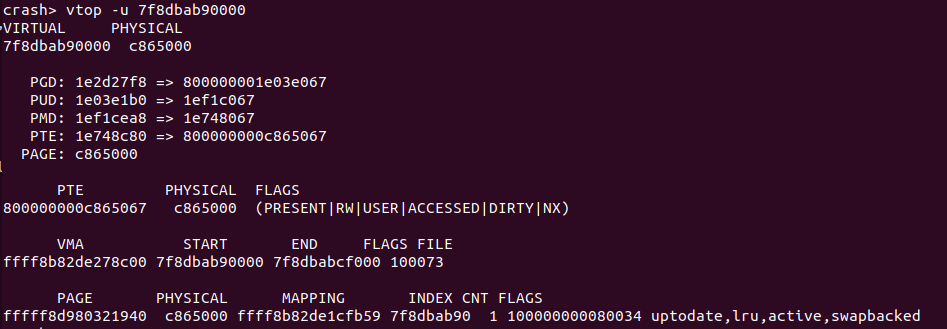
当 vtop 使用上面的命令在转换一个用户空间虚拟地址时,如果页表存在,那么 vtop 就会输出上图的内容,首先是虚拟地址和物理地址的内容,接着是 PGD/PMD/PTE/PAGE 的地址以及内容,然后是 PTE 页表的内容、PTE 包含的物理地址以及 PTE 页表的置位信息。vtop 还输出了包含当前进程包含该虚拟地址的 struct vm_area_struct 的地址、起始和结束地址、VMA 的 flags 信息、以及 VMA 对应的文件信息。vtop 最后还会输出物理地址对应的物理页信息,包含了物理页 struct page 的地址、物理地址、物理页所在的 NUMA NODE 等信息. 当当前进程的虚拟地址没有绑定物理内存,那么 vtop 将显示该虚拟地址没有被访问过:

在 BiscuitOS 中提供了一个实践案例用于介绍该命令的使用,其部署流程如下 (以 linux 5.0 X86_64 为例):
cd BiscuitOS
make linux-5.0-x86_64_defconfig
make menuconfig
[*] Package --->
[*] CRASH and BUG Example --->
[*] Example: vtop translate user address --->
BiscuitOS/output/linux-5.0-x86_64/package/BiscuitOS-crash-vtop-user-address-default
实践例子为一个应用程序,在 main() 函数内,程序从 malloc() 分配一段虚拟内存,在打印该虚拟内容之后程序进程死循环,以此获得内核核心转储文件。接着在 BiscuitOS 上实践该案例,并使用 CRASH 进行调试:
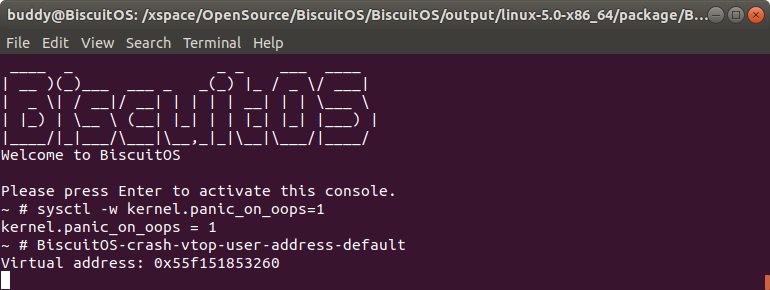
在 BiscuitOS 上运行实例之前,先将 PANIC 的 OOPS 选项设置为 1,以免 OOPS 被 killed,具体命令 “sysctl -w kernel.panic_on_oops=1”. 接着运行应用程序 BiscuitOS-crash-vtop-user-address-default, 此时程序进入死循环,此时通过不同的方法获得内核核心转储文件,并对其进行分析:
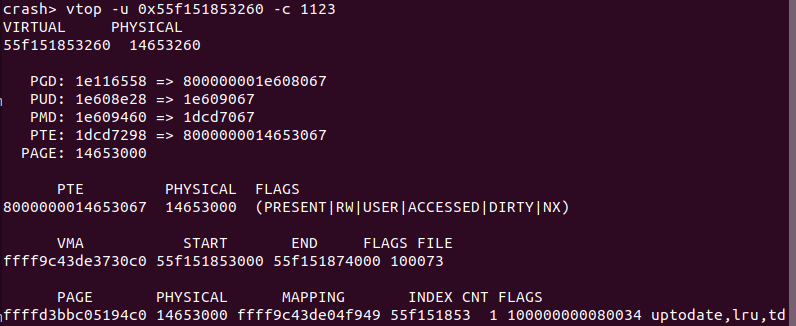
从实践案例运行情况可知,进程获得的虚拟地址是 0x55f151853260, 那么使用 vtop 查看 0x55f151853260 对应的物理地址,当使用 “vtop -u 0x55f151853260” 进行查询,结果显示虚拟地址没有被访问过,那时因为当前进程是 CPU 0 上的 “swapper/1” 进程,那么此时使用 “-c” 选项绑定到 BiscuitOS-crash-vtop-user-address-default 进程,此时使用命令 “vtop -u 0x55f151853260 -c 1123”, 此时可以到所需的各种信息.
vtop -k <address> 将一个内核空间的虚拟地址转换成物理地址
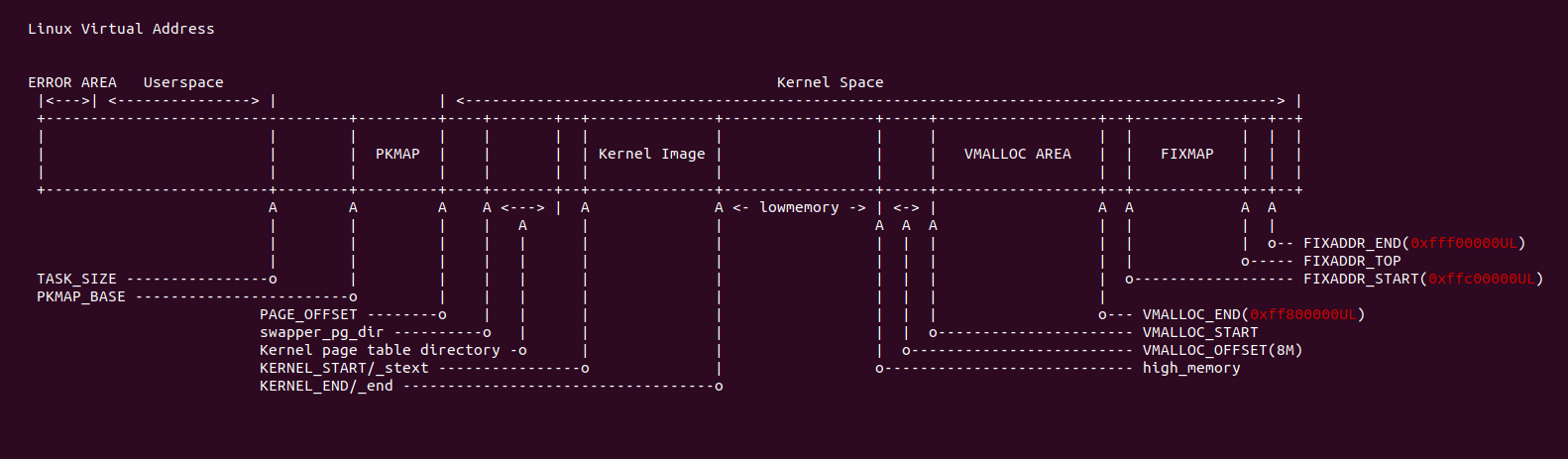
进程的地址空间分为两部分,一部分是进程使用的用户虚拟地址空间,另外一部分是内核使用的虚拟地址空间。对于内核空间的虚拟地址,所有进程看到的都是一致的,另外内核空间的虚拟地址划分为多个区域,例如 VMALLOC 区域、PKMAP 区域、FIXMAP 区域、线性映射区域等,在每个区域中虚拟地址可能已经与物理地址建立好页表可以直接访问,有的区域则需要动态分配并动态建立页表。CRASH 提供的 vtop 工具通过可以基于页表等信息将一个内核空间的虚拟地址转换成物理地址,并输出页表以及 PTE 页表内容。该命令的格式如下:
crash> vtop -k address
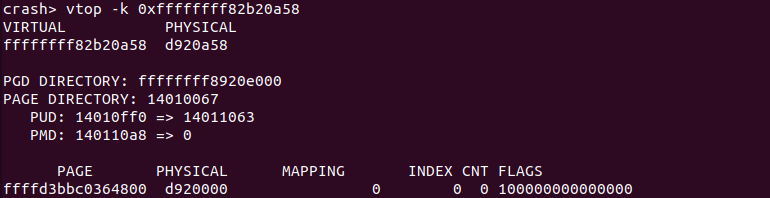
当 vtop 使用上面的命令转换一个内核空间的虚拟地址时,如果页表存在,那么 vtop 将输出虚拟地址和物理地址的信息、PGD/PMD/PTE 页表的地址和内容,并输出 PTE 页表的具体内容,最后输出物理页的信息。如果一个虚拟地址不是内核地址,那么 vtop 将进行提示:

在 BiscuitOS 中提供了一个实践案例用于介绍该命令的使用,其部署流程如下 (以 linux 5.0 X86_64 为例):
cd BiscuitOS
make linux-5.0-x86_64_defconfig
make menuconfig
[*] Package --->
[*] CRASH and BUG Example --->
[*] Example: vtop translate kernel address --->
BiscuitOS/output/linux-5.0-x86_64/package/BiscuitOS-crash-vtop-kernel-address-default
实践例子为一个独立模块,在模块的初始化函数 BiscuitOS_init() 内,模块从 kmalloc() 函数申请了一段内存,并通过 virt_to_phys() 函数获得对应的物理地址,并将两个地址都打印出来。在打印内容之后程序触发 PANIC,以此获得内核核心转储文件。接着在 BiscuitOS 上实践该案例,并使用 CRASH 进行调试:
在 BiscuitOS 上运行实例之前,先将 PANIC 的 OOPS 选项设置为 1,以免 OOPS 被 killed,具体命令 “sysctl -w kernel.panic_on_oops=1”. 接着加载内核模块 BiscuitOS-crash-vtop-kernel-address-default.ko,此时通过不同的方法获得内核核心转储文件,并对其进行分析:
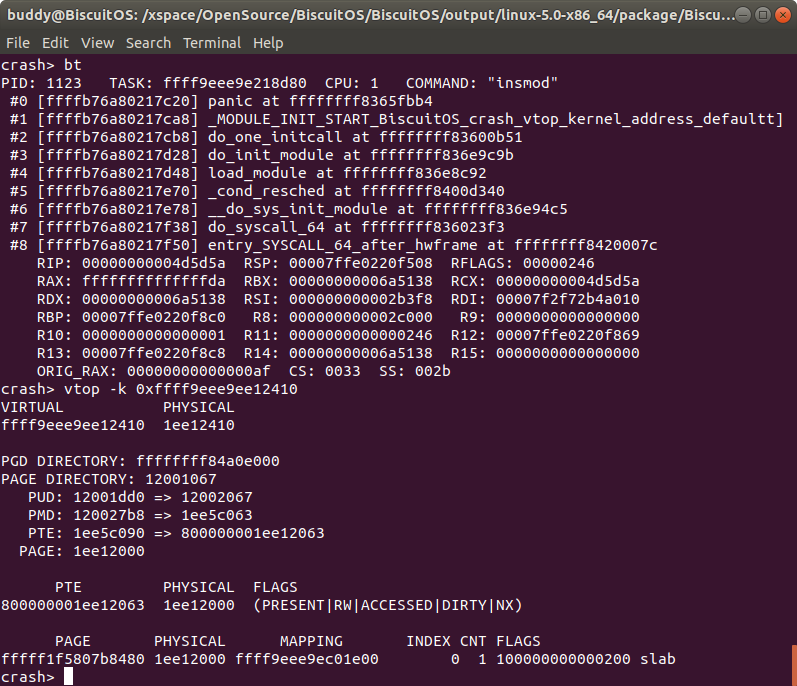
从实践的 log 可以看出,分配的虚拟地址是 0xffff9eee9ee12410, 其对应的物理地址是 0x1ee12410, 此时使用 vtop 进行转换,可以看到虚拟地址和物理地址与程序运行的一致。另外还可以获得内核虚拟地址对应的 PGD/PUD/PMD/PTE 页表的地址与内容,并打印了 PTE 页表位图信息,最后还打印了物理地址和物理页的信息。
vtop -c pid <address> 将某个进程的虚拟地址转换成物理地址
进程的地址空间分为两部分,一部分是进程使用的用户虚拟地址空间,另外一部分是内核使用的虚拟地址空间。用户空间的的虚拟地址只有与物理内存建立页表之后才能进行使用,通常页表时在对虚拟地址访问发生缺页时建立。CRASH 提供的 vtop 工具可以基于不同的进程将一个用户空间的虚拟地址转换成物理地址。该命令的格式如下:
crash> vtop -c pid -u address
当 vtop 使用上面的命令在转换一个用户空间指定进程的虚拟地址时,如果页表存在,那么 vtop 就会输出上图的内容,首先是虚拟地址和物理地址的内容,接着是 PGD/PMD/PTE/PAGE 的地址以及内容,然后是 PTE 页表的内容、PTE 包含的物理地址以及 PTE 页表的置位信息。vtop 还输出了包含指定进程包含该虚拟地址的 struct vm_area_struct 的地址、起始和结束地址、VMA 的 flags 信息、以及 VMA 对应的文件信息。vtop 最后还会输出物理地址对应的物理页信息,包含了物理页 struct page 的地址、物理地址、物理页所在的 NUMA NODE 等信息. 当指定进程的虚拟地址没有绑定物理内存,那么 vtop 将显示该虚拟地址没有被访问过:

在 BiscuitOS 中提供了一个实践案例用于介绍该命令的使用,其部署流程如下 (以 linux 5.0 X86_64 为例):
cd BiscuitOS
make linux-5.0-x86_64_defconfig
make menuconfig
[*] Package --->
[*] CRASH and BUG Example --->
[*] Example: vtop translate user address with PID --->
BiscuitOS/output/linux-5.0-x86_64/package/BiscuitOS-crash-vtop-pid-user-address-default
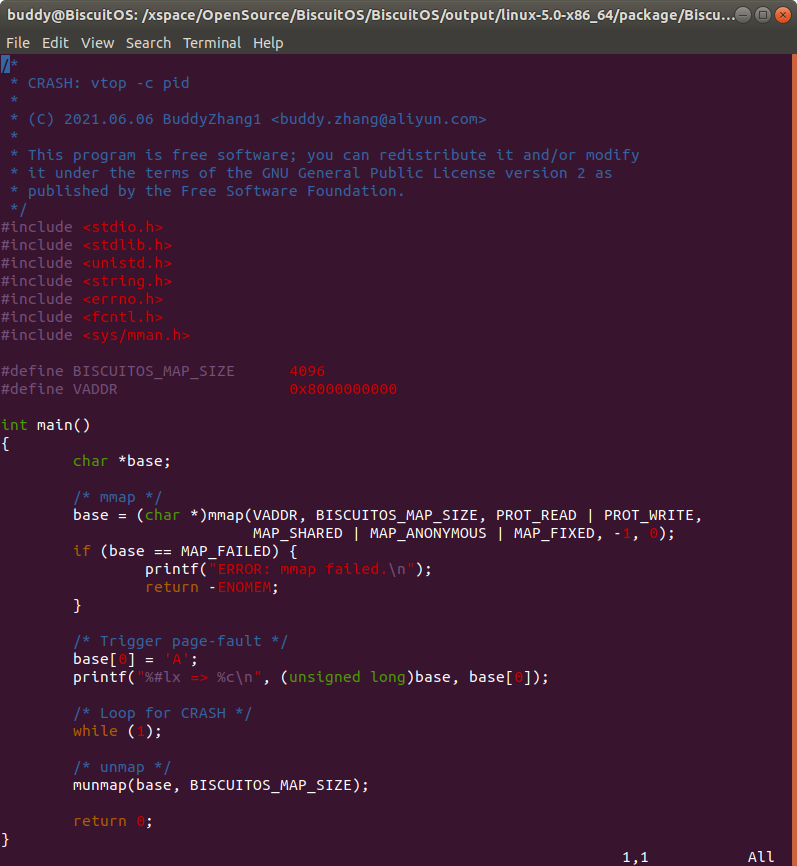
实践例子为一个应用程序,通过匿名共享映射的方式分配了一段虚拟内存,并对虚拟内存进行写操作,最后打印写入的虚拟内存地址和对应的值。在打印该虚拟内容之后程序进程死循环,以此获得内核核心转储文件。接着在 BiscuitOS 上实践该案例,并使用 CRASH 进行调试:
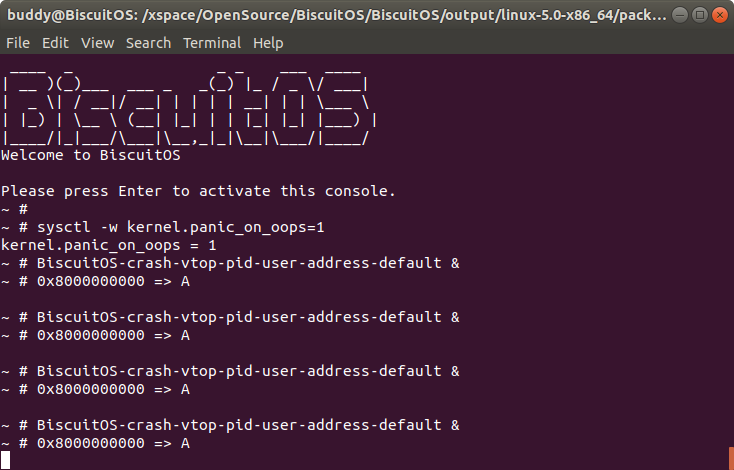
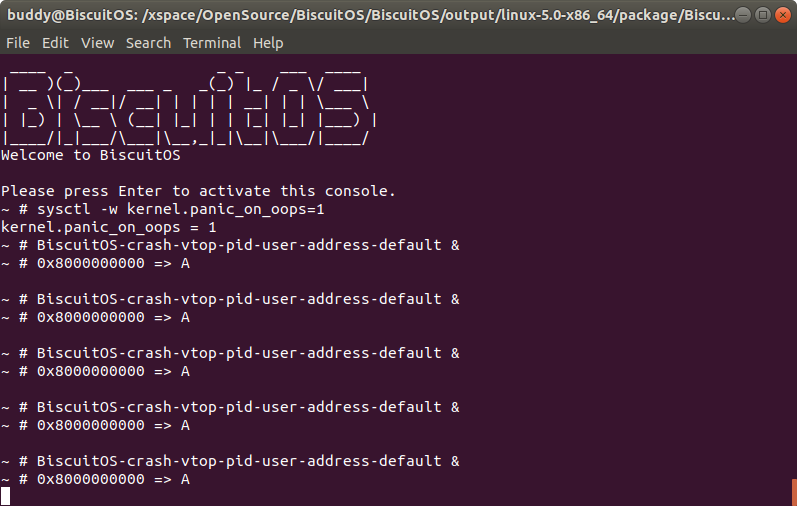
在 BiscuitOS 上运行实例之前,先将 PANIC 的 OOPS 选项设置为 1,以免 OOPS 被 killed,具体命令 “sysctl -w kernel.panic_on_oops=1”. 接着以压后台的方式多次运行应用程序 BiscuitOS-crash-vtop-pid-user-address-default, 此时程序进入死循环,此时通过不同的方法获得内核核心转储文件,并对其进行分析:
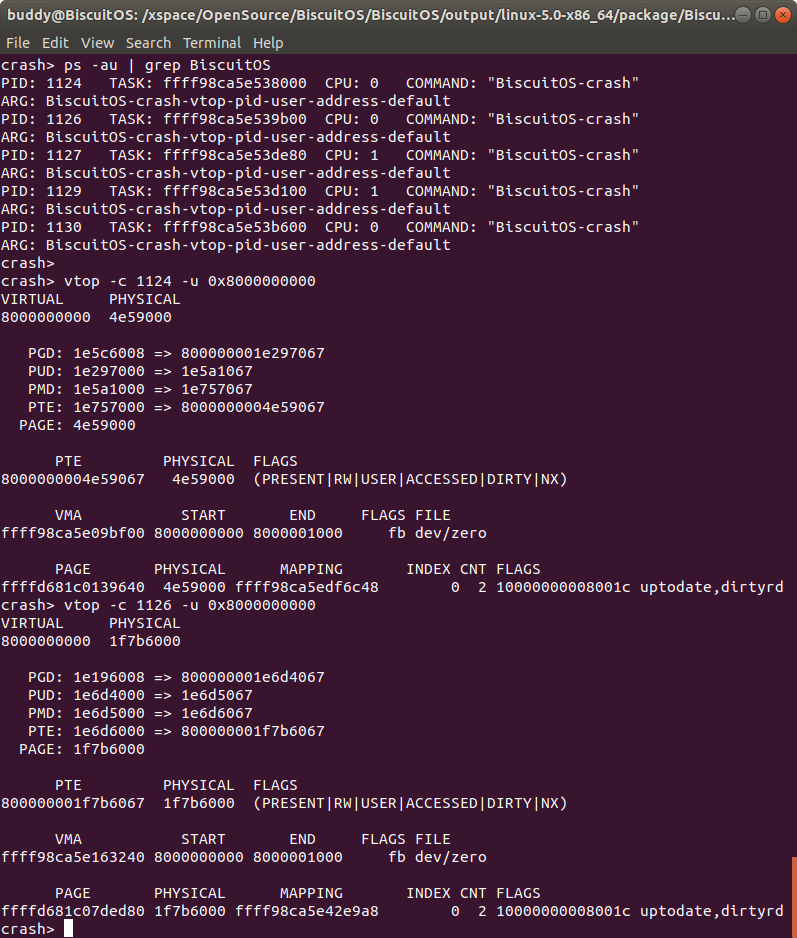
从实践案例运行情况可以,BiscuitOS-crash-vtop-pid-user-address-default 程序运行了 5 次,每次获得的虚拟地址都是 0x8000000000, 此时首先在 CRASH 中通过 ps 命令查看进程的 PID,然后使用 vtop 命令查看 0x8000000000 对应的物理内存。上图实例中查看了 PID 为 1124 和 1126 的进程,虽然虚拟地址相同,但物理地址却不相同。因此该命令可以很便捷的获得指定进程的虚拟地址到物理地址映射信息.
vtop -c taskp <address> 将某个进程的虚拟地址转换成物理地址
进程的地址空间分为两部分,一部分是进程使用的用户虚拟地址空间,另外一部分是内核使用的虚拟地址空间。用户空间的的虚拟地址只有与物理内存建立页表之后才能进行使用,通常页表时在对虚拟地址访问发生缺页时建立。CRASH 提供的 vtop 工具可以基于不同的进程将一个用户空间的虚拟地址转换成物理地址。该命令的格式如下:
crash> vtop -c taskp -u address
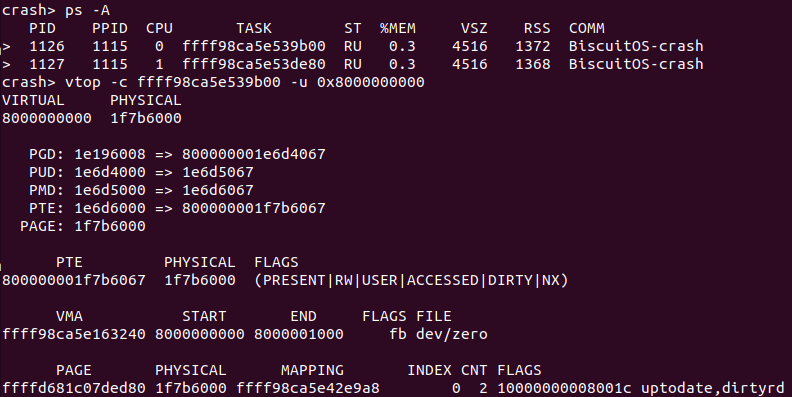
当 vtop 使用上面的命令在转换一个用户空间指定进程的虚拟地址时,如果页表存在,那么 vtop 就会输出上图的内容,首先是虚拟地址和物理地址的内容,接着是 PGD/PMD/PTE/PAGE 的地址以及内容,然后是 PTE 页表的内容、PTE 包含的物理地址以及 PTE 页表的置位信息。vtop 还输出了包含指定进程包含该虚拟地址的 struct vm_area_struct 的地址、起始和结束地址、VMA 的 flags 信息、以及 VMA 对应的文件信息。vtop 最后还会输出物理地址对应的物理页信息,包含了物理页 struct page 的地址、物理地址、物理页所在的 NUMA NODE 等信息. 当指定进程的虚拟地址没有绑定物理内存,那么 vtop 将显示该虚拟地址没有被访问过:

在 BiscuitOS 中提供了一个实践案例用于介绍该命令的使用,其部署流程如下 (以 linux 5.0 X86_64 为例):
cd BiscuitOS
make linux-5.0-x86_64_defconfig
make menuconfig
[*] Package --->
[*] CRASH and BUG Example --->
[*] Example: vtop translate user address with PID --->
BiscuitOS/output/linux-5.0-x86_64/package/BiscuitOS-crash-vtop-pid-user-address-default
实践例子为一个应用程序,通过匿名共享映射的方式分配了一段虚拟内存,并对虚拟内存进行写操作,最后打印写入的虚拟内存地址和对应的值。在打印该虚拟内容之后程序进程死循环,以此获得内核核心转储文件。接着在 BiscuitOS 上实践该案例,并使用 CRASH 进行调试:
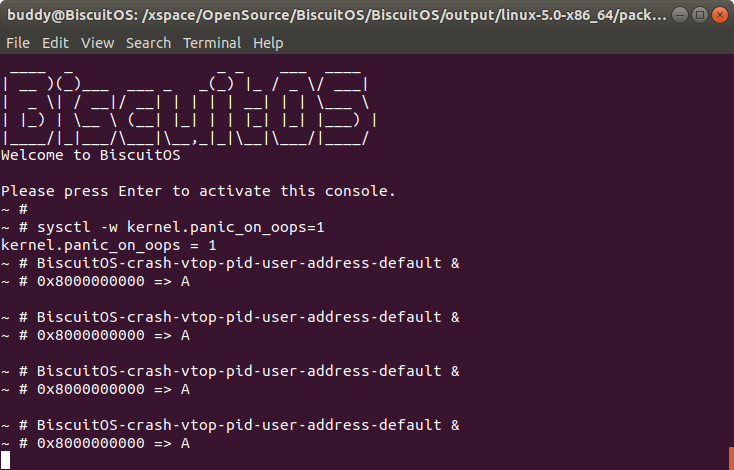
在 BiscuitOS 上运行实例之前,先将 PANIC 的 OOPS 选项设置为 1,以免 OOPS 被 killed,具体命令 “sysctl -w kernel.panic_on_oops=1”. 接着以压后台的方式多次运行应用程序 BiscuitOS-crash-vtop-pid-user-address-default, 此时程序进入死循环,此时通过不同的方法获得内核核心转储文件,并对其进行分析:
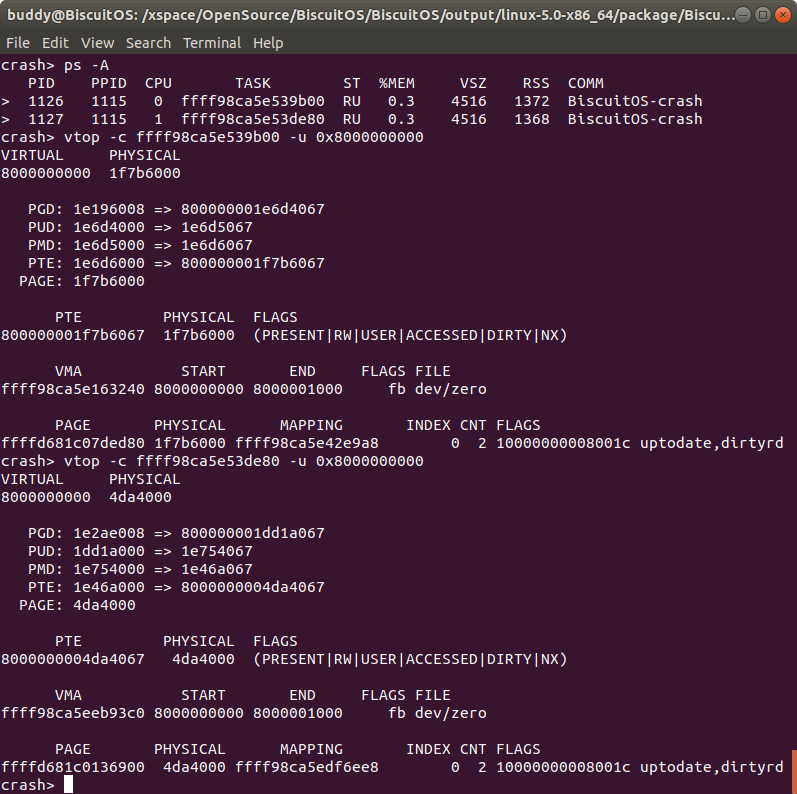
从实践案例运行情况可以,BiscuitOS-crash-vtop-pid-user-address-default 程序运行了 5 次,每次获得的虚拟地址都是 0x8000000000, 此时首先在 CRASH 中通过 ps 命令查看进程的进程描述符,然后使用 vtop 命令查看 0x8000000000 对应的物理内存。上图实例中查看了进程描述符为 ffff98ca5e539b00 和 ffff98ca5e53de80 的进程,虽然虚拟地址相同,但物理地址却不相同。因此该命令可以很便捷的获得指定进程的虚拟地址到物理地址映射信息.
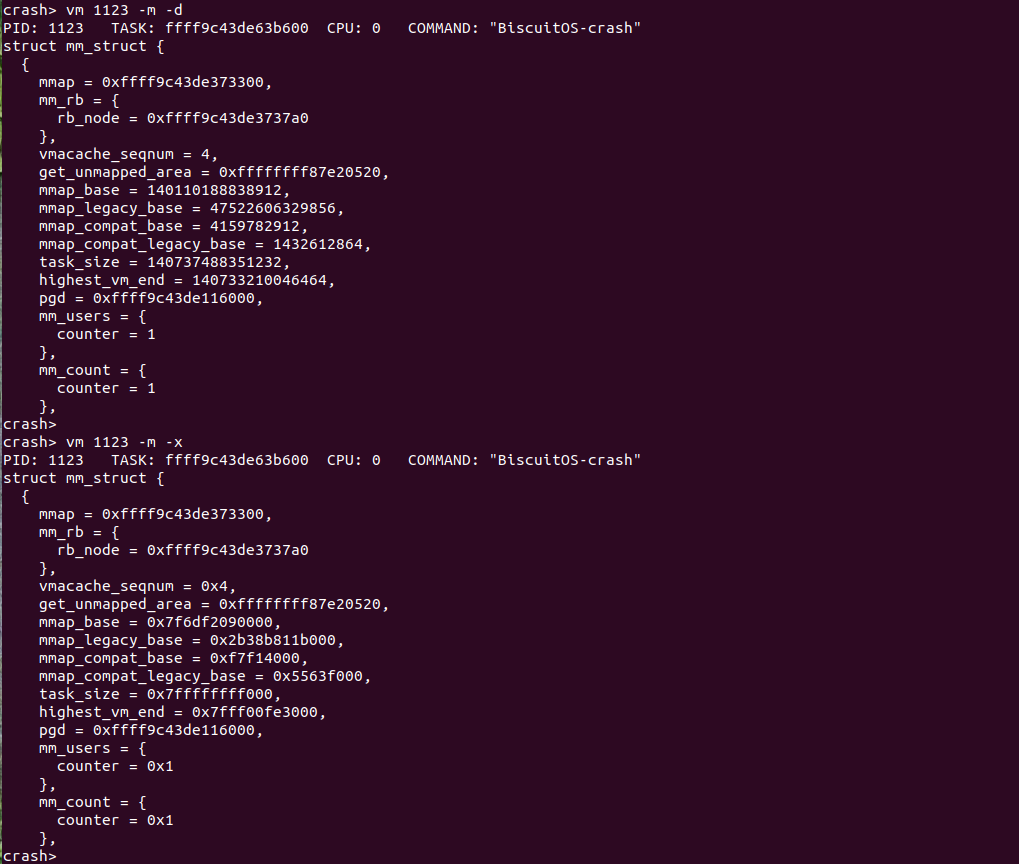
vm 获得当前进程用户空间的虚拟区域信息

用户进程的地址空间有多个区域组成,这些区域称为虚拟区域 VMA。每个 VMA 维护了一段虚拟内存,并用于指定的任务,例如用于存储进程代码段的 VMA、用于存储进程数据的 VMA 等。CRASH 提供了 vm 命令可以获得当前 CPU 上运行进程的用户进程虚拟区域信息,其命令格式如下:
crash> vm
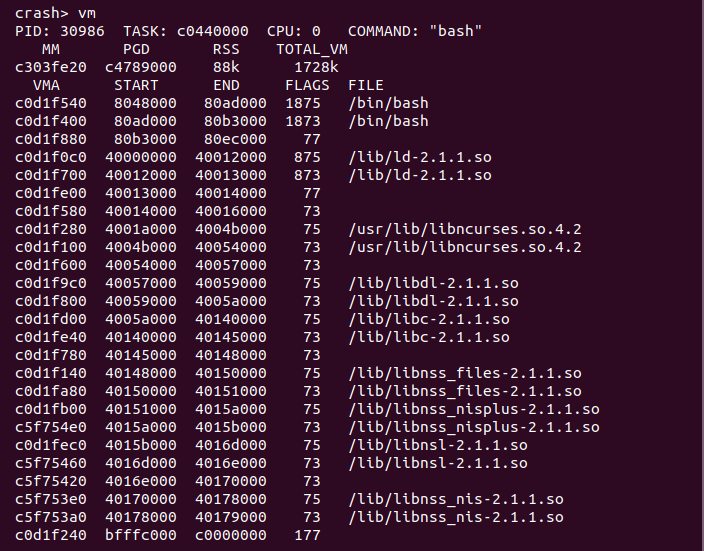
vm 命令之后没有跟任何参数,这个时候就读取当前 CPU 上运行的进程的虚拟区域信息。CRASH vm 命令将展示一下信息:
- PID 进程 ID
- TASK 进程描述符 struct task_struct 的虚拟地址
- CPU 当前 CPU ID
- COMMAND 当前进程运行的命令名字命令名字
- MM 进程地址空间描述符 struct mm_struct 的地址
- PGD 进程 PGD 页表入口的地址
- RSS 进程使用物理内存的数量
- TOTAL_VM 进程占用的虚拟内存数量
- VMA 虚拟区域的描述符 struct vm_area_struct 的虚拟地址
- START 虚拟区域的起始地址
- END 虚拟区域的结束地址
- FLAGS 虚拟区域标志
- FILE 虚拟区域映射的文件
如果当前 CPU 上运行的是内核线程,那么内核线程不包含任何用户空间虚拟内存的信息,其展示信息如下:

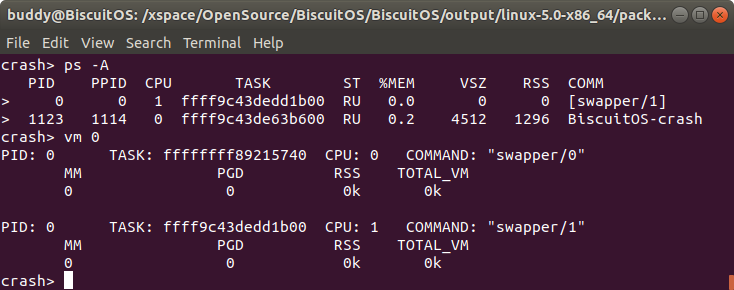
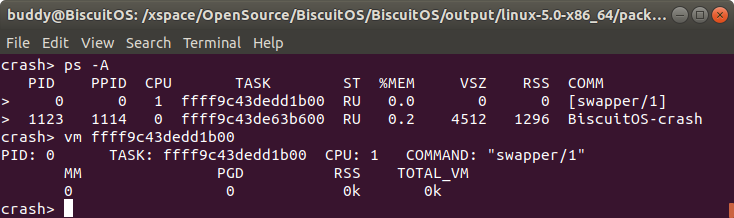
vm pid 通过进程 ID 获得指定进程用户空间的虚拟区域信息

用户进程的地址空间有多个区域组成,这些区域称为虚拟区域 VMA。每个 VMA 维护了一段虚拟内存,并用于指定的任务,例如用于存储进程代码段的 VMA、用于存储进程数据的 VMA 等。CRASH 提供了 vm 命令可以通过进程 ID 获得指定进程的虚拟区域信息,其命令格式如下:
crash> vm pid
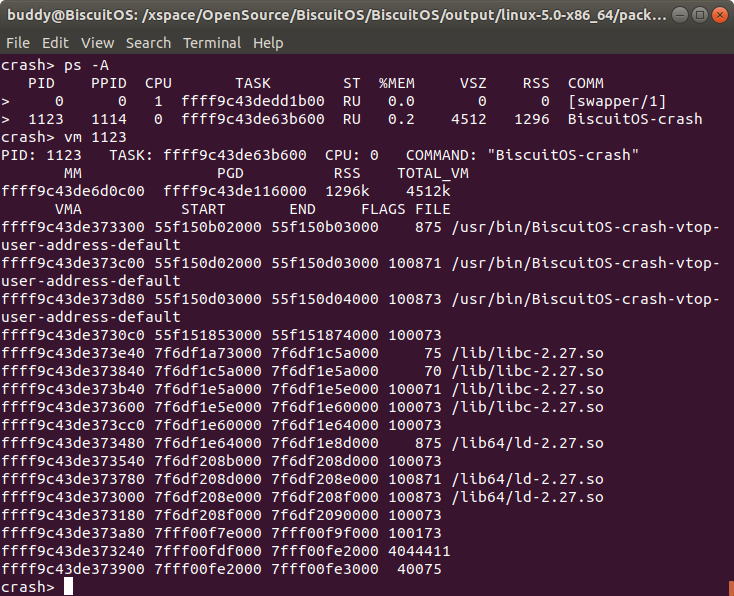
vm 命令之后跟随进程描述符地址,这个时候将输出指定进程的用户空间虚拟区域信息。CRASH vm 命令将展示一下信息:
- PID 进程 ID
- TASK 进程描述符 struct task_struct 的虚拟地址
- CPU 当前 CPU ID
- COMMAND 当前进程运行的命令名字命令名字
- MM 进程地址空间描述符 struct mm_struct 的地址
- PGD 进程 PGD 页表入口的地址
- RSS 进程使用物理内存的数量
- TOTAL_VM 进程占用的虚拟内存数量
- VMA 虚拟区域的描述符 struct vm_area_struct 的虚拟地址
- START 虚拟区域的起始地址
- END 虚拟区域的结束地址
- FLAGS 虚拟区域标志
- FILE 虚拟区域映射的文件
如果 pid 对应的 TASK 是一个内核线程,那么内核线程不包含任何用户空间虚拟内存的信息,其展示信息如下:
vm taskp 通过进程描述符获得进程用户空间虚拟区域信息

用户进程的地址空间有多个区域组成,这些区域称为虚拟区域 VMA。每个 VMA 维护了一段虚拟内存,并用于指定的任务,例如用于存储进程代码段的 VMA、用于存储进程数据的 VMA 等。CRASH 提供了 vm 命令可以通过进程描述符获得指定进程的虚拟区域信息,其命令格式如下:
crash> vm taskp
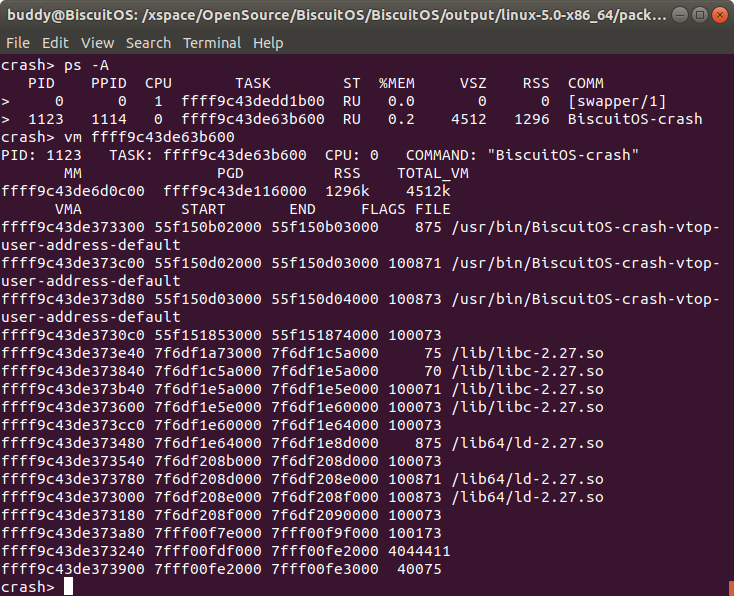
vm 命令之后跟随进程描述符地址,这个时候将输出指定进程的用户空间虚拟区域信息。CRASH vm 命令将展示一下信息:
- PID 进程 ID
- TASK 进程描述符 struct task_struct 的虚拟地址
- CPU 当前 CPU ID
- COMMAND 当前进程运行的命令名字命令名字
- MM 进程地址空间描述符 struct mm_struct 的地址
- PGD 进程 PGD 页表入口的地址
- RSS 进程使用物理内存的数量
- TOTAL_VM 进程占用的虚拟内存数量
- VMA 虚拟区域的描述符 struct vm_area_struct 的虚拟地址
- START 虚拟区域的起始地址
- END 虚拟区域的结束地址
- FLAGS 虚拟区域标志
- FILE 虚拟区域映射的文件
如果 taskp 对应的 TASK 是一个内核线程,那么内核线程不包含任何用户空间虚拟内存的信息,其展示信息如下:
vm -p 打印进程所有虚拟区域到物理内存的映射关系

用户进程的地址空间有多个区域组成,这些区域称为虚拟区域 VMA。每个 VMA 维护了一段虚拟内存,并用于指定的任务,例如用于存储进程代码段的 VMA、用于存储进程数据的 VMA 等。VMA 可以映射一段物理内存,也可能映射一段文件,CRASH 提供了 vm 可以打印进程所有虚拟区域的映射关系,这个映射关系包括虚拟内存到物理内存的映射关系,也可能是虚拟地址到映射文件的映射关系,具体命令格式如下:
crash> vm -p
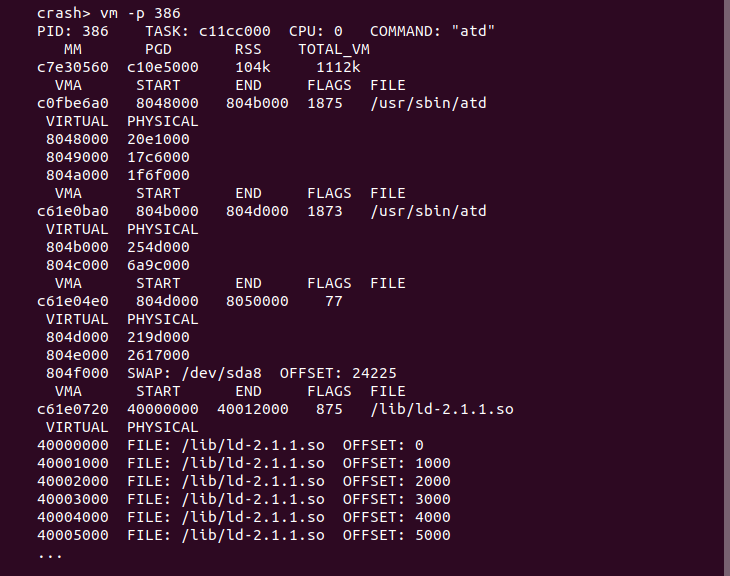
vm 命令之后跟上 “-p” 选项之后,CRASH 将打印当前 CPU 上进程的所有虚拟区域的映射关系。如果想打印某个进程的虚拟区域映射关系,可以在命令之后添加进程的 PID 或者进程描述符 taskp. CASH vm 命令将展示一下信息:
- PID 进程 ID
- TASK 进程描述符 struct task_struct 的虚拟地址
- CPU 当前 CPU ID
- COMMAND 当前进程运行的命令名字命令名字
- MM 进程地址空间描述符 struct mm_struct 的地址
- PGD 进程 PGD 页表入口的地址
- RSS 进程使用物理内存的数量
- TOTAL_VM 进程占用的虚拟内存数量
- VMA 虚拟区域的描述符 struct vm_area_struct 的虚拟地址
- START 虚拟区域的起始地址
- END 虚拟区域的结束地址
- FLAGS 虚拟区域标志
- FILE 虚拟区域映射的文件
如果 taskp 对应的 TASK 是一个内核线程,那么内核线程不包含任何用户空间虚拟内存的信息,其展示信息如下:

在显示每个 VMA 的时候,如果 VMA 映射的是物理内存,那么 CRASH 将打印该虚拟区域内已经映射物理内存的虚拟区域信息,该信息包括虚拟区域的描述符 vmap、虚拟区域的起始地址和结束地址、虚拟区域的标志,最后包括已经映射物理内存的虚拟地址和映射的物理地址. 如果虚拟地址映射的物理内存被交换到 SWAP 空间,那么会显示 SWAP 空间的位置和 sWAP entry 信息。例如下图:

在显示每个 VMA 的时候,如果 VMA 映射的是文件,那么 CRASH 将打印虚拟区域的描述符地址 vmap、虚拟区域的起始地址和结束地址、虚拟区域的标志、以及虚拟区域映射的文件。接着 CRASH 将打印虚拟地址映射文件的偏移信息:
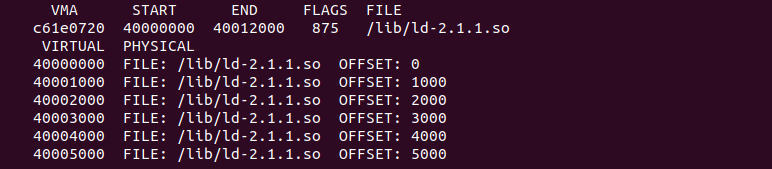
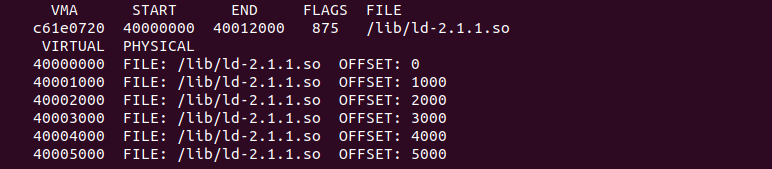
vm -P 打印进程的指定虚拟区域到物理内存的映射关系

用户进程的地址空间有多个区域组成,这些区域称为虚拟区域 VMA。每个 VMA 维护了一段虚拟内存,并用于指定的任务,例如用于存储进程代码段的 VMA、用于存储进程数据的 VMA 等。VMA 可以映射一段物理内存,也可能映射一段文件,CRASH 提供了 vm 可以打印进程所有虚拟区域的映射关系,这个映射关系包括虚拟内存到物理内存的映射关系,也可能是虚拟地址到映射文件的映射关系,与 “vm -p” 命令类似, “vm -p” 显示指定进程所有 VMA 的映射关系,这对于查找指定的 VMA 区域不太友好。CRASH vm 提供了 “-P” 可以查看指定 VMA 的映射关系,具体命令格式如下:
crash> vm -P VMAp
vm 命令之后跟上 “-P VMAp” 选项之后,CRASH 将打印当前 CPU 上进程 VMAp 对应的虚拟区域的映射关系。如果想打印某个进程的虚拟区域映射关系,可以在命令之后添加进程的 PID 或者进程描述符 taskp. CASH vm 命令将展示一下信息:
- PID 进程 ID
- TASK 进程描述符 struct task_struct 的虚拟地址
- CPU 当前 CPU ID
- COMMAND 当前进程运行的命令名字命令名字
- MM 进程地址空间描述符 struct mm_struct 的地址
- PGD 进程 PGD 页表入口的地址
- RSS 进程使用物理内存的数量
- TOTAL_VM 进程占用的虚拟内存数量
- VMA 虚拟区域的描述符 struct vm_area_struct 的虚拟地址
- START 虚拟区域的起始地址
- END 虚拟区域的结束地址
- FLAGS 虚拟区域标志
- FILE 虚拟区域映射的文件
如果 taskp 对应的 TASK 是一个内核线程,那么内核线程不包含任何用户空间虚拟内存的信息,其展示信息如下:

在显示指定 VMA 的时候,如果 VMA 映射的是物理内存,那么 CRASH 将打印该虚拟区域内已经映射物理内存的虚拟区域信息,该信息包括虚拟区域的描述符 vmap、虚拟区域的起始地址和结束地址、虚拟区域的标志,最后包括已经映射物理内存的虚拟地址和映射的物理地址. 如果虚拟地址映射的物理内存被交换到 SWAP 空间,那么会显示 SWAP 空间的位置和 sWAP entry 信息。例如下图:

在显示每个 VMA 的时候,如果 VMA 映射的是文件,那么 CRASH 将打印虚拟区域的描述符地址 vmap、虚拟区域的起始地址和结束地址、虚拟区域的标志、以及虚拟区域映射的文件。接着 CRASH 将打印虚拟地址映射文件的偏移信息:
vm -m 打印用户进程的地址描述符 struct mm_struct 内容

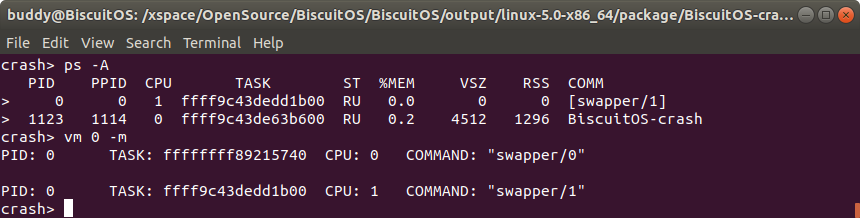
用户进程的地址空间通过地址空间描述符进行描述,其通过 struct mm_struct 进行管理。地址空间描述符记录了进程的虚拟内存信息、页表、VMA 等多种信息,对分析进程的行为有很大的帮助。CRASH 提供了 “ps” 命令可以打印进程描述符,但不能直观的给出进程的地址描述符,因此 CRASH 提供了 “vm -m” 命令可以将指定进程的地址描述符内容打印出来。具体命令格式如下:
crash> vm -m
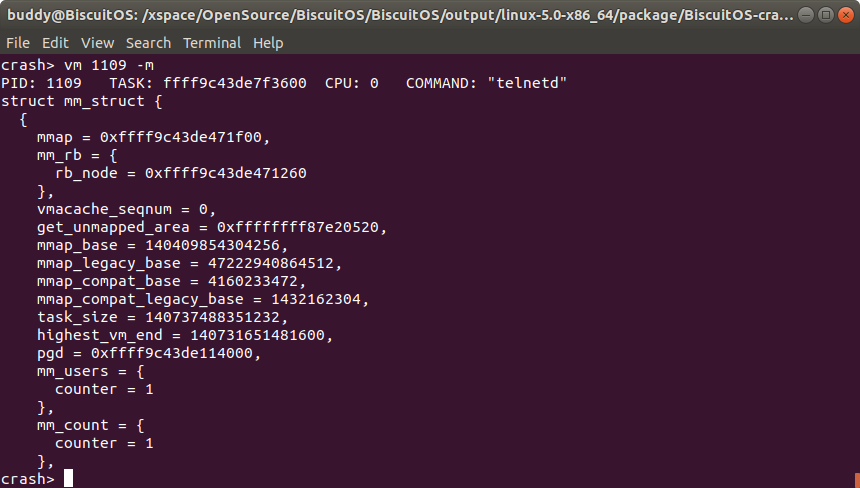
vm 命令之后跟上 “-m” 选项之后,CRASH 将打印当前进程的地址描述符信息,如果需要打印指定进程的地址描述符,那么可以跟上进程 PID 信息。CRASH vm 命令将展示以下信息:
- PID 进程 ID
- TASK 进程描述符 struct task_struct 的虚拟地址
- CPU 当前 CPU ID
- COMMAND 当前进程运行的命令名字命令名字
- struct mm_struct 内容
如果 PID 对应的 TASK 是一个内核线程,那么内核线程不包含用户进程地址空间:
vm -R 在用户进程虚拟内容找查找信息

用户进程的地址空间有多个区域组成,这些区域称为虚拟区域 VMA。每个 VMA 维护了一段虚拟内存,并用于指定的任务,例如用于存储进程代码段的 VMA、用于存储进程数据的 VMA 等。CRASH 提供 vm 命令可以打印进程虚拟内存相关的信息,但信息特别复杂,那么 CRASH 提供了 “vm -R” 选项可以在进程的虚拟内存信息中查找包含内容,具体命令格式如下:
crash> vm -R <reference>

vm 命令之后跟上 “-R” 和要查找的内容,那么 CRASH 将输出当前进程虚拟地址信息中包含指定内容的地方。如果想在指定进程的虚拟内存信息中查找,可以在命令之后添加进程的 PID 信息. 其输出的信息包括:
- PID 进程 ID
- TASK 进程描述符 struct task_struct 的虚拟地址
- CPU 当前 CPU ID
- COMMAND 当前进程运行的命令名字命令名字
- MM 进程地址空间描述符 struct mm_struct 的地址
- PGD 进程 PGD 页表入口的地址
- RSS 进程使用物理内存的数量
- TOTAL_VM 进程占用的虚拟内存数量
- VMA 虚拟区域的描述符 struct vm_area_struct 的虚拟地址
- START 虚拟区域的起始地址
- END 虚拟区域的结束地址
- FLAGS 虚拟区域标志
- FILE 虚拟区域映射的文件
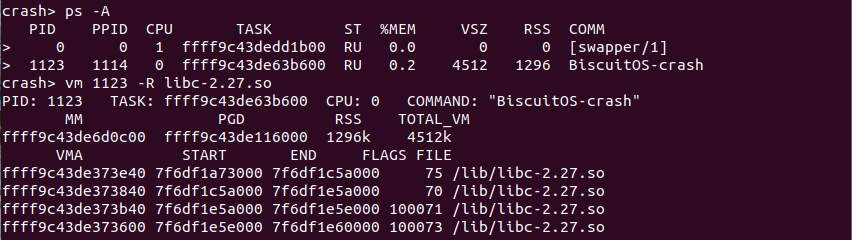
vm -R filename 命令可以查找映射了文件 libc-2.27.so 的 VMA 信息
vm -R vaddr 命令可以查找进程包含虚拟地址的 VMA 信息:

vm -R flags 命令可以查找 VMA Flags 为指定值的 VMA 信息:
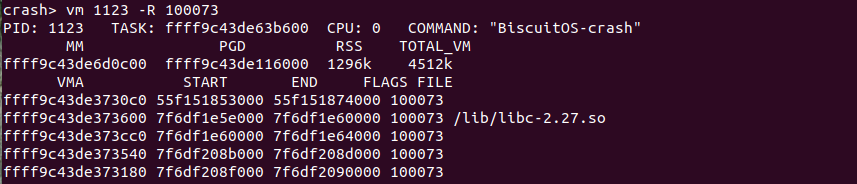
vm -R phys 命令可以查找映射该物理地址的虚拟地址信息:

vm -R vmap 命令 vmap 的虚拟区域信息:

vm -v 打印进程所有 VMA 描述符内容

用户进程的地址空间有多个区域组成,这些区域称为虚拟区域 VMA。每个 VMA 维护了一段虚拟内存,并用于指定的任务,例如用于存储进程代码段的 VMA、用于存储进程数据的 VMA 等。内核使用 struct vm_area_struct 结构体描述一个 VMA,CRASH vm 提供了命令可以将用户进程所有的虚拟区域描述符的内容打印出来,具体命令如下:
crash> vm -v
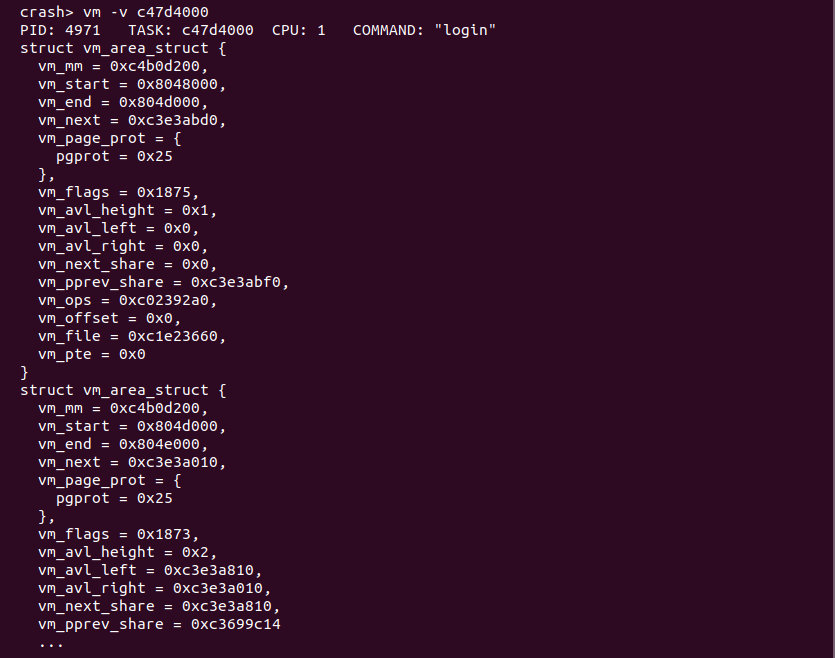
vm 命令之后跟上 “-v” 选项之后,CRASH 将打印当前 CPU 上进程的所有虚拟区域描述符的内容,如果想查找指定进程的话,可以在命令之后跟上进程的 PID 或者 taskp 内容。此时可以使用 CRASH 提供的 struct 命令查看 struct vm_area_struct 结构体定义.
vm -f 解码虚拟区域标志
用户进程的地址空间有多个区域组成,这些区域称为虚拟区域 VMA。每个 VMA 维护了一段虚拟内存,并用于指定的任务,例如用于存储进程代码段的 VMA、用于存储进程数据的 VMA 等。内核使用 struct vm_area_struct 结构体描述一个 VMA,每个虚拟区域都有不同的属性,有的可读、有的可行、有的可执行等,这些标志通过虚拟区域标志集合进行维护。CRASH 提供了 “vm -f” 命令用于将虚拟区域标志集合转换为字符串形式,以便使用。具体命令如下:
crash> vm -f <flags>

- READ: PROT_READ VMA 可读
- WRITE: PROT_WRITE VMA 可写
- EXEC: PROT_EXEC VMA 可执行
- SHARED: MAP_SHARED VMA 共享映射
- MAYREAD: MAY_READ VMA 也许可读
- MAYWRITE: MAY_WRITE VMA 也许可写
- MAYEXEC: MAY_EXEC VMA 也许可写
- MAYSHARE: VMA 也许是共享映射
- GROWDOWN: PROT_GROWSDOWN VMA 向下生长
- NOHUGEPAGE: MADV_NOHUGEPAGE 非大页映射
- PFNMAP: VM_PFNMAP PFN 映射,没有 struct page.
- DENYWRITE: 禁止写入
- EXECUTABLE: 可执行的
- LOCKED: VM_LOCKED VMA 被锁住了
- IO: VM_IO IO 映射
- SEQ_READ: 串行读
vm -d/-x 输出内容格式控制
当使用 CRASH 提供的 vm 命令查看虚拟区域描述符或者地址空间描述符的时候,为了方便查看,CRASH vm 命令提供了输出格式选项,其中 “-d” 选项以十进制方式输出内容、”-x” 选项以十六进制方式输出内容:
pte <conteents> 解码 PTE 内容
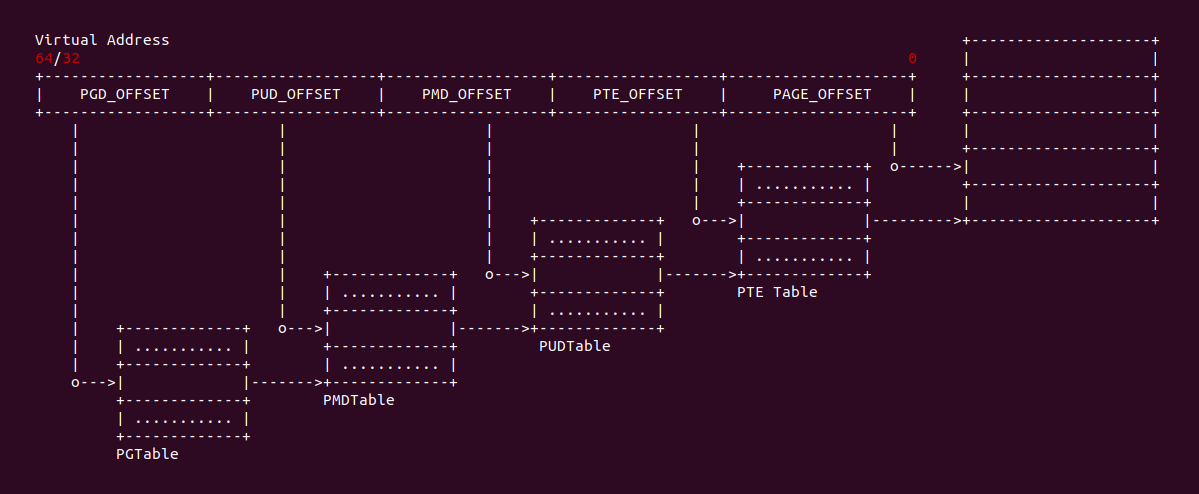
虚拟内存与物理内存之间通过页表进行映射,在有的架构中页表有两级页表,分别是 PGD/PTE,有的有三级页表 PGD/PMD/PTE, 有的有四级页表 PGD/PUD/PMD/PTE, 有的架构有五级页表 PGD/P4D/PUD/PMD/PTE. 无论几级页表,在页大小都是 4KiB 的情况下,最后一级页表都是 PTE。CRASH 提供了 pte 命令用来解码 PTE 页表项中的内容,其命令格式如下:
crash> pte content

CRASH 提供的 pte 命令将一个十六进制的 PTE 页表内容进行解码,解码之后可以获得 PTE 对应的物理页以及 PTE 页表的标志。如果 PTE 对应的物理页表位于 SWAP 中,那么 CRASH 将输出物理页在 SWAP 中偏移以及 SWAP 的设备名.
Crash 打印表达式的值
当使用 CRASH 分析内核转储文件时,需要查看某些变量或者表达式的值,CRASH 提供了 “p” 命令,该命令类似 print 的作用,将会打印变量的值,这对问题的分析起到了很大的作用。该命令格式如下:
# SYNOPSIS
p [-x|-d][-u] [expression | symbol[:cpuspec]]
本节以手动触发 Panic 为例进行实践讲解。在 BiscuitOS 上通过输入 “echo c > /proc/sysrq-trigger” 来触发内核崩溃,并对转储文件为例进行分析:
p symobl 打印符号的值

CRASH 提供的 “p symbol” 命令可以打印 symbol 的值,这里值得注意的是如果 symbol 的范围,目前支持全局导出的 symbol。具体系统导出的 symobl 可以在内核源码的生成的 System.map 里获得。
”p symbol” 命令执行之后将会输出 symbol 的值,如果 symbol 是一个变量,那么就输出变量的值; 如果 symbol 是一个结构体或联合体,那么就输出其内容; 如果 symbol 是一个 PERCPU 变量,那么将打印 PERCPU 变量在所有 CPU 上的值。
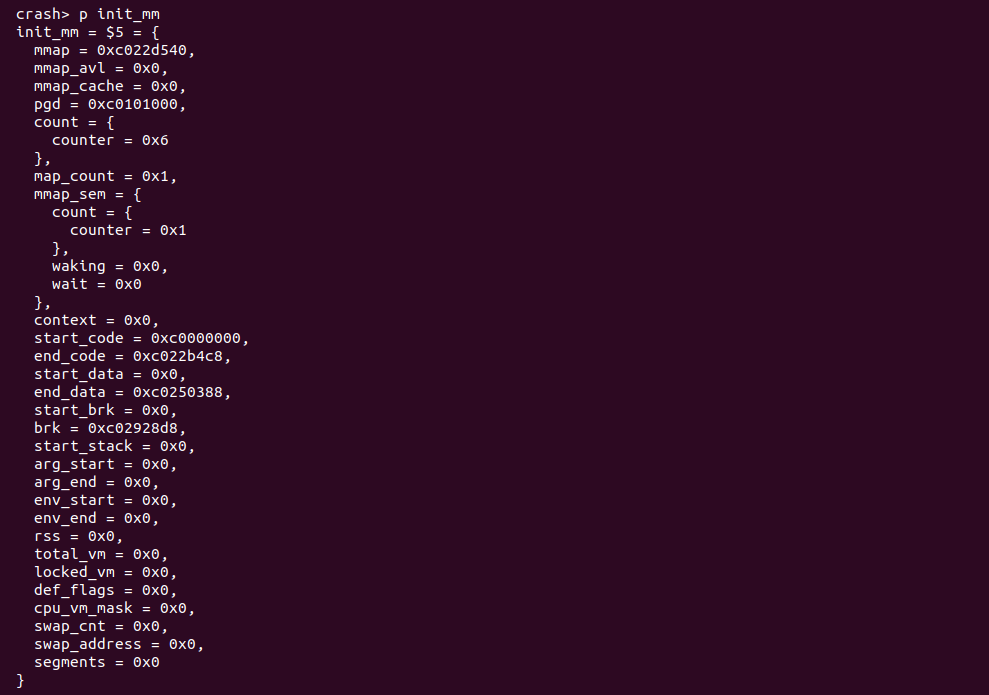
p symbol:cpuspec 打印 PERCPU 变量的值

CRASH 提供的 p symbol:cpuspec命令可以用于打印 PERCPU 变量,众所周知 PERCPU 变量在每个 CPU 上都有一个副本,那么该命令正好可以打印 PERCPU 变量在指定 CPU 上的值,也可以打印所有 CPU 上的值,其命令格式如下:
p symbol:cpuspec CPU specification for a per-cpu symbol:
: CPU of the currently selected task.
:a[ll] all CPUs.
:#[-#][,...] CPU list(s), e.g. "1,3,5", "1-3",
or "1,3,5-7,10".
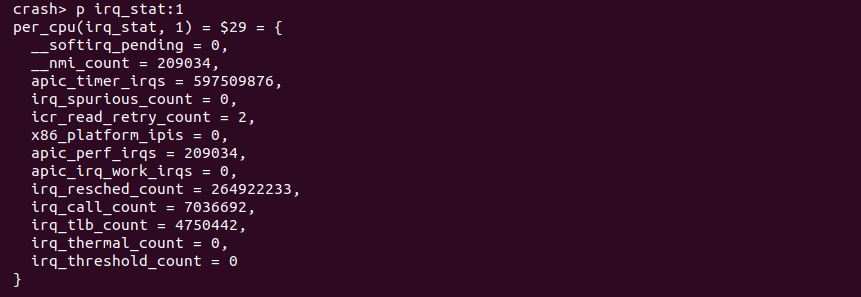
对于 PERCPU 变量 irq_stat, 通过 p 命令打印了其在 CPU 1 上的值.
px/pd 以十六进制/十进制方式输出

CRASH 提供的 “p symbol” 命令可以打印 symbol 的值,在输出值的时候,p 命令提供了 “x/u” 的选择,以此按十进制或十六进制的方式输出。其中 x 表示按十六进制的方式输出,u 表示按十进制的方式输出。
Crash 内存读写
当使用 CRASH 分析内存转储文件时,有时需要对进程的虚拟内存进行读写操作、有时需要对物理内存进行读写操作,那么为了满足这方面的需求,CRASH 提供了相应的命令满足需求,具体命令如下:
# SYNOPSIS
rd [-adDsSupxmfNR][-8|-16|-32|-64][-o offs][-e addr][-r file][address|symbol][count]
wr [-u|-k|-p] [-8|-16|-32|-64] [address|symbol] value
rd -p <address> 读取物理地址的内容
CRASH rd -p 命令用于读取物理地址对应的的内容,其中 “address” 参数是一个物理地址。在 Linux 系统中,可以使用 “cat /proc/iomem” 查看系统的物理内存信息,以此便于物理内存的查看:

不是所有的物理内存都可以读,Crash rd -p 命令只对 Reserved(0x00000000)、System RAM(0x00001000)、Video ROM(0x000c0000)、Adaptor ROM(0x000c9800) 的物理地址是可读取内容的。
Crash rd -p 命令对于 PCI Bus(0x000a0000)、IOAPIC(0xfec00000)、HPET(0xfed00000)、Local APIC(0xfee00000) 对应的 IO 物理地址是不可读的.
rd -u <addresss> 读取虚拟地址的内容

CRASH rd 命令用于读取虚拟地址对应的内容。在 Linux 中虚拟内存主要分作两部分,一部分为进程的用户空间,另外一部分为内核的虚拟空间。
对于所有进程来说内核虚拟空间都是一致的,而用户空间则是进程独占的。CRASH rd address 参数默认假设为内核空间的虚拟地址,因此在使用该命令查看用户进程的虚拟地址时需要显示的加上 “-u” 参数说明该地址是一个用户空间虚拟地址。
另外当使用该命令查看用户进程的虚拟地址时需要指定进程,而内核虚拟空间的虚拟地址则不需指定进程。
rd [-dDx][-8][-16][-32][-64][-a] <address> 格式化输出物理地址内容
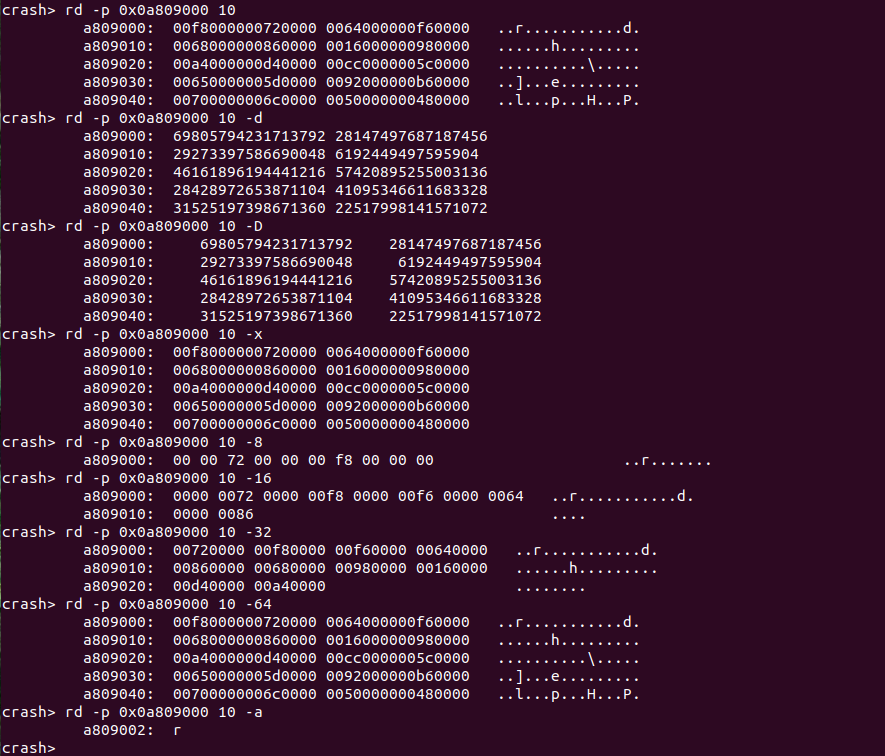
CRASH 在使用 rd 命令输出物理内存的内容时,可使用格式化参数来控制输出内容的格式
- -d 以十进制的方式输出
- -D 以无符号十进制方式输出
- -x 以十六进制方式输出
- -8 按 8-bit 长度进程输出
- -16 按 16-bit 长度进行输出
- -32 按 32-bit 长度进行输出
- -64 按 64-bit 长度进行输出
- -a 以 ASCII 方式进行输出
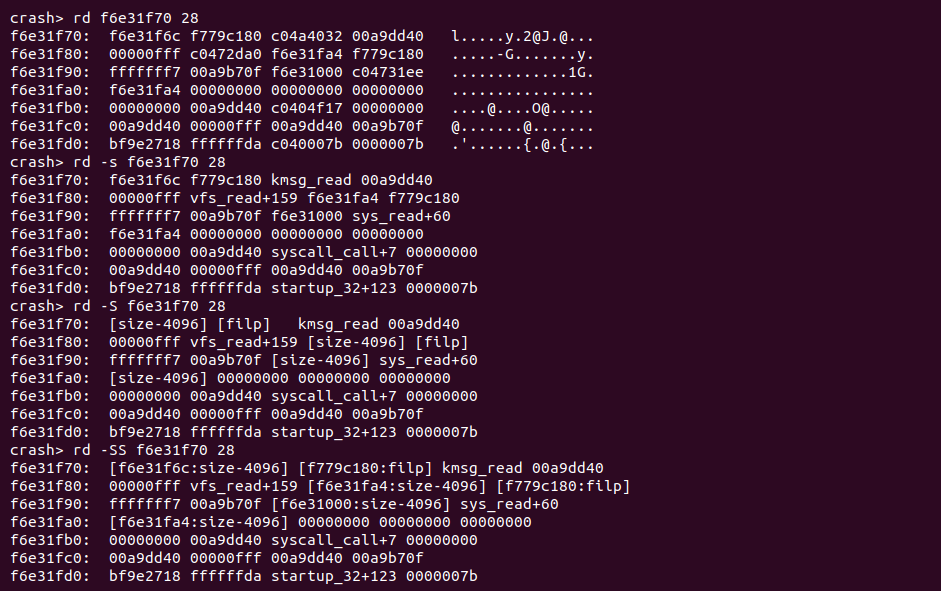
rd -s <address> 读取物理内存中符号引用
CRASH rd 命令提供了 “-s” 选项,该选项将物理内存中符号引用的内容打印出来. 例如 rd 打印的物理内存正好是进程的堆栈区域,那么该选项就会将函数调用栈给打印处理,从中可以看出物理内存对应的函数调用关系.
rd -S <address> 读取物理内存中 SLAB cache 的引用
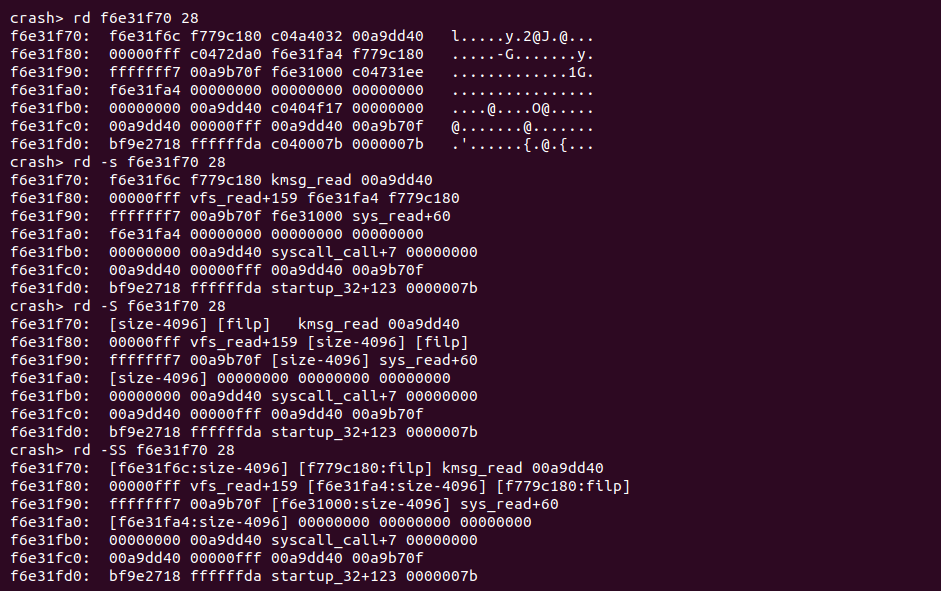
CRASH rd 命令提供了 “-S” 选项,该选项可以将物理内存中作为 SLAB cache 的引用进行输出,通过该命令可以便捷查看 SLAB cache 的地址。
rd -SS <address> 读取物理内存中 SLAB cache 的引用和内容
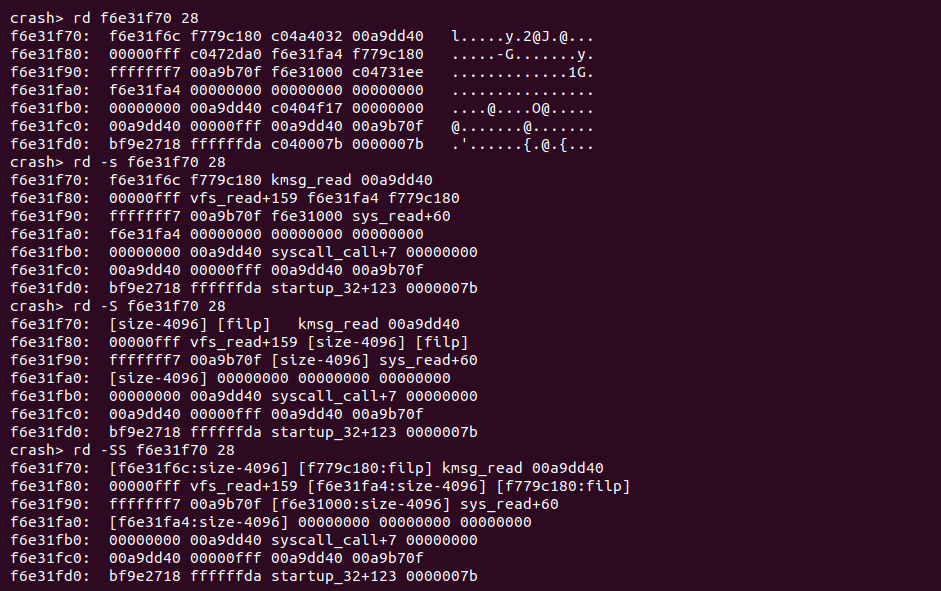
CRASH rd 命令提供了 “-SS” 选项,与 “-S” 相比,”-SS” 选项不仅输出了物理内存中作为 SLAB cache 的引用,还输出了对应物理内存的内容。
rd <symbol> 读取符号所在物理内存的内容
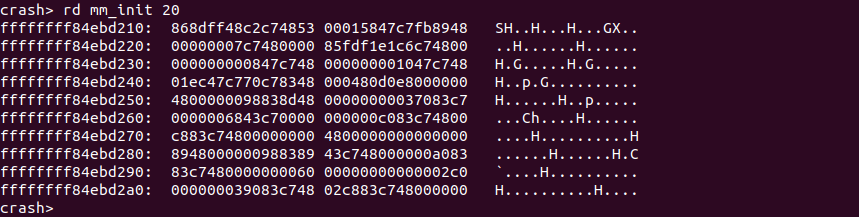
CRASH 通过 rd 命令可以读取 symbol 对应物理内存的值,可用的符号可以通过 System.map 获得。
rd <address> count 读取一定数量物理内存的内容

CRASH 的 rd 命令的 count 选项可以控制读取物理内存的数量。默认情况下,rd 命令的 count 为 1,并且最右边输出 ASCII 的内容。
rd <address> -o offset 读取起始物理地址偏移处的内容
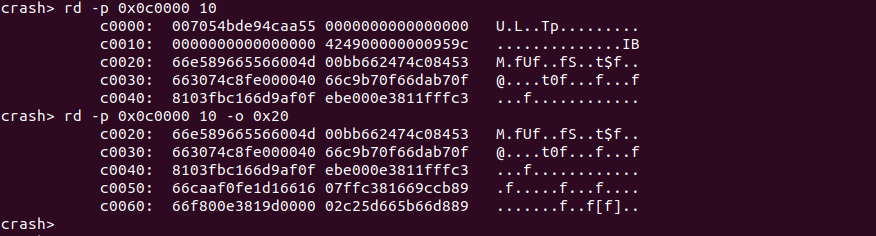
CRASH rd 命令提供了 “-o offset” 选项,该选项用于读取起始物理地址偏移 offset 处的内容.
rd <addr0> -e <addr1> 读取物理内存 addr0 到 addr1 之间的内容
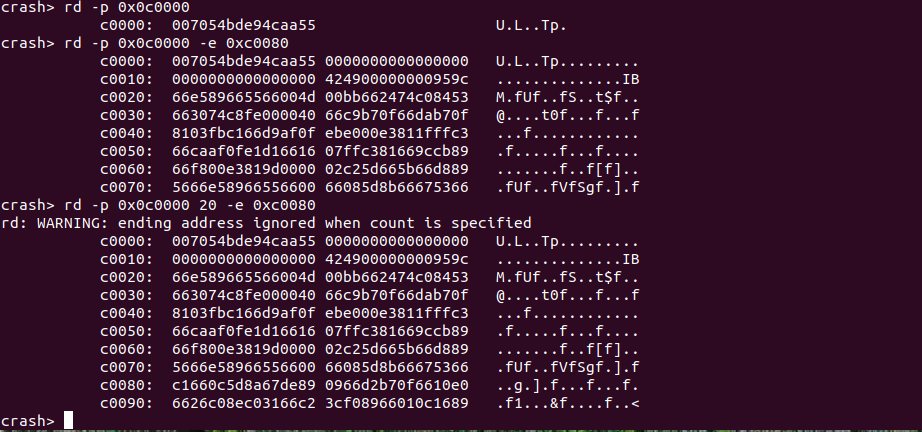
CRASH rd 命令提供了 “-e address” 选项,该选项可以打印起始物理地址到 address 物理地址之间的内容。当该命令不可以与 “count” 选项共同使用.
Crash 模块分析
当使用 CRASH 分析内核转储文件时,有时需要对内核模块进行分析,由于内核模块一般独立于源码树之外编译,因此模块的符号表和调试信息在内核转储文件中不存在,因此无法直接对内核模块进行调试。CRASH 提供了 mod 命令可以动态加载模块的调试信息和符号表,这位于模块中的问题定位提供了有力的帮助。具体命令如下:
# SYNOPSIS
mod -s module [objfile] | -d module | -S [directory] [-D|-t|-r|-R|-o|-g]
在使用 CRASH 调试模块之前,需要确保内核的 CONFIG_KALLSYMS 宏已经打开,已经模块编译的时候带上了 -g 标志 (例如在模块的 Makefile 中添加如下代码):

mod -s <module> [objectfile] 加载模块的符号表和 debuginfo
在使用 CRASH 分析模块的时候,由于模块的符号表和 debuginfo 的内容不包含在内核转储文件中,因此在分析模块文件之间需要先将这些信息导入到 CRASH 中,CRASH mod 命令提供了 “-s” 选项,该选项的命令格式如下:
mod -s module [objfile]
在 mod 命令的 “-s” 选项中,module 为模块的名字,objfile 为模块对应的目标文件, 值得注意的是 module 必须是一个模块名字,该命令可以通过 lsmod 进行查看,否则模块名字不对将被认为非法模块。
objfile 选项如果存在,那么需要给出 object 的绝对路径。当 object 选项不存在的时候,该命令用于查询模块的目标文件。
接下来通过一个实践例子进行理解该命令的使用. 在 BiscuitOS 中提供了一个实践案例用于介绍该命令的使用,其部署流程如下 (以 linux 5.0 X86_64 为例):
cd BiscuitOS
make linux-5.0-x86_64_defconfig
make menuconfig
[*] Package --->
[*] CRASH and BUG Example --->
[*] Example: Module Common --->
BiscuitOS/output/linux-5.0-x86_64/package/BiscuitOS-crash-module-common-default
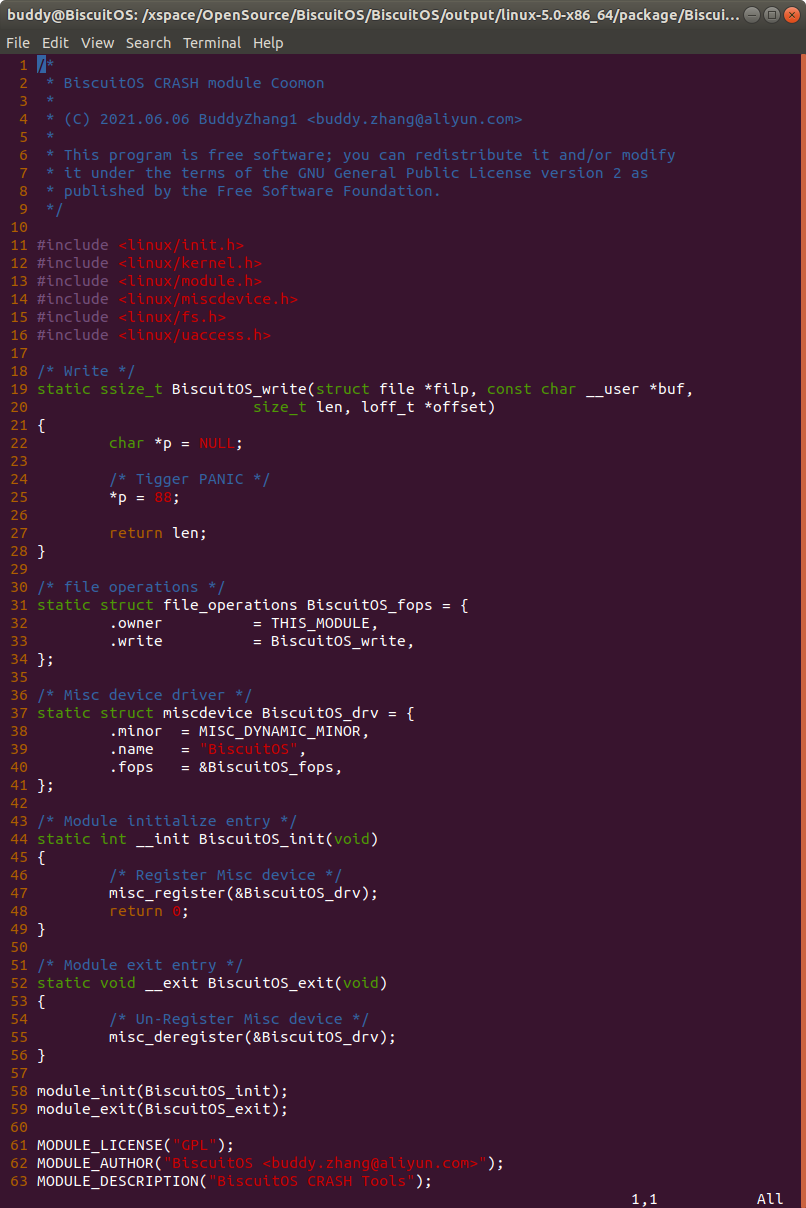
实践例子是一个独立模块,模块基于 MISC 驱动框架进行构建。模块中提供了 write 接口,在 BiscuitOS_write() 函数中,存在一个空指针的引用。如果在用户空间向该驱动写入操作的时候,就会触发空指针的引用,这个时候就会触发内核 PANIC,最终获得内核转储文件。接着在 BiscuitOS 上实践该实例,并使用 CRASH 进行调试:
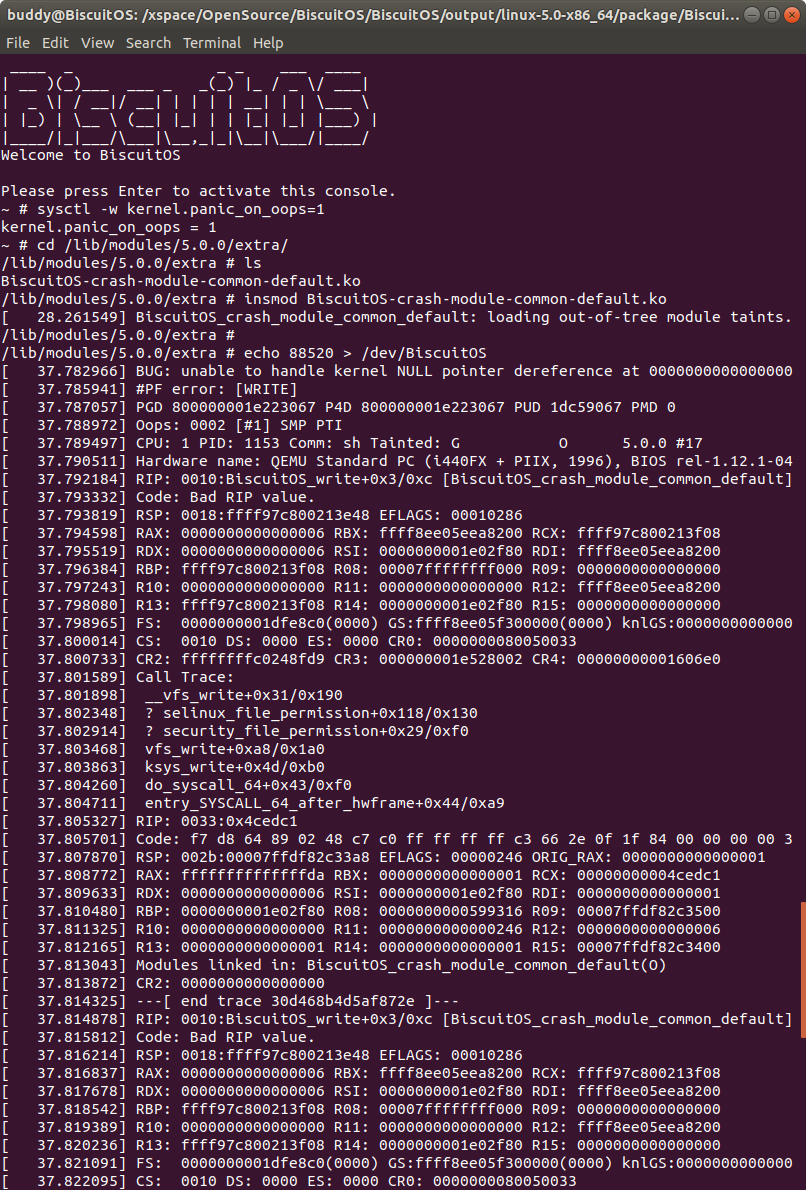
在 BiscuitOS 上运行实例之前,先将 PANIC 的 OOPS 选项设置为 1,以免 OOPS 被 killed,具体命令 “sysctl -w kernel.panic_on_oops=1”.
接着加载模块 “BiscuitOS-crash-module-common-default.ko”, 此时触发内核核心转储,此时通过不同的方法获得内核核心转储文件,并对其进行分析:
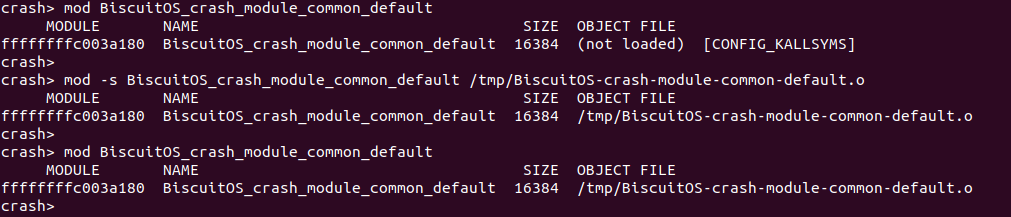
在使用 CRASH 分析内核转储文件时,使用 mod 命令查看模块是否加载符号表,第一次查看的时候发现 CRASH 没有加载模块的符号表。
接着使用 “mod -s” 命令进行加载,加载之前先将模块的目标文件拷贝到指定目录,然后进行加载,加载完毕之后再次使用 mod 命令查看模块的符号表,这个时候可以看到模块的符号表和 debuginfo 信息已经加载到 CRASH。
值得注意的时,如果某个模块在加载时出错,那么 CRASH 无法将该模块的符号表和 debuginfo 信息加载到 CRASH 内进行分析, 此时 CRASH 会认为这是一个非法模块,例如下图中不存在的模块:

mod -d <module> 移除模块的符号表和 debuginfo
在使用 CRASH 分析模块的时候,可以使用 “mod -s” 选项将模块的符号表和 debuginfo 动态加载到 CRASH 中进行分析。但有的时候需要更新模块的符号表或者移除模块的符号表,这个时候可以使用 “mod -d” 选项。该选项用于移除模块的符号表和 debuginfo,该选项的命令格式如下:
mod -d module
在 mod 命令的 “-d” 选项中,module 为模块的名字,值得注意的是 module 必须是一个模块名字,该命令可以通过 lsmod 进行查看,否则模块名字不对将被认为非法模块。
接下来通过一个实践例子研究该选项的使用。在 BiscuitOS 中提供了一个实践案例用于介绍该命令的使用,其部署流程如下 (以 linux 5.0 X86_64 为例):
cd BiscuitOS
make linux-5.0-x86_64_defconfig
make menuconfig
[*] Package --->
[*] CRASH and BUG Example --->
[*] Example: Module Common --->
BiscuitOS/output/linux-5.0-x86_64/package/BiscuitOS-crash-module-common-default
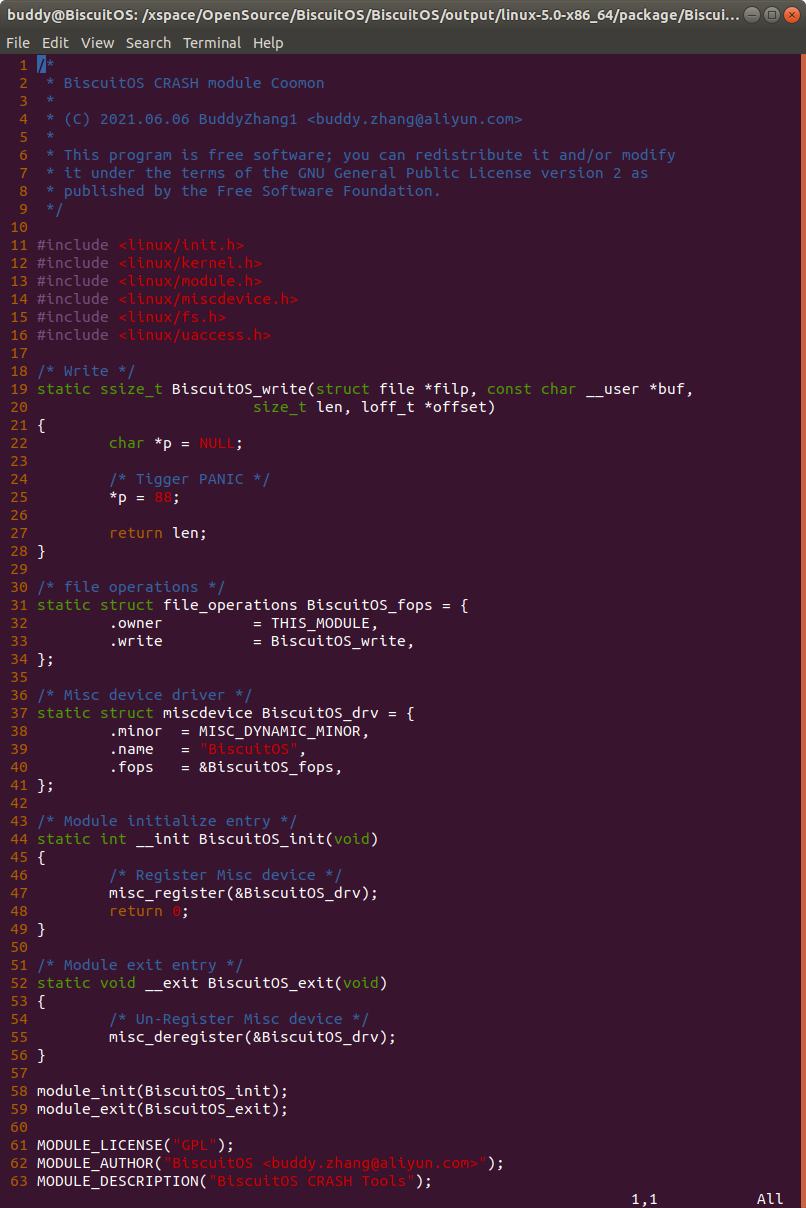
实践例子是一个独立模块,模块基于 MISC 驱动框架进行构建。模块中提供了 write 接口,在 BiscuitOS_write() 函数中,存在一个空指针的引用。
如果在用户空间向该驱动写入操作的时候,就会触发空指针的引用,这个时候就会触发内核 PANIC,最终获得内核转储文件。接着在 BiscuitOS 上实践该实例,并使用 CRASH 进行调试:
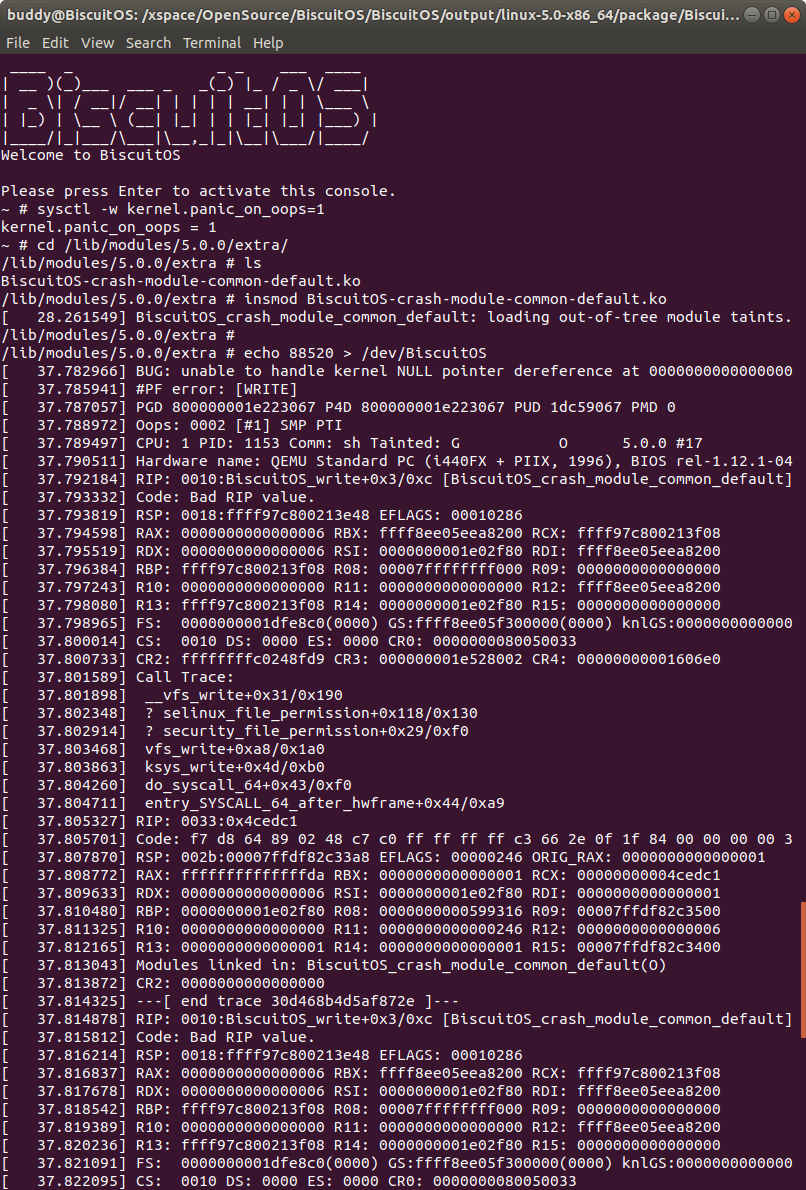
在 BiscuitOS 上运行实例之前,先将 PANIC 的 OOPS 选项设置为 1,以免 OOPS 被 killed,具体命令 “sysctl -w kernel.panic_on_oops=1”. 接着加载模块 “BiscuitOS-crash-module-common-default.ko”, 此时触发内核核心转储,此时通过不同的方法获得内核核心转储文件,并对其进行分析:
在使用 CRASH 分析内核转储文件时,使用 “mod -d” 命令移除模块的符号表和 debuginfo,在某些特定需求下这样的命令很有用。
mod 打印内核转储时系统中模块的信息
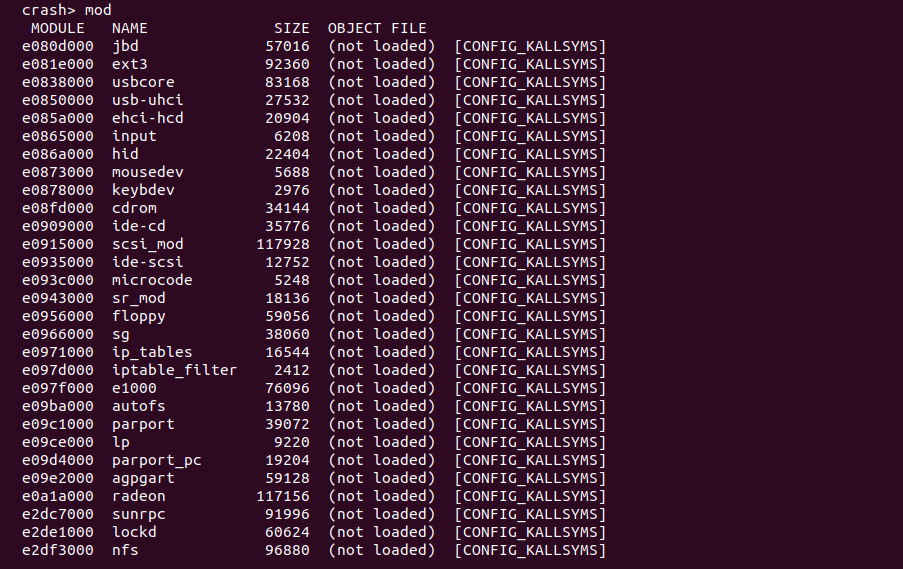
CRASH 提供 mod 命令可以查看内核转储时安装到系统的模块信息,各项的含义如下:
- MODULE 模块在的地址
- NAME 模块的名字
- SIZE 模块的长度
- OBJECT FILE 模块的目标文件
mod -S [directory] 从指定路径加载模块的目标文件
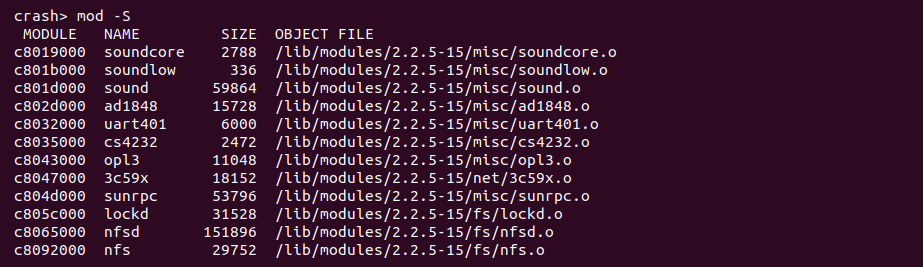
CRASH mod 在分析内核模块的时候,模块默认没有将对应的目标文件加入到 CRASH 内,mod 提供了 “-S” 选项可以将所有模块的目标文件都加载到 CRASH 内,如果 “-S” 后面没有跟路径信息,那么 CRASH 默认从主机的 “/lib/modules/$(uname -r)” 目录下进行查找并加载。接下来以一个实践例子进行讲解,在 BiscuitOS 中提供了一个实践案例用于介绍该命令的使用,其部署流程如下 (以 linux 5.0 X86_64 为例):
cd BiscuitOS
make linux-5.0-x86_64_defconfig
make menuconfig
[*] Package --->
[*] CRASH and BUG Example --->
[*] Example: Module Common --->
BiscuitOS/output/linux-5.0-x86_64/package/BiscuitOS-crash-module-common-default
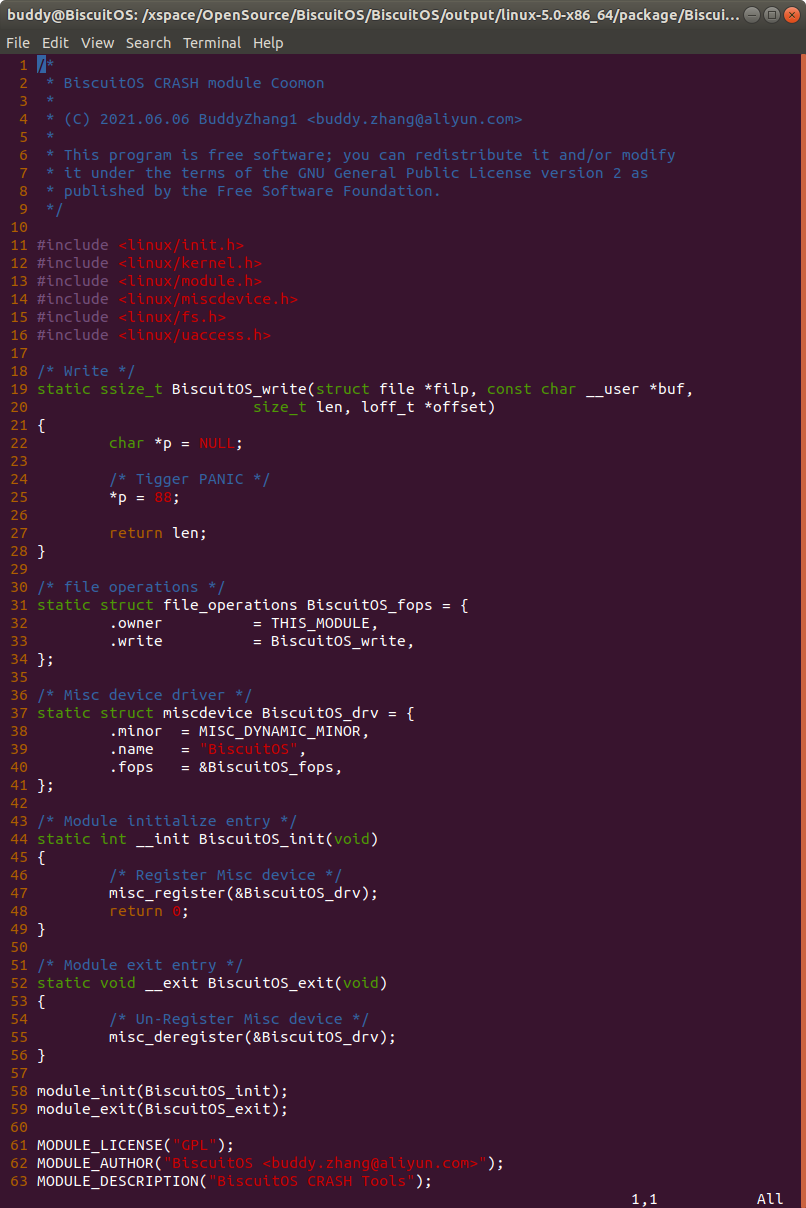
实践例子是一个独立模块,模块基于 MISC 驱动框架进行构建。模块中提供了 write 接口,在 BiscuitOS_write() 函数中,存在一个空指针的引用。如果在用户空间向该驱动写入操作的时候,就会触发空指针的引用,这个时候就会触发内核 PANIC,最终获得内核转储文件。接着在 BiscuitOS 上实践该实例,并使用 CRASH 进行调试:
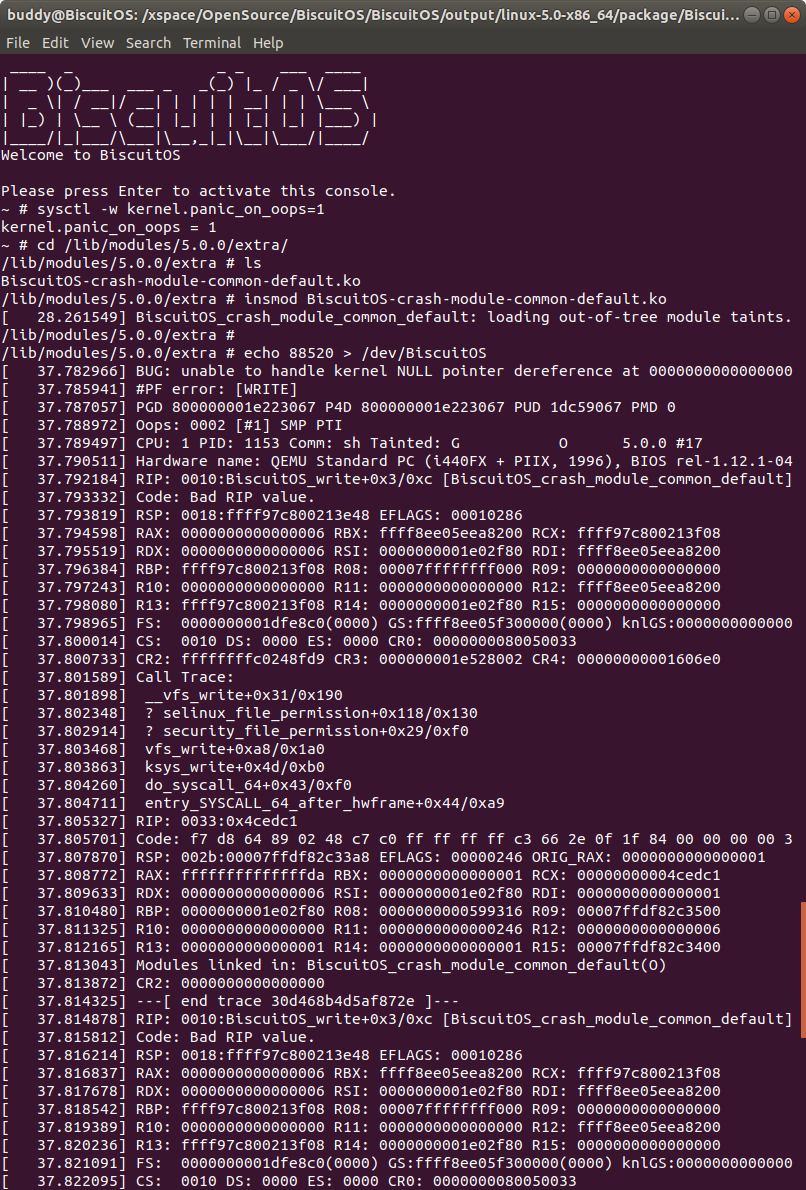
在 BiscuitOS 上运行实例之前,先将 PANIC 的 OOPS 选项设置为 1,以免 OOPS 被 killed,具体命令 “sysctl -w kernel.panic_on_oops=1”. 接着加载模块 “BiscuitOS-crash-module-common-default.ko”, 此时触发内核核心转储,此时通过不同的方法获得内核核心转储文件,并对其进行分析:

如果 “-S” 之后指明了路径,那么 CRASH 从指定的路径进行查找并加载目标文件。另外 CRASH 在启动命令上支持 “–mod " 的方式指明目标文件的路径,两者作用效果一致.
sudo crash kdump vminux --mod <mod_path>
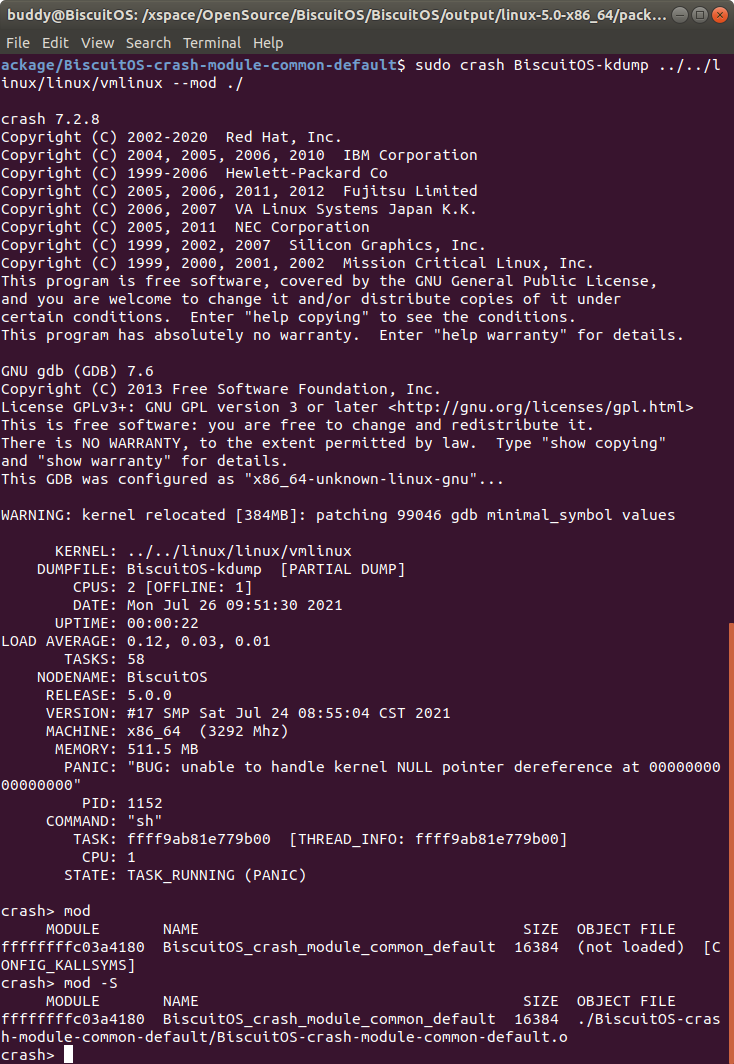
mod -D 移除所有模块的目标文件
在使用 CRASH 分析模块的时候,可以使用 “mod -s/S” 选项将模块的符号表和 debuginfo 动态加载到 CRASH 中进行分析。但有的时候需要更新模块的符号表或者移除模块的符号表,这个时候可以使用 “mod -d” 选项一个一个移除比较慢,CRASH 提供了 “mod -D” 命令可以一次性将所有模块的目标文件移除。该选项的命令格式如下:
mod -D
在 mod 命令的 “-D” 选项中,无需跟任何参数就可以将所有模块的目标文件移除。接下来通过一个实践例子研究该选项的使用。在 BiscuitOS 中提供了一个实践案例用于介绍该命令的使用,其部署流程如下 (以 linux 5.0 X86_64 为例):
cd BiscuitOS
make linux-5.0-x86_64_defconfig
make menuconfig
[*] Package --->
[*] CRASH and BUG Example --->
[*] Example: Module Common --->
BiscuitOS/output/linux-5.0-x86_64/package/BiscuitOS-crash-module-common-default
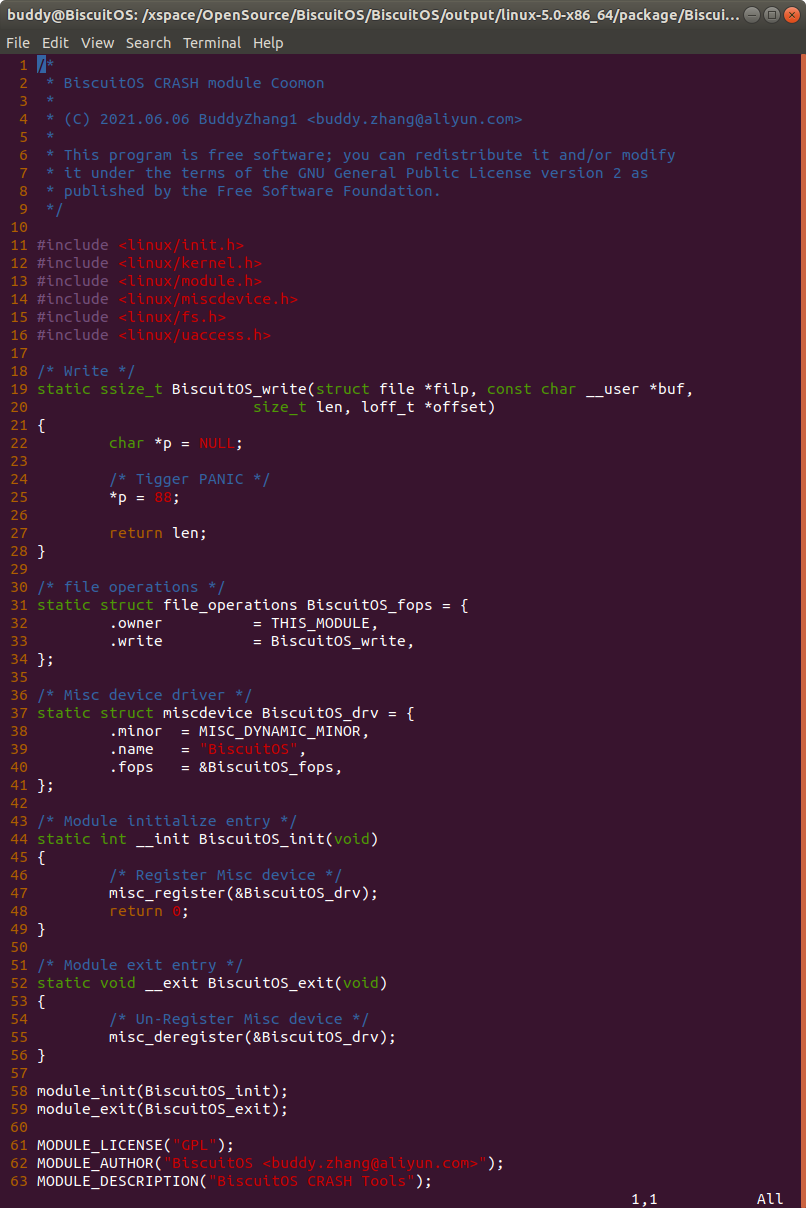
实践例子是一个独立模块,模块基于 MISC 驱动框架进行构建。模块中提供了 write 接口,在 BiscuitOS_write() 函数中,存在一个空指针的引用。如果在用户空间向该驱动写入操作的时候,就会触发空指针的引用,这个时候就会触发内核 PANIC,最终获得内核转储文件。接着在 BiscuitOS 上实践该实例,并使用 CRASH 进行调试:
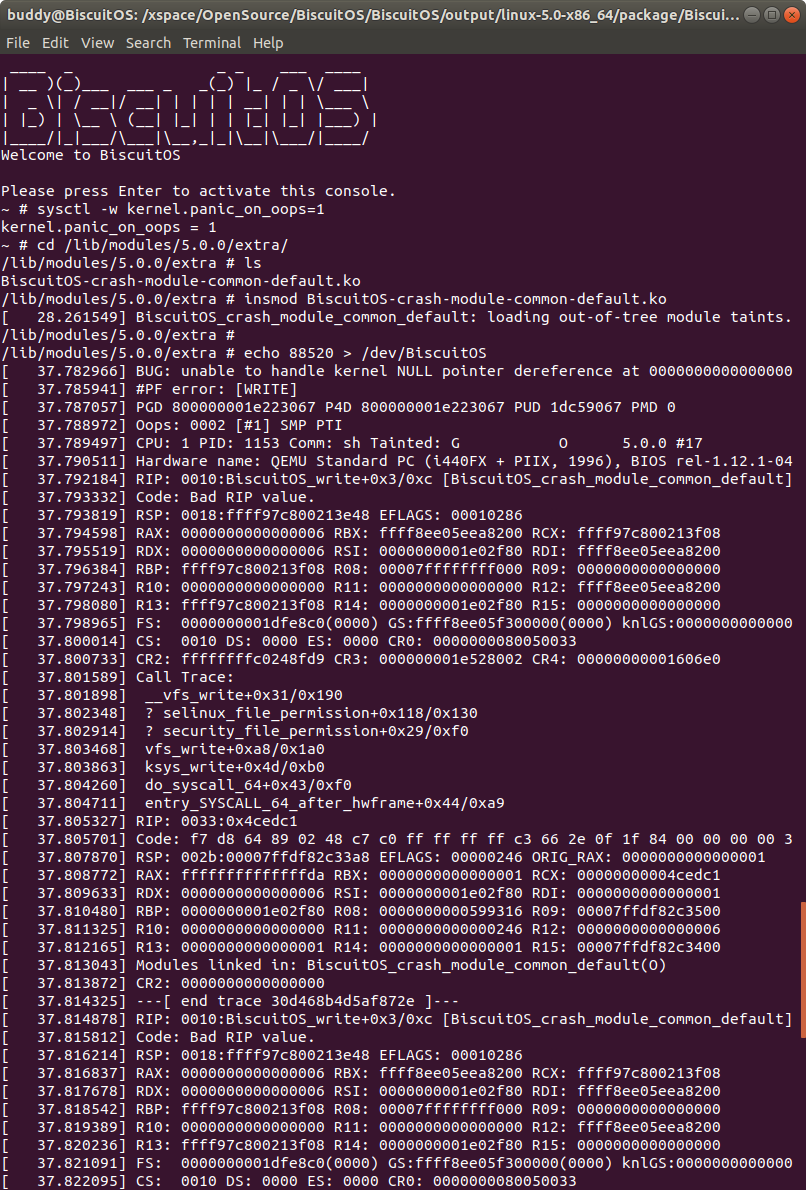
在 BiscuitOS 上运行实例之前,先将 PANIC 的 OOPS 选项设置为 1,以免 OOPS 被 killed,具体命令 “sysctl -w kernel.panic_on_oops=1”. 接着加载模块 “BiscuitOS-crash-module-common-default.ko”, 此时触发内核核心转储,此时通过不同的方法获得内核核心转储文件,并对其进行分析:

在使用 CRASH 分析内核转储文件时,使用 “mod -D” 命令移除所有模块的符号表和 debuginfo,在某些特定需求下这样的命令很有用。
lsmod 查看内核崩溃是加载的模块

CRASH 提供 lsmod 命令可以查看内核转储时安装到系统的模块信息,各项的含义如下:
- MODULE 模块在的地址
- NAME 模块的名字
- SIZE 模块的长度
- OBJECT FILE 模块的目标文件
Crash 链表操作
在内核中存在很多链表,例如常见的单链表和双链表。当内核发生崩溃时,使用 CRASH 分析内核转储文件时,对于链表上的内容分析可以采用 struct 或者 p 指令进行分析,但这两个指令无法满足对于整个链表内容的快速便捷分析,于是 CRASH 提供了 list 指令用来分析链表的内容。具体命令格式如下:

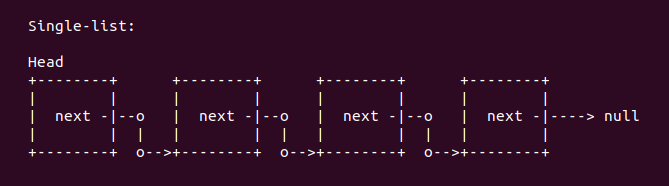
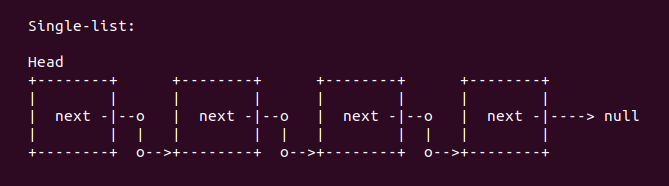
list 命令用于打印以链表链接起来的数据结构的内容。list 命令主要处理两种链表关系,第一种链表是单链表关系:
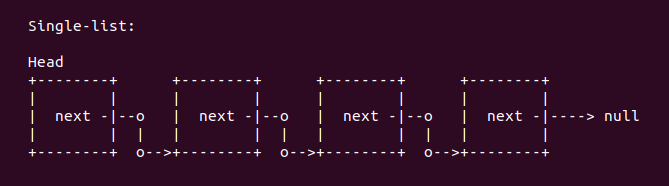
单链表关系一般内嵌在数据结构中,用于指向一下个同类型的数据结构。在这种情况下,list 命令的 start 参数指向了包含链表的数据结构的起始地址。该单链表的 next 指针可能指向一个空指针,也可能作为一个链表的表头,也可能指向自己,或者可能指向下一个同样数据结构的结构体。
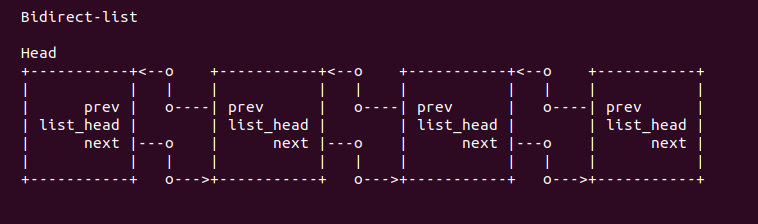
内核中更多存在的是双链表关系,该关系可以指向前一个数据结构和后一个数据结构,在内核中通常使用 struct list_head 数据结构进行描述。该数据结构可能作为成员嵌入在某个数据结构中,或者作为指针嵌入在数据结构中。无论以何种方式嵌入,双链表都会将包含该链表的数据结构前后链接成一个双链表。CRASH list 命令提供了多个选项用于打印链表的内容:
list structure.member <start> 通过单链表成员起始地址打印单链表所有成员的地址
CRASH list 命令可以用于打印单链表成员的地址,并使用 “structure.member” 的方式将单链表上的数据结构地址打印出来。接下来通过一个实践例子研究该选项的使用。在 BiscuitOS 中提供了一个实践案例用于介绍该命令的使用,其部署流程如下 (以 linux 5.0 X86_64 为例):
cd BiscuitOS
make linux-5.0-x86_64_defconfig
make menuconfig
[*] Package --->
[*] CRASH and BUG Example --->
[*] Example: list Common --->
BiscuitOS/output/linux-5.0-x86_64/package/BiscuitOS-crash-list-common-default
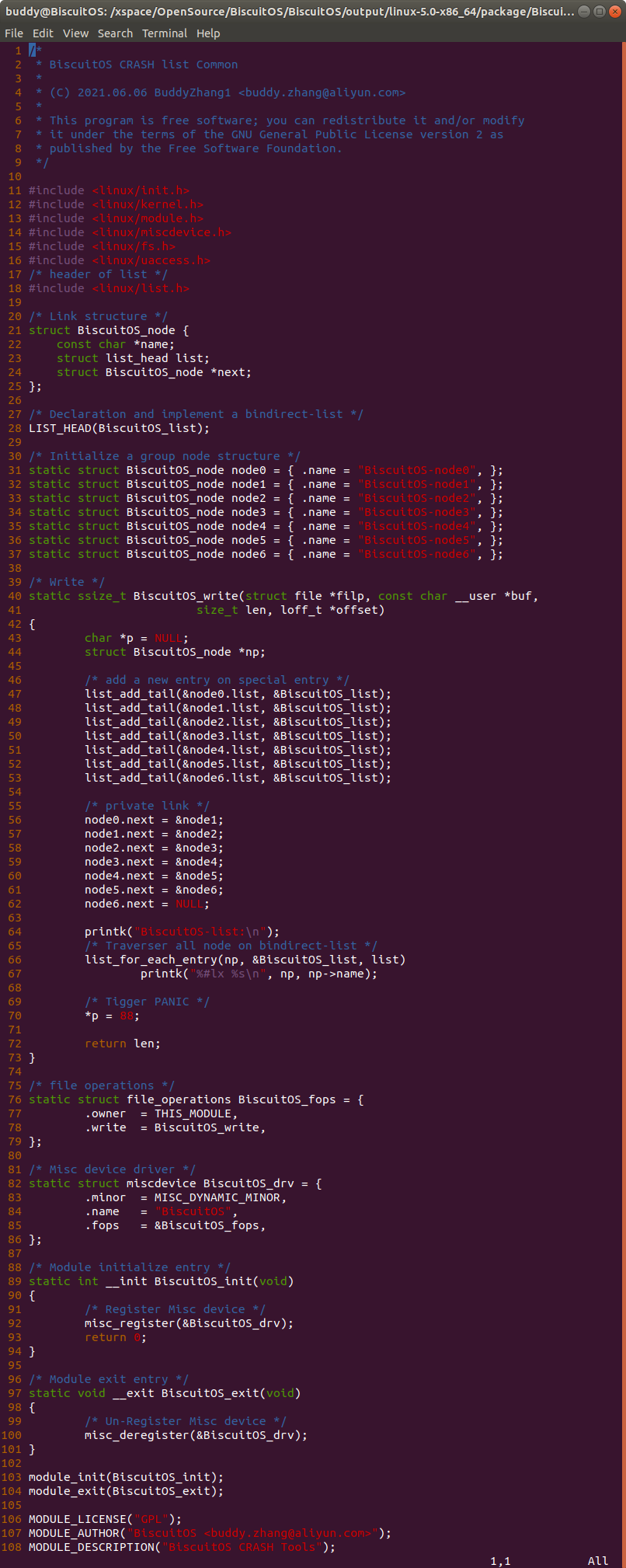
实践例子是一个独立模块,模块基于 MISC 驱动框架进行构建。在模块中构建名为 BiscuitOS_node 的结构体,该结构体的 name 成员用于包含名字相关的字符串; 成员 list 为内嵌在结构体中双链表数据结构,该成员将 BiscuitOS_node 链接成双链表的关系; 成员 next 则为指向相同数据类型的指针,该指针构成一个 BiscuitOS_node 的单链表。模块定义了一个双链表的表头 BiscuitOS_list, 以及定义了 6 个 struct BiscuitOS_node 变量,每个变量都有独立的名字。模块中提供了 write 接口,在 BiscuitOS_write() 函数中,通过调用 list_add_tail() 函数将 6 个成员链接到 BiscuitOS_list 双链表上。函数紧接着将 node0 的 next 成员指向 node1, 以此类推,构建了 node0 到 node6 的单链表。最后 BiscuitOS_write() 函数中存在一个空指针的引用。如果在用户空间向该驱动写入操作的时候,就会触发空指针的引用,这个时候就会触发内核 PANIC,最终获得内核转储文件。接着在 BiscuitOS 上实践该实例,并使用 CRASH 进行调试:
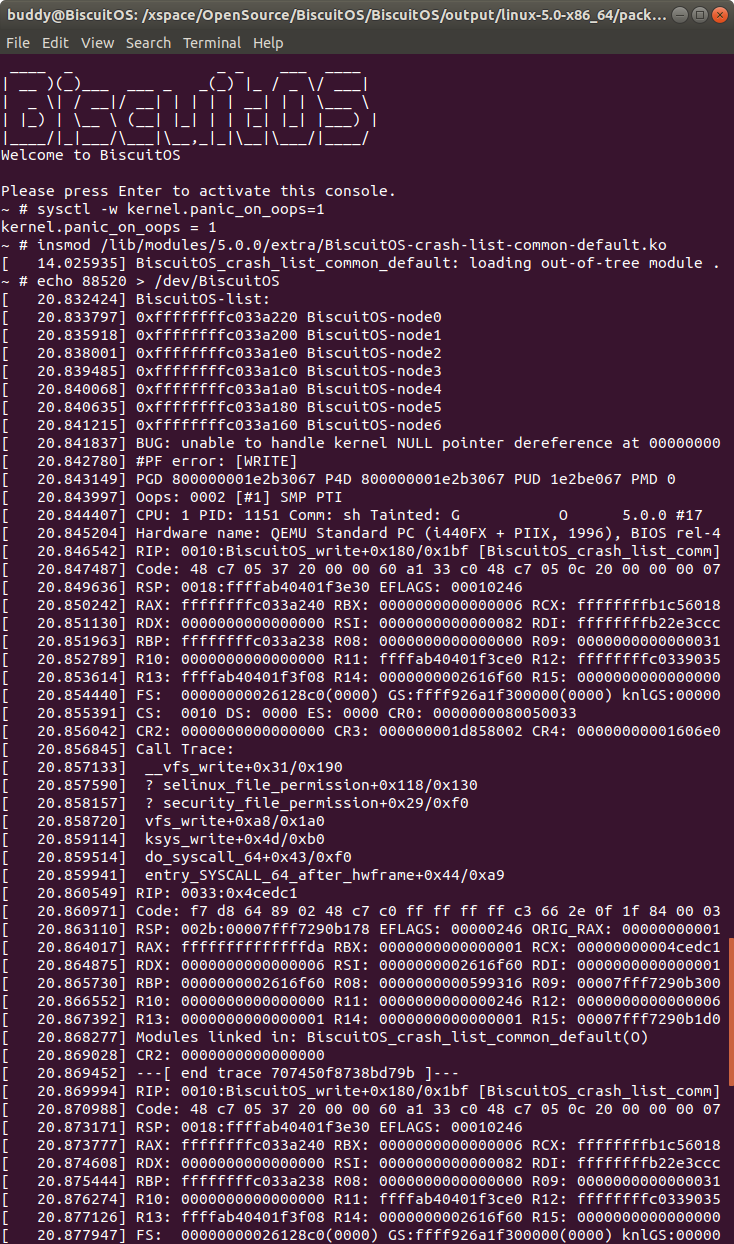
在 BiscuitOS 上运行实例之前,先将 PANIC 的 OOPS 选项设置为 1,以免 OOPS 被 killed,具体命令 “sysctl -w kernel.panic_on_oops=1”. 接着加载模块 “BiscuitOS-crash-list-common-default.ko”, 此时触发内核核心>转储,此时通过不同的方法获得内核核心转储文件,并对其进行分析:
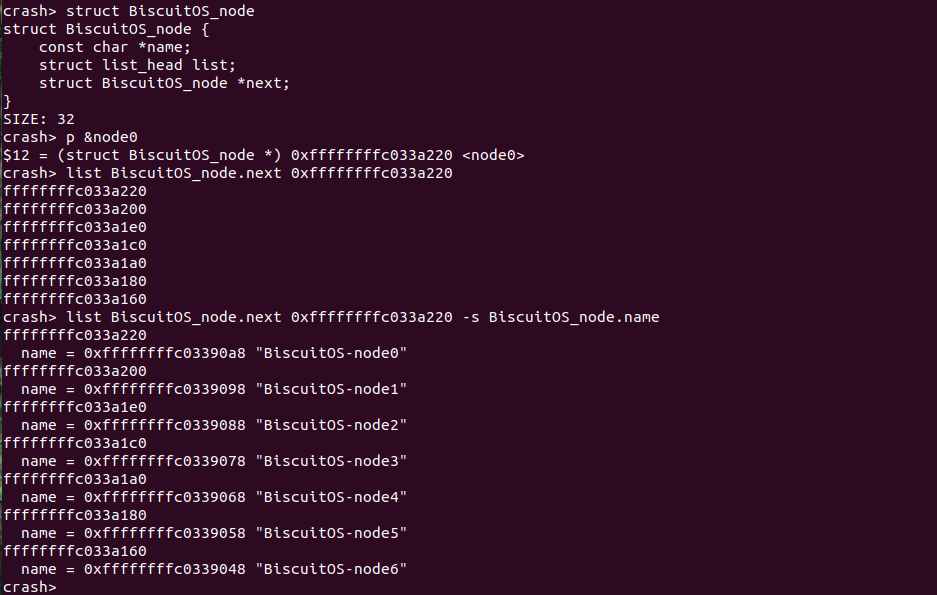
在实践例子中,node0 与其他 node 通过 next 构成了一个单链表,如果我想获得链表上所有 struct BiscuitOS_node 的地址,那么可以首先使用 struct 命令查看其数据结构布局,其中 next 成员作为一个 struct BiscuitOS_node 的指针,此时通过 p 命令获得 node0 的地址,接下来使用 “list BiscuitOS_node.next” 与 node0 的起始地址,就可以获得在这个链表上其他 struct BiscuitOS_node 的地址。最后借助 “-s” 命令打印 BiscuitOS_node 的 name 成员.
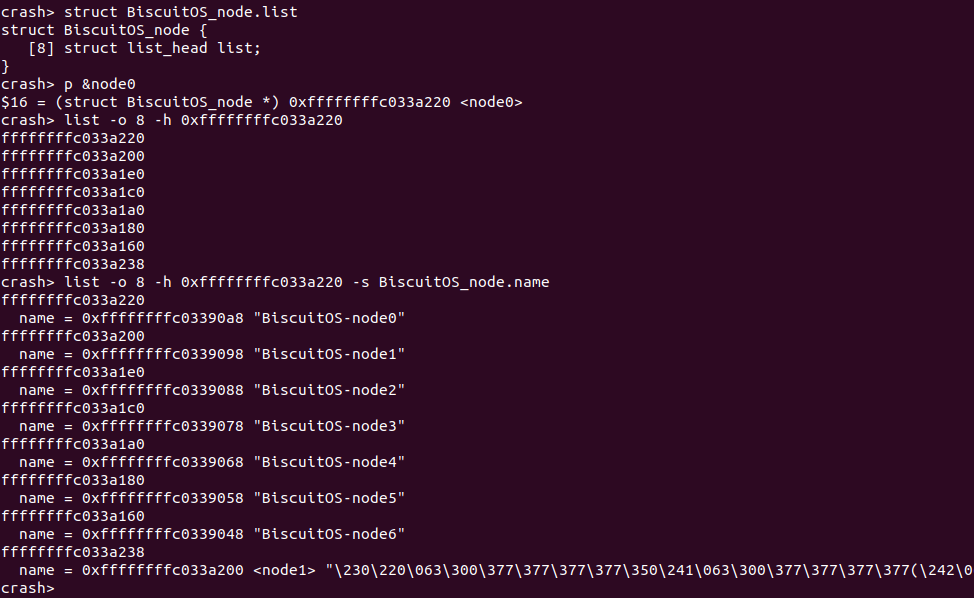
list [-o] offset <start> 通过单链表成员起始地址打印单链表所有成员的地址
CRASH list 命令可以用于打印单链表成员的地址,并使用 “[-o] offset” 的方式将单链表上的数据结构地址打印出来, 其中 offset 是嵌入在结构体中单链表成员的偏移。接下来通过一个实践例子研究该选项的使用。在 BiscuitOS 中提供了一个实践案例用于介绍该命令的使用,其部署流程如下 (以 linux 5.0 X86_64 为例):
cd BiscuitOS
make linux-5.0-x86_64_defconfig
make menuconfig
[*] Package --->
[*] CRASH and BUG Example --->
[*] Example: list Common --->
BiscuitOS/output/linux-5.0-x86_64/package/BiscuitOS-crash-list-common-default
实践例子是一个独立模块,模块基于 MISC 驱动框架进行构建。在模块中构建名为 BiscuitOS_node 的结构体,该结构体的 name 成员用于包含名字相关的字符串; 成员 list 为内嵌在结构体中双链表数据结构,该成员将 BiscuitOS_node 链接成双链表的关系; 成员 next 则为指向相同数据类型的指针,该指针构成一个 BiscuitOS_node 的单链表。模块定义了一个双链表的表头 BiscuitOS_list, 以及定义了 6 个 struct BiscuitOS_node 变量,每个变量都有独立的名字。模块中提供了 write 接口,在 BiscuitOS_write() 函数中,通过调用 list_add_tail() 函数将 6 个成员链接到 BiscuitOS_list 双链表上。函数紧接着将 node0 的 next 成员指向 node1, 以此类推,构建了 node0 到 node6 的单链表。最后 BiscuitOS_write() 函数中存在一个空指针的引用。如果在用户空间向该驱动写入操作的时候,就会触发空指针的引用,这个时候就会触发内核 PANIC,最终获得内核转储文件。接着在 BiscuitOS 上实践该实例,并使用 CRASH 进行调试:
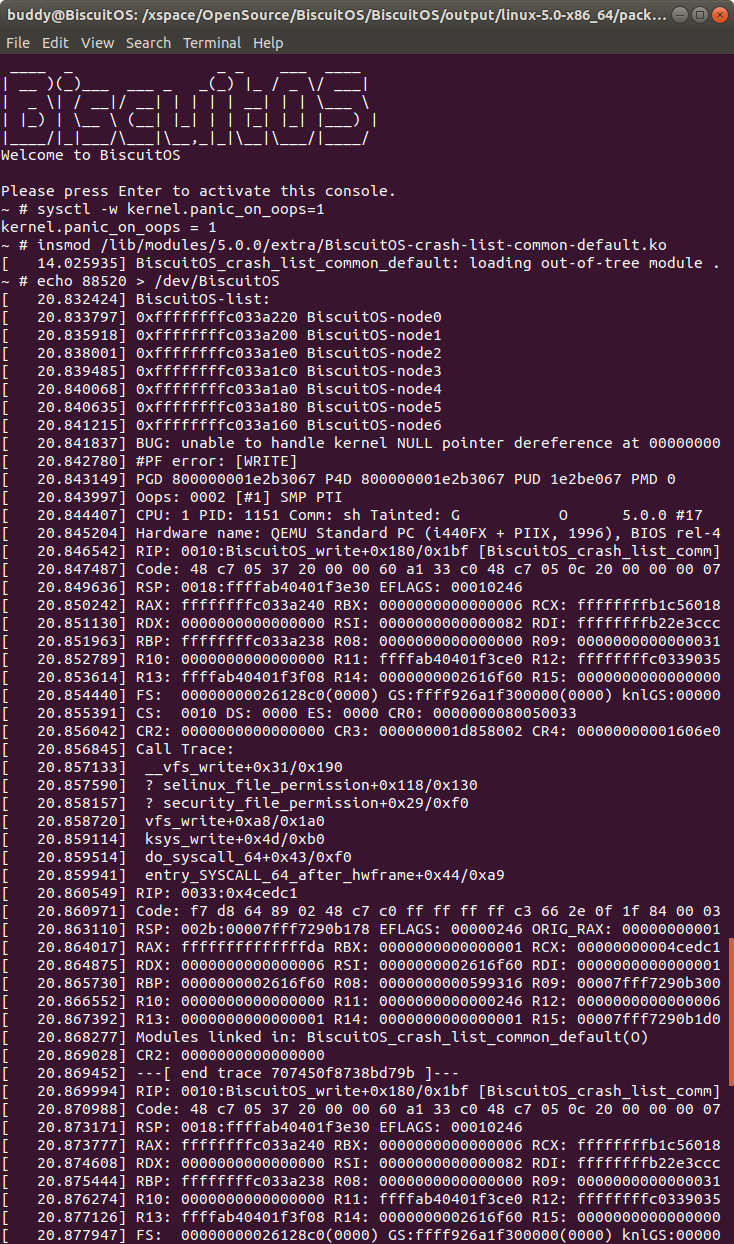
在 BiscuitOS 上运行实例之前,先将 PANIC 的 OOPS 选项设置为 1,以免 OOPS 被 killed,具体命令 “sysctl -w kernel.panic_on_oops=1”. 接着加载模块 “BiscuitOS-crash-list-common-default.ko”, 此时触发内核核心转储,此时通过不同的方法获得内核核心转储文件,并对其进行分析:
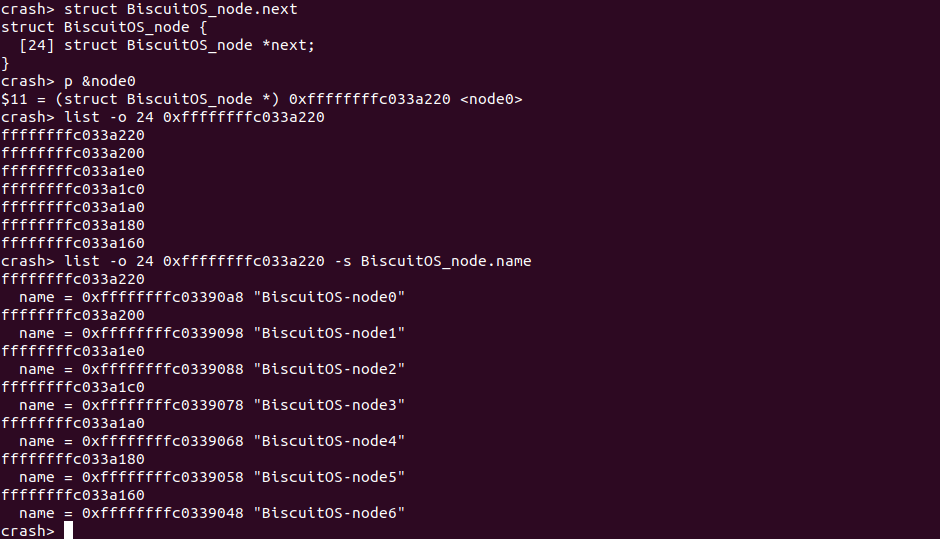
在实践例子中,node0 与其他 node 通过 next 构成了一个单链表,如果我想获得链表上所有 struct BiscuitOS_node 的地址,那么可以首先使用 struct 命令查看 next 在 BiscuitOS_node 中的偏移,此时 next 的偏移为 24,此时通过 p 命令获得 node0 的地址,接下来使用 “-o 24” 与 node0 的起始地址,就可以获得在这个链表上其他 struct BiscuitOS_node 的地址。最后借助 “-s” 选项将单表成员的 name 成员打印出来.
list -H <start> 通过双链表表头起始地址打印双链表成员的地址
CRASH list 命令可以用于打印双链表成员的地址,内核通常使用在结构体嵌入 struct list_head 结构体构建双链表。CRASH list 提供了 “-H” 选项可以依据双链表的表头打印双链表上所有成员的地址。这里可以使用 “structure.member” 的方式指明双链表成员,也可以使用 “[-o] offset” 的方式指明双链表成员。接下来通过一个实践例子研究该选项的使用。在 BiscuitOS 中提供了一个实践案例用于介绍该命令的使用,其部署流程如下 (以 linux 5.0 X86_64 为例):
cd BiscuitOS
make linux-5.0-x86_64_defconfig
make menuconfig
[*] Package --->
[*] CRASH and BUG Example --->
[*] Example: list Common --->
BiscuitOS/output/linux-5.0-x86_64/package/BiscuitOS-crash-list-common-default
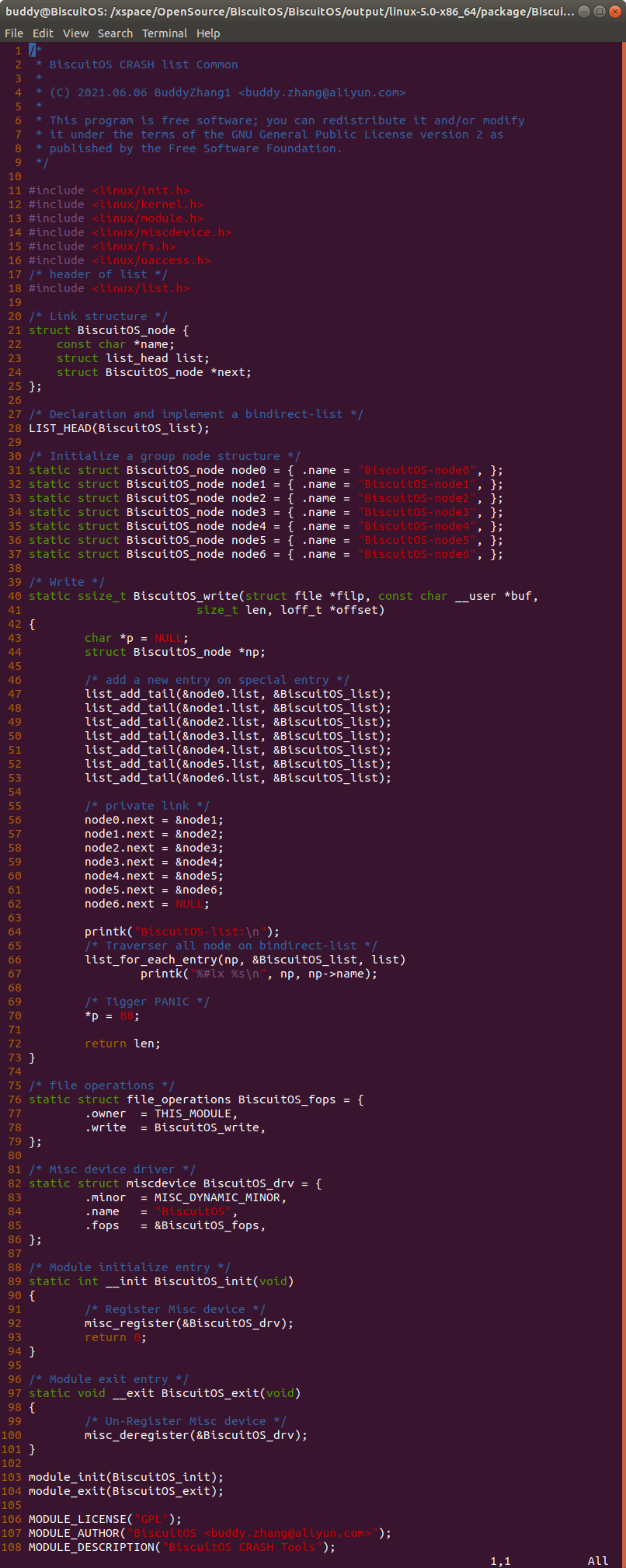
实践例子是一个独立模块,模块基于 MISC 驱动框架进行构建。在模块中构建名为 BiscuitOS_node 的结构体,该结构体的 name 成员用于包含名字相关的字符串; 成员 list 为内嵌在结构体中双链表数据结构,该成员将 BiscuitOS_node 链接成双链表的关系; 成员 next 则为指向相同数据类型的指针,该指针构成一个 BiscuitOS_node 的单链表。模块定义了一个双链表的表头 BiscuitOS_list, 以及定义了 6 个 struct BiscuitOS_node 变量,每个变量都有独立的名字。模块中提供了 write 接口,在 BiscuitOS_write() 函数中,通过调用 list_add_tail() 函数将 6 个成员链接到 BiscuitOS_list 双链表上。函数紧接着将 node0 的 next 成员指向 node1, 以此类推,构建了 node0 到 node6 的单链表。最后 BiscuitOS_write() 函数中存在一个空指针的引用。如果在用户空间向该驱动写入操作的时候,就会触发空指针的引用,这个时候就会触发内核 PANIC,最终获得内核转储文件。接着在 BiscuitOS 上实践该实例,并使用 CRASH 进行调试:
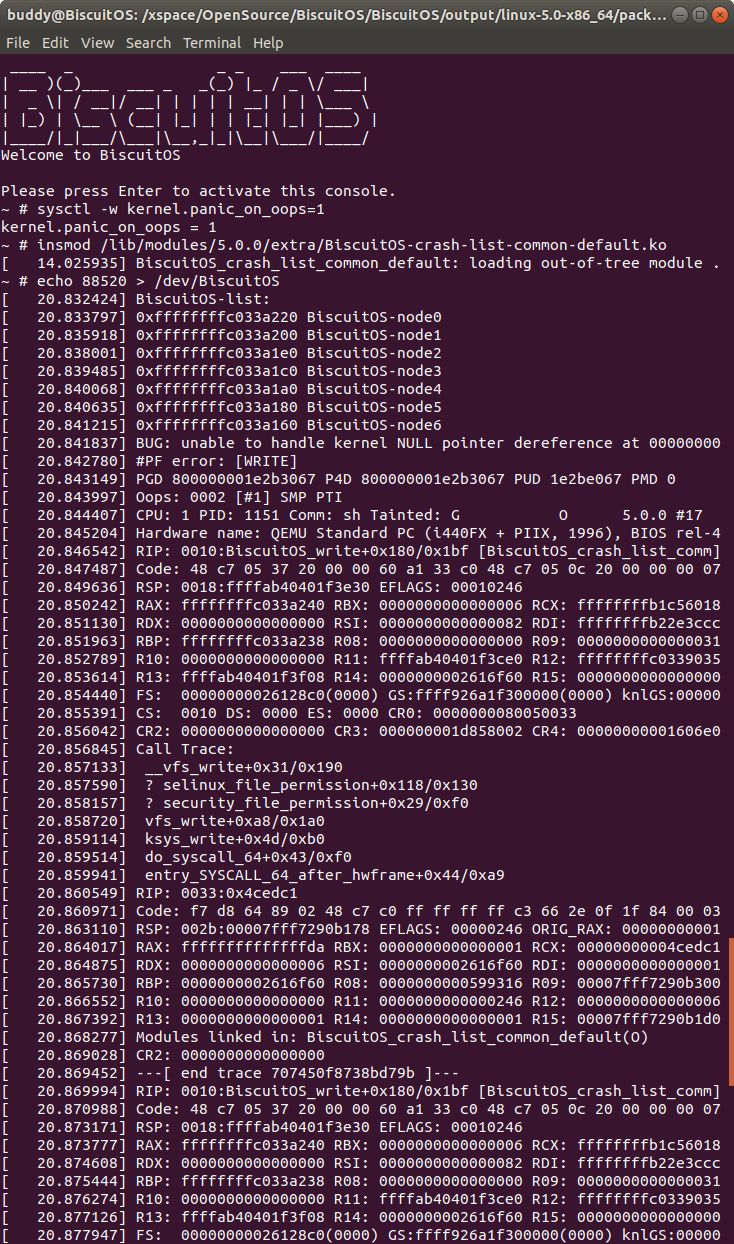
在 BiscuitOS 上运行实例之前,先将 PANIC 的 OOPS 选项设置为 1,以免 OOPS 被 killed,具体命令 “sysctl -w kernel.panic_on_oops=1”. 接着加载模块 “BiscuitOS-crash-list-common-default.ko”, 此时触发内核核心转储,此时通过不同的方法获得内核核心转储文件,并对其进行分析:
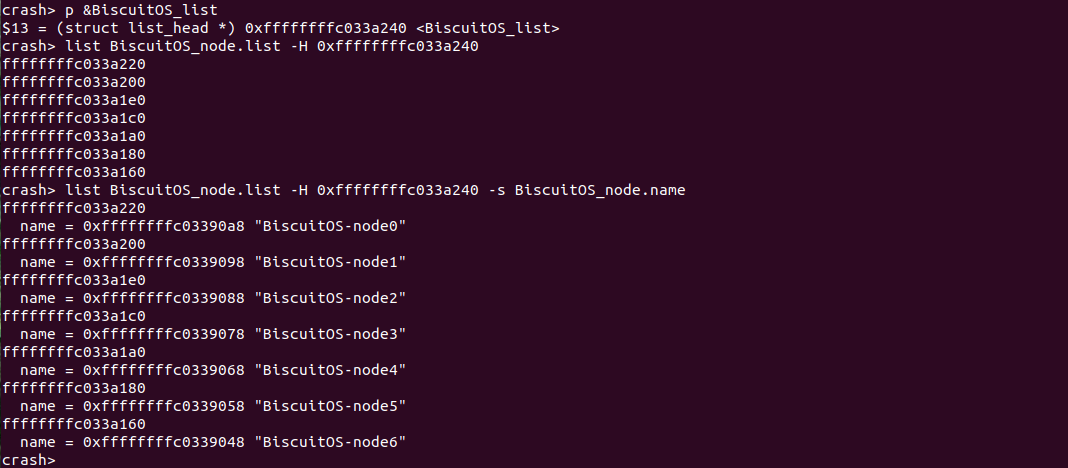
在实践例子中,node0 与其他 node 通过 list 成员都成了一个双链表,并以 BiscuitOS_list 为双链表的表头。那么首先通过 p 命令获得 BiscuitOS_list 的地址,接着通过 “structure.member” 的方式指明数据结构中的双链表成员,这里指定为 “BiscuitOS_node.list”. 那么接下来通过 “-H” 选项跟上双链表表头的地址,这样就可以遍历整个双链表。最后借助 “-s” 选项打印 BiscuitOS_node 成员的 name。另外也可以使用 offset 的方式:

list -h <start> 通过双链表成员起始地址打印双链表所有成员的地址
CRASH list 命令可以用于打印双链表成员的地址,内核通常使用在结构体嵌入 struct list_head 结构体构建双链表。CRASH list 提供了 “-h” 选项可以依据双链表的成员打印双链表上所有成员的地址。这里可以使用 “structure.member” 的方式指明双链表成员,也可以使用 “[-o] offset” 的方式指明双链表成员。接下来通过一个实践例子研究该选项的使用。在 BiscuitOS 中提供了一个实践案例用于介绍该命令的使用,其部署流程如下 (以 linux 5.0 X86_64 为例):
cd BiscuitOS
make linux-5.0-x86_64_defconfig
make menuconfig
[*] Package --->
[*] CRASH and BUG Example --->
[*] Example: list Common --->
BiscuitOS/output/linux-5.0-x86_64/package/BiscuitOS-crash-list-common-default
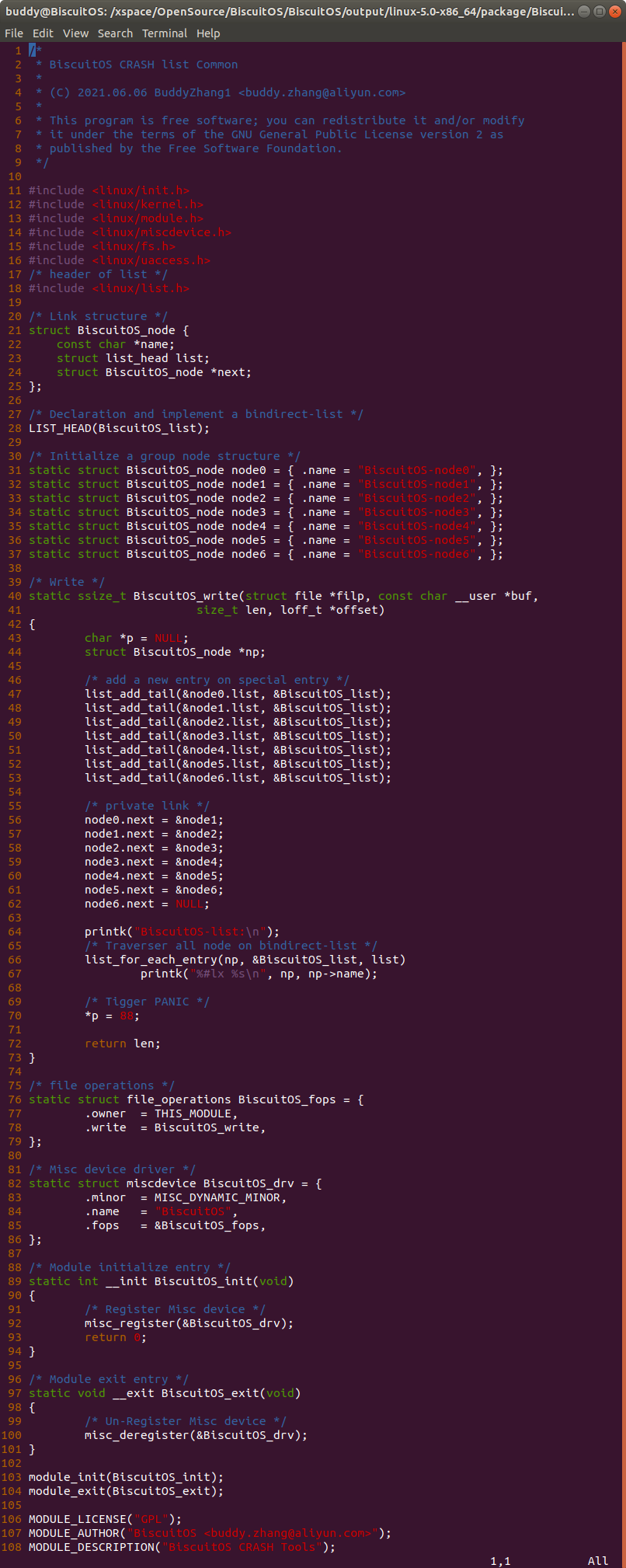
实践例子是一个独立模块,模块基于 MISC 驱动框架进行构建。在模块中构建名为 BiscuitOS_node 的结构体,该结构体的 name 成员用于包含名字相关的字符串; 成员 list 为内嵌在结构体中双链表数据结构,该成员将 BiscuitOS_node 链接成双链表的关系; 成员 next 则为指向相同数据类型的指针,该指针构成一个 BiscuitOS_node 的单链表。模块定义了一个双链表的表头 BiscuitOS_list, 以及定义了 6 个 struct BiscuitOS_node 变量,每个变量都有独立的名字。模块中提供了 write 接口,在 BiscuitOS_write() 函数中,通过调用 list_add_tail() 函数将 6 个成员链接到 BiscuitOS_list 双链表上。函数紧接着将 node0 的 next 成员指向 node1, 以此类推,构建了 node0 到 node6 的单链表。最后 BiscuitOS_write() 函数中存在一个空指针的引用。如果在用户空间向该驱动写入操作的时候,就会触发空指针的引用,这个时候就会触发内核 PANIC,最终获得内核转储文件。接着在 BiscuitOS 上实践该实例,并使用 CRASH 进行调试:
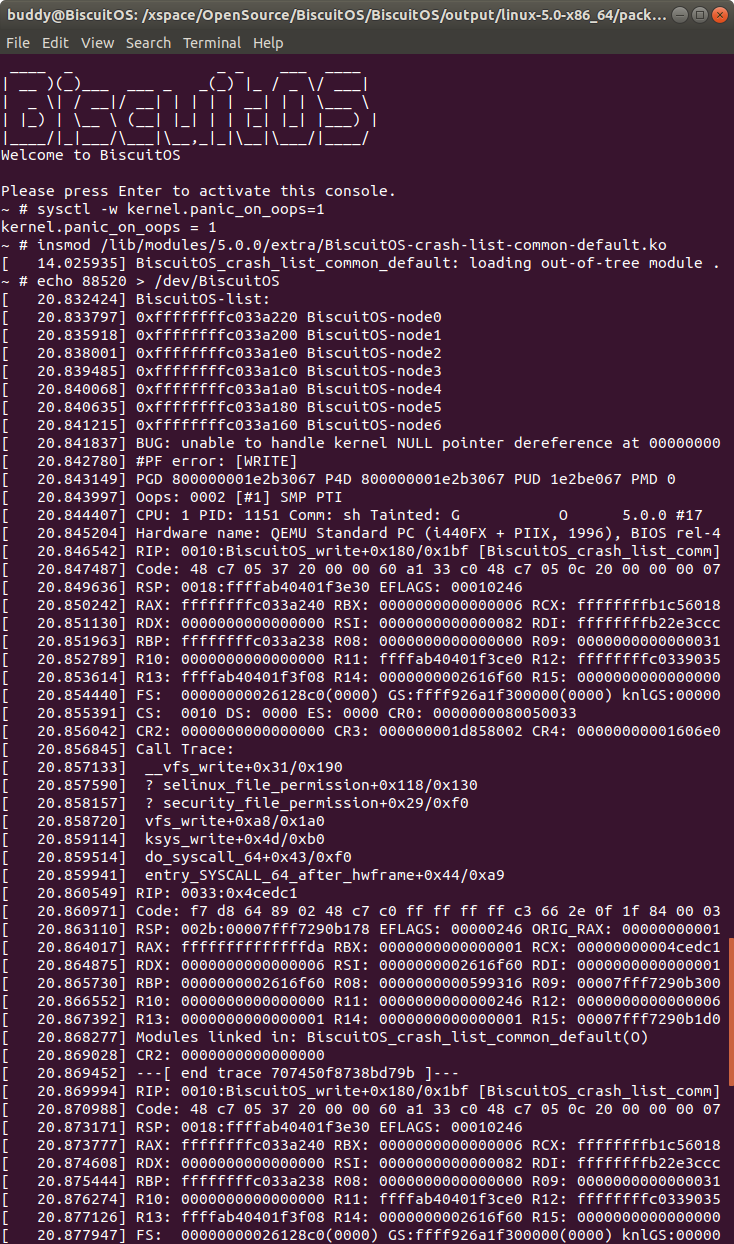
在 BiscuitOS 上运行实例之前,先将 PANIC 的 OOPS 选项设置为 1,以免 OOPS 被 killed,具体命令 “sysctl -w kernel.panic_on_oops=1”. 接着加载模块 “BiscuitOS-crash-list-common-default.ko”, 此时触发内核核心转储,此时通过不同的方法获得内核核心转储文件,并对其进行分析:
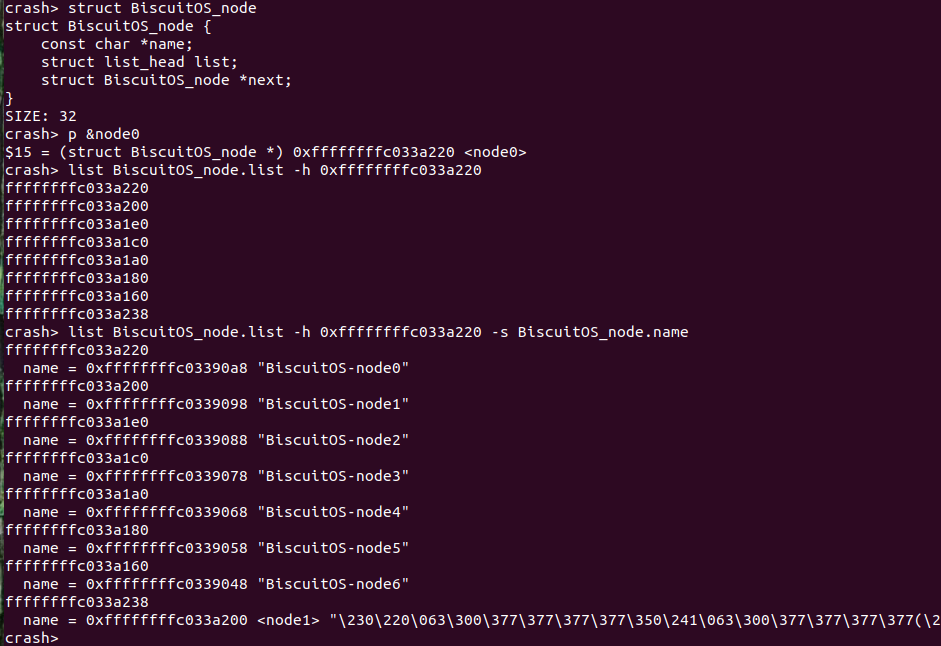
在实践例子中,node0 与其他 node 通过 list 成员都成了一个双链表,并以 BiscuitOS_list 为双链表的表头。那么首先通过 p 命令获得 node0 的地址,接着通过 “structure.member” 的方式指明数据结构中的双链表成员,这里指定为 “BiscuitOS_node.list”. 那么接下来通过 “-h” 选项跟上双链表成员的起始地址,这样就可以遍历整个双链表。最后借助 “-s” 选项打印 BiscuitOS_node 成员的 name。另外也可以使用 offset 的方式:
list -s/-S struct 打印链表成员的内容
CRASH list 命令可以用于打印链表成员的地址,但通常需要查看链表成员的内容,这个时候可以使用 “-s” 选项,其后跟上需要查看内容的成员描述,可以使用 “structure.member” 进行描述。”-S” 选项与 “-s” 类似,由于内容直接从内存中读取,比 “-s” 速度快一些。接下来通过一个实践例子研究该选项的使用。在 BiscuitOS 中提供了一个实践案例用于介绍该命令的使用,其部署流程如下 (以 linux 5.0 X86_64 为例):
cd BiscuitOS
make linux-5.0-x86_64_defconfig
make menuconfig
[*] Package --->
[*] CRASH and BUG Example --->
[*] Example: list Common --->
BiscuitOS/output/linux-5.0-x86_64/package/BiscuitOS-crash-list-common-default
实践例子是一个独立模块,模块基于 MISC 驱动框架进行构建。在模块中构建名为 BiscuitOS_node 的结构体,该结构体的 name 成员用于包含名字相关的字符串; 成员 list 为内嵌在结构体中双链表数据结构,该成员将 BiscuitOS_node 链接成双链表的关系; 成员 next 则为指向相同数据类型的指针,该指针构成一个 BiscuitOS_node 的单链表。模块定义了一个双链表的表头 BiscuitOS_list, 以及定义了 6 个 struct BiscuitOS_node 变量,每个变量都有独立的名字。模块中提供了 write 接口,在 BiscuitOS_write() 函数中,通过调用 list_add_tail() 函数将 6 个成员链接到 BiscuitOS_list 双链表上。函数紧接着将 node0 的 next 成员指向 node1, 以此类推,构建了 node0 到 node6 的单链表。最后 BiscuitOS_write() 函数中存在一个空指针的引用。如果在用户空间向该驱动写入操作的时候,就会触发空指针的引用,这个时候就会触发内核 PANIC,最终获得内核转储文件。接着在 BiscuitOS 上实践该实例,并使用 CRASH 进行调试:
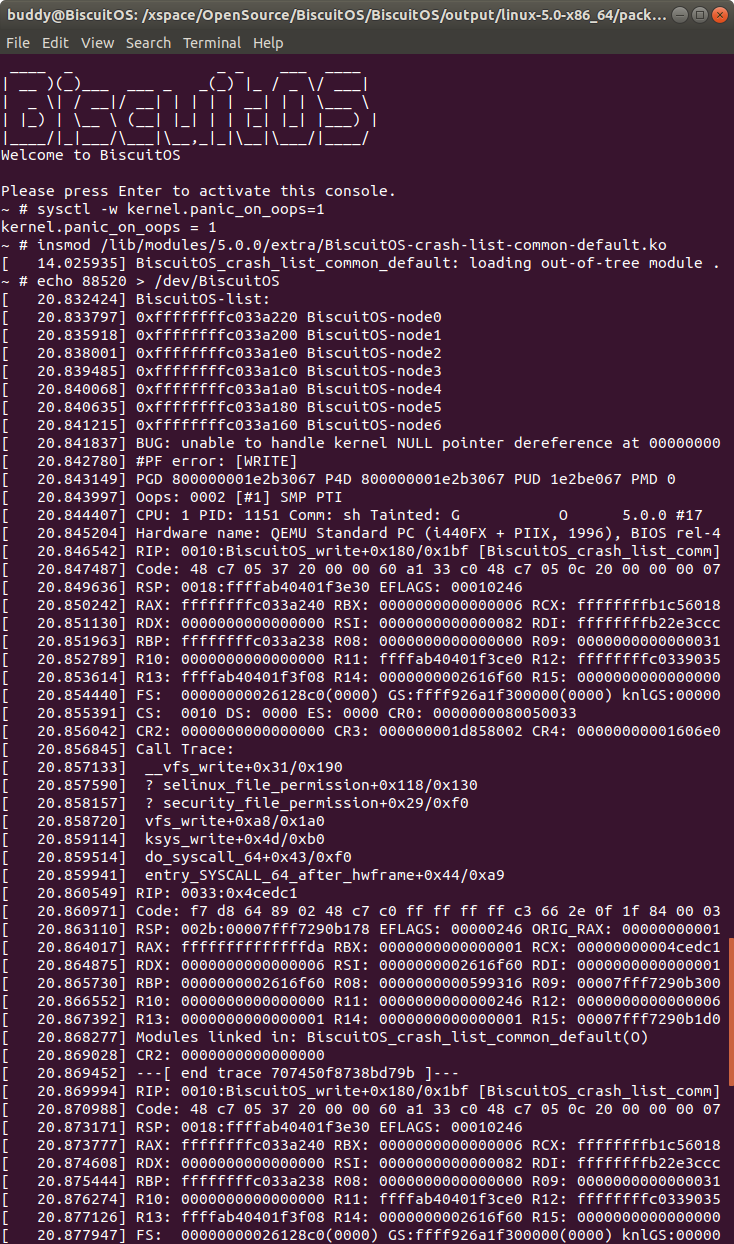
在 BiscuitOS 上运行实例之前,先将 PANIC 的 OOPS 选项设置为 1,以免 OOPS 被 killed,具体命令 “sysctl -w kernel.panic_on_oops=1”. 接着加载模块 “BiscuitOS-crash-list-common-default.ko”, 此时触发内核核心转储,此时通过不同的方法获得内核核心转储文件,并对其进行分析:
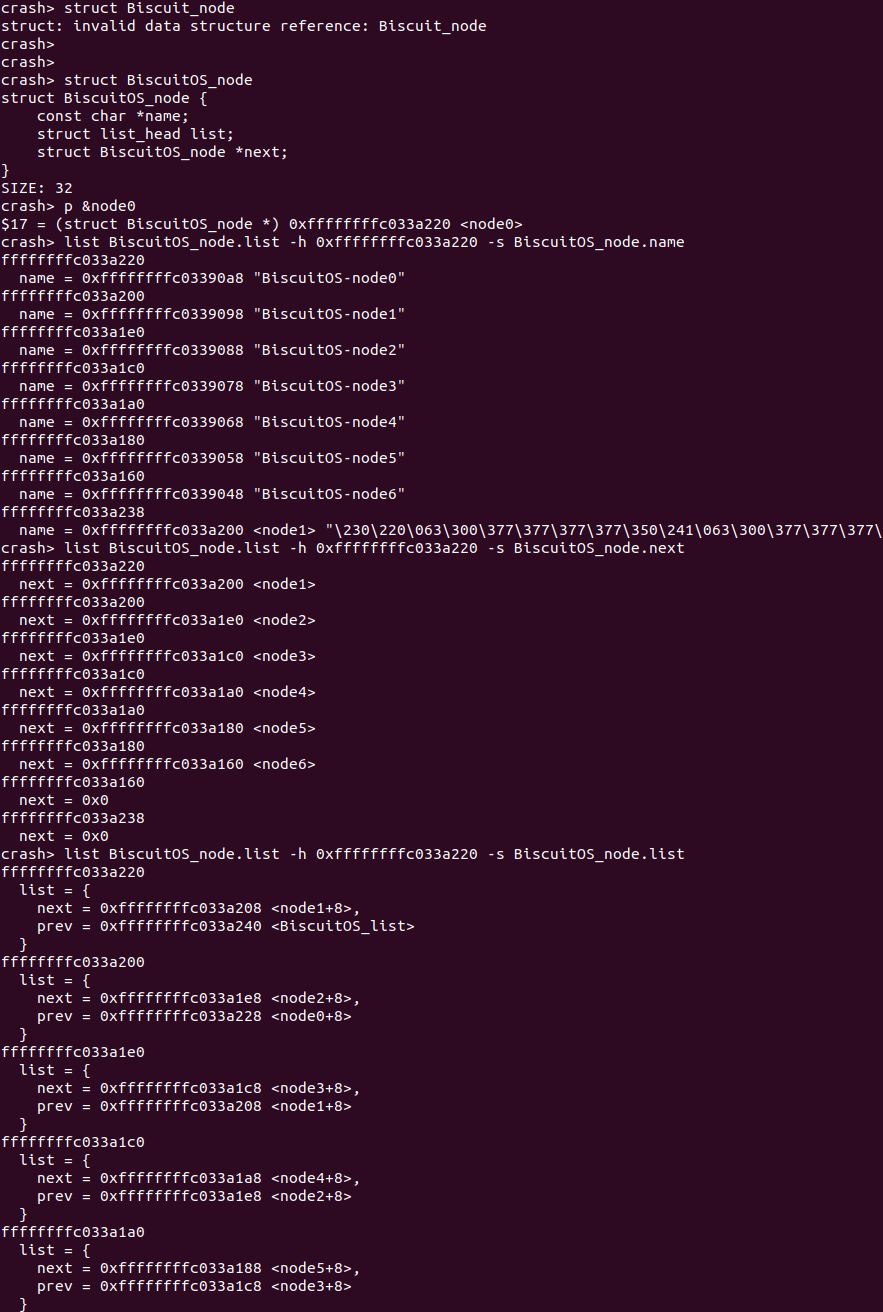
在实践例子中,使用 “-h” 选项遍历了双链表,在遍历的时候使用 “-s” 选项可以查看链表成员的 name、next、以及 list 的值.
list -r 逆序输出链表
CRASH list 命令可以用于打印链表成员的地址,此时按链表的正序输出链表的成员地址。CRASH list 同时提供了 “-r” 选项实现逆序输出成员的地址,再结合其他选项可以输出符合要求的链表内容。接下来通过一个实践例子研究该选项的使用。在 BiscuitOS 中提供了一个实践案例用于介绍该命令的使用,其部署流程如下 (以 linux 5.0 X86_64 为例):
cd BiscuitOS
make linux-5.0-x86_64_defconfig
make menuconfig
[*] Package --->
[*] CRASH and BUG Example --->
[*] Example: list Common --->
BiscuitOS/output/linux-5.0-x86_64/package/BiscuitOS-crash-list-common-default
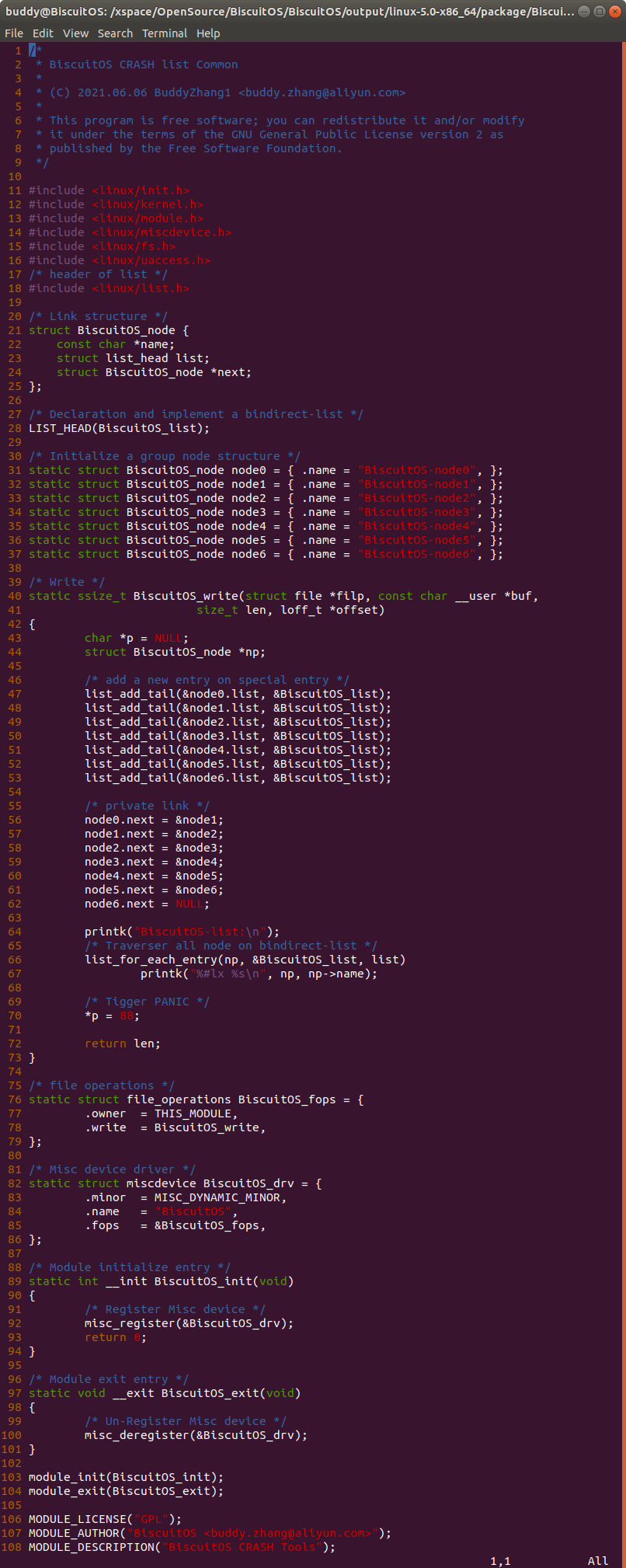
实践例子是一个独立模块,模块基于 MISC 驱动框架进行构建。在模块中构建名为 BiscuitOS_node 的结构体,该结构体的 name 成员用于包含名字相关的字符串; 成员 list 为内嵌在结构体中双链表数据结构,该成员将 BiscuitOS_node 链接成双链表的关系; 成员 next 则为指向相同数据类型的指针,该指针构成一个 BiscuitOS_node 的单链表。模块定义了一个双链表的表头 BiscuitOS_list, 以及定义了 6 个 struct BiscuitOS_node 变量,每个变量都有独立的名字。模块中提供了 write 接口,在 BiscuitOS_write() 函数中,通过调用 list_add_tail() 函数将 6 个成员链接到 BiscuitOS_list 双链表上。函数紧接着将 node0 的 next 成员指向 node1, 以此类推,构建了 node0 到 node6 的单链表。最后 BiscuitOS_write() 函数中存在一个空指针的引用。如果在用户空间向该驱动写入操作的时候,就会触发空指针的引用,这个时候就会触发内核 PANIC,最终获得内核转储文件。接着在 BiscuitOS 上实践该实例,并使用 CRASH 进行调试:
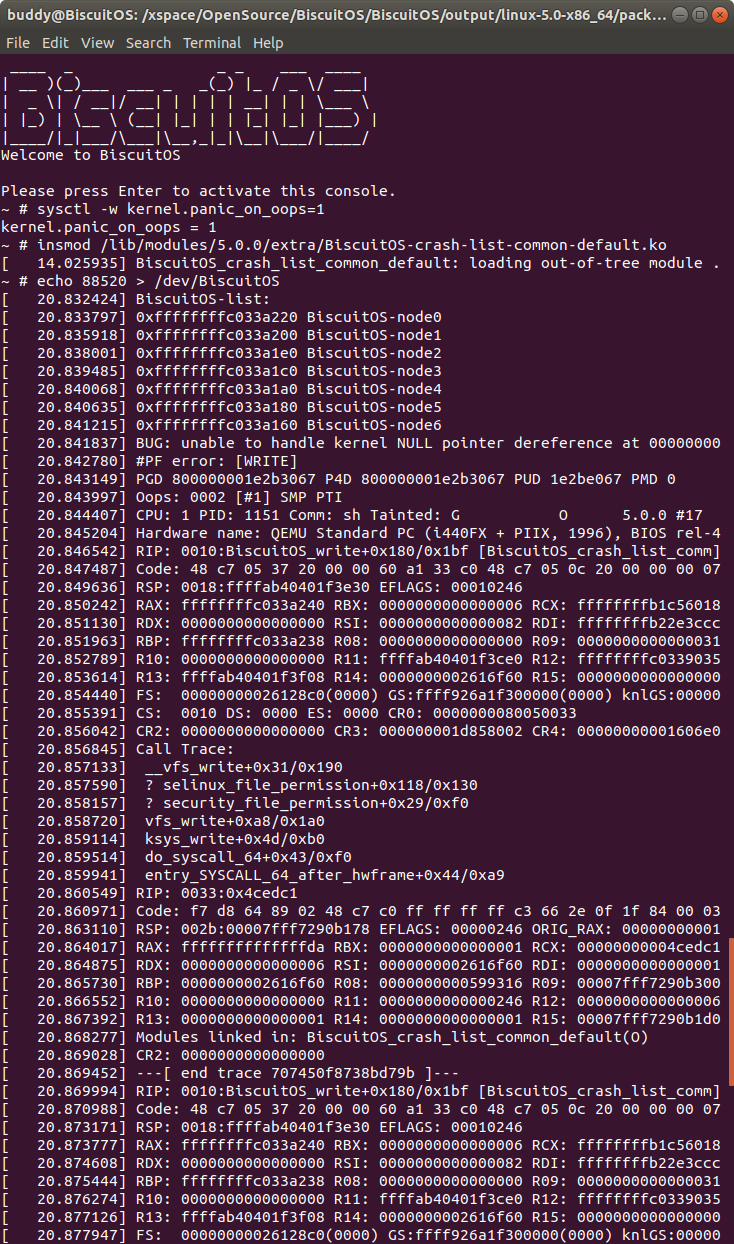
在 BiscuitOS 上运行实例之前,先将 PANIC 的 OOPS 选项设置为 1,以免 OOPS 被 killed,具体命令 “sysctl -w kernel.panic_on_oops=1”. 接着加载模块 “BiscuitOS-crash-list-common-default.ko”, 此时触发内核核心转储,此时通过不同的方法获得内核核心转储文件,并对其进行分析:
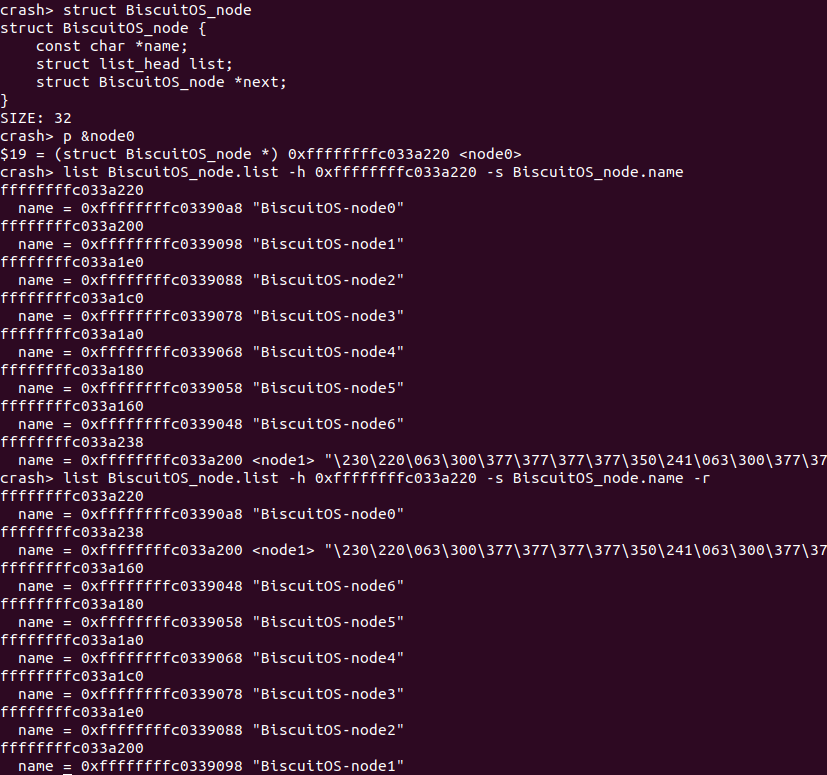
在实践例子中,使用 “-h” 选项遍历了双链表,在遍历的时候使用 “-s” 选项可以查看链表成员的 name、next、以及 list 的值. 此时使用 “-r” 选项逆序输出链表成员的内容.
Crash 系统内存统计信息
当使用 CRASH 分析内核转储文件时,系统的内存使用率对问题的定位提供了很多有用的信息,例如当前系统物理内存使用情况、物理页使用情况、SLAB 缓存数据情况等,CRASH 提供了 kmem 命令用于获得系统内存使用信息,如下 :
# SYNOPSIS
kmem [-f|-F|-c|-C|-i|-v|-V|-n|-z|-o|-h] [-p | -m member[,member]]
[[-s|-S|-r] [slab] [-I slab[,slab]]] [-g [flags]] [[-P] address]]
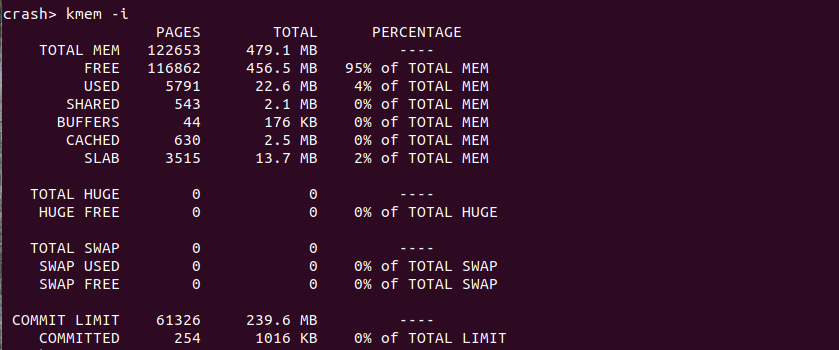
kmem -i 打印系统物理内存使用情况
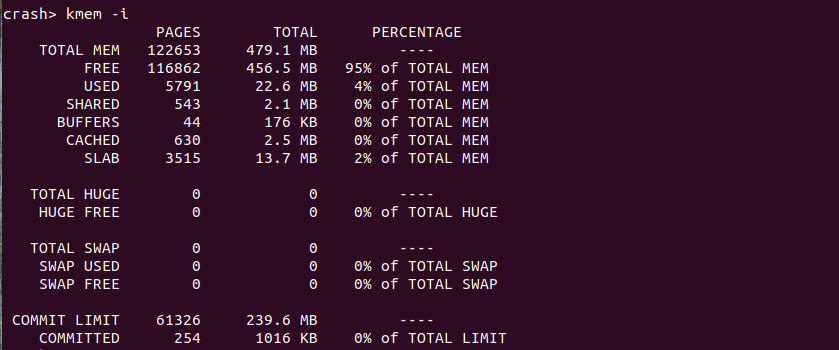
当使用 CRASH 解析内核转储文件时,使用 “kmem -i” 命令可以获得内核崩溃时系统物理内存的使用量,其各字段含义如下:
- PAGES 表示占有物理页的数量
- TOTAL 表示占用物理内存的数量
- PERCENTAGE 表示占用总物理内存的百分比
- TOTAL MEM 表示系统总共占用物理内存的情况
- FREE 表示系统中空闲物理内存的情况
- USED 表示系统中已经使用物理内存的情况
- SHARED 表示系统中共享物理内存使用情况
- BUFFERS 表示 Buffer 占用物理内存情况
- CACHED 表示 Page Cache 占用物理内存的情况
- TOTAL HUGE 表示系统中大页占用物理内存的数量
- HUGE FREE 表示系统中可用大页占用的物理内存数量
- TOTAL SWAP 表示 SWAP 空间的大小
- SWAP USED 表示 SWAP 空间已使用的数量
- SWAP FREE 表示 SWAP 空间空闲的数量
kmem -f 打印 ZONE 内 free_area 的信息
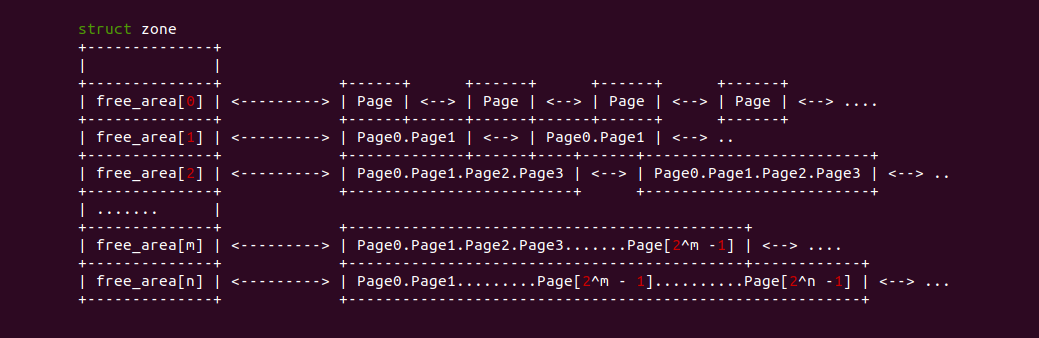
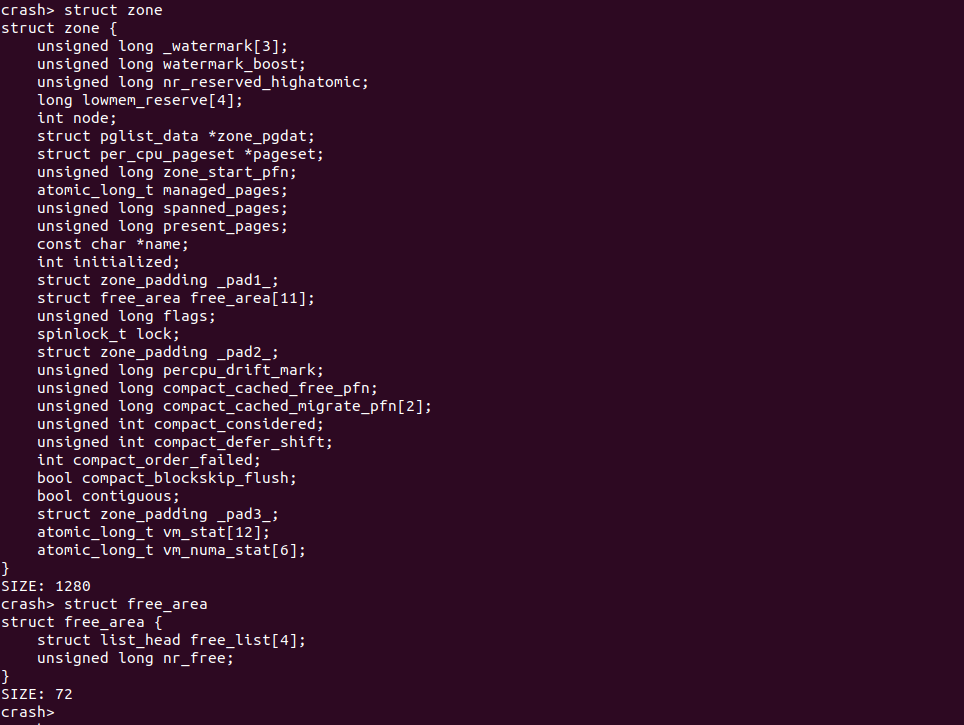
系统物理内存被划分成一个一个物理页,物理页通过 struct page 进行维护管理,每个物理页按循序进行编号,该号码称为物理页的页帧号,简称为 PFN. 系统在初始化过程中,将物理内存划分成不同的 Zone,Zone 也是一定物理页的集合,Zone 区域的物理页用于特定功能,例如 DMA/DMA32 Zone 的物理内存就用于特殊地址的外设使用,而 Normal Zone 的物理页则用于正常的内核活动,而 Highmem Zone 的物理页就给用户空间使用。Zone 通过 struct zone 进行管理和维护,struct zone 结构体中存在 free_area 成员,该成员是由 struct free_aera 组成长度为 11 的数组,位于该 Zone 的物理页基于其大小被 page->lru 链表链接到了不同 free_area[] 数组成员上,以此作为 Buddy 分配器物理页来源。
在 struct free_area 结构体中包含了一个 struct list 的数组,数组长度为 4,系统根据迁移类型将物理页划分成 MIGRATE_UNMOVABLE、MIGRATE_MOVABLE、MIGRATE_RECLAIMABLE、MIGRATE_PCPTYPES、MIGRATE_HIGHATOMIC、MIGRATE_CMA、MIGRATE_ISOLATE 种类,其中数组的长度为 MIGRATE_TYPES. 同样大小的物理页会因为迁移类型不同最终插入到不同的 free_list 上。基于上面的原理,CRASH kmem 命令提供了 “-f” 选项用于打印所有 Zone 上 free_area 信息,CRASH 可以根据这些信息获得更多有效的信息,其使用如下:
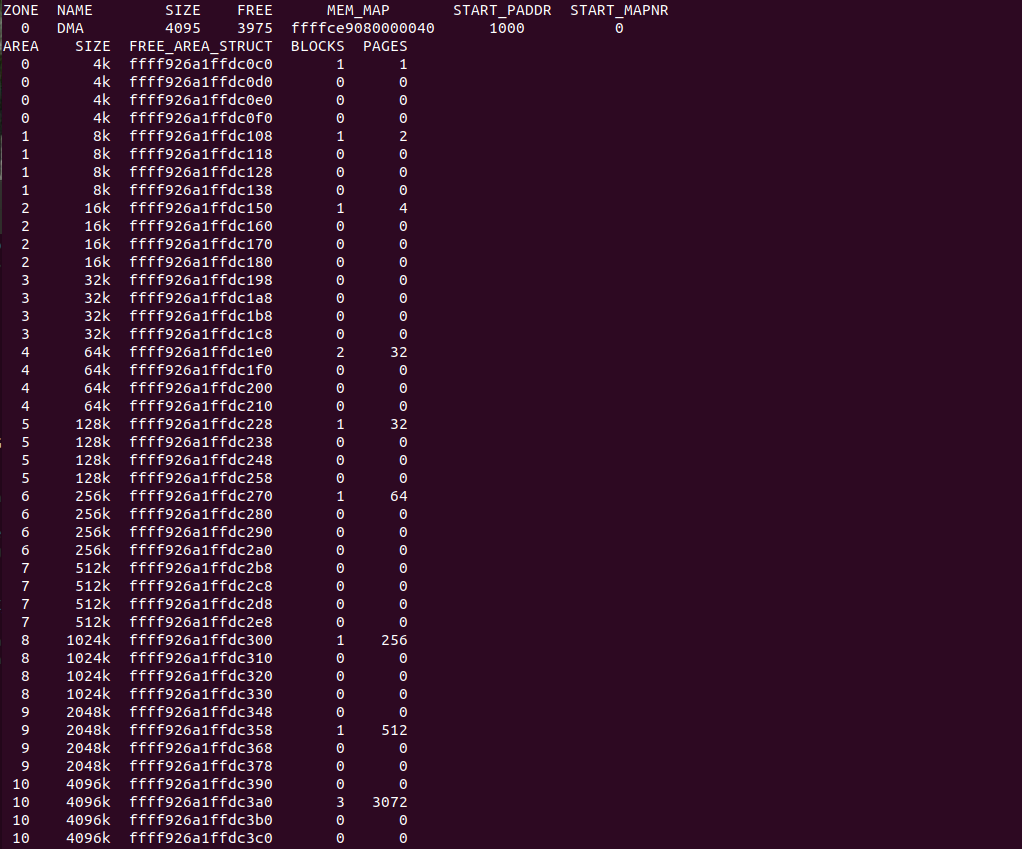
- ZONE 表明 Zone Idx 编号
- NAME 指明 Zone 的名字
- SIZE 该 Zone 物理页的总数
- FREE 空闲物理页的数量
- MEM_MAP 该 Zone 在 mem_map[] 数组中第一个 struct page 的地址
- START_PADDR 该 Zone 第一个物理页对应的物理地址
- START_MAPNR 该 Zone 第一个物理页在 mem_map[] 数组中的偏移
- AREA 表明该 free_arae 中物理页的 ORDER 大小
- SIZE 表明该 free_area 中物理页块的大小
- FREE_AREA_STRUCT 表明 free_area 中 free_list 的地址
- BLOCKS 表明该 free_area 中物理页块的数量
- PAGES 表明该 free_area 中物理页的数量
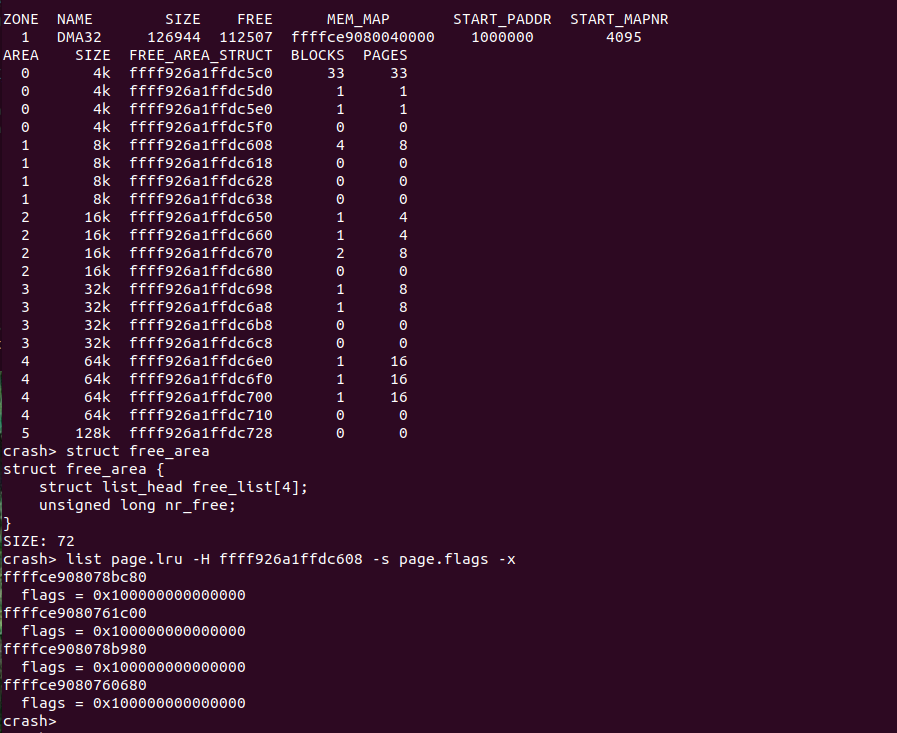
由于 “kmem -f” 是输出了所有 free_area 的 free_list 地址,该链表作为指定迁移类型的双链表表头,于是可以使用 “list” 命令将链表中的成员都打印出来。物理页 struct page 的 lru 成员通过物理页的迁移类型插入到指定的 free_list 双链表上,有了以上两个基础,使用 “list -H” 命令指向该双链表表头,然后借助 “list -s” 打印所需的内容,这里打印的物理页 struct page 的 flags 成员. 在上图的实例中,选择了 8k 的 ffff926a1ffdc608 作为研究对象.
kmem -v 打印 VMALLOC 分配器分配的内存信息

KMALLOC 内存分配器用于分配虚拟地址连续而物理地址不一定连续的内存,其从内核的虚拟区域中划分一段区域,起始与 VMALLOC_START, 终止于 VMALLOC_END. VMALLOC 分配器将每分配出去的区域使用 struct vmap_area 结构体进行描述,对于该区域对于的物理内存则通过 struct vm_struct 结构体进行描述,其定义如下:
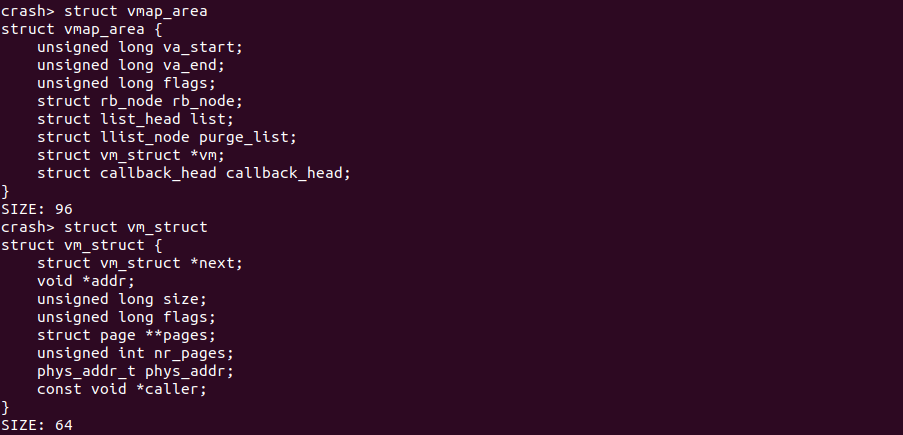
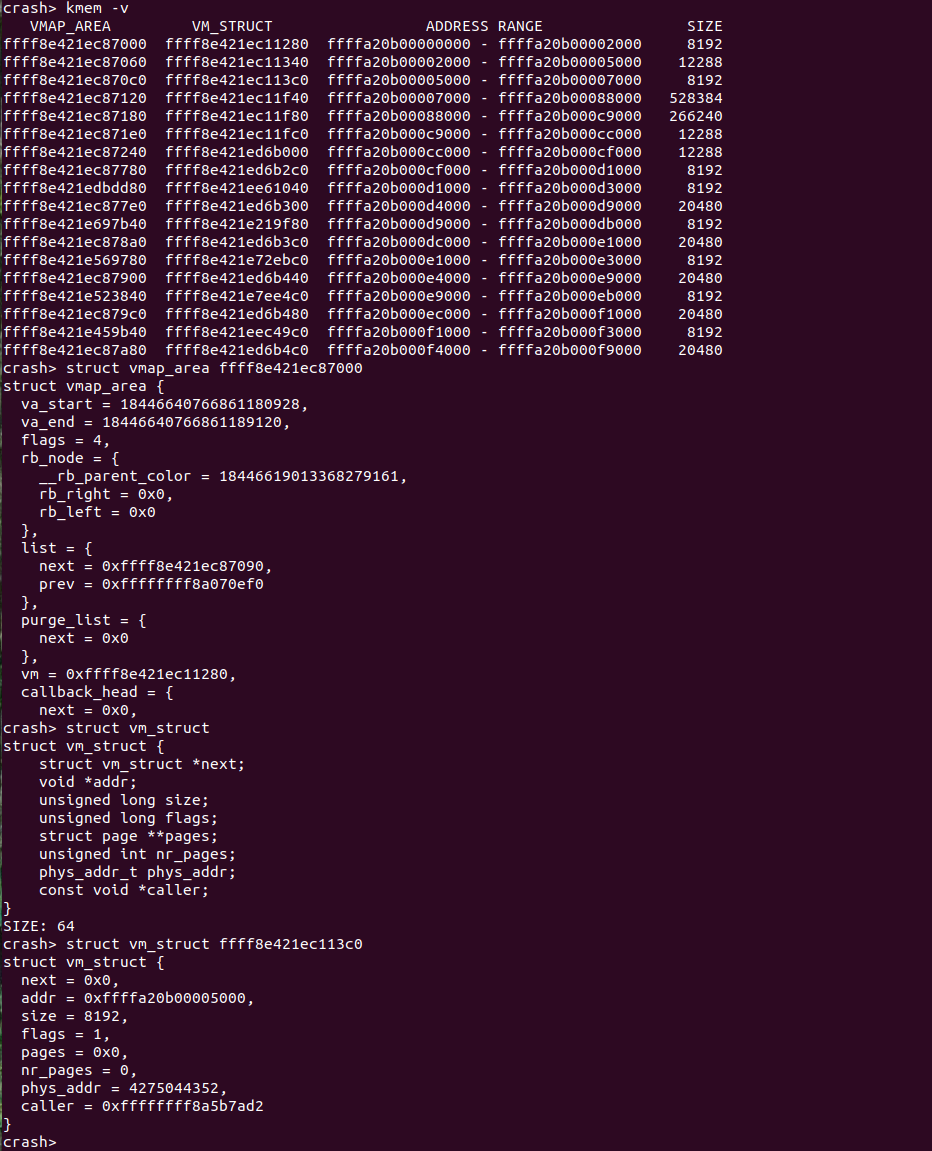
CRASH 提供了 “kmem -v” 命令用于查看 VMALLOC 分配器分配的情况,通过该命令可以获得已经分配区域 struct vmap_area 的地址、struct vm_struct 的地址、区域的范围以及区域的大小。结合 CRASH 其它命令还可以获得更多有用的信息:
kmem -V 打印系统 vm_state 表内容
内核将物理内存根据用途划分为不同的 Zone,每个 Zone 通过 struct zone 结构体进行维护,该结构体中包含了 vm_state/vm_numa_state 等用于统计内存使用情况的成员,内核在统计内存使用情况时,其从各个 Zone 的 struct zone 成员中读取数据进行统计。其中 struct zone 的 vm_state 成员通过 enum zone_state_item 进行描述,其具体成员包括:
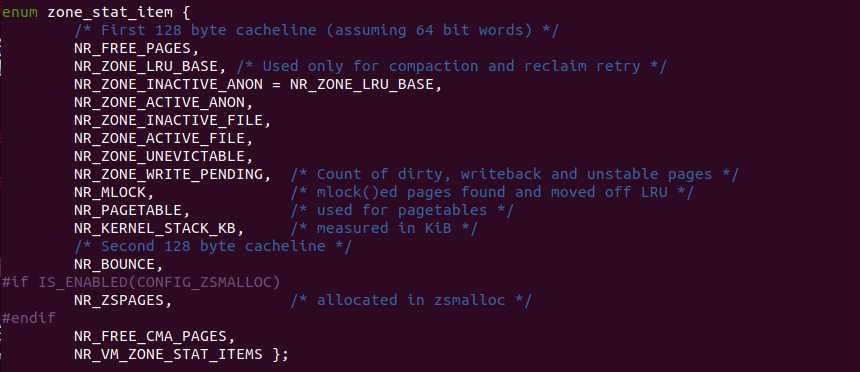
- NR_FREE_PAGES Zone 中空闲物理页的数量
- NR_ZONE_LRU_BASE Zone 中压缩和回收 LRU 基础物理页数量
- NR_ZONE_INACTIVE_ANON Zone 中不活跃匿名页的数量
- NR_ZONE_ACTIVE_ANON Zone 中活跃匿名页的数量
- NR_ZONE_INACTIVE_FILE Zone 中不活跃的文件映射页数量
- NR_ZONE_ACTIVE_FILE Zone 中活跃的文件映射页数量
- NR_ZONE_UNEVICTABLE
- NR_ZONE_WRITE_PENDING Zone 中脏页的数量
- NR_MLOCK mlock 的页数量
- NR_PAGETABLE Zone 中页表页的数量
- NR_KERNEL_STACK_KB
- NR_BOUNCE
- NR_ZSPAGES ZSMALLOC 分配器分配的物理页数量
- NR_FREE_CMA_PAGES Zone 上空闲的 CMA 物理页数量

CRASH 提供的 “kmem -V” 命令可以查看内核崩溃时所有 Zone 的 vm_state 统计数据. CRASH 打印的 VM_ZONE_STATE 数据项目正好以 enum zone_state_item 中的项目对应上, 因此可以通过这些数据分析内核崩溃时一些物理页的使用信息.
kmem -V 打印系统 vm_node_state 表内容
在多 NUMA NODE 或者单 NUMA NODE 的系统中,内核使用 struct pglist_data 结构体维护一个 NUMA NODE,在其中包含了 vm_state 成员,该成员统计了该 NUMA NODE 上物理页使用情况。该 vm_state 的成员通过 enum node_state_item 进行定义,其具体成员如下:
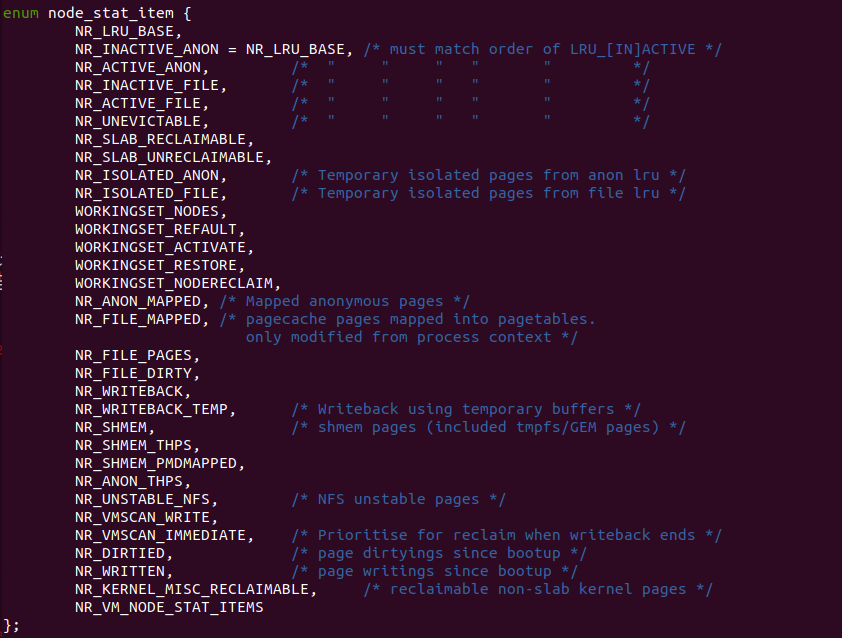
- NR_LRU_BASE NODE 上 LRU 物理页的最小值
- NR_INACTIVE_ANON NODE 上不活跃匿名页的数量
- NR_ACTIVE_ANON NODE 上活跃匿名页的数量
- NR_INACTIVE_FILE NODE 上不活跃文件映射页的数量
- NR_ACTIVE_FILE NODE 上活跃文件映射页的数量
- NR_UNEVICTABLE
- NR_SLAB_RECLAIMABLE NODE 上 SLAB 回收物理页的数量
- NR_SLAB_UNRECLAIMABLE NODE 上 SLAB 不可回收物理页的数量
- NR_ISOLATED_ANON NODE 上 LRU 链表里孤立匿名页的数量
- NR_ISOLATED_FILE NODE 上 LRU 链表里孤立 Page Cache 页数量
- WORKINGSET_NODES
- WORKINGSET_REFAULT
- WORKINGSET_ACTIVATE
- WORKINGSET_RESTORE
- WORKINGSET_NODERECLAIM
- NR_ANON_MAPPED NODE 上匿名映射物理页的数量
- NR_FILE_MAPPED NODE 上文件映射物理页的数量
- NR_FILE_PAGES NODE 上 Page Cache 页的数量
- NR_FILE_DIRTY NODE 上文件脏页的数量
- NR_WRITEBACK NODE 上回写物理页的数量
- NR_WRITEBACK_TEMP
- NR_SHMEM NODE 上共享页的数量
- NR_SHMEM_THPS NODE 上共享透明大页的数量
- NR_SHMEM_PMDMAPPED NODE 上共享 PMD 映射的大页数量
- NR_ANON_THPS NODE 上匿名透明大页的数量
- NR_UNSTABLE_NFS
- NR_VMSCAN_WRITE
- NR_VMSCAN_IMMEDIATE
- NR_DIRTIED
- NR_WRITTEN
- NR_KERNEL_MISC_RECLAIMABLE
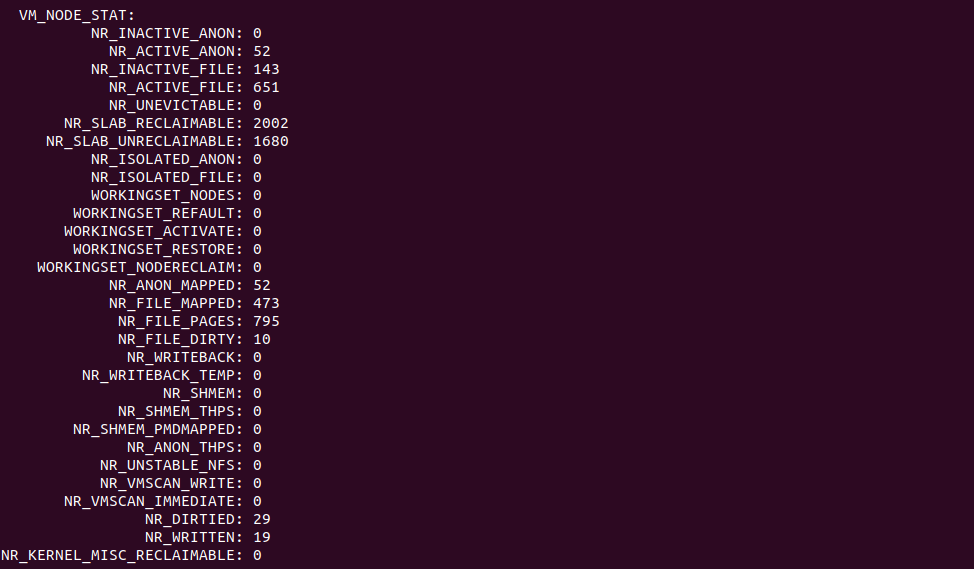
CRASH 提供的 “kmem -V” 命令可以查看内核崩溃时所有 NODE 的 vm_state 统计数据. CRASH 打印的 VM_NODE_STATE 数据项目正好以 enum node_state_item 中的项目对应上, 因此可以通过这些数据分析内核崩溃时一些物理页的使用信息.
kmem -V 打印系统 vm_numa_state 表内容
内核将物理内存根据用途划分为不同的 Zone,每个 Zone 通过 struct zone 结构体进行维护,该结构体中包含了 vm_state/vm_numa_state 等用于统计内存使用情况的成员,内核在统计内存使用情况时,其从各个 Zone 的 struct zone 成员中读取数据进行统计。Zone 可能位于一个或多个 NUNA NODE 之上,通常情况下本地 CPU 应从本地 NUMA NODE 上分配物理内存,只有本地物理内存不够用时才从其他 NUMA NODE 上分配物理内存。另外 struct zone 的 vm_numa_state 成员通过 enum numa_state_item 进行描述,其具体成员包括:

- NUMA_HIT 在该 NUMA NODE 上分配物理页的数量
- NUMA_MISS 在其他 NUMA NODE 上分配物理页的数量
- NUMA_FOREIGN
- NUMA_INTERLEAVE_HIT
- NUMA_LOCAL
- NUMA_OTHER

CRASH 提供的 “kmem -V” 命令可以查看内核崩溃时所有 ZONE 的 vm_numa_state 统计数据. CRASH 打印的 VM_NUMA_STATE 数据项目正好以 enum numa_state_item 中的项目对应上, 因此可以通过这些数据分析内核崩溃时一些物理页的使用信息.
kmem -V 打印系统 vm_event_state 表内容
内核使用 vm_event_states 统计所有内存事件,其属于 struct vm_event_state 结构体,其包含了一个长度为 NR_VM_EVENT_ITEMS 的 unsigned long 数组。vm_event_states 维护的事件类型通过 enum vm_event_item 定义:
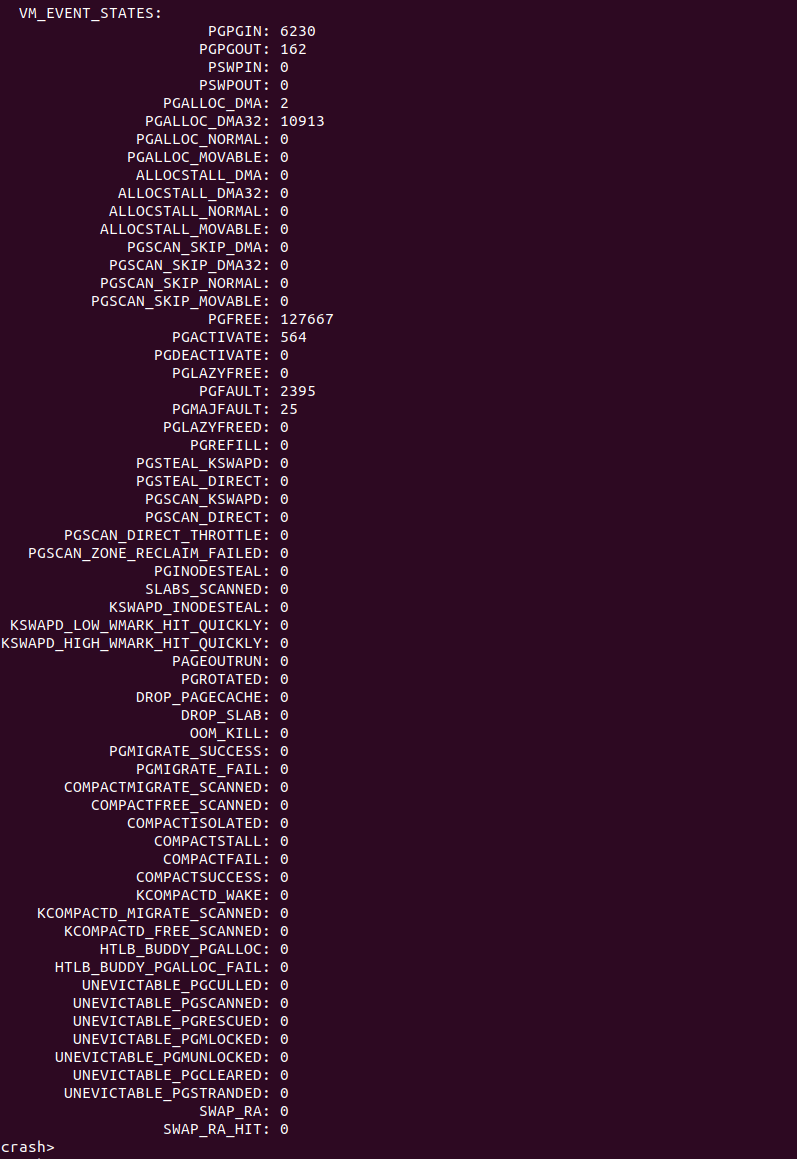
CRASH 提供的 “kmem -V” 命令可以查看内核崩溃时所有内存事件的统计数据,其数据来源正好是 vm_event_states 变量。因此可以通过这些数据分析内核崩溃时的内存情况:
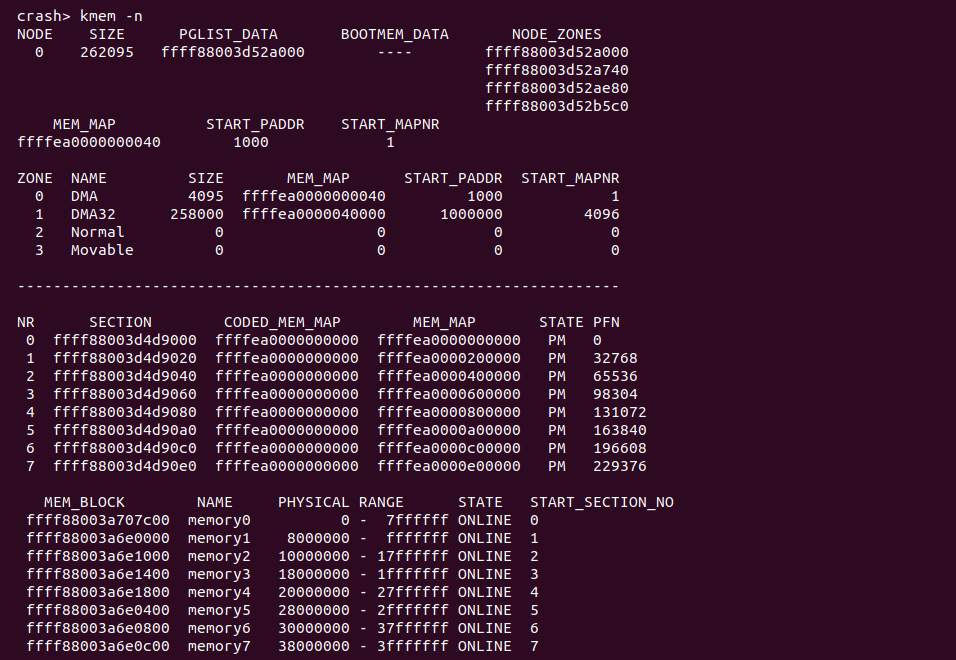
kmem -n 打印内存模型下的物理内存信息
内核支持平坦内存模式和 SPARSE 内存模型,平坦内存模型会将物理内存当做一个整体,并将整体按顺序划分成一块块的物理页,每个物理页都有各自的物理页帧号; SPARSE 内存模型则将物理内存划分成一块一块的 memory section,在每个 memory section 内部再按顺序划分成一块块物理页,每个物理页也有属于自己的物理页帧号。两种模型都有各自的特点,从物理页的角度来看,来自似乎是一致的。但 SPARSE 内存模型多用于 NUMA 架构下,内核使用 struct pglist_data 结构体来描述一个 NUMA NODE,其定义如下:
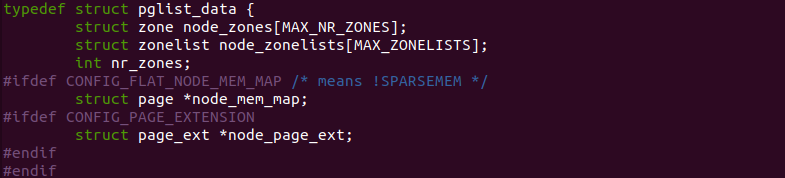
在 struct pglist_data 结构体中包含了 node_zones[] 数组,该数组维护了该 NODE 下 Zone 的信息,内核使用 struct zone 结构体来描述一个 Zone,每个 NODE 能包含的最大 Zone 数量通过 MAX_NR_ZONES 进行指定。在每个 NODE 下包含了多个 ZONE,这些 Zone 可能是 ZONE_DMA/ZONE_DMA32/ZONE_Normal/ZONE_Movable/ZONE_Highmem 等。物理页通过 struct page 结构体进行描述,内核将所有的 struct page 放置在 mem_map[] 数组中。由于在 SPARSE 内存模型中,内核将多个物理页组成一个 memory section,该 memory section 就是物理页的集合,其通过 struct mem_section 结构体进行维护。CRASH 提供了 “kmem -n” 命令就是用于打印内核模型下物理内存信息, 其各字段含义如下:
- NODE 字段描述了 NUMA NODE ID
- SIZE 字段描述了 Memory Section 的大小,以 KB 为单位
- PGLIST_DATA 字段描述 NUMA NODE 对应 struct pglist_data 的地址
- BOOTMEM_DATA 字段描述了 BOOT NUMA NODE 对应 struct bootmem_data 的地址
- NODE_ZONES 描述了该 NUMA NODE 下对应 ZONE struct zone 的地址
- MEM_MAP 字段描述了系统 mem_map[] 的地址
- START_PADDR 描述了 mem_map[] 第一个成员对应的物理地址
- START_MAPNR 描述了 mem_map[] 第一个成员对应的物理页帧号
- ZONE NAME 字段描述了 ZONE 的名字
- SIZE 字段描述了该 ZONE 中包含物理页的数量
- MEM_MAP 字段描述该 ZONE 的起始物理页在 mem_map[] 中的地址
- START_PADDR 字段描述 ZONE 的起始物理页对应的物理地址
- START_MAPNR 字段描述 ZONE 的起始物理页帧号
- NR 字段描述了 memory section 的 SECTION ID
- SECTION 字段描述该 memory section 对应的 struct mem_section 地址
- CODED_MEM_MAP 字段描述该 Section 对应的 mem_map
- MEM_MAP 字段描述该 Section 起始物理页在 mem_map[] 中的地址
- PFN 字段描述了该 Section 的起始物理页帧号
- STATE 字段描述了 Section 的状态 (P: SECTION_MARKED_PRESENT, M: SECTION_HAS_MEM_MAP, O: SECTION_IS_ONLINE, E: SECTION_IS_EARLY)
- MEM_BLOCK 字段描述 struct memory_block 的地址
- NAME 字段描述 MEM_BLOCK 的名字
- PHYSICAL RANGE 字段描述 MEM_BLOCK 的物理内存范围
- STATE 字段描述 MEM_BLOCK 的状态
- START_SECTION_NO 字段描述 MEM_BLOCK 所在的 SECTION ID.
kmem -z 打印所有 Zone 的统计信息
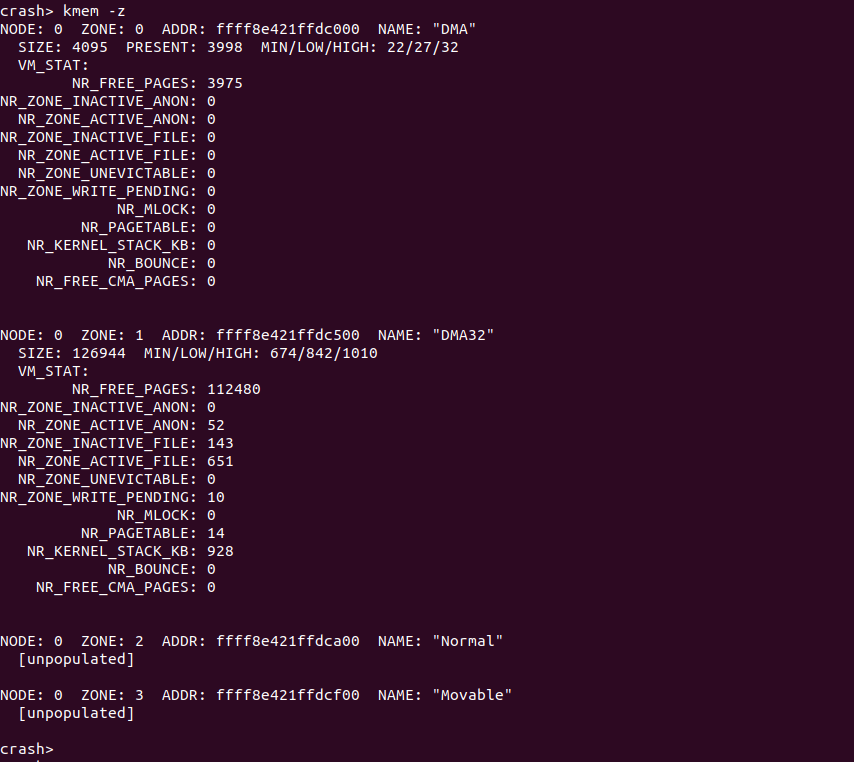
内核将内存划分成不同的 ZONE 进行维护,不同的 ZONE 用于不同的目的。ZONE_DMA 主要给一些老式的设备使用的内存,ZONE_DMA32 主要给内核和一些新的外设使用,ZONE_Normal 则给基础的内核活动使用,ZONE_Highmem 则给用户使用的物理内存,ZONE_Movable 则是可以移动的物理内存。ZONE 通过 struct zone 结构体进行描述,其包含了该 Zone 的内存使用统计信息。CRASH 提供了 “kmem -z” 命令可以用于查看所有 ZONE 的上的统计信息,其个字段含义如下:
- NODE 字段指明 ZONE 所在的 NUMA NODE
- ZONE 字段指明 ZONE ID
- ADDR 字段指明 ZONE 对应 struct zone 的地址
- NAME 字段指明了 ZONE 的名字
- SIZE 字段指明了 ZONE 中包含物理页的数量
- PRESENT 字段指明了实际存在的物理页数量
- MIN/LOW/HIGH 字段指明了该 ZONE 的物理内存水位线
- VM_STAT 字段指明了 Zone 的 vm_state 统计信息
- NR_FREE_PAGES Zone 中空闲物理页的数量
- NR_ZONE_LRU_BASE Zone 中压缩和回收 LRU 基础物理页数量
- NR_ZONE_INACTIVE_ANON Zone 中不活跃匿名页的数量
- NR_ZONE_ACTIVE_ANON Zone 中活跃匿名页的数量
- NR_ZONE_INACTIVE_FILE Zone 中不活跃的文件映射页数量
- NR_ZONE_ACTIVE_FILE Zone 中活跃的文件映射页数量
- NR_ZONE_UNEVICTABLE
- NR_ZONE_WRITE_PENDING Zone 中脏页的数量
- NR_MLOCK mlock 的页数量
- NR_PAGETABLE Zone 中页表页的数量
- NR_KERNEL_STACK_KB
- NR_BOUNCE
- NR_ZSPAGES ZSMALLOC 分配器分配的物理页数量
- NR_FREE_CMA_PAGES Zone 上空闲的 CMA 物理页数量
kmem -h 打印大页内存信息

CRASH 提供了 “kmem -h” 命令可以查看大页的使用情况,各字段的含义如下:
- SIZE 大页的体积
标签:BiscuitOS,crash,struct,命令,内核,进程,CRASH,方法,调试 From: https://www.cnblogs.com/dongxb/p/17364995.html原文链接:https://biscuitos.github.io/blog/CRASH/#D1 版权归原作者所有,如有侵权,请联系作者删除