1、张量(tensor)
张量我们可以理解为三维及以上的数据。
2、使用PyTorch创建张量
-
通过torch.rand()的方法,构造一个随机初始化的矩阵:
import torch x = torch.rand(4, 3) print(x) -
通过torch.zeros()构造一个矩阵全为 0,并且通过dtype设置数据类型为 long
-
我们还可以通过torch.zero_()和torch.zeros_like()将现有矩阵转换为全0矩阵.
import torch x = torch.zeros(4, 3, dtype=torch.long) print(x) -
通过torch.tensor()直接使用数据,构造一个张量:
import torch x = torch.tensor([5.5, 3]) print(x) -
基于已经存在的 tensor,创建一个 tensor :
x = x.new_ones(4, 3, dtype=torch.double)
# 创建一个新的全1矩阵tensor,返回的tensor默认具有相同的torch.dtype和torch.device
# 也可以像之前的写法 x = torch.ones(4, 3, dtype=torch.double)
print(x)
x = torch.randn_like(x, dtype=torch.float)
# 重置数据类型
print(x)
# 结果会有一样的size
# 获取它的维度信息
print(x.size())
print(x.shape)
3、张量的运算
(1)加法运算
import torch
# 方式1
y = torch.rand(4, 3)
print(x + y)
# 方式2
print(torch.add(x, y))
# 方式3 in-place,原值修改
y.add_(x)
print(y)
(2)索引
索引出来的结果与原数据共享内存,修改一个,另一个会跟着修改。如果不想修改,可以考虑使用copy()等方法
import torch
x = torch.rand(4,3)
# 取第二列
print(x[:, 1])
tensor([-0.0720, 0.0666, 1.0336, -0.6965])
y = x[0,:]
y += 1
print(y)
print(x[0, :]) # 源tensor也被改了
tensor([3.7311, 0.9280, 1.2497])
tensor([3.7311, 0.9280, 1.2497])
(3)维度变换
常见的方法有torch.view()和torch.reshape()
torch.reshape()虽然可以改变张量的形状,但是此函数并不能保证返回的是其拷贝值,所以官方不推荐使用。下面我们将介绍第一中方法torch.view():
x = torch.randn(4, 4)
y = x.view(16)
z = x.view(-1, 8) # -1是指这一维的维数由其他维度决定
print(x.size(), y.size(), z.size())
torch.Size([4, 4]) torch.Size([16]) torch.Size([2, 8])
接下来详细解释一下view(-1)
- 首先我们要明确view()返回的数据和传入的tensor一样,只是形状不同
- 随后我们就可以知悉-1在这里的意思是让电脑帮我们计算,比如上面的例子,总长度是16,我们不想自己算16/8=2,就可以在不想算的位置放上-1,电脑就会自己计算对应的数字,这个在实际搭建网络的时候是很好用的
- 如果我们单纯的只写了view(-1),那么由于我们缺乏其他的维度,因此就会将X里面的所有维度数据转化成一维的,并且按先后顺序排列。
- 还要注意view()返回的tensor和传入的tensor共享内存,意思就是修改其中一个,数据都会变。所以官方推荐的方法是我们先用 clone() 创造一个张量副本然后再使用 torch.view()进行函数维度变换 。
(4)取值操作
如果我们有一个元素 tensor ,我们可以使用 .item() 来获得这个 value,而不获得其他性质:
import torch
x = torch.randn(1)
print(type(x))
print(type(x.item()))
4、广播机制
当对两个形状不同的 Tensor 按元素运算时,会触发广播(broadcasting)机制:先适当复制元素使这两个 Tensor 形状相同后再按元素运算。
x = torch.arange(1, 3).view(1, 2)
print(x)
y = torch.arange(1, 4).view(3, 1)
print(y)
print(x + y)
tensor([[1, 2]])
tensor([[1],
[2],
[3]])
tensor([[2, 3],
[3, 4],
[4, 5]])
由于x和y分别是1行2列和3行1列的矩阵,如果要计算x+y,那么x中第一行的2个元素被广播 (复制)到了第二行和第三行,⽽y中第⼀列的3个元素被广播(复制)到了第二列。如此,就可以对2个3行2列的矩阵按元素相加。
5、自动求导(autograd)
构建深度学习模型的基本流程就是:根据网络结构逐步搭建计算图,然后求得损失函数,之后根据计算图来计算导数,最后利用梯度下降方法更新参数。
搭建计算图的过程,称为“正向传播”,这个是需要我们自己动手的,因为我们需要设计我们模型的结构。由损失函数求导的过程,称为“反向传播”,求导是件辛苦事儿,所以自动求导基本上是各种深度学习框架的基本功能和最重要的功能之一,PyTorch也不例外。
自动求导能够让我们避免手动去计算非常复杂的导数,这能够极大地减少了我们构建模型的时间,这也是其前身 Torch 这个框架所不具备的特性。
6、Tensor
(1)设置Tensor的自动求导属性
- 所有的tensor都有.requires_grad属性,都可以设置成自动求导。具体方法就是,在定义tensor的时候,设置它的属性 .requires_grad 为 True
对于这种我们自己定义的变量,我们称之为叶子节点(leaf nodes),而基于叶子节点得到的中间或最终变量则可称之为结果节点。设置叶子节点这个概念主要是为了节省内存,因为我们在反向传播完了之后,非叶子节点的梯度是默认被释放掉的。
(2)Tensor的运算
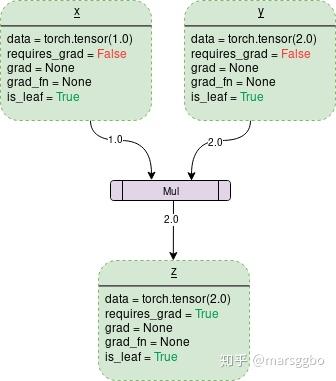
Tensor中通常会记录如下图中所示的属性:
- data: 即存储的数据信息
- requires_grad: 设置为True则表示该Tensor需要求导
- grad: 该Tensor的梯度值,每次在计算backward时都需要将前一时刻的梯度归零,否则梯度值会一直累加。如果我们想保留a的梯度, 那么可以使用retain_grad()方法。 就是在执行反向传播之前, 执行一行代码:a.retain_grad()即可。
- grad_fn: 叶子节点通常为None,只有结果节点的grad_fn才有效,用于指示梯度函数是哪种类型。这个属性,会记录变量具体是怎么得到的, 比如两数相加,或者两数相乘,这样反向计算梯度的时候才能使用相应的法则求变量的梯度。 当然知道是用于反向传播即可。grad_fn=<PowBackward0 at 0x213550af048>, z.grad_fn=<AddBackward0 at 0x2135df11be0>
- is_leaf: 用来指示该Tensor是否是叶子节点。(图中z的is_leaf应为False)
(3)tourch.Tensor
PyTorch中数据以张量(n维数组)的形式流动torch.Tensor可以用来创建张量.当Tensor的属性中requires_grad=True时,则系统会开始跟踪针对此Tensor的所有操作.其中每个操作都会有此操作想对于输入的梯度,则整个操作完成的输出张量相对于输入张量的梯度就是中间过程中所有张量的链式法则。例如, x 为输入张量, y=操作(x),z=操作(y) ,则:
$$\frac{\partial z}{\partial x}=\frac{\partial z}{\partial y} \frac{\partial y}{\partial x}$$
其中 x 为叶节点, z 为根节点, y 并不会被收集。
每个张量都有一个grad_fn属性用于保存张量的操作,如果这个张量为用户自己创建的,则grad_fn为None。
7、使用PyTorch进行自动求导
(1)让所有的tensor都有.requires_grad属性,都可以设置成自动求导
import torch
x = torch.ones(2, 3, requires_grad=True)
print('x:', x)
x: tensor([[1., 1., 1.],
[1., 1., 1.]], requires_grad=True)
(2)如上设置后,它将会追踪对于该张量的所有操作,也即后面由x经过运算得到的其他tensor都会有requires_grad=True 属性。可以通过x.requires_grad来查看这个属性。
y = x + 1
print(y)
print(y.requires_grad)
y: tensor([[2., 2., 2.],
[2., 2., 2.]], grad_fn=<AddBackward0>)
grad: True
(3)改变requires_grad=True 属性,可以调用x.requires_grad_()方法:
x.requires_grad_(False)
print(x.requires_grad); print(y.requires_grad)
False
True
x.requires_grad和x.requires_grad_()是两个东西,前面是调用变量的属性值,后者是调用内置的函数,来改变属性。
(4)自动求导
- 首先定义一个计算图
import torch
x = torch.tensor([[1., 2., 3.], [4., 5., 6.]], requires_grad=True)
y = x + 1
z = 2 * y * y
J = torch.mean(z)
要想使x支持求导,必须让x为浮点类型,否则会报错:RuntimeError: Only Tensors of floating point dtype can require gradients;
求导,只能是【标量】对标量,或者【标量】对向量/矩阵求导。在本题中,x、y、z都是tensor,但是size为(2,3)的矩阵。但是J是对z的每一个元素加起来求平均,所以J是标量。
- J对x进行求导:PyTorch里面,求导是调用.backward()方法。直接调用backward()方法,会计算对计算图叶节点(允许求导)的导数。获取求得的导数,用.grad方法。
J.backward()
x.grad
tensor([[1.3333, 2.0000, 2.6667],
[3.3333, 4.0000, 4.6667]])
(5)过程总结
(6)当J是一个向量或者是一个矩阵的情况,该怎么计算梯度:定义grad_tensor来计算矩阵的梯度
源代码中backward的接口定义:
torch.autograd.backward( tensors, grad_tensors=None, r?etain_graph=None, create_graph=False, grad_variables=None)tensor: 用于计算梯度的tensor。也就是说这两种方式是等价的:torch.autograd.backward(z) == z.backward()
grad_tensors: 在计算矩阵的梯度时会用到。他其实也是一个tensor,shape一般需要和前面的tensor保持一致。
retain_graph: 通常在调用一次backward后,pytorch会自动把计算图销毁,所以要想对某个变量重复调用backward,则需要将该参数设置为True
create_graph: 当设置为True的时候可以用来计算更高阶的梯度
grad_variables: 这个官方说法是grad_variables' is deprecated. Use 'grad_tensors' instead.也就是说这个参数后面版本中应该会丢弃,直接使用grad_tensors就好了。
以一个例子举例说明grad
_tensors参数的作用
x = torch.ones(2,requires_grad=True)
z = x + 2
z.backward()
>>> ...
RuntimeError: grad can be implicitly created only for scalar outputs
报错信息为RuntimeError: grad can be implicitly created only for scalar outputs。意思是只有对标量输出它才会计算梯度,而求一个矩阵对另一矩阵的导数束手无策。
所以当我们相求导时,我们要想办法把矩阵转变成一个标量。比如我们可以对z求和,然后用求和得到的标量在对x求导,这样不会对结果有影响
x = torch.ones(2,requires_grad=True)
z = x + 2
z.sum().backward()
print(x.grad)
>>> tensor([1., 1.])
再思考后我们可以发现,对z求和等价于z 点乘一个相同维度的全为1的矩阵。即 sum(Z)=dot(Z,I) ,而这个I也就是我们需要传入的grad_tensors参数。(点乘只是相对于一维向量而言的,对于矩阵或更高为的张量,可以看做是对每一个维度做点乘)
x = torch.ones(2,requires_grad=True)
z = x + 2
z.backward(torch.ones_like(z)) # grad_tensors需要与输入tensor大小一致
print(x.grad)
>>> tensor([1., 1.])
再复杂一些的例子
x = torch.tensor([2., 1.], requires_grad=True)
y = torch.tensor([[1., 2.], [3., 4.]], requires_grad=True)
z = torch.mm(x.view(1, 2), y)
print(f"z:{z}")
z.backward(torch.Tensor([[1., 0]]), retain_graph=True)
print(f"x.grad: {x.grad}")
print(f"y.grad: {y.grad}")
>>> z:tensor([[5., 8.]], grad_fn=<MmBackward>)
x.grad: tensor([[1., 3.]])
y.grad: tensor([[2., 0.],
[1., 0.]])
结果解释:
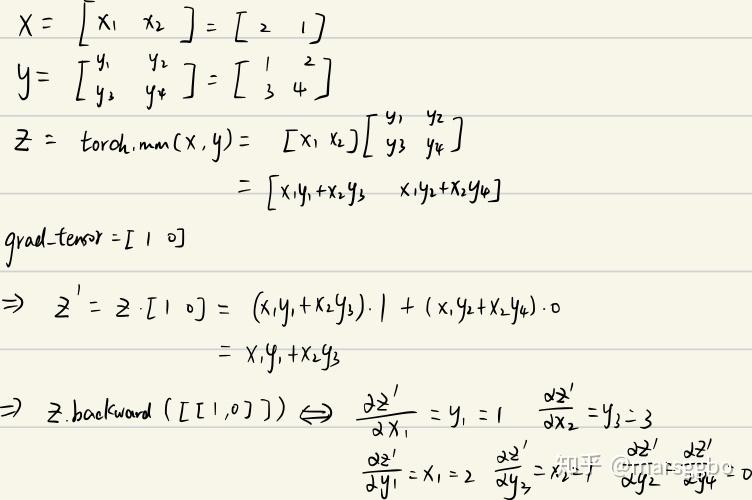
总结:grad_tensors的作用其实可以简单地理解成在求梯度时的权重,因为可能不同值的梯度对结果影响程度不同,所以pytorch弄了个这种接口,而没有固定为全是1。如果从最后一个节点(总loss)来backward,这种实现(torch.sum(y*w))的意义就具体化为 multiple loss term with difference weights 这种需求了。
8、关于backward函数的一些关键问题
(1)一个计算图只能backward一次
一个计算图在进行反向求导之后,为了节省内存,这个计算图就销毁了。如果你想再次求导,就会报错。
如果我们想再次求导怎么办?
- 当我们的实际计算,确实需要保留计算图,不让子图释放。那么,就需要更改backward函数,添加参数retain_graph=True,重新进行backward,这个时候你的计算图就被保留了,不会报错。但是这样会吃内存!尤其是,你在大量迭代进行参数更新的时候,很快就会内存不足,memory out了。
import torch
x = torch.tensor([[1., 2., 3.], [4., 5., 6.]], requires_grad=True)
y = x + 1
z = 2 * y * y
J = torch.mean(z)
J.backward(retain_graph=True) # 保留图
x.grad
tensor([[1.3333, 2.0000, 2.6667],
[3.3333, 4.0000, 4.6667]])
J.backward() # 正常运行
也就是说第8行([8]:J.backward() )想要正常运行,则需要在第6行增加retain_graph=True,即第6行改为J.backward(retain_graph=True);换句话说,想要再次求导成功,则需要前一次求导中保留图。
- 如果我们实际根本没必要对一个计算图backward多次,而我们不小心多跑了一次backward函数。
这种情况在Jupyter中的比较常见,粗暴的解决办法是:重启Jupyter核,重运行一遍所有代码cell。
(2)不是标量也可以用backward()函数来求导
例子:
其中,y是向量,可以对x求导,但同时发现需要传递参数gradients。那么gradients是什么呢?
- 如果你要求导的是一个标量,那么gradients默认为None,所以前面可以直接调用J.backward()就行了
- 如果你要求导的是一个张量,那么gradients应该传入一个Tensor。
大意就是说,我们有时候需要让loss(loss=[loss1,loss2,loss3])的各个分量分别对x求导,这个时候就采用loss.backward(torch.tensor([[1.0,1.0,1.0,1.0]])),其中各个分量的权重都为1;
还有一种情况,如果你想让不同的分量有不同的权重,那么就赋予gradients不一样的值即可,比如:loss.backward(torch.tensor([[0.1,1.0,10.0,0.001]]))。
这样就使得backward()操作更加灵活。
9、并行计算
在利用PyTorch做深度学习的过程中,可能会遇到数据量较大无法在单块GPU上完成,或者需要提升计算速度的场景,这时就需要用到并行计算。
(1)为什么要做并行计算
PyTorch可以在编写完模型之后,让多个GPU来参与训练,减少训练时间。
(2)为什么需要CUDA
CUDA是我们使用GPU的提供商——NVIDIA提供的GPU并行计算框架。对于GPU本身的编程,使用的是CUDA语言来实现的。但是,在我们使用PyTorch编写深度学习代码时,使用的CUDA又是另一个意思。在PyTorch使用 CUDA表示要开始要求我们的模型或者数据开始使用GPU了。
在编写程序中,当我们使用了 .cuda() 时,其功能是让我们的模型或者数据从CPU迁移到GPU(0)当中,通过GPU开始计算。
(3)GPU的设置
当我们的服务器上有多个GPU,我们应该指明我们使用的GPU是哪一块,如果我们不设置的话,tensor.cuda()方法会默认将tensor保存到第一块GPU上,等价于tensor.cuda(0),这将会导致爆出out of memory的错误。我们可以通过以下两种方式继续设置。
#设置在文件最开始部分
import os
os.environ["CUDA_VISIBLE_DEVICE"] = "2" # 设置默认的显卡
CUDA_VISBLE_DEVICE=0,1 python train.py # 使用0,1两块GPU
(4)并行运算
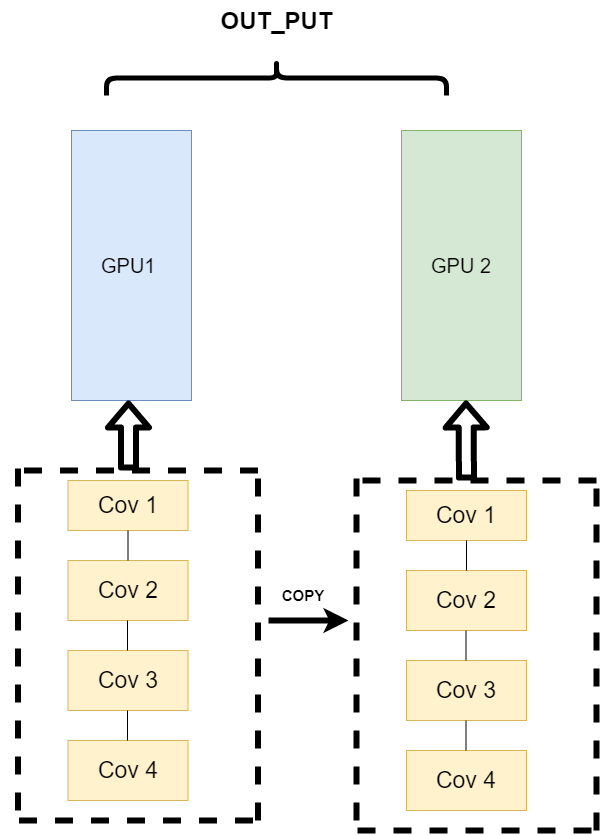
不同的数据分布到不同的设备中,执行相同的任务(Data parallelism)。它的逻辑是,我不再拆分模型,我训练的时候模型都是一整个模型。但是我将输入的数据拆分。所谓的拆分数据就是,同一个模型在不同GPU中训练一部分数据,然后再分别计算一部分数据之后,只需要将输出的数据做一个汇总,然后再反传。其架构如下: