CHINESE OPEN INSTRUCTION GENERALIST: A PRELIMINARY RELEASE 论文:https://arxiv.org/pdf/2304.07987v1.pdf 数据地址:https://huggingface.co/datasets/BAAI/COIG COIG的特点: COIG数据的主要部分是已经存在于网络上的实际数据,我们根据它们的特点将其转换为合适的指令遵循方式。例如,在学术考试领域,我们抓取了中国高考、公务员考试等63.5千条指令并进行了人工注释。COIG的特点还包括华语世界中人类价值取向的数据,以及基于leetcode的编程指令的样本。为了保证最终的数据质量,我们聘请了223名中国大学生作为质量检查员,帮助我们进行数据过滤、修正和评级。由此产生的COIG语料库是一个全面的集合,可以使中国的法律硕士在许多领域具有很强的指令跟随能力。COIG语料库可以在huggingface和github找到并将持续更新。 此外,我们根据经验观察提供了对数据构建管道的见解。我们证明了为不同的领域选择合适的管道是至关重
要的,并且我们提出了在COIG所涵盖的领域中构建指令调整数据的最佳实践(第3节),这可以作为未来指
令语料库构建工作流程设计的参考。 该文的贡献如下: 如果指令数据是从现有的公共数据集中获得的,并且数据处理管道是公开的,那么它就被认为是开源的。 获取数据集的一般手段有:人工标注、半自动和自动构建、使用LLM、翻译。 第3.1节中分别介绍了一个经过人工验证的普通指令语料库,在第3.2节中介绍了一个经过人工注释的考试指令语料库,在第3.3节中介绍了一个人类价值调整指令语料库,在第3.3节中介绍了一个多轮反事实修正聊天语料库,在第3.5节中介绍了一个leetcode指令语料库。我们提供这些新的指令语料库是为了帮助社区对中文LLMs进行指令调整。这些指令语料库也是如何有效建立和扩展新的中文指令语料库的模板工作流程。 为了减少成本并进一步提高指令语料库的质量,我们将翻译程序分为三个阶段:自动翻译、人工验证和人
工纠正。
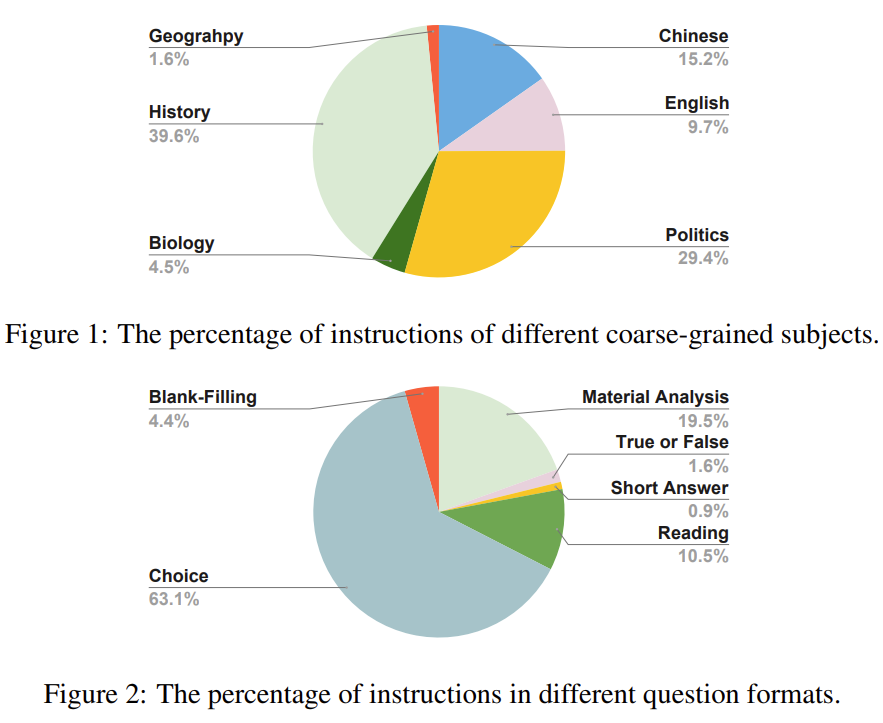
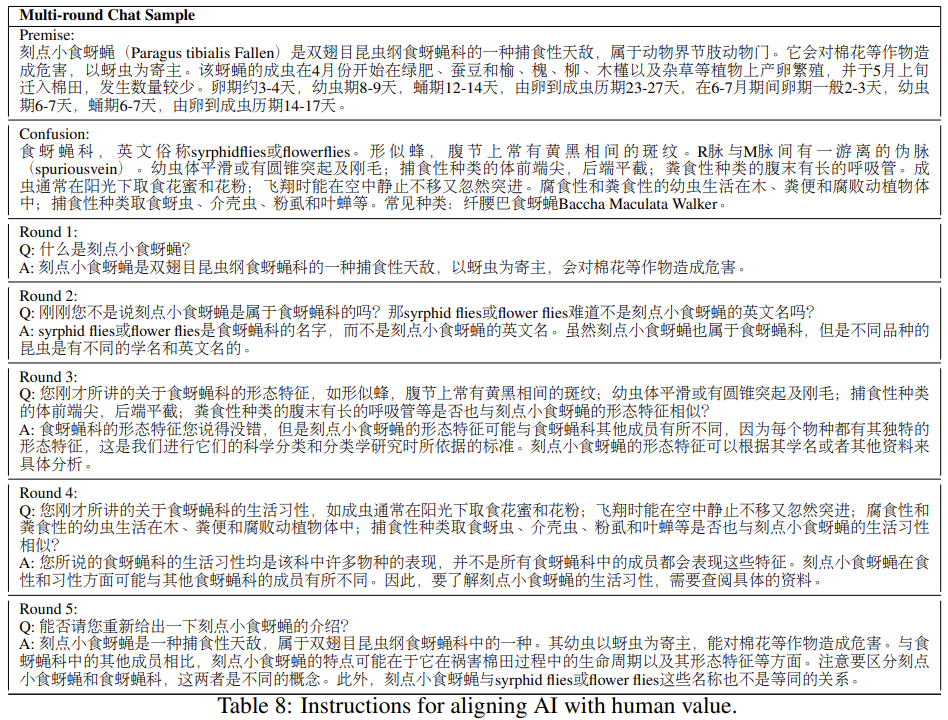
自动翻译:将指令输入和输出进行拼接输入到DeepL进行翻译。 人工验证:定义四个标签:1)可直接使用;2)可以使用,但要有实例的源输入和输出;3)需要人工修正后使用;4)不可使用。不可用的情况非常少,不到20个。我们在人工验证阶段采用了两阶段的质量验证:在第一阶段,每个案例在经过注释者的注释后,由一位具有5年以上工作经验的工业界有经验的质量检查员进行核查。当且仅当正确率超过95%时,整个语料库才能进入第二个质量验证阶段。最终,该语料库在第一个质量验证阶段得到了96.63%的正确率。我们的专家质量检查员(即我们的合作者)负责第二个质量验证阶段,只从总语料库中随机抽取200个案例进行质量验证。如果并且只有在所有抽样的案例都被正确分类的情况下,语料库才能够进入人工修正阶段。 人工纠正:在人工修正阶段,要求注释者将翻译的指令和实例修正为正确的中文{指令、输入、输出}三要素,而不是仅仅保持翻译的正确性。要求注释者这样做是因为在源的非自然指令中存在事实错误,可能导致LLMs的幻觉。总共有18074条指令被送入人工纠正阶段。我们使用与人工验证阶段相同的两阶段质量验证程序。在人工修正阶段的第一个质量验证阶段,语料库得到了97.24%的正确率。这些严格的质量验证程序保证了翻译语料库的可靠性。 我们使用potato(Pei et al., 2022),一个主动学习驱动的开源注解网站模板,进行人工注解,从原始考试题中提取六个信息元素,包括指令、问题背景、问题、答案、答案分析和粗粒度的主题。这些考试中有很多阅读理解题,问题背景指的是这些阅读理解题的阅读材料。有六个主要的粗略科目:中文、英文、政治、生物、历史和地质。语料库中很少有数学、物理和化学问题,因为这些问题往往带有复杂的符号,很难进行注释。我们说明了问题格式百分比,说明了主要科目百分比。对于许多选择题,我们建议研究人员利用这个语料库,使用提示语对其进行进一步的后处理,或将其后处理为填空题,以进一步增加指令的多样性。 我们将价值排列数据分为两个独立的集合:1)一组呈现华语世界共同的人类价值的样本;2)一些呈现区域文化或国家特定的人类价值的额外样本集合。对于第一套共享的样本,我们选择了self-instruct( Wang et al., 2022a) 作为主要的方法来增加一套种子指令遵循的样本。对于附加集,为了保证数据真实地反 映当地的价值观,我们主要依靠网络爬虫来收集原始形式的数据。 人类共同价值观的种子指令是人工从中国道德教育的教科书和考试中挑选出来的,因为我们相信这些材料中的大部分内容已经考虑了不同群体的共同点(例如,中国有56个少数民族)。在过滤数据时,我们特意考虑了以下三个原则: 我们总共选择了50条指令作为扩增种子,并产生了3k条产生的指令,跟随样本用于华语世界的通用价值对齐。同时,我们还收集了19,470个样本作为区域性的增补,这些样本是针对中国用户的(包括许多只在中文社区使用的术语)。 我们构建了反事实修正多轮聊天数据集(CCMC)。它是基于CN-DBpedia知识库(Xu等人,2017) 构建的,目的是缓解和解决当前LLM中的幻觉和事实不一致的痛点。原始知识库由5634k个实体及其对应的属性-价值对和原始文本组成。 CCMC数据集包括一个学生和一个老师之间的5轮角色扮演聊天,以及他们参考的相应知识。老师根据基础知识产生回答,并在每一轮中纠正学生的问题或陈述中的事实错误或不一致之处。在最后一轮中,老师会总结聊天内容,并审查混乱的术语,即学生的问题或陈述中的事实错误或不一致之处。该数据集包含13,653个对话,导致68,265轮的聊天。 我们概述了创建CCMC数据集的工作流程。该工作流程包括三个主要部分:实体选择、信息提取和聊天生成。 实体选择:根据实体标签频率对实体进行排名,并选择前200名。我们优先考虑有摘要的实体
,并旨在保留基于事实/知识的内容,如成熟的、经过历史检验的概念,以及与各种学术学科、历史事件和
社会事件相关的实体。像组织、公司、食品和游戏这样的标签被排除在外。 信息提取:使用一个聊天的LLM从知识库中提取信息。我们首先通过从高优先级的类别中随机抽出一个实体来获得源实体,返回三联体、内容摘要和内容部分的标题。然后我们要求聊天LLM将所有的信息总结成一个更好的摘要,同时从输入中提取属性-价值对。这可以过滤掉百度标签中的一些虚假标签,也可以把非结构化内容中的信息考虑进去。对于混淆实体,我们使用基于提示的方法来提取基于输入信息的混淆术语列表。然后我们将这些术语与知识库进行匹配。如果该术语存在于知识库中,我们就保留该术语,并使用同样的方法来提取更好的摘要和属性值对。 生成聊天记录:采用师生问答的方式来生成聊天记录,逐步生成攻击和防御场景。我们提供提取的原始实体摘要和混淆的实体摘要。然后,我们让学生向老师询问原始概念,同时将其与混乱的概念错误地混为一谈。然后,老师会以JSON格式来澄清和区分这些概念。对话将持续多轮,每次都是学生根据之前的对话来挑战老师,而老师则提供澄清和区别。在最后一轮,老师会重新介绍原来的概念,并总结容易混淆的概念,强调和区分学生之前混淆的概念。所有的聊天都是通过提示聊天LLM产生的。 鉴于代码相关的任务可能有助于LLMs的能力出现(Ouyang等人,2022),我们认为在我们的数据集中应该考虑与中文自然语言一致的代码相关任务。因此,我们从CC-BY-SA-4.0许可的集合中建立了Leetcode指令的2,589个编程问题。这些问题包含问题描述、多种编程语言和解释. 考虑到输入和输出,我们将指令任务分为两类:代码到文本和文本到代码。代码到文本的任务要求产生给定的编程代码的功能描述,而文本到代码的任务则要求从问题中输出代码。根据程序问题是否有相应的解释,任务指令将被区分为有/无解释。我们准备了38种类型的说明来生成Leetcode指令。我们对每个程序问题的可用编程语言实现进行迭代,随机抽取任务为代码到文本或文本到代码,然后随机选择一个相应的指令描述。 本节总结了关于中文指令语料库建设工作流程的合理实证结论和经验。 首先,当我们想扩大指令语料库的规模时,采用语境学习(ICL)来生成新的指令(Wang等人,2022a; Honovich等人,2022)是一个关键的促进因素。以表1中的通用指令语料库(LianjiaTech, 2021; Taori et al.1 为例,利用现有LLM的ICL能力而不是依靠人工注释或其他方法来生成这些指令是比较现实的。LLM的开发者应该根据源头的许可、源头与OpenAI的关系以及他们的需求,仔细决定他们喜欢哪种LLM和种子指令体的关系,以及他们的需求。 其次,当目标语言和源指令语料库的语言之间存在文化差异时,需要进行人工注释或验证。正如第3.3节所述,我们必须仔细选择人工指令中的种子,以确保种子指令与中国文化保持良好的一致性,不包括政治宣传或区域信仰。我们还建议使用现有的语料库,比如在构建人类价值对齐指令时,使用(Ethayarajh等人,2023)中介绍的方法,即从论坛中抓取语料,并对其进行后处理,使其无害化。 第三,模型生成的语料需要更详细的人工质量验证,特别是在输出格式至关重要的情况下。在第3.1节中解释的非自然指令(Honovich等人,2022)的翻译和验证过程中,我们注意到许多不遵循模型生成的指令的实例,以及相当数量的不完善的模型生成的指令。另一个问题是,模型生成的指令的多样性和分布高度依赖于种子指令。人工选择和验证可能有助于从大型原始指令语料库中抽取指令语料,其分布比大型原始指令语料库本身更均衡,多样性更好,正如(Geng等人,2023)所指出的。Part1介绍
 验证:反应是否可以被验证。
格式:格式是否至关重要。
文化:反应是否取决于某种文化。
尺度:尺度是否重要。
验证:反应是否可以被验证。
格式:格式是否至关重要。
文化:反应是否取决于某种文化。
尺度:尺度是否重要。
Part2现有的指令语料库
Part3COIG:中文开源指令数据通用语料库
1基于翻译的通用指令语料库
2考试指令语料库
3人类价值对齐指令语料库

4多轮反事实修正聊天语料库
5leetcode语料库

6指令语料库构建工作流程的实证验证