前言 本文汇总了21篇CVPR2023中有关数据集的工作,附下载链接。
本文转载自极市平台
仅用于学术分享,若侵权请联系删除
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
以下是 CVPR 2023 论文关于数据集的工作汇总。
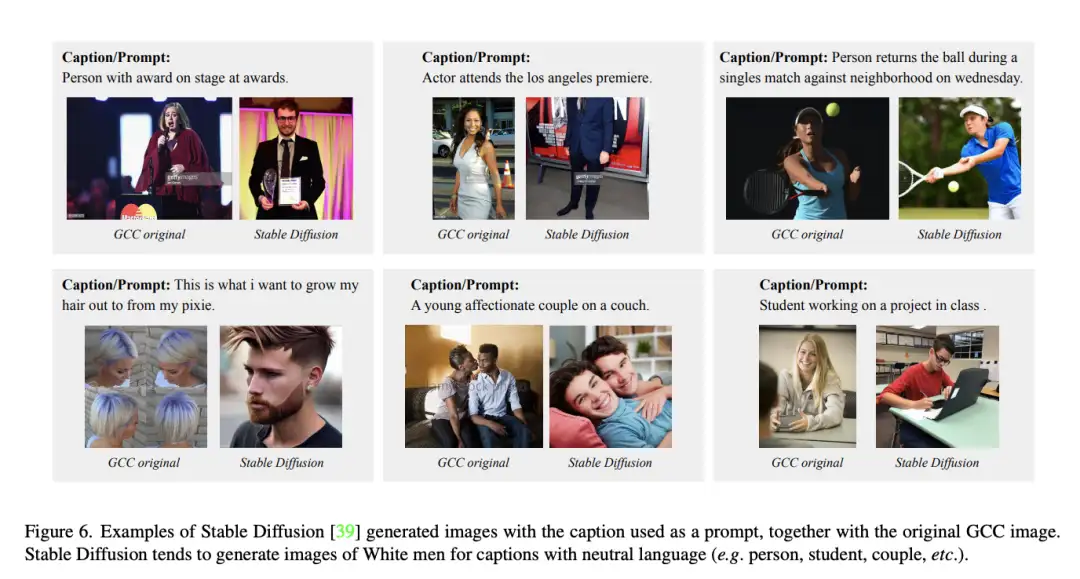
[21]Uncurated Image-Text Datasets: Shedding Light on Demographic Bias
paper:https://arxiv.org/abs/2304.02828
code:https://github.com/noagarcia/phase
[20]CIMI4D: A Large Multimodal Climbing Motion Dataset under Human-scene Interactions
paper:https://arxiv.org/abs/2303.17948
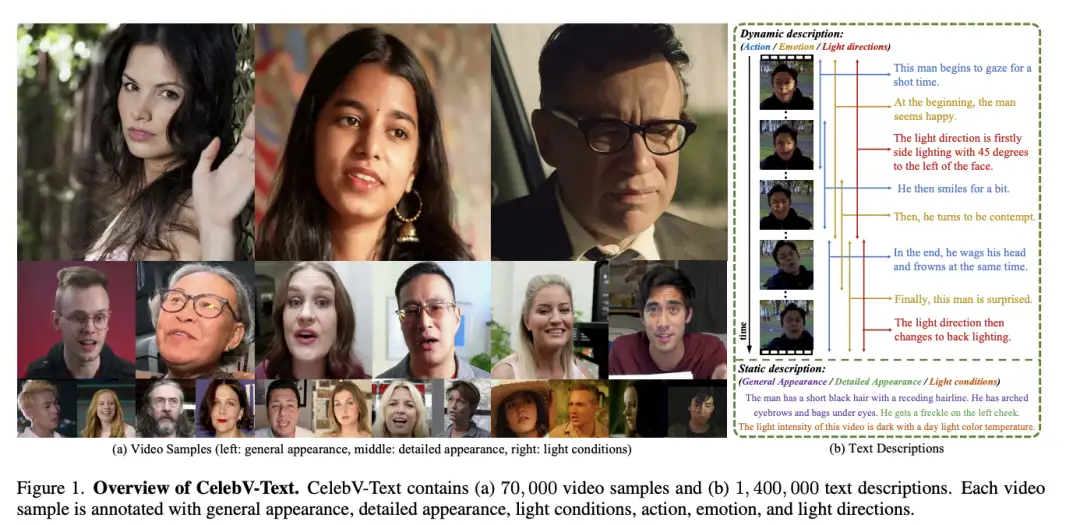
[19]CelebV-Text: A Large-Scale Facial Text-Video Dataset
paper:https://arxiv.org/abs/2303.14717
code:https://github.com/CelebV-Text/CelebV-Text
[18]On the Importance of Accurate Geometry Data for Dense 3D Vision Tasks
paper:https://arxiv.org/abs/2303.14840
code:https://github.com/junggy/hammer-dataset
[17]Towards Artistic Image Aesthetics Assessment: a Large-scale Dataset and a New Method
paper:https://arxiv.org/abs/2303.15166
code:https://github.com/dreemurr-t/baid
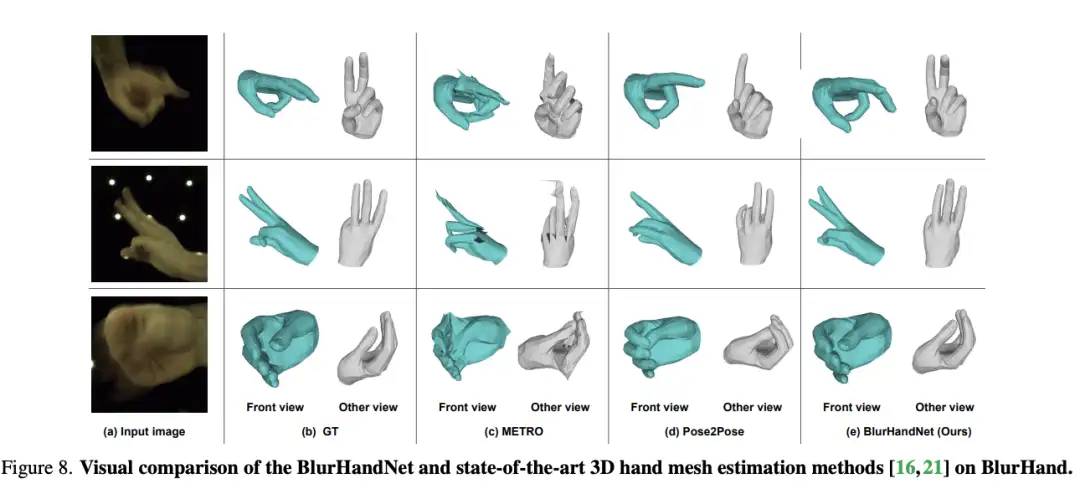
[16]Recovering 3D Hand Mesh Sequence from a Single Blurry Image: A New Dataset and Temporal Unfolding
paper:https://arxiv.org/abs/2303.15417
code:https://github.com/jaehakim97/blurhand_release
[15]GAPartNet: Cross-Category Domain-Generalizable Object Perception and Manipulation via Generalizable and Actionable Parts
paper:https://arxiv.org/abs/2211.05272
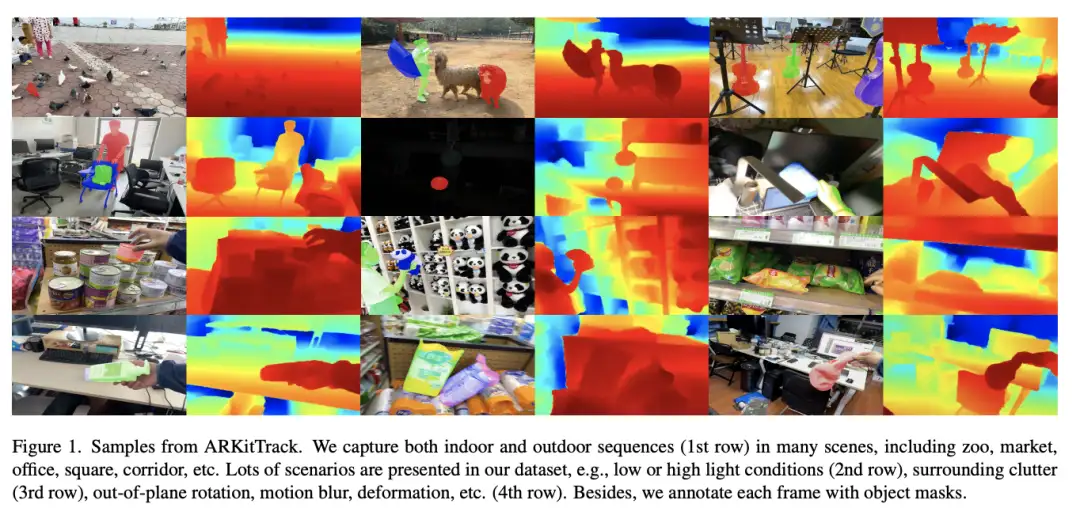
[14]ARKitTrack: A New Diverse Dataset for Tracking Using Mobile RGB-D Data
paper:https://arxiv.org/abs/2303.13885
[13]Fantastic Breaks: A Dataset of Paired 3D Scans of Real-World Broken Objects and Their Complete Counterparts
paper:https://arxiv.org/abs/2303.14152
[12]A Bag-of-Prototypes Representation for Dataset-Level Applications
paper:https://arxiv.org/abs/2303.13251
[11]Music-Driven Group Choreography
paper:https://arxiv.org/abs/2303.12337
[10]RaBit: Parametric Modeling of 3D Biped Cartoon Characters with a Topological-consistent Dataset
paper:https://arxiv.org/abs/2303.12564
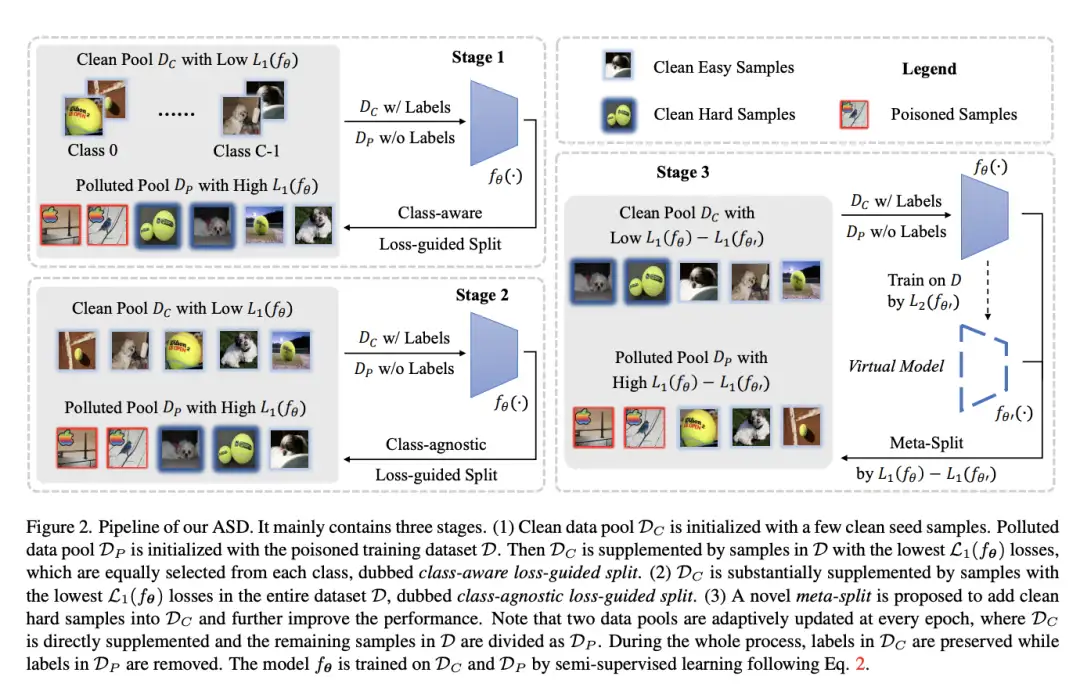
[9]Backdoor Defense via Adaptively Splitting Poisoned Dataset
paper:https://arxiv.org/abs/2303.12993
code:https://github.com/kuofenggao/asd
[8]Learning a Practical SDR-to-HDRTV Up-conversion using New Dataset and Degradation Models
paper:https://arxiv.org/abs/2303.13031
code:https://github.com/andreguo/hdrtvdm

[7]SLOPER4D: A Scene-Aware Dataset for Global 4D Human Pose Estimation in Urban Environments
paper:https://arxiv.org/abs/2303.09095 code:https://github.com/climbingdaily/SLOPER4D
[6]A Whac-A-Mole Dilemma: Shortcuts Come in Multiples Where Mitigating One Amplifies Others
paper:https://arxiv.org/abs/2212.04825
code:https://github.com/facebookresearch/Whac-A-Mole

[5]MVImgNet: A Large-scale Dataset of Multi-view Images
paper:https://arxiv.org/abs/2303.06042
[4]Spring: A High-Resolution High-Detail Dataset and Benchmark for Scene Flow, Optical Flow and Stereo
paper:https://arxiv.org/abs/2303.01943
[3]CUDA: Convolution-based Unlearnable Datasets
paper:https://arxiv.org/abs/2303.04278

[2]V2V4Real: A Real-world Large-scale Dataset for Vehicle-to-Vehicle Cooperative Perception
paper:http://arxiv.org/abs/2303.07601
[1]Human-Art: A Versatile Human-Centric Dataset Bridging Natural and Artificial Scenes
paper:https://arxiv.org/abs/2303.02760
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【技术文档】《从零搭建pytorch模型教程》122页PDF下载
QQ交流群:470899183。群内有大佬负责解答大家的日常学习、科研、代码问题。
其它文章
CVPR 2023|两行代码高效缓解视觉Transformer过拟合,美图&国科大联合提出正则化方法DropKey
ViT-Adapter:用于密集预测任务的视觉 Transformer Adapter
CodeGeeX 130亿参数大模型的调优笔记:比FasterTransformer更快的解决方案
CVPR 2023 深挖无标签数据价值!SOLIDER:用于以人为中心的视觉
上线一天,4k star | Facebook:Segment Anything
Efficient-HRNet | EfficientNet思想+HRNet技术会不会更强更快呢?
ICLR 2023 | SoftMatch: 实现半监督学习中伪标签的质量和数量的trade-off
目标检测创新:一种基于区域的半监督方法,部分标签即可(附原论文下载)
CNN的反击!InceptionNeXt: 当 Inception 遇上 ConvNeXt
拯救脂肪肝第一步!自主诊断脂肪肝:3D医疗影像分割方案MedicalSeg
AI最全资料汇总 | 基础入门、技术前沿、工业应用、部署框架、实战教程学习
AAAI 2023 | 轻量级语义分割新范式: Head-Free 的线性 Transformer 结构
标签:abs,arxiv,Dataset,CVPR,paper,https,2023,org,21 From: https://www.cnblogs.com/wxkang/p/17318354.html