搜索引擎实现
实现步骤
搜集
例如google、baidu都是根据爬虫爬取网页数据
分析
根据爬取的数据分词解析,建立临时索引等
索引
通过分析阶段产生的临时索引构建倒排索引,用于查询
查询
响应用户请求,根据倒排索引获取相关网页信息,计算权重等
倒排索引
正排索引:文档中包含了哪些单词
倒排索引:某一个单词存在于哪些文档中,一般来说,倒排索引一旦建立,因为其就不能更改
关系型数据库通过利用B+树实现索引,便于查询检索;ES通过倒排索引这个数据结构达到同样的目的
除了倒排索引外,还可以构建单词与文档的偏移索引,基于hash,实现快速的查询文档效果
ElasticSearch基操
Instead of storing information as rows of columnar data, Elasticsearch stores complex data structures that have been serialized as JSON documents.
// 相比于行式的字段存储,ElasticSearch将不同的数据结构存储为复杂的json文档格式来进行查询
Elasticsearch uses a data structure called an inverted index that supports very fast full-text searches.
// elasticsearch使用倒排索引来检索数据
Elasticsearch indexes all data in every field and each indexed field has a dedicated, optimized data structure. For example, text fields are stored in inverted indices, and numeric and geo fields are stored in BKD trees. The ability to use the per-field data structures to assemble and return search results is what makes Elasticsearch so fast.
Elasticsearch 索引每个字段中的所有数据,每个索引字段都有一个专用的优化数据结构。 例如,文本字段存储在倒排索引中,而数字和地理字段存储在 BKD 树中。使用每个字段的数据结构来组装和返回搜索结果的能力是 Elasticsearch 如此快速的原因。
While you can use Elasticsearch as a document store and retrieve documents and their metadata, the real power comes from being able to easily access the full suite of search capabilities built on the Apache Lucene search engine library.
// elasticsearch强大的检索和分析数据能力基于Apache的Lucene
安装
# 如果有需要可以配置一下elasticsearch.yml文件
# vim /opt/elasticsearch7.8.0/config/elasticsearch.yml
# 数据和日志的存储目录,默认放在ES安装目录下,但如果重新安装ES这些文件也会清空,所以建议自定义路径
path.data: /home/es/data
path.logs: /home/es/logs
# 设置绑定的ip,设置为0.0.0.0以后就可以让任何计算机节点访问到了
network.host: 0.0.0.0
# 端口
http.port: 9200
# 集群名称,默认是elasticsearch,可以自定义名字防止其他节点以外的加入到你的集群中
cluster.name: my-application
# 节点名称,每次重启服务都会随机生成,建议自定义,这样在日志中也好查看信息
node.name: node-1
# 设置在集群中的所有节点名称,这个节点名称就是之前所修改的,当然你也可以采用默认的也行,目前是单机,放入一个节点即可
cluster.initial_master_nodes: ["node-1"]
# 支持跨域,跨域配置是为了kibana,head连接
http.cors.enabled: true
http.cors.allow-origin: "*"
# 设置为true锁住内存,当服务混合部署了多个组件及服务时,应开启此操作,允许es占用足够多的内存。
bootstrap.memory_lock: false
# es优化,是否支持过滤掉系统调用
bootstrap.system_call_filter: false
elasticsearch因为安全问题拒绝使用root用户启动,添加es用户
# 创建用户并授权
groupadd es
useradd es -g es -p 1306848431XO
chown es:es -R /opt/elasticsearch-8.2.2
# 如果提示jvm内存不够,在config的jvm.options中配置jvm内存分配大小
# 后台执行
elasticsearch -d
[2022-05-29T16:14:50,451][WARN ][o.e.x.s.t.n.SecurityNetty4HttpServerTransport] [ahao-1] received plaintext http traffic on an https channel, closing connection Netty4HttpChannel
elasticsearch8.x版本开始默认开启安全访问,也即基于TLS的https访问,如果在测试机没有安全环境,需要调整elasticsearch.yml文件,使其关闭默认的安全访问设置
# 后台执行
kibana &
注意事项
ES7废除_type类型,但还可以用,ES8彻底抛弃
在关系型数据库中,一个数据库中可以创建多个物理表,多个物理表中可以创建相同字段的属性
但在搜索型数据库ES中,由于内部分片分布式存储的缘故,索引index只是一个逻辑概念,所以在index中创建type其实没有实质所用,因此同一个index的不同type中无法创建相同字段属性
重要配置说明
官方说明:其他数据库可能存在调优的情况,ES不需要,若遇到性能问题,只需要将数据更好的布局或增加更多的节点,尽量不用修改elasticsearch.yml中的配置!!
简单CRUD
索引
创建索引
索引名字必须小写,不能以下划线开头,不能包含逗号
# 注意,创建索引不能加请求体(es要求),这里创建索引只能用PUT,不能用POST
curl -XPUT http://47.94.11.98:9200/website
定义索引内文档属性映射
# 创建索引之后才能属性映射
curl -XPUT -H "Content-Type:application/json" http://47.94.11.98:9200/website/_mapping -d
{
"properties": {
"name": {
"type": "text", # 文本字段,可以分词查询
"index": true # 可被索引查询
},
"age": {
"type": "keyword", # keyword表示不能分词查询,只能全量查询
"index": false # 不能被索引查询
}
}
}
删除索引
curl -XDELETE http://47.94.11.98:9200/website
清空ES索引
curl -X DELETE 'http://localhost:9200/_all'
# 如果不行,一个一个删
# 原理就是先执行 _cat/indices 列出所有的索引,然后循环结果,一个一个删除
for i in `curl -XGET 'http://localhost:9200/_cat/indices' | awk '{print $3}'`; do curl -XDELETE "http://localhost:9200/$i"; done
清空索引数据
POST http://es-server:9200/{index_name}/_delete_by_query
#body
{
"query": {
"match_all": {}
}
}
查看索引信息
# 查看ES中所有索引的情况
curl -XGET http://47.94.11.98:9200/_cat/indices
# 查看ES中指定索引的情况
curl -XGET http://47.94.11.98:9200/_cat/indices/website
# 查看单个索引信息
curl -XGET http://47.94.11.98:9200/website/_search
文档
新增文档
PUT和POST的区别
在http协议规范中,PUT是幂等的,对同意数据多次PUT操作结果是一样的,而POST非幂等,对统一数据多次操作结果可能不同,例如新增同一数据,PUT结果相同,不会新增重复的,而POST则会新增重复的
但在elasticsearch中,对于新增数据两者的区别主要在是否有唯一id的条件
当使用PUT,应该指明唯一id值:curl -XPUT http://47.94.11.98:9200/website/_doc/{id} -d{xx}, 表示使用这个 URL 存储这个文档
当使用POST,可以不用指明id: curl -XPOST http://47.94.11.98:9200/website/_doc -d {xxx},表示存储文档在这个 URL 命名空间下,当然POST也可以指明id
# Starting from Elasticsearch 6.0, all REST requests that include a body must also provide the correct content-type for that body.
# PUT存储具体id文档
curl -XPUT -H "Content-Type:application/json" http://47.94.11.98:9200/website/_doc/{id} -d{xxxx}
# POST存储索引下的文档
curl -XPOST -H "Content-Type:application/json" http://47.94.11.98:9200/website/_doc -d {xxx}
特殊新增
# 新建文件并指定version
curl -XPUT -H "Content-Type:application/json"http://47.94.11.98:9200/website/_doc/2?version=5&version_type=external -d{xxx}
删除文档
删除文档不会立刻从磁盘中删除,而是标记为已删除状态,ES后续清除
# 删除指定文档
curl -XDELETE http://47.94.11.98:9200/website/_doc/{id}
删除所有索引的文档
# 删除所有索引数据,但不删除索引本身
for i in `curl -XGET 'http://" + ip + ":9200/_cat/indices' | awk '{print $3}'`; do curl -X POST -H 'Content-Type:application/json' "http://" + ip + ":9200/$i/_delete_by_query?pretty=true" -d '{"query":{"match_all": {}}}'; done;
修改文档
普通修改
注意,ES中一个文档建立之后就不可变,之所以能修改,是因为ES内部封装了 DELETE -> PUT ,也即删除了旧文档,新构建新文档,所以_create参数为false,表示不是新创建的
# POST方式修改文档
curl -XPOST -H "xx" http://47.94.11.98:9200/website/_doc/{id} -d{xxx}
# PUT方式修改文档
curl -XPUT -H "xx" http://47.94.11.98:9200/website/_doc/{id} -d{xxx}
部分修改!!!
修改时type要改为_update,如果还是doc,会以为是新增
# 部分修改type置为_update, 且请求体中主key为“doc”
curl -XPUT -H "Content-Type:application/json" http://47.94.11.98:9200/website/_update/2
{
"doc":{
key: value
}
}
并发修改
# 数据并发控制:在关系型数据库中,通过行锁实现记录并发控制,细分实现为乐观锁和悲观锁,在ES中也可以
# 老版本的ES使用文档的版本_version实现,新版本使用索引的版本_seq_no以及:
curl -XPUT -H "xx" http://47.94.11.98:9200/website/_doc/1?if_seq_no=14&if_primary_term=1 -d{xxx}
version是索引中单个文档的版本,seq_no是整个索引全部文档的版本,即index中任一文档更新(包括删除)都会 seq_no+1
primary_term是每当Primary Shard发生重新分配时,比如重启,Primary选举等,_primary_term会递增1
之后怎么做取决于我们的应用需求,可以告诉用户说其他人已经修改了文档,并且在再次保存之前检查这些修改内容。 或在之前的商品
stock_count场景,我们可以获取到最新的文档并尝试重新应用这些修改。
普通查找文档
RFC文档 并没有规定一个带有请求体的
GET请求应该如何处理!但由于使用者自己的习惯导致一些 HTTP 服务器允许这样子,而有一些 — 特别是一些用于缓存和代理的服务器 — 则不允许。对于一个查询请求,Elasticsearch 的工程师偏向于使用
GET方式,因为他们觉得它比POST能更好的描述信息检索(retrieving information)的行为。然而,因为带请求体的GET请求并不被广泛支持,所以searchAPI同时支持POST请求
# 获取全部文档主要信息
curl -XGET http://47.94.11.98:9200/_count
# 查询索引下所有文档
curl -XGET http://47.94.11.98:9200/website/_search
# 查看普通文档
curl -XGET http://47.94.11.98:9200/website/_doc/{id}
# 只查看_source
curl -XGET http://47.94.11.98:9200/website/_source/{id}
# 查看文档中_source部分数据
curl -XGET http://47.94.11.98:9200/website/_source/{id}?_source=name,age
结果字段属性详解
# request:查看index为website和test的文档
curl -XGET http://47.94.11.98:9200/website,test/_search
# response:
{
# took 表示搜索过程消费的毫秒数
"took": 1,
# 是否超时,默认情况下,超时时间是1min,所以一般不会超时,当然也可以指定,例如指定timeout为10ms,请注意,一旦查询超时,ES的查询是不会停止的,仅会告知正在协调的节点返回到目前为止收集的结果并关闭连接,也就是说,结果也会返回
"timed_out": false,
# _shards部分告诉我们参与查询的分片的总数,以及这些分片成功与失败的个数,如果遇到事故,查询失败,那么主分片和副本分片都不会更新数据
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
# GET -XGET /_search 结果中 hits 表示所有结果,total表示结果数量,但在hits数组中最多只展示10个文档
# hits数组中每个文档还有一个_score,衡量文档与查询的匹配程度,降序输出
"hits": {
"total": {
"value": 3,
"relation": "eq"
},
"max_score": 1.0,
"hits": [
{
"_index": "employee",
"_id": "1",
"_score": 1.0,
"_source": {
"first_name": "John",
"last_name": "Smith",
"age": 25,
"about": "I love to go rock climbing",
"interests": [
"sports",
"music"
]
}
}
]
}
}
查看文档是否存在
# 查看文档是否存在,HEAD方法不会返回方法体,节省带宽,一般用于查看服务器文件是否存在、查看文件最新版本等场景,如果存在,会返回200 code
curl -XHEAD http://47.94.11.98:9200/website/_doc/{id}
批量查询
# 不指定index批量查,需要在请求体中指定“docs”中的每个数据的_index和_id
# 当然也可以部分查找,在_resource中指定查看内容
curl -XGET -H "Content-Type:application/json" http://47.94.11.98:9200/_mget
{
"docs" : [
{
"_index" : "website",
"_id" : 2
},
{
"_index" : "website",
"_id" : 1,
"_source": "views"
}
]
}
# 有index,批量查的时候就不需指明index
curl -XGET -H "Content-Type:application/json" http://47.94.11.98:9200/website/_mget
{
"docs": [
{
"_id": 1
},
{
"_id": 2,
"_source": "name"
}
]
}
# 简便多查
curl -XGET -H "Content-Type:application/json" http://47.94.11.98:9200/website/_mget
{
"ids" : [ "2", "1" ]
}
bulk批量操作
为什么写的批量操作不像读的mget用json呢?
解析麻烦,用这样的形式可以直接转发,减少了解析的功夫
# 格式如下,其中action指明操作:create(创建文档)、index(创建或更新文档)、update(局部修改文档)、delete
# 注意,此时的update不需要指定type为_update,批量操作中update默认不覆盖局部修改
POST /_bulk
{
{ action: { metadata }}\n
{ request body }\n
{ action: { metadata }}\n
{ request body }\n
}
例如:
curl -XPOST -H "Content-Type:application/json" http://47.94.11.98:9200/_bulk -d
{"delete": {"_index": "website", "_id": 1}}
{"create": {"_index": "website", "_id": 1}}
{"title": "my first website doc"}
{"index": {"_index": "website", "_id": 1}}
{"title": "my second website doc"}
{"update": {"_index": "website", "_id": 1}}
{"doc": {"age": 31}}
# 最后一行也要加上换行符,这被用作一个标记,可以有效分隔行
# bulk返回结果中既有操作成功的,也有失败的,说明bulk不是原子操作,不能用来当作事务处理
# 批量操作的条数最大值1,000 到 5,000,超过了性能就会下降
例:https://www.elastic.co/guide/cn/elasticsearch/guide/current/bulk.html
ES复杂Retrieve
查询语句汇总
# 比较常用的几个复杂Retrive点:
query: 查询条件
bool:多条件查询,其中的条件都要满足,可接收以下参数
1) must: 必须满足(&&),如果有多个条件使用[]接收
2) must_not: 必须不满足
3) should: 用于修正查询的文档得分情况;可设置minimum_should_match实现or功能
4) filter: 用于query中,过滤数据,必须匹配,但它以不评分、过滤模式来进行
range: 范围(注意,一旦用gt等边界词,就要使用range)
gt: 大于
gte: 大于等于
lt: 小于
lte: 小于等于
match: 匹配,类似模糊查询,只要匹配信息分词任一词出现就可以返回结果,最相近的相关性得分高
multi_match: 可在多个字段上都执行match操作
match_phrase: 全文精确匹配,匹配信息不分词,必须完全包含匹配信息
term: 精确值匹配查询,多用于数字、日期、布尔等not_analyzed字段
exists: 字段中有值即可
missing: 字段中无值即可
_source: 结果过滤,用于只想查看source中的部分字段数据
sort: 结果排序,注意排序写法有先后顺序,类似order by后的顺序一样
from/size:结果分页(从from开始,查询size个数据,和mysql不一样,注意,from从0开始,即第一条数据下标为0)
size: 返回几条数据
highlight: 高亮查询,自定义高亮,默认<em></em>
pre_tags: 高亮CSS代码前缀
post_tags: CSS代码后缀
fields: 高亮匹配属性
aggs: 聚合函数,类似SQL中的group by,查询的结果除了hits之外,还会额外增加aggregations
term: 分组说明
关于should的使用,有以下使用注意点:
# 当bool处在query上下文时,若must或者filter匹配了doc,那么should即使一条都不满足也可以召回doc
# 当bool处于filter上下文时,或者bool处于query上下文,但没有must或者filter子句,should至少匹配一个才会召回doc
总结:如果没有 must 语句,那么至少需要能够匹配其中的一条 should 语句。但,如果存在至少一条 must 语句,则对 should 语句的匹配没有要求。
ES的基于request Body的DSL查询语句笼统分两类:
叶子语句:只用于将查询字段和一个或多个字段做对比,例如单个match语句
复合语句:合并多个叶子语句,比如bool语句,可以组合must、should、must_not等语句
例子1:找出信件email正文包含 business opportunity 的星标邮件,或者在收件箱正文包含 business opportunity 的非垃圾邮件:
curl -XGET -H "Content-Type:application/json" http://47.94.11.98:9200/_search -d
{
"query": {
"bool": {
"must": {"match": {"email": "business opportunity"}},
"should": [
{"match": {"starred": true}},
{"bool":{
"must": {"match": {"folder": "inbox"}},
"must_not": {"match": {"spam": true}}
}}
],
"minimum_should_match": 1
}
}
}
查找 title 字段匹配 how to make millions 并且tag不被标识为 spam 的文档。那些tag被标识为 starred 或时间在date在2014之后的文档,将比另外那些文档拥有更高的排名。如果 两者 都满足,那么它排名将更高:
{
"query": {
"bool": {
"must": {
"match": {
"title": "how to make millions"
}
},
"must_not": {
"match": {
"tag": "spam"
}
},
"should": [
{"match": {"tag": "starred"}},
{"range": {"date": {"gt": "2014-01-01"}}}
]
}
}
}
简单
# 条件查询
crul -XGET http://47.94.11.98:9200/employee/_search?q=last_name:Smith
ES的复杂查询一般借助ES的DSL(领域特定语言),即在请求体中构造查询条件,如下
# 查询的结果不像关系型数据库一样要必须匹配,ES可以匹配部分,以相关性得分的方式降序输出,例如结果也可能输出"last_name"为"Smi"的文档,但是排在"Smith"后面,相关性得分低,这就是ES分词查询的优点
crul -XGET http://47.94.11.98:9200/employee/_search -d
{
"query": {
"match": { # 精准匹配
"last_name": "Smith"
}
}
}
中等
# 搜索姓氏为 Smith 的员工且年龄大于 30 的 last_name和age信息
crul -XGET http://47.94.11.98:9200/employee/_search -d
{
"query": {
"bool":{
"must": {
"match": {
"last_name": "Smith"
}
},
"filter": {
"range": {
"age": {"gt": 30}
}
}
}
},
# _source表示query查询之后过滤
"_source": ["last_name", "age"],
# 注意排序和过滤一样,都需要加在查询之后进行,排完序之后文档的score分数就省略了
"sort": [
{
"age": {
"order": "desc"
}
}
],
# 从0开始
"from": 0,
"size": 1
}
困难
聚合函数(aggs)
curl -XGET -H "Content-Type:application/json" http://47.94.11.98:9200/employee/_search -d
{
"query": {
"bool": {
"must": {
"match": {
"last_name": "Smith"
}
}
}
},
# 聚合函数aggregations,类似于SQL中的group by分组求和,本例:挖掘出员工中最受欢迎的兴趣爱好
"aggs": {
"all_interests": {
# 聚合函数的前提是字段属性允许聚合,官方:text或annotated_text字段doc_values默认为false,不允许聚合使用,因为interests类型是text,所以使用interests.keyword聚合
"terms": {"field": "interests.keyword"}
}
},
"highlight": {
"fields": {
"about": {}
}
}
}
# 聚合函数2: 查询有特定兴趣爱好的员工的平均年龄
curl -XGET -H "Content-Type:application/json" GET http://xxx:xx/employee/_search -d
{
"aggs" : {
"all_interests" : {
"terms" : { "field" : "interests" },
"aggs" : {
"avg_age" : {
"avg" : { "field" : "age" }
}
}
}
}
}
ES分布式存储文档
ES概念解析
1) node节点:1个节点对1个ES实例,即一个ES的java的进程
2) 1个节点可以有多个index索引(主分片数量是在索引创建时指定,默认1个,后续不允许修改,如果修改,需要重建索引)
3) ES中的索引实际上是一个逻辑概念,指向1个或多个物理分片,这些分片散布在集群中
4) 1个分片(share)是一个Lucene的index(Luncene的Index和ES的Index不是一个概念),所以ES中的分片实际上就是一个完整的搜索引擎
5) 技术上来说,一个主分片最大能够存储 Integer.MAX_VALUE - 128 个文档,但是实际最大值还需要参考你的使用场景:包括你使用的硬件, 文档的大小和复杂程度,索引和查询文档的方式以及你期望的响应时长。
6) 副本分片(Replica Shard):
服务高可用:作为硬件故障时保护数据不丢失的冗余备份
扩展性能:为搜索和返回文档提供读的服务
ES的主旨就是随时可用和按需扩容
这里的扩容可以通过垂直扩容即购买强大性能服务器或者水平扩容即扩展更多服务器实现集群
ES天生就是分布式的,会自动管理多节点来提高可用性和稳定性
ES集群信息
# ES中的 /config/elasticsearch.yml 文件中 cluster.name 表示集群名字,多个node节点的 cluster.name 相同即表示同一个集群,可以承担同样数据的访问压力,当有数据来时,会平均分配到集群内部的节点中;任一个请求打到集群内部的任何一个节点,都可以从包含目的数据的节点中获取数据
cluster.name=cluster_1_ahao
# 在集群中当有一个节点被选举为主节点后,将会负责管理集群内部所有变更,例如增加、删除索引等;主节点不涉及文档级别的变更和搜索。
ES的单播和组播
单播和组播都是网络系统中的概念
单播:网络节点之间相互通信
组播:网络节点通过关系网络通信,也即不是点对点,而是 点 —> 面 —> 点
ES官方十分建议使用单播,多播状态会导致其他服务器的节点意外加入自己集群中,如果是在生产环境很离谱
ES的单播默认只会将本机的节点(ES实例)加入到集群中,如果要加入其他服务器的节点,需要额外配置:
可以为 ES 提供一些它应该去尝试连接的节点列表,当一个节点联系到单播列表中的成员时,它就会得到整个集群所有节点的状态,然后它会联系 master 节点,并加入集群。
文档路由到分片中
# 当索引创建时分片数量就不会再变化,所以利用hash函数将文档散列到分片中
# 下列routing是一个路由参数,默认为文档的id,也可自定义;取余的number_of_primary_shards代表分片数量
shard = hash(routing) % number_of_primary_shards
主分片与副本分片如何交互
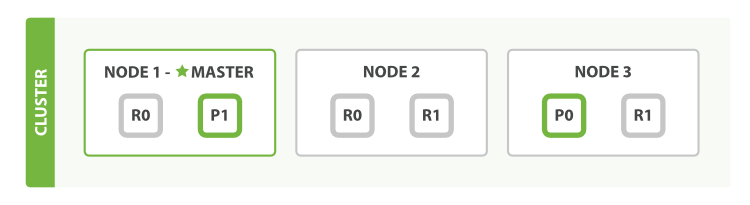
查询
上述是官网的图示,假设一个集群有三个节点,每个主分片都有两个副本分片,像上图一样分散在各个节点中,这样每个节点都有处理查询请求的功能
在实际发送请求时,服务端可以采用轮询等方式降低单点压力
新建、索引和删除文档
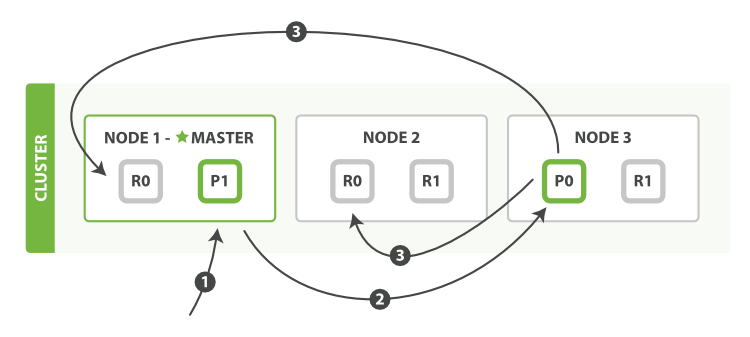
1:如图,客户端向集群的node1节点中执行文档写操作(新建、删除、索引)
2:节点使用文档的 _id 确定文档属于分片 0 。请求会从node1被转发到 Node 3,因为分片 0 的主分片目前被分配在 Node 3 上
3:Node 3 在主分片上面执行请求。如果成功了,它将请求并行转发到 Node 1 和 Node 2 的副本分片上。一旦所有的副本分片都报告成功, Node 3 将向协调节点报告成功,协调节点向客户端报告成功
当然,也可以设计ES响应的超时时间,默认是1分钟
取文档
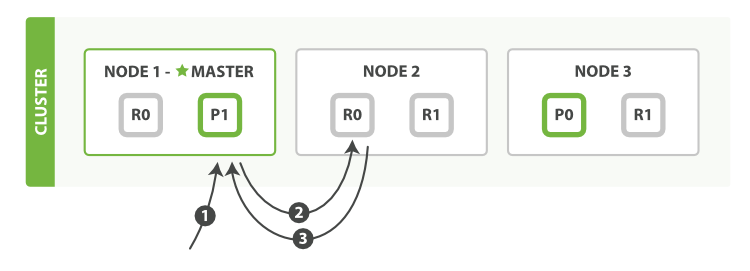
由于副本分片也可以读取数据,所以客户端不管像哪个节点发送请求,都可以得到响应,不需要转发到主分片上
局部更新文档
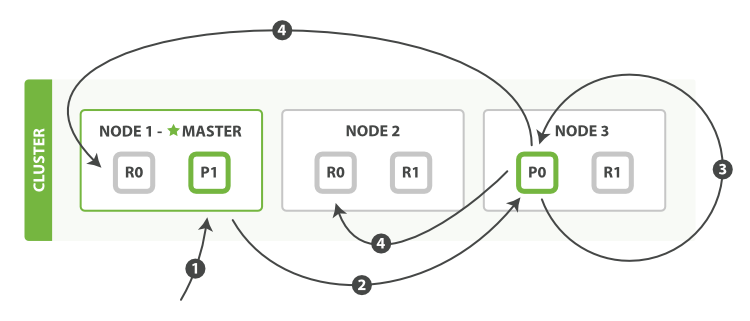
- 客户端向
Node 1发送更新请求。 - 它将请求转发到主分片所在的
Node 3。 Node 3从主分片检索文档,修改_source字段中的 JSON ,并且尝试重新索引主分片的文档。 如果文档已经被另一个进程修改,它会重试步骤 3 ,超过retry_on_conflict次后放弃。- 如果
Node 3成功地更新文档,它将新版本的文档并行转发到Node 1和Node 2上的副本分片,重新建立索引。 一旦所有副本分片都返回成功,Node 3向协调节点也返回成功,协调节点向客户端返回成功。
注意,这里局部修改文档时,主分片向副本分片发送的不是更新请求,而是以异步转发的形式将完整文档发送并直接覆盖副本文档
ES中的重要点
字段属性索引不同
如下,通过默认的 _all 模糊查询时间会有14条文档,而具体到 data 字段模糊查没有文档
ES中对不同字段类型索引类型也不同,插入2014-09-16数据后,ES会动态帮我们将这个数据映射为date类型的数据,而 _all 默认是String类型的,类型不同,索引方式也不同;
最大的不同就是数据精度问题,也即string和date或者其他boolean、numbers等都有所不同
curl -XGET http://47.94.11.98:9200/_search?q=2014 # 12 results
curl -XGET http://47.94.11.98:9200/_search?data:2014 # 0 result
插入文档分析器工作过程
# 当一个文档插入到ES中后,会对插入的文档进行分词处理:
# 首先,将一块文本分成适合于倒排索引的独立的 词条
# 之后,将这些词条统一化为标准格式以提高它们的“可搜索性”,或者 recall
具体的说有以下3个步骤:
- 字符过滤:插入的字符串按顺序通过字符过滤,这一步主要在分词前进行整理工作,例如去除HTML标签,将&转化为and等
- 分词器:过滤后的字符串会被分词器分为单个的词条,以英文为例,遇到空格或标点符号就会拆分
- token过滤器:分词之后每个词条都会进入到token过滤器中再次过滤,进行修改词条(大写转化为小写)、删除词条(a、the等)等操作
Elasticdump使用
安装过程省略
# 迁移配置(可以指定某一个index或者不指定)
elasticdump --input=http://172.16.0.39:9200/companydatabase --output=http://172.16.0.20:9200/companydatabase --type=settings
# 迁移mapping
elasticdump --input=http://172.16.0.39:9200 --output=http://172.16.0.20:9200 --type=mapping --limit=100000
#迁移数据
elasticdump --input=http://172.16.0.39:9200 --output=http://172.16.0.20:9200 --type=data --limit=100000
# 整体迁移
elasticdump --input=http://172.16.0.39:9200 --output=http://172.16.0.20:9200 --limit=100000