kubeadm安装kubernetes
kubeadm 是官方社区推出的一个用于快速部署 kubernetes 集群的工具。 这个工具能通过两条指令完成一个 kubernetes 集群的部署:
$ kubeadm init 创建一个master节点
$ kubeadm join 将一个 Node 节点加入到当前集群中
试验背景
在学习k8s搭建中,网上大部分教程都是用虚拟机做集群,只有极少数是使用服务器搭建教程,用云服务器的更少。
试验环境
这里准备了三台服务器进行测试
110.42.149.60 master 阿里云 2H4G CentOS7.6
42.193.254.253 node1 阿里云 2H4G CentOS7.6
69.165.74.251 node2 阿里云 2H4G CentOS7.6
是干净的系统刚开通的环境
安装集群版本 1.23.1
1 前置
1 所有节点上安装 docker kubeadman kubelet、kubectl 而且这三个版本要统一
docker 运行时容器 kubeadman 快速安装k8s的工具
kubectl 命令行操作节点 kubelet node节点的代理 来进行干活创建pod 管理网络
2 修改主机名 hosts配置 master节点 就用master node节点 就用node
hostnamectl 检测主机名
vim /etc/hosts
本机内网ip的名字改为master/node
3 关于防火墙如果使用的云服务器就不用管他
2 安装 前置软件
docker
touch docker.sh
#!/bin/bash
yum install -y yum-utils
yum-config-manager \
--add-repo \
https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
mkdir -p /etc/docker && touch /etc/docker/daemon.json
cat > /etc/docker/daemon.json <<END
{
"registry-mirrors": ["https://3sf1ht53.mirror.aliyuncs.com"],
"exec-opts": ["native.cgroupdriver=systemd"]
}
END
yum install docker-ce docker-ce-cli containerd.io
systemctl start docker
chmod +x docker.yml && ./docker.yml
kubeadman kubelet、kubectl
kubeadman kubelet kubectl 指定版本 最好版本统一和kubernetes的版本统一
1 添加yum 源
cat > /etc/yum.repos.d/kubernetes.repo << EOF
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=0
repo_gpgcheck=0
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg
https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
2 安装
yum install -y kubelet-1.23.1-0 kubeadm-1.23.1-0 kubectl-1.23.1-0
3 查看是否安装成功
kubectl version
kubelet --version
kubeadm version
4 设置开机自启
systemctl restart kubelet
3 master主节点
1 修改hosts文件
这里的ip 都要可以ping通 最好用这个内网ip 要和etho的那个保持一致

vim /etc/hosts
110.42.149.60 master
42.193.254.253 node
169.165.74.251 node
2 下载镜像
如果网络不好 下载镜像可能就下载不下来,提前把镜像下载下来
编写一个脚本文件 自己先下载
vim master_images.sh
#!/bin/bash
images=(
kube-apiserver:v1.17.3
kube-proxy:v1.17.3
kube-controller-manager:v1.17.3
kube-scheduler:v1.17.3
coredns:1.6.5
etcd:3.4.3-0
pause:3.1
)
for imageName in ${images[@]} ; do
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/$imageName
# docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/$imageName k8s.gcr.io/$imageName
done
chmod 700 master_images.sh 赋予权限
./master_images.sh 开始执行
下载好的镜像

3 开始初始化master节点
kubeadm init \
--apiserver-advertise-address=120.77.82.244 \
--image-repository registry.cn-hangzhou.aliyuncs.com/google_containers \
--kubernetes-version v1.23.1-0 \
--service-cidr=10.96.0.0/16 \
--pod-network-cidr=192.168.0.0/16
kubeadm init \ 设置主节点 的ip就是你的公网ip需要写的hosts文件里
--kubernetes-version=1.23.1 指定k8s的版本
--apiserver-advertise-address=自己的ip 因为k8s的所有操作命令都要经过 apiserver 并设置主节点的地址
如果是使用云服务器 这个参数就去掉
--kubernetes-version 指定版本
--image-repository 默认是从k8s.io 现在改成阿里云的
service-cidr=10.96.0.0/16 \ 对不同节点 pod 之间网络的访问 ,集群内部虚拟网络,Pod统一访问入口
--pod-network-cidr=10.244.0.0/1 所在的ip pod和 pod 之间 与下面部署的CNI网络组件yaml中保持一致
4 使用阿里云搭建k8s时,在主节点执行kubeadm init时候卡在
Waiting for the kubelet to boot up the control plane as static Pods from directory "/etc/kubernetes/manifests". This can take up to 4m0
这是因为kubeadm init 指定了"--apiserver-advertise-address"为公网ip,但是阿里云的机器是vpc网络,使用ifconfig时候,可以看到网卡上显示的是内网ip,并没有公网ip,这就会导致etcd无法启动,etcd 启动不了 kubelet也就启动不了 解决办法为去掉--apiserver-advertise-address参数。
如果初始化失败
echo "1" > /proc/sys/net/ipv4/ip_forward
nmcli c reload
https://www.cnblogs.com/fufengyuan/p/16382182.html
5 初始化成功
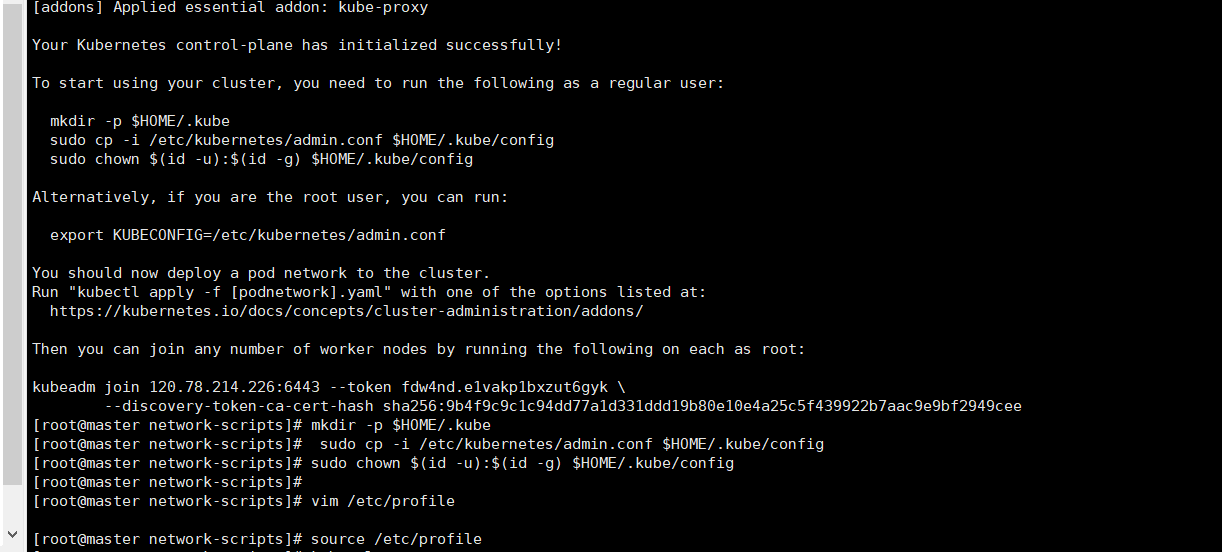
6 跟着步骤进行操作 需要先复制 最后一行的 kubeadm的join 这是别的节点加入你的集群的token 有效时间2h
mkdir -p $HOME/.kube
cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
chown $(id -u):$(id -g) $HOME/.kube/config
vim /etc/profile
export KUBECONFIG="/etc/kubernetes/admin.conf"
source /etc/profile
7 如果忘记token了,在主节点使用kubeadm token list命令查看。如果token过期了
8 K8s集群创建的时候,在主节点使用kubeadm init命令,如果第一次失败了,再次执行此命令发现提示端口已占用,文件已存在,怎么办?使用kubeadm reset 命令清空,然后重新init
9 设置网络插件
用fanl
kubectl apply -f \ https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
2 如果fanl下载不了
3 用手动方式进行下载
4 配置fanl
kubectl apply -f kube-flannel.yml
如果此时报错
The connection to the server localhost:8080 was refused - did you specify the right host or port?
解决方法
具体根据情况,此处记录linux设置该环境变量
方式一:编辑文件设置
vim /etc/profile
在底部增加新的环境变量 export KUBECONFIG=/etc/kubernetes/admin.conf
方式二:直接追加文件内容
echo "export KUBECONFIG=/etc/kubernetes/admin.conf" >> /etc/profile
在次运行 kubectl apply -f kube-flannel.yml
4 node 节点
1 node节点加入 master节点
这是我自己的tokn 你要加入你自己的就是之前生成的tokn
kubeadm join 120.78.214.226:6443 --token fdw4nd.e1vakp1bxzut6gyk \--discovery-token-ca-cert-hash sha256:9b4f9c9c1c94dd77a1d331ddd19b80e10e4a25c5f439922b7aac9e9bf2949cee
加入成功

2 如果token过期了 需要自己在master节点上重新生成一个
1.通过下面的命令可以创建一个不过期的token
# kubeadm token create --ttl 0
p4rynu.uj4jaxnzk2s0y9vi #这个值就是Token
把这个tokn进行替换即可
2.查看可用的token列表
# kubeadm token list
TOKEN TTL EXPIRES USAGES
检测是否加入集群成功

3 如果我想在node节点上操作k8s该怎么操作
如果直接使用kubectl 会报错
出现这个问题的原因是kubectl命令需要使用kubernetes-admin的身份来运行,在“kubeadm int”启动集群的步骤中就生成了“/etc/kubernetes/admin.conf”。
因此,解决方法如下,将主节点中的【/etc/kubernetes/admin.conf】文件拷贝到工作节点相同目录下:
用ssh登录或者用xftp 进行文件传输
然后分别在工作节点上配置环境变量:
#设置kubeconfig文件
export KUBECONFIG=/etc/kubernetes/admin.conf
echo "export KUBECONFIG=/etc/kubernetes/admin.conf" >> ~/.bash_profile
刷新环境变量 source/etc/profile
然后输入密码即可
任意一台机器只要安装了kubelet 都可以 按照上述操作即可进行远程操控我的k8s集群
5 远程连接
win上远程操作kubernetes集群
1、在Windows上安装kubectl
打开CMD工具,并创建kubectl文件夹,进入创建的文件夹中 在C:\Program Files目录下创建Kubectl目录,并进入Kubectl目录
用curl命令安装kubectl 执行命名安装kubectl 这里安装的是1.19.0,如果要安装其他版本只需在url中修改版本号即可
curl -LO "https://dl.k8s.io/release/v1.19.0/bin/windows/amd64/kubectl.exe"
2、下载K8S集群的配置文件
联接K8S集群主节点,找到$HOME/.kube/config文件并下载 连接master节点,进入.kube目录找到config文件,并下载到本地
cd $HOME/.kube/
在本地win系统C:\Users\XXX目录下创建.kube文件夹
将步骤(1)下载的config文件拷贝到步骤(2)创建的.kube文件夹中
3、配置环境变量
将kubectl所在目录添加到win系统环境变量中
说明: Windows 版的 Docker Desktop 将其自带版本的 kubectl 添加到 PATH。 如果你之前安装过 Docker Desktop,可能需要把此 PATH 条目置于 Docker Desktop 安装的条目之前, 或者直接删掉 Docker Desktop 的 kubectl。
4、验证 kubectl 配置
执行下列命令查看结果
kubectl cluster-info
如果命令 kubectl cluster-info 返回了 url,但你还不能访问集群,那可以用以下命令来检查配置是否妥当
kubectl cluster-info dump
执行kubectl get nodes查看结果