发表于2019 年 12 月 9 日
在 .NET 中,处理二进制数据时通常使用字节数组;例如,在方法之间传递文件的内容、编码/解码文本、从套接字读取数据等。这些数组可能会变得非常大(最大为兆字节),OutOfMemoryException如果运行时无法运行,最终可能会导致被抛出分配足够大的内存块来保存数组。由于数组始终作为单个连续块分配,因此即使有足够的可用内存也可能会引发此异常。这是由于碎片化,其中使用的内存块占据了稀疏的地址范围,可用内存仅作为这些块之间的小间隙存在。

避免此问题的一种方法是使用缓冲区一次仅对少量字节进行操作。这种方法通常与流结合使用。例如,我们可以避免将整个文件加载到内存中,方法是使用 aFileStream并将其内容读入一个小数组,比如一次 4KB。如果数据来自外部源并且可以通过Stream对象公开,这可能是一种非常有效的内存使用方式。
如果不是这种情况,则MemoryStream课程通常会发挥作用。这种类型允许我们在不使用 I/O 的情况下读取和写入数据,如果需要,一次仍然是一小部分。例如,您可以使用内存流来执行数据的即时转换,或者制作通常不支持此功能的流的可查找副本。但是,有一个很大的限制,即内存流的后备存储只是一个大字节数组!因此,它在连续分配和内存碎片漏洞方面存在相同的问题。
因此,无论是内存流的大字节数组,OutOfMemoryException如果您经常或大量使用这些机制,无论哪种方式都可能遇到。
数组与链表
当我们查看各种集合类型及其实现时,数组和链表之间存在明显差异。虽然数组需要一个连续的内存块,但链表能够跨越多个不连续的地址。因此,乍一看,字节链表似乎是我们问题的合理解决方案。
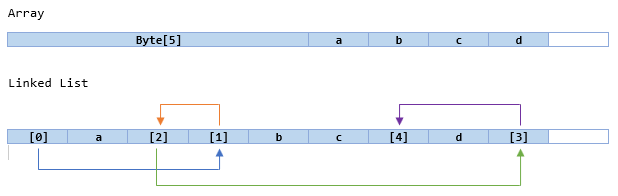
使用字节直链表的问题在于,每个字节需要 4 个额外的字节(或 64 位机器上的 8 个字节)来存储下一个元素的地址,这使得它在存储方面效率极低。此外,数组是固定长度的,而链表往往会根据需要增长和缩小;由于每个新元素都需要分配内存,因此写入链表要慢得多。
此外,链表无法从该Buffer.BlockCopy()方法中受益,该方法在字节数组之间复制时提供了极大改进的性能。
混合解决方案
一个理想的解决方案将为我们提供两全其美的解决方案;即链表的非连续性质与数组的性能优势。换句话说,一个较小数组的链表。由于我们的目标是最终替换大字节数组和 MemoryStream 类,因此解决方案需要是可写的和可变长度的。

为了以最有效的方式利用可用内存,这些较小的数组中的每一个都应该等于(或倍数)操作系统分配的每个内存块的大小。在 Windows 的情况下(至少在撰写本文时),虚拟内存以 4KB 的块分配。这称为页面大小。通过将数组与页面大小对齐,我们避免浪费我们分配的任何内存(从而剥夺我们代码的其他部分)。
如果我们要写入这个结构,最好将整个 4KB 分配给每个数组一次,而不是每次长度更改时都必须重新声明和复制现有数据。这个决定的效果是我们需要在每个节点上都有一个额外的字段来存储实际使用的字节数。这也意味着即使是 1 个元素的集合仍会占用 4KB 的内存。我们可以通过为第一个数组设置异常来避免这种情况。
索引
要访问集合中特定偏移量的字节,我们需要遍历链表直到到达包含偏移量的节点,然后在该节点的数组中获取/设置该元素。
阅读
从此集合中读取任意数量的字节涉及两个步骤:
- 遍历链表,直到我们到达包含我们要开始读取的偏移量的节点。
- 将字节从数组复制到目标。如果达到已用字节数后还有更多字节要复制,则遍历到下一个节点并重复此步骤。
写作
将任意数量的字节写入此集合包括以下步骤:
- 遍历链表,直到我们到达包含我们要开始写入的偏移量的节点。
- 如果当前节点之后还有更多节点,则只复制已使用的字节数;否则,复制到数组的完整长度并更新使用的字节数。(这避免了当我们打算替换或附加数据时插入数据)
- 如果还有更多字节要写入,则遍历到下一个节点。如果它不存在,则创建它。从第 2 步开始重复。
插入
虽然这对于流或字节数组通常是不可能的,但在集合中的某个点插入任意数量的字节的能力将是非常可取的。例如,假设您通过 UDP 连接接收到一系列数据包并希望以正确的顺序重建消息,您可以简单地将每个数据包中的字节插入所需的偏移量。如果没有此功能,将需要多个数组,并且您可能必须在内存中复制数据。
插入涉及以下步骤:
- 遍历链表,直到我们到达包含我们要插入数据的偏移量的节点。
- 在此偏移处截断数组(即更新使用的字节数)并将剩余字节复制到临时数组中。(如果阵列完全未使用,请跳过此步骤)
- 复制字节直到数组已满。如果需要更多数组,请将它们插入到当前节点之后并重复。
- 将步骤 2 中的剩余字节复制到当前数组中(如果需要,插入另一个节点)。
在插入操作之后,集合中可能存在“间隙”,其中使用的字节数小于每个数组的长度。消除这些差距将是一项昂贵的操作。
删除
作为插入的补充操作,应该可以从集合中删除任意数量的字节,从任何偏移量开始。该过程包括:
- 遍历链表,直到到达包含要删除数据的起始偏移量的节点。捕获此节点。
- 继续遍历链表,直到我们到达包含结束偏移量(开始 + 计数)的节点。捕获此节点。
- 将结束偏移(在结束节点中)之后的尾随字节复制到临时数组中。(如果数组中没有尾随字节,则跳过此步骤)
- 在起始偏移量之后截断起始节点中的数组(即更新使用的字节数)。
- 在起始偏移后插入步骤 3 中的尾随字节。
- 从链表中删除所有中间节点(通过更新“下一个”和“上一个”标记),包括结束节点。
与插入一样,删除可能会在集合中产生“间隙”。
序列化
有时需要序列化一个字节序列;例如,为了将数据嵌入到 XML 文档中,或者在应用程序域之间编组。由于字节数组和内存流支持此功能,我们的集合也应该实现它。
接受默认的二进制序列化会导致次优结果,因此我们将通过实现ISerializable. XML 序列化器也是如此(实际上它可能根本不起作用),因此我们还将实现IXmlSerializable. 对于前者,序列化形式是与我们集合中的字节数组镜像的字节数组序列,然后是数组总数。对于后者,只需要写入数组(使用 Base64 编码)。
流实现
至此,我们已经实现了一个字节集合,其使用方式与传统字节数组大致相同;索引,阅读,写作等。现在,我们想要实现一个流类,它使用我们的集合作为后备存储,并且可以用来代替MemoryStream. 这两种类型一起应该允许我们避免分配连续的内存块,从而避免OutOfMemoryException(当然,除非进程真的耗尽内存,我们无能为力)。
Streams 提供 3 种基本操作;阅读、写作和寻找。要将数据读入缓冲区,我们可以简单地使用我们已经实现的功能从底层集合中读取,从流的位置标记开始。这同样适用于写作。每次操作后,我们需要将位置标记增加实际读/写的字节数。最后,通过直接操纵位置标记来实现搜索。
流的一个高级用例是能够更改流的长度。这可以通过截断集合(参见上面的删除)或通过在集合末尾添加所需的字节数来实现。
结果
为了了解我们的新集合提供的好处是否真正得到了体现,我进行了一个简单的测试,该测试可以同样应用于它或传统的字节数组:分配大量字节(在本例中为 10MB),并且结果保存在一个列表中(以防止垃圾收集器回收内存)。此过程无限重复,直到OutOfMemoryException抛出 an,此时测量迭代次数。我观察到,与使用字节数组相比,非连续方法的迭代次数持续增加了 50%。
然而,这并不都是好消息。如您所料,更有效地使用内存会降低性能,并且非连续方法需要更长的时间才能完成(实际上是几个数量级)。这是因为与数组的 O(1) 相比,内存的非连续分配是 O(n) 操作。这意味着非连续分配 10MB 的时间比作为数组的时间长 2560 倍。您可以通过选择更大的块大小来改进这一点(例如,32KB 的块大小会导致运行速度明显加快,而迭代次数不会显着减少),但如果大小太大,则首先会破坏非连续分配内存的目的. 这也依赖于调用者知道数据的总长度,这是无法保证的。
最终,这种集合和流类型旨在解决一个非常具体的问题,如果内存碎片也是影响您的代码的问题,我建议使用这种方法。我不会推荐它用于一般用途,或者MemoryStream完全替代字节数组。
下载
该项目的源代码可在 GitHub 上获得: https ://github.com/BradSmith1985/NonContig
标签:MemoryStream,链表,内存,数组,集合,节点,字节 From: https://www.cnblogs.com/firespeed/p/16709094.html