Part A
前置准备
gcc -Wall -O1 -g -c yis.c
gcc -Wall -O1 -g -c isa.c
gcc -Wall -O1 -g yis.o isa.o -o yis
gcc -Wall -O1 -g -c yas.c
flex yas-grammar.lex
make: flex: Command not found
Makefile:22: recipe for target 'yas-grammar.c' failed
解决方案
sudo apt-get install bison flex
sum_list

链表求和和书上的数组求和本质上是差不多的,仿照着写即可
/* sum_list - Sum the elements of a linked list */
long sum_list(list_ptr ls)
{
long val = 0;
while (ls) {
val += ls->val;
ls = ls->next;
}
return val;
}
分析程序分为哪些部分
-
main作为程序入口一定是要有的
主要任务是准备函数参数,然后调用sum_list函数
其中rdi寄存器即负责传递参数,又充当链表指针
这是因为在传递参数时,初始值就相当于链表的第一个位置的指针,所以后续就直接使用该寄存器作为链表指针
irmovq ele1, %rdi call sum_list -
sum_list作为函数
sum_list会初始化一些寄存器,然后跳转到判断
从写高级语言的角度思考,在进行循环求和之前,首先会定义一个计数器并初始化为0,这里选择使用rax寄存器,因为这个计数器同时还应当是返回值,而rax寄存器恰好是作为返回值的寄存器,所以直接采用rax作为计数器,然后开始while的第一次条件判断
xorq %rax, %rax jmp test -
一个循环loop
循环内部要做两件事情
-
完成累加
rdi是链表指针,存储着一个内存地址,我们需要将这个值从内存中取出后累加到计数器rax上
需要注意的是,在Y86-64中,add指令只支持对寄存器数据进行操作,无法直接将内存数据累加到寄存器中,所以需要首先将内存中的数据取出放到寄存器中,这里参照数组求和的代码,选择%r10寄存器
-
使链表指针向后移动一位
这里必须要看懂链表的结构
看懂.quad,表示4个word,即8个字节非常关键,知道这个可以得知链表具有如下结构
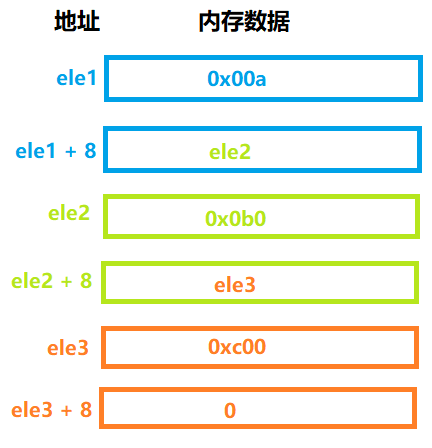
起初R[rdi] = ele1
现在期望R[rdi] = ele2
而ele2 = M[ele1 + 8] = M[R[rdi] + 8]
即
mrmovq 8(%rdi), %rdi
mrmovq (%rdi), %r10 addq %r10, %rax mrmovq 8(%rdi), %rdi -
-
循环还需要一个判断test
通过对于链表的定义可知,判断是否遍历完成只需要判断rdi存储的地址是否为0即可
这里需要对rdi进行判断,并且不能改变rdi的值,只能选择与操作,一个数自身与自身相与,只有其为0,结果才为0,不为0则继续进行loop,否则return
# addq %rdi, %rdi 因为这个找了好久错 andq %rdi, %rdi jne loop ret
rsum_list
/* rsum_list - Recursive version of sum_list */
long rsum_list(list_ptr ls)
{
if (!ls)
return 0;
else {
long val = ls->val;
long rest = rsum_list(ls->next);
return val + rest;
}
}
与sum_list相比,整体框架不变
汇编写递归的难点在于
它像是使用高级语言通过全局变量写递归
代码照着高级语言进行翻译即可,但是一个容易忽略的点是r10寄存器需要进出栈操作
在下面的代码中可以发现的是,r10寄存器在递归调用之前出现过一次负责存储值,在函数调用之后期望使用到它在函数调用前存储的值
前面说到,使用寄存器相当于全局变量而非局部变量,r10在函数调用前后都是一个r10,也就是说上一层r10存储的值会被当前层的操作所修改,那么上一层在函数调用后也就无法正确得到函数调用前存储的值
也就是说在我们要修改r10时,必须把上一层的r10存储起来,在返回时将r10的值恢复回去,才能保证上一层在函数调用后使用的r10的值是正确的,这也就是pushq和popq的作用
rsum_list:
pushq %r10
xorq %rax, %rax # 为了rsum_list递归时后续计算
# 对应 if (!ls) return 0;
andq %rdi, %rdi
je end
# 对应 long val = ls->val
mrmovq (%rdi), %r10
# 对应 long rest = rsum_list(ls->next)
mrmovq 8(%rdi), %rdi
call rsum_list
# 对应 val + rest
addq %r10, %rax
end:
popq %r10
ret
总结:一些寄存器是否需要压栈取决于以下两点,只有两点都满足时需要压弹栈操作
- 函数调用是否会修改它的值
- 是否需要它在函数调用前后保持相同的值
copy_block
/* copy_block - Copy src to dest and return xor checksum of src */
long copy_block(long *src, long *dest, long len)
{
long result = 0;
while (len > 0) {
long val = *src++;
*dest++ = val;
result ^= val;
len--;
}
return result;
}
有了以上两个函数的铺垫,这个是不难写的
寄存器分配如下
rdi : 第1个参数,存储dest
rsi:第2个参数,存储src
以上两者同时充当指针
rdx:第3个参数,控制循环次数,初始值设置为3
r8:值为1,负责rdx递减
r9:值为8,赋值rdi和rsi地址的递增
rbx:充当内存到内存数据传递中转站
loop:
# 循环次数判断
andq %rdx, %rdx
jle end
# copy
mrmovq (%rsi), %rbx
rmmovq %rbx, (%rdi)
# 指针移动和循环变量加1
addq %r9, %rdi
addq %r9, %rsi
subq %r8, %rdx
jmp loop
最终结果
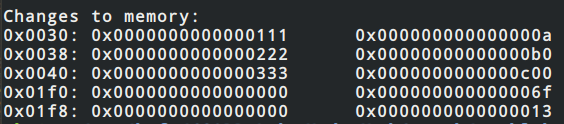
左侧为内存中原内容,右侧为最终内存中内容
优化
在以上3个代码中,除了第2个代码寄存器必须通过压栈和弹栈才能保证结果的正确
其余我们均未考虑将寄存器压栈弹栈
可以看到,即使我们没有这么做,最终的运行结果也是正确的,这是因为我们的代码没有牵扯到其他程序,即使一些寄存器初始值和最终值不同也不会影响最终结果
但是如果涉及到其他程序,在我们的程序中发生改变的寄存器我们应当保证它们的值在调用我们的代码前后值不发生改变,否则可能影响其他程序的运行
作为参数的寄存器不需要压栈
在sum_list中,涉及到的寄存器为%r10
在rsum_list中,涉及到的寄存器为%r10,但是这一寄存器是必须压弹栈的,否则结果不正确
在copy_block中,涉及到的寄存器为%rbx, %r8, %r9
Part B
直接查看archlab.pdf是有点懵的,在[Part A](#Part A)中我们还在写汇编代码,怎么到了Part B突然就涉及到硬件的HCL描述了
但是如果去看下书籍,就明白了

在Part A我们做的内容对应4.1部分,4.2是了解的部分
Part B做的内容对应4.3
Part C对应4.4 和 4.5
所以我们做这个部分的实验,跟随4.3的讲解顺序即可
- 逻辑上分析指令的顺序实现方式
- 通过HCL语言对上述分析结果进行描述
这个实验的目的就是添加一个iaddq指令,添加指令,对于硬件的描述就要发生改变,因此需要修改HCL描述
顺序实现逻辑分析
通过查看homework 4.51得知如下内容
iaddq指令:将立即数与寄存器相加


参照subq和rmmovq顺序实现的过程,可以自行推出iaddq的顺序实现过程如下:
iaddq的指令结构与irmovq完全,都是由立即数和寄存器组成的

-
取值阶段
其中valC为立即数
valP为下一条指令地址
-
译码阶段
valB为寄存器存储数值
\(valB \leftarrow R[r_B]\)
-
执行阶段
valE存储最终结果
\(valE \leftarrow valC + valB\)
-
访存阶段
-
写回阶段
\(R[r_B] \leftarrow valE\)
-
更新PC
\(PC \leftarrow valP\)
为什么要分析指令的顺序实现
按照homework 4.52的说法,实现iaddq指令的逻辑控制块的HCL描述,实际是参照它的顺序实现的描述的
HCL描述
所谓HCL,学过数字电路多少有些涉及到类似的只是
就是用HCL语句描述硬件的实现
对应不同阶段,需要修改的内容不同
-
取址阶段
- instr_valid:是否是一合法指令
- need_regids:是否包括一个寄存器指示符字节
- need_valC:是否包括一个常数字
显然iaddq指令满足以上3点,所以需要将iaddq加入进去
bool instr_valid = icode in { INOP, IHALT, IRRMOVQ, IIRMOVQ, IRMMOVQ, IMRMOVQ, IOPQ, IJXX, ICALL, IRET, IPUSHQ, IPOPQ, IIADDQ }; # Does fetched instruction require a regid byte? bool need_regids = icode in { IRRMOVQ, IOPQ, IPUSHQ, IPOPQ, IIRMOVQ, IRMMOVQ, IMRMOVQ, IIADDQ }; # Does fetched instruction require a constant word? bool need_valC = icode in { IIRMOVQ, IRMMOVQ, IMRMOVQ, IJXX, ICALL, IIADDQ }; -
译码和写回阶段
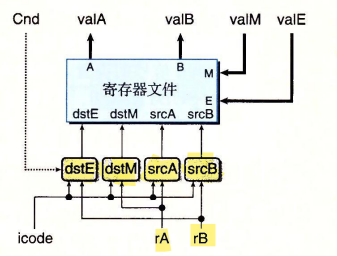
valA 和 valB 负责存储从寄存器取出的值
valM 和 valE 负责输入要存入寄存器的值
srcA 和 srcB 负责给定要读取寄存器的地址
detE 和 detM 负责给定要存入数据的寄存器的地址

src提供一个地址,这个地址指示要读取哪个寄存器的数据
dst提供一个地址,指示要将从寄存器中读取到的数据存入到哪里
根据逻辑描述的
\(valB \leftarrow R[r_B]\)
\(R[r_B] \leftarrow valE\)
iaddq指令要读取的寄存器和要写入的寄存器是同一个,均使用rb来指示
使用rB的为srcB和dstE,所以修改这两项
## What register should be used as the B source? word srcB = [ icode in { IOPQ, IRMMOVQ, IMRMOVQ, IIADDQ } : rB; icode in { IPUSHQ, IPOPQ, ICALL, IRET } : RRSP; 1 : RNONE; # Don't need register ]; ## What register should be used as the E destination? word dstE = [ icode in { IRRMOVQ, IIADDQ } && Cnd : rB; icode in { IIRMOVQ, IOPQ} : rB; icode in { IPUSHQ, IPOPQ, ICALL, IRET } : RRSP; 1 : RNONE; # Don't write any register ]; -
执行阶段
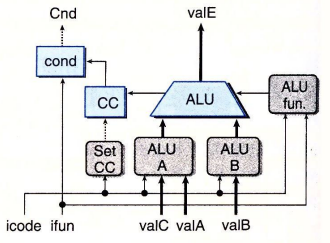
iaddq指令通过valB和valC将数据传入逻辑运算单元ALU B 和 ALU A
所以修改这两个逻辑运算单元的描述
同时iaddq指令涉及到更新标志位的操作,所以还需要修改set cc的硬件实现描述
## Select input A to ALU word aluA = [ icode in { IRRMOVQ, IOPQ } : valA; icode in { IIRMOVQ, IRMMOVQ, IMRMOVQ, IIADDQ } : valC; icode in { ICALL, IPUSHQ } : -8; icode in { IRET, IPOPQ } : 8; # Other instructions don't need ALU ]; ## Select input B to ALU word aluB = [ icode in { IRMMOVQ, IMRMOVQ, IOPQ, ICALL, IPUSHQ, IRET, IPOPQ, IIADDQ } : valB; icode in { IRRMOVQ, IIRMOVQ } : 0; # Other instructions don't need ALU ]; ## Should the condition codes be updated? bool set_cc = icode in { IOPQ, IIADDQ }; -
访存阶段
iaddq在访存阶段没有操作,所以不需要修改
-
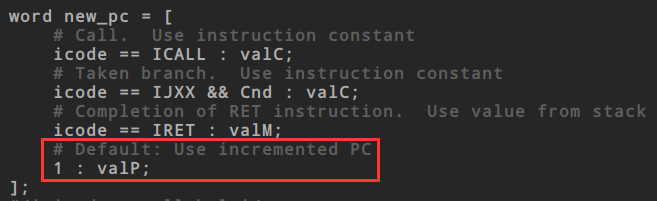
更新pc阶段
更新PC寄存器默认使用的就是valP,而iaddq使用的正是valP,所以不需要修改
-
进行测试
make VERSION=full # 构建 ./ssim -t ../y86-code/asumi.yo cd ../y86-code; make testssim cd ../ptest; make SIM=../seq/ssim cd ../ptest; make SIM=../seq/ssim TFLAGS=-i
Part C
可以优化的有两部分
- ncopy.ys:汇编文件
- pipe-full.c:HCL描述文件
对于pipe-full.c可修改内容从直观上来说应当是不多的,因为毕竟涉及到硬件结构
主攻方向目测要放在汇编文件上
要优化的程序是一个复制程序,并返回大于0的元素个数
对汇编文件的优化对应书籍第5章-优化程序性能
对HCL描述文件的优化对应4.5-Y86-64的流水线实现
优化策略
-
考虑内存引用次数

-
函数调用改内联

-
消除循环低效率
将要执行多次但是计算结果不会改变的部分移动到不会被多次求值的部分
例如下面红色框的改变

-
减少过程调用
b是将函数调用内嵌进去,d是取消函数调用
例如有一个数组,从中取值,通过一个函数去取值就可以优化为直接取值
-
循环展开
循环展开即一次循环中执行多次元素计算,循环的步长大于1
-
使用多个累积变量
不同变量的计算是可以并行完成的
这就比使用一个变量要更快
-
重新结合变换
for (i = 0; i < limit; i+=2) { acc = (acc OP data[i]) OP data[i+1]; // 一次循环实际计算了两个元素 } // 改为 for (i = 0; i < limit; i+=2) { acc = acc OP (data[i] OP data[i+1]); // 一次循环实际计算了两个元素 }后面的方法(data[2] op data[3]]) 和 acc op (data[0] op data[1])两个操作之间是没有联系的,所以在进行上一层运算时,下一层可以并行地执行,流水线一样,从而提高速度
优化流程
初始状态
# Loop header
xorq %rax,%rax # count = 0;
andq %rdx,%rdx # len <= 0?
jle Done # if so, goto Done:
Loop: mrmovq (%rdi), %r10 # read val from src...
rmmovq %r10, (%rsi) # ...and store it to dst
andq %r10, %r10 # val <= 0?
jle Npos # if so, goto Npos:
irmovq $1, %r10
addq %r10, %rax # count++
Npos: irmovq $1, %r10
subq %r10, %rdx # len--
irmovq $8, %r10
addq %r10, %rdi # src++
addq %r10, %rsi # dst++
andq %rdx,%rdx # len > 0?
jg Loop # if so, goto Loop:
Done:
ret
-
修改pipe-full.hcl添加iaddq指令
这个步骤理应当是我们在优化汇编代码时发现使用iaddq指令可以使程序跑得更快,但是既然Part B让我们做了这一步,就一定有应用的道理
它的优化原理是,addq指令只能在寄存器与寄存器之间进行运算,若想要实现寄存器与立即数运算,至少需要2条指令,而iaddq则只需要1条
-
将ncopy.ys中立即数与寄存器之间的加法均改为iaddq指令
CPE : 15.18 -> 12.70
# Loop header xorq %rax,%rax # count = 0; andq %rdx,%rdx # len <= 0? jle Done # if so, goto Done: Loop: mrmovq (%rdi), %r10 # read val from src... rmmovq %r10, (%rsi) # ...and store it to dst andq %r10, %r10 # val <= 0? jle Npos # if so, goto Npos: iaddq $1, %rax # count++ Npos: iaddq $-1, %rdx # len-- iaddq $8, %rdi # src++ iaddq $8, %rsi # dst++ andq %rdx,%rdx # len > 0? jg Loop # if so, goto Loop: Done: ret -
iaddq $-1, %rdx # len--和andq %rdx,%rdx # len > 0?的作用对于条件跳转指令来说是相同的,而iaddq指令必须执行,所以去掉andq指令CPE: 12.70 -> 11.70
-
循环展开
我们应当认为展开次数是不固定的,并不能按照ncopy.c程序中写定的8来进行展开
所以假设我们按照4*4进行展开
有一个部分应当是处理完整的4项的(入口定位Loop),还有一部分是处理不足4项的(入口定为Remain)
整体框架:
ncopy: Loop: copy1: # copy第1部分 copy2: # copy第2部分 copy3: # copy第3部分 copy4: # copy第4部分 nLoop: # 进入下一次Loop,参数准备 Remain: # 剩余待copy部分可能为0, 1, 2, 3 Rcopy1: # copy剩余第1部分 Rcopy2: # copy剩余第2部分 Rcopy3: # copy剩余第3部分 Done: # 结束返回-
循环开始之前
初始化rax为0
xorq %rax, %rax判断rdx(len)与4的大小关系
- 大于等于4,进入处理完整4项的部分
- 小于4,进入处理不足4项的部分
令rdx减去4,检查标志位即可
iaddq $-4, %rdx jl Remain # len < 4,进入Remain -
Loop部分
直接进入copy阶段
每一次copy的操作逻辑都是相同的,内容如下(以copy1为例,其余只需要需改rdi的地址和jle的地址即可)
mrmovq (%rdi), %r10 rmmovq %r10, (%rsi) andq %r10, %r10 jle copy2 iaddq $1, %rax -
nLoop部分
需要移动rdi,rsi,修改长度值
处理了4部分,即%rdi, %rdi+8, %rdi+16, %rdi+24,所以偏移量为32
同时长度应当减少4
iaddq $32, %rdi iaddq $32, %rsi iaddq $-4, %rdx jge Loop # 在剩余长度>=0时进行下一轮完整copy -
Remain部分
进入此部分,说明长度值可能为0,1,2,3,对应rdx的值为-4,-3,-2,-1
需要恢复为正常值,rdx的定义为剩余长度值,显然通过+4恰好对应剩余长度值
iaddq $4, %rdx je Done # 长度为0时结束程序 -
Rcopy部分
每一次Rcopy的操作逻辑都是相同的,内容如下(以Rcopy1为例,其余只需要需改rdi,rsi和jle的地址即可)
iaddq $-1, %rdx jl Done # rdx-1<0,说明rdx==0,结束程序 mrmovq (%rdi), %r10 rmmovq %r10, (%rsi) andq %r10, %r10 jle Rcopy2 iaddq $1, %rax
CPE: 11.70 -> 9.27
修改为5*5循环展开
CPE: 9.27-> 9.20
修改为6*6循环展开
CPE: 9.20-> 9.17
-
#/* $begin ncopy-ys */
##################################################################
# ncopy.ys - Copy a src block of len words to dst.
# Return the number of positive words (>0) contained in src.
#
# Include your name and ID here.
#
# Describe how and why you modified the baseline code.
#
##################################################################
# Do not modify this portion
# Function prologue.
# %rdi = src, %rsi = dst, %rdx = len
ncopy:
##################################################################
# You can modify this portion
# Loop header
xorq %rax,%rax # count = 0;
iaddq $-6, %rdx
jl Remain
Loop:
copy1:
mrmovq (%rdi), %r10
rmmovq %r10, (%rsi)
andq %r10, %r10
jle copy2
iaddq $1, %rax
copy2:
mrmovq 8(%rdi), %r10
rmmovq %r10, 8(%rsi)
andq %r10, %r10
jle copy3
iaddq $1, %rax
copy3:
mrmovq 16(%rdi), %r10
rmmovq %r10, 16(%rsi)
andq %r10, %r10
jle copy4
iaddq $1, %rax
copy4:
mrmovq 24(%rdi), %r10
rmmovq %r10, 24(%rsi)
andq %r10, %r10
jle copy5
iaddq $1, %rax
copy5:
mrmovq 32(%rdi), %r10
rmmovq %r10, 32(%rsi)
andq %r10, %r10
jle copy6
iaddq $1, %rax
copy6:
mrmovq 40(%rdi), %r10
rmmovq %r10, 40(%rsi)
andq %r10, %r10
jle nLoop
iaddq $1, %rax
nLoop:
iaddq $48, %rdi
iaddq $48, %rsi
iaddq $-6, %rdx
jge Loop
Remain:
iaddq $6, %rdx
je Done
Rcopy1:
iaddq $-1, %rdx
jl Done # rdx-1<0,说明rdx==0,结束程序
mrmovq (%rdi), %r10
rmmovq %r10, (%rsi)
andq %r10, %r10
jle Rcopy2
iaddq $1, %rax
Rcopy2:
iaddq $-1, %rdx
jl Done # rdx-1<0,说明rdx==0,结束程序
mrmovq 8(%rdi), %r10
rmmovq %r10, 8(%rsi)
andq %r10, %r10
jle Rcopy3
iaddq $1, %rax
Rcopy3:
iaddq $-1, %rdx
jl Done # rdx-1<0,说明rdx==0,结束程序
mrmovq 16(%rdi), %r10
rmmovq %r10, 16(%rsi)
andq %r10, %r10
jle Rcopy4
iaddq $1, %rax
Rcopy4:
iaddq $-1, %rdx
jl Done # rdx-1<0,说明rdx==0,结束程序
mrmovq 24(%rdi), %r10
rmmovq %r10, 24(%rsi)
andq %r10, %r10
jle Rcopy5
iaddq $1, %rax
Rcopy5:
iaddq $-1, %rdx
jl Done # rdx-1<0,说明rdx==0,结束程序
mrmovq 32(%rdi), %r10
rmmovq %r10, 32(%rsi)
andq %r10, %r10
jle Done
iaddq $1, %rax
##################################################################
# Do not modify the following section of code
# Function epilogue.
Done:
ret
##################################################################
# Keep the following label at the end of your function
End:
#/* $end ncopy-ys */
-
提前为下一步骤读取内存,更好利用cpu流水线特性
对于内存引用这个操作,下一步操作是不需要前一步执行结束就可以进行操作的,
所以在前一步进行其他操作的同时,可以提前为下一步的内存引用做准备,从而提速
#/* $begin ncopy-ys */ ################################################################## # ncopy.ys - Copy a src block of len words to dst. # Return the number of positive words (>0) contained in src. # # Include your name and ID here. # # Describe how and why you modified the baseline code. # ################################################################## # Do not modify this portion # Function prologue. # %rdi = src, %rsi = dst, %rdx = len ncopy: ################################################################## # You can modify this portion # Loop header xorq %rax,%rax # count = 0; iaddq $-6, %rdx jl Remain Loop: copy1: mrmovq (%rdi), %r10 mrmovq 8(%rdi), %r11 rmmovq %r10, (%rsi) andq %r10, %r10 jle copy2 iaddq $1, %rax copy2: rmmovq %r11, 8(%rsi) andq %r11, %r11 jle copy3 iaddq $1, %rax copy3: mrmovq 16(%rdi), %r10 mrmovq 24(%rdi), %r11 rmmovq %r10, 16(%rsi) andq %r10, %r10 jle copy4 iaddq $1, %rax copy4: rmmovq %r11, 24(%rsi) andq %r11, %r11 jle copy5 iaddq $1, %rax copy5: mrmovq 32(%rdi), %r10 mrmovq 40(%rdi), %r11 rmmovq %r10, 32(%rsi) andq %r10, %r10 jle copy6 iaddq $1, %rax copy6: rmmovq %r11, 40(%rsi) andq %r11, %r11 jle nLoop iaddq $1, %rax nLoop: iaddq $48, %rdi iaddq $48, %rsi iaddq $-6, %rdx jge Loop Remain: iaddq $6, %rdx je Done Rcopy1: iaddq $-1, %rdx jl Done # rdx-1<0,说明rdx==0,结束程序 mrmovq (%rdi), %r10 mrmovq 8(%rdi), %r11 rmmovq %r10, (%rsi) andq %r10, %r10 jle Rcopy2 iaddq $1, %rax Rcopy2: iaddq $-1, %rdx jl Done # rdx-1<0,说明rdx==0,结束程序 rmmovq %r11, 8(%rsi) andq %r11, %r11 jle Rcopy3 iaddq $1, %rax Rcopy3: iaddq $-1, %rdx jl Done # rdx-1<0,说明rdx==0,结束程序 mrmovq 16(%rdi), %r10 mrmovq 24(%rdi), %r11 rmmovq %r10, 16(%rsi) andq %r10, %r10 jle Rcopy4 iaddq $1, %rax Rcopy4: iaddq $-1, %rdx jl Done # rdx-1<0,说明rdx==0,结束程序 rmmovq %r11, 24(%rsi) andq %r11, %r11 jle Rcopy5 iaddq $1, %rax Rcopy5: iaddq $-1, %rdx jl Done # rdx-1<0,说明rdx==0,结束程序 mrmovq 32(%rdi), %r10 rmmovq %r10, 32(%rsi) andq %r10, %r10 jle Done iaddq $1, %rax ################################################################## # Do not modify the following section of code # Function epilogue. Done: ret ################################################################## # Keep the following label at the end of your function End: #/* $end ncopy-ys */CPE: 9.17-> 8.21
尝试为更多后续操作进行读内存操作,但是效果反而更差了
#/* $begin ncopy-ys */ ################################################################## # ncopy.ys - Copy a src block of len words to dst. # Return the number of positive words (>0) contained in src. # # Include your name and ID here. # # Describe how and why you modified the baseline code. # ################################################################## # Do not modify this portion # Function prologue. # %rdi = src, %rsi = dst, %rdx = len ncopy: ################################################################## # You can modify this portion # Loop header xorq %rax,%rax # count = 0; iaddq $-6, %rdx jl Remain Loop: copy1: mrmovq (%rdi), %r10 mrmovq 8(%rdi), %r11 mrmovq 16(%rdi), %r12 rmmovq %r10, (%rsi) andq %r10, %r10 jle copy2 iaddq $1, %rax copy2: rmmovq %r11, 8(%rsi) andq %r11, %r11 jle copy3 iaddq $1, %rax copy3: rmmovq %r12, 16(%rsi) andq %r12, %r12 jle copy4 iaddq $1, %rax copy4: mrmovq 24(%rdi), %r10 mrmovq 32(%rdi), %r11 mrmovq 40(%rdi), %r12 rmmovq %r10, 24(%rsi) andq %r10, %r10 jle copy5 iaddq $1, %rax copy5: rmmovq %r11, 32(%rsi) andq %r11, %r11 jle copy6 iaddq $1, %rax copy6: rmmovq %r12, 40(%rsi) andq %r12, %r12 jle nLoop iaddq $1, %rax nLoop: iaddq $48, %rdi iaddq $48, %rsi iaddq $-6, %rdx jge Loop Remain: iaddq $6, %rdx je Done Rcopy1: iaddq $-1, %rdx jl Done # rdx-1<0,说明rdx==0,结束程序 mrmovq (%rdi), %r10 mrmovq 8(%rdi), %r11 mrmovq 16(%rdi), %r12 rmmovq %r10, (%rsi) andq %r10, %r10 jle Rcopy2 iaddq $1, %rax Rcopy2: iaddq $-1, %rdx jl Done # rdx-1<0,说明rdx==0,结束程序 rmmovq %r11, 8(%rsi) andq %r11, %r11 jle Rcopy3 iaddq $1, %rax Rcopy3: iaddq $-1, %rdx jl Done # rdx-1<0,说明rdx==0,结束程序 rmmovq %r12, 16(%rsi) andq %r12, %r12 jle Rcopy4 iaddq $1, %rax Rcopy4: iaddq $-1, %rdx jl Done # rdx-1<0,说明rdx==0,结束程序 mrmovq 24(%rdi), %r10 mrmovq 32(%rdi), %r11 rmmovq %r10, 24(%rsi) andq %r10, %r10 jle Rcopy5 iaddq $1, %rax Rcopy5: iaddq $-1, %rdx jl Done # rdx-1<0,说明rdx==0,结束程序 rmmovq %r11, 32(%rsi) andq %r11, %r11 jle Done iaddq $1, %rax ################################################################## # Do not modify the following section of code # Function epilogue. Done: ret ################################################################## # Keep the following label at the end of your function End: #/* $end ncopy-ys */CPE: 8.21-> 8.24
-
减少无用操作
有人说rax初始值就是0,所以把
xorq %rax,%rax去除不会影响结果经尝试,结果确实正确,但是初始值这件事并没有找到确切依据
CPE: 8.21-> 8.14