Kubernetes 已经成为了云原生时代基础设施的事实标准,越来越多的应用系统在 Kubernetes 环境中运行。Kubernetes 已经依靠其强大的自动化运维能力解决了业务系统的大多数运行维护问题,然而还是要有一些状况是需要运维人员去手动处理的。那么和传统运维相比,面向 Kubernetes 解决业务运维问题是否有一些基本思路,是否可以借助其他工具简化排查流程,就是今天探讨的主题。
业务问题的范畴
首先有必要明确一点,什么样的问题算是 Kubernetes 领域的业务系统问题。Kubernetes 目前已经是云原生时代各类 “上云” 业务系统所处运行环境的事实标准。
我们假定你已经拥有了一套健壮的 Kubernetes 环境,业务系统的运行状态不会受到底层运行环境异常的影响,当业务系统出现问题时,Kubernetes 也可以正确的收集到业务系统的运行状态信息。
有了这假定条件之后,我们就可以将业务系统问题约束在业务从部署到正常运行起来这一时间区间内。所以本文探讨的业务系统问题的范畴包括:
- 业务系统的规格定义问题
- 业务系统的调度问题
- 业务系统长期运行中的问题
解决这类问题的意义
解决这一类的问题的意义是显而易见的,因为将业务系统运行起来是一种最基础的需求。具备一套健壮的 Kubernetes 运行环境或者是编写了一套业务系统代码都不会为我们产生直接的价值。只有将业务系统代码运行到一个稳定的环境中,面向最终用户提供服务时才会为我们产生真正的价值。
值得庆幸的是,解决这类问题多半只需要我们踩一次坑。对于大多数全新的业务系统而言,部署到 Kubernetes 环境中去时,所可能遭遇的问题只需要被处理一次。一旦部署完成,业务系统就可以专注于迭代功能,不断循环完成发布过程即可,顺利进入了一个循环往复的 CI/CD 流程之中。
除去基础需求这一显而易见的意义,我们也会探讨如何降低解决这类问题的难度,解决问题难度的降低本身也具有意义。云原生时代,我们倡导每个开发人员都能够掌控自己的业务系统,这种掌控也对开发人员提出了新的要求,即掌控 Kubernetes 的使用。这有点将运维层面的工作附加给开发人员的意思,实际推广过程并不顺利。为了便于开发人员使用 Kubernetes 来部署与调试自己开发的业务系统,企业可以选择云原生应用平台来降低开发人员使用 Kubernetes 的门槛,Rainbond 就是这样一款云原生应用管理平台,其易用性的特点降低了开发人员的学习门槛,同时能够为业务系统赋能。
从一份yaml开始
正常情况下,负责部署业务系统的工作人员是通过声明式的配置文件来定义业务系统的,其中的关键部分称之为规约(Spec)。这些规约字段通过格式严苛的 Yaml 类型配置文件来定义,正确填写其中的键与值需要庞杂的 Kubernetes 知识的保障。而掌握配置文件的格式,以及配置中的内容,往往是开发人员学习原生 Kubernetes 的首个陡峭门槛。
原生的使用方式中,kubectl 命令行工具会为这些配置文件提供严苛的校验机制,然而在校验无法通过时,能够给出的提示却并不是很友好。
以一份非常简单的 Yaml 配置文件为例:
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: my-nginx
name: my-nginx
namespace: default
spec:
replicas: 1
selector:
matchLabels:
app: my-nginx
template:
metadata:
labels:
app: my-nginx
spec:
containers:
- image: nginx
name: nginx
env:
- name: DEMO_GREETING
value: "true" # 此处必须用引号扩起来,因为这是个 string 类型
securityContext:
privileged: true # 此处必须不能使用引号,因为这是个 bool 类型
配置中有两个 true 值,然而其中一个必须使用引号,而另一个则不是,这对一些新手而言并不是很友好。而加载这份配置文件的错误版本时,系统给出的报错虽然可以定位问题,但是交互体验更加不友好。
$ kubectl apply -f my-deployment.yaml
Error from server (BadRequest): error when creating "my-deployment.yaml": Deployment in version "v1" cannot be handled as a Deployment: v1.Deployment.Spec: v1.DeploymentSpec.Template: v1.PodTemplateSpec.Spec: v1.PodSpec.Containers: []v1.Container: v1.Container.Env: []v1.EnvVar: v1.EnvVar.Value: ReadString: expects " or n, but found t, error found in #10 byte of ...|,"value":true}],"ima|..., bigger context ...|ainers":[{"env":[{"name":"DEMO_GREETING","value":true}],"image":"nginx","name":"nginx"}]}}}}
像这样的问题,在类似 Rainbond 这样的云原生应用管理平台中,则不会出现。产品设计之时,就已经屏蔽了一些常见输入错误,用户不需要关注传入值的类型问题,平台会自行进行转换。
平台会自动为环境变量添加引号以匹配 string 类型:

以开启/关闭来体现 bool 类型:

对于一些特殊输入,也会进行合理校验,提供的反馈信息更加人性化:

借助这些功能,即使是小白用户也可以正确的定义业务系统的规格。
调度过程中的问题排查
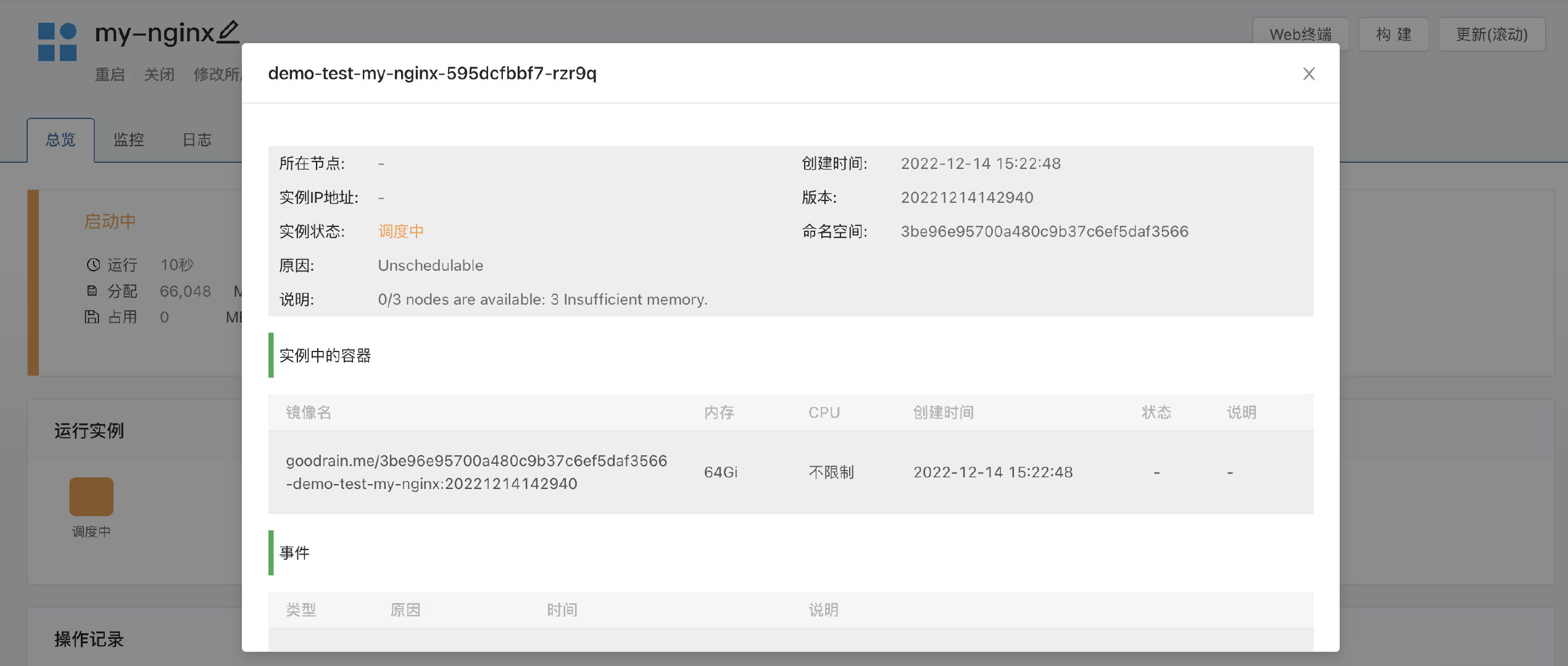
业务系统的规格定义完成后,就可以提交给 Kubernetes 系统了,下一步,Kubernetes 将会借助自身调度机制,将业务系统分配到合适的宿主机上运行起来。在进行调度的过程中,业务系统会在一小段时间内处于 Pending(待定的) 的状态,然而长期处于 Pending 状态则说明调度过程中出现了问题。
Kubernetes 以事件的形式,记录了业务系统在进入运行状态之前的每一个步骤。一旦出现了 Warning 甚至更严重级别的事件时,就说明业务系统的部署过程受阻了。了解如何查看这些事件,并理解其背后代表的意义,对于排查调度问题非常有帮助。
能够让业务系统长期处于 Pending 状态的常见问题包括:镜像拉取失败、资源不足等。使用原生 Kubernetes 时,难免和命令行打交道,来获取对应 Pod 的事件信息。
$ kubectl describe pod <podName> -n <nameSpace>
当所有的计算节点都没有足够的内存资源来调度业务系统的 Pod 时,事件信息是这样的:
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedScheduling <unknown> default-scheduler 0/3 nodes are available: 3 Insufficient memory.
而拉取镜像失败则是这样的:
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning Failed 26s kubelet, cn-shanghai.10.10.10.25 Error: ErrImagePull
Normal BackOff 26s kubelet, cn-shanghai.10.10.10.25 Back-off pulling image "nginx_error"
Warning Failed 26s kubelet, cn-shanghai.10.10.10.25 Error: ImagePullBackOff
Normal Pulling 15s (x2 over 29s) kubelet, cn-shanghai.10.10.10.25 Pulling image "nginx_error"
对事件列表的解读,是需要较深厚的 Kubernetes 领域知识的。开发者需要从事件列表中找到关键词,进而采取正确的行动来解决问题。
在 Rainbond 云原生应用管理平台中,已经事先想到了降低问题排查成本的需求,用户点击代表有问题的业务系统 Pod 的方块,即可了解其详细信息。在这个页面中,浓缩了核心问题的说明、当前 Pod 的状态以及说明,可以帮助用户极快的定位问题。
运行过程中的问题排查
当业务系统完成了调度过程后,Kubernetes 系统就会将业务系统对应的 Pod 启动起来,到这里,已经距离业务系统对外提供服务很近了。但是不要掉以轻心,Pod 启动时是有可能遭遇运行异常的。
一般情况下,正常运行中的 Pod 是体现 Running 状态的,开发人员可以通过命令行的方式获取其状态:
$ kubectl get pod <podName> -n <nameSpace>
但是如果处于异常状态,则可能得到以下结果:
NAME READY STATUS RESTARTS AGE
demo-test-my-nginx-6b78f5fc8-f9rkz 0/1 CrashLoopBackOff 3 86s
CrashLoopBackOff 是一种异常的状态,除此之外还可能出现一些其他的异常状态,比如:OOMkilled 、 Evicted等。对于每一种错误类型的处理也不尽相同。这需要非常丰富的 Kubernetes 问题排查经验。
比如对于 CrashLoopBackOff 这种异常状态,它意味着 Pod 中的某个容器无法正常运行,代码运行过程中遭遇了不可容忍的问题,报错退出了。正确的处理,是应该查询问题 Pod 的日志,了解业务代码层面的异常。
$ kubectl logs -f <podName> -n <nameSpace>
这种排查的思路是可以固化的,与所部署的业务系统本身没有关系,所以 Rainbond 云原生应用管理平台做了一些人性化的设计,如果业务系统的 Pod 处于这种异常状态并被操作记录捕获,那么用户点击这条异常的操作记录,即可直接跳转到日志页面查看问题日志。这种设计隐式的为用户提供了排查思路,即使用户自己并没有意识到应该这么做。

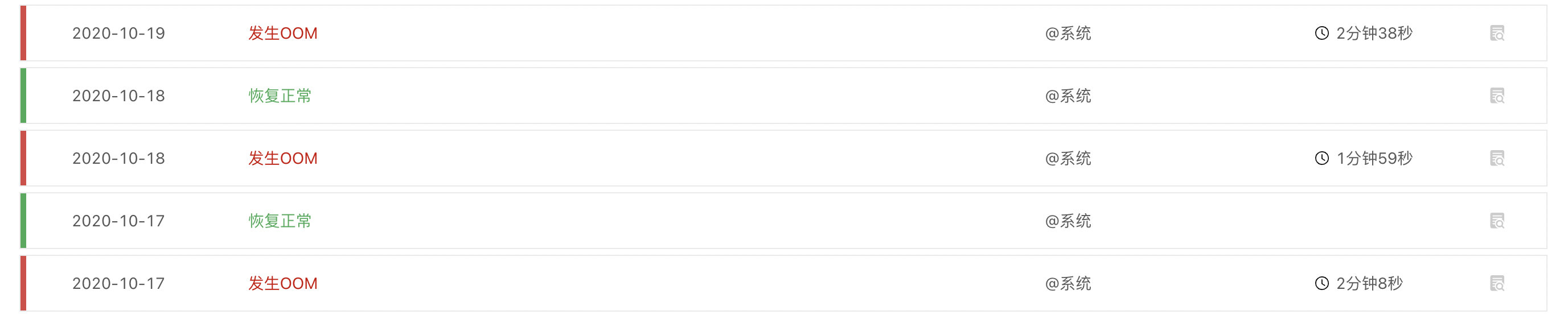
还有一种特殊类型的运行过程中问题需要注意。 CrashLoopBackOff 这种问题一般出现在 Pod 启动时,用户很容易就可以捕捉到,而类似于 OOMkilled 这种问题一般是在业务系统运行很久之后,才会出现。这种问题不容易被用户捕捉到,这是因为 Kubernetes 会自动重启出现这类问题的业务系统 Pod 来自动恢复,从而导致问题的湮没。
Rainbond 云原生应用管理平台会自动记录这一类异常状态,并留下相应日志供后续的分析,了解到到底是 Pod 中的哪个容器导致了内存泄露。
写在最后
基于原生 Kubernetes 进行业务系统的各阶段问题排查,需要开发人员对 Kubernetes 知识体系有较深入的了解,并且能够接受命令行交互式操作体验。这无形中提升了对开发人员的技术要求,也对其强加了一些运维领域的工作内容,使云原生落地体验受阻。开发人员也不应该拿到可以直接操作 Kubernetes 的命令行权限,这不符合安全规定。
为了能够让开发人员合理的调试业务系统,选用一款云原生管理平台将会是个正确的选择。云原生应用管理平台的设计者,深入了解过开发人员的诉求,通过为开发人员提供简单易用的功能,以及人性化的设计,让开发人员调试业务系统变得事半功倍。
标签:原生,Kubernetes,开发人员,系统,业务,Rainbond,排查,Pod From: https://www.cnblogs.com/rainbond/p/17245362.html