链表知识点总结
链表简介
链表:是由一种一个或多个指针域和数据域组成的特殊数据结构

链表类型
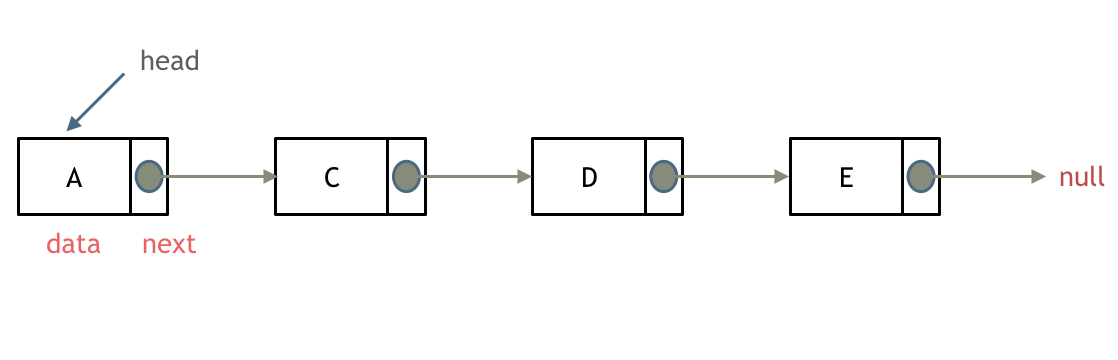
单链表
单链表中的指针域指向下一个节点
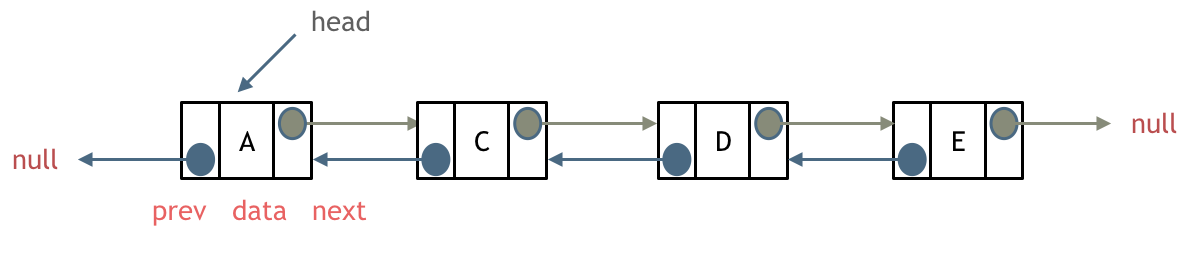
双链表
双链表中有两个指针域,一个指向前一个节点,还有一个指向后一个节点
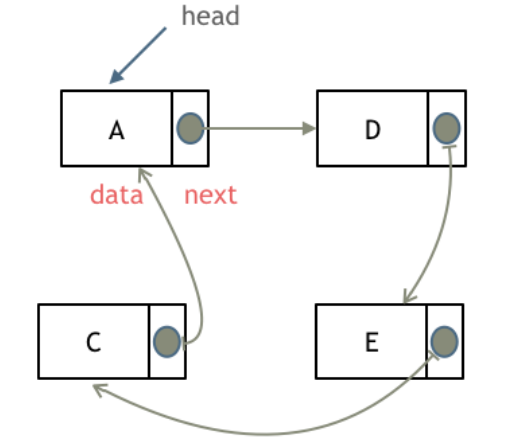
循环链表
循环链表结构如字面上的意思,链表首尾相接
链表存取方式
链表和数组不同,数组在内存中的存储方式是连续的,链表在内存中的存储方式是不连续的,链表通过指针就可以找到链表的其它节点,因此,链表在删除方面较数组有更大的优势和进步
链表重要概念
首元结点
就是链表中存储第一个数据元素的结点
头结点
它是在首元节点之前附设的一个结点,其指针域指向首元节点。头结点的数据域可以不存储任何信息,也可以存储与数据元素类型的其他附加信息
头指针
它是指向链表中的第一个结点的指针。若链表设有头结点,则头指针所指结点为线性表的头结点,若链表不设头结点,则头指针所指结点为该链表的首元节点

设有头结点:

不设置头结点:

优点
- 增加了头结点后,首元节点的地址保存在头结点的指针域中,则对于链表的第一个元素的操作就与其他元素相同,不需要进行特殊处理
- 便于空表的和非空表的统一处理;当链表不设头结点时,假设L为单链表的头指针,它应该指向首元节点,则当单链表为长度n为0的空表时,L指针为空 (判断空表的条件可记为: L == NULL)
链表的定义
首先,来定义一个简单的单链表
// 单链表
struct ListNode {
int val; // 数据域
ListNode *next; // 指针域
ListNode(int x) : val(x), next(NULL) {} //结点构造函数 可以定义也可以不定义
}
如果没有定义构造函数,那么使用默认的构造函数初始化的时候就不能够赋值
ListNode* head = new ListNode(1);
----
ListNode* _head = new ListNode();
_head->val = 1;
链表的操作
删除结点
删除给出的结点
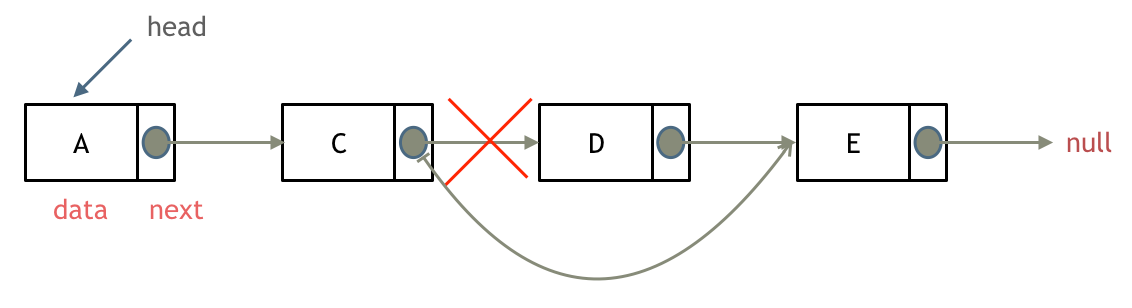
只需要通过修改C结点的指针域就可以删除掉D结点,因为在C/C++中没有内存回收机制,所以需要自己手动释放内存,在Python,Java中不需要这样的操作。
代码操作
struct ListNode {
int val;
ListNode *next;
ListNode(int x) : val(x), next(NULL){} //构造函数
}
/*
给一个链表
head = [1, 2, 3, 4, 5]
val = 4
*/
// 定义一个头结点
ListNode* dummyHead = new ListNode(0);
dummyHead->next = head;
ListNode* cur = dummyHead; // 头指针
// 删除结点
while (cur->next != NULL){
if (cur->next->val == val) {
ListNode* tmp = cur->next;
cur->next = cur->next->next;
delete tmp;
} else {
cur = cur->next;
}
}
head = dummyHead->next;
delete dummyHead;
return head;
添加结点
在原有基础上添加一个结点
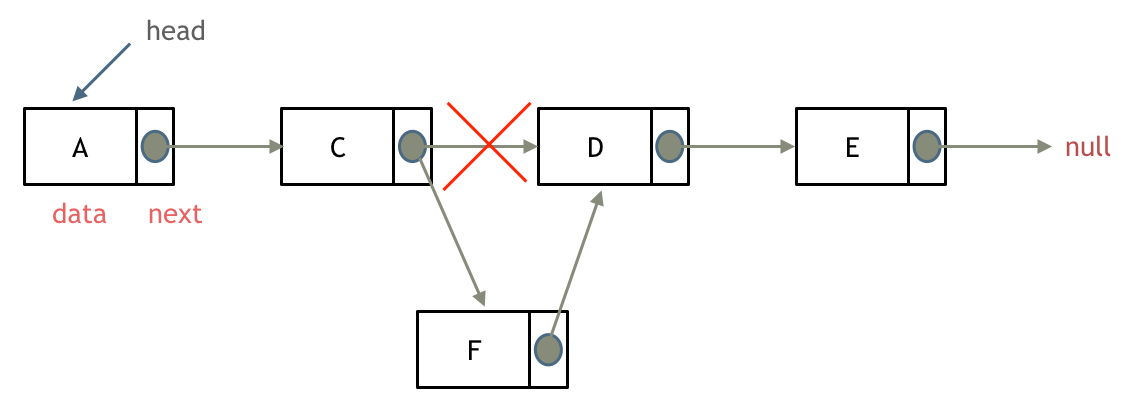
链表在删除和添加上面有天生的优势,可以看到在删除和添加上都只是O(1)的操作,也不影响其他结点
链表和数组的比较
| 插入/删除(时间复杂度) | 查询(时间复杂度) | 适用场景 | |
|---|---|---|---|
| 数组 | O(n) | O(1) | 数据量固定,查询较多,较少增删 |
| 链表 | O(1) | O(n) | 数据量不固定,增删较多,较少查询 |