0307-0314
1.模块的简介
# 1.定义:一系列功能的集合
# 2.作用:拿来主义,极大提高开发效率
# 3.来源:
1.内置:# python解释器自带的,直接拿来使用的
2.第三方:# 别人写的,如果想用,就要先下载在使用
3.自定义:# 我们自己写的
# 4.存在形式:
1.我们自己写的py文件(一个py文件就是一个模块)
2.包:一系列py文件的集合(文件夹)# 一个包里面会有一个__init__.py文件
"""
以后在写一个复杂项目的功能时候,要先考虑有没有被人已经写好的模块,我们直接拿来使用
"""
2.import句式
# 在学习模块的时候,要区分开谁是执行文件,谁是导入文件
import md # 导入模块的时候,文件名后缀不能加
"""
23种设计模式:单例模式。
在导入模块的时候,只有第一次会执行,其他的都不会执行"""
# 首次导入模块发生了什么事情?
1.运行执行文件,产生执行文件的全局名称空间
2.运行导入文件
3.产生导入文件的全局名称空间,并把导入文件中产生的名字都保存到导入文件的全局名称空间中
4.在执行文件中,产生一个md的名字指向导入文件的全局名称空间
''' 一旦你使用了import句式之后,我们就可以通过句点符的形式找到导入文件中得名字'''
3.from...import... 句式
"""
首次导入只会执行一次,只会的导入都不在执行
1. 运行执行文件,产生执行文件的全局名称空间
2. 运行md.py文件
3. 产生导入文件的全局名称空间,把运行之后产生的名字都保存到导入文件的全局名称空间中
4. 在执行文件中,产生一个名字money指向导入文件中得money值
"""
#from...import...句式是指名道姓地导入,当导入文件和执行文件中出现相同的名字,此时会产生冲突,就会使用当前执行文件中的名字
4.导入方法的扩展用法
# 1.起别名
import 模块名 as 新名字
from 模块名 import 名字 as 新名字
import mddddddddddddddddddddddddddddddddddddddd as md
print(mddddddddddddddddddddddddddddddddddddddd.name)
from mddddddddddddddddddddddddddddddddddddddd import namenamenamenamenamenamenamenamenamenamenamename as name
# 2.连续导入
import 模块名1,模块名2,模块名3,模块名4 #推荐还是分开写好一些
import time
import md
import os
import sys
import time, md, os, sys # 等价于上面4行代码
import 模块名1, 模块名2, 模块名3, 模块名4, 模块名
# 3.通用导入
from 模块 import * 可配合__all__ =['变量名','变量名']
__all__限制当前文件中哪些名字可以被导入(是写在导入文件里)
'''导入句式都写在文件开头'''
5.判断文件类型
# 判断当前文件是执行文件还是导入文件
__name__在不同的文件中,结果是不一样的,在执行文件中,结果是__main__,str,
在导入文件中,结果是模块名,str[直接输入main]
6.循环导入
# 1.循环导入的现象在实际工作中,坚决不能出现
# 2.如果你的程序出现了循环导入,说明你的程序设计不合理
7.模块的查找顺序[重点]
# 1.先从内存中查找
# 2.再从内置模块中查找
一定要注意以后的文件名命名坚决不能跟内置模块名重名
# 3.从环境变量中查找sys.path[重要]
sys.path中的第一个路径永远是当前文件所在的路径
以列表的形式返回
# 4.当查找模块找不到的时候,该如何解决?
1.把模块所在的路径添加到环境变量中
import sys
sys.path.append('')
2.from 模块名1.模块名2 import 模块名3
8.绝对导入和相对导入
# 绝对导入:始终以执行文件的环境变量sys.path为基准
# 相对导入:打破了以执行文件所在的路径为基准的原则,只考虑2个文件间的位置
'''
1.程序中多个模块之间导入的时候,始终以执行文件所在的路径为基准
2.当文件中出现了相对导入的句式,该文件只能被当成导入文件使用
3.相对导入的句式需要用到句点符[.];.代表当前路径,..代表上层路径
'''
9.包
# 1.什么是包?
包是一系列模块的集合体,本质上就是文件夹,与普通文件夹又微小区别,包里又一个__init__.py的文件
# 2.导包的时候发生了什么事?
1.运行执行文件,产生执行文件的全局名称空间
2.运行__init__.py文件,该文件的名字保存在包下的名称空间中
3.在执行文件中产生一个包名字指向包的全局名称空间
'''本质:导包就是导__init__.py'''
10.软件开发目录规范
# 1.bin
一般存放启动文件,当启动文件只有一个时也可以放在文件夹外:run.py start.py
# 2.db
databases数据库,一般存放数据相关文件:db_handle.py
# 3.confi
config配置,一般放配置文件(默认数据,可被更改),里面的变量一般都是大写,HOST = '127.0.0.1':settings.py
# 4.lib
library库,存放公共的文件,如装饰器:common.py
# 5.core/api
核心的,一般写项目的核心逻辑:src.py
# 6.README
一般写说明性的信息,介绍项目用
'''http://github.com'''
11.常用模块[正则表达式]
# 1.正则表达式跟任何一门语言都没有关系,它是一门独立的语言
# 2.定义:利用一些特殊符号来筛选出我们想要的数据
# 3.在python中,如果想使用正则表达式,需要使用re模块
# 4.字符组
1.[0123456789]即[0-9] #匹配0-9数字
2.[A-Z] #匹配A-Z之间任意一个字符
3.[a-z] #匹配a-z之间任意一个字符
4.[0-9a-fA-F] #匹配0-9 a-f A-F之间任意一个字符
# 5.字符
1.\d #匹配0-9
2.\D #取反
3.\w #匹配任意数字、字母、下划线
4.\W #取反
5.\^ #匹配字符串开头
6.\$ #匹配字符串结尾
7.. #匹配除换行符外任意一个字符
8.a|b #匹配字符a或b
9.() #分组
10.[...] #匹配[]中任意一个字符
11.[^...] #匹配除[]内任意字符,取反
# 6.量词
'''1.不可以单独使用,需要搭配表达式 2.只影响前面一个字符'''
1.* #重复0次或更多次
2.+ #重复1次或更多次
3.? #重复0次或1次
4.{n} #重复n次
5.{n,} #重复n次或更多次
6.{n,m} #重复n到m次
# 7.贪婪匹配和非贪婪匹配
1.贪婪匹配:.*
2.非贪婪匹配:.*?
'''取消贪婪匹配:在贪婪匹配后面加一个问号,即尽可能得少匹配'''
# 8.取消转义
1.正则中匹配正常的字符串''\n''而不是换行符就需要对''\''进行转义,变成''\\''
2.因为字符串中\也有特殊的含义,本身还需要转义,如果匹配一次''\n'',字符串中要写成''\\n'',那么正则里就要写成''\\\\n'',非常麻烦
3.我们就用到了r''\n''这个概念,此时的正则是r''\\n''即可
# 9.小作业
'''^[1-9]\d{13,16}[0-9x]$
首位是1-9中的一位,中间是13位-16位0-9的数字,最后一位是0-9以及x中的一个
'''
'''^[1-9]\d{14}(\d{2}[0-9x])?$
首位是1-9中的一位,中间是14位的0-9的数字,末尾有或者没有0-9以及x中的一个
'''
'''^([1-9]\d{16}[0-9x]|[1-9]\d{14})$
首位是1-9中的一位,末尾是16位的0-9或者x,或者是1位1-9的数字以及末尾是14位的0-9的数字
12.re模块
# 1.re = regular express = regxp
# 2.方法
1.re.findall(pattern,str,默认参数=0)
如果匹配到了,以列表的形式返回匹配到的结果;如果匹配不到返回空列表[]不报错
2.re.search(pattern,str,默认参数=0)
不能直接返回结果需要使用group方法,如果匹配不到返回None,使用group会报错;解决的办法有2个,一是使用异 常捕捉,二是使用if re.search(): else:(有结果走上面,无结果走下面)
3.re.match(pattern,str,默认参数=0)
同search,不过只在字符串开始处进行匹配
# 3.正则分组
1.无名分组:group(索引),分组取值是按照索引取值,索引从1开始;findall方法时分组优先展示,列表里面套元组,取消优先展示的方法是?:
2.有名分组:?P<name>,注意取名后依然可以索引取值
# 4.小作业
# 匹配标签
ret = re.search(r"<(\w+)>\w+</\1>","<h1>hello</h1>")
print(ret.group(1))
# 匹配整数
ret=re.findall(r"-?\d+\.\d*|(-?\d+)","1-2*(60+(-40.35/5)-(-4*3))")
# -?表示前面可以有一个可选的减号
# \d+表示一到多个数字,(-?\d+)这个表示整数部分
# \.\d*表示一个小数点跟多个数字,这部分匹配一个可选的小数部分
# 结果不含小数是因为用的是findall方法,当有括号时优先展示括号内的
print(ret)
# 数字匹配
# 分别取出1年的12个月
res = re.search('^(0?\d|1[0-2])$','10')
print(res.group())
# 一个月的31天
res = re.search('^(0?\d|[1-2]\d|3[0-1])$','30')
res = re.search('^([0-3][0-1])$','30')
print(res.group())
#匹配一个浮点数
res = re.search('-?\d+\.?\d+','-30.45')
print(res.group())
# 匹配出所有整数
res = re.search('-?\d+','30')
print(res.group())
13.爬取红牛官网数据
# 思路
1.将源代码CV进一个txt文档中
2.f.read()一次性读完文件
3.re.findall()得到所需数据;注意用pattern将代码写活
4.小作业,爬取豆瓣电影
with open('douban_movies.txt','r',encoding='utf-8') as f1:
data = f1.read()
movie_name = re.findall('alt="(.*?)"',data)
movie_review = re.findall('<span class="inq">(.*?)</span>',data)
movie_year = re.findall('<br>\n\s*(.*?)&',data)
movie_rating = re.findall('property="v:average">(.*?)</span>',data)
lst =list(zip(movie_name,movie_year,movie_review,movie_rating))
for i in lst:
print('''
电影:%s
年份:%s
评语:%s
评分:%s
''' % (i[0],i[1],i[2],i[3]))
14.time模块
# 1.就是处理时间相关的模块
# 2.时间的三种格式
2.1 timestamp
2.2 struct_time
2.3 format string
# 3.使用方法
1.time.sleep(secs) #(线程)推迟指定的时间运行。单位为秒。
2.time.time() #获取当前时间戳
3.time.gmtime(时间戳) #UTC时间,与英国伦敦当地时间一致
>>>time.gmtime(1500000000)
time.struct_time(tm_year=2017, tm_mon=7, tm_mday=14, tm_hour=2, tm_min=40, tm_sec=0, tm_wday=4, tm_yday=195, tm_isdst=0)
4.time.localtime(时间戳) #当地时间
>>>time.localtime(1500000000)
time.struct_time(tm_year=2017, tm_mon=7, tm_mday=14, tm_hour=10, tm_min=40, tm_sec=0, tm_wday=4, tm_yday=195, tm_isdst=0)
5.time.mktime(结构化时间)
>>>time_tuple = time.localtime(1500000000)
>>>time.mktime(time_tuple)
1500000000.0
6.time.strftime("格式定义","结构化时间") 结构化时间参数若不传,则显示当前时间
>>>time.strftime("%Y-%m-%d %X")
'2017-07-24 14:55:36'
>>>time.strftime("%Y-%m-%d",time.localtime(1500000000))
'2017-07-14'
7.time.strptime(时间字符串,字符串对应格式)
>>>time.strptime("2017-03-16","%Y-%m-%d")
time.struct_time(tm_year=2017, tm_mon=3, tm_mday=16, tm_hour=0, tm_min=0, tm_sec=0, tm_wday=3, tm_yday=75, tm_isdst=-1)
8.time.asctime(结构化时间) 如果不传参数,直接返回当前时间的格式化串
>>>time.asctime(time.localtime(1500000000))
'Fri Jul 14 10:40:00 2017'
>>>time.asctime()
'Mon Jul 24 15:18:33 2017'
9.time.ctime(时间戳) 如果不传参数,直接返回当前时间的格式化串
>>>time.ctime()
'Mon Jul 24 15:19:07 2017'
>>>time.ctime(1500000000)
'Fri Jul 14 10:40:00 2017'
15.datetime模块
datetime.date.today() # 年月日
datetime.datetime.today() # 年月日时分秒
# 无论是年月日,还是年月日时分秒对象都可以调用以下方法获取针对性的数据
# 以datetime对象举例
print(now_time.year) # 获取年份2019
print(now_time.month) # 获取月份7
print(now_time.day) # 获取日1
print(now_time.weekday()) # 获取星期(weekday星期是0-6) 0表示周一
print(now_time.isoweekday()) # 获取星期(weekday星期是1-7) 1表示周一
timedelta对象
# 可以对时间进行运算操作
# 获得本地日期 年月日
tday = datetime.date.today()
# 定义操作时间 day=7 也就是可以对另一个时间对象加7天或者减少7点
tdelta = datetime.timedelta(days=7)
# 打印今天的日期
print('今天的日期:{}'.format(tday)) # 2019-07-01
# 打印七天后的日期
print('从今天向后推7天:{}'.format(tday + tdelta)) # 2019-07-08
# 总结:日期对象与timedelta之间的关系
"""
日期对象 = 日期对象 +/- timedelta对象
timedelta对象 = 日期对象 +/- 日期对象
"""
16.random模块
# 1.随机小数
>>> random.random() # 大于0且小于1之间的小数
0.7664338663654585
>>> random.uniform(1,3) #大于1小于3的小数,也可填float
1.6270147180533838
# 2.随机整数
>>> random.randint(1,5) # 大于等于1且小于等于5之间的整数
>>> random.randrange(1,10,2) # 大于等于1且小于10之间的奇数,顾头不顾尾
# 3.随机选择一个返回
>>> random.choice([1,'23',[4,5]]) # #1或者23或者[4,5]
# 4.随机选择多个返回,返回的个数为函数的第二个参数
>>> random.sample([1,'23',[4,5]],2) # #列表元素任意2个组合
[[4, 5], '23']
# 5.打乱列表顺序
>>> item=[1,3,5,7,9]
>>> random.shuffle(item) # 打乱次序,没有返回值
>>> item
[5, 1, 3, 7, 9]
>>> random.shuffle(item)
>>> item
[5, 9, 7, 1, 3]
# 6.随机6位验证码
def my_fun(n):
code = ''
for i in range(n):
my_int = str(random.randint(0, 9))
my_abc = chr(random.randint(97, 122))
my_ABC = chr(random.randint(65, 90))
my_choice = random.choice([my_int, my_ABC, my_abc])
# print(my_choice,end = '')
code += my_choice
return code
17.os模块
# 1.对文件或目录的名字增删改查,没有创建文件的方法
os.makedirs('dirname1/dirname2') #可生成多层递归目录
os.removedirs('dirname1') #若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推
os.mkdir('dirname') #生成单级目录;相当于shell中mkdir dirname
os.rmdir('dirname') #删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname
os.listdir('dirname') # 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印
os.remove() #删除一个文件
os.rename("oldname","newname") #重命名文件/目录,可以移动文件
os.stat('path/filename') #获取文件/目录信息
# 2.路径的查找和更改
os.system("bash command") 运行shell命令,直接显示,跟在cmd里面智勋哥结果一样,有乱码
os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径
os.chdir("dirname") 改变当前脚本工作目录;相当于shell下cd,注意cd是跳转到其他文件夹,这里是更改工作路径
# 3.os.path
os.path.abspath(path) 返回path规范化的绝对路径os.path.split(path) 将path分割成目录和文件名二元组返回
os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素
os.path.basename(path) 返回path最后的文件名。如果path以/或\结尾,那么就会返回空值。即os.path.split(path)的第二个元素
os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False
os.path.isabs(path) 如果path是绝对路径,返回True
os.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回False
os.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回False
os.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略
os.path.getsize(path) 返回path的大小,返回的是字节数,可以判断文件是否为空
'''shell命令没学,不用管'''
# 4.小练习:将同一个文件夹里的所有子文件夹里的带有mask的png图片转移到另一个文件夹中
src_path = r'D:\python笔记\JSON2png'
target = r'D:\python笔记\JSON2png\tongyi\mask'
for root, dirs, files in os.walk(src_path):
# 获取文件中各个文件名
for file in files:
# 判断文件后缀是否为mask.png
if file.endswith('_mask.png') :
# 获取源文件绝对路径
abs_path = os.path.join(root, file)
# 移动文件
os.rename(abs_path, target+r'\\'+file)
'''os.walk用法如下'''
os.walk()主要用来扫描某个指定目录下所包含的子目录和文件。这篇文章将通过几个简单的例子来说明python中os.walk()的使用方法。
假设我们的test文件夹有如下的目录结构:
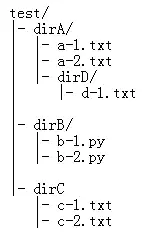
我们首先用os.walk扫描test文件夹下所有的子目录和文件:
# 使用os.walk扫描目录
import os
for curDir, dirs, files in os.walk("test"):
print("====================")
print("现在的目录:" + curDir)
print("该目录下包含的子目录:" + str(dirs))
print("该目录下包含的文件:" + str(files))
输出结果:

上面的代码在扫描子目录和文件的时候,是采用自顶向下的方式进行扫描。如果想要自底向上地扫描子目录和文件,可以添加上topdown=False参数:
# 使用os.walk自底向上扫描目录
import os
for curDir, dirs, files in os.walk("test", topdown=False):
print("====================")
print("现在的目录:" + curDir)
print("该目录下包含的子目录:" + str(dirs))
print("该目录下包含的文件:" + str(files))
输出结果:

我们还可以利用os.walk输出test文件夹下所有的文件:
# 使用os.walk输出某个目录下的所有文件
import os
for curDir, dirs, files in os.walk("test"):
for file in files:
print(os.path.join(curDir, file))
输出结果:

也可以利用os.walk输出test文件夹下指定后缀名(比如.txt)文件:
# 使用os.walk输出某个特定后缀(比如.txt)的文件
import os
for curDir, dirs, files in os.walk("test"):
for file in files:
if file.endswith(".txt"):
print(os.path.join(curDir, file))
输出结果:

同样地,我们也可以利用os.walk输出test文件夹下所有的子目录(子文件夹):
# 使用os.walk输出所有的目录
import os
for curDir, dirs, files in os.walk("test"):
for dir in dirs:
print(dir)
输出结果:

https://zhuanlan.zhihu.com/p/149824829
18.sys模块
# sys模块是与python解释器交互的一个接口
sys.argv #命令行参数List,第一个元素是程序本身路径
print(sys.argv) #默认是该脚本绝对路径,可以在外部执行命令和传参
pyhton36 文件名 aaa bbb # >>>[文件名,'aaa','bbb']
print(sys.argv[1])# >>>aaa
print(sys.argv[2])# >>>bbb
try :
username = sys.argv[1]
password = sys.argv[2]
if username == '' and password == '':
pring('bingo')
else:
print('sorry')
except Exception:
print('')
sys.version #获取Python解释程序的版本信息
print(sys.version)>>>3.6.8
sys.path #返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值
print(sys.path)
sys.platform #返回操作系统平台名称
print(sys.platform)#>>>win32 (str)
19.序列化模块[json、pickle]
# 1.序列:字符串 序列化:把其他数据类型转为字符串的过程 反序列化:把字符串转化为其他数据类型的过程
'''可以直接写入文件的类型:1.字符串 2.二进制'''
# 2.json格式数据:目前为止所有编程语言都认识json格式,实现了跨语言传输数据
dumps() 序列化
loads() 反序列化
d = {'username':'kevin','age':19}
res = jaon.dumps(d)
res1 = json.loads(res)
print (res,type(res)) # {''username'':''kevin'',''age'':19} Json格式字符串'' ''
print(res1,type(res1)) #dict
# 把字典写入文件,并且读出来的时候也是字典
with open('a.txt','w',encoding='utf-8') as f:
f.write(json.dumps(d))
with open('a.txt','r',encoding='utf-8') as f:
data = json.loads(f.read())
print(data)
# json.loads的一个小用法
1.不同语言之间数据传输,要通过网络进行,网络传输需要的数据类型是二进制
res = b'{'username':'kevin','age':19}
2.把二进制转为json格式字符串
json_str = res.decode(res)
3.把json格式字符串转为字典
json_dict = json.loads(json_str)
dump()
load()
with open('a.txt','w',encoding='utf-8') as f:
json.dump(d,f) #1.先序列化 2.再写入文件
with open('a.txt','r',encoding='utf-8') as f:
json.load(f)
d = {'username':'kevin你好吗','age':19}
print(json.dumps(d)) #{"username": "kevin\u4f60\u597d\u5417", "age": 19}
\u是unicode万国码
print(json.dumps(d,ensure_ascii=False)) #{"username": "kevin你好吗", "age": 19}
'''哪些数据类型可以序列化'''
json.JSONEncoder #集合类型不能支持序列化
'''
json和pickle模块都支持dumps\loads\dump\load
1.pickle处理的数据只能在python中使用
2.pickle序列化之后的数据是二进制
3.pickle在python中可序列化所有类型
'''
import pickle
d = {'a':1}
print(pickle.dumps(d)) #b'\x80\x03}q\x00X\x01\x00\x00\x00aq\x01K\x01s.'
with open('a.txt','wb') as f:
pickle.dump(d,f)
20.练习题
# 把之前写的员工关系系统里面用户名和密码以字典格式写进去{'username':'kevin', 'password':123}
import os,json
temp_dic = {}
username = input('username:')
password = input ('password:')
temp_dic['username'] = username
temp_dic['password'] = password
path = username +'.txt'
with open(path,'w',encoding='utf-8') as f:
json.dump(temp_dic,f)
print('写入成功')
# 获取文件夹里所有文件名,输入相关序号得到相关文件内容
import os #执行文件与secret同级
abs_path =(os.path.dirname(os.path.abspath(__file__)))
print(abs_path)
target_lst = os.listdir(os.path.join(abs_path,'secret'))#读取文件夹所有文件
for index,filename in enumerate(target_lst):#打印输出文件列表
print(index+1,filename)
choice = int(input('请输入你的序号>>>:').strip())#让用户输入序号
if choice in range(1,len(target_lst)+1):#判断序号是否在合理区间
file_name = target_lst[choice-1]
path = os.path.join(abs_path,'secret',file_name)
with open(path,'r',encoding='utf-8') as f:
print(f.read())
else:
print('WWWWrong!')
21.subprocess模块
# windows系统默认的编码格式是:gbk
# 它是可以远程执行命令的
import subprocess
"""
1. 使用我们自己的电脑去链接别人的电脑 (socket模块)
"""
res=subprocess.Popen('tasklistaaa', shell=True,#实现了用python代码执行远程命令
stdout=subprocess.PIPE,
stderr=subprocess.PIPE
)
print(res) # <subprocess.Popen object at 0x000001ABB1970310>
print(res.stdout.read().decode('gbk')) # tasklist执行之后的正确结果返回
print(res.stderr.read().decode('gbk')) # 当命令不正确的时候,会把返回结果丢在stderr里面
22.hashlib模块
# 专门用来加密数据的,就是为了数据的安全才加密的
import hashlib
# 1. 先确定你要使用的加密方式: MD系列,SHA系列
md5 = hashlib.md5() # 指定加密方式
# 2. 进行明文数据的加密
data = '1234567890dfjkdfhsdjfhdskjfhsdjkfhddddddddddddddddddddddddddddddddds'
md5.update(data.encode('utf-8')) # 括号里面加密数据必须是字节类型,bytes类型
"""
1. 被加密的明文数据不管多长,得到的加密串的长度都是固定的
2. 针对md5数据,密文数据不能倒推出明文数据?
3. 数据加密时可以分开加密
4. 用户在写项目时,只要牵涉到用户注册与登录,都要加密
"""
# 3. 取出加密结果
print(md5.hexdigest())
# 4.加密方式的选择
"""
1. 被加密的数据,密文结果越长代表越难被破解,内部的加密算法越复杂,数据也更安全
被加密出来的结果越长,在发送数据的时候就会占用更多的资源
2. 如何选择加密方式
根据自己项目实际需求选择,一般情况下,md5足够了
"""
# 5.使用场景
以后我们做项目时,用户的密码都是密文保存这样1内部人员也看不到明文密码2数据被泄露也能保证数据的安全,归根结底就是为了保证数据的安全
# 6.加盐(干扰项)处理
6.1 固定加盐
1. 先确定你要使用的加密方式: md系列,sha系列
style = hashlib.md5() # 指定加密方式
2. 进行明文数据的加密
2.1 内部在给他添加一个干扰项
# random_str = '!@#$%^&dsfsdghdf432534!@#$%%'
# data = '123456'
# result = random_str + data
# md5.update(result.encode('utf-8'))
3.取出加密结果
# print(md5.hexdigest()) # eeb9bad681184779aa6570e402d6ef6c
6.2 动态加盐
1. 先确定你要使用的加密方式: md系列,sha系列
style = hashlib.md5() # 指定加密方式
2. 进行明文数据的加密
2.1 内部在给他添加一个干扰项
import s#定义一个随机6位数验证码的函数
random_str = s.get_code(6)
data = '123456'
result = random_str + data
style5.update(result.encode('utf-8'))
3. 取出加密结果
print(md5.hexdigest()) # eeb9bad681184779aa6570e402d6ef6c
# 7.实战案例
# 动态加盐
# username = input('username:')
# password = input('password:')
#
# import s
# # 明文密码改成密文密码
# md5 = hashlib.md5()
# random_str = s.get_code(6)
# new_str = random_str + password # 得到被加盐之后的新字符串
# md5.update(new_str.encode('utf-8'))
# new_password = md5.hexdigest() # 加密之后的结果
#
# res = '%s|%s|%s' % (username, new_password, random_str)
# with open('a.txt', 'w', encoding='utf-8') as f:
# f.write(res)
# 登录
username = input('username:')
password = input('password:') # 123456
# 判断用户名和密码是否正确
# 1. 先取出原来的用户名和密码
with open('a.txt', 'r', encoding='utf-8') as f:
real_username, real_password, random_s = f.read().split('|')
# real_password = e10adc3949ba59abbe56e057f20f883e
# 把用户输入的密码再次加密与文件中得密码进行对比,是否一样
md5 = hashlib.md5()
# new_str = 'hello'+password
new_str = random_s + password
md5.update(new_str.encode('utf-8'))
new_pwd = md5.hexdigest()
# 2. 用户新输入的用户名和密码进行比较
if username == real_username and new_pwd == real_password:
print('输入正确')
else:
print('输入错误')
23.logging模块
'''日志模块的学习,不需要记忆,直接CV'''
# 什么是日志?
日志就是记录你的代码在运行过程中产生的变化
# 日志的级别
'''根据日志级别的不同,选择性的记录'''
logging.debug('debug message') # 10
logging.info('info message') # 20
logging.warning('warning message') # 30
logging.error('error message') # 40
logging.critical('critical message') # 50
import logging
# 产生日志的
file_handler = logging.FileHandler(filename='x1.log', mode='a', encoding='utf-8',)
"""
2023-03-13 12:06:48 PM - root - ERROR -05 logging模块基本使用: 你好
"""
# 指定日志的格式
logging.basicConfig(
format='%(lineno)d - %(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s - %(pathname)s',
datefmt='%Y-%m-%d %H:%M:%S %p',
handlers=[file_handler,],
level=logging.ERROR
)
logging.error('你好') # 10
# 日志的组成部分
1.logger对象 #负责产生日志
2.filter对象 #过滤的
3.handler对象 #负责日志产生的位置
4.formatter对象 #负责产生的格式
# 日志详细使用
import logging
# 1.logger对象:负责产生日志
logger = logging.getLogger('转账记录')
# 2.filter对象:负责过滤日志(直接忽略)
# 3.handler对象:负责日志产生的位置
hd1 = logging.FileHandler('a1.log',encoding='utf8') # 产生到文件的
hd2 = logging.FileHandler('a2.log',encoding='utf8') # 产生到文件的
hd3 = logging.StreamHandler() # 产生在终端的
# 4.formatter对象:负责日志的格式
fm1 = logging.Formatter(
fmt='%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s',
datefmt='%Y-%m-%d %H:%M:%S %p',
)
fm2 = logging.Formatter(
fmt='%(asctime)s - %(name)s %(message)s',
datefmt='%Y-%m-%d',
)
# 5.绑定handler对象
logger.addHandler(hd1)
logger.addHandler(hd2)
logger.addHandler(hd3)
# 6.绑定formatter对象
hd1.setFormatter(fm1)
hd2.setFormatter(fm2)
hd3.setFormatter(fm1)
# 7.设置日志等级
logger.setLevel(30)
# 8.记录日志
logger.debug('写了半天 好累啊 好热啊')
# 配置成字典格式,当成配置文件使用
import logging
import logging.config
standard_format = '[%(asctime)s][%(threadName)s:%(thread)d][task_id:%(name)s][%(filename)s:%(lineno)d]' \
'[%(levelname)s][%(message)s]' #其中name为getlogger指定的名字
simple_format = '[%(levelname)s][%(asctime)s][%(filename)s:%(lineno)d]%(message)s'
test_format = '%(asctime)s] %(message)s'
logfile_path = 'a3.log'
# log配置字典
LOGGING_DIC = {
'version': 1,
'disable_existing_loggers': False,
'formatters': {
'standard': {
'format': standard_format
},
'simple': {
'format': simple_format
},
'test': {
'format': test_format
},
},
'filters': {}, # 过滤日志
'handlers': {
#打印到终端的日志
'console': {
'level': 'DEBUG',
'class': 'logging.StreamHandler', # 打印到屏幕
'formatter': 'simple'
},
#打印到文件的日志,收集info及以上的日志
'default': {
'level': 'DEBUG',
'class': 'logging.handlers.RotatingFileHandler', # 保存到文件
'formatter': 'standard',
'filename': logfile_path, # 日志文件
'maxBytes': 1024*1024*5, # 日志大小 5M
'backupCount': 5, #循环5个日志
'encoding': 'utf-8', # 日志文件的编码,再也不用担心中文log乱码了
},
'other': {
'level': 'DEBUG',
'class': 'logging.FileHandler', # 保存到文件
'formatter': 'test',
'filename': 'a2.log',
'encoding': 'utf-8',
},
},
'loggers': {
#logging.getLogger(__name__)拿到的logger配置 空字符串作为键 能够兼容所有的日志
'': {
'handlers': ['default', 'console'], # 这里把上面定义的两个handler都加上,即log数据既写入文件又打印到屏幕
'level': 'DEBUG',
'propagate': True, # 向上(更高level的logger)传递
}, # 当键不存在的情况下 (key设为空字符串)默认都会使用该k:v配置
'other': {
'handlers': ['other',],
'level': 'DEBUG',
'propagate': False,
},
},
}
# 使用配置字典
logging.config.dictConfig(LOGGING_DIC) # 自动加载字典中的配置
logger1 = logging.getLogger()
logger1.debug('好好的 不要浮躁 努力就有收获')
24.第三方模块下载和使用
# 图中
"""
清华源:
https://pypi.tuna.tsinghua.edu.cn/simple
阿里云源:
http://mirrors.aliyun.com/pypi/simple/
中科大源:
https://pypi.mirrors.ustc.edu.cn/simple/
豆瓣源:
http://pypi.douban.com/simple/
"""