让我们看看如何根据 Pandas DataFrame 中的某些条件选择行。
使用运算符根据特定列值选择行'>', '=', '=', '<=', '!=' 。
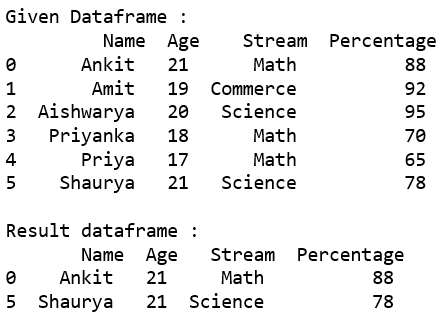
代码#1:使用基本方法从给定数据框中选择“百分比”大于 80 的所有行。
# importing pandas
import pandas as pd
record = {
'Name': ['Ankit', 'Amit', 'Aishwarya', 'Priyanka', 'Priya', 'Shaurya' ],
'Age': [21, 19, 20, 18, 17, 21],
'Stream': ['Math', 'Commerce', 'Science', 'Math', 'Math', 'Science'],
'Percentage': [88, 92, 95, 70, 65, 78] }
# create a dataframe
dataframe = pd.DataFrame(record, columns = ['Name', 'Age', 'Stream', 'Percentage'])
print("Given Dataframe :\n", dataframe)
# selecting rows based on condition
rslt_df = dataframe[dataframe['Percentage'] > 80]
print('\nResult dataframe :\n', rslt_df)
输出 :
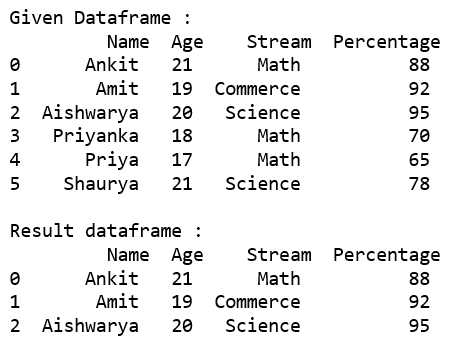
代码 #2 :使用 .从给定数据框中选择“百分比”大于 80 的所有行loc[]。
# importing pandas
import pandas as pd
record = {
'Name': ['Ankit', 'Amit', 'Aishwarya', 'Priyanka', 'Priya', 'Shaurya' ],
'Age': [21, 19, 20, 18, 17, 21],
'Stream': ['Math', 'Commerce', 'Science', 'Math', 'Math', 'Science'],
'Percentage': [88, 92, 95, 70, 65, 78]}
# create a dataframe
dataframe = pd.DataFrame(record, columns = ['Name', 'Age', 'Stream', 'Percentage'])
print("Given Dataframe :\n", dataframe)
# selecting rows based on condition
rslt_df = dataframe.loc[dataframe['Percentage'] > 80]
print('\nResult dataframe :\n', rslt_df)
输出 :
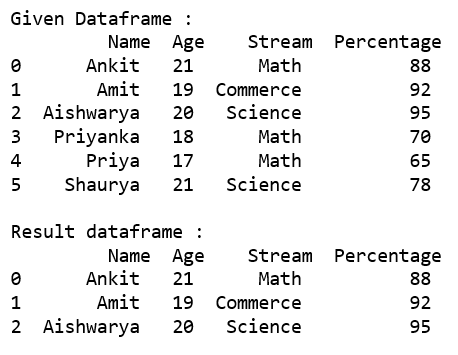
代码#3:使用 .从给定数据框中选择“百分比”不等于 95 的所有行loc[]。
# importing pandas
import pandas as pd
record = {
'Name': ['Ankit', 'Amit', 'Aishwarya', 'Priyanka', 'Priya', 'Shaurya' ],
'Age': [21, 19, 20, 18, 17, 21],
'Stream': ['Math', 'Commerce', 'Science', 'Math', 'Math', 'Science'],
'Percentage': [88, 92, 95, 70, 65, 78]}
# create a dataframe
dataframe = pd.DataFrame(record, columns = ['Name', 'Age', 'Stream', 'Percentage'])
print("Given Dataframe :\n", dataframe)
# selecting rows based on condition
rslt_df = dataframe.loc[dataframe['Percentage'] != 95]
print('\nResult dataframe :\n', rslt_df)
输出 :
使用数据框的方法选择列值存在于列表中的那些行isin()。
代码#1:使用基本方法从给定数据框中选择选项列表中存在“Stream”的所有行。
# importing pandas
import pandas as pd
record = {
'Name': ['Ankit', 'Amit', 'Aishwarya', 'Priyanka', 'Priya', 'Shaurya' ],
'Age': [21, 19, 20, 18, 17, 21],
'Stream': ['Math', 'Commerce', 'Science', 'Math', 'Math', 'Science'],
'Percentage': [88, 92, 95, 70, 65, 78]}
# create a dataframe
dataframe = pd.DataFrame(record, columns = ['Name', 'Age', 'Stream', 'Percentage'])
print("Given Dataframe :\n", dataframe)
options = ['Math', 'Commerce']
# selecting rows based on condition
rslt_df = dataframe[dataframe['Stream'].isin(options)]
print('\nResult dataframe :\n', rslt_df)
输出 :
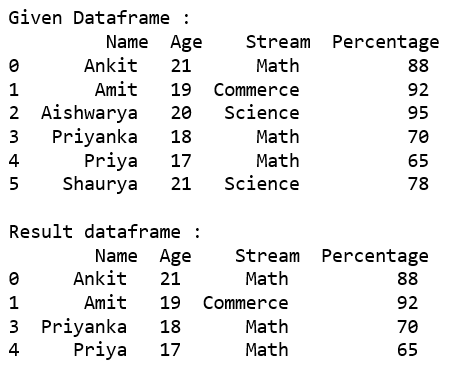
代码 #2:使用 .从给定数据框中选择选项列表中存在“流”的所有行loc[]。
# importing pandas
import pandas as pd
record = {
'Name': ['Ankit', 'Amit', 'Aishwarya', 'Priyanka', 'Priya', 'Shaurya' ],
'Age': [21, 19, 20, 18, 17, 21],
'Stream': ['Math', 'Commerce', 'Science', 'Math', 'Math', 'Science'],
'Percentage': [88, 92, 95, 70, 65, 78]}
# create a dataframe
dataframe = pd.DataFrame(record, columns = ['Name', 'Age', 'Stream', 'Percentage'])
print("Given Dataframe :\n", dataframe)
options = ['Math', 'Commerce']
# selecting rows based on condition
rslt_df = dataframe[dataframe['Stream'].isin(options)]
print('\nResult dataframe :\n', rslt_df)
输出 :
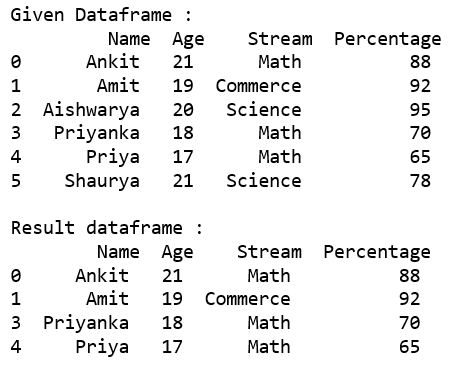
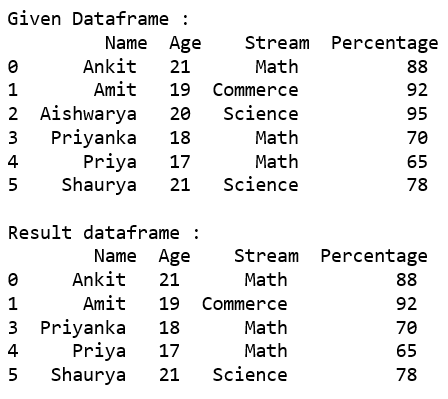
代码#3:从给定数据框中选择所有行,其中“Stream”不存在于选项列表中,使用.loc[].
# importing pandas
import pandas as pd
record = {
'Name': ['Ankit', 'Amit', 'Aishwarya', 'Priyanka', 'Priya', 'Shaurya' ],
'Age': [21, 19, 20, 18, 17, 21],
'Stream': ['Math', 'Commerce', 'Science', 'Math', 'Math', 'Science'],
'Percentage': [88, 92, 95, 70, 65, 78]}
# create a dataframe
dataframe = pd.DataFrame(record, columns = ['Name', 'Age', 'Stream', 'Percentage'])
print("Given Dataframe :\n", dataframe)
options = ['Math', 'Science']
# selecting rows based on condition
rslt_df = dataframe.loc[~dataframe['Stream'].isin(options)]
print('\nresult dataframe :\n', rslt_df)
输出 :
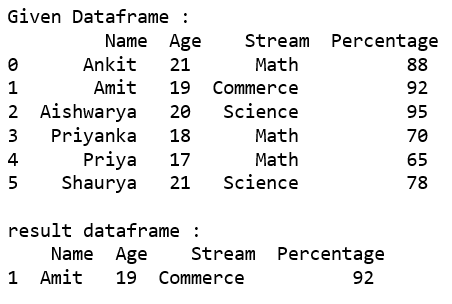
使用运算符根据多列条件选择行'&'。
代码 #1:使用基本方法从给定数据框中选择“年龄”等于 21 并且“流”出现在选项列表中的所有行。
# importing pandas
import pandas as pd
record = {
'Name': ['Ankit', 'Amit', 'Aishwarya', 'Priyanka', 'Priya', 'Shaurya' ],
'Age': [21, 19, 20, 18, 17, 21],
'Stream': ['Math', 'Commerce', 'Science', 'Math', 'Math', 'Science'],
'Percentage': [88, 92, 95, 70, 65, 78]}
# create a dataframe
dataframe = pd.DataFrame(record, columns = ['Name', 'Age', 'Stream', 'Percentage'])
print("Given Dataframe :\n", dataframe)
options = ['Math', 'Science']
# selecting rows based on condition
rslt_df = dataframe[(dataframe['Age'] == 21) &
dataframe['Stream'].isin(options)]
print('\nResult dataframe :\n', rslt_df)
输出 :
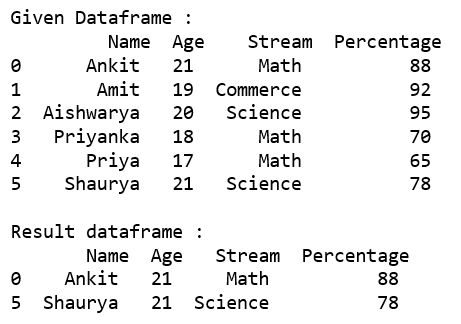
代码 #2:使用.loc[]从给定数据框中选择“年龄”等于 21 并且“流”存在于选项列表中的所有行。
# importing pandas
import pandas as pd
record = {
'Name': ['Ankit', 'Amit', 'Aishwarya', 'Priyanka', 'Priya', 'Shaurya' ],
'Age': [21, 19, 20, 18, 17, 21],
'Stream': ['Math', 'Commerce', 'Science', 'Math', 'Math', 'Science'],
'Percentage': [88, 92, 95, 70, 65, 78]}
# create a dataframe
dataframe = pd.DataFrame(record, columns = ['Name', 'Age', 'Stream', 'Percentage'])
print("Given Dataframe :\n", dataframe)
options = ['Math', 'Science']
# selecting rows based on condition
rslt_df = dataframe.loc[(dataframe['Age'] == 21) &
dataframe['Stream'].isin(options)]
print('\nResult dataframe :\n', rslt_df)
# importing pandas
import pandas as pd
record = {
'Name': ['Ankit', 'Amit', 'Aishwarya', 'Priyanka', 'Priya', 'Shaurya' ],
'Age': [21, 19, 20, 18, 17, 21],
'Stream': ['Math', 'Commerce', 'Science', 'Math', 'Math', 'Science'],
'Percentage': [88, 92, 95, 70, 65, 78]}
# create a dataframe
dataframe = pd.DataFrame(record, columns = ['Name', 'Age', 'Stream', 'Percentage'])
print("Given Dataframe :\n", dataframe)
options = ['Math', 'Science']
# selecting rows based on condition
rslt_df = dataframe.loc[(dataframe['Age'] == 21) &
dataframe['Stream'].isin(options)]
print('\nResult dataframe :\n', rslt_df)
|
输出 :