该博客是Pandas课程习题,前往此处可学习课程
该习题引用的数据集为Wine Reviews dataset,前往此处下载
数据集初始化
import pandas as pd
reviews = pd.read_csv("./winemag-data-130k-v2.csv")
运行下列代码查看该数据集的概览
reviews.head()
习题
1.
选出reviews中的description列并将其赋值给变量desc
提示
提示:举例来说,当我们想要从一个DataFrametable中获取一个列column,我们有两种选择:使用table.column或者是table['column']
Code
desc = reviews['description']
2.
从revews中的description列选出其第一个值,并命名为first_description
提示
提示:为了得到DataFrametable中一个具体条目(对应列column和行i),我们可以调用table.column.iloc[i]。记住Python的索引是从0开始的!
Code
first_description = reviews['description'].iloc[0]
3.
从reviews中选择第一行数据,并将其赋给变量first_row
提示
提示:为了得到DataFrame中具体的行,可以使用iloc操作
Code
first_row = reviews.iloc[0]
4.
从reviews中的description列选择最前面的10个数据,并赋给变量first_descriptions
提示:将输出格式规整为pandas.Series
提示
提示:我们可以用loc或者iloc来解决这个问题
Code
first_descriptions = reviews['description'].iloc[:10]
注意还有许多方式可以解决这个问题,比如desc.head(10)或者是reviews.loc[:9, 'description']
5.
选择列名为1,2,3,5和8的数据,并赋给变量sample_reviews
换句话来说,生成一个下图所示的DataFrame
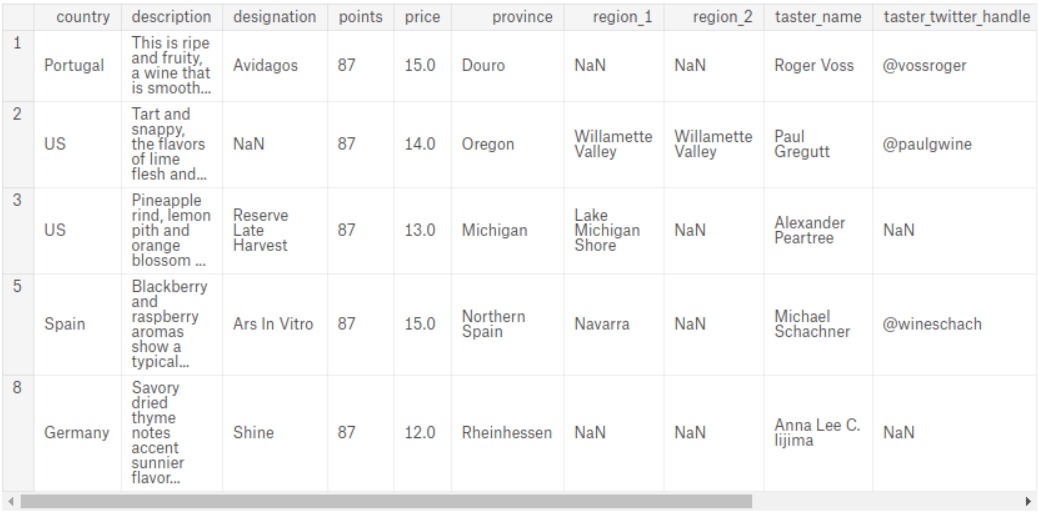
提示
提示:用loc或者iloc操作来从DataFrame选择行
Code
indices = [1, 2, 3, 5, 8]
sample_reviews = reviews.loc[indices]
6.
从reviews中提取并创建一个包含country,province,region_1,region_2列的DataFrame数据df,且索引标签为reviews中的0,1,10和100。换句话说,创建一个如下图的DataFrame
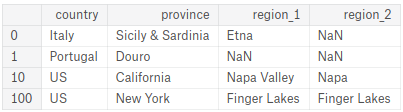
提示
提示:用loc操作
Code
df = reviews.loc[[0, 1, 10, 100], ['country', 'province', 'region_1', 'region_2']]
7.
创建一个包含reviews的前100条数据,且只包含country列和variety列的DataFramedf
提示
提示:用loc或iloc操作
Code
df = reviews.iloc[:100][['country', 'variety']]
8.
创建一个DataFrameitalian_wines包含reviews中属于Italy的红酒。提示:reviews[country]该与什么相等?
Code
italian_wines = reviews.loc[reviews['country'] == 'Italy']
9.
创建一个DataFrametop_oceania_wines包含来自Australia或者New Zealand的红酒,且其points应至少为95
Code
top_oceania_wines = reviews.loc[(reviews['country'].isin(['Australia', 'New Zealand'])) & (reviews['points'] >= 95)]
上一篇:Pandas的创建、读取和写入
标签:定位,Code,description,loc,提示,reviews,索引,iloc,Pandas From: https://www.cnblogs.com/ToryRegulus/p/17175690.html