注:本文所有函数名为中文名,并不符合代码规范,仅供读者理解参考。
上下文
上下文(Context)代表了程序(也可以是进程,操作系统,机器)运行时的环境和状态,联系程序整个生命周期与资源调用,是程序可以访问到的所有资源的总和,资源可以是一个变量,也可以是一个对象的引用。
上下文切换
所谓的上下文切换(context switch),指的是发生进程调度(进程切换)时,内核(kernel)要把当前进程的状态和数据保存起来以备以后使用,同时把之前保存的进程的相关状态调出来,这样新调度出来的进程才能运行。
原语
原语,一般是指由若干条指令组成的程序段,用来实现某个特定功能,在执行过程中不可被中断。
计算机是一门人造科学,因此真正意义上的“原语”(Primitive)是不存在的。操作系统层面上的“原语”(比如 write 之类的系统调用)对程序员来讲的确是不可分割的最小单位,但是这些系统调用本身还是用好几句汇编语句组成的(对于 Linux 来说是 C 语言)。可能有人要说到了机器代码这一级就不能再分了,但事实上一条机器指令也是由好几个组合逻辑信号构成的。同样的道理,控制信号也不过是无数电子在器件内部漂移的结果。
因此定义“原语”的前提是观察者所处的位置(上下文)。一旦规定了观察者的位置和观察的角度,比如就在操作系统的这层上,read,write,wait这些个系统调用自然就是最“原始”的词汇,这也是为什么“原语”会在操作系统中频繁出现的缘故。
上下文也可以被定义为一个操作被认为是原子性的界限。
竞争条件
两个或多个操作必须按正确的顺序执行,而程序并未保证这个顺序,就会发生竞争条件。
大多数情况下,竞争条件会出现在数据竞争中,一个并发操作尝试读取一个变量,而在某个不确定的时间,另一个并发操作视图写入同一个变量。因为开发人员总是用顺序性的思维来思考问题,他们总假设某行代码会先于另一行代码执行。
func 竞争条件() {
var data int
go func() {
data++
}()
if data == 0 {
fmt.Println("Value", data)
}
}
在这段代码中会出现三种可能性,可以根据 go程(goroutine)、if判断、打印输出执行的顺序判断。
- if、打印、go程 => Value 0
- if、go程、打印 => Value 1
- go程、if => 跳过打印,无输出
仅仅几行代码就给程序带来了巨大的不确定性。
有时,某些程序员会写出一种看似解决了问题的“方案”,就是添加 time.Sleep,但是这种方案并不可靠!通过显式休眠的方式只是在概率上增加了逻辑的正确性,但不会真正变成逻辑上的正确。休眠时间也会影响程序的运行效果!
原子性
某些东西被认为是原子的,或者具有原子性的时候,这意味着在它运行的环境中,它是不可分割或不可中断的。在你所定义的上下文中,原子的东西将被完整的运行,在这种情况下不会同时发生任何事情。
在考虑原子性时,经常第一件需要做的事就是定义上下文或范围,然后再考虑这些操作是否是原子性的。
当一个东西是原子的,说明它在并发环境中是安全的。而大多数语句不是原子的,更不用说函数、方法和程序了,所以为了构建逻辑正确的程序,需要我们做内存访问同步,使用一系列操作来强制保持原子性。
内存访问同步
临界区:程序中需要独占访问共享资源的部分。(可以理解成读写共享资源的代码段)
正如前面的例子,保护程序临界区的一个方法是在临界区之间内存访问做同步。具体做法是添加一个互斥锁。
func 竞争条件_互斥锁() {
var lock sync.Mutex
var data int
go func() {
lock.Lock()
data++
lock.Unlock()
}()
lock.Lock()
if data == 0 {
fmt.Println("Value", data)
} else {
fmt.Println("Value", data)
}
lock.Unlock()
}
如果你发现你的代码中有临界区,那就添加互斥锁,保证各个临界区对共享资源(data)的独占访问权,从而对内存的访问进行了同步。但这仅仅解决了数据竞争,没有解决竞争条件 !这种方式同步对内存的访问有性能上的问题。
死锁
所有并发进程彼此等待。
活锁
正在主动执行并发操作的程序,但无法向前推进程序状态。
饥饿
在任何情况下,并发进程都无法获得执行工作所需的所有资源
通常意味着有一个或多个贪婪的并发进程,不公平地阻止(贪婪地抢占锁,以完成整个工作循环(通常是不必要地扩大其持有共享锁上的临界区))一个或多个并发进程以尽可能有效地完成工作。
饥饿也可能产生于 CPU、内存、文件句柄、数据库连接,任何必须共享的资源都是有可能产生饥饿的原因。
找到同步访问内存的平衡点
同步访问内存代价是昂贵的,所以将锁扩展到临界区外是有利的,但是会产生前面的饥饿问题。
需要在粗粒度和细粒度同步之间找到一个平衡点。
一般经验是将内存访问同步限制在关键部分,不扩展到临界区外;直到同步成为性能问题,再扩展范围。
给并发函数注释
- 谁负责并发,是调用者负责,还是函数自己负责。
- 如何利用并发原语解决这个问题的。比如递归调用。
- 谁负责同步,调用者负责内存访问同步还是结构体内部处理。
函数可以采用纯函数式方法,尽可能消除同步的问题。
函数最好返回一个只读的channel,而不是传入参数的指针,这样更具有明确性。
并发与并行
并发属于代码,并行属于一个运行中的程序的属性。
并行的"同时"是同一时刻可以多个进程在运行(处于running),并发的"同时"是经过上下文快速切换,使得看上去多个进程同时都在运行的现象,是一种OS欺骗用户的现象。
实际上,当程序中写下多进程或多线程代码时,这意味着的是并发而不是并行。并发是因为多进程/多线程都是需要去完成的任务,不并行是因为并行与否由操作系统的调度器决定,可能会让多个进程/线程被调度到同一个CPU核心上。只不过调度算法会尽量让不同进程/线程使用不同的CPU核心,所以在实际使用中几乎总是会并行,但却不能以100%的角度去保证会并行。也就是说,并行与否程序员无法控制,只能让操作系统决定。
CSP
通信顺序进程。一个进程的输出应该直接流向另一个进程的输入。
Go魅力
一般编程语言会把它们的抽象链结束在系统线程和内存访问同步的层级。
但是Go语言采取了不同的路线,使用goroutine和channel代替这些概念。goroutine把我们从必须按照并行的思考方式中解放出来,作为替代,他允许我们按照更为自然的等级对问题进行建模。Go语言的运行时自动地将goroutine映射到系统的线程上,并为我们管理它们之间的调度(智能分配OS线程)。
Go并发哲学
不要通过共享内存进行通信,通过通信来共享内存。在面对不同场景时,选择不同的方式。
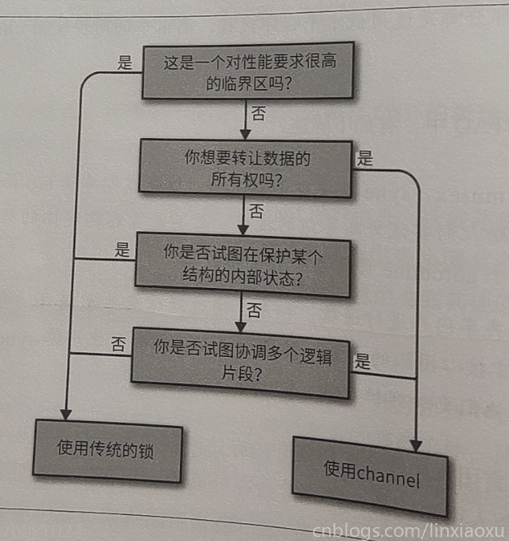
数据所有权:并发程序安全就是保证同时只有一个并发上下文拥有数据的所有权,通过channel可以把数据传递给其他go程,解耦生产者和消费者。
追求简洁,尽量使用channel,并且认为goroutine的使用是没有成本的。
参考书籍
-
《Go语言并发之道》Katherine CoxBuday
-
《Go语言核心编程》李文塔
-
《Go语言高级编程》柴树彬、曹春辉