一次goroutine 泄漏排查案例
背景
这是一个比较经典的golang协程泄漏案例。
背景是这样,今天看到监控大盘数据发现协程的数量监控很奇怪。呈现上升趋势,然后骤降。由于上升期间增长的内存远远没有达到报警的地步,所以也没有报警产生。
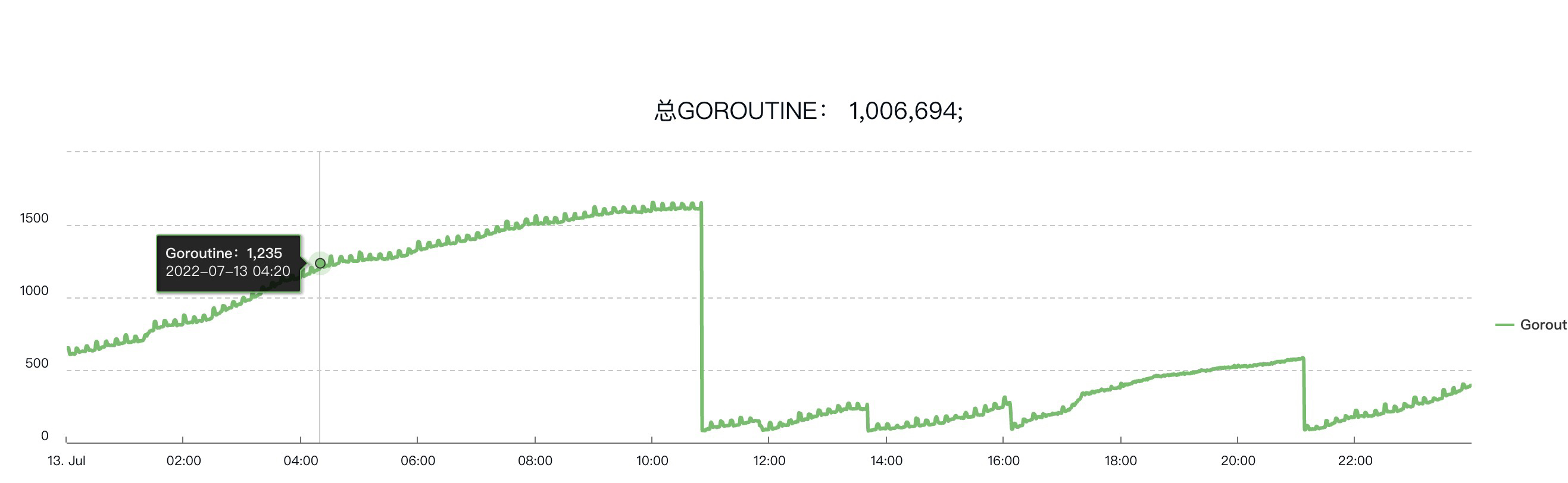
有经验的开发应该n能一眼看出,这个肯定是协程泄漏了,中间下降的曲线其实是服务器重启造成的。
pprof分析
线上开启了
直接采用pprof分析协程数量变化
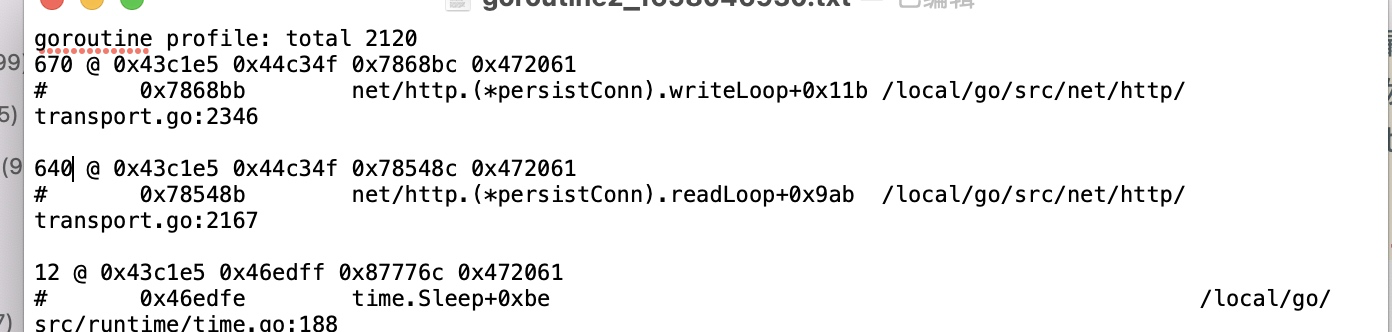
可以发现主要是transport这个文件里产生的协程没有被释放,transport这个文件是golang里用于发起http请求的文件,并且定位到了具体的代码位置,熟悉golang的同学应该能立马想到,协程没有释放的原因极大可能是请求的响应体没有关闭。这也算是golang里面的一个坑了。
现在来用代码具体分析下为啥resp body不关闭,会造成协程泄漏。
回归代码分析
http.Get()请求路径分析
| code | pos | explain |
|---|---|---|
| DefaultClient.Get | src/net/http/client.go:449 | |
| (c *Client) do(req *Request) | src/net/http/client.go:593 | |
| err = c.send(req, deadline) | src/net/http/client.go:725 | |
| send(req, c.transport(), deadline) | src/net/http/client.go:176 | |
| resp, err = rt.RoundTrip(req) | src/net/http/client.go:252 | |
| pconn, err := t.getConn(treq, cm) | src/net/http/transport.go:581 | 从连接池获取或者新建连接,相同域名协议端口可以复用连接 |
| resp, err = pconn.roundTrip(treq) | src/net/http/transport.go:594 |
采用默认的http client 发起get请求
func Get(url string) (resp *Response, err error) {
return DefaultClient.Get(url)
}
实际上调用了client的Do 方法
req, err := NewRequest("GET", url, nil)
if err != nil {
return nil, err
}
return c.Do(req)
底层调用client 的do方法,着重看其中发起网络请求的部分
func (c *Client) do(req *Request) (retres *Response, reterr error) {
if testHookClientDoResult != nil {
defer func() { testHookClientDoResult(retres, reterr) }()
}
......
// 在for循环里发起了请求
for {
// 准备请求体
req = &Request{
Method: redirectMethod,
Response: resp,
URL: u,
Header: make(Header),
Host: host,
Cancel: ireq.Cancel,
ctx: ireq.ctx,
}
......
reqs = append(reqs, req)
var err error
var didTimeout func() bool
// send 方法实际发起请求
if resp, didTimeout, err = c.send(req, deadline); err != nil {
// c.send() always closes req.Body
reqBodyClosed = true
if !deadline.IsZero() && didTimeout() {
err = &httpError{
err: err.Error() + " (Client.Timeout exceeded while awaiting headers)",
timeout: true,
}
}
return nil, uerr(err)
}
var shouldRedirect bool
// 对重定向请求的处理
redirectMethod, shouldRedirect, includeBody = redirectBehavior(req.Method, resp, reqs[0])
if !shouldRedirect {
return resp, nil
}
req.closeBody()
}
}
看send 方法
func send(ireq *Request, rt RoundTripper, deadline time.Time) (resp *Response, didTimeout func() bool, err error) {
// 参数校验
......
if !deadline.IsZero() {
forkReq()
}
stopTimer, didTimeout := setRequestCancel(req, rt, deadline)
// 实际发出请求的地方
resp, err = rt.RoundTrip(req)
// 返回结果处理
......
return resp, nil, nil
}
查看RoundTrip 方法
// 一些参数校验逻辑
....
for {
select {
case <-ctx.Done():
req.closeBody()
return nil, ctx.Err()
default:
}
// treq gets modified by roundTrip, so we need to recreate for each retry.
treq := &transportRequest{Request: req, trace: trace, cancelKey: cancelKey}
cm, err := t.connectMethodForRequest(treq)
if err != nil {
req.closeBody()
return nil, err
}
// Get the cached or newly-created connection to either the
// host (for http or https), the http proxy, or the http proxy
// pre-CONNECTed to https server. In any case, we'll be ready
// to send it requests.
// 获取连接 两种方式 1,从 连接池获取 2,新建连接
pconn, err := t.getConn(treq, cm)
if err != nil {
t.setReqCanceler(cancelKey, nil)
req.closeBody()
return nil, err
}
var resp *Response
if pconn.alt != nil {
// HTTP/2 path.
t.setReqCanceler(cancelKey, nil) // not cancelable with CancelRequest
resp, err = pconn.alt.RoundTrip(req)
} else {
// 实际发起请求的地方
resp, err = pconn.roundTrip(treq)
}
if err == nil {
resp.Request = origReq
return resp, nil
}
// Failed. Clean up and determine whether to retry.
....
// 失败和重试处理
}
}
查看 roundTrip方法
func (pc *persistConn) roundTrip(req *transportRequest) (resp *Response, err error) {
// 构造请求参数
...
startBytesWritten := pc.nwrite
writeErrCh := make(chan error, 1)
// 将请求写入pc.writech里
pc.writech <- writeRequest{req, writeErrCh, continueCh}
resc := make(chan responseAndError)
pc.reqch <- requestAndChan{
req: req.Request,
cancelKey: req.cancelKey,
ch: resc,
addedGzip: requestedGzip,
continueCh: continueCh,
callerGone: gone,
}
var respHeaderTimer <-chan time.Time
cancelChan := req.Request.Cancel
ctxDoneChan := req.Context().Done()
pcClosed := pc.closech
canceled := false
// 接收请求也是采用select case 从channel里获取resp 或者超时处理
for {
testHookWaitResLoop()
select {
case err := <-writeErrCh:
if debugRoundTrip {
req.logf("writeErrCh resv: %T/%#v", err, err)
}
if err != nil {
pc.close(fmt.Errorf("write error: %v", err))
return nil, pc.mapRoundTripError(req, startBytesWritten, err)
}
if d := pc.t.ResponseHeaderTimeout; d > 0 {
if debugRoundTrip {
req.logf("starting timer for %v", d)
}
timer := time.NewTimer(d)
defer timer.Stop() // prevent leaks
respHeaderTimer = timer.C
}
case <-pcClosed:
pcClosed = nil
if canceled || pc.t.replaceReqCanceler(req.cancelKey, nil) {
if debugRoundTrip {
req.logf("closech recv: %T %#v", pc.closed, pc.closed)
}
return nil, pc.mapRoundTripError(req, startBytesWritten, pc.closed)
}
case <-respHeaderTimer:
if debugRoundTrip {
req.logf("timeout waiting for response headers.")
}
pc.close(errTimeout)
return nil, errTimeout
case re := <-resc:
// 收到实际返回resp
if (re.res == nil) == (re.err == nil) {
panic(fmt.Sprintf("internal error: exactly one of res or err should be set; nil=%v", re.res == nil))
}
if debugRoundTrip {
req.logf("resc recv: %p, %T/%#v", re.res, re.err, re.err)
}
if re.err != nil {
return nil, pc.mapRoundTripError(req, startBytesWritten, re.err)
}
return re.res, nil
case <-cancelChan:
canceled = pc.t.cancelRequest(req.cancelKey, errRequestCanceled)
cancelChan = nil
case <-ctxDoneChan:
canceled = pc.t.cancelRequest(req.cancelKey, req.Context().Err())
cancelChan = nil
ctxDoneChan = nil
}
}
}
找到往resp body的channel 里写入数据的地方,找到了readLoop 方法
而readLoop 方法在外部是用go协程启动的,在新创建一个链接的时候则同时启动两个协程,一个负责发送请求,一个负责接收返回体。
func (t *Transport) dialConn(ctx context.Context, cm connectMethod) (pconn *persistConn, err error) {
...
go pconn.readLoop()
go pconn.writeLoop()
}
然后看看readLoop究竟在做什么操作
func (pc *persistConn) readLoop() {
// 定义一些方法和变量
....
// 在for循环里执行一段重复读取的逻辑
alive := true
for alive {
pc.readLimit = pc.maxHeaderResponseSize()
_, err := pc.br.Peek(1)
pc.mu.Lock()
if pc.numExpectedResponses == 0 {
pc.readLoopPeekFailLocked(err)
pc.mu.Unlock()
return
}
pc.mu.Unlock()
rc := <-pc.reqch
trace := httptrace.ContextClientTrace(rc.req.Context())
var resp *Response
if err == nil {
// 接收到真正的resp
resp, err = pc.readResponse(rc, trace)
} else {
err = transportReadFromServerError{err}
closeErr = err
}
.......
waitForBodyRead := make(chan bool, 2)
// bodyEOFSignal 为最后http.Response body 里的body对象
body := &bodyEOFSignal{
body: resp.Body,
// 注意往waitForBodyRead 发送布尔值的时机
// 可以看到是要调用 earlyCloseFn fn 才会往waitForBodyRead 通道发消息,找到调用earlyCloseFn fn的地方
earlyCloseFn: func() error {
waitForBodyRead <- false
fmt.Println("earlyCloseFn start")
<-eofc // will be closed by deferred call at the end of the function
fmt.Println("earlyCloseFn end")
return nil
},
// 注意往waitForBodyRead 发送布尔值的时机
fn: func(err error) error {
isEOF := err == io.EOF
waitForBodyRead <- isEOF
fmt.Println("fn start")
if isEOF {
<-eofc // see comment above eofc declaration
fmt.Println("fn end")
} else if err != nil {
if cerr := pc.canceled(); cerr != nil {
return cerr
}
}
return err
},
}
resp.Body = body
if rc.addedGzip && ascii.EqualFold(resp.Header.Get("Content-Encoding"), "gzip") {
resp.Body = &gzipReader{body: body}
resp.Header.Del("Content-Encoding")
resp.Header.Del("Content-Length")
resp.ContentLength = -1
resp.Uncompressed = true
}
select {
// 将resp 发往RoundTrip 方法里,RoundTrip里的select case方法得以正常运行
case rc.ch <- responseAndError{res: resp}:
case <-rc.callerGone:
return
}
// select case 语句,实际上线上 代码也是阻塞在了这里,为什么会阻塞?
select {
// 等待body被读取完毕
case bodyEOF := <-waitForBodyRead:
replaced := pc.t.replaceReqCanceler(rc.cancelKey, nil) // before pc might return to idle pool
alive = alive &&
bodyEOF &&
!pc.sawEOF &&
pc.wroteRequest() &&
replaced && tryPutIdleConn(trace)
if bodyEOF {
eofc <- struct{}{}
}
// 请求被取消
case <-rc.req.Cancel:
alive = false
pc.t.CancelRequest(rc.req)
// 请求被取消
case <-rc.req.Context().Done():
alive = false
pc.t.cancelRequest(rc.cancelKey, rc.req.Context().Err())
// 连接关闭
case <-pc.closech:
alive = false
}
testHookReadLoopBeforeNextRead()
}
}
找到fn,earlyCloseFn 调用的地方
func (es *bodyEOFSignal) Read(p []byte) (n int, err error) {
es.mu.Lock()
closed, rerr := es.closed, es.rerr
es.mu.Unlock()
if closed {
return 0, errReadOnClosedResBody
}
if rerr != nil {
return 0, rerr
}
n, err = es.body.Read(p)
if err != nil {
es.mu.Lock()
defer es.mu.Unlock()
if es.rerr == nil {
es.rerr = err
}
// err报错的时候调用condfn
err = es.condfn(err)
}
return
}
// close方法会调用es.earlyCloseFn 或者es.condfn
func (es *bodyEOFSignal) Close() error {
es.mu.Lock()
defer es.mu.Unlock()
if es.closed {
return nil
}
es.closed = true
if es.earlyCloseFn != nil && es.rerr != io.EOF {
return es.earlyCloseFn()
}
err := es.body.Close()
return es.condfn(err)
}
// es.condfn 实际是对es.fn的调用
func (es *bodyEOFSignal) condfn(err error) error {
if es.fn == nil {
return err
}
err = es.fn(err)
es.fn = nil
return err
}
可以看到其实报错的时候(包括io.EOF)也会调用fn方法,而fn方法会往waitForBodyRead 发送true,
bodyEOF 则为true,pc.sawEOF 为连接是否断开的标记,如果断开,对端会收到io.EOF,这里由于是长链接,所以pc.sawEOF 为false ,最终alive为true,并且连接重新放入了连接池。
由于这段逻辑又是在for循环里,所以当连接又从连接池拿出来的时候,readLoop依然会继续工作。
注意如果如果每次都把resp body全部读完的话,即使没有关闭 resp body 协程泄漏的情况依然不会很严重,因为全部读完body,会往waitForBodyRead通道 发送true的布尔值,从而让连接又放入连接池,放入连接池以后就能在接受相同域名的请求或者空闲连接超时 时,让连接自动关闭,然后readLoop 协程就停止了。
select {
// 等待body被读取完毕
case bodyEOF := <-waitForBodyRead:
replaced := pc.t.replaceReqCanceler(rc.cancelKey, nil) // before pc might return to idle pool
alive = alive &&
bodyEOF &&
!pc.sawEOF &&
pc.wroteRequest() &&
replaced && tryPutIdleConn(trace)
if bodyEOF {
eofc <- struct{}{}
}
// 请求被取消
case <-rc.req.Cancel:
alive = false
pc.t.CancelRequest(rc.req)
// 请求被取消
case <-rc.req.Context().Done():
alive = false
pc.t.cancelRequest(rc.cancelKey, rc.req.Context().Err())
// 连接关闭时结束协程
case <-pc.closech:
alive = false
}
那么线上生产为什么会有那么多的协程阻塞呢,原因在于没有将resp body 完整读取并且没有关闭resp body。
看看线上写法,将resp body 用io.limitReader装饰了下,并且只读前10个字节,没有触发resp body io.EOF error 这样就导致readLoop协程select case 那里一直处于阻塞状态。
_, err = ioutil.ReadAll(io.LimitReader(resp.Body, 10))
if err != nil && err != io.EOF {
t.Fatal(err)
}
修正
修正也很简单,即对resp body关闭即可。
resp.body.Close()
反思
golang resp body 还是一定要记得关闭,不然就会引发协程泄漏问题,这次由于同事对此类问题没有过多重视,导致了这个问题,好在有监控大盘,及时发现,不然后果不堪设想。
标签:body,泄漏,req,nil,err,resp,goroutine,排查,es From: https://www.cnblogs.com/hobbybear/p/17190304.html