1. CPU电源管理简介
如果我们的能源是无限制的,那可能也不需要做现在这样复杂的电源管理控制,尤其是在嵌入式设备如手机上,在追求极致性能的同时,还要追求续航时间,二者是一对相互约束的矛盾体,需要软硬件紧密配合以满足用户越发苛刻的性能和功耗的需求。
CPU是设备的控制核心,它的电源管理是整个SOC电源管理非常重要的一环。常见的CPU电源管理设计,主要也是围绕静态功耗和动态功耗的设计和优化展开:
1)静态功耗:ASIC集成电路的最基本单元是晶体管,我们的SOC在待机时仍然会有漏电流产生,从而引起静态功耗的消耗,得益于晶圆厂SOC制程(工艺)不断改进,如相比7nm FinFET,台积电5nm EUV工艺能效提升15%,功耗减少30%。所以从这个角度来讲,CPU要降低静态功耗,需要ASIC工程师把面积做小,同时需要晶圆厂把工艺制程不断改进。
2)动态功耗:这块比较复杂,软硬件配合的有cpufreq、cpuidle、锁机制底层实现等,ASIC方面有clock gating、不同power domain等,我们简单介绍下。
- cpufreq:根据cpu负载,选择满足性能需求的最低的电压/频率对(也叫OPP,Operating Performance Points)。对ARM而言,这种电压/频率对的调整的最小单位是cluster,也就是说一个cluster里的所有工作的CPU核心的频率/电压对是相同的。在ARM支持DynamIQ后,不再是只有2个cluster了,每个cluster也不要求放置同一种微架构的CPU核心了,而是出现了如1小核+3中核+4小核的结构,笔者手中的Google Pixel4手机,就是这种架构,这款手机中vendor厂商把大核和中核,电压设置成一路电源去供电,而频率却不一样,这样对软件调频的策略提出了更高的要求,这里不再展开了。这种电压/频率对的调整,其他很多设备也都适用,统称为DVFS(Dynamic Voltage/Frequency Scaling,动态电压/频率调整)。
- cpuidle:Linux用C-States来描述,最早应该是Intel提出来的概念,有4个状态(C0到C3)。ARM架构中,C0对应Running状态,C1对应Idle状态,C3对应Sleep状态,没有C2,CPU根据设定策略进入不同的低功耗状态,当然进出不同低功耗状态的时延是不也一样的。C1状态对应我们的cpuidle去控制,底层实现一般会执行WFI(Wait for Interrupt )指令,等到有中断的时候从C1迁移至C0状态,如果没有中断且满足一定条件会进一步转移至C3状态。CPU内部会有一个状态机控制这些状态的迁移和转换,不同状态可以简单的理解为参与工作的CPU部件不一样,状态的数字越小,参与工作的部件就越多。细节请参考ARM ARM(ARM Architecture Reference Manual)和各个CPU的微架构的TRM(Technical Reference Manual)。
- spinlock锁机制:底层实现会执行WFE(Wait for Event)指令,进入低功耗状态,待收到SEV指令的时候,会从低功耗状态退出。避免在lock时忙等,节省部分功耗。
- clock gating:这是ASIC设计的自动门控功能,一般外设会有寄存器控制是否使能,而CPU主要是在WFI的时候会关闭一些时钟,这个是CPU内部的状态机逻辑来做的,也算是clock gating,这个过程一般不需要软件参与。
- power domain:划分不同的domain,是为了方便去做精细控制,需要软件参与。例如Pixel4手机有3个cluster划分了两个power domain(大核和中核是一个domain,小核是另外一个domain)。例如在系统轻载,甚至可以把大核和中核这两个cluster下电。细节可以参考TRM,比如A57 TRM的有关power domain划分示意如下图所示,这里不再展开。

2. cpufreq总体框架简介
介绍完CPU电源管理的常用手段,我们简单回顾下cpufreq的总体架构和各模块的作用,以及体现的软件思想。
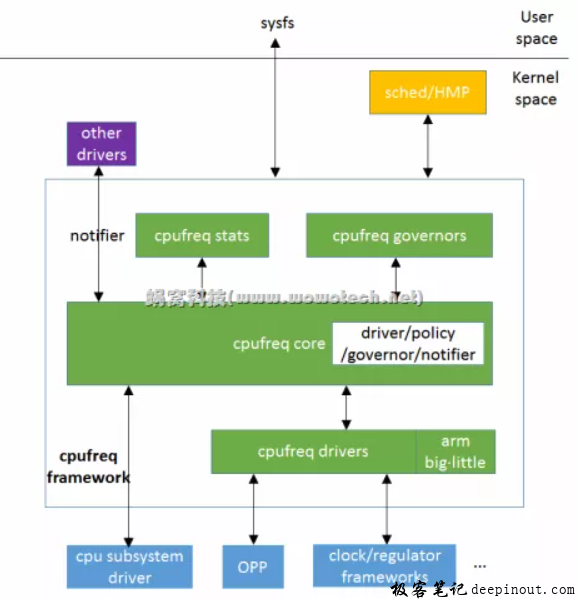
2.1 cpufreq主要模块介绍
- Core:是对通用流程和方法的抽象;
- Governor:负责调频策略,解决如何调频的问题;
- Driver:负责平台相关调频机制的具体实现(需要直接操作硬件);
- Stats:负责调频信息和各频点运行时间等统计,使用time_in_state ,结合算力和最大频率,可以做归一化的CPU负载统计。
- Notifer:通知链,负责通知其他关心调频动作的driver。
- Sysfs:暴露接口给用户态应用程序,使其可以灵活控制,实现不同的控制策略。
2.2 cpufreq软件思想介绍
cpufreq体现的一些软件设计思想,在Linux kernel中其他模块中也很常见,值得我们学习和借鉴:
-
分层思想。底层(driver)负责实现平台相关的实现,越往上越抽象(core、governor),尽量内聚(每个模块尽可能独立完成自己的功能,不依赖于模块外部的代码)。
-
策略/机制分离思想。内核有两种形态:
- 内核提供机制,用户空间实现策略。比如后文我们会介绍的User Space这个governor就是由用户程序决策,直接控制频率切换策略。
- 内核提供机制,特定的策略由governor去实现,用户空间修改governor的参数,例如后文我们介绍的schedutil如果scheduler选择用WALT去跟踪task和CPU负载就有一些参数会在用户空间调节。
-
观察者模式。通知链也是内核常用的设计,其他模块通过注册到通知链的回调函数,会在相应变化发生的时候调用这些回调,这些模块可以以观察者身份及时捕获这些变化。实现了解耦。
2.3 调频方法和影响CPU频率的因素

从内核文档,我们可以知道:
- 如果driver实现了setpolicy方法,则表明cpu硬件支持自动调频,不需要软件的governor干预,用户只要设置max/min freq(称作policy)即可。在手机上每个cluster会对应一个policy。
- 另外一种则需要governor实现控制策略,需要通过一定的方法计算出目标频率,告诉driver(调用driver实现的target/targetindex/fastswitch方法中的一种),最终由drvier控制CPU频率调整。
无论是采取哪种方法,一般CPU的工作频率都会和CPU工作承担的负载正相关。但也会有有一些其他因素影响CPU的频率,主要是thermal和用户态策略,thermal主要功能是一个热保护,过高的CPU温度除了引起如烫手等因素外,累积效应还有可能引起如晶体管击穿导致SOC不能正常工作,甚至会导致引起一些其他严重的后果(类似于若干年前的三星手机的电池爆炸的)。
thermal一般会通过内核态接口cpufreq_update_policy来实现频率控制。而用户态应用程序会通过sysfs去控制。最终都是影响policy的{max, min}。
2.4 常见governor
- Performance:性能优先的governor,直接将cpu频率设置为policy->{min,max}中的最大值。
- Powersave:功耗优先的governor,直接将cpu频率设置为policy->{min,max}中的最小值。
- Userspace:由用户空间程序通过scaling_setspeed文件节点修改频率。
- Ondemand:根据CPU的当前使用率,动态的调节CPU频率。scheduler通过调用ondemand注册进来的钩子函数来触发系统负载的估算(异步的)。它以一定的时间间隔对系统负载情况进行采样。按需动态调整CPU频率, 如果的CPU当前使用率超过设定阈值,就会立即达到最大频率运行,等执行完毕就立即回到最低频率。好处是调频速度快,但问题是调的不够精确。
- Conservative:类似Ondemand,不过频率调节的会平滑一下,不会有忽然调整为最大值又忽然调整为最小值的现象。区别在于:当系统CPU 负载超过一定阈值时,Conservative的目标频率会以某个步长步伐递增;当系统CPU 负载低于一定阈值时,目标频率会以某个步长步伐递减。同时也需要周期性地去计算系统负载。
- Interactive:由Android提出的机制,未被linux kernel社区接纳,在AOSP的linux分支上存在了较长时间。它针对CPU密集的任务的调频策略会比较激进。因为它在每一个 CPU 上都注册了一个 idle notifier。当 CPU 退出 idle 时,去检查然后决策是否需要调整频率,非idle时仍然需要依赖timer去定时采样,才能知道系统负载信息。
- schedutil:本文要讨论的重点,后续章节展开。
3. schedutil的总体框架
该governor由Rafael J. Wysocki在2016年提出,最终合入到linux kernel 4.7中。它体现主要的思想和相比其他governor的改进点如下:
- 基于scheduler的 CPU 调频策略,它直接使用来自scheduler的负载数据,之所以能做到这样,是因为在此之前内核有了负载变化回调机制(mechanism for registering utilization update callbacks),schedutil的通过将自己的调频策略注册到hook,在负载变化时候会回调该hook,此时就可以进行调频决策和甚至于执行调频动作。而前面介绍的ondemand、conservation、interactive都需要定期采样以计算CPU负载,具有一定的滞后性,精度也有限。实际上scheduler已经可以用PELT(Per Entity Load Tracking) 或者WALT(Window Assist Load Tracking)去较为准确的追踪Task负载和CPU负载,现在可以直接去利用其中的CPU负载,省去了采样,使调频能更快速。
- 支持从中断上下文直接切换频率机制,可以进一步缩短调频的时延。该特性需要driver能够支持fast_switch功能,这些driver甚至只需要通过简单的写寄存器就可以完成频率的切换。
一句话总结就是:通过它,让scheduler和调频建立起更加紧密的联系,同时提升了性能和功耗表现(调频上升和下降的曲线都更加陡峭,频率更快的上升或者下降到目标频率)。
无论是PELT还是WALT,schedutil都可以与之协同工作,Pixel4内核使用了PELT,其他很多手机产商一般会沿用SOC产商的策略,采用WALT。究竟哪个能发挥更好的调频效果,现在也没有定论,看各自的调优手段了,不在本次讨论的范畴。
3.1 schedutil 软件框图
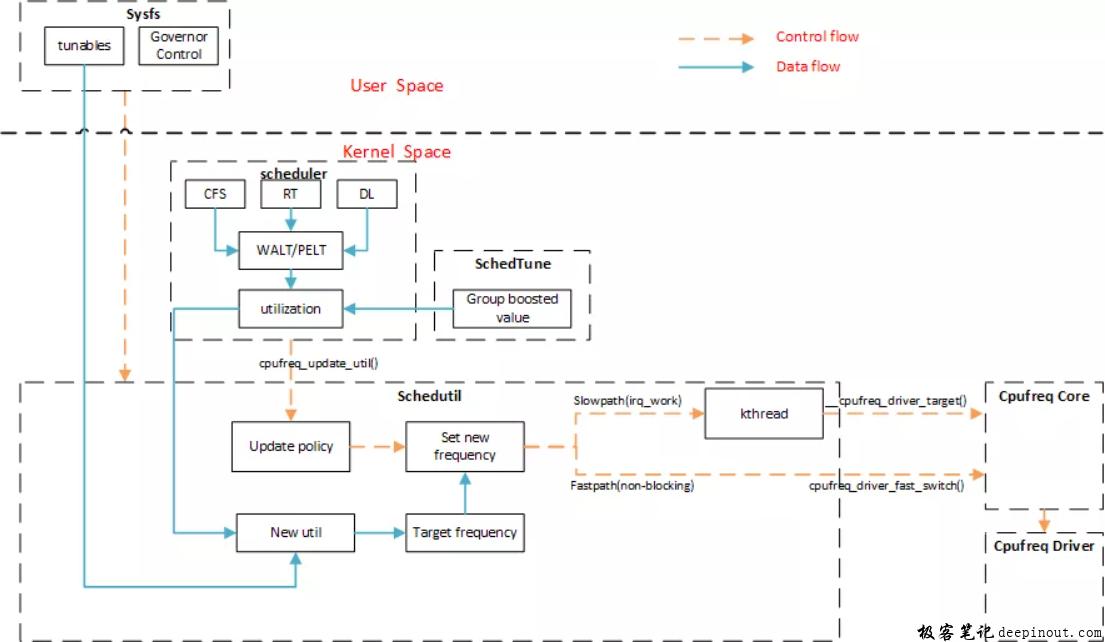
其实起初内核社区有两个基于scheduler的调频方案:
- 一个是Linaro 主导的 cpufreq_sched,属于 EAS 的一部分。当然EAS曾经使用过的schedfreq也是这种基于scheduler的governor。
- 另外一个 Intel 主导的schedutil。随着该governor合入linux mainline,EAS后来也使用了schedutil。
scheduler,一方面使用WALT或PELT去跟踪TASK负载进而产生CPU负载用来作为目标频率计算的输入,一方面在负载变化时调用cpufreq_update_util调用hook触发schedutil工作,进而进行频率决策和后续的频率调整。
SchedTune,则是通过cgroup进程组的方式,影响CPU负载,进而影响CPU调频的频率选择,是一种性能提升技术。它还可以通过prefer_idle标志位,告诉scheduler用户空间进程组希望在调度时更倾向于功耗还是性能(值为1表示更倾向于性能),在linux kernel mainline 5.4中这块功能将被UClamp(Utilization Clamping)所代替,有兴趣的同学可以自行研究。
tunables,提供了sysfs接口在用户空间灵活配置,根据细分场景进行调优:
- up_rate_limit_us/down_rate_limit,频率升高/降低的速率(阈值),调频的时间间隔必须要在这两个阈值控制的范围内才能真正的去执行频率切换动作。通过动态配置这两个阈值,可以满足多样的调优需求。
- pl/hispeed_load/hispeed_freq,这几个参数属于WALT调优的范畴,暂不展开。
schedutil最终决策需要进行调频后,有2个路径:
- 慢速路径:需要去irqwork上去排队,进而唤醒kthread,最终调用__cpufreq_driver_target接口调整成硬件平台支持的目标频率。
- 快速路径:省去了排队和唤醒动作,最终调用cpufreq_driver_fast_switch接口,像在pixel4上的driver通过写寄存器实现的。
最后,从软件框图我们可以看到,无论是CFS、RT、DL task本质上都是通过cpu utilization去影响频率的计算和选择。对DL task,认为是负载时未知的(目前还不能追踪utilization),会将CPU频率设置到policy->max,对CFS/RT Task则会根据都会根据utilization(runqueue的avg.util_avg成员,即struct sched_avg的util_avg成员)去计算频率。其实一开始RT/DL task的调度策略是一样的,都是简单粗暴地设置到最高频,后来通过sched/rt: add utilization tracking和sched: cpufreq: use PELT rt_rq as estimate of required RT CPU capacity,这两个patch对RT task做了改进。
至此,schedutil和相关联模块的简单分析就结束,接下来我们继续分析它的实现细节。
4. schedutil的核心逻辑
本文的代码分析会侧重分析核心逻辑,有些细节不做展开,防止胡子眉毛一把抓。我们主要关注这个governor是怎么初始化和启动的,何时触发schedutil工作,以及schedutil的决策逻辑最终怎么去做频率切换的。
4.1 schedutil的初始化和启动
governor的初始化和启动,是在cpufreq_set_policy函数中来做的。一般发生在governor切换的时候。Governor的停止和去初始化,是逆过程,不再展开。
4.2 sugov_init函数
一般初始化函数都是要准备一些资源,我们schedutil也不例外。
这个函数每个policy都会执行到,可能会同时执行,产生竞争条件,最终会在cpufreq_init_governor函数中被调用。简化代码如下:


- 调用框架提供的cpufreq_enable_fast_switch接口尝试使能快速切换功能
- 给struct sugov_policy类型的指针分配内存并初始化
- 如果不支持快速切换,则调用sugov_kthread_create走slow_path,创建相关进程和workqueue相关的work,包括sugov_work和sugov_irqwork。
- tunables的初始化,包括创建sysfs接口,供用户态空间进行调优。
4.3 sugov_start函数
该函数最主要的作用就是要把最终调频决策和执行调频动作的核函数注册到scheduler的hook中。该函数会在框架的cpufreq_start_governor函数中先被调用,紧接着还要调用sugov_limits函数进行限频的检查。简化码如下:

- sstruct sugov_policy sg_policy变量的初始化。
- 所有共用policy都要循环执行struct sugov_cpu sg_cpu变量的初始化
- 调用cpufreq_add_update_util_hook接口,向scheduler注册回调函数,在cpufreq_update_util中被调用。当多个CPU共用一个policy时,则将sugov_update_shared函数注册给scheduler;反之,则将sugov_update_single函数注册给scheduler。
4.4 sugov_limits函数
该函数完成频率限制的检查,简化代码如下:

-
是否支持频率快速切换(支持在中断上下文中调用)的区别在于调用时间信息的函数和频率限制后最终调用的调频接口的区别:
- 快速切换:调用sched_ktime_clock获取时间戳信息;如果需要,最终调用cpufreq_driver_fast_switch切换频率。
- 慢速切换:调用ktime_get_ns获取时间戳信息;如果需要,最终调用_cpufreq_driver_target切换频率。
-
调用sugov_track_cycles函数更新sgpolicy的curr_cycles(累加值)和last_cyc_update_time(最后一次时间戳)成员。
-
根据当前policy->{max, min}的限制和当前频率信息,看是否需要将当前频率调整到policy->{max, min}当中的一个。
4.4 schedutil调频的触发时机
CFS负载变化或者RT/DL任务状态更新时就可以启动调频,这几个scheduler类会调用cpufreq_update_util函数(也就是调用注册进来的hook函数)触发schedutil工作。每个CPU最终会回调到sugov_update_shared或者sugov_update_single函数当中的一个。
因为是从scheduler里直接调用下来的,最终执行频率切换时无论慢速路径触发kthread运行,还是快速路径简单写寄存器都不会占用过多的调度开销,这也是schedutil能被社区接纳的一个很重要的原因。
触发的具体时机如下:
- 当一个task被唤醒的时候(对应try_to_wake_up函数被调用),如果使用WALT且满足PL(Predict Load);
- 在系统tick到来(对应scheduler_tick函数被调用),如果使用WALT且满足ED(Early Detection)时;
- 如果使用WALT且WALT窗口滑动时(对应walt_irq_work函数被调用);
- DL任务状态更新时(对应update_curr_dl函数被调用);
- RT任务更新时(对应cpufreq_update_util函数被调用);
- 当CFS更新RQ的负载时(对应cfs_rq_util_change函数被调用)
- 当一个设置了in_iowait的CFS(TODO)任务进入Runqueue,并且是Schedtune类型的进程组设置了prefer_idle标识时。
4.5 schedutil调频的决策和频率切换
schedutil调频被触发工作以后,剩下的工作就交由sugov_update_shared或者sugov_update_single这两个核心函数去完成了。
4.5.1 sugov_update_single函数
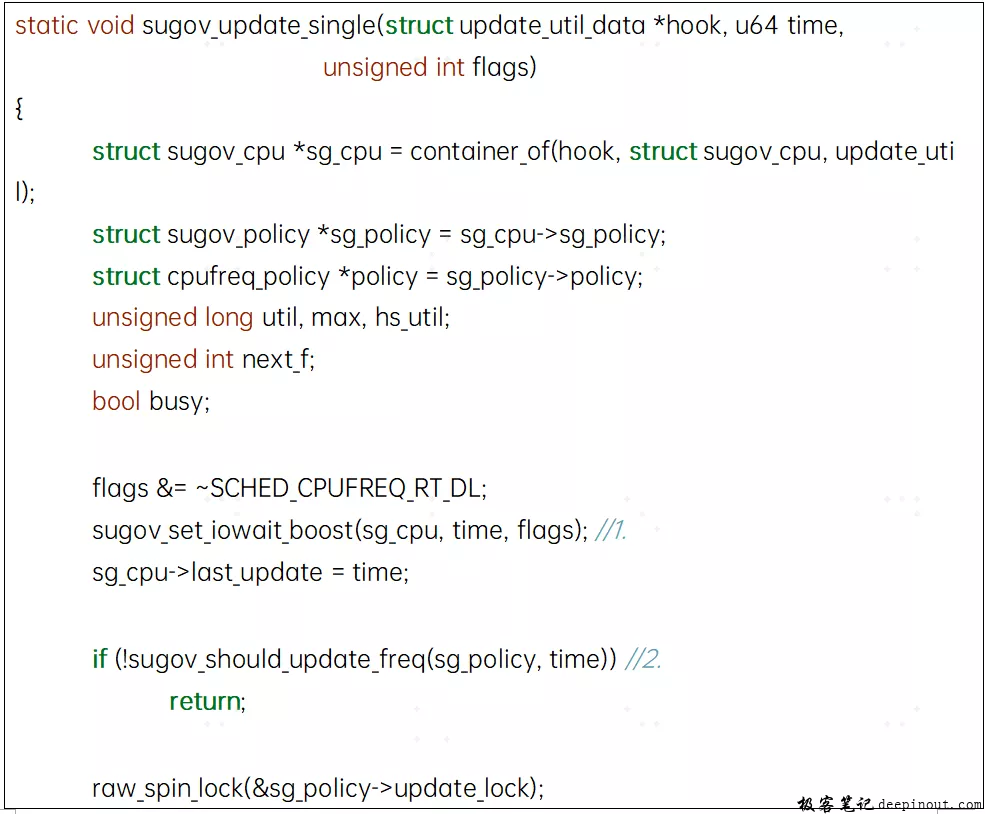


-
调用sugov_set_iowait_boost设置iowait_boost相关变量
-
调用sugov_should_update_freq判断是否真的需要频率切换,不需要更新则直接返回,需要切换则主要是如下情况:
- limits发生了改变(对应policy->{max, min},如thermal触发限频或者其他机制如高通的perf_lock进行提频)。
- 频率更新的时间间隔超过min_rate_limit_ns的阈值。
-
如果是DL任务,则直接将目标频率设置成硬件支持的最大值。
-
如果是其他调度类的任务,则继续处理5-11步的处理。
-
调用sugov_get_util获取CPU统计的负载,会同时考虑WALT/PELT的处理方式,同时会Schedtune类型的进程组设置的boost_value考虑进来。
-
对sgpolicy的hispeed_util做归一化处理。归一化到算力最高的CPU上,同时考虑tunables的hispeed_freq的设置(hispeed_freq默认为0)。
-
计算平均算力,不使用WALT特性则不做处理。
-
如果scheduler设置SCHED_CPUFREQ_IOWAIT标志,主要依据第一步的iowait_boost变量提升负载,进而提升频率,起到加速执行的效果。
-
如果是WALT特性,则tunables的hispeed_load、pl变量设置以及sg_policy的平均算力等,进一步提升负载,进而提升频率加速task的执行。
-
调用get_next_freq函数,将负载数据转换成平台支持的目标频率,具体计算过程我们后续单独展开。
-
调用sugov_update_commit函数,执行频率切换,我们后续单独展开。
4.5.2 sugov_update_shared函数
针对该cluster里有多个CPU的情形,因为多个CPU复用该函数,需要要考虑并发的问题,与sugov_update_single函数在于:
- 将sugov_get_util函数的调用,放到了锁的外面;
- 将sugov_set_iowait_boost和sugov_should_update_freq这两个函数的调用这两个函数的调用,放到了锁的里面;
- 目标频率的计算,改为sugov_next_freq_shared 函数来实现。
4.5.3 目标频率的计算-get_next_freq函数
该函数在sugov_update_single函数中被调用,适用于cluster里只有一个CPU的情形,或者说一个cpu独享一个policy的时候。简化代码如下所示:

-
对ARM体系结构而言,有目标频率的计算公式如下:
freqnext = 1.25 * freqmax * util / capacitymax
util / capacitymax ,也就是当前CPU使用率与该CPU的最大算力的比值等于0.8为临界点,当该系数小于 0.8会降频;超过0.8则会升频。
为什么会取1.25这个系数或者说将0.8作为临界点呢,其实这里0.8的意思是“当负载达到最大算力的80%就要选择升频了”,这样就有一定的提前量(猜测负载还会继续升高),如果这个值设置过小就会显得“太激进”,设置过大就显得“太保守”。当然这个值的设定也不是完全靠经验决定的,而是在这个feature的patch提出后经过linux kernel pm maillist成员的讨论、实测以及借鉴schedfreq的类似设定来决定的,更细节信息请参考patch讨论。
-
如果使用计算出来的目标频率和已缓存的频率相等,直接使用sg_policy->next_freq的值,省去了driver的映射查找的过程时间消耗。
4.4 目标频率的计算- sugov_next_freq_shared函数
该函数在sugov_update_shared函数中被调用,适用于cluster里有多个CPU的情形,或者说多个cpu共享一个policy的时候。简化代码如下:

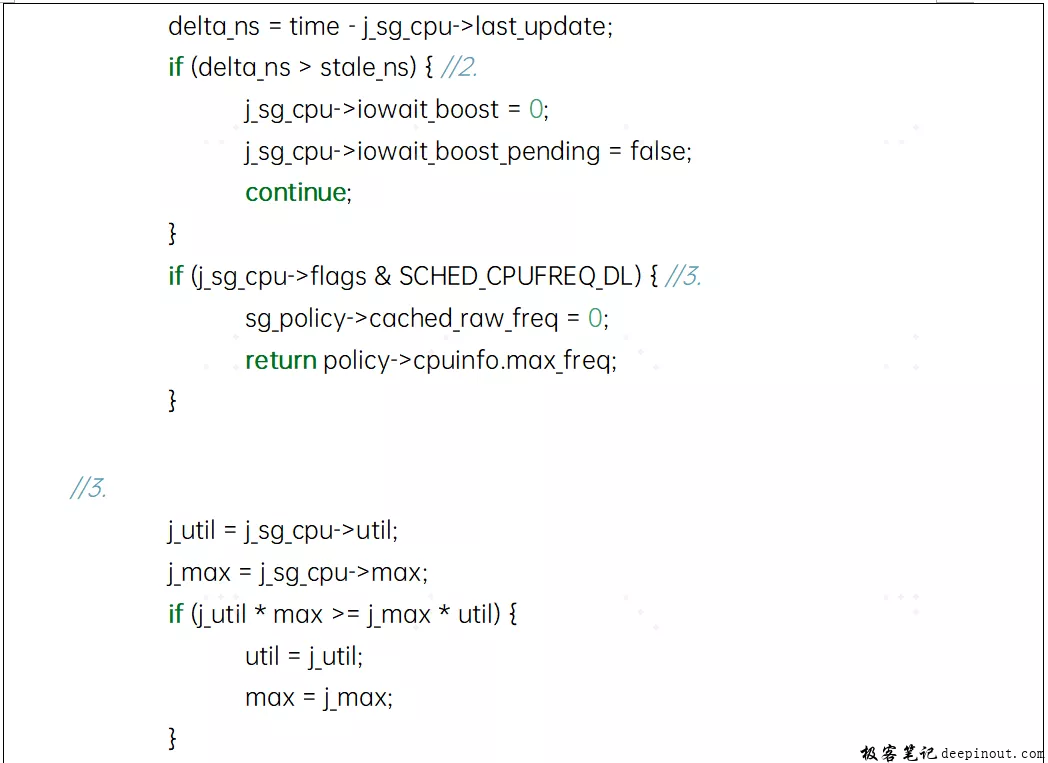
- 遍历所有共享policy的CPU(一个cluster里面的CPU),取CPU负载最重的那个CPU作为该cluster的所有CPU的目标频率。当然,也会对CPU的负载进行iowait_boost和WALT特有的boost(如果开启WALT的话)。
- 如果最后一次的CPU负载更新和频率更新的时间间隔足够长的话,很可能这个CPU处在idle态,该CPU略过(同时将iowait_boost相关状态清楚)直接考虑下一个CPU了。
- 取所有CPU中,使用率与CPU算力的比值最大的那个组合。
- 这部分代码的作用和sugov_update_single函数代码片段相同,不再赘述。
4.5 频率切换的执行-sugov_update_commit函数


- 目标频率与当前频率相等,直接返回
- schedutil为频率上下调分别设置了两个时间间隔,这个通过sysfs供用户空间配置,必须要大于这两个时间间隔才去执行频率切换动作。
- 如果支持快速切换功能,直接调用cpufreq_driver_fast_switch接口让driver切换频率(比如可以通过简单的读寄存器)
- 如果不支持快速切换功能,则需要去irq_work上去排队。通过依次调用sugov_irq_work和sugov_work这两个函数去执行调频请求,最后会调用__cpufreq_driver_target接口去完成调频切换的动作。
还有一些细节的代码,我们没有展开,不过不影响我们对核心逻辑的分析。
标签:sugov,调用,schedutil,函数,调速器,频率,调频,CPU From: https://www.cnblogs.com/linhaostudy/p/17183176.html