一,set集合
Collection集合的体系结构:
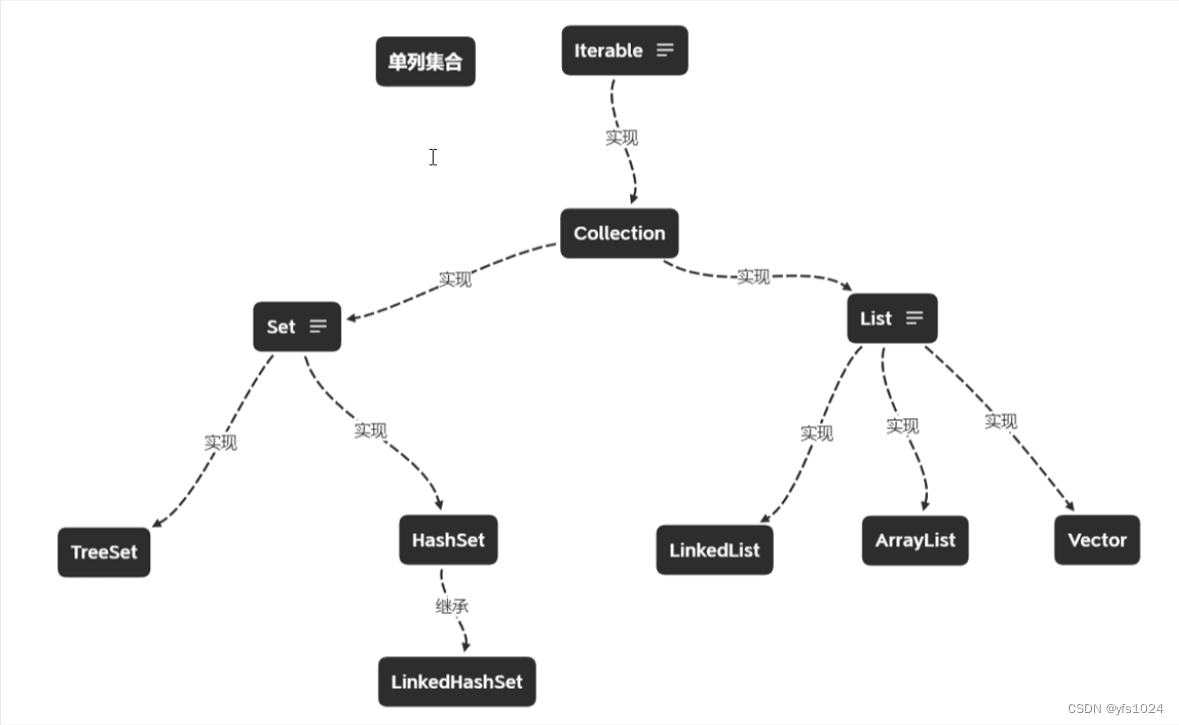
List集合的见上个笔记,这个主要来学习Set和Map中的类
1,Set集合的特点
Set系列集合的特点:无序 < 添加和取出的顺序不一致> :不重复,无索引
三个主要的实现类:
HashSet: 无序,不重复,无索引
LinkeHashSet: 有序,不重复,无索引
TreeSet : 用来排序,不重复,无索引
前面先学了他们父接口,Collection,当时有说到,因为父亲要兼顾子类的特性,所以父亲的方法都是中和与连个类的特性,存在的方法。比如,add 方法,clear方法,remove( E e),contains,idEmpty,size,toArray。等 很容易发现这些方法都是很中规中矩。但因为Set集合的特点其实Set集合也就这些方法。List比接口中多的也就无非哪些通过索引操作数据的方法。
即Set中常用的方法如下:
| 方法名 | 说明 |
|---|---|
| public boolean add(E e) | 把给定的对象添加到当前集合中 |
| public void clear() | 清空集合中所有的元素 |
| public boolean remove(E e) | 把给定的对象在当前集合中删除 |
| public boolean contains(Object obj) | 判断当前集合中是否包含给定的对象 |
| public boolean isEmpty() | 判断当前集合是否为空 |
| public int size() | 返回集合中元素的个数。 |
| public Object[] toArray() | 把集合中的元素,存储到数组中 |
2,HashSet集合的底层原理
首先先了解一个知识,Hash值:
- 就是一个int类型的数值,Java中每个对象都有一个哈希值。
- Java中的所有对象,都可以调用obejct类提供的hashCode方法,返回该对象自己的哈希值
先看Object中hashCode的源码:
@IntrinsicCandidate public native int hashCode();
native关键字说明其修饰的方法是一个原生态方法,方法对应的实现不是在当前文件,而是在用其他语言(如C和C++)实现的文件中。也就是说在java源码中看不到,但是我们可以从等下的对象重写的方法中知道这个方法是干什么的
这个算法其实就是根据传入的对象,然后通过内部的一通运算返回一个int值。
对象哈希值的特点<小重点>:
- 同一个对象多次调用hashCode()方法返回的哈希值是相同的。 <因为传入的参数一样,里面的运算一样,所以返回的数据肯定一样呀>
- 不同的对象,它们的哈希值一般不相同,但也有可能会相同(哈希碰撞)。<因为int的取值有限,那么传入参数之后的运算结果就有概率相同。很低,这个也称为哈希碰撞>
// hash碰撞
String s = "通话";
String s4 = "重地";
System.out.println(s.hashCode()); // 1179395
System.out.println(s4.hashCode()); // 1179395
HashSet集合的底层实现原理 : 基于哈希表实现,哈希表是一种增删改查数据,性能都较好的数据结构
JDk8之前: 哈希表 = 数组+ 链表
jdk8开始: 哈希表 = 数组+ 链表+红黑树
1,jdk8之前HashSet集合底层的原理, 哈希表 = 数组+ 链表
-
创建一个默认长度为16的数组,默认加载因子为0.75<下面介绍>,数组名为table
-
使用元素的哈希值对数组的长度的求余计算出应存入的位置。
-
判断是否为null,如果为null直接存入
-
如果不为null,表示在这个索引已经有其他的元素了,则调用equals方法比较是否相等,相等,则不存,不相等,则存入数组<当前位置的链表中>
a、 JDk 8 之前,新的元素存入数组,占老元素位置,老元素往链表上挂,
b、 JDk8 之后, 新元素直接挂载老元素下面 <又细微的提高了性能,没有了新老元素的来回折腾>
过程如下:( 兄弟们一定要学会做动图啊)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4QO2eflb-1677913057342)(C:\Users\57589\AppData\Roaming\Typora\typora-user-images\image-20230304092644817.png)]](/i/ll/?i=209e27ac695440979a64d2c230dddd20.png)
当添加第一个元素的时候,就会默认创建一个大小为16的数组。这里的两个球是两个对象,当存入的时候java会调用hashCode方法求出当前对象的Hash值,如果当前对象重写了,那么就调用自己的HashCode方法,如果没有就是Object的hashCode方法。这样就得到了当前对象的Hash值。然后用这个hash值对数组的长度求余,就得出了对应的索引。然后将当前元素存入对应的索引位置即可。如果当前位置已经有了,那么就通过equals比较,如果相同,就不添加,如果不相同,如下图,jdk8之前是对象1,占用对象2 的位置,对象2以链表的方式,接在对象1的后面。jdk8之后是直接链接在后面
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-PeWPFo00-1677913057343)(C:\Users\57589\AppData\Roaming\Typora\typora-user-images\image-20230304094007930.png)]](/i/ll/?i=23a3d2b5525a40cc91b382a7b5b11f78.png)
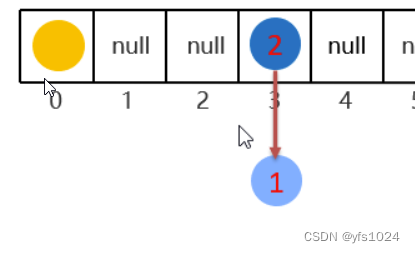
在说一下加载因子的作用,我们会发现在hash值对数组的长度求余之后得到了一个索引,但是问题是索引就16个,随着对象的增加,数组中的位置也会被占用,就取个极限,当前已经有15个了,那么就还有一个位置,这样很容易的就发生了hash碰撞,但是如果定义的空间太大,又很浪费内存资源,那么有没有一个很好的临界值,当然有,通过研究发现,也就是当前数组的 75%,即加载因子的0.75,即能保证空间的利用率最高,也能尽量的避免哈希碰撞
那么什么时候数组会扩容呢?一种情况是当数组中的大小超过了这个临界值,即 数组的长度 X 加载因子 ,这个时候就会扩容,扩容的规则是两倍的扩容。还有一种情况如下:
我们上面都是忽略了链表,这样好做分析,下面我们就从链表来看,我们会发现即使有了加载因子,也难免会发生hash冲突的问题。上面说到如果,冲突了,就会调用equals方法对两个对象作比较。如果相同则舍弃,如果不同则以链表的方式添加。取一个极端,就是对象中的hash值一直相同,但是通过equals方法比较之后的结果为false,那么就会一直在链表的尾部进行插入对象,如果不规定一个界限,这样子在查询的时候就会很慢,但是我们使用hash表的结构就是为了提高速度。怎么解决呢?java规定,如果这个链表的长度大于8时,就认为这个数组已经满了,很容易产生哈希碰撞。需要进行扩容,然后就会把16的数组扩容为32,如果单个链表的长度还是超过8或数组的长度超过了临界值 32 * 0.75,那么就会继续扩容。扩容到64。 如果某个链表的长度还是超过8,这次就不在扩容了,就会树化,把当前的链表转换为红黑树的数据结构 ,即JDK8开始,当链表长度超过8,且数组长度>=64时,自动将链表转成红黑树
如果我们想看到这种现象,我们可以在循环中new 一个自定义的对象,并且对象中重写了hashCode方法,没有重写equals方法<比较地址>,这个时候就会一直hash冲突,然后判断,不相等,一直扩容,知道树化。可以通过debug的方法查看细节
但是idea默认隐藏了细节,所以需要取消勾选这两个位置,就可以看到啦

上面提到了数据结构中树,为了防止忘记,就对树作一个复习:
最简单的树是二叉树
标签:Map,Set,map,对象,链表,Collections,集合,public From: https://www.cnblogs.com/yfs1024/p/17178372.html