前言 该系列教程旨在向计算机视觉领域入门者介绍当下流行的 OpenMMLab 框架,从计算机视觉领域多个基础任务入手,详细解读其基础知识、在 OpenMMLab 体系下的组织构建方式、基本使用方法,以及如何利用 OpenMM 系列算法进行自己的拓展和改进。
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
本教程禁止转载。同时,本教程来自知识星球【CV技术指南】更多技术教程,可加入星球学习。
本系列的目录结构如下:
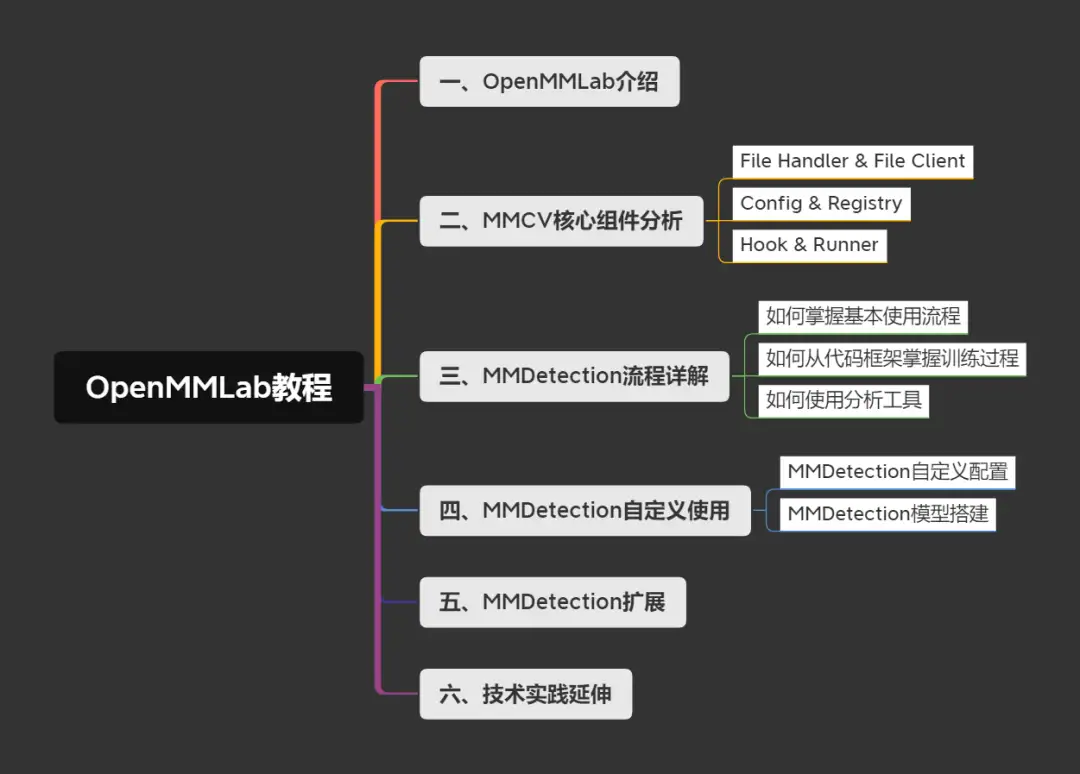
一、 OpenMMLab介绍
OpenMMLab 是一个用于学术研究和工业应用的开源算法体系,于2018年年中开始,由 MMLab(香港中文大学多媒体实验室)和商汤科技联合启动。OpenMMLab 致力于为计算机视觉领域的重要方向创建统一且开源的代码库,推进可复现算法生态的建立;目前为止 OpenMMLab 已经陆续开源30多个视觉算法库,实现了300多种算法,并包含2000+预训练模型,涵盖2D/3D目标检测、语义分割、视频理解、姿态分析等多个方向。
OpenMMLab算法库的特点:
- 模块化组合设计。将网络框架分解为不同组件,将数据集构建、模型搭建、训练过程设计等过程封装为模块,在统一而灵活的架构上,用户能够轻松组合调用不同的模块,构建自定义计算机视觉网络框架;
- 高性能。基于底层库MMCV,OpenMMLab中几乎所有基本运算操作都在GPU上运行,训练速度快;
- SOTA方法。开源框架中集成计算机视觉各个领域最新的先进算法,并且不断更新,使用者能够轻松使用新方法并进行改进。OpenMMLab系列项目的核心组件是MMCV,它是用于计算机视觉研究的基础Python库,支持OpenMMLab旗下其他开源库,是上述一系列上层框架的基础支持库,提供底层通用组件,灵活性强,可扩展性好。

图源OpenMMLab
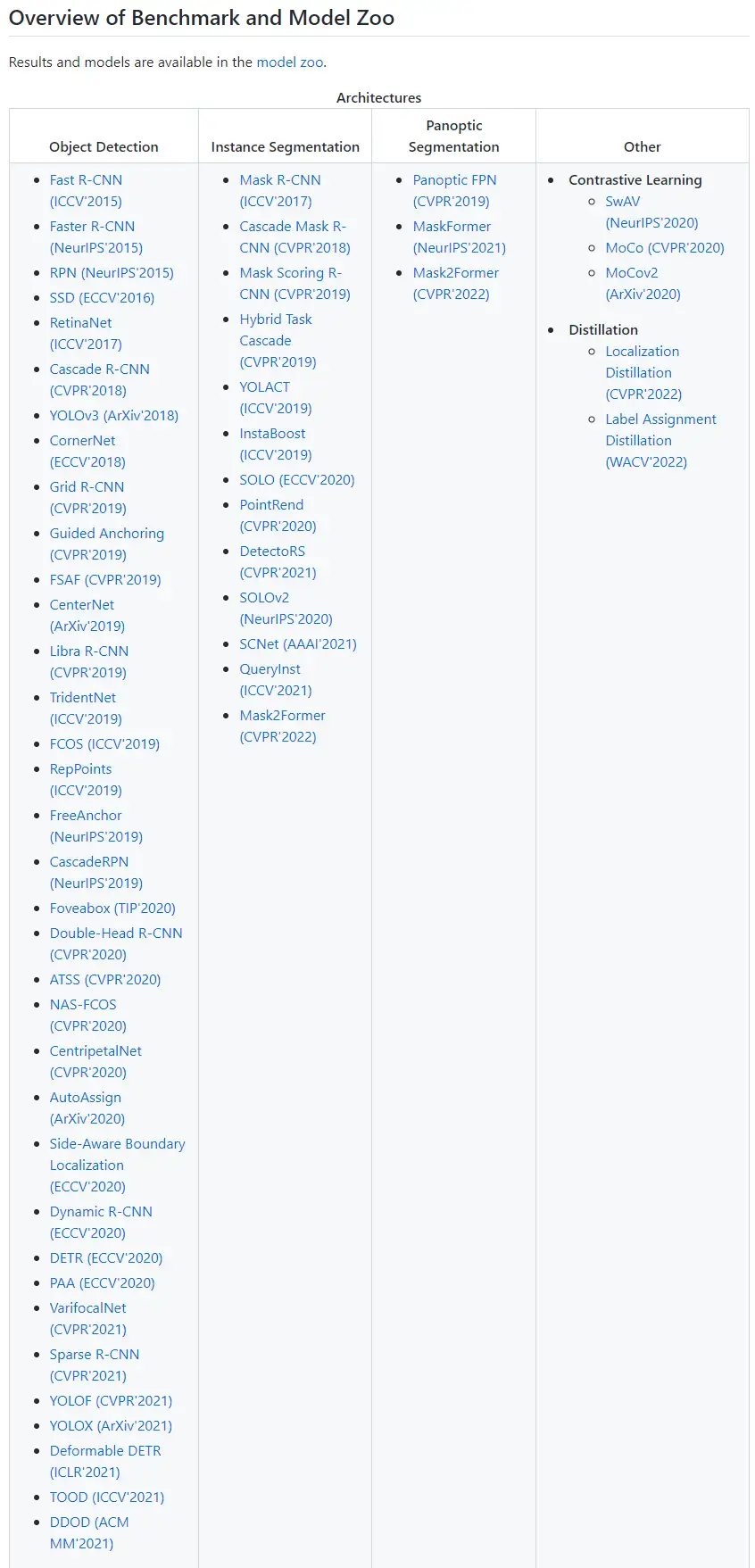
二、 MMDetection介绍与安装
OpenMMLab系列包含针对2D/3D目标检测的MMDetection/MMDetection3D、针对旋转目标检测的MMRotate、针对图像分割的MMSegmentation、针对目标追踪的MMTracking等多种算法库,它们均以Pytorch和MMCV为基础实现上层算法。
本系列教程从最具影响力的算法库MMDetection入手,来从零讲解OpenMMLab系列算法库的使用,由于MM系列算法库的搭建框架、使用方法基本相同,因此读者在掌握MMDetection的基础用法后,使用其他类别的算法库也能够快速上手。
MMDetection是一款基于PyTorch的开源目标检测工具箱,也是OpenMMLab最知名的开源库,包含目标检测、实例分割领域的基础框架数十种sota算法。目前在Github上已经收获21.7k star,也是本文重点介绍的视觉库。(项目地址](https://github.com/open-mmlab/mmdetection) )
图源OpenMMDetection
2.1 MMDetecion安装
在使用之前,搭建环境是一切的基础,首先使用Anaconda搭建虚拟环境,进行mmdetection安装。 下面介绍Linux、Windows下环境搭建、相关库(Pytorch、CUDA)版本选择,CPU、GPU平台安装的步骤;如果想在Google Colab下安装,或者使用Docker安装,可以参考官方的(https://github.com/open-mmlab/mmdetection/blob/master/docs/en/get_started.md)。
1)从头搭建MMDetection运行环境
1. 创建Anaconda虚拟环境
conda create --name openmmlab python=3.8 -y # python也可以选择其他版本
conda activate openmmlab2. 安装PyTorch 安装GPU版:conda install pytorch torchvision -c pytorch 安装CPU版:conda install pytorch torchvision cpuonly -c pytorch 使用conda命令安装时,anaconda会根据python版本自动安装对应版本的Pytorch和cudatoolkit等相关依赖项,因此不需要用户自己再去网上搜索版本对应关系安装,十分简便。
3. 安装MMCV库并编译
pip install -U openmim
mim install mmcv-full接着安装mmdetection库:
git clone https://github.com/open-mmlab/mmdetection.git
cd mmdetection
pip install -v -e . #进行编译
当然,如果想直接将mmdet作为第三方库使用,可以直接pip安装:
pip install mmdet2.2 MMDetecion简单使用
1)验证安装
在完成上述环境搭建过程后,我们如何确定自己的环境配置是否正确、能否开始运行代码了呢?官方给出了测试用的demo代码来确认你的环境是否就绪。 所使用的demo代码指的是mmdetection-master\mmdetection-master\demo\image_demo.py文件,它通过调用已有模型、加载已有权重来对图片内容进行目标检测推理,下面对其使用方法与内容进行介绍。
1. 下载权重文件 官网上以yolov3为示例,使用mim命令下载: mim download mmdet --config yolov3_mobilenetv2_320_300e_coco --dest . 下载完毕后能够在目录下找到yolov3_mobilenetv2_320_300e_coco.py和yolov3_mobilenetv2_320_300e_coco_20210719_215349-d18dff72.pth这两个文件,前者是yolov3的配置文件,包括四个基本组件:datasets、models、schedules和runtime,这些在后续会详细介绍;后者就是已经训练好的权重。
2. demo验证 使用Anaconda激活刚刚创建的虚拟环境,进入项目路径下执行运行命令:
python demo/image_demo.py demo/demo.jpg yolov3_mobilenetv2_320_300e_coco.py yolov3_mobilenetv2_320_300e_coco_20210719_215349-d18dff72.pth --device cpu --out-file result.jpg`
运行结束后,如果在自己的文件夹下多出`result.jpg`文件,并且如下图所示,成功检测到输入图片中的物体。说明环境安装配置成功,可以放心进行后续使用了。

demo.jpg检测效果
2)demo解读
好了,现在我们成功对一张图片完成了目标检测,并且进行可视化,但是这只是使用已训练好的权重、加载已有模型的推理过程,那么image_demo.py是如何对图片进行推理的呢?我们又该如何去构建自己的数据、训练自己的模型并进行推理呢?
后一个问题会在之后的章节中,从MMDetection训练、测试等过程为大家进行详细介绍,下面先对image_demo.py文件的内容进行详细解读: 首先是参数定义函数def parse_args():,它的内容与注释如下
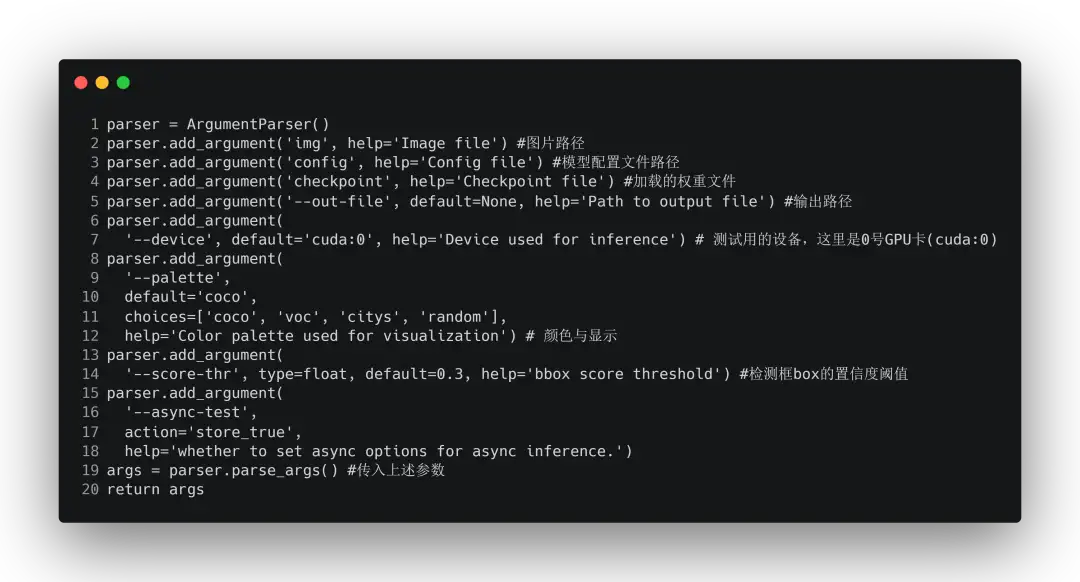
上面我们可以看到,在这个参数定义部分中,parser这个对象通过add_argument方法来添加参数,而我们执行测试代码的命令中就包含了这些参数的内容输入,如待测试的图片路径、下载的模型配置与权重、测试用的设备(cpu)等等。 其中参数解析<class 'argparse.Namespace'>的原理:通过上面的参数解析函数我们得到了一个返回形参args,这个对象是一个argparse.Namespace类的对象,这个类的属性便是我们上面定义的config、checkpoint等数据,通过访问这些属性便可以得到一个参数值,可见这个类起到一个“参数存储器”的作用——参数被解析器parser解析后用一个Namespace参数存储器存储起来。 接着在main函数中:
#build the model from a config file and a checkpoint file`
model = init_detector(args.config, args.checkpoint, device=args.device)这句代码由它的注释可以得知,它通过调用模块化函数init_detector来初始化模型,并访问Namespace对象的config等属性获取参数。在读取参数后就是推理过程,主要过程如下:先通过inference_detector来调用加载的模型对图片进行推理,获取预测结果result,然后通过函数show_result_pyplot在输入图像上绘制预测的结果(预测框、类别与置信度)。
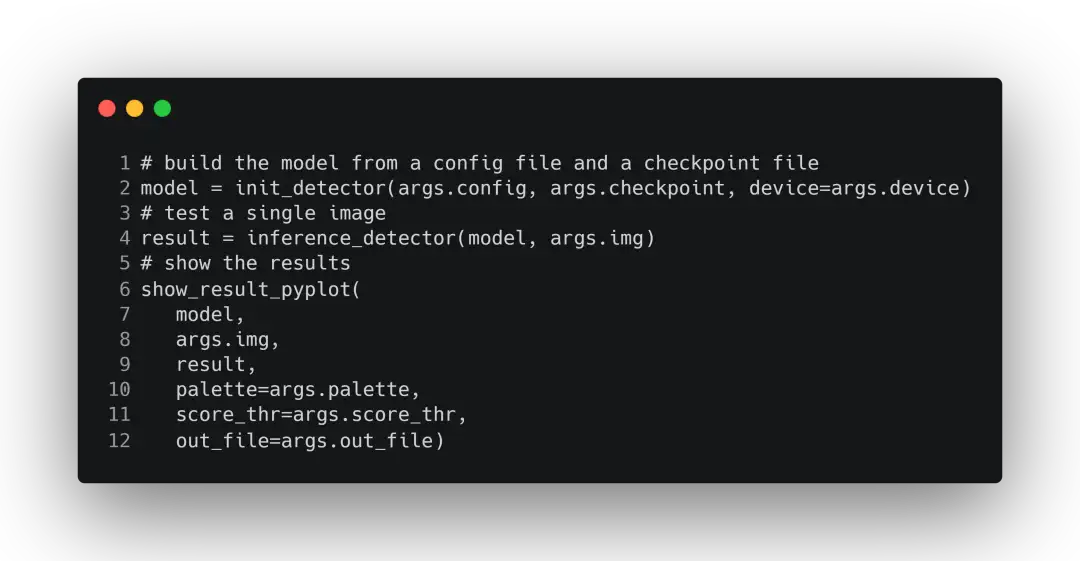
main函数完整内容
我们可以通过手动为参数赋值并设置断点,来查看main函数中涉及到的关键变量args、model与result的内容:
1. args

args的内容如上图,可以看到这里面就是我们传入的图片路径、模型文件、权重文件等参数,args本质上是一个参数储存器,为字典形式。
2. model
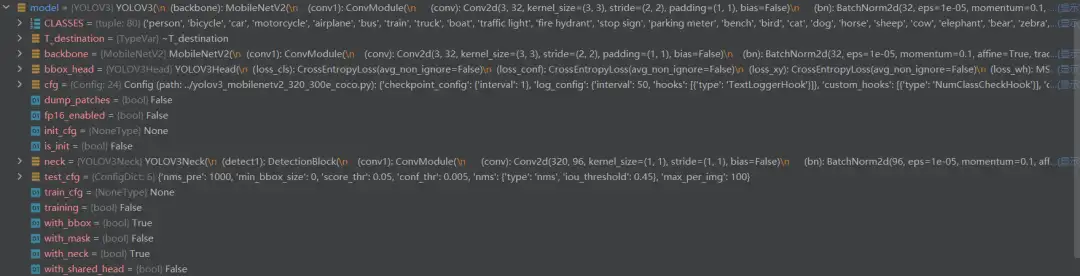
model的内容如上图,可以看到它以字典的形式储存了数据集格式(CLASSES,80类表示COCO数据集的类别)、YOLOV3模型的网络结构(backbone、bbox_head等组件,后续文章会详细解读)、以及测试方法test_cfg,其中包含了模型推理时的相关配置。另外需要注意的是,train_cfg的值为None,这是因为该模型仅在推理过程使用。
3. result
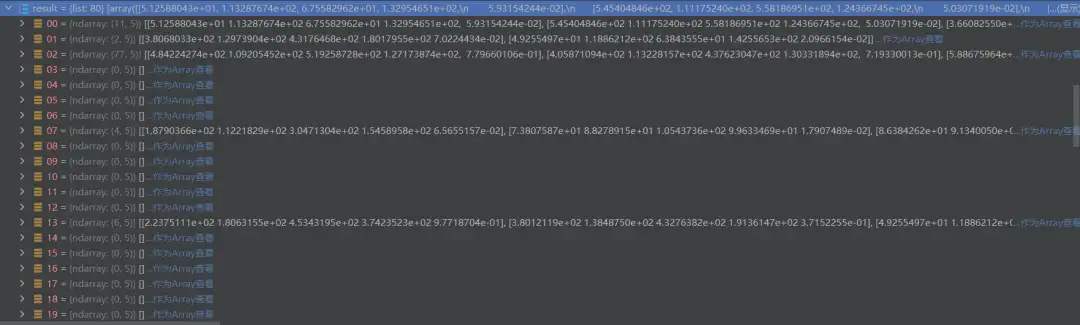
result的内容如上图,可以发现它是一个长度为80的列表list,80这个数字大家是不是很眼熟?这正是其对应的数据集COCO下的类别,也就是说推理得到的类别数量和训练是一样的。这个list中的每个元素都对应一个类别的预测内容,长度为(n,5),n为预测到的某一类别物体的数量,而5表示水平预测框的4个定位参数(xmin,ymin,xmax,ymax)+1个预测置信度,我们查看result[1]={ndarray:(2,5)}为例:
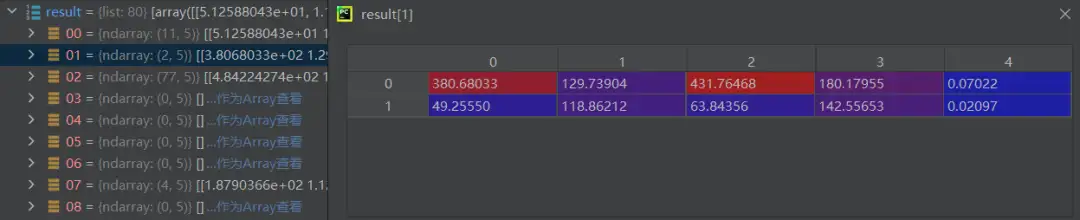
如上,预测到2个对象,数组给出它们的位置和预测置信度,可以发现这一类别的两个预测对象置信度较低,所以会被后处理过滤掉。
至此MMDetection的安装、测试以及demo运行部分便完成了,下一篇文章将结合代码,为大家先从OpenMMLab系列的底层模块MMCV讲起,解析它的核心组件和框架原理。
本教程禁止转载。同时,本教程来自知识星球【CV技术指南】更多技术教程,可加入星球学习。
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【技术文档】《从零搭建pytorch模型教程》122页PDF下载
QQ交流群:444129970。群内有大佬负责解答大家的日常学习、科研、代码问题。
其它文章
用于超大图像的训练策略:Patch Gradient Descent
CV小知识讨论与分析(5)到底什么是Latent Space?
CVPR 2023 Workshop | 首个大规模视频全景分割比赛
如何更好地应对下游小样本图像数据?不平衡数据集的建模的技巧和策
CVPR 2023 Workshop | 首个大规模视频全景分割比赛
如何更好地应对下游小样本图像数据?不平衡数据集的建模的技巧和策
用少于256KB内存实现边缘训练,开销不到PyTorch千分之一
DAMO-YOLO | 超越所有YOLO,兼顾模型速度与精度
入门必读系列(十六)经典CNN设计演变的关键总结:从VGGNet到EfficientNet
标签:教程,demo,算法,OpenMMLab,视觉,安装 From: https://www.cnblogs.com/wxkang/p/17159346.html