译者按: 最近一段时间,ChatGPT 作为一个现象级应用迅速蹿红,也带动了对其背后的大语言模型 (LLM) 的讨论,这些讨论甚至出了 AI 技术圈,颇有些到了街谈巷议的程度。在 AI 技术圈,关于 LLM 和小模型的讨论在此之前已经持续了不短的时间,处于不同生态位置和产业环节的人都有表达自己的观点,其中不少是有冲突的。
大模型的研究者和大公司出于不同的动机站位 LLM,研究者出于对 LLM 的突现能力 (emergent ability) 的好奇和对 LLM 对 NLP 领域能力边界的拓展、而大公司可能更多出自于商业利益考量;而社区和中小公司犹犹豫豫在小模型的站位上徘徊,一方面是由于对 LLM 最终训练、推理和数据成本的望而却步,一方面也是对大模型可能加强大公司数据霸权的隐隐担忧。但讨论,尤其是公开透明的讨论,总是好事,让大家能够听到不同的声音,才有可能最终收敛至更合理的方案。
我们选译的这篇文章来自于 2021 年 10 月的 Hugging Face 博客,作者在那个时间点站位的是小模型,一年多以后的 2023 年作者的观点有没有改变我们不得而知,但开卷有益,了解作者当时考虑的那些点,把那些合理的点纳入自己的思考体系,并结合新的进展最终作出自己的判断可能才是最终目的。
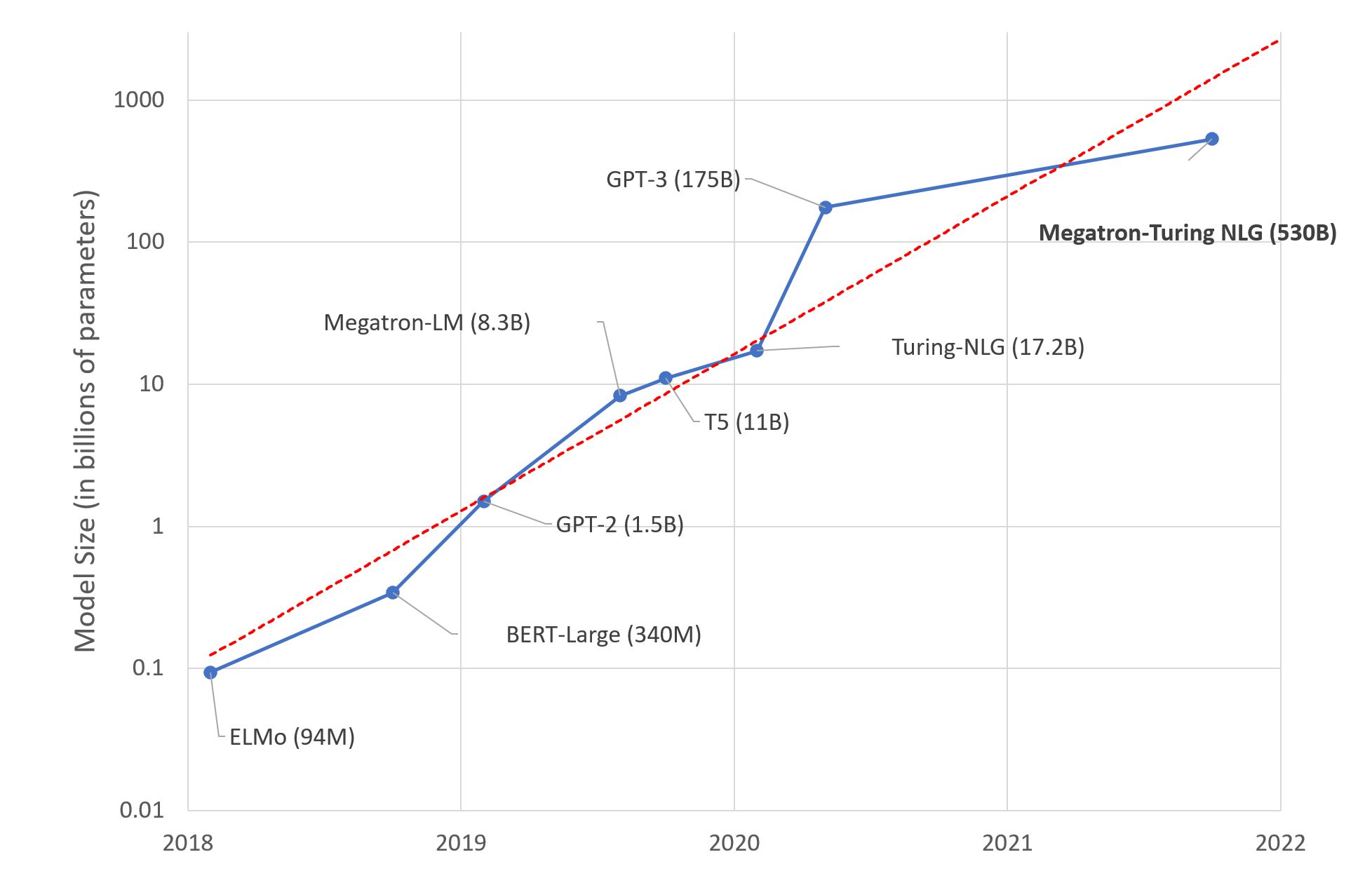
不久前,微软和 Nvidia 推出 了 Megatron-Turing NLG 530B,一种基于 Transformer 的模型,被誉为是 “世界上最大且最强的生成语言模型”。
毫无疑问,此项成果对于机器学习工程来讲是一场令人印象深刻的能力展示,表明我们的工程能力已经能够训练如此巨大的模型。然而,我们应该为这种超级模型的趋势感到兴奋吗?我个人倾向于否定的回答。我将在通过本文阐述我的理由。
这是你的深度学习大脑
研究人员估计,人脑平均包含 860 亿个神经元和 100 万亿个突触。可以肯定的是,这里面并非所有的神经元和突触都用于语言。有趣的是,GPT-4 预计 有大约 100 万亿个参数...... 虽然这个类比很粗略,但难道我们不应该怀疑一下构建与人脑大小相当的语言模型长期来讲是否是最佳方案?
当然,我们的大脑是一个了不起的器官,它经过数百万年的进化而产生,而深度学习模型仅有几十年的历史。不过,我们的直觉告诉我们: 有些东西无法计算 (这是个双关语,
标签:语言,训练,摩尔定律,Hugging,Face,学习,LLM,模型 From: https://www.cnblogs.com/huggingface/p/17139085.html