4次迭代,让我的HttpClient提速100倍
在大家的生产项目中,经常需要通过Client组件(HttpClient/OkHttp/JDK Connection)调用第三方接口。
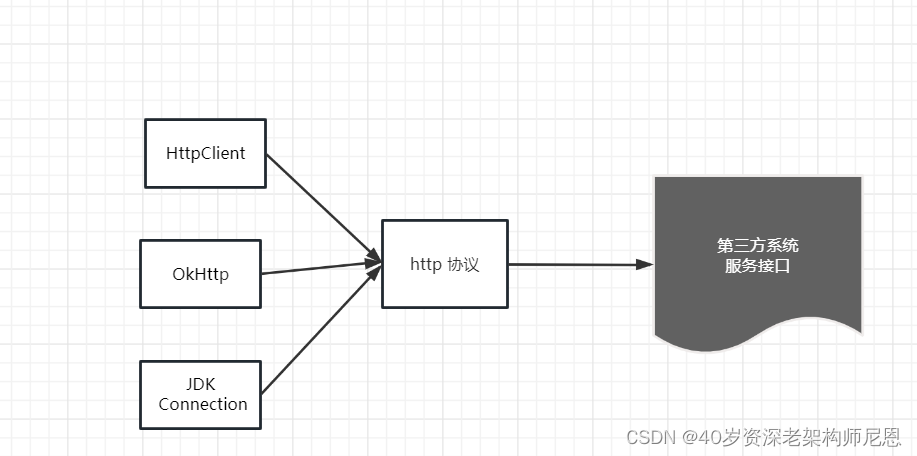
尼恩的一个生产项目也不例外。
在一个高并发的中台生产项目中。有一个比较特殊的请求,一次请求,包含 10个 Web 外部服务调用,每个服务调用的预定时间200ms。
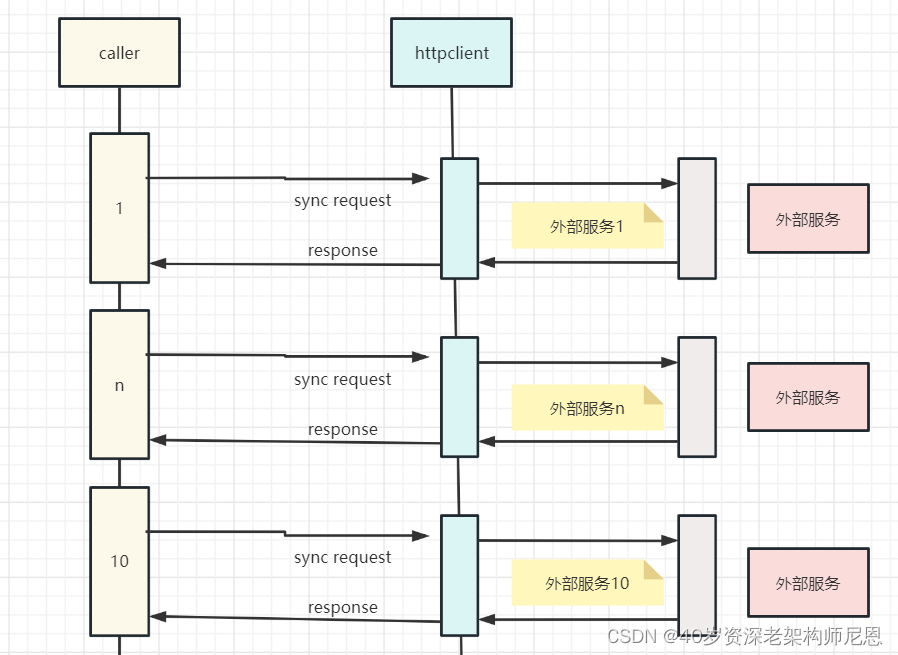
为了并行,使用了一个很大的线程池,最大100个线程。
注意,这里100个线程已经很多了,因为其他的环节也需要很多线程。所以不能太多了。
尼恩和团队小伙伴经过4次迭代,把这个客户端调用不断提升,最终的提升了100倍。
为啥写此文呢?
尼恩最近在指导小伙伴的简历,发现很多小伙伴没有素材,简历写得太low、太low。在尼恩读者50+交流群中,尼恩经常指导小伙伴改简历。 改简历所涉及的一个要点是:
在 XXX 项目中,完成了 XXX 模块的代码优化
另外,在面试的过程中,面试官也常常喜欢针对提问,来考察候选人对代码质量的追求、对设计模式的应用能力:
你做过哪些代码优化?
大家一般的套路,都是通过模板模式、策略模式等,完成 XXXXX 模块的重构,提升代码的可扩展行,可维护性。
如果有类似扩展场景、类似优化经历的小伙伴还好。
头疼的是,很多小伙伴确实没有。然后无奈的说,没有做过代码的优化。
所以,为了能帮到大家,上一次给大家提供了一个人人可用的、涉及到切面思想、非常高明的的代码优化点:
阿里一面:你做过哪些代码优化?来一个人人可以用的极品案例
这一次又是一个大大的代码优化、性能优化点,甚至比上次的更为出彩。固,尼恩通过这个文章,把Client性能提升100倍的迭代过程记录下来,再一次为大家提供一个代码优化的参考答案。
大家可以对着实操一下,然后写入简历,为简历增加一个不小的亮点。当然,如果确实不知道怎么优化简历,可以来找40岁老架构师尼恩。
接下来看看,尼恩团队是怎么做到的。
注:本文以 PDF 持续更新,最新尼恩 架构笔记、面试题 的PDF文件,请从这里获取:码云
第1次迭代:使用 CompletableFuture 完成并发
最早的代码,是通过向线程池中提交任务的方式完成的,从代码的优雅程度上来说,比使用CompletableFuture 的方式,差得太远。
所以,第1轮迭代,是通过CompletableFuture进行代码的优化。这个环节,对性能没有本质的提升,但是CompletableFuture 这种 函数式编程的风格,为后面的迭代打下来一些技术基础。
使用CompletableFuture 并发10个远程api 接口,有两个方法
- 方法1:CompletableFuture 和 CountDownLatch
- 方法2:CompletableFuture.allOf 算子
在代码实现的时候,使用了结合使用CompletableFuture 和 CountDownLatch 进行并发回调

为了大家能体验效果,给大家提供了一段原始代码的参考程序,具体如下:
package com.crazymaker.springcloud;
import com.crazymaker.springcloud.common.util.ThreadUtil;
import org.junit.Test;
import java.util.concurrent.CompletableFuture;
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.ExecutorService;
public class CoCurrentDemo {
/**
* 使用CompletableFuture 和 CountDownLatch 进行并发回调
*/
@Test
public void testMutiCallBack() {
CountDownLatch countDownLatch = new CountDownLatch(10);
//批量异步
ExecutorService executor = ThreadUtil.getIoIntenseTargetThreadPool();
long start = System.currentTimeMillis();
for (int i = 0; i < 10; i++) {
CompletableFuture<Long> future = CompletableFuture.supplyAsync(() -> {
long tid = ThreadUtil.getCurThreadId();
try {
doRpc(tid); //异步执行 远程调用
} catch (InterruptedException e) {
e.printStackTrace();
}
return tid;
}, executor);
future.thenAccept((tid) -> {
System.out.println("线程" + tid + "结束了");
countDownLatch.countDown();
});
}
try {
countDownLatch.await();
//输出统计结果
float time = System.currentTimeMillis() - start;
System.out.println("所有任务已经执行完毕");
System.out.println("运行的时长为(ms):" + time);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
private void doRpc(long tid) throws InterruptedException {
System.out.println("线程" + tid + "开始了,模拟一下远程调用");
Thread.sleep(200);
}
}
尼恩提示:CompletableFuture 的知识,非常重要。具体请大家去阅读尼恩在清华大学出版社出版的《Java 高并发核心编程 卷2 加强版》。
很多小伙伴和尼恩说:这本书写得太好,之前读博客的时候,很多高并发的知识看不懂的,通过卷2加强版,都看懂了。
第2次迭代:响应式 Flux 流进行异步回调改造
回顾一下咱们这个优化的案例:一次请求,触发 10 个 Web 服务调用。
什么分析一下,发现一个秘密:执行一次WEB调用操作所需的实际工作非常少。实际的工作就2点:
- 生成并触发一个请求
- 等等一段时间,会收到一个响应。
而且,其中有一个节非常低性能,这个环节是:在请求和响应之间,线程根本没有做任何工作,而且在等待,等待200ms。
线程资源是宝贵的。咱们一个java应用不能开始太多的线程,一般最多就400个左右。如果开启太多,很多的cpu资源就用去做线程上下文切换了。
如何要让这些线程不等待,去干别的工作,该当如何?
这是使用异步框架。使用异步框架发出 Web 请求的核心优势之一,在请求进行中时您不会占用任何线程。第2次迭代:响应式 Flux 流进行异步回调改造。

使用异步框架的核心逻辑,如下所以:
Flux.range(0,100)
.subscribeOn(Schedulers.boundedElastic())
.flatMap(i -> webClientCallApi(i))
.subscribe(...) //定义结果
响应式的本质,是回调。其原理,具体请参考 尼恩的深度文章:《京东一面:20种异步,你知道几种?含协程》
响应式编程门槛非常高,学习曲线很长。但是一旦掌握了其编程的风格之后,其实也就简单了。
有关响应式编程的内容,尼恩给大家准备了一本10W字的《响应式 圣经,pdf可以找尼恩获取》
在响应式框架中,我们的线程不用再死耗了,底层的逻辑是:把异步任务加入响应式组件的内部的队列之后,就去干起别的事情了,不需要去死死等200ms。
so,我们进行了第2次迭代:响应式Flux流进行异步回调改造。
为了大家能体验效果,给大家提供了一段原始代码的参考程序,具体如下:
private Flux<Integer> doRpcFlux(int key) {
return Flux.create(sink -> {
log.info("模拟远程调用,参数为:" + key);
ThreadUtil.sleepMilliSeconds(100);
sink.next(key);
sink.complete();
});
}
@Test
public void mergeTest5() throws InterruptedException {
long startTime = LocalTiker.SINGLETON.now();
Iterable<Integer> targetKeys = Arrays.asList( 101, 102, 103, 104, 105);
Flux.fromIterable(targetKeys)
.publishOn(Schedulers.fromExecutorService(
ThreadUtil.getMixedTargetThreadPool()))
.flatMap(key -> doRpcFlux(key))
.doOnError(ReactorPrallelDemo::doOnError)
.doOnComplete(ReactorPrallelDemo::doOnComplete)
.doFinally(signalType -> log.info("并发执行的时间: " + LocalTiker.SINGLETON.gapFrom(startTime)))
.subscribe(responseData -> log.info(responseData.toString()), e -> log.info("error:" + e.getMessage()));
Thread.sleep(200000);
}
第3次迭代:响应式 parallel Flux 流进行并行异步回调改造
在刚开始使用响应式编程的时候,感觉也没有耗费太长时间,就把传统的命令式代码,切换到了响应式的风格,不免洋洋得意。
第2次迭代响应式Flux流进行异步回调改造,以为十全十美,改造成功了。

实际不然,改造之后,虽然线程资源得到了有效的利用。但是由于前期对flux流的机制,不是太清楚。实际上的情况是,性能反而下降了。
实际上,flux的内部机制:flux流里边的任务,默认是串行执行的。
所以上面的代码,实际上是让10次调用 串行执行。初心是并行,实际上适得其反,变成了串行,性能反而大大下降。
怎么回到并行呢?需要使用 Flux parallel流。
下面是一段 使用paralle Flux 的demo:
Flux.range(0,100)
.parallel()
.runOn(Schedulers.boundedElastic())
.flatMap(i -> webClientCallApi(i))
.sequential().collecttoList();
so,我们进行了第3次迭代:响应式 parallel Flux 流进行并行异步回调改造。

为了大家能体验效果,给大家提供了一段原始代码的参考程序,具体如下:
@Test
public void mergeTest6() throws InterruptedException {
long startTime = LocalTiker.SINGLETON.now();
Iterable<Integer> targetKeys = Arrays.asList(100, 101, 102, 103, 104, 105, 106, 107);
Flux.fromIterable(targetKeys)
.parallel()
.runOn(Schedulers.fromExecutorService(ThreadUtil.getMixedTargetThreadPool()))
.flatMap(key -> doRpcFlux(key))
.sequential()
.doOnError(ReactorPrallelDemo::doOnError)
.doOnComplete(ReactorPrallelDemo::doOnComplete)
.doFinally(signalType -> log.info("并发执行的时间: " + LocalTiker.SINGLETON.gapFrom(startTime)))
.subscribe(i -> log.info("->" + i));
Thread.sleep(200000);
}
private static void doOnComplete() {
log.info("并发远程调用异常完成");
}
运行的结果如下:
12:31:34.138 [Biz-1-cpu-2] INFO com.crazymaker.springcloud.user.main.ReactorPrallelDemo - this taskB start
12:31:34.138 [Biz-1-cpu-1] INFO com.crazymaker.springcloud.user.main.ReactorPrallelDemo - this taskA start
12:31:34.227 [main] DEBUG reactor.util.Loggers$LoggerFactory - Using Slf4j logging framework
12:31:34.296 [Biz-2-mixed-18] INFO com.crazymaker.springcloud.user.main.ReactorPrallelDemo - 模拟远程调用,参数为:101
12:31:34.296 [Biz-2-mixed-22] INFO com.crazymaker.springcloud.user.main.ReactorPrallelDemo - 模拟远程调用,参数为:105
12:31:34.296 [Biz-2-mixed-23] INFO com.crazymaker.springcloud.user.main.ReactorPrallelDemo - 模拟远程调用,参数为:106
12:31:34.296 [Biz-2-mixed-24] INFO com.crazymaker.springcloud.user.main.ReactorPrallelDemo - 模拟远程调用,参数为:107
12:31:34.296 [Biz-2-mixed-20] INFO com.crazymaker.springcloud.user.main.ReactorPrallelDemo - 模拟远程调用,参数为:103
12:31:34.296 [Biz-2-mixed-21] INFO com.crazymaker.springcloud.user.main.ReactorPrallelDemo - 模拟远程调用,参数为:104
12:31:34.296 [Biz-2-mixed-17] INFO com.crazymaker.springcloud.user.main.ReactorPrallelDemo - 模拟远程调用,参数为:100
12:31:34.296 [Biz-2-mixed-19] INFO com.crazymaker.springcloud.user.main.ReactorPrallelDemo - 模拟远程调用,参数为:102
12:31:34.398 [Biz-2-mixed-20] INFO com.crazymaker.springcloud.user.main.ReactorPrallelDemo - 并发执行的结果->103
12:31:34.398 [Biz-2-mixed-20] INFO com.crazymaker.springcloud.user.main.ReactorPrallelDemo - 并发执行的结果->100
12:31:34.398 [Biz-2-mixed-20] INFO com.crazymaker.springcloud.user.main.ReactorPrallelDemo - 并发执行的结果->101
12:31:34.398 [Biz-2-mixed-20] INFO com.crazymaker.springcloud.user.main.ReactorPrallelDemo - 并发执行的结果->102
12:31:34.398 [Biz-2-mixed-20] INFO com.crazymaker.springcloud.user.main.ReactorPrallelDemo - 并发执行的结果->104
12:31:34.398 [Biz-2-mixed-20] INFO com.crazymaker.springcloud.user.main.ReactorPrallelDemo - 并发执行的结果->105
12:31:34.398 [Biz-2-mixed-20] INFO com.crazymaker.springcloud.user.main.ReactorPrallelDemo - 并发执行的结果->106
12:31:34.398 [Biz-2-mixed-20] INFO com.crazymaker.springcloud.user.main.ReactorPrallelDemo - 并发执行的结果->107
12:31:34.398 [Biz-2-mixed-20] INFO com.crazymaker.springcloud.user.main.ReactorPrallelDemo - 并发远程调用异常完成
12:31:34.398 [Biz-2-mixed-20] INFO com.crazymaker.springcloud.user.main.ReactorPrallelDemo - 并发执行的时间: 105
响应式Flux parallel流进行并行异步回调改造,看上去已经圆满了。
终于,尼恩和小伙伴实现了两个效果:
- 并行
- 没有线程阻塞等待(异步回调)
还有点问题没有解决,就是底层组件是httpclient,没有使用异步非阻塞的netty组件。虽然底层IO组件还是存在线程阻塞,只是这个下一次迭代再说。
至少从业务维度,第三次迭代之后,没有线程阻塞等待。
接下来,说说parallel Flux并行 流的使用场景和基础原理。因为尼恩的社群中,经常有这块的生产问题,被小伙伴抛出来。说明这个组件,在生产场景有很大的使用价值。
parallel Flux 流的使用场景
Flux 本质上是将通量元素划分为单独的轨道,元素之间是串行。
Flux parallel 模式,就是将通量元素划分为并行的轨道,才是真正并行的。
Flux parallel 并行流,在生产场景,经常用到。
下面是来自尼恩的社群50+群中的一个生产问题:
@架构师尼恩
假设我上游有一个元素,下游需要根据这个元素有多个Task处理,但是需要等多个Task处理完成后才能返回,如果我不用ConnectFlux的话 ,还有什么其他方法解决吗?
类似于 Mono.just(1).map(a-> { executeTaskA(a); executeTaskB(a); }).subscribe();
我这个executeTaskA 和 executeTaskB 是并行操作的,不存在依赖关系
以上这样的生产问题,都可以使用并行流。
parallel Flux 的底层原理
1. parallel FLux 分配上游元素过程是
parallel操作符执行过后,会生成一个新的flux 即parallelFLux。parallelFLux能够接受多个订阅者,他会从原始flux中请求perfetch个元素,将上游传递push过来的元素依次按顺序分配给子订阅者。
parallelFLux分配上游元素过程是:
依次分配给下游每个订阅者,当某个子订阅者请求数已经满足时,将跳过此订阅者继续向下一个子订阅者分配。
他有两个参数 parallelism 和 prefetch,
- parallelism 第一个参数表示划分子流的数量,默认等于cpu核心数,
- prefetch表示向原始流预取的数量。
parallel本质上是包装每个子订阅者,将接受到的数据存入子订阅者的queue中,然后使用线程池处理queue内的数据。
2. parallel 操作符后接 map/flapMap 操作符
map/flapMap操作符会将真实订阅者生成代理,他将上游onNext的值使用map/flapMap操作符进行转换。
在parallelFlux场景下,它会将每个子订阅者包装起来进行转换。
3. parallel 后面可以接 sequential 操作符
sequential 可以将parallelFlux转成普通flux,
他的原理是创建parallel需要的子订阅者,使用子订阅者订阅parallelFlux,然后将数据依次从每个子订阅者中获取到数据,向下游发送。
在sequential操作执行时,数据可能来自多个线程,这里采用的是哪个线程先到则负责将其他子订阅者队列中的值向下发,没获取到锁的线程存入队列直接退出。
sequential允许传递参数,表示每个子订阅者身上能存储的元素最大数。
4.parallel 后接 runOn 操作符
parallel本质上是包装每个子订阅者,将接受到的数据存入子订阅者的queue中,然后使用线程池处理queue内的数据。
runOn处理的逻辑也是和上面sequential类似,使用AtomicInteger限制每个子订阅者同时只会有一个线程在执行,如果当前已经存在一个线程在执行,后来的数据存入queue后会直接退出。
它还可以传递第二个参数表示每个子订阅者预取的数量,这里为什么要预取呢?
是因为如果下游订阅者请求了非常大的数量,而runOn将任务分配到线程池中本身是非堵塞的,也就是任务全部堆积在线程池中,可能导致内存溢出。所以使用预取参数分批次满足下游的请求数量。
第4次迭代:响应式 WebClient 组件去掉底层的io线程阻塞
对于客户端调用要提升100倍,没有那么容易。
路漫漫其修远,尼恩团队上下求索。
虽然httpclient也支持高性能的nio 模式,但是httpclient 线程模型是阻塞的,httpclient没有和Netty这样的reactor反应器线程模型。
httpclient底层的io线程是阻塞式的,具体如下图:
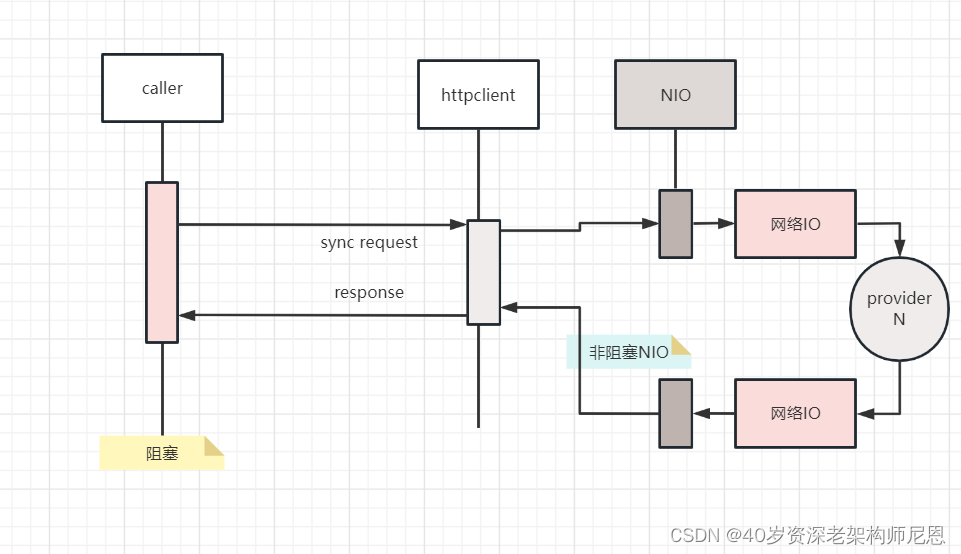
Netty这样的reactor反应器线程模型,底层的io线程是非阻塞式的
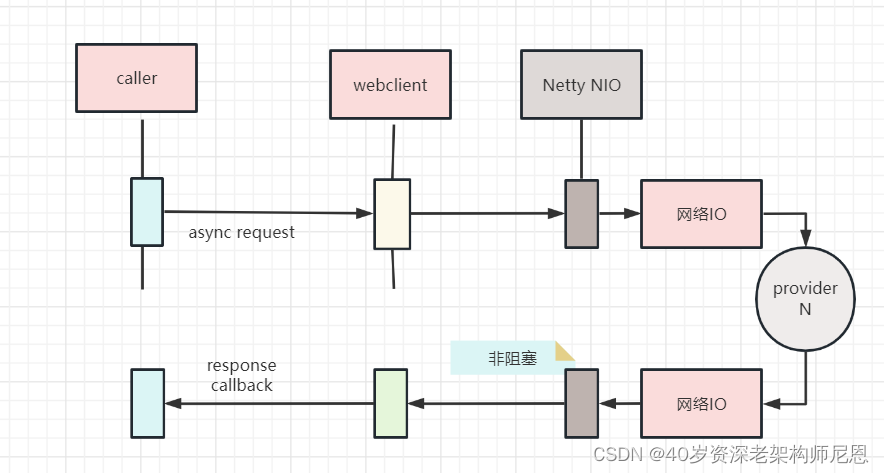
所以,要彻底提升性能,底层需要非阻塞。
如果底层的io传输,也需要使用反应器线程,怎么办? 3个措施:
- 那么要么使用netty,
- 要么使用基于netty的http组件。
- 或者基于netty自己进行封组
这里,使用了响应式的http组件,WebClient组件。使用 WebClient 进行了第四次迭代。

为了大家能体验效果,给大家提供了一段原始代码的参考程序,具体如下:
@Test
public void mergeTest7() throws InterruptedException {
long startTime = LocalTiker.SINGLETON.now();
Iterable<Integer> targetKeys = Arrays.asList( 101, 102, 103, 104, 105);
Flux.fromIterable(targetKeys)
.parallel()
.runOn(Schedulers.fromExecutorService(ThreadUtil.getMixedTargetThreadPool()))
.flatMap(key -> doRpcUseWebClient(key))
.sequential()
.doOnError(ReactorPrallelDemo::doOnError)
.doOnComplete(ReactorPrallelDemo::doOnComplete)
.doFinally(signalType -> log.info("并发执行的时间: " + LocalTiker.SINGLETON.gapFrom(startTime)))
.subscribe(responseData -> log.info(responseData.toString()), e -> log.info("error:" + e.getMessage()));
Thread.sleep(200000);
}
private Flux<RestOut<JSONObject>> doRpcUseWebClient(int key) {
//响应式客户端
WebClient client = null;
WebClient.RequestBodySpec request = null;
//方式一:极简创建
//方式二:使用builder创建
client = WebClient.builder()
.baseUrl("")
.defaultHeader(HttpHeaders.CONTENT_TYPE, "application/json")
.defaultHeader(HttpHeaders.USER_AGENT, "Spring 5 WebClient")
.build();
String restUrl = "http://crazy.api/demo/hello/v1?key=" + key;
/**
* 是通过 WebClient 组件构建请求
*/
request = client
// 请求方法
.method(HttpMethod.GET)
// 请求url 和 参数
// .uri(restUrl, params)
.uri(restUrl)
// 媒体的类型
.accept(MediaType.APPLICATION_JSON);
WebClient.ResponseSpec retrieve = request.retrieve();
// 处理异常 请求发出去之后判断一下返回码
retrieve.onStatus(status -> status.value() == 404,
response -> Mono.just(new RuntimeException("Not Found")));
ParameterizedTypeReference<RestOut<JSONObject>> parameterizedTypeReference =
new ParameterizedTypeReference<RestOut<JSONObject>>() {
};
// 返回流
Mono<RestOut<JSONObject>> resp = retrieve.bodyToMono(parameterizedTypeReference);
return Flux.from(resp);
}
终于,让我的 HttpClient 提速100倍
最终,通过测试的验证,实际效果提升了100多倍。
这里咱们从理论上计算一下,这里的4次迭代,为啥能够提升了100多倍?
假设一次请求的10个 Web 外部服务调用,每个服务调用的预定时间200ms,使用了100个线程的线程池
那么:100个线程,同时可以并发完成10个请求,1s可以并发50个请求,吞吐量为 50qps
经过异步改造之后,线程没有任何阻塞,在网卡(千兆)限制范围内 + 和后端的吞吐量保证 下,可以轻松实现5000qps,甚至更多。

最终,性能轻松提速了100倍+。
说在最后
以上内容作为生产案例,收录于《响应式圣经 V2》供大家学习和参考,此书pdf电子版,可以找尼恩获取。
另外,很多小伙伴的小伙伴没有技术亮点,可以参考这个案例,做个实操,然后作为一个小亮点放到简历里边。如果不会刷入简历,可以来找尼恩做简历指导。
在云原生时代、高并发时代,很多底层组件都开始响应式编程,所以响应式编程将会越来越流行。
虽然说,响应式编程虽然很晦涩难懂,但是掌握了、习惯了后,其实也就那么回事,反而会享受响应式编程的优雅。
关于响应式编程的技术问题,可以来找尼恩交流。 最后,送大家一本不断迭代的电子书,帮助大家在响应式时代,游刃有余。

推荐阅读:
《全链路异步,让你的 SpringCloud 性能优化10倍+》
《阿里一面:谈一下你对DDD的理解?2W字,帮你实现DDD自由》
《阿里一面:你做过哪些代码优化?来一个人人可以用的极品案例》
《阿里二面:千万级、亿级数据,如何性能优化? 教科书级 答案来了》
《峰值21WQps、亿级DAU,小游戏《羊了个羊》是怎么架构的?》
《Springcloud gateway 底层原理、核心实战 (史上最全)》
《分库分表 Sharding-JDBC 底层原理、核心实战(史上最全)》
《clickhouse 超底层原理 + 高可用实操 (史上最全)》
《队列之王: Disruptor 原理、架构、源码 一文穿透》
《环形队列、 条带环形队列 Striped-RingBuffer (史上最全)》
《一文搞定:SpringBoot、SLF4j、Log4j、Logback、Netty之间混乱关系(史上最全)》
《缓存之王:Caffeine 源码、架构、原理(史上最全,10W字 超级长文)》
标签:迭代,springcloud,Flux,Client,线程,100,com,ReactorPrallelDemo From: https://www.cnblogs.com/crazymakercircle/p/17136216.html