1 题目
原题链接。

2 想法
题目本质上是一条拓扑排序的题,只不过,在拓扑排序的基础上,加上了一个时间的限制。每门课程规定了需要一定的时间完成,也就是说,完成一门课程的时间,需要根据先修课程确定。
拓扑排序可以使用广搜配合入度数组去处理,而计算某一门课程的时间,需要根据先修时间确定。可以肯定的是,如果一门课程没有先修课程,那么修这门课程的时间,就是time数组中的时间。
而如果一门课程有先修课程,容易想到,需要根据最大的一门先修课程时间去确定,比如课程3的先修课程是课程1和课程2,假设:
课程1需要花费的单位时间为3课程2需要花费的单位时间为5
那么,课程3需要花费的时间就是max(课程1,课程2)+课程3的时间,也就是取课程1和课程2最大值再加上修课程3的时间。
这样,可以推测,如果一门课程n+1有n门先修课程,那么修课程n+1的时间,就是这修n门课程的最大值,再加上修课程n+1的时间。这实际上就是一个简单的动态规划:
dp[n+1] = max(dp[0]..dp[n])+time[n+1]
3 实现
代码有很详细的注释:
import java.util.*;
public class Solution {
public int minimumTime(int n, int[][] relations, int[] time) {
// 时间dp,注意存储的是dp[1]..dp[n]
int[] dp = new int[n + 1];
// 存储入度,为了方便计算同样开了n+1
int[] inDegree = new int[n + 1];
// 邻接表
List<List<Integer>> list = new ArrayList<>();
for (int i = 0; i <= n; i++) {
list.add(new ArrayList<>());
}
// 通过邻接表建图
for (int[] r : relations) {
// 更新入度
++inDegree[r[1]];
list.get(r[0]).add(r[1]);
}
// 广搜队列
LinkedList<Integer> queue = new LinkedList<>();
for (int i = 1; i <= n; i++) {
// 如果入度为0
if (inDegree[i] == 0) {
// 可以直接设置dp[i]的值,因为入度为0代表课程i没有先修课程
dp[i] = time[i - 1];
// 加入广搜队列
queue.addLast(i);
}
}
// 广搜队列不为空
while (!queue.isEmpty()) {
// 获取当前队列大小
int size = queue.size();
// 遍历当前队列中入度为0的课程
for (int i = 0; i < size; i++) {
// 出队
int front = queue.pollFirst();
// 获取先修课程指向的是哪些课程
for (int v : list.get(front)) {
// 课程v的时间是dp[v]与先修课程front+修课程v的最大值
dp[v] = Math.max(dp[v], dp[front] + time[v - 1]);
// 将课程v的入度减1,表示已经完成一门课程
if (--inDegree[v] == 0) {
// 如果入度为0,也就是先修课程全部完成,将其入队
queue.addLast(v);
}
}
}
}
// 取最大值,不能直接dp[n],因为最后修的课程不一定是课程n,所以需要遍历一次,取所有dp的最大值
int res = 0;
for (int v : dp) {
res = Math.max(v, res);
}
return res;
}
}
时间与内存如下:
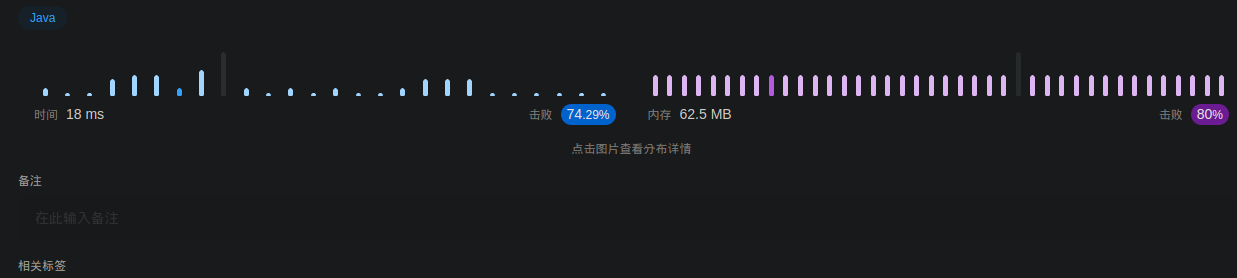
4 优化
4.1 队列优化
对于带队列的题目,一个常见的优化技巧是使用数组去模拟队列。
需要注意的是,这需要根据题目去确定,虽然队列中存储的是点,但是实际上存储的是边,因为每遍历到一个点就将对应的出边(的点)加入到队列中。观察题目边的范围:

直接取这个范围的队列即可,不会OOM:
int[] queue = new int[(int) Math.min(n * (n + 1L) / 2, 5L * 10_000)];
注意由于n取值可能比较大,导致n^2可能会爆int,所以需要做一下强制转换。
然后用两个变量代表队头和队尾:
int queueFront = 0;
int queueTail = 0;
// 入队
queue[queueTail++] = i;
// 出队
i = queue[queueFront++];
完整代码(逻辑与上面一样,只是修改了队列部分):
import java.util.*;
public class Solution {
public int minimumTime(int n, int[][] relations, int[] time) {
int[] dp = new int[n + 1];
int[] inDegree = new int[n + 1];
List<List<Integer>> list = new ArrayList<>();
for (int i = 0; i <= n; i++) {
list.add(new ArrayList<>());
}
for (int[] r : relations) {
++inDegree[r[1]];
list.get(r[0]).add(r[1]);
}
int[] queue = new int[(int) Math.min(n * (n + 1L) / 2, 5L * 10_000)];
int queueFront = 0;
int queueTail = 0;
for (int i = 1; i <= n; i++) {
if (inDegree[i] == 0) {
dp[i] = time[i - 1];
// 入队
queue[queueTail++] = i;
}
}
// 判断队列是否为空
while (queueFront < queueTail) {
// 获取队列大小
int size = queueTail - queueFront;
for (int i = 0; i < size; i++) {
// 出队
int front = queue[queueFront++];
for (int v : list.get(front)) {
dp[v] = Math.max(dp[v], dp[front] + time[v - 1]);
if (--inDegree[v] == 0) {
// 入队
queue[queueTail++] = v;
}
}
}
}
int res = 0;
for (int v : dp) {
res = Math.max(v, res);
}
return res;
}
}
时间:
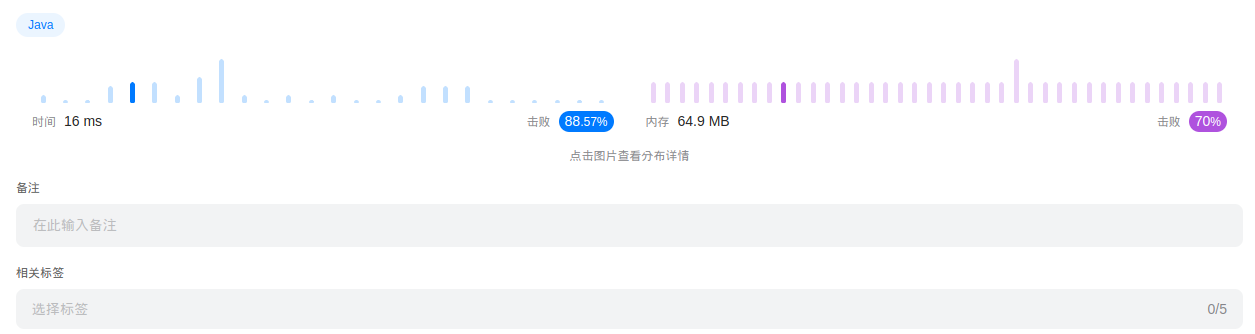
有一点点的优化,但是不多。
4.2 算法细节优化
末尾可以看到有一处计算最大值的地方:
int res = 0;
for (int v : dp) {
res = Math.max(v, res);
}
为什么需要再次遍历dp计算最大值呢?
因为不知道哪一个dp最大,但是,可以在每一次dp计算结束的时候,计算res:
import java.util.*;
public class Solution {
public int minimumTime(int n, int[][] relations, int[] time) {
int[] dp = new int[n + 1];
int[] inDegree = new int[n + 1];
List<List<Integer>> list = new ArrayList<>();
for (int i = 0; i <= n; i++) {
list.add(new ArrayList<>());
}
for (int[] r : relations) {
++inDegree[r[1]];
list.get(r[0]).add(r[1]);
}
int[] queue = new int[(int) Math.min(n * (n + 1L) / 2, 5L * 10_000)];
int queueFront = 0;
int queueTail = 0;
int res = 0;
for (int i = 1; i <= n; i++) {
if (inDegree[i] == 0) {
// 计算最大值
res = Math.max(res, time[i - 1]);
dp[i] = time[i - 1];
queue[queueTail++] = i;
}
}
while (queueFront < queueTail) {
int size = queueTail - queueFront;
for (int i = 0; i < size; i++) {
int front = queue[queueFront++];
// dp[front]已经确定是计算完毕了,用dp[front]计算最大值
res = Math.max(res, dp[front]);
for (int v : list.get(front)) {
dp[v] = Math.max(dp[v], dp[front] + time[v - 1]);
if (--inDegree[v] == 0) {
queue[queueTail++] = v;
}
}
}
}
return res;
}
}
时间:
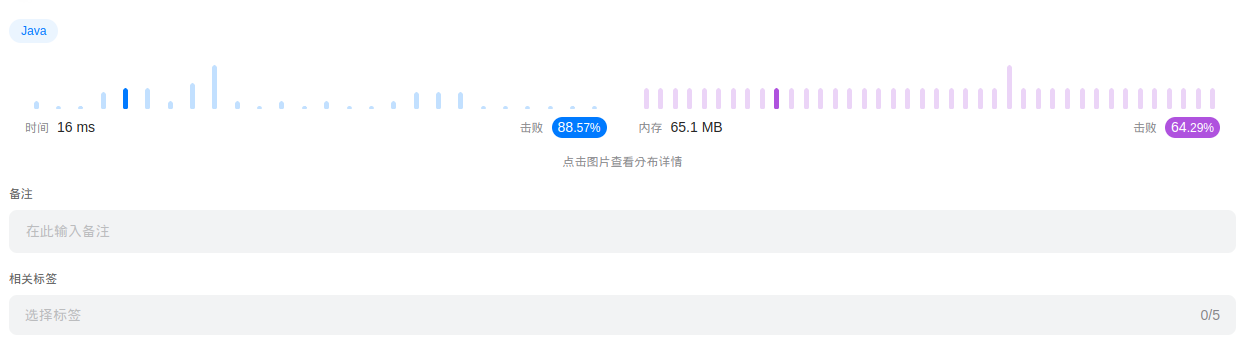
貌似没影响,再继续优化一下。
4.3 建图优化
没错,就是使用链式前向星代替邻接表进行建图优化。
链式前向星介绍可以参考此处,不细说了。
最终代码:
import java.util.*;
public class Solution {
public int minimumTime(int n, int[][] relations, int[] time) {
int[] dp = new int[n + 1];
int[] inDegree = new int[n + 1];
int[] last = new int[n + 1];
int edgeCount = relations.length;
int[] pre = new int[edgeCount + 1];
// 初始化last为-1
Arrays.fill(last, -1);
for (int i = 0; i < edgeCount; i++) {
int v0 = relations[i][0];
int v1 = relations[i][1];
++inDegree[v1];
// 建图
pre[i] = last[v0];
last[v0] = i;
}
int[] queue = new int[(int) Math.min(n * (n + 1L) / 2, 5L * 10_000)];
int queueFront = 0;
int queueTail = 0;
int res = 0;
for (int i = 1; i <= n; i++) {
if (inDegree[i] == 0) {
res = Math.max(res, time[i - 1]);
dp[i] = time[i - 1];
queue[queueTail++] = i;
}
}
while (queueFront < queueTail) {
int size = queueTail - queueFront;
for (int i = 0; i < size; i++) {
int front = queue[queueFront++];
res = Math.max(res, dp[front]);
// 遍历所有边
for (int lastEdge = last[front]; lastEdge != -1; lastEdge = pre[lastEdge]) {
int v = relations[lastEdge][1];
dp[v] = Math.max(dp[v], dp[front] + time[v - 1]);
if (--inDegree[v] == 0) {
queue[queueTail++] = v;
}
}
}
}
return res;
}
}
时间:
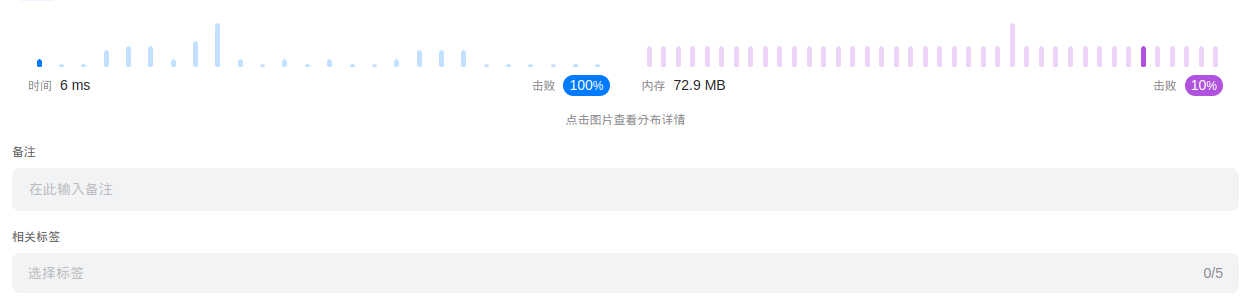
至此优化完成。
5 总结
题目以拓扑排序为基础,再其中加入了计算时间的动态规划。
实现时,拓扑排序可以广搜+队列实现,计算时间的dp是比较简单的一维dp,转移方程也比较好推。
写代码时有些细节要注意:
- 数组分配
n+1而不是n - 由于一开始的算法不完善导致了计算完成
dp后还需要再遍历一次dp取最大值
优化主要依靠链式前向星的时间优化,队列优化以及算法细节优化效果并不明显。
标签:2050,int,inDegree,并行,relations,课程,new,LeetCode,dp From: https://www.cnblogs.com/6b7b5fc3/p/17136063.html