使用大型数据集训练大型深度神经网络 (DNN) 的问题是深度学习领域的主要挑战。 随着 DNN 和数据集规模的增加,训练这些模型的计算和内存需求也会增加。 这使得在计算资源有限的单台机器上训练这些模型变得困难甚至不可能。 使用大型数据集训练大型 DNN 的一些主要挑战包括:
- 训练时间长:训练过程可能需要数周甚至数月才能完成,具体取决于模型的复杂性和数据集的大小。
- 内存限制:大型 DNN 可能需要大量内存来存储训练期间的所有模型参数、梯度和中间激活。 这可能会导致内存不足错误并限制可在单台机器上训练的模型的大小。
为了应对这些挑战,已经开发了各种技术来扩大具有大型数据集的大型 DNN 的训练,包括模型并行性、数据并行性和混合并行性,以及硬件、软件和算法的优化。
在本文中我们将演示使用 PyTorch 的数据并行性和模型并行性。
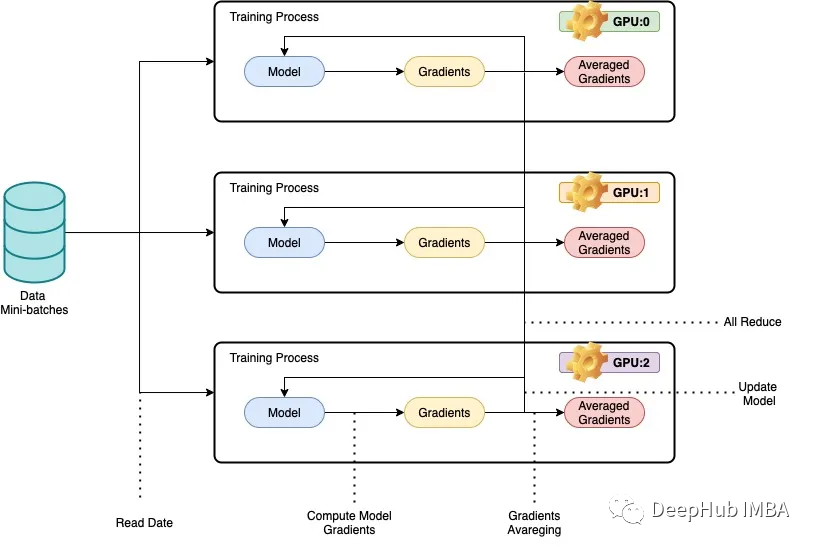
我们所说的并行性一般是指在多个gpu,或多台机器上训练深度神经网络(dnn),以实现更少的训练时间。数据并行背后的基本思想是将训练数据分成更小的块,让每个GPU或机器处理一个单独的数据块。然后将每个节点的结果组合起来,用于更新模型参数。在数据并行中,模型体系结构在每个节点上是相同的,但模型参数在节点之间进行了分区。每个节点使用分配的数据块训练自己的本地模型,在每次训练迭代结束时,模型参数在所有节点之间同步。这个过程不断重复,直到模型收敛到一个令人满意的结果。
完整文章:
https://avoid.overfit.cn/post/67095b9014cb40888238b84fea17e872
标签:DistributedDataParallel,训练,示例,模型,DNN,并行性,PyTorch,数据,节点 From: https://www.cnblogs.com/deephub/p/17134263.html