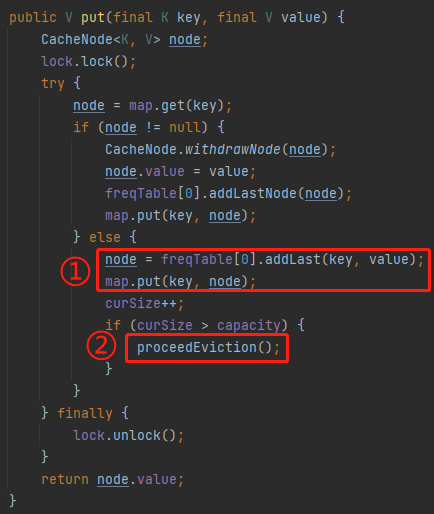
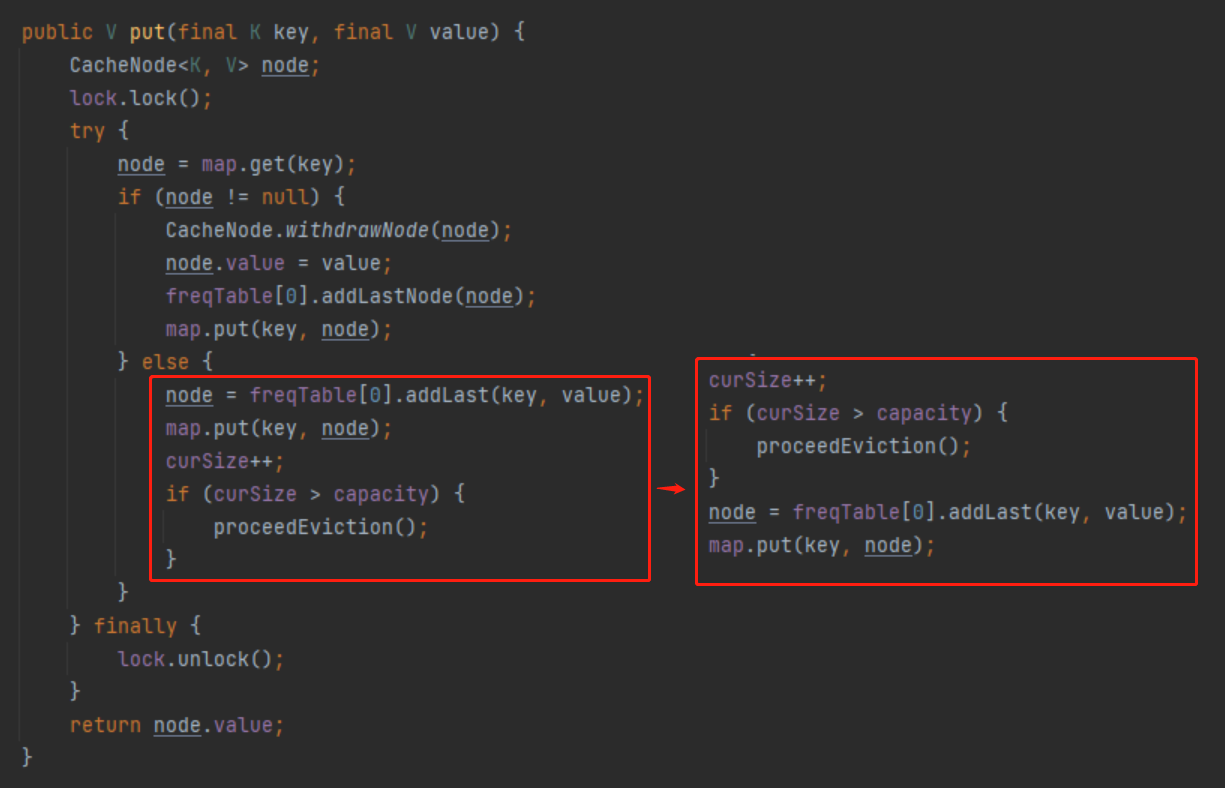
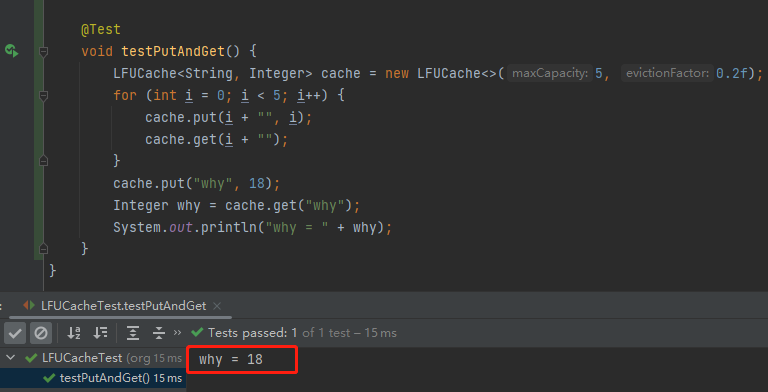
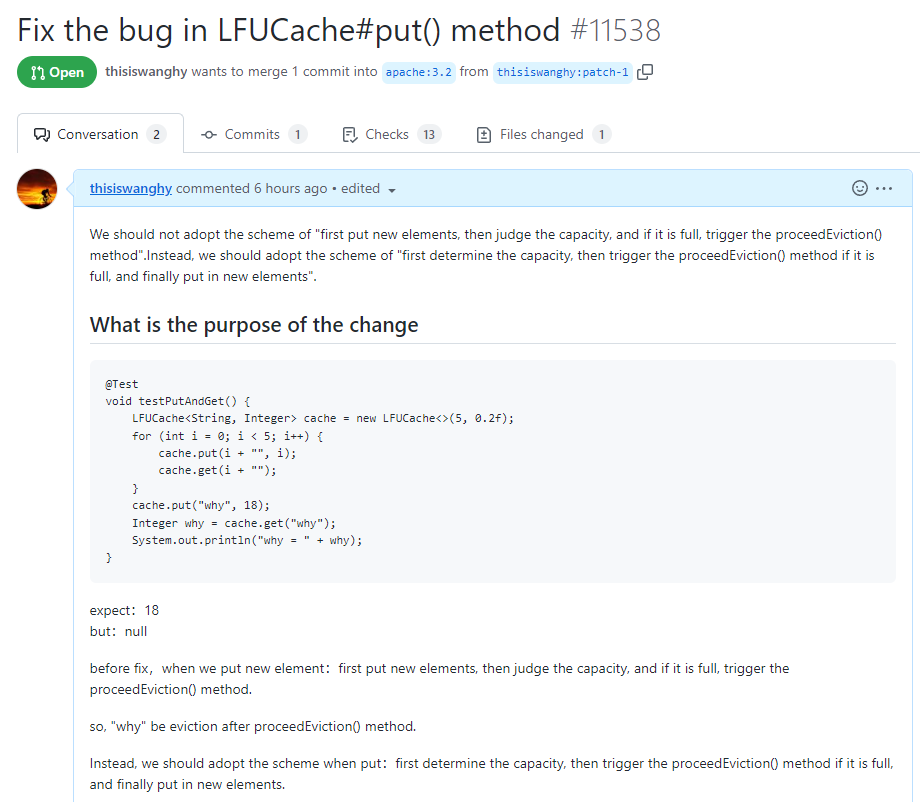
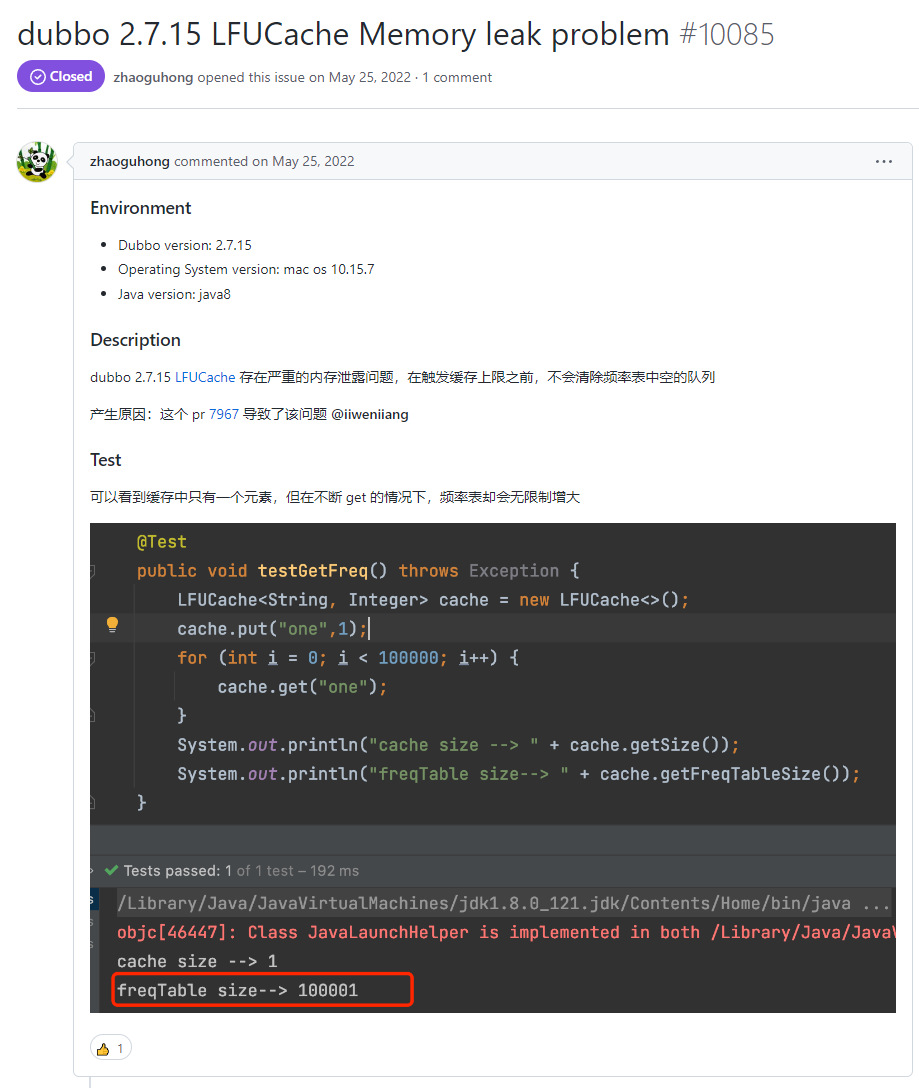
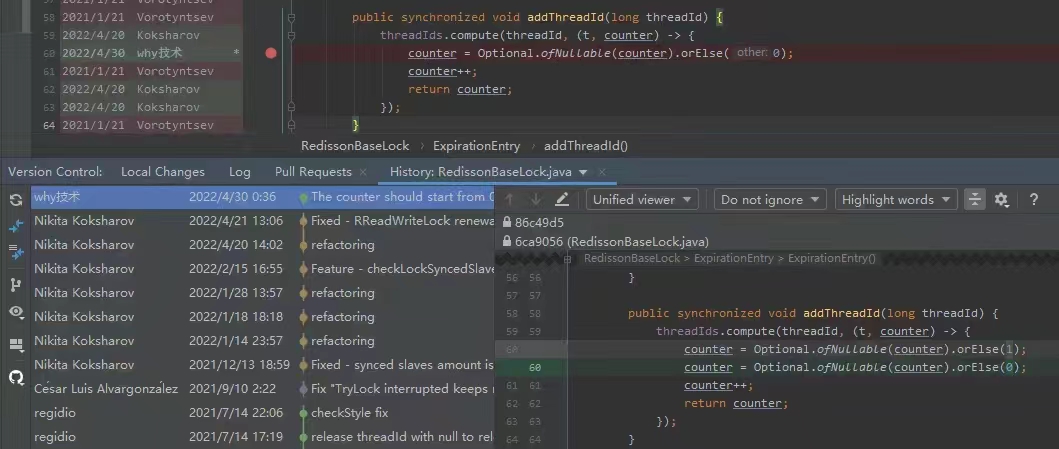
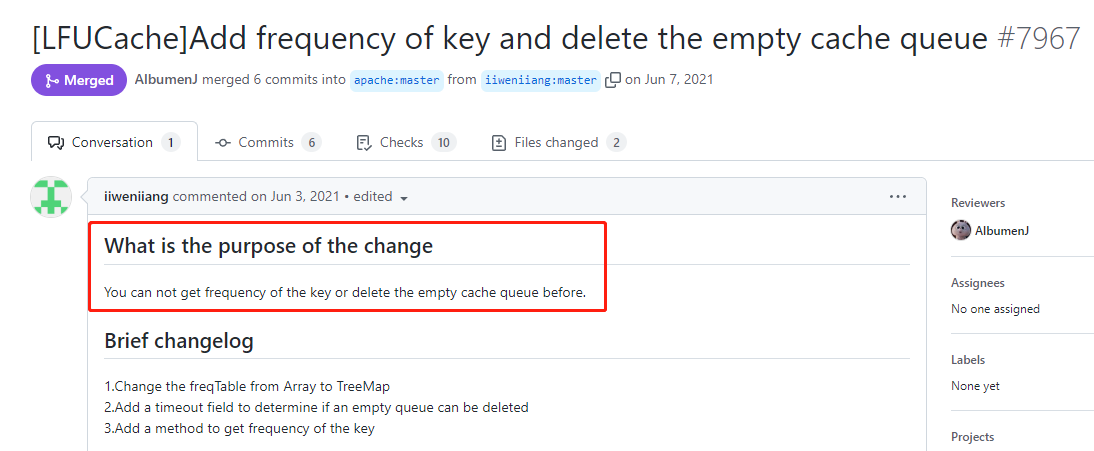
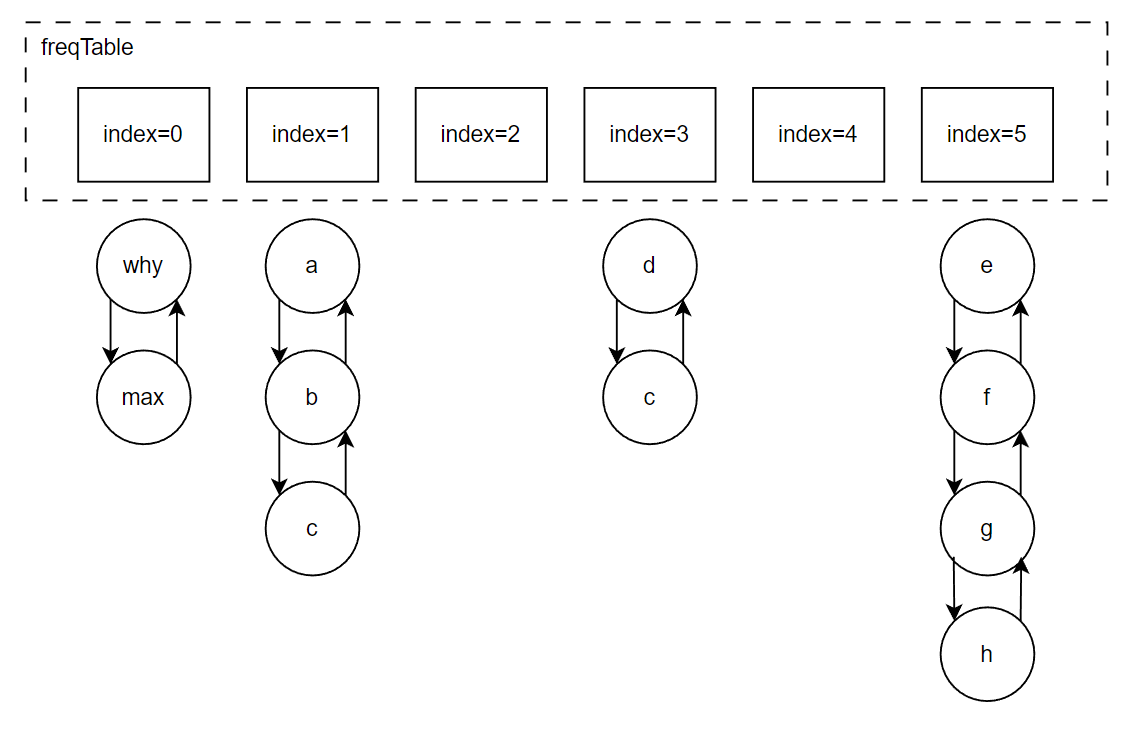
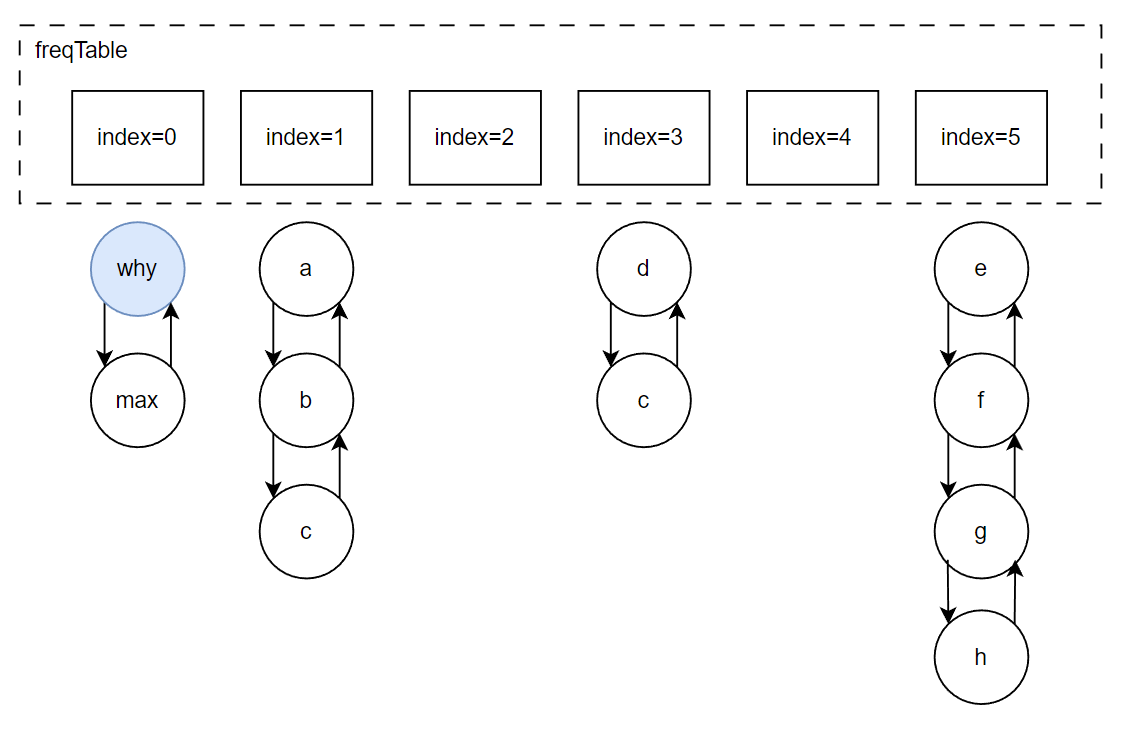
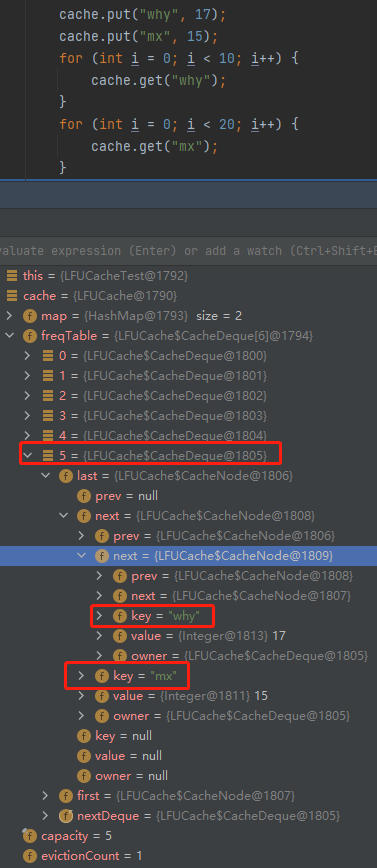
你好呀,我是歪歪。 这篇文章带大家盘一下 LFU 这个玩意。 为什么突然想起聊聊这个东西呢,因为前段时间有个读者给我扔过来一个链接: 我一看,好家伙,这不是我亲爱的老朋友,Dubbo 同学嘛。 点进去一看,就是一个关于 LFU 缓存的 BUG: https://github.com/apache/dubbo/issues/10085 你知道的,我就喜欢盘一点开源项目的 BUG,看看有没有机会,捡捡漏什么的。在我辉煌的“捡漏”历中,曾经最浓墨重彩的一笔是在 Redisson 里面,发现作者在重构代码的时候,误把某个方法的计数,从默认值为 0,改成了为 1。 这个 BUG 会直接导致 Redission 锁失去可重入的性质。我发现后,源码都没下载,直接在网页上就改回去了: 我以为这可能就是巅峰了。 但是直到我遇到了 Dubbo 的这个 LFUCache 的 BUG,它的修复方案,只是需要交换两行代码的顺序就完事儿了,更加简单。 到底怎么回事呢,我带你盘一把。 首先,刚刚提到 BUG,因为这一次针对 LFU 实现的优化提交: https://github.com/apache/dubbo/pull/7967 通过链接我们知道,这次提交的目的是优化 LFUCache 这个类,使其能通过 frequency 获取到对应的 key,然后删除空缓存。 但是带了个内存泄露的 BUG 上去,那么这个 BUG 是怎么修复的呢? 直接给对应的提交给回滚掉了: 但是,回滚回来的这一份代码,我个人觉得也是有问题的,使用起来,有点不得劲。 在为你解析 Dubbo 的 LFU 实现的问题之前,我必须要先把 LFU 这个东西的思路给你盘明白了,你才能丝滑入戏。 在说 LFU 之前,我先给简单提一句它的好兄弟:LRU,Least Recently Used,最近最少使用。 LRU 这个算法的思想就是:如果一个数据在最近一段时间没有被访问到,那么在将来它被访问的可能性也很小。所以,当指定的空间已存满数据时,应当把最久没有被访问到的数据淘汰。 听描述你也知道了,它是一种淘汰算法。 如果说 LRU 是 Easy 模式的话,那么把中间的字母从 R(Recently) 变成 F(Frequently),即 LFU ,那就是 hard 模式了。 如果你不认识 Frequently 没关系,毕竟这是一个英语专八的词汇。 我,英语八级半,我可以教你: 这是一个 adv,副词,是指在句子中表示行为或状态特征的词,用以修饰动词、形容词、其他副词或全句,表示时间、地点、程度、方式等概念。 在 LFU 里面,表示的就是频率,它翻译过来就是:最不经常使用策略。 LRU 淘汰数据的时候,只看数据在缓存里面待的时间长短这个维度。 而 LFU 在缓存满了,需要淘汰数据的时候,看的是数据的访问次数,被访问次数越多的,就越不容易被淘汰。 但是呢,有的数据的访问次数可能是相同的。 怎么处理呢? 如果访问次数相同,那么再考虑数据在缓存里面待的时间长短这个维度。 也就是说 LFU 算法,先看访问次数,如果次数一致,再看缓存时间。 给你举个具体的例子。 假设我们的缓存容量为 3,按照下列数据顺序进行访问: 如果按照 LRU 算法进行数据淘汰,那么十次访问的结果如下: 十次访问结束后,缓存中剩下的是 b,c,d 这三个元素。 你仔细嗦一下,你有没有觉得有一丝丝不对劲? 十次访问中元素 a 被访问了 5 次,说明 a 是一个经常要用到的东西,结果按照 LRU 算法,最后元素 a 被淘汰了? 如果按照 LFU 算法,最后留在缓存中的三个元素应该是 b,c,a。 这样看来,LFU 比 LRU 更加合理,更加巴适。 好的,题目描述完毕了。假设,要我们实现一个 LFUCache: 那么思路应该是怎样的呢? 如果是我去面试,在完全没有接触过 LFU 算法之前,面试官出了这么一道题,让我硬想,我能想到的方案也只能是下面这样的。 因为前面我们分析了,这个玩意既需要有频次,又需要有时间顺序。 我们就可以搞个链表,先按照频次排序,频次一样的,再按照时间排序。 因为这个过程中我们需要删除节点,所以为了效率,我们使用双向链表。 还是假设我们的缓存容量为 3,还是用刚刚那组数据进行演示。 我们把频次定义为 freq,那么前三次访问结束后,即这三个请求访问结束后: 每个元素的频次,即 freq 都是 1。所以链表里面应该是这样的: 由于我们的容量就是 3,此时已经满了。 那我问你一个问题:如果此时来任意一个不是 a 的元素,谁会被踢出缓存? 就这问题,你还思考个毛啊,这不是一目了然的事情吗? 对于目前三个元素来说,value=a 是频次相同的情况下,最久没有被访问到的元素,所以它就是 head 节点的下一个元素,随时等着被淘汰。 但是你说巧不巧, 接着过来的请求就是 value=a: 当这个请求过来的时候,链表中的 value=a 的节点的频率(freq)就变成了2。 此时,它的频率最高,最不应该被淘汰,a 元素完成了自我救赎! 因此,链表变成了下面这个样子,没有任何元素被淘汰了。 链表变化的部分,我用不同于白色的颜色(我色弱不知道这是个啥颜色,蓝色吗?)标注出来: 接着连续来了三个 value=a 的请求: 此时的链表变化就集中在 value=a 这个节点的频率(freq)上。 为了让你能丝滑跟上,我把每次的 freq 变化都给你画出来。这行为,实锤了,妥妥的暖男作者: 接着,这个 b 请求过来了: b 节点的 freq 从 1 变成了 2,节点的位置也发生了变化: 然后,c 请求过来: 这个时候就要特别注意了: 你说这个时候会发生什么事情? 链表中的 c 当前的访问频率是 1,当这个 c 请求过来后,那么链表中的 c 的频率就会变成 2。 你说巧不巧,此时,value=b 节点的频率也是 2。 撞车了,那么你说,这个时候怎么办? 前面说了:频率一样的时候,看时间。 value=c 的节点是正在被访问的,所以要淘汰也应该淘汰之前被访问的 value=b 的节点。 此时的链表,就应该是这样的: 然后,最后一个请求过来了: d 元素,之前没有在链表里面出现过,而此时链表的容量也满了。 那么刺激的就來了,该进行淘汰了,谁会被“优化”掉呢? 一看链表,哦,head 的下一个节点是 value=b: 然后把 value=d 的节点插入: 最终,所有请求完毕。 留在缓存中的是 d,c,a 这三个元素。 最后,汇个总,整体的流程就是这样的: 当然,这里只是展示了链表的变化。 前面说了,这是缓存淘汰策略,缓存嘛,大家都懂,是一个 key-value 键值对。 所以前面的元素 a,b,c 啥的,其实对应的是我们放的 key-value 键值对。也就是应该还有一个 HashMap 来存储 key 和链表节点的映射关系。 这个点比较简单,用脚趾头都能想到,我也就不展开来说了。 按照上面这个思路,你慢慢的写代码,应该是能写出来的。 上面这个双链表的方案,就是扣着脑壳硬想,大部分人能直接想到的方案。 但是,面试官如果真的是问这个问题的话,当你给出这个回答之后,他肯定会追问:有没有时间复杂度为 O(1) 的解决方案呢? 如果我们要拿出时间复杂度为 O(1) 的解法,那就得细细的分析了,不能扣着脑壳硬想了。 我们先分析一下需求。 第一点:我们需要根据 key 查询其对应的 value。 前面说了,这是一个缓存淘汰策略,缓存嘛,用脚趾头都能想到,用 HashMap 存储 key-value 键值对。 查询时间复杂度为 O(1),满足。 第二点:每当我们操作一个 key 的时候,不论是查询还是新增,都需要维护这个 key 的频次,记作 freq。 因为我们需要频繁的操作 key 对应的 freq,频繁地执行把 freq 拿出来进行加一的操作。 获取,加一,再放回去。来,请你大声的告诉我,用什么数据结构? 是不是还得再来一个 HashMap 存储 key 和 freq 的对应关系? 第三点:如果缓存里面放不下了,需要淘汰数据的时候,把 freq 最小的 key 删除掉。 注意啊,上面这句话,看黑板,我再强调一下:把 freq 最小的 key 删除掉。 freq 最小? 我们怎么知道哪个 key 的 freq 最小呢? 前面说了,我们有一个 HashMap 存储 key 和 freq 的对应关系。我们肯定是可以遍历这个 HashMap,来获取到 freq 最小的 key。 但是啊,朋友们,遍历出现了,那么时间复杂度还会是 O(1) 吗? 那怎么办呢? 注意啊,高潮来了,一学就废,一点就破。 我们可以搞个变量来记录这个最小的 freq 啊,记为 minFreq,在对缓存操作的过程中持续的对其进行维护,不就行了? 现在我们有最小频次(minFreq)了,需要获取到这个最小频次对应的 key,时间复杂度得为 O(1)。 来,朋友,请你大声的告诉我,你又想起了什么数据结构? 是不是又想到了 HashMap? 好了,我们现在有三个 HashMap 了,给大家介绍一下: 一个存储 key 和 value 的 HashMap,即HashMap<key,value>。 它们每个都是各司其职,目的都是为了时间复杂度为 O(1)。 但是我们可以把前两个 HashMap 合并一下。 我们弄一个对象,对象里面包含两个属性分别是 value、freq。 假设这个对象叫做 Node,它就是这样的,频次默认为 1: 那么现在我们就可以把前面两个 HashMap ,替换为一个了,即 HashMap<key,Node>。 同理,我们可以在 Node 里面再加入一个 key 属性: 因为 Node 里面包含了 key,所以可以把第三个 HashMap<freq,key> 替换为 HashMap<freq,Node>。 当我们有了封装了 key、value、freq 属性的 Node 对象之后,我们的三个 HashMap 就变成了两个: 一个存储 key 和 Node 的 HashMap,即 HashMap<key,Node> 你捋一捋这个思路,是不是非常的清晰,有了清晰的思路,去写代码是不是就事半功倍了。 好,现在我告诉你,到这一步,我们还差一个逻辑,而且这个逻辑非常的重要,你现在先别着急往下看,先再回顾一下目前整个推理的过程和最后的思路,想一想到底还差啥? ... ... ... ... 到这一步,我们还差了一个非常关键的信息没有补全,就是下面这一个点。 第四点:可能有多个 key 具有相同的最小的 freq,此时移除这一批数据在缓存中待的时间最长的那个元素。 在这个需求里面,我们需要通过 freq 查找 Node,那么操作的就是 HashMap<freq,Node> 这个哈希表。 上面说[多个 key 具有相同的最小的 freq],也就是说通过 minFreq ,是可以查询到多个 Node 的。 所以HashMap<freq,Node> 这个哈希表,应该是这样的:HashMap<freq,集合 这个能想明白吧? 一个坑位下,挂了一串节点。 此时的问题就变成了:我们应该用什么集合来装这个 Node 对象呢? 不慌,我们又接着分析嘛。 先理一下这个集合需要满足什么条件。 我们通过 minFreq 获取这个集合的时候,也就是队列满了,要从这个集合中删除数据的时候 首先,需要删除 Node 的时候。 因为这个集合里面装的是访问频次一样的数据,那么希望这批数据能有时序,这样可以快速的删除待的时间最久的 Node。 有序,有时序,能快速查找删除待的时间最久的 key。 LinkedList,双向链表,可以满足这个需求吧? 另外还有一种大多数情况是一个 Node 被访问的时候,它的频次必然就会加一。 所以还要考虑访问 Node 的时候。 比如下面这个例子: 假设最小访问频次,minFreq=5,而 5 这个坑位对应了 3 个 Node 对象。 此时,我要访问 value=b 的对象,那么该对象就会从 minFreq=5 的 value 中移走。 然后频次加一,即 5+1=6。 加入到 minFreq=6 的 value 集合中,变成下面这个样子: 也就是说我们得支持任意 node 的快速删除。 LinkedList 不支持任意 node 的快速删除,这玩意需要遍历啊。 当然,你可以自己去手撸一个符合要求的 MySelfLinkedList。 但是,在 Java 集合类中,其实有一个满足上面说的有序的、支持快速删除的集合。 那就是 LinkedHashSet,它是一个基于 LinkedHashMap 实现的有序的、去重集合列表。 底层还是一个 Map,Map 针对指定元素的删除,O(1)。 所以,HashMap<freq,集合>,就是HashMap<freq,LinkedHashSet>。 总结一下。 我们需要两个 HashMap,分别是 然后还需要维护一个最小访问频次,minFreq。 哦,对了,还得来一个参数记录缓存支持的最大容量,capacity。 然后,没了。 有的小伙伴肯定要问了:你倒是给我一份代码啊? 这些分析出来了,代码自己慢慢就撸出来了,这一份代码应该就是绝大部分面试官问 LFU 的时候,想要看到的代码了。 另外,关于 LFU 出现在面试环节,我突然想起一个段子,我觉得还有一丝道理: 面试官想要,我会出个两数之和,如果我不想要你,我就让你写LFU。 我这里主要带大家梳理思路,思路清晰后再去写代码,就算面试的时候没有写出 bug free 的代码,也基本上八九不离十了。 所以具体的代码实现,我这里就不提供了,网上一搜多的很,关键是把思路弄清楚。 这玩意就像是你工作,关键的是把需求梳理明白,然后想想代码大概是怎么样的。 至于具体去写的时候,到处粘一粘,也不是不可以。再或者,把设计文档写出来了,代码落地就让小弟们照着你的思路去干就行了。 应该把工作精力放在更值得花费的地方:比如 battle 需求、写文档、写周报、写 PPT、舔领导啥的... 到这里,你应该是懂了 LFU 到底是个啥玩意了。 现在我带你看看 Dubbo 里面的这个 LFU,它的实现方案并没有采取我们前面分析出来的方案。 它另辟蹊径,搞了一个新花样出来。它是怎么实现的呢?我给你盘一下。 Dubbo 是在 2.7.7 版本之后支持的 LFU,所以如果你要在本地测试一把的话,需要引入这个版本之后的 Maven 依赖。 我这里直接是把 Dubbo 源码拉下来,然后看的是 Master 分支的代码。 首先看一下它的数据结构: 它有一个 Map,是存放的 key 和 Node 之间的映射关系。然后还有一个 freqTable 字段,它的数据结构是数组,我们并没有看到一个叫做 minFreq 的字段。 当我的 LFUCache 这样定义的时候: new LFUCache<>(5, 0.2f); 含义是这个缓存容量是 5,当满了之后,“优化” 5*0.2 个对象,即从缓存中踢出 1 个对象。 通过 Debug 模式看,它的结构是这样的: 我们先主要关注 freqTable 字段。 在下面标号为 ① 的地方,表示它是一个长度为 capacity+1 的数组,即长度为 6,且每个位置都 new 了一个 CacheDeque 对象。 标号为 ② 的地方,完成了一个单向链表的维护动作: freqTable 具体拿来是干啥用的呢? 用下面这三行代码举个例子: 当第一行执行完成之后,why 这个元素被放到了 freqTable 的第一个坑位,即数组的 index=0 里面: 当第二行执行完成之后,why 这个元素被放到了 freqTable 的第二个坑位里面: 当第三行执行完成之后,why 这个元素被放到了 freqTable 的第三个坑位里面: 有没有点感觉了? freqTable 这个数组,每个坑位就是对应不同的频次,所以,我给你搞个图: 比如 index=3 位置放的 d 和 c,含义就是 d 和 c 在缓存里面被访问的频次是 4 次。 但是,d 和 c 谁待的时间更长呢? 我也不知道,所以得看看源码里面删除元素的时候,是移走 last 还是 first,移走谁,谁就在这个频率下待的时间最长。 答案就藏在它的驱逐方法里面: org.apache.dubbo.common.utils.LFUCache#proceedEviction 从数组的第一个坑位开始遍历数组,如果这个坑位下挂的有链表,然后开始不断的移除头结点,直到驱逐指定个数的元素。 移除头结点,所以,d 是在这个频次中待的时间最长的。 基于这个图片,假设现在队列满了,那么接下来,肯定是要把 why 这个节点给“优化”了: 这就是 Dubbo 里面 LFU 实现的最核心的思想,很巧妙啊,基于数组的顺序,来表示元素被访问的频次。 但是,细细的嗦一下味道之后,你有没有想过这样一个问题,当我访问缓存中的元素的次数大于 freqTable 数组的长度的时候,会出现什么神奇的现象? 我还是给你用代码示意: 虽然 mx 元素的访问次数比 why 元素的次数多得多,但是这两个元素最后都落在了 freqTable 数组的最后一个坑位中。 也就是会出现这样的场景: 好,我问你一个问题:假设,在这样的情况下,要淘汰元素了,谁会被淘汰? 肯定是按照头结点的顺序开始淘汰,也就是 why 这个节点。 接下来注意了,我再问一个问题:假设此时 why 有幸再次被访问了一下,然后才来一个新的元素,触发了淘汰策略,谁会被淘汰? why 会变成这个坑位下的链表中的 last 节点,从而躲避过下一次淘汰。mx 元素被淘汰了。 这玩意突然就从 LFU,变成了一个 LRU。在同一个实现里面,既有 LFU 又有 LRU,这玩意,知识都学杂了啊。 我就问你 6 不 6? 所以,这就是 Dubbo 的 LFU 算法实现的一个弊端,这个弊端是由于它的设计理念和数据结构决定的,如果想要避免这个问题,我觉得有点麻烦,得推翻从来。 所以我这里也只是给你描述一下有这个问题的存在。 然后,关于 Dubbo 的 LFU 的实现,还有另外一个神奇的东西,我觉得这纯纯的就是 BUG 了。 我还是给你搞一个测试用例: 一个容量为 5 的 LFUCache,我先放五个元素进去,每个元素 put 之后再 get 一下,所以每个元素的频率变成了 2。 然后,此时我放了一个 why 进去,然后在取出来的时候, why 没了。 你这啥缓存啊,我刚刚放进去的东西,等着马上就要用呢,结果获取的时候没了,这不是 BUG 是啥? 问题就出在它的 put 方法中: 标号为 ① 的地方往缓存里面放,放置完毕之后,判断是否会触发淘汰机制,然后在标号 ② 的地方删除元素。 前面说了,淘汰策略,proceedEviction 方法,是从 freqTable 数组的第一个坑位开始遍历数组,如果这个坑位下挂的有链表,然后开始不断的移除头结点,直到驱逐指定个数的元素。 所以,在刚刚我的示例代码中,why 元素刚刚放进去,它的频率是 1,放在了 freqTable 数组的第 0 个位置。 放完之后,一看,触发淘汰机制了,让 proceedEviction 方法看看是谁应该被淘汰了。 你说,这不是赶巧了嘛,直接又把 why 给淘汰了,因为它的访问频率最低。 所以,立马去获取 “why” 的时候,获取不到。 这个地方的逻辑就是有问题的。 不应该采取“先放新元素,再判断容量,如果满了,触发淘汰机制”的实现方案。 而应该采取“先判断容量,如果满了,再触发淘汰机制,最后再放新元素的”方案。 也就是我需要把这两行代码换个位置: 再次执行测试案例,就没有问题了: 诶,你说这是什么? 这不就是为开源项目贡献源码的好机会吗? 于是... https://github.com/apache/dubbo/pull/11538 关于提 pr,有一个小细节,我悄悄的告诉你:合不合并什么的不重要,重要的是全英文提问,哪怕是中文一键翻译过来的,也要贴上去,逼格要拉满,档次要上去... 至于最后,如果没合并,说明我考虑不周,又是新的素材。 如果合并了,简历上又可以写:熟练使用 Dubbo,并为其贡献过源码。 到时候,我脸皮再厚一点,还可以写成:阅读过 Apache 顶级开源项目源码,多次为其贡献过核心源码,并写过系列博文,加深学习印象... 不能再说了,剩下的就靠自己悟了! 最后,文章就到这里了,如果对你有一丝丝的帮助,帮我点个免费的赞,不过分吧?

LRU vs LFU
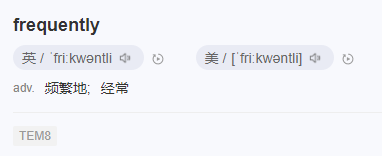




class LFUCache {
public LFUCache(int capacity) {
}
public int get(int key) {
}
public void put(int key, int value) {
}
}
一个双向链表

















双哈希表


一个存储 key 和 freq 的 HashMap,即HashMap<key,freq>。
一个存储 freq 和 key 的 HashMap,即HashMap<freq,key>。class Node {
int value;
int freq = 1;
//构造函数省略
}class Node {
int key;
int value;
int freq = 1;
//构造函数省略
}
一个存储 freq 和 Node 的 HashMap,即 HashMap<freq,Node>







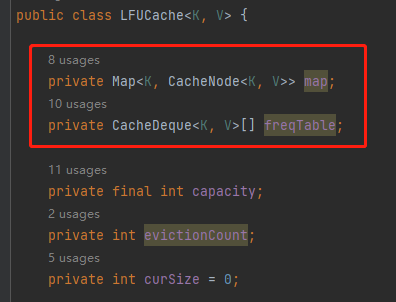
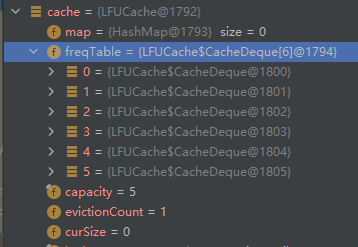
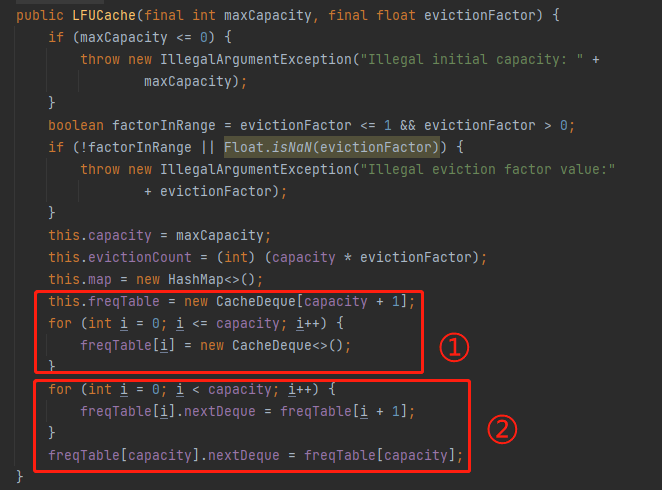
Dubbo 的 LFU

cache.put("why", 18);
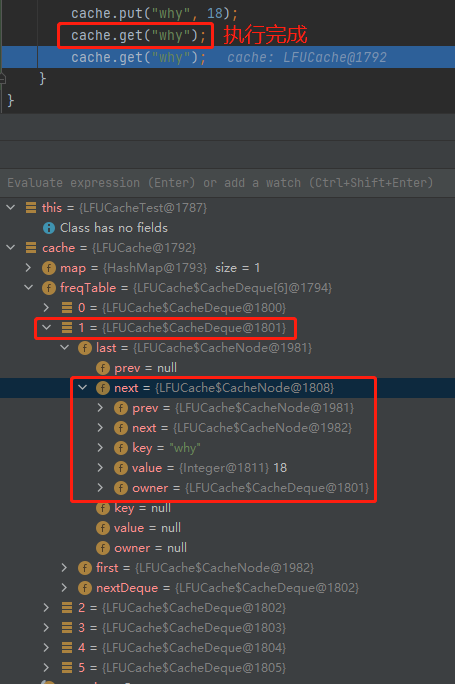
cache.get("why");
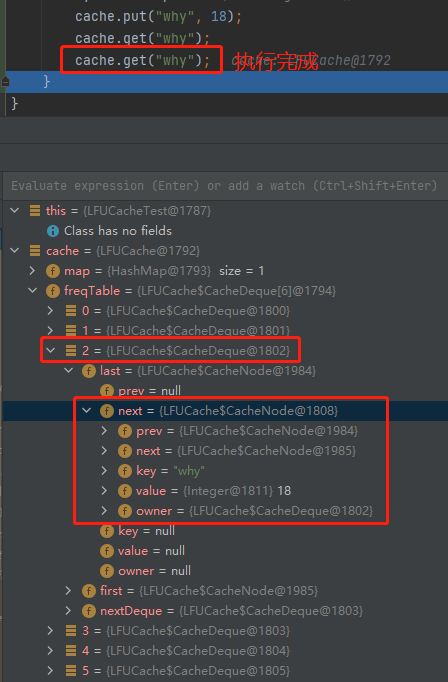
cache.get("why");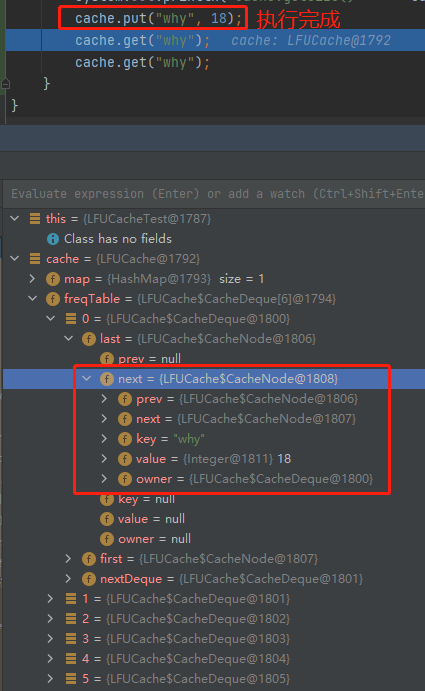




@Test
void testPutAndGet() {
LFUCache<String, Integer> cache = new LFUCache<>(5, 0.2f);
for (int i = 0; i < 5; i++) {
cache.put(i + "", i);
cache.get(i + "");
}
cache.put("why", 18);
Integer why = cache.get("why");
System.out.println("why = " + why);
}