最小生成树
最小生成树:由n个节点,和n-1条边构成的无向连通图被称为G的一颗生成树,在G的所有生成树中,边的权值之和最小的生成树,被称为G的最小生成树。(换句话说就是用最小的代价把n个点都连起来)
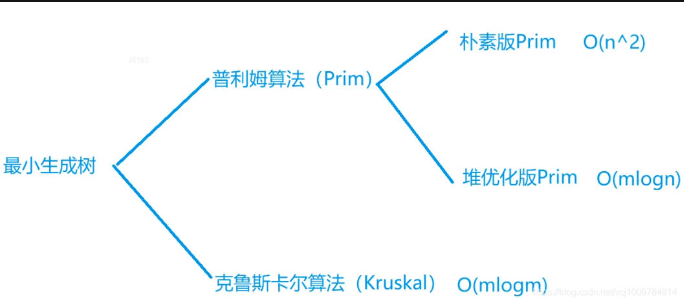
有两种常用算法:
- Prim算法(普利姆)朴素版Prim(时间复杂度O(n2),适用于稠密图)堆优化版Prim(时间复杂度O(mlogn),适用于稀疏图)
- Kruskal算法(克鲁斯卡尔)适用于稀疏图,时间复杂度O(mlogm)对于最小生成树问题,如果是稠密图,通常选用朴素版Prim算法,因为其思路比较简洁,代码比较短,如果是稀疏图,通常选用Kruskal算法,因为其思路比Prim简单清晰。堆优化版的Prim通常不怎么用。
朴素Prim
算法流程
-
初始化距离, 将所有点的距离初始化为INF
(这里的距离指的是点到集合的距离,而Dijkstra的距离是到起点的距离)
-
n次循环
-
找到不在集合s中, 且距离最近的点t
-
用t来更新其他点到的距离
集合s
-
将t加入到集合s中
-
代码模板
// 时间复杂度是 O(n2+m)O(n2+m) , nn 表示点数,mm 表示边数
int n; // n表示点数
int g[N][N]; // 邻接矩阵,存储所有边
int dist[N]; // 存储其他点到当前最小生成树的距离
bool st[N]; // 存储每个点是否已经在生成树中
// 如果图不连通,则返回INF(值是0x3f3f3f3f), 否则返回最小生成树的树边权重之和
int prim()
{
memset(dist, 0x3f, sizeof dist);
int res = 0;
for (int i = 0; i < n; i ++ )
{
int t = -1;
for (int j = 1; j <= n; j ++ )
if (!st[j] && (t == -1 || dist[t] > dist[j]))
t = j;
if (i && dist[t] == INF) return INF;
if (i) res += dist[t];
st[t] = true;
for (int j = 1; j <= n; j ++ ) dist[j] = min(dist[j], g[t][j]);
}
return res;
}
Kruskal
算法流程
- 先将所有边,按照权重,从小到大排序
- 从小到大枚举每条边(a,b,w),若a,b不连通,则将这条边,加入集合中(将a点和b点连接起来)
代码模板
int n, m; // n是点数,m是边数
int p[N]; // 并查集的父节点数组
struct Edge // 存储边
{
int a, b, w;
bool operator< (const Edge &W)const
{
return w < W.w;
}
}edges[M];
int find(int x) // 并查集核心操作
{
if (p[x] != x) p[x] = find(p[x]);
return p[x];
}
int kruskal()
{
sort(edges, edges + m);
for (int i = 1; i <= n; i ++ ) p[i] = i; // 初始化并查集
int res = 0, cnt = 0;
for (int i = 0; i < m; i ++ )
{
int a = edges[i].a, b = edges[i].b, w = edges[i].w;
a = find(a), b = find(b);
if (a != b) // 如果两个连通块不连通,则将这两个连通块合并
{
p[a] = b;
res += w;
cnt ++ ;
}
}
if (cnt < n - 1) return INF;
return res;
}
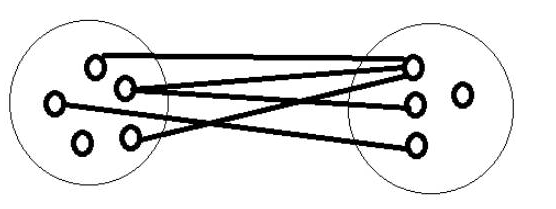
二分图
二分图
指的是,可以将一个图中的所有点,分成左右两部分,使得图中的所有边,都是从左边集合中的点,连到右边集合中的点。而左右两个集合内部都没有边。
有两种常用的相关算法
- 染色法
- 匈牙利算法
其中染色法是通过深度优先遍历实现,时间复杂度是O(n×m);匈牙利算法的时间复杂度理论上是O(n×m),但实际运行时间一般远小于O(n×m)。
图论中的一个重要性质:一个图是二分图,当且仅当图中不含奇数环奇数环,指的是这个环中边的个数是奇数。(环中边的个数和点的个数是相同的)
染色法
可以用染色法来判断一个图是否是二分图,使用深度优先遍历,从根节点开始把图中的每个节点都染色,保证每个节点与相邻节点的颜色不同(但是只有黑白两种),只要染色过程中没有出现矛盾,说明该图是一个二分图,否则,说明不是二分图。
匈牙利算法
解决的问题
匈牙利算法,是给定一个二分图,用来求二分图的最大匹配的。
二分图的匹配:给定一个二分图 G,在 G 的一个子图 M 中,M 的边集 {E} 中的任意两条边都不依附于同一个顶点,则称 M 是一个匹配。
二分图的最大匹配:所有匹配中包含边数最多的一组匹配被称为二分图的最大匹配,其边数即为最大匹配数。
代码模板
int n1, n2; // n1表示第一个集合中的点数,n2表示第二个集合中的点数
int h[N], e[M], ne[M], idx; // 邻接表存储所有边,匈牙利算法中只会用到从第一个集合指向第二个集合的边,所以这里只用存一个方向的边
int match[N]; // 存储第二个集合中的每个点当前匹配的第一个集合中的点是哪个
bool st[N]; // 表示第二个集合中的每个点是否已经被遍历过
bool find(int x)
{
for (int i = h[x]; i != -1; i = ne[i])
{
int j = e[i];
if (!st[j])
{
st[j] = true;
if (match[j] == 0 || find(match[j]))
{
match[j] = x;
return true;
}
}
}
return false;
}
// 求最大匹配数,依次枚举第一个集合中的每个点能否匹配第二个集合中的点
int res = 0;
for (int i = 1; i <= n1; i ++ )
{
memset(st, false, sizeof st);
if (find(i)) res ++ ;
}