Better
-
Batch Normalization(BN 层)
Yolo v2 中在每个卷积层后都加了BN层,去掉了dropout层。BN层可以起到一定的正则化效果,能提升模型收敛速度,防止模型过拟合。通过BN层,yolov2的mAP提高了2%。
-
High Resolution Classifier(高分辨率分类器)
YOLO v2将输入图片的分辨率提升448 × 448,为了使网络适应新的分辨率,YOLO v2先在ImageNet上以448 × 448 的分辨率对网络进行10个epoch的微调,让网络适应高分辨率的输入。通过使用高分辨率的输入,YOLO v2的mAP提升了约4%。
-
Anchor
Dimension Cluster(Anchor Box的宽高由聚类产生)
Direct location prediction(绝对位置预测)
在yolo v2中,将图片分成了13*13个grid cell,每个grid cell预测5种anchor,每一种anchor对应了一个预测框,每一个预测框只需要输出它相对于其他anchor的偏移量。


其中,这5个anchor由聚类产生。
约束预测边框的位置: YOLOv2 对边界框的位置预测进行约束,将预测边框的中心约束在特定gird网格内,使模型更容易稳定训练,这种方式使得模型的mAP值提升了约 5%。

-
Fine-Grained Features(细粒度特征)
目标检测面临的一个问题是图像中对象会有大有小,输入图像经过多层网络提取特征,最后输出的特征图中(比如YOLO2中输入416×416经过卷积网络下采样最后输出是13*13),较小的对象可能特征已经不明显甚至被忽略掉了。为了更好的检测出一些比较小的对象,最后输出的特征图需要保留一些更细节的信息。
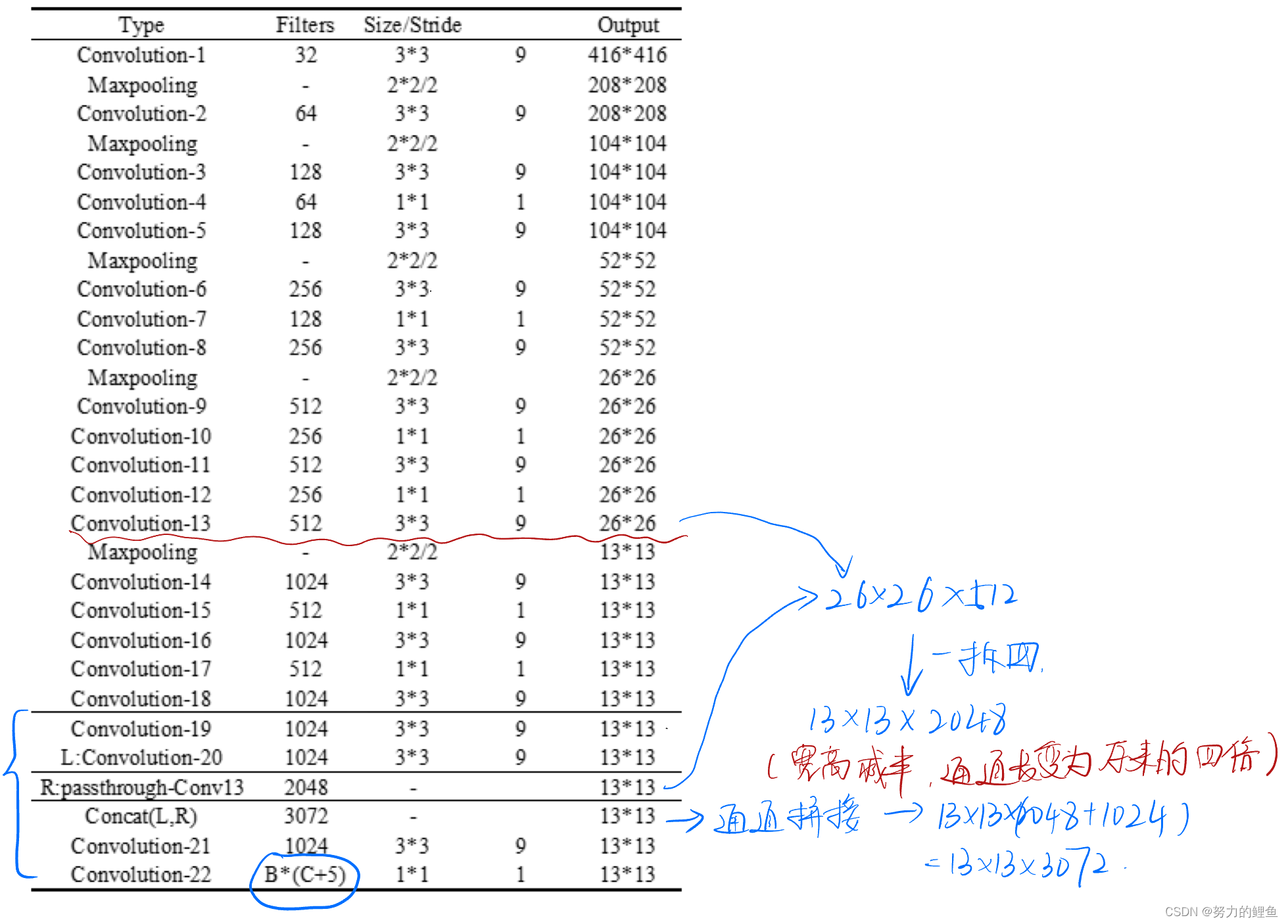
YOLOv2引入一种称为passthrough层的方法在特征图中保留一些细节信息。具体来说,就是在最后一个pooling之前,特征图的大小是26×26×512,将特征图尺寸1拆4(2626拆分成4个1313),直接传递(passthrough)到pooling+conv后的特征图,然后两者叠加到一起作为输出的特征图。使用 Fine-Grained Features,YOLOv2 的性能提升了 1%.


-
Multi-Scale Training(多尺度训练)
Faster
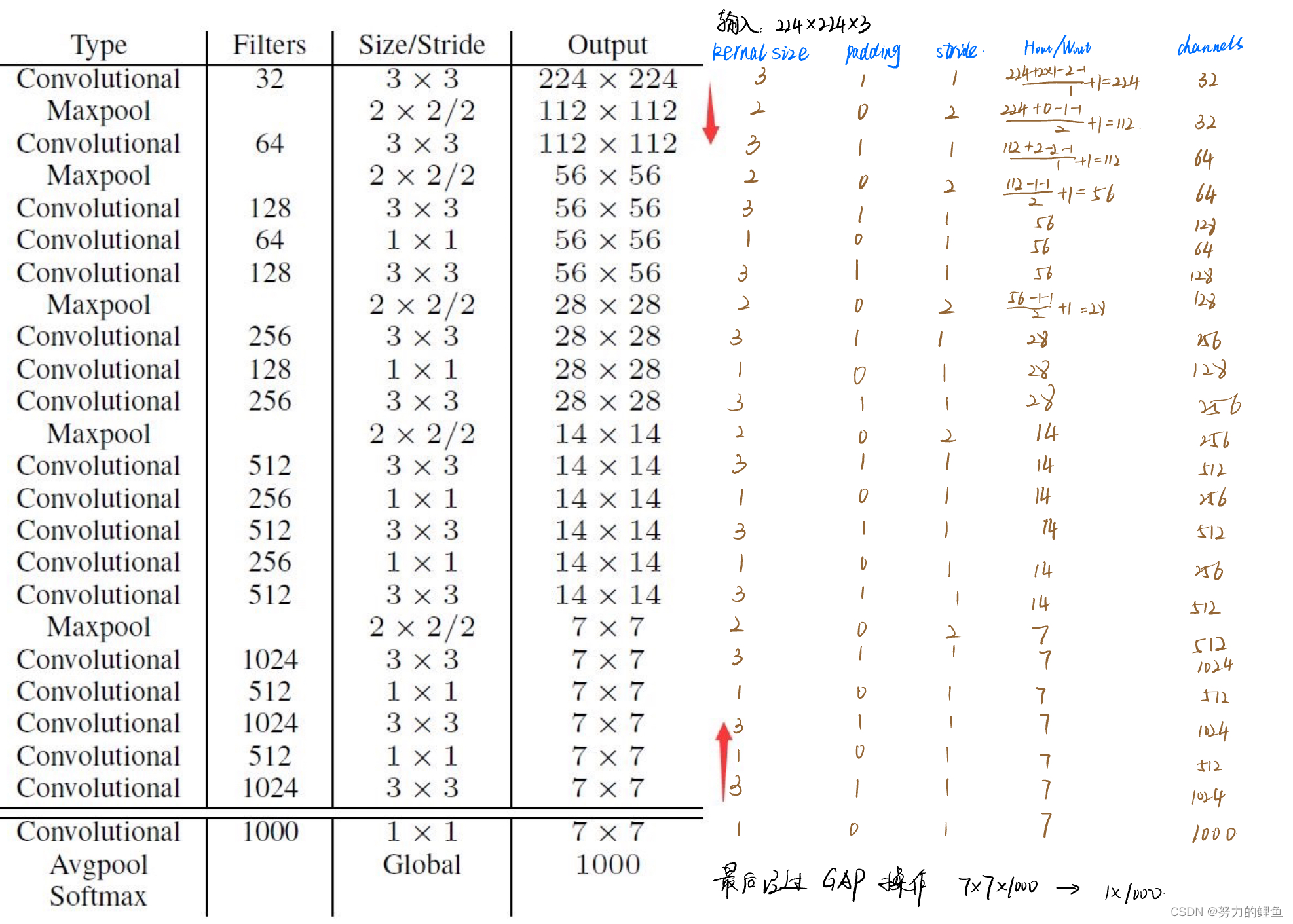
Darknet19包含两个网络结构:分别是用于分类和用于目标检测的网络结构。
用于分类的网络结构如下:
目标检测网络如下:
Darknet19的网络结构:和VGG模型相似,在Darknet19网络中作者使用的大多数是3×3的卷积核,并且在每一次采样操作后,通道个数翻倍;受Network in Network的启发,作者使用global average pooling(全局平均池化)进行预测,并且在3×3卷积之间使用1×1卷积进行特征降维。
Stronger
作者提出了分类、检测训练集联合训练的方案。
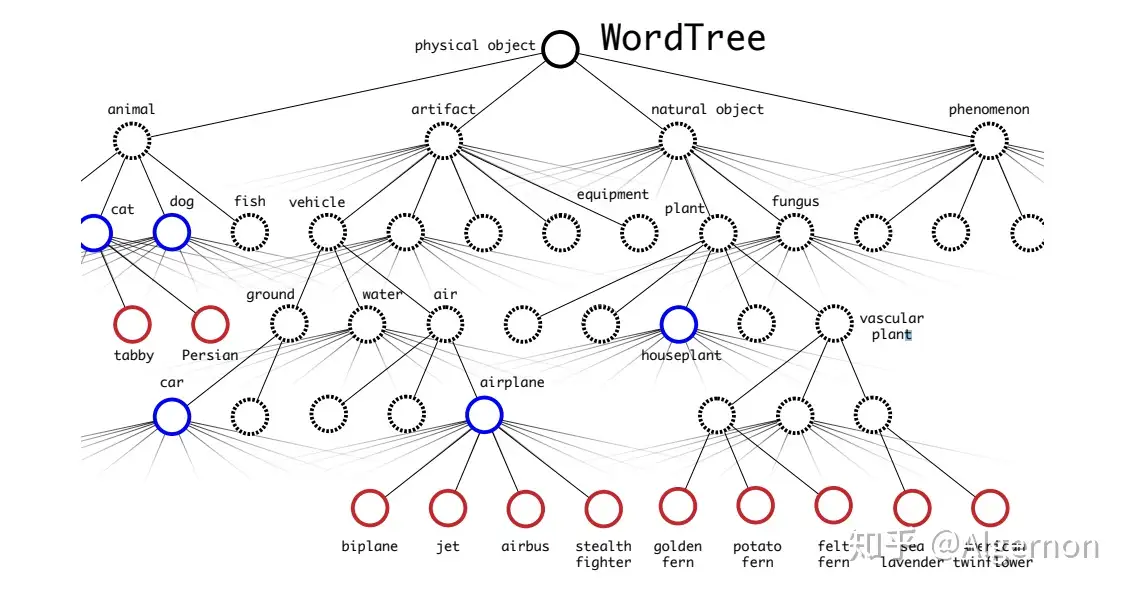
联合分类与检测数据集,这里不同于将网络的backbone在ImageNet上进行预训练,预训练只能提高卷积核的鲁棒性,而分类检测数据集联合,可以扩充识别物体种类。例如,在检测物体数据集中,有类别人,当网络有了一定的找出人的位置的能力后,可以通过分类数据集,添加细分类别:男人、女人、小孩、成人、运动员等等。这里会遇到一个问题,类别之间并不一定是互斥关系,可能是包含(例如人与男人)、相交(运动员与男人),那么在网络中,该怎么对类别进行预测和训练呢?
在文中,作者使用WordTree,解决了ImageNet与coco之间的类别问题。
损失函数

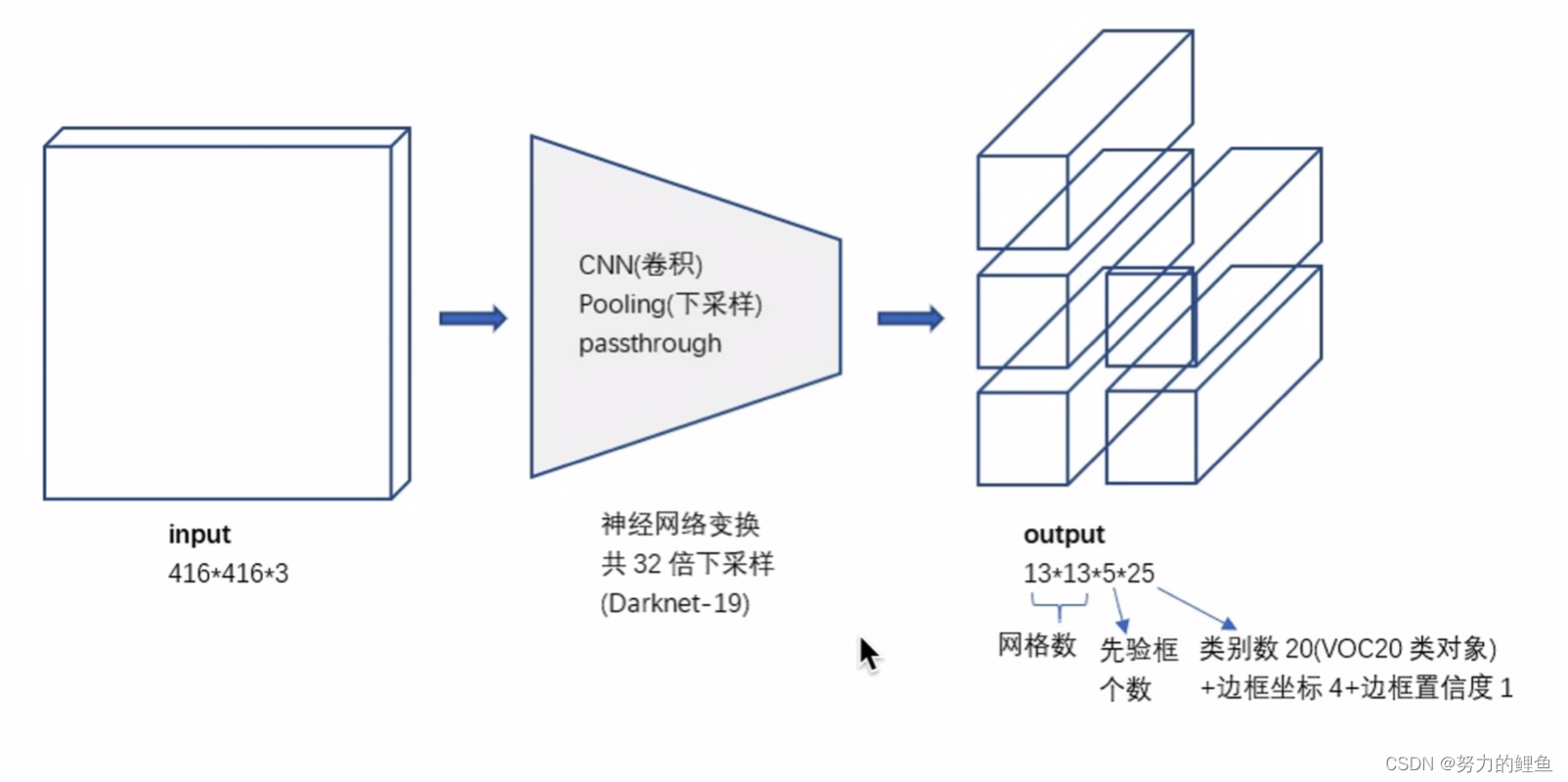
yolo v2 的输出图示