一.NetApp存储操作系统
Data ONTAP是NetApp最流行的存储操作系统,它运行在NetApp FAS(Fabric Attached Storage)系统上。FAS系统是被设计为共享的存储系统,它支持多种SAN和NAS存储协议,并具有灵活的功能。
NetApp还提供在E-系列上运行的SANtricity操作系统。E系列系统是为某些应用程序应用程序需要专用的SAN存储,特别是应用程序需要管理自己的数据。E系列系统从2011年收购Engenio发展而来。
Data ONTAP有两种模式:7模式和集群也称作为群集模式或CDOT)。FAS系统可以运行在7模式或集群,但不能同时运行两种模式。两种模式都完全相同,都是操作和控制存储系统上的所有内容。
7模是是从NetApp的原始操作系统Data ONTAP -7G演进。集群模式是从ONTAP收购的Spinnaker发展而来,群集模式比7模式更具可扩展性。
群集ONTAP的早期软件版本的功能与7模模相比有一些限制。在8.3之前的版本中,NetApp在两个版本中都发布了DataONTAP以供用户选择,两个版本中7模式具有全部的功能和特性,而集群模式有更好的可扩展性。而从8.3开始NetApp专注于开发集群模式,并不在开发7模式。
二.7-mode 可扩展限制
最多两个FAS控制器可以配置为高可用性,HA配对并作为配对系统进行管理。控制器1拥有的磁盘将通过控制器1访问。由单个节点处理的磁盘量和吞吐量是有最大限制的,可以购买额外的HA对,但是它们对客户端来说是单独的系统。
在同一个控制器上磁盘之间无中断地移动数据,但在控制器这间移动将会中断客户端的访单,并且比较复杂。
三.Cluster-mode
为克服7模式的可扩展性限制,NetApp完全重写7模式软件体系结构。集群的DataONTAP是从2003年收购Spinnaker Networks发展而来。
集群Data ONTAP能在NAS协议上扩展到24个节点,可以扩展到支持SAN协议的集群的8个节点。单个集群可以扩展到138PB。并且可以不中断地添加磁盘,磁盘柜和节点。
整个集群可以作为单个系统进行管理。集群可以虚拟化为不同的虚拟存储系统,称为SVM存储虚拟机或Vservers。SVM作为单个系统显示给客户端。可以创建SVM级管理员,SVM管理员呮能访问自己的SVM。数据可以在集群中所有节点之间通过集群互连不中断地移动。
数据处理遍布群集中的不同节点,每个都有自己的CPU,内存和网络资源,可以提供跨集群的性能扩展和负载平衡。数据可以在群集中的多个节点上镜像或缓存数据。
四.磁盘与磁盘柜
NetApp之前使用光纤通道连接控制器与磁盘架,但现在光纤通道磁盘架已经被其本停用了。
目前的型号使用的是SAS(串行连接SCSI)磁盘架,意思是控制器通过SAS端口和线缆连接到机柜。NetApp提供3种类型的磁盘 - SSD固态硬盘,SAS硬盘和SATA硬盘。所有3种类型的磁盘都适用于SAS磁盘架。
- SSD磁盘提供最佳性能,但每GB的成本最高。
- SATA(大容量)磁盘提供最低的性能,但是每GB成本最低。
- SAS(性能)磁盘平衡了每GB的性能和成本。
五.NetApp存储网络
可以通过实施VLAN,可以提高局域网的性能和安全性。将LAN划分为第2层的单独广播域在终端主机插入的端口上配置接入VLAN,只有该特定VLAN的流量才会被发送出访问端口。配置全部在交换机上进行,终端主机不会知道自己的VLAN。
在交换机之间的链路上配置Dot1Q中继,以传输需要携带多个VLAN的流量。当交换机将流量转发到另一个交换机时,它将其标记在具有正确VLAN的第2层Dot1Q头,接收交换机只会转发出来的端那个VLAN。
终端主机通常只是一个VLAN的成员,并不会意识到VLAN的存在。一个特殊情况是虚拟化的主机,其中有多个虚拟机连接到不同的子网,在这种情况下,我们需要将VLAN中继到主机。
NIC Teaming是将多个物理网卡组合成一个逻辑接口, 以提供冗余和(可选)负载平衡。NIC Teaming也被称作为绑定、负载或聚合。当在交换机上将多个物理端口捆绑为一个逻辑链路上时它被称为端口通道(Port Channel),以太通道(Ether channel)或链路束(Link Bundle)。
在服务器上将网卡进行主/备组合,所有流量都将通过主物理端口传输。如果该端口出现故障,流量将自动故障切换到备用端口。对于主备冗余,不需要在交换机上估任何配置。
主动/主动的NIC Teaming,流量将在所有的物理端口上负载平衡。在端口出现故障的情况下,有多个端口提供冗余。对于主动/主动模式,服务器和连接的交换机都需要将物理端口加入一个逻辑链路,两端的配置需要一致。用于协商服务器和交换机之间的协议有:静态802.3ad或LACP链路聚合控制协议,如果服务器和交换机都支持LACP,那么它是首选。
六.SAN存储入门
SAN术语:
- LUN(逻辑单元号)对主机呈现为磁盘
- LUN特定于SAN(而不是NAS)协议
- 客户端被称为发起者
- 存储系统称为目标
光纤通道是原始的SAN协议,并且仍然非常流行。它使用专用适配器,电缆和交换机。不同于以太网在OSI中的分层(包括物理层),FCP通过光纤通道网络发送SCSI命令。光纤通道是一个非常稳定可靠的协议,它是无损的,不像TCP和UDP,它支持2,4,6,8和16 Gbps的带宽
FCP使用WWN全名称进行寻址,WWN是由16个十六进制字符组成的8字节地址,格式为:15:00:00:f0:8c:08:95:de。 WWNN全名称在存储网络中分配给该节点,同一个WWNN可以识别单个网络节点的多个网络接口。
在节点上,每个单独的端为会被分配不同的WWPN全名称端口名。多端口HBA在每个端口上具有不同的WWPN。WWPN相当于以太网中的MAC地址,WWPN被制造商烧录,并保证在全球唯一。WWPN分配到客户端和存储系统上的HBA上,当配置光纤通道网络时,我们主要关心WWPN,而不是WWNN。
可以配置别名进行更方便的配置和故障排除,例如,我们可以为具有WWPN的Exchange Server 15:00:00:f0:8c:08:95:de创建一个名为EXCHANGE-SERVER的别名。可以在光纤通道交换机和存储系统上配置别名。
为了安全起见,将在交换机上配置分区(zoning)以进行控制哪些主机被允许相互通信,在光纤通道网络上服务器被允许与存储系统通信,但是服务器将不允许彼此通信。
将正确的LUN呈现给正确的主机至关重要,如果错误的主机能够连接到LUN,那么它可能会损坏它。分区防止未经授权的主机连接到存储系统,但它不会阻止主机访问它所到达的错误的LUN。在存储系统上配置LUN mask,以将LUN锁定到被授权访问的主机。为了保护存储,需要在交换机上配置分区并存储系统上的LUN masking.
光纤通道网络中的每个交换机将被分配一个唯一的Domain ID,网络中的一个交换机将被自动分配为根交换机,它将为其他交换机分配Domain ID。每个交换机根据他们的Domain ID侦听网络中的其他交换机以及如何路由去其它机换机。
当服务器或存储系统的HBA加电时,它将发送一个FLOGI Fabric登录请求到其本地连接的光纤通道交换机,然后交换机将为其分配24位FCID光纤通道ID地址。分配给主机的FCID由交换机的域ID和主机接入的交换机端口生成。FCID类似于IP地址。由光纤通道交换机使用在服务器及其存储之间路由流量。交换机维护FCID表到WWPN地址映射到主机所在的端口。
光纤通道交换机共享FLOGI数据库信息,彼此使用FCNS光纤通道名称服务(Channel Name Service)。网络中的每个交换机都会学习每个WWPN在哪里以及如何路由。
FLOGI Fabric登录过程完成后,发起者将发送PLOGI端口登录,基于在交换机上的分区配置,主机将学习它可用的目标WWPN。最后发起主机将向其目标发送PLRI进程登录到存储,存储系统将基于它配置的LUN masking授予对主机的访问权限.
在企为中服务器访问其存储是关键任务,必须没有单点失效问题。所以需要配置冗余光纤通道网络。每个服务器和存储系统都将通过冗余的HBA端口连接到两个光纤通道网络。
光纤通道交换机将共享信息彼此分发的信息(例如Domain ID,FCNS数据库和Zoning)。如果其中的一个交换机发生错误能够传播到另一台交换机上,这样使两台交换机失效并降低服务器到存储的连接。因此,不同旁路的FABRIC不要相互交叉连接,两个旁路fabric保持物理分离。主机连接到两个FABRICS,但交换机不是.
存储使用ALUA非对称逻辑单元分配,存储系统告诉客户端哪些是其使用的首选路径。将拥有LUN的节点的直接路径标记为优化路径,其他路径被标记为非优化路径。
在进程登录期间,启动者将检测可用的端口连接到存储目标端口组,并且ALUA将会通知哪些是首选路径,启动者上的多路径软件将选择哪些路径或路径可以到达存储。所有流行的操作系统都有多路径软件,并支持主动/主动或主动/备用路径。客户端的某个端口如果失效将自动故障转移到备用路径。
客户端与SAN存储的连接与以太网的工作方式完全不同。在以太网中,所有的路由和交换决策都是由网络基础设备处理的。但在SAN存储中,由客户端和主机启用多路径智能选择。
在光纤通道中,发起者将通过FLOGI自动检测可用路径,在发起者上的PLOGI和PLRI进程将选择哪个路径或使用路径。
iSCSI是互联网小型计算机系统接口协议,它运行在以太网上,最初被视为一个较少便宜的替代光纤通道方案。它具有更高的头部分组开销,可靠性和性能比光纤通道低。它通过以太网运行,可以共享数据网络或拥有自己的数据专用网络基础设施。TOE(TCP卸载引擎)卡是可以使用的专业适配器,用于降低服务器的CPU负载。有时称为iSCSI HBA。
光纤通道使用WWN来识别发起者和目标,iSCSI使用IQN iSCSI合格名称(或较不常见的EUI扩展唯一)标识符进行寻址。IQN最多可达255个字符,具有以下格式:iqn.yyyy-mm.naming-authority:唯一的名字例如iqn.1991-05.com.microsoft:testHost。IQN作为一个整体分配给主机,类似于Fiber中的WWNN。ISCSI通过以太网运行,因此各个端口由IP地址寻址。
iSCSI不支持光纤通道FLOGI/ PLOGI / PLRI进程,管理员必须通过指定明确地将发启者指向其目标端口组中的IP地址之一,然后,它将发现目标的IQN和TPG中的其他端口。发启器上的多路径软件可以选择哪个路径或要采取的路径。虽然它运行在以太网上,但iSCSI仍然是SAN协议,在发启者上仍使用多路径软件进行智能选路。
LUN masking的配置方式与使用光纤通道相同,在存储系统上使用IQN而不是WWPN识别客户端。iSCSI不支持Zoning。通常在发启都上配置基于密码的身份验证以防范欺骗攻击。端到端也可以启用IPSec加密来增强安全性。
以太网光纤通道(FCoE)是最新的SAN协议,随着10Gbps以太网的出现成为可能,在相同的适配器上以足够的带宽来支持数据和存储流量。
FCoE使用封装在以太网中的光纤通道协议,但在以太网上运行。QoS用于保证存储流量所需的带宽,它保留了光纤通道的可靠性和性能。
以太网光纤通道(FCoE)的工作方式与原本的光纤通道FCP的工作原理一样,只是封装在以太网中,以便可以越过以太网。我们仍然有WWPN的发起者和目标,并使用FLOGI,PLOGI和PLRI过程。
在FCoE中,存储和数据流量都是共享物理接口,存储流量使用FCP,因此需要WWPN。以太网数据流量需要一个MAC地址,以太网数据流量和FCP存储流量的工作原理完全不同,所以我们如何能让物理接口够同时支持他们?答案是 - 我们将物理接口虚拟化为两个虚拟接口:具有以太网数据流量的MAC地址的虚拟NIC和具有WWPN的虚拟HBA用于存储流量。存储和数据流量分为两个不同的VLAN中。
光纤通道在发起者和目标之间传输是无损协议,它确保没有帧丢失。以太网不是无损的。 TCP需要得到接收方的确认,以确认数的据到达目的地。如果确认未被收到,数据包将被重新发送。FCoE使用假设无损网络的FCP,所以我们需要一种方法确保我们的存储数据包在穿过以太网时不会丢失。
PFC优先流量控制用于以太网的FCoE扩展确保无损到达,PFC以逐跳为基础工作。必须在发起者和目标之间的路径中的每个NIC和交换机都必须支持FCoE。具有FCoE功能的网卡被称为CNA融合网络适配器。
- NIC:网络接口适配器, 传统的以太网卡,它被用于NAS协议和iSCSI。
- TOE:TCP卸载引擎, 用于从服务器的CPU中卸载TCP / IP处理,可以提高NAS协议和iSCSI的性能。
- HBA:主机总线适配器。 光纤通道等效于NIC。
- iSCSI HBA:针对iSCSI优化的以太网TOE卡。
- CNA:融合网络适配器。 支持FCoE的10Gb以太网卡。
- UTA:通用目标适配器 支持FCoE的NetApp专有卡或光纤通道。
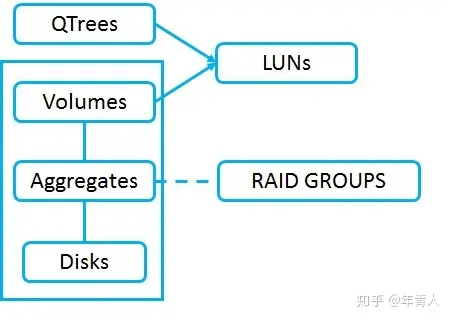
RAID是廉价磁盘或冗余冗余阵列,多个物理磁盘组合成一个逻辑单元提供冗余或改进的性能,或两者兼而有之。与单个磁盘相比,不同的RAID级别提供不同级别的冗余和性能,RAID可以通过操作系统的软件进行管理或由硬件RAID控制器控制。
七.NetApp 存储系统配置
Vol0
- 存储系统出工厂时,它已经安装有Data ONTAP
- 操作系统映像是安装在CompactFlash(CF卡)上
- 系统配置信息存储在硬盘上
- 需要一个已存在的聚合和卷来存放系统配置
- Aggr0和Vol0存在于集群中的每个节点上
- 系统信息包括复制数据库(RDB)和日志文件存储在Vol0上
- 系统信息在集群上的节点网络之间复制
- 不要在Vol0上存放用户数据,它仅用于存储系统信息
复制数据库(RDB)
- RDB包括五个单元:
- 管理网关
- 卷位置数据库
- 虚拟接口管理器
- 阻止配置和操作管理
- 配置复制服务
- 群集中的某一个节点将被选定为每个节点的复制RDB信息
- 相同的节点在发生故障转移时将成为新的主节点
管理网关
- 管理网关提供管理CLI
- 集群作为一个整体,可以通过一个命令行对整个集群进行管理,而不需要对每个节点进行单独的配置
- 通过连接到集群的管理地址来管理集群,可以使用GUI或CLI模式
- 当在集群中发生任何更改时,这些更改将在整个集群所有节点中复制
卷位置数据库(VLDB)
- 卷位置数据库列出哪个聚合包含哪些卷,以及哪个节点包含哪些聚合
- 客户端可以连接到不同的节点查看卷,而不需要到卷的宿主节点上。VLDB允许集群中的所有节点跟踪卷位于哪里
- 管理员可以将卷移动到不同的聚合,这个时候将触发VLDB更新
- VLDB缓存在每个节点的内存中,以优化性能
虚拟接口管理器(VIFMGR)
- 虚拟接口管理器列出逻辑接口当前开启在哪个物理接口上
- IP地址存在于逻辑接口(LIF)
- 如果发生故障切换,逻辑接口可以移动到不同的物理接口
磁盘块配置和操作管理(BCOM)
- BCOM存储关于SAN协议的信息
- 包含LUNs和iGroups (LUN Masking)上的信息
配置复制服务(CRS)
配置复制服务是用于MetroCluster去复制配置和操作数据复制到远程辅协集群
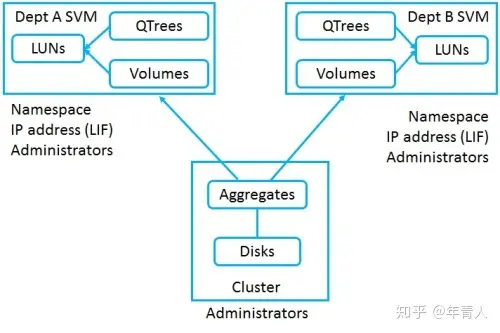
数据SVMs
- 数据SVM向客户端提供数据
- 默认(初始)情况下不存在数据SVM
- 您必须至少有一个数据SVM并包含卷以让客户端访问数据
- 您可以为不同部门创建多个数据SVM来创建分离的安全逻辑存储系统
管理的SVM
- 管理SVM也称为群集管理服务器,它提供对系统的管理访问
- 管理SVM是在系统设置过程中创建的
- 管理SVM不托管用户卷,它是纯粹用于管理访问
- 管理SVM拥有集群管理LIF,集群管理LIF可以故障转移到整个集群中的另一个物理端口
节点SVM
- 节点SVM也纯粹用于管理访问
- 在系统设置期间也创建节点SVM
- 节点SVM拥有该节点的节点管理LIF
- 节点管理LIF可以故障切换到同一个节点的另一个物理端口
- 就像群集管理LIF一样,节点管理LIF也可以用于管理整个集群,而不仅仅是该个体节点
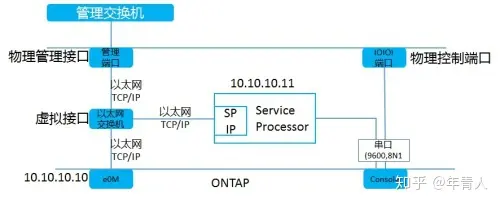
服务处理器(SP)
- 服务处理器提供对于控制器的远程管理功能
- SP是控制器内独立系统,只要电源线连通后,SP例可以使用,即使Data ONTAP处理关闭状态
- 可以通过SP的CLI查看环境属性,如温度、风扇速度、电压等
- 如果管理IP地址没有响应,可以通过连接到Data ONTAP CLI重新启动系统。
- 如果有任何环境限制,SP可以关闭控制器,并通知NetApp支持
cluster1::>system nodeservice-processor network modify –node cluster1-01
-address-type IPv4 -enable true-ip-address 172.23.1.14
-netmask 255.255.255.0 –gateway172.23.1.254
访问服务处理器
有两种方式访问服务处理器
- 通过SSH服务处理器的IP地址
- 在控制器会话中按Ctrl+G, 按Ctrl+D结束会话
登陆到SP需要使用一个特别的用户名:naroot,并使用admin的密码
硬件辅助的故障转移
- HA pair对之间的控制器通过HA连接线相互发送keepaives
- 如果多个keepalives未收到,开始故障转移
- 通过硬件辅助的故障转移,如果检测到自己的控制器失效,SP发送信号到对端控制器并要求立即接管。
授权,有三种授权
- 标准授权
标准许可证是节点锁定许可证。许可证与节点的序列号相关联。如果节点离开集群,许可证将一起离开集群。只要集群中至少有一个节点,功能就可以使用。集群中的每个节点都应具有许可证。
- 站点授权
站点许可证与集群序列号相关,而不是特定的节点。功能可用于集群中的所有节点。如果一个节点离开集群,许可证仍然会留在站点。
- 评估授权
评估许可证是演示许可,有过期时间限制。它们与集群序列号绑定,而不是特定节点。功能可用于集群中的所有节点。如果一个节点离开了集群,许可证仍然会留在站点。
八.NetApp 物理资源与结构
存储结构
SVM (Vservers) 结构
磁盘柜
您可以在堆叠中最多存放10个磁盘柜,最佳做法是不要在相同的堆栈中混合媒体类型,将以0结尾ID分配顶层的磁盘柜。
磁盘(和由它们组成的聚合)属于某一个节点。如果一个节点失效,HA对等体可以获取磁盘的所有权,通过SAS连接的HA对等体是主动/备用结构。节点可以通过集群互连达到其他节点的聚合交换机。
Aggr0 和vol0:当系统通电时,它将从CF卡加载Data ONTAP系统映像,然后从磁盘加载系统信息。最低可访问数据的级别卷(volume)级别,所以需要一个aggr和vol来保存系统信息。系统根集合和卷是Aggr0和Vol0,系统信息在集群中的所有节点上复制,群集中的每个节点都有Aggr0和Vol0。如果系统出厂重置,那么所有磁盘都将被擦除,然后将再创建一个新的Aggr0,并在每个节点上创建Vol0。
Ownership: 必须将磁盘分配给HA对中的特定节点以便使用磁盘。默认情况下磁盘自动分配,自动分配可以在Stack,Shelf或bay级完成。在Stack级别,Stack中的所有磁盘都将分配给连接到Stack上的IOM-A控制器。在Shelf层,Stack中的一半Shelf将分配给每个节点。在bay级别,一个Shelf中的一半磁盘将被分配给每个节点。可以禁用自动磁盘分配,如果这样做,需要手动分配所有新添加的磁盘到系统然后才能使用。在较小的2节点系统上,可能需要将所有磁盘分配给特定的节点,可以做一个大的聚合,这样做,系统将作为主动/待机(而不是每个节点控制一个aggr)。客户端的读写请求将只有一个节点处理。
磁盘分组到RAID组。RAID组被分配给聚合。 RAID组配置是聚合的属性。RAID组配置指定我们拥有多少个数据磁盘、容量,多少个奇偶校验磁盘用于冗余。
RAID组可以是RAID 4或RAID-DP。RAID 4- 单奇偶校, 存在单个硬盘故障,-aggr0的最小大小为2个磁盘,- 正常数据聚合的最小大小为3个磁盘。RAID-DP- 双重奇偶校验,能容忍存在两块硬盘故障,- aggr0的最小大小为3个磁盘,- 正常数据聚合的最小大小为5个磁盘。
RAID组中的磁盘必须是相同类型(SAS,SATA或SSD)相同的大小和速度。
如果硬盘发生故障,系统将自动将其替换为备用磁盘。相同类型、大小和速度的磁盘和数据将被重建。在重建完成之前会出现性能下降。在磁盘系统中应该至少有两种备用磁盘,每种类型的大小和速度。
聚合可以由一个或多个RAID组组成,小的聚合将只有一个RAID组,更大的聚合将会有多个RAID组,目的是在能力和冗余之间取得良好的平衡。可以拥有由16个单个RAID-DP组组成的聚合磁盘,这将给14个数据驱动器的容量和2个奇偶校验磁盘,为了冗余不要把一个48个硬盘的聚合只有一个RAID组。这将给46个数据磁盘和2个奇偶校验磁盘。因为有太多的机会发生多个驱动器故障。磁盘越多故障的机率越高。使用3个大小为16个磁盘的RAID组。这样会提高冗余能力。聚合中的所有RAID组应尽可能接近相同的大小,HDD的推荐RAID组大小为12到20个磁盘;SSD的推荐RAID组大小为20到28个磁盘。我们还需要考虑性能,拥有的磁盘越多,性能越好,因为可以同时从多个磁盘读取和写入数据。
高级磁盘分区,仅在入门级平台(FAS2500)和AFF上支持ADP,它使用RAID-DP,不支持MetroCluster。新的系统配有ADP,运行较早版本的Data ONTAP的系统可以转换为ADP。
标签:RAID,DataONTAP,光纤,交换机,集群,磁盘,NetApp,节点 From: https://www.cnblogs.com/a154172/p/17094489.html