
Loss函数
机器学习中的监督学习本质上是给定一系列训练样本(xi,yi),尝试学习x→y的映射关系,使得给定一个x,即便这个x不在训练样本中,也能够输出y^,尽量与真实的y接近。损失函数是用来估量模型的输出y^与真实值y之间的差距,给模型的优化指引方向。模型的结构风险包括了经验风险和结构风险,损失函数是经验风险函数的核心部分:
θ^=argminθ1N∑i=1NL(yi,f(xi;θ)+λΦ(θ))

式中,前面的均值函数为经验风险,L(yi,f(xi;θ))为损失函数,后面的项为结构风险,Φ(θ)衡量模型的复杂度
首先区分损失函数、代价函数和目标函数之间的区别和联系:
- 损失函数(Loss Function)通常是针对单个训练样本而言,给定一个模型输出y^和一个真实值y,损失函数输出一个实值损失L=f(yi,y^i),比如说:
- 线性回归中的均方差损失:L(yi,f(xi;θ)=(f(xi;θ)−yi)2
- SVM中的Hinge损失:L(yi,f(xi;θ)=max(0,1−f(xi;θ)yi)
- 精确度定义中的0/1损失:L(yi,f(xi;θ)=1)⟺f(xi;θ)≠yi
- 代价函数(Cost Function)通常是针对整个训练集(或者在使用mini-batch gradient descent时的一个mini-batch)的总损失J=∑i=1Nf(yi,y^i),比如说:

- 均方误差:MSE(θ)=1N∑i=1N(f(xi;θ)−yi)2
- SVM的代价函数:SVM(θ)=‖θ‖2+C∑i=1Nξi
- 目标函数(Objective Function)通常是一个更通用的术语,表示任意希望被优化的函数,用于机器学习领域和非机器学习领域(比如运筹优化),比如说,最大似然估计(MLE)中的似然函数就是目标函数
一句话总结三者的关系就是:A loss function is a part of a cost function which is a type of an objective function
1 均方差损失(Mean Squared Error Loss)

均方差(Mean Squared Error,MSE)损失是机器学习、深度学习回归任务中最常用的一种损失函数,也称为 L2 Loss。其基本形式如下:
JMSE=1N∑i=1N(yi−y^i)2

2 平均绝对误差损失(Mean Absolute Error Loss)
平均绝对误差(Mean Absolute Error Loss,MAE)是另一类常用的损失函数,也称为L1 Loss。其基本形式如下:

MAE与MSE的区别:
- MSE比MAE能够更快收敛:当使用梯度下降算法时,MSE损失的梯度为−y^i,而MAE损失的梯度为±1。所以。MSE的梯度会随着误差大小发生变化,而MAE的梯度一直保持为1,这不利于模型的训练
- MAE对异常点更加鲁棒:从损失函数上看,MSE对误差平方化,使得异常点的误差过大;从两个损失函数的假设上看,MSE假设了误差服从高斯分布,MAE假设了误差服从拉普拉斯分布,拉普拉斯分布本身对于异常点更加鲁棒
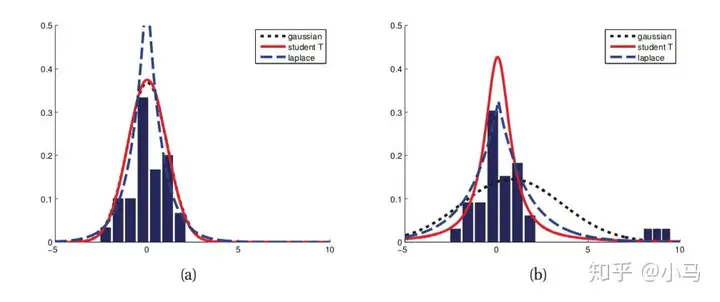
3 Huber Loss
Huber Loss是一种将MSE与MAE结合起来,取两者优点的损失函数,也被称作Smooth Mean Absolute Error Loss 。其原理很简单,就是在误差接近0时使用MSE,误差较大时使用MAE,公式为:

可以看到在 [−δ,δ]内实际上就是MSE的损失,使损失函数可导并且梯度更加稳定;在(−∞,δ)和(δ,∞)区间内为MAE损失,降低了异常点的影响,使训练更加鲁棒
4 分位数损失(Quantile Loss)
分位数回归Quantile Regression是一类在实际应用中非常有用的回归算法,通常的回归算法是拟合目标值的期望(MSE)或者中位数(MAE),而分位数回归可以通过给定不同的分位点,拟合目标值的不同分位数。例如我们可以分别拟合出多个分位点,得到一个置信区间,如下图所示:
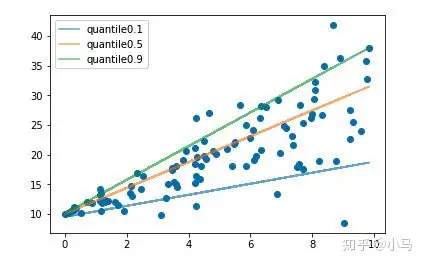
分位数回归是通过使用分位数损失Quantile Loss来实现这一点的,分位数损失形式如下:
Jquant=1N∑i=1NIy^i≥yi(1−r)|yi−y^i|+Iy^i<yir|yi−y^i|
式中的r为分位数,这个损失函数是一个分段的函数,将y^i≥yi(高估)和 y^i<yi (低估)时,低估的损失要比高估的损失更大;反之,当r<0.5 时,高估的损失要比低估的损失更大,分位数损失实现了分别用不同的系数控制高估和低估的损失,进而实现分位数回归。特别地,当r=0.5时,分位数损失退化为MAE损失,从这里可以看出 MAE 损失实际上是分位数损失的一个特例—中位数回归
Jquantr=0.5=1N∑i=1N|yi−y^i|
5 交叉熵损失(Cross Entropy Loss)
对于分类问题,最常用的损失函数是交叉熵损失函数(Cross Entropy Loss)
5.1 二分类:
考虑二分类,在二分类中我们通常使用Sigmoid函数将模型的输出压缩到(0,1)区间内,y^i∈(0,1),用来代表给定输入xi,模型判断为正类的概率。由于只有正负两类,因此同时也得到了负类的概率:
p(yi=1|xi)=y^ip(yi=0|xi)=1−y^i
将两条式子合并成一条:
p(yi|xi)=(y^i)yi(1−y^i)1−yi
假设数据点之间独立同分布,则似然可以表示为:
L(x,y)=∏i=1N(y^i)yi(1−y^i)1−yi
对似然取对数,然后加负号变成最小化负对数似然,即为交叉熵损失函数的形式:
NLL(x,y)=JCE=−∑i=1Nyilog(y^i)+(1−yi)log(1−y^i)
下图是对二分类的交叉熵损失函数的可视化:
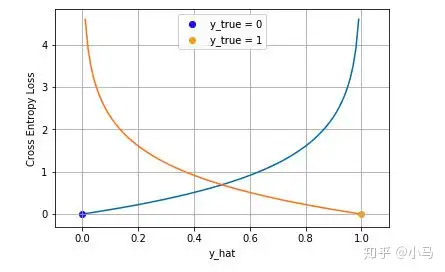
蓝线是目标值为0时输出不同输出的损失,黄线是目标值为1时的损失。可以看到约接近目标值损失越小,随着误差变差,损失呈指数增长
5.2 多分类:
在多分类的任务中,交叉熵损失函数的推导思路和二分类是一样的,变化的地方是真实值yi是一个One-hot 向量,同时模型输出的压缩由原来的Sigmoid函数换成Softmax函数。Softmax 函数将每个维度的输出范围都限定在(0,1)之间,同时所有维度的输出和为1,用于表示一个概率分布
p(yi|xi)=∏k=1K(y^ik)yik
其中,k∈K表示K个类别中的一类,同样的假设数据点之间独立同分布,可得到负对数似然为:
NLL(x,y)=JCE=−∑i=1N∑k=1Kyiklog(y^ik)
由于yi是一个One-hot向量,除了目标类为1之外其他类别上的输出都为 0,因此上式也可以写为:
JCE=−∑i=1Nyicilog(yic^i)
其中,ci是xi的目标类,通常这个应用于多分类的交叉熵损失函数也被称为Softmax Loss或者Categorical Cross Entropy Loss
5.3 Logistics loss和Cross Entropy Loss:
对于Logistics loss,我们说的是二分类问题,y^是一个数;对于Cross Entropy Loss,我们说的是多分类问题,y^是一个k维的向量。当k=2时,Logistics loss与Cross Entropy Loss一致
5.4 为什么用交叉熵损失:
分类中为什么不用均方差损失?上文在介绍均方差损失的时候讲到实际上均方差损失假设了误差服从高斯分布,在分类任务下这个假设没办法被满足,因此效果会很差
为什么是交叉熵损失呢?
(1)一个角度是用最大似然来解释:也就是我们上面的推导
(2)另一个角度是用信息论来解释交叉熵损失:假设对于样本xi 存在一个最优分布yi⋆真实地表明了这个样本属于各个类别的概率,那么我们希望模型的输出y^i尽可能地逼近这个最优分布,在信息论中,我们可以使用KL散度(Kullback–Leibler Divergence)来衡量两个分布的相似性。给定分布p和分布q, 两者的 KL 散度公式如下:
KL(p,q)=∑k=1Kplog(p)−∑k=1Kplog(q)
其中第一项为分布p的信息熵,第二项为分布p和分布q的交叉熵。将最优分布yi⋆和输出分布y^i代入分布p和分布q得到:
KL(yi⋆,y^i)=∑k=1Kyi⋆log(yi⋆)−∑k=1Kyi⋆log(y^i)
由于我们希望两个分布尽量相近,因此我们最小化KL散度。同时由于上式第一项信息熵仅与最优分布本身相关,因此我们在最小化的过程中可以忽略掉,变成最小化
∑k=1Kyi⋆log(y^i)
我们并不知道最优分布yi⋆,但训练数据里面的目标值yi 可以看做是yi⋆的一个近似分布:
−∑k=1Kyilog(y^i)
这个是针对单个训练样本的损失函数,如果考虑整个数据集,则:
JKL=−∑i=1N∑k=1Kyiklog(y^ik)=−∑i=1Nyicilog(yic^i)
可以看到通过最小化交叉熵的角度推导出来的结果和使用最大化似然得到的结果是一致的
(3)最后一个角度为BP过程:当使用平方误差损失函数时,最后一层的误差为δ(l)=−(y−a(l))f′(z(l)),其中最后一项为f′(z(l)),为激活函数的导数。当激活函数为Sigmoid函数时,如果z(l)的值非常大,函数的梯度趋于饱和,即f′(z(l))的绝对值非常小,导致δ(l)的取值也非常小,使得基于梯度的学习速度非常缓慢;
当使用交叉熵损失函数时,最后一层的误差为δ(l)=f(zk(l))−1=ak~(l)−1,此时导数是线性的,因此不存在学习速度过慢的问题
引入交叉熵损失函数目的是解决一些实例在刚开始训练时学习得非常慢的问题,其主要针对激活函数为Sigmod 函数,如果在输出神经元是S型神经元时,交叉熵一般都是更好的选择,交叉熵无法改善隐藏层中神经元发生的学习缓慢,交叉熵损失函数只对网络输出明显背离预期时发生的学习缓慢有改善效果, 交叉熵损失函数并不能改善或避免神经元饱和,而是当输出层神经元发生饱和时,能够避免其学习缓慢的问题。可参考
Evan:深度学习-bp神经网络8 赞同 · 1 评论文章
6 合页损失(Hinge Loss)
合页损失(Hinge Loss)是另外一种二分类损失函数,适用于 maximum-margin 的分类,支持向量机Support Vector Machine (SVM)模型的损失函数本质上就是Hinge Loss + L2正则化。合页损失的公式如下:
Jhinge=∑i=1Nmax(0,1−sgn(yi)y^i)
下图是y为正类,即sgn(y)=1时,不同输出的合页损失示意图:
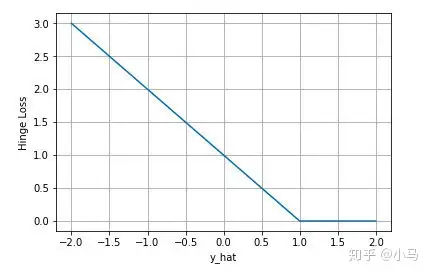
可以看到当y为正类时,模型输出负值会有较大的惩罚,当模型输出为正值且在(0,1)区间时还会有一个较小的惩罚。即合页损失不仅惩罚预测错的,并且对于预测对了但是置信度不高的也会给一个惩罚,只有置信度高的才会有零损失。使用合页损失直觉上理解是要找到一个决策边界,使得所有数据点被这个边界正确地、高置信地被分类
7 0/1损失函数
0/1损失函数是指预测值和目标值不相等为1, 否则为0:
L(Y,f(X))={1,Y≠f(X)0,Y=f(X)
(1)0/1损失函数直接对应分类判断错误的个数,但是它是一个非凸函数,不太适用
(2)感知机就是用的这种损失函数。但是相等这个条件太过严格,因此可以放宽条件,即满足 |Y−f(x)|<T 则认为相等:
L(Y,f(X))={1,|Y−f(X)|≥T0,|Y=f(X)|<T
8 指数损失
指数损失函数的标准形式如下:L(Y,f(X))=exp(−Yf(X))
Adaboost中使用了指数损失函数,李航书中证明了:Adaboost算法是前向分步算法的特例,模型是由基本分类器组成的加法模型,损失函数为指数函数
9 对数损失/对数似然损失(Log-likelihood Loss)
log对数损失函的标准形式如下:L(Y,P(Y|X))=−logP(Y|X)
log对数损失函数能非常好的表征概率分布,在很多场景尤其是多分类,如果需要知道结果属于每个类别的置信度,那它非常适合;健壮性不强,相比于hinge loss对噪声更敏感
10 参考资料
[1] https://zhuanlan.zhihu.com/p/77686118
[2] https://blog.csdn.net/Tianlock/article/details/88232467
[4] https://www.zhihu.com/question/271846573
[5] 李宏毅机器学习课程SVM
[6] 李航统计学习方法第二版
[7] https://zhuanlan.zhihu.com/p/58883095
[8] https://www.cnblogs.com/hejunlin199
标签:yi,Loss,常用,xi,函数,损失,1N From: https://www.cnblogs.com/oceaning/p/17071416.html