前言
相信大部分面试都是说用 Redis 去实现分布式锁,用 Zookeeper 实现分布式锁相对而言遇到的较少,最近在整理之前的面经答案,因此特意写篇博客解释一下。
实现一把分布式锁通常有很多方法,比较常见的有 redis 和 Zookeeper。相信大家对 redis 实现分布式锁已经非常了解,今天介绍的是如何通过 Zookeeper 去实现一把分布式锁。
首先 Zookeeper 为什么能实现一把分布式锁呢?这是因为它有一个特性,就是多个线程去 Zookeeper 里面去创建同一个节点的时候,只会有一个线程去执行成功。
Zookeeper 的 ZNode 节点
在了解 Zookeeper 实现分布式锁之前,首先,我们需要了解 Zookeeper 里面节点相关的知识。
Zookeeper 里面的节点可以分为两大类,一种是临时节点,一种是持久化节点。
临时节点,指的是节点创建后,如果创建节点的客户端和 Zookeeper 服务端的会话失效(例如断开连接),那么节点就会被删除。
持久化节点指的是节点创建后,即使创建节点的客户端和 Zookeeper 服务端的会话失效(例如断开连接),节点也不会被删除,只有客户端主动发起删除节点的请求,节点才会被删除。
另外还有一种节点叫做有序节点,这种节点在创建时会有一个序号,这个序号是自增的。有序节点既可以是有序临时节点,也可以是有序持久化节点。
Zookeeper 中所有的数据都是通过节点来存储的,它的目录结构就像一个文件树,如下图。
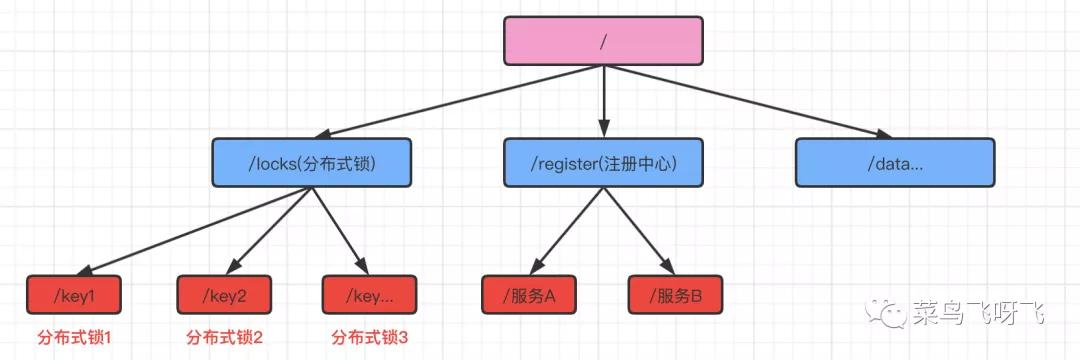
Zookeeper结构
图中的 locks、register、data 这几个目录自定义创建的,分别用来存储不同业务的数据,例如 locks 用来存放分布式锁相关的信息,register 用来存放注册中心相关的数据。
现在我们要获取一个分布式的所,那么假设这个锁的 K 叫做 K1,那么现在有一个客户端 a,然后去 JK 里面去创建一个分布式的,所创建 K1 这个分布式锁,那么他就会在 nex 这个目录下面创建一个叫做 K1 的文件夹,叫做 K1 的文件。现在我们要获取一个分布式的所,那么假设这个锁的 K 叫做 K1,那么现在有一个客户端 a,然后去 JK 里面去创建一个分布式的,所创建 K1 这个分布式锁,那么他就会在 nex 这个目录下面创建一个叫做 K1 的文件夹,叫做 K1 的文件。
如何实现
采用 Zookeeper 实现分布式锁,有两种方案:1. 基于临时节点实现;2. 基于临时顺序节点实现。下面以及介绍这种方案的实现原理。
首先,假设所有的分布式锁都存储在 locks 这个目录中。
方案一:基于临时节点实现(不推荐)
假设现在有客户端 A、B、C 均来获取同一把分布式锁:Key1。
首先,客户端 A 来获取分布式锁 Key1,那么它就会尝试在 locks 这个目录下去创建一个叫做 Key1 的 ZNode 节点。如果这个时候 locks 目录里面没有 Key1 这个 ZNode 节点,那么客户端 A 就能成功创建 Key1 节点,这就表示客户端 A 成功获取到了 Key1 这把锁锁。

图1
同时,客户端 B 也来获取 Key1 这把锁。客户端 B 也需要去 locks 这个目录里面去创建 Key1 ZNode 节点,这个时候,由于 Key1 这个 ZNode 节点已经存在,所以客户端 B 就会创建失败。而创建失败就表示客户端 B 获取锁失败,所以这个时候客户端 B 就会向 Zookeeper 注册自己的监听器(Watcher),监听 Key1 这个 ZNode 节点的变化(当 Key1 节点发生变化时,Zookeeper 会通知到客户端 B)。
如果客户端 A 和客户端 B,是同时请求到 Zookeeper,那么 Zookeeper 它有一个机制,它会保证只会有其中一个客户端能创建成功 Key1 这个 ZNode 节点。

图2
同理,此时客户端 C 来获取 Key1 锁时,也是无法获取到锁,也会把自己的 Watcher 注册到 ZK 中,监听 Key1 这个 ZNode 节点的变化。
当客户端 A 处理完自己的业务逻辑之后,那么就会执行释放锁的操作。释放锁时,客户端删除 Key1 节点,如果节点删除成功就表示锁释放成功。当 Key1 这个节点被删除后,Zookeeper 就会通知所有监听 Key1 这个节点的客户端,也就是客户端 B、C。
当客户端 B 和 C 接到通知以后,知道 Key1 节点发生了变化,这个时候它们就会重新去请求 Zookeeper,尝试在 locks 目录下面创建 Key1 节点,这个时候也只会有一个客户端能成功创建 Key1 节点。假如说是客户端 B 创建成功了,那么就表示客户端 B 成功获取到了锁.客户端 C 获取锁失败,那么就继续去监听 Key1 这个节点的变化。

图3
为什么不推荐
以上就是基于临时节点这个方案去实现 Zookeeper 分布式锁,但是这个方案通常是不被推荐的。为什么呢?这是因为使用这个方案会存在一个很大的问题:羊群效应。
什么意思呢?
从上面的过程中我们可以看到,当客户端 A 释放锁成功以后,Zookeeper 需要去通知所有监听 Key1 这个节点的客户端。上面我们的例子中只有客户端 B 和客户端 C,但是在实际应用中可能有成百上千个客户端,甚至更多。Zookeeper 在这一瞬间需要发送成百上千个请求,首先这个效率显然是不高的,另外当分布式锁的竞争较为激烈时,极有可能在这一瞬间 Zookeeper 的网卡可能被撑爆。而且系统中可能并不仅仅存 Key1 这一把锁,还会存在 Key2、Key3、Key4...,这些锁也会存在竞争,Zookeeper 的压力会更大。
在这个过程中,我们很明显地能感觉到这是不合理的,因为获取分布式锁时肯定是只有其中一个客户端能获取到,那么当 Key1 这个节点被删除以后,需要通知其他的客户端来获取锁,这个时候我们有必要去通知所有的客户端吗?
显然是没有必要的,我们只需要通知其中一个客户端就可以了。因此方案二出现了。
方案二:基于临时顺序节点实现(推荐)
基于临时顺序节点去实现分布式锁时,就不是在 Linux 这个目录下面创建 Key1 这个临时节点了。而是先在 locks 这个目录下面创建一个 Key1 目录,然后在 Key1 目录里面去创建临时顺序节点。
假设现在客户端 a 来获取分布式锁 Key1,那么这个时候客户端 A 就会在 Key1 这个目录里面创建一个临时顺序节点,这个临时顺序节点的序号是 001。
然后客户端 A 会判断自己创建的这个临时顺序节点 001 在 Key1 这个目录里面,它的序号是不是最小的?如果是最小的,那么就表示客户端 A 获取锁成功。
接着客户端 B 也来获取 Key1 这个分布式锁,它也会在 Key1 这个目录下面去创建一个临时顺序节点,由于这个时候自增序号已经变为 002 了,因为之前已经创建过 001 了,所以客户端 B 会创建 002 这个临时顺序节点。

图4
同理,客户端 B 也会判断自己当前创建的临时顺序节点 002,是不是当前 Key1 目录中序号最小的临时节点,显然不是,因为前面有一个 001 临时顺序节点,所以客户端 B 这个时候是获取锁失败。
当客户端 B 获取锁失败之后,它会把自己的监听器注册到 Zookeeper,它监听的是它前面一个临时顺序节点,也就是 001 这个顺序节点。

图5
此时如果客户端 C 也来获取分布式锁 Key1,这个时候它就会在 Key 目录中创建临时顺序节点 003,同样 003 也不是序号最小的临时顺序节点,所以客户端 C 也获取锁失败,接着它会去监听 002 这个临时顺序节点。
当客户端 A 处理完业务逻辑之后,它就会去释放锁。释放锁的操作就是去删除 Key1 这个目录下面客户端 A 所创建的临时顺序节点,也就是删除 001 这个临时顺序节点。当 001 这个顺序节点被删除以后,Zookeeper 就会去通知监听 001 这个顺序节点的所有客户端,也就是通知客户端 B。客户端 B 接收到 Zookeeper 的通知之后,它就会去判断我当前创建的临时顺序节点 002 是不是当前 Key1 这个目录中序号最小的一个临时顺序节点。此时由于 001 这个顺序节点已经不存在了,显然 002 是最小的了,因此客户端 B 就获取锁成功。

图6
同样当客户端 B 释放锁之后,就会将 002 删除,002 删除以后,Zookeeper 会通知客户端 C,客户端 C 发现我当前创建的临时顺序节点 003 是 Key1 这个目录里面最小的序号,所以客户端 C 获取锁成功。
思考
当客户端 A 获取锁成功以后,长时间不释放锁,或者说客户端 A 所在的机器宕机,或者客户端 A 所在的机器出现网络故障,这个时候会出现什么状况?
当客户端 A 所在的机器出现宕机,或者出现网络故障后,长时间不和 Zookeeper 通信的时候,客户端 A 和 Zookeeper 之间创建的 Session 就会失效,当这个 Session 失效以后,Zookeeper 会将客户端 A 所创建的临时顺序节点给直接删除,这个时候其他的客户端就能正常获取锁了。
标签:创建,Key1,Zookeeper,原理,分布式,节点,客户端 From: https://www.cnblogs.com/LoveShare/p/17052728.html