因为有的网站被攻击之后会被攻击者悄悄挂上暗链,用来提升恶意网站的搜索权重排名,突发奇想看一下暗链扫描工具是咋做的,去github上翻了一下,这次分析Libra
项目地址:https://github.com/rabbitmask/Libra
项目功能:网站篡改、暗链、死链监测平台
这里我们只分析暗链检测
使用
因为这里我想要测试暗链检测的功能,随便找一个18禁网址进行暗链检测
python3 Libra.py -u http://*******
运行结束后就会输出一份报告,并且列出具体结果
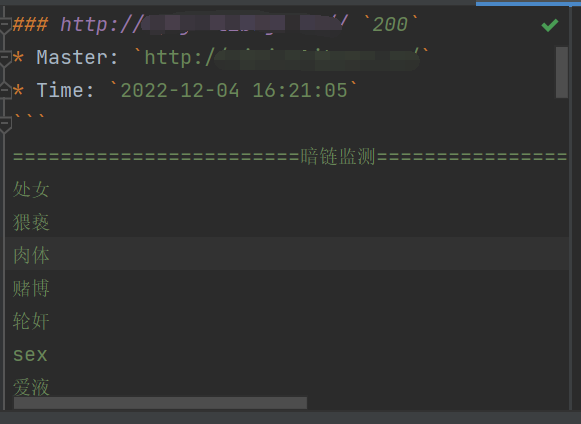
实际在运行过程中会有一些问题,我自行在代码里进行了部分修改
原理
暗链检测原理很清晰:
- 输入待检测网址
- 获取该网址内的所有URL
- 获取这些URL的源代码
- 检测源代码中是否存在暗链关键字
- 保存结果
下面对每一步进行阐述
输入待检测网址
这里使用argparse库来获取解析用户的输入参数,可以形成我们常见的命令行效果
如果我们输入--help参数就能够查看到使用用法
源代码如下
parser = argparse.ArgumentParser()
parser.add_argument("-u", dest='url',help="The Target Url")
parser.add_argument("-m", dest='monitor',help="Monitor The Target Url")
parser.add_argument("-f", dest='file',help="The List Of Target Urls")
args = parser.parse_args()
看代码可以知道我们 -u 的时候就是输入待检测网址
获取该网址内的所有URL
跟进代码在crawler_api方法里面能够获取网址内的所有URL,这里的方式是通过re.compile直接匹配正则
def crawler_api(url):
if isinstance(url, str):
out_link=[]
in_link=[]
html=GetData(url)[1]
href = re.compile('href="(.*?)"')
src = re.compile('src="(.*?)"')
res_href = href.findall(html)
res_src = src.findall(html)
res_html = res_href+res_src
in_link.append(url)
for i in res_html:
file_ok=True
for j in file_type_black:
if j in i:
file_ok = False
break
if file_ok and len(i)>0:
# print(i)
if i[:4] == 'http':
out_link.append(i)
else:
if i[0]=='/':
in_link.append(url+i)
else:
in_link.append(url+'/'+ i)
res=[]
for i in list(set(out_link+in_link)):
tmp=[]
tmp.append(i)
tmp.append(url)
res.append(tmp)
return res
获取这些URL的源代码
在getData方法中获取源代码
def GetData(url):
try:
r = requests.get(url, headers=headers, timeout=5)
r.encoding = 'utf-8'
return r.status_code,r.text
except(requests.exceptions.ReadTimeout,requests.exceptions.ConnectTimeout,requests.exceptions.ConnectionError):
return 'Timeout','Timeout'
检测源代码中是否存在暗链关键字
在hlfind方法中检测是否存在暗链关键字
def hlfind(res):
rules = []
host = True
re_rules_list = get_re()
for re_rules in re_rules_list:
result = re.findall(r'{}'.format(re_rules[0]), res, re.S)
if result != []:
rules.append(re_rules[0])
host = False
if host == False:
return rules
else:
pass
保存结果
通过libra_log方法保存检测后的数据
def libra_log(url,master,res_comparer,res_hlfind,res_diedlink,filename):
if res_comparer or res_hlfind or res_diedlink != 200:
fw = open(filename, 'a',encoding="utf-8")
fw.write('### '+url+' `'+str(res_diedlink)+'` '+'\n')
fw.write('* Master: `'+master+'`\n')
fw.write('* Time: `'+ getDate()+'`\n')
fw.write('```\n')
if res_comparer:
fw.write('========================篡改监测===============================\n')
if push_token:
push(master, "篡改监测", getDate())
for i in res_comparer:
if i[0]=='+' or i[0]== '-' or i[0] =='?':
fw.write(i+'\n')
if res_hlfind:
fw.write('========================暗链监测===============================\n')
if push_token:
push(master, "暗链监测", getDate())
for i in res_hlfind:
fw.write(i+'\n')
if res_diedlink != 200:
fw.write('========================死链监测===============================\n')
if push_token:
push(master, "死链监测", getDate())
fw.write(url+' '+str(res_diedlink)+'\n')
fw.write('==============================================================\n')
fw.write('```\n\n')
fw.close()
总结
代码整体的流程很清晰,但URL提取和关键字列表还有待维护,通过修改数据库中的关键字列表来进行优化即可
本来想自己写一个插件的,逻辑比较简单就算了
END
建了一个微信的安全交流群,欢迎添加我微信备注进群,一起来聊天吹水哇,以及一个会发布安全相关内容的公众号,欢迎关注