摘要
目前的图像文本预训练模型通常通过每个模态全局特征的相似性来建模跨模态的交互,然而这会导致缺乏足够的信息;或者通过在视觉/文本token上使用跨模态注意力/自注意力来建模细粒度的交互,但这会降低训练/推理效率。因此作者提出了一种大规模细粒度的交互模型FILIP,通过跨模态交互实现更精细的对齐。同时作者还构建了一个大规模的图像-文本对数据集FILIP300M用于预训练。
方法
FINE-GRAINED CONTRASTIVE LEARNING
跨模态的对比学习想要的是同一个图像文本对经过image encoder得到的全局特征以及经过text encoder得到的特征在embedding space尽可能接近。
CROSS-MODAL LATE INTERACTION
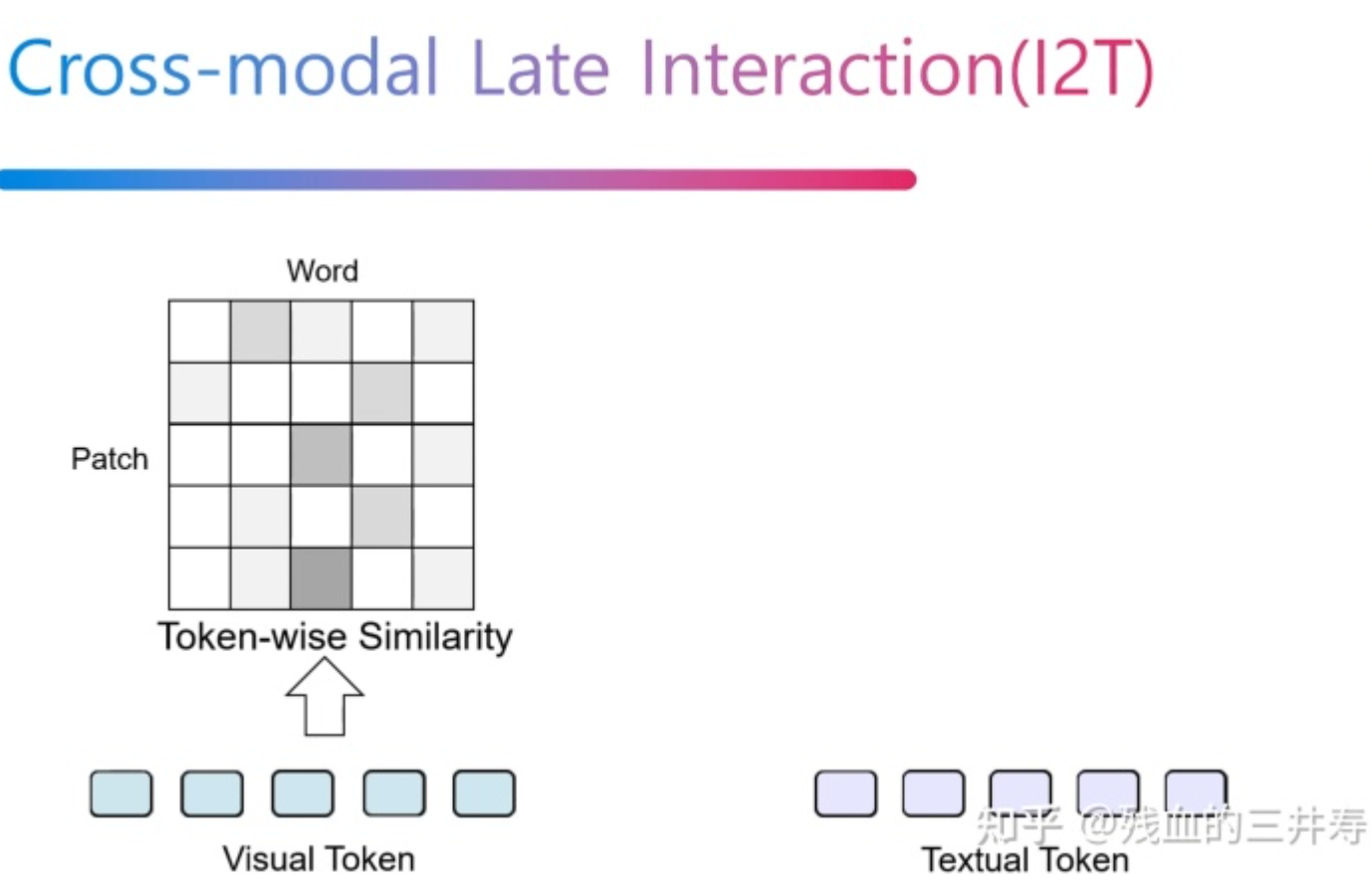
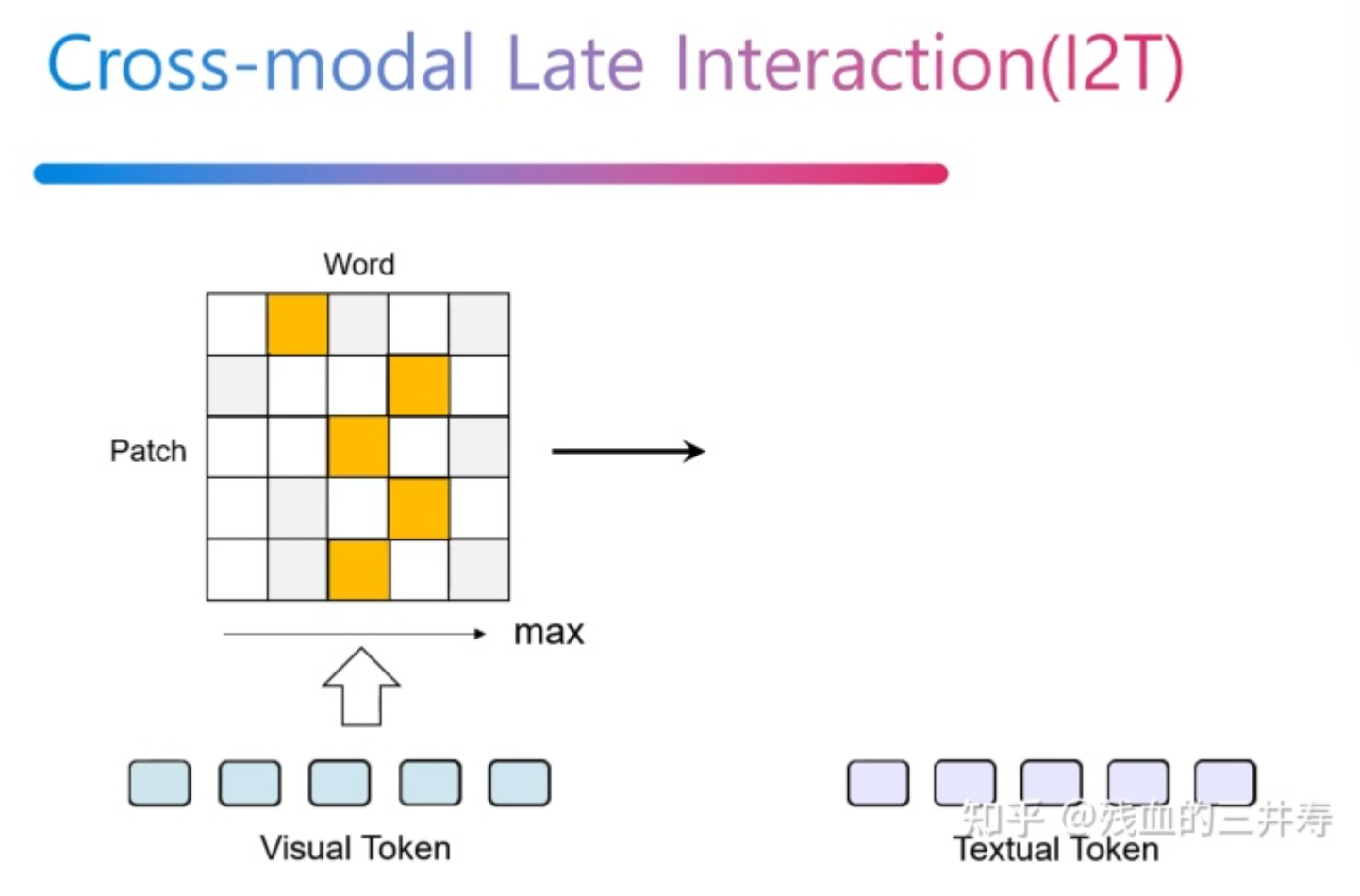
CLIP等方法使用编码后的视觉全局特征与文本特征计算相似度,忽略了细粒度的交互(例如word与patch的对齐)。为此作者提出了CROSS-MODAL LATE INTERACTION,设n1是第i张图像的token数,n2是第j个文本的token数,对于第k个视觉token,作者将其与全部n2个文本token计算相似度,并取值最大的一个作为token级别的相似度:
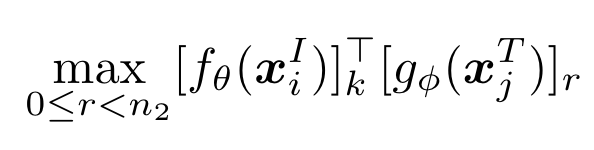
之后取这些相似度的均值作为当前图像与文本的相似度。文章公式比较繁琐,可以直接看图:
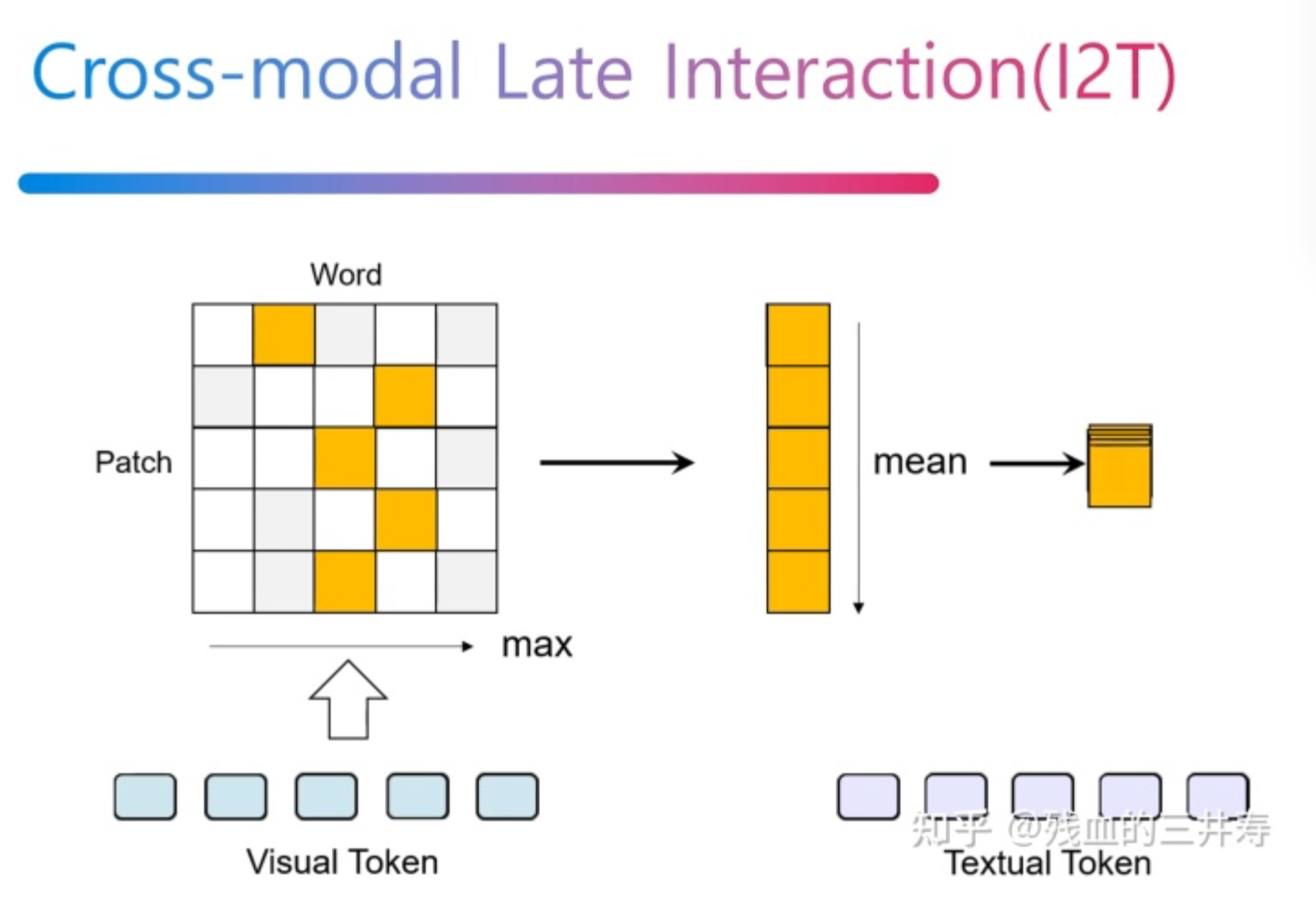
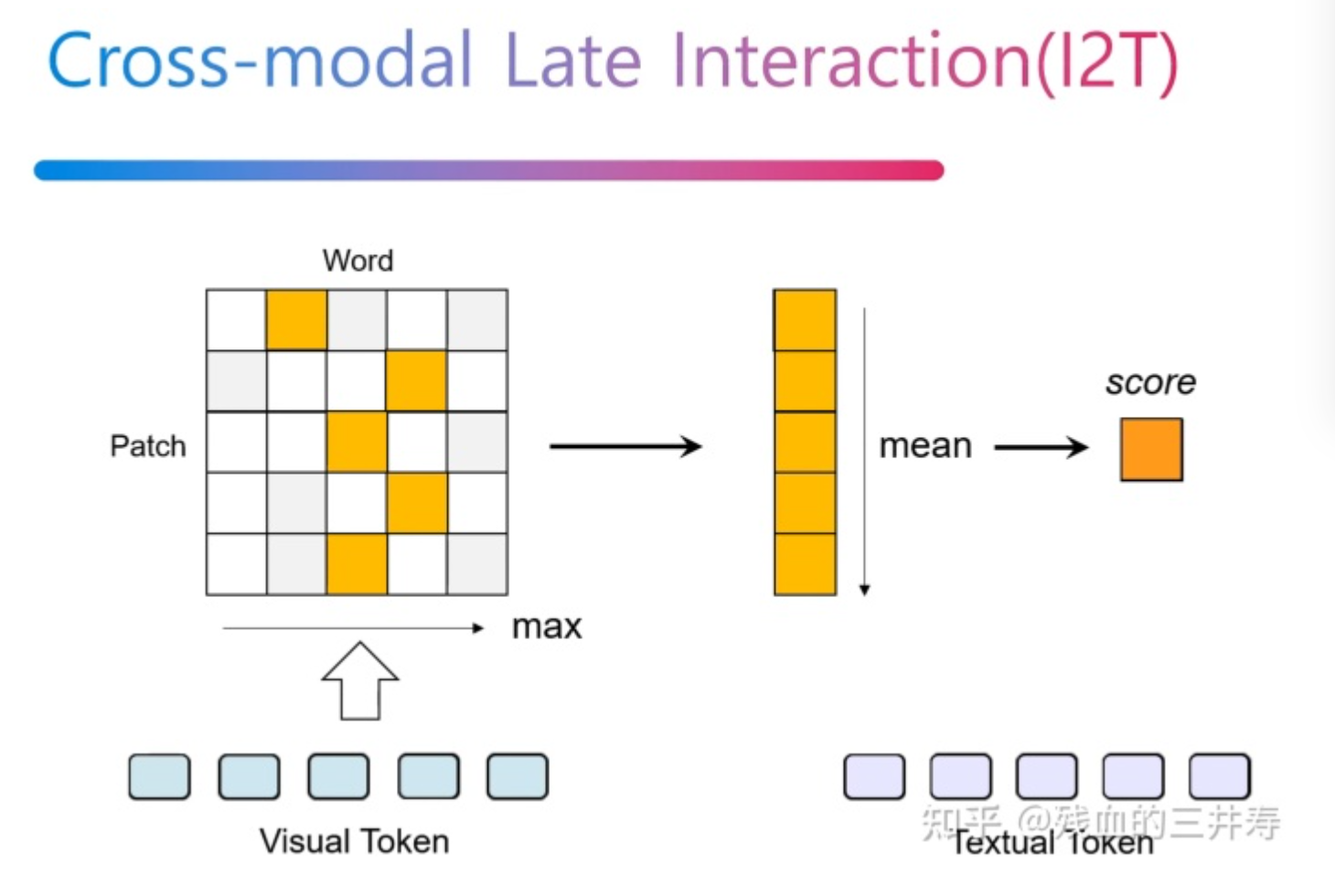
文本到图像的相似度也是通过类似方法进行计算。
为了提高训练效率,作者将embedding size减少到256,同时在最后两层使用半精度计算乘法,最后选择25%最相似的token进行计算。
PROMPT ENSEMBLE AND TEMPLATES
作者通过将token级别的相似度做平均从而集成不同的提示模版:
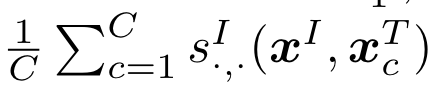
对于提示模版,由如下几部分组成:
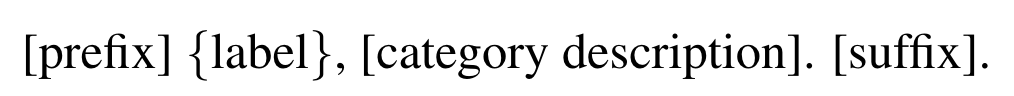
IMAGE AND TEXT AUGMENTATION
为了得到更多的图像文本对,作者对数据进行了增广。方式是将文本翻译到新的语言再翻译回来,每个图像文本对的文本从三种语言的结果(源语言英语、俄语以及德语)随机采样。
PRE-TRAINING DATASET
这一节作者主要在讲提出的数据集FILIP300M。因为代码以及数据集没开源,所以实验结果看看就好~~
标签:PRE,GRAINED,TRAINING,模态,token,作者,相似,图像,文本 From: https://www.cnblogs.com/lipoicyclic/p/17041494.html