目录
Wenet多机多卡分布式训练
PyTorch分布式训练Demo
Wenet框架基于PyTorch实现,因此wenet多机多卡训练依赖于PyTorch分布式训练的实现。
下面代码展示了如何基于PyTorch进行分布式训练:
def ddp_demo(rank, world_size, accum_grad=4):
assert dist.is_gloo_available(), "Gloo is not available!"
print(f"world_size: {world_size}, rank: {rank}, is_gloo_available: {dist.is_gloo_available()}")
# 1. 初始化进程组
dist.init_process_group("gloo", world_size=world_size, rank=rank)
model = nn.Sequential(nn.Linear(10, 100), nn.ReLU(), nn.Linear(100, 20))
# 2. 模型转化成ddp模型
ddp_model = DistributedDataParallel(model)
criterion = nn.MSELoss()
optimizer = optim.SGD(ddp_model.parameters(), lr=1e-3)
dataset = TensorDataset(torch.randn(1000, 10))
# 3. 数据分布式并行(内部会根据rank采样)
sampler = DistributedSampler(dataset=dataset, num_replicas=world_size, shuffle=True)
dataloader = DataLoader(dataset=dataset, batch_size=24, sampler=sampler, collate_fn=transform)
for epoch in range(1):
for step, batch in enumerate(dataloader):
output = ddp_model(batch)
label = torch.rand_like(output)
if step % accum_grad == 0:
# 同步参数
context = contextlib.nullcontext
else:
# 4. 梯度累计,不同步参数
context = ddp_model.no_sync
with context():
time.sleep(random.random())
loss = criterion(output, label)
loss.backward()
if step % accum_grad == 0:
optimizer.step()
optimizer.zero_grad()
print(f"epoch: {epoch}, step: {step}, rank: {rank} update parameters.")
# 5. 销毁进程组上下文数据(一些全局变量)
dist.destroy_process_group()
本地环境没有Nvidia显卡,用
gloo后端替代nccl。
源代码参考:https://gist.github.com/hotbaby/15950bbb43d052cd835b0f18c997f67c
模型转换成分布式训练的步骤:
- 初始化进程组
dist.init_process_group; - 分布式数据并行封装模型
DistributedDataParallel(model); - 数据分布式并行,将数据分成
world_size份,根据rank采样DistributedSampler(dataset=dataset, num_replicas=world_size, shuffle=True); - 训练过程中梯度累计,降低训练进程间的参数同步频率,提升通信效率【可选】;
- 销毁进程组
dist.destroy_process_group()。
Wenet分布式训练实践
Wenet如何配置多机多卡分布式训练?
GPU机器列表:
| 节点名称 | IP地址 | GPU数量 |
|---|---|---|
| node1 | 10.10.23.9 | 8 |
| node2 | 10.10.23.10 | 8 |
以aishell数据集为例,说明Wenet框架中文ASR模型在GPU机器上的训练过程:
-
环境初始化和数据准备
环境初始化参考Wenet官方文档https://github.com/wenet-e2e/wenet#installationtraining-and-developing。
将aishell数据集解压后,分别拷贝node1和node2两台机器的
/data/aishell/目录。 -
配置训练脚本配置
node1训练脚本配置:
wenet/examples/aishell/s0/run.sh
export CUDA_VISIBLE_DEVICES="0,1,2,3,4,5,6,7"
data=/data/aishell/
num_nodes=2
node_rank=0
init_method="tcp://${node1_ip}:23456"
dist_backend="nccl"
node2训练脚本配置:
wenet/examples/aishell/s0/run.sh
export CUDA_VISIBLE_DEVICES="0,1,2,3,4,5,6,7"
num_nodes=2
node_rank=1
init_method="tcp://${node1_ip}:23456"
dist_backend="nccl"
-
运行训练脚本
分别在node1和node2上后台运行
run.sh训练脚本。# export NCCL_SOCKET_IFNAME=ens1f0 nohup bash run.sh > train.log 2>&1 &ens1f0为网卡接口名字,如果没有配置,可能会导致多机网络通信问题。
Wenet分布式训练实验结果
| GPU配置 | 每个Epoch的训练时间(秒) | 速度提升 |
|---|---|---|
| 单机多卡(4) | 407.17 | |
| 单机多卡(8) | 204.36 | 相比单机多卡(4)提升99.24% |
| 多机多卡(8) | 221.75 | 相比单机多卡(8)慢了7.84% |
| 多机多卡(16) | 121.7 | 相比单机多卡(8)提升了67.92% |
详细数据参考https://docs.qq.com/sheet/DSmprVEdyVmh0aHFI?tab=BB08J2
Wenet分布式训练如何实现?
与上述DDP Demo类似,Wenet调用PyTorch相关接口实现分布式训练。
- 初始化进程组
wenet/bin/train.py
def main():
...
if distributed:
logging.info('training on multiple gpus, this gpu {}'.format(args.gpu))
dist.init_process_group(args.dist_backend,
init_method=args.init_method,
world_size=args.world_size,
rank=args.rank)
...
Wenet源代码链接:https://github.com/wenet-e2e/wenet/blob/main/wenet/bin/train.py#L141
- 分布式数据并行封装模型
def main():
...
if distributed:
assert (torch.cuda.is_available())
# cuda model is required for nn.parallel.DistributedDataParallel
model.cuda()
model = torch.nn.parallel.DistributedDataParallel(
model, find_unused_parameters=True)
...
Wenet源代码链接:https://github.com/wenet-e2e/wenet/blob/main/wenet/bin/train.py#L232
- 数据分布式并行
wenet/dataset/dataset.py
class DistributedSampler:
...
def sample(self, data):
""" Sample data according to rank/world_size/num_workers
Args:
data(List): input data list
Returns:
List: data list after sample
"""
data = list(range(len(data)))
# TODO(Binbin Zhang): fix this
# We can not handle uneven data for CV on DDP, so we don't
# sample data by rank, that means every GPU gets the same
# and all the CV data
if self.partition:
if self.shuffle:
random.Random(self.epoch).shuffle(data)
data = data[self.rank::self.world_size]
# num_workers参数与world_size相等,按world_size进行切片。
data = data[self.worker_id::self.num_workers]
return data
...
Wenet源代码链接:https://github.com/wenet-e2e/wenet/blob/main/wenet/dataset/dataset.py#L79
- 梯度累积,降低训练进程参数同步频率
wenet/utils/executor.py
class Executor:
def train(...):
with model_context():
for batch_idx, batch in enumerate(data_loader):
if is_distributed and batch_idx % accum_grad != 0:
# 梯度累计,不同步参数
context = model.no_sync
# Used for single gpu training and DDP gradient synchronization
# processes.
else:
# 同步参数
context = nullcontext
with context():
# autocast context
# The more details about amp can be found in
# https://pytorch.org/docs/stable/notes/amp_examples.html
with torch.cuda.amp.autocast(scaler is not None):
loss_dict = model(feats, feats_lengths, target,
target_lengths)
loss = loss_dict['loss'] / accum_grad
if use_amp:
scaler.scale(loss).backward()
else:
loss.backward()
Wenet源代码链接:https://github.com/wenet-e2e/wenet/blob/main/wenet/utils/executor.py#L67
- 销毁进程组,Wenet源码中没有调用PyTorch的
destroy_process_group()方法,因为训练进程退出后,process_group相关全局变量和上下文会自然销毁,所以不会影响训练过程。
Wenet分布式训练对一些超参的影响?
多机多卡(16卡)相关对于单机多卡(4卡)开发集loss收敛速度变慢?
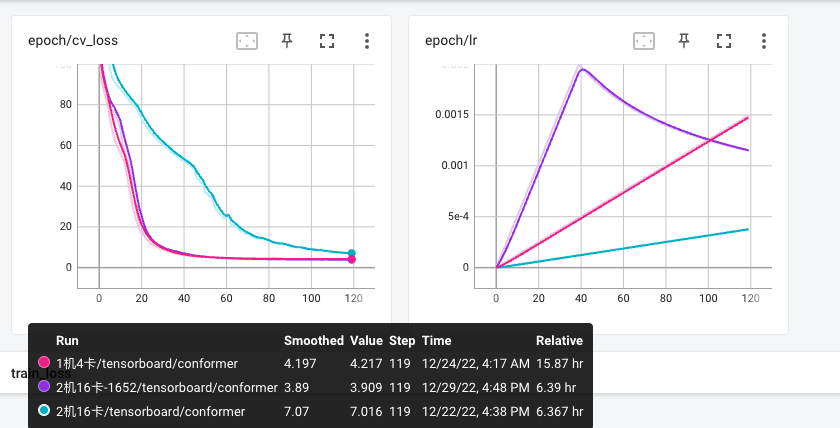
调整wenet/examples/aishell/s0/conf/train_conformer.yaml的warmup_steps参数可以解决此问题。
optim_conf:
lr: 0.002
scheduler: warmuplr # pytorch v1.1.0+ required
scheduler_conf:
warmup_steps: 1562
如何调整梯度累计的间隔?
调整wenet/examples/aishell/s0/conf/train_conformer.yaml的accum_grad参数。