映射详解

Mapping 映射是什么
映射定义索引中有什么字段、字段的类型等结构信息。相当于数据库中表结构定义,或 solr中的schema。因为lucene索引文档时需要知道该如何来索引存储文档的字段。
ES中支持手动定义映射,动态映射两种方式。
1.1. 为索引创建mapping
PUT test
{
<!--映射定义 -->
"mappings" : {
<!--名为type1的映射类别 mapping type-->
"type1" : {
<!-- 字段定义 -->
"properties" : {
<!-- 名为field1的字段,它的field datatype 为 text -->
"field1" : { "type" : "text" }
}
}
}
}
说明:映射定义后续可以修改
映射类别 Mapping type 废除说明
ES最先的设计是用索引类比关系型数据库的数据库,用mapping type 来类比表,一个索引中可以包含多个映射类别。这个类比存在一个严重的问题,就是当多个mapping type中存在同名字段时(特别是同名字段还是不同类型的),在一个索引中不好处理,因为搜索引擎中只有 索引-文档的结构,不同映射类别的数据都是一个一个的文档(只是包含的字段不一样而已)
从6.0.0开始限定仅包含一个映射类别定义( "index.mapping.single_type": true ),兼容5.x中的多映射类别。从7.0开始将移除映射类别。
为了与未来的规划匹配,请现在将这个唯一的映射类别名定义为“_doc”,因为索引的请求地址将规范为:PUT {index}/_doc/{id} and POST {index}/_doc
Mapping 映射示例:
PUT twitter
{
"mappings": {
"_doc": {
"properties": {
"type": { "type": "keyword" },
"name": { "type": "text" },
"user_name": { "type": "keyword" },
"email": { "type": "keyword" },
"content": { "type": "text" },
"tweeted_at": { "type": "date" }
}
}
}
}
多映射类别数据转储到独立的索引中:
ES 提供了reindex API 来做这个事

字段类型
字段类型定义了该如何索引存储字段值。ES中提供了丰富的字段类型定义,请查看官网链接详细了解每种类型的特点:
3.1 Core Datatypes 核心类型
string
text and keyword
Numeric datatypes
long, integer, short, byte, double, float, half_float, scaled_float
Date datatype
date
Boolean datatype
boolean
Binary datatype
binary
Range datatypes 范围
integer_range, float_range, long_range, double_range, date_range
3.2 Complex datatypes 复合类型
Array datatype
数组就是多值,不需要专门的类型
Object datatype
object :表示值为一个JSON 对象
Nested datatype
nested:for arrays of JSON objects(表示值为JSON对象数组 )
3.3 Geo datatypes 地理数据类型
Geo-point datatype
geo_point: for lat/lon points (经纬坐标点)
Geo-Shape datatype
geo_shape: for complex shapes like polygons (形状表示)
3.4 Specialised datatypes 特别的类型
IP datatype
ip: for IPv4 and IPv6 addresses
Completion datatype
completion: to provide auto-complete suggestions
Token count datatype
token_count: to count the number of tokens in a string
mapper-murmur3
murmur3: to compute hashes of values at index-time and store them in the index
Percolator type
Accepts queries from the query-dsl
join datatype
Defines parent/child relation for documents within the same index
字段定义属性介绍
字段的type (Datatype)定义了如何索引存储字段值,还有一些属性可以让根据需要来覆盖默认的值或进行特别定义。请参考官网介绍详细了解:
analyzer 指定分词器
normalizer 指定标准化器
boost 指定权重值
coerce 强制类型转换
copy_to 值复制给另一字段
doc_values 是否存储docValues
dynamic
enabled 字段是否可用
fielddata
eager_global_ordinals
format 指定时间值的格式
ignore_above
ignore_malformed
index_options
index
fields
norms
null_value
position_increment_gap
properties
search_analyzer
similarity
store
term_vector
字段定义属性—示例
PUT my_index
{
"mappings": {
"_doc": {
"properties": {
"date": {
"type": "date",
<!--格式化日期 -->
"format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis"
}
}
}
}
}
Multi Field 多重字段
当需要对一个字段进行多种不同方式的索引时,可以使用fields多重字段定义。如一个字符串字段即需要进行text分词索引,也需要进行keyword 关键字索引来支持排序、聚合;或需要用不同的分词器进行分词索引。
示例:
定义多重字段:
说明:raw是一个多重版本名(自定义)
PUT my_index
{
"mappings": {
"_doc": {
"properties": {
"city": {
"type": "text",
"fields": {
"raw": {
"type": "keyword"
}
}
}
}
}
}
}
往多重字段里面添加文档
PUT my_index/_doc/1
{
"city": "New York"
}
PUT my_index/_doc/2
{
"city": "York"
}
获取多重字段的值:
GET my_index/_search
{
"query": {
"match": {
"city": "york"
}
},
"sort": {
"city.raw": "asc"
},
"aggs": {
"Cities": {
"terms": {
"field": "city.raw"
}
}
}
}
元字段
官网链接:https://www.elastic.co/guide/en/elasticsearch/reference/current/mapping-fields.html
元字段是ES中定义的文档字段,有以下几类:


动态映射
动态映射:ES中提供的重要特性,让可以快速使用ES,而不需要先创建索引、定义映射。 如直接向ES提交文档进行索引:
PUT data/_doc/1
{ "count": 5 }
ES将自动为创建data索引、_doc 映射、类型为 long 的字段 count
索引文档时,当有新字段时, ES将根据字段的json的数据类型为自动加人字段定义到mapping中。
7.1 字段动态映射规则

7.2 Date detection 时间侦测
所谓时间侦测是指往ES里面插入数据的时候会去自动检测的数据是不是日期格式的,是的话就会给自动转为设置的格式
date_detection 默认是开启的,默认的格式dynamic_date_formats为:
[ "strict_date_optional_time","yyyy/MM/dd HH:mm:ss Z||yyyy/MM/dd Z"]
PUT my_index/_doc/1
{
"create_date": "2015/09/02"
}
GET my_index/_mapping
自定义时间格式:
PUT my_index
{
"mappings": {
"_doc": {
"dynamic_date_formats": ["MM/dd/yyyy"]
}
}
}
禁用时间侦测:
PUT my_index
{
"mappings": {
"_doc": {
"date_detection": false
}
}
}
7.3 Numeric detection 数值侦测
开启数值侦测(默认是禁用的)
PUT my_index
{
"mappings": {
"_doc": {
"numeric_detection": true
}
}
}
PUT my_index/_doc/1
{
"my_float": "1.0",
"my_integer": "1"
}
索引别名

别名的用途
如果希望一次查询可查询多个索引。
如果希望通过索引的视图来操作索引,就像数据库库中的视图一样。
索引的别名机制,就是让可以以视图的方式来操作集群中的索引,这个视图可是多个索引,也可是一个索引或索引的一部分。
新建索引时定义别名
PUT /logs_20162801
{
"mappings" : {
"type" : {
"properties" : {
"year" : {"type" : "integer"}
}
}
},
<!-- 定义了两个别名 -->
"aliases" : {
"current_day" : {},
"2016" : {
"filter" : {
"term" : {"year" : 2016 }
}
}
}
}
别名操作
创建别名 /_aliases
为索引test1创建别名alias1
POST /_aliases
{
"actions": [
{
"add": {
"index": "test1",
"alias": "alias1"
}
}
]
}
删除别名
POST /_aliases
{
"actions": [
{
"remove": {
"index": "test1",
"alias": "alias1"
}
}
]
}
还可以这样写
DELETE /{index}/_alias/{别名}
批量操作别名
进行别名替换
删除索引test1的别名alias1,同时为索引test2添加别名alias1
POST /_aliases
{
"actions": [
{
"remove": {
"index": "test1",
"alias": "alias1"
}
},
{
"add": {
"index": "test2",
"alias": "alias1"
}
}
]
}
为多个索引定义一样的别名
方式1
POST /_aliases
{
"actions": [
{
"add": {
"index": "test1",
"alias": "alias1"
}
},
{
"add": {
"index": "test2",
"alias": "alias1"
}
}
]
}
方式2:
POST /_aliases
{
"actions": [
{
"add": {
"indices": [
"test1",
"test2"
],
"alias": "alias1"
}
}
]
}
注意:只可通过多索引别名进行搜索,不可进行文档索引和根据id获取文档。
当一个别名对应了多个索引的时候,系统会返回其关联的多个索引的信息。
方式3:通过统配符*模式来指定要别名的索引
POST /_aliases
{
"actions": [
{
"add": {
"index": "test*",
"alias": "all_test_indices"
}
}
]
}
注意:在这种情况下,别名是一个点时间别名,它将对所有匹配的当前索引进行别名,当添加/删除与此模式匹配的新索引时,它不会自动更新。
创建字段别名
索引可以拥有别名,字段也可以,在创建索引时,可以为字段设置一个别名。例如,为username字段设置一个别名name。

带过滤器的别名
索引中需要有字段
为一个索引中的部分数据创建别名,例如,一个索引中存放了一整年的数据,现在新增一个业务场景,更多的是对其中某一个月的数据进行检索,这时,可以在创建别名时,通过设置过滤条件filter,可以单独令别名指向一个月的数据,使得检索更加高效。
PUT /test1
{
"mappings": {
"type1": {
"properties": {
"user" : {
"type": "keyword"
}
}
}
}
}
过滤器通过Query DSL来定义,将作用于通过该别名来进行的所有Search, Count, Delete By Query and More Like This 操作。
POST /_aliases
{
"actions" : [
{
"add" : {
"index" : "test1",
"alias" : "alias2",
"filter" : { "term" : { "user" : "kimchy" } }
}
}
]
}
带routing的别名
可在别名定义中指定路由值,可和filter一起使用,用来限定操作的分片,避免不需要的其他分片操作。
POST /_aliases
{
"actions" : [
{
"add" : {
"index" : "test",
"alias" : "alias1",
"routing" : "1"
}
}
]
}
为搜索、索引指定不同的路由值
POST /_aliases
{
"actions" : [
{
"add" : {
"index" : "test",
"alias" : "alias2",
"search_routing" : "1,2",
"index_routing" : "2"
}
}
]
}
以PUT方式来定义一个别名
PUT /{index}/_alias/{name}
PUT /logs_201305/_alias/2013
带filter 和 routing
PUT /users
{
"mappings" : {
"user" : {
"properties" : {
"user_id" : {"type" : "integer"}
}
}
}
}
PUT /users/_alias/user_12
{
"routing" : "12",
"filter" : {
"term" : {
"user_id" : 12
}
}
}
查看别名定义信息
GET /{index}/_alias/{alias}
GET /logs_20162801/_alias/*
GET /_alias/2016
GET /_alias/20*
# 查看别名信息
GET /_cat/aliases/<alias>
GET /_cat/aliases
索引生命周期
在生产环境中,索引的动态模板设置、索引Mapping设置、索引分片数/副本数设置、索引创建、打开、关闭、删除的全生命周期的管理必须高度关注,做好提前知识储备,否则,会在开发后期出现由于数据激增暴露架构设计不合理问题,甚至引发分片/节点数据丢失、集群宕机等严重问题。
索引生命周期管理的重要性?
索引管理决定Elasticsearch鲁棒性、高可用性。
索引管理和搜索、插入性能也密切相关。
实际场景例子:100节点的集群中某一个节点数据丢失后,GET /_cat/nodes?v 接口的返回时延时延非常大,接近5-8s。搜索、聚合的性能更不必说。
原因:节点丢失后,ES会自动复制分片到新的节点中去,但是该丢失节点的shard非常大(几百个GB甚至上TB),集群当时的写入压力也非常大。这么大量级的数据拷贝和实时写入,最终导致延时会非常大。
高可用的索引管理初探
索引生命周期管理的核心就是定义索引的早期阶段,前面考虑充分了,后面的架构才会高效、稳定。
实际Elasticsearch5.X之后的版本已经推出:新增了一个Rollover API。Rollover API解决的是以日期作为索引名称的索引大小不均衡的问题。
medcl介绍如下:Rollover API对于日志类的数据非常有用,一般按天来对索引进行分割(数据量更大还能进一步拆分),没有Rollover之前,需要在程序里设置一个自动生成索引的模板,相比于模板,Rollover API是更为简洁的方式。
ILM
ILM:索引生命周期管理,即Manage the index lifecycle。使用ILM应确保集群中的所有节点运行的是同一个版本,不然无法保证他们会按预期工作。
ES从6.7版本推出了索引生命周期管理(Index Lifecycle Management ,简称ILM)机制,能帮自动管理一个索引策略(Policy)下索引集群的生命周期。索引策略将一个索引的生命周期定义为四个阶段:
- Hot:索引可写入,也可查询。
- Warm:索引不可写入,但可查询。
- Cold:索引不可写入,但很少被查询,查询的慢点也可接受。
- Delete:索引可被安全的删除。
rollover
当索引满足一定条件之后,将不再写入数据,而是自动创建一个新的索引,所有的数据将写入新索引。
使用滚动索引能够:
- 优化活跃索引,在高性能
hot节点上提升高接收速率。 - 优化
warm节点搜索性能。 - 将旧的、访问频率低的数据转移到成本低的
cold节点上。 - 通过删除整个索引,根据索引保留策略删除数据。
官方推荐使用data stream数据流来管理时间序列数据。每个数据流都需要一个索引模板,其中包括:
- 数据流的名称或通配符(*)模式。
- 数据流时间戳字段。该字段必须映射为
date或date_nanos数据类型。并且包含在索引到该数据流的每个文档中。 - 当创建每一个索引时将应用索引模板的映射和设置。
数据流专为追加数据而设计,其中数据流名称可用作操作(读取、写入、翻转、收缩等)目标。如果需要更新数据,可以使用索引别名来管理时间序列数据。
自动 rollover
ILM会根据你的配置:索引大小、文档数量、所在阶段 ,当满足这些条件时,自动实现rollover。
RollOver的适用场景
生命周期策略控制索引如何通过这些阶段以及在每个阶段对索引执行的操作。该策略可以指定:
- 您希望滚动到新索引的最大大小或年龄。
- 索引不再更新并且可以减少主分片数量的点。
- 何时强制合并以永久删除标记为删除的文档。
- 可以将索引移动到性能较低的硬件的点。
- 可用性不那么关键并且可以减少副本数量的点。
- 何时可以安全删除索引。
例如,如果您要将 ATM 机群中的指标数据索引到 Elasticsearch 中,您可以定义一个策略:
- 当索引达到 50GB 时,翻转到新索引。
- 将旧索引移动到暖阶段,将其标记为只读,然后将其缩小为单个分片。
- 7 天后,将索引移至冷阶段并将其移至较便宜的硬件。
- 达到所需的 30 天保留期后,删除索引。
索引生命周期管理
索引生命周期策略更新
- 生命周期策略被应用到索引上时,索引会获取当前策略的最新版本号。如果更新了当前策略,版本号会发生冲突,
ILM就能检测出当前索引正在使用上一个版本的策略,需要将索引策略更新到最新版本。 - 如果将不同的策略应用到已经被管理的索引上时,索引还是使用先前管理策略中的缓存定义来完成当前阶段。直到进入下一个阶段,索引才会应用新的管理策略。
索引生命周期操作
allocate:将分片移动到具有不同性能特征的节点上,并减少副本的数量。delete:永久移除索引。force merge:减少索引段的数量并清除已删除的文档。使索引为只读。freeze:冻结索引以最大程度减少其内存的占用量。read only:阻止对索引的写操作。rollover:删除索引作为过渡别名的写索引,然后开始索引到新索引。set priority:降低索引在生命周期中的优先级,以确保首先恢复热索引。shrink:通过将索引缩小为新索引来减少主分片的数量。unfollow:将关注者索引转换为常规索引。在进行滚动或收缩操作之前自动执行。wait for snapshot:删除索引之前,确保快照存在。
配置生命周期策略
要让ILM管理索引,必须要在index.lifecycle.name索引设置中指定有效的策略。
要为滚动索引创建生命周期策略,你要创建该策略并把它加入到索引模板中。
创建生命周期策略
可以通过Kibana管理页面设置,也可以通过API设置。
PUT _ilm/policy/my_policy
{
"policy": {
"phases": {
"hot": {
"actions": {
"rollover": {
"max_size": "25GB"
}
}
},
{
"delete": {
"min_age": "30d",
"actions": {
"delete": {}
}
}
}
}
}
}
将生命周期策略应用到索引模板中
可以通过Kibana管理页面设置,也可以通过API设置。
PUT _index_template/my_template
{
"index_patterns": ["test-*"],
"template": {
"settings": {
"number_of_shards": 1,
"number_of_replicas": 1,
"index.lifecycle.name": "my_policy",
"index.lifecycle.rollover_alias": "test-alias"
}
}
}
创建一个初始被管理的索引
如果要给滚动索引设置策略,需要手动创建第一个被该策略管理的索引,并指定为可写索引。
索引的名称必须跟索引模板里定义的模式相匹配,并且以数字结尾。
PUT test-000001
{
"aliases": {
"test-alias": {
"is_write_index": true
}
}
}
手动应用生命周期策略
你可以在创建索引的时候指定一个策略,也可以直接将策略应用到一个已经存在的索引上通过Kibana管理或者更新设置的API。一旦你应用了策略,ILM立即会开始管理该索引。
PUT test-index
{
"settings": {
"number_of_shards": 1,
"number_of_replicas": 1,
"index.lifecycle.name": "my_police"
}
}
将策略应用于多个索引
PUT mylogs-pre-ilm*/_settings
{
"index": {
"lifecycle": {
"name": "mylogs_policy_existing"
}
}
}
解决生命周期策略运行报错
查看错误:
GET /my-index-000001/_ilm/explain
重新运行报错的一步:
POST /my-index-000001/_ilm/retry
开启和终止索引生命周期管理
查看ILM状态:
GET _ilm/status
# 返回结果
{
"operation_mode": "RUNNING"
}
终止ILM:
POST _ilm/stop
# 返回结果
{
"operation_mode": "STOPPING"
}
{
"operation_mode": "STOPPED"
}
开启ILM:
POST _ilm/start
跳过rollover
设置index.lifecycle.indexing_complete为true。
举个例子,如果你要改变一系列新索引的名称,并保留之前根据你配置的策略产生的索引数据,你可以:
- 为新的索引模式创建一个模板,并使用之前相同的策略。
- 根据新的模板创建一个初始索引。
- 使用索引别名API将别名的
write索引更改为bootstrapped索引。 - 设置旧索引的
index.lifecycle.indexing_complete的值为true。
Rollover的不足和改进
Rollover API大大简化了基于时间的索引的管理。但是,仍然需要以一种重复的方式调用_rollover API接口,可以手动调用,也可以通过基于crontab的工具(如director)调用。
但是,如果翻转过程是隐式的并在内部进行管理,则会简单得多。其思想是在创建索引时(或在索引模板中相等地)在别名中指定滚动条件。
PUT /<logs-{now/d}-1>
{
"mappings": {...},
"aliases" : {
"logs-search" : {},
"logs-write" : {
"rollover" : {
"conditions": {
"max_age": "1d",
"max_docs": 100000
}
}
}
}
}
github提出的改进建议如下:https://github.com/elastic/elasticsearch/issues/26092
索引生命周期管理案例
对于日志型数据经常面临的一个场景是保存N天,大于该时间后自动删除,以下为示例:
创建ILM
PUT _ilm/policy/my_ilm
{
"policy": {
"phases": {
"hot": {
"min_age": "0ms",
"actions": {
"set_priority": {
"priority": 100
}
}
},
"delete": {
"min_age": "3d",
"actions": {
"delete": {}
}
}
}
}
}
以上ilm将关联的索引模板中的索引保存3天,到期自动删除
创建索引模板
PUT _template/my_template
{
"index_patterns": [
"jpaas-back*",
"jpaas-front*"
],
"settings": {
"index": {
"lifecycle": {
"name": "my_ilm"
},
"number_of_shards": "2"
}
},
"mappings": {},
"aliases": {}
}
模板自动匹配jpaas-back和jpaas-front开头的索引,并关联ilm
也可以在kibana上配置,填写具体的 Policy name 以及其他配置并保存。这里是自动删除 7 天前创建的 index。
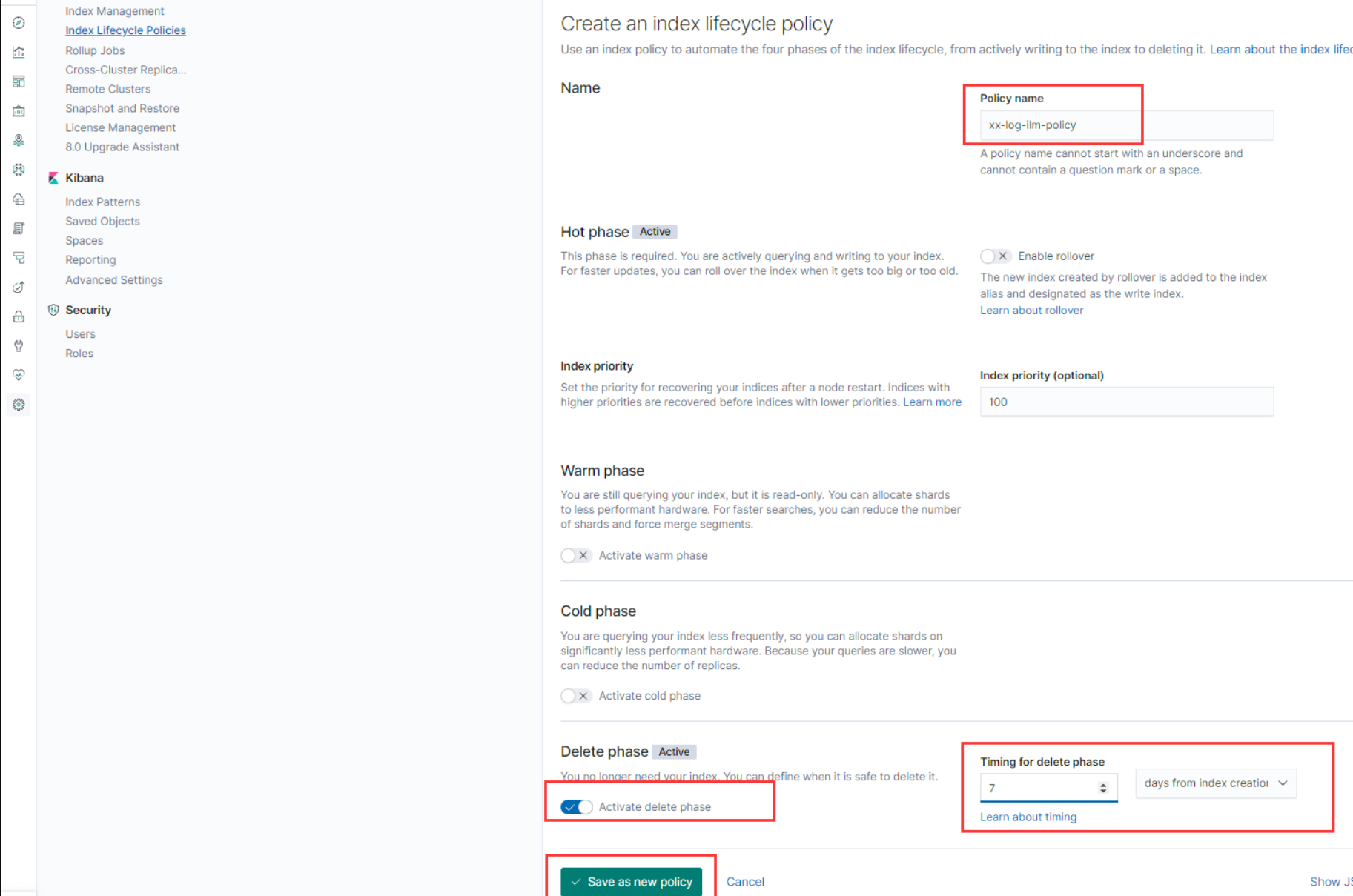
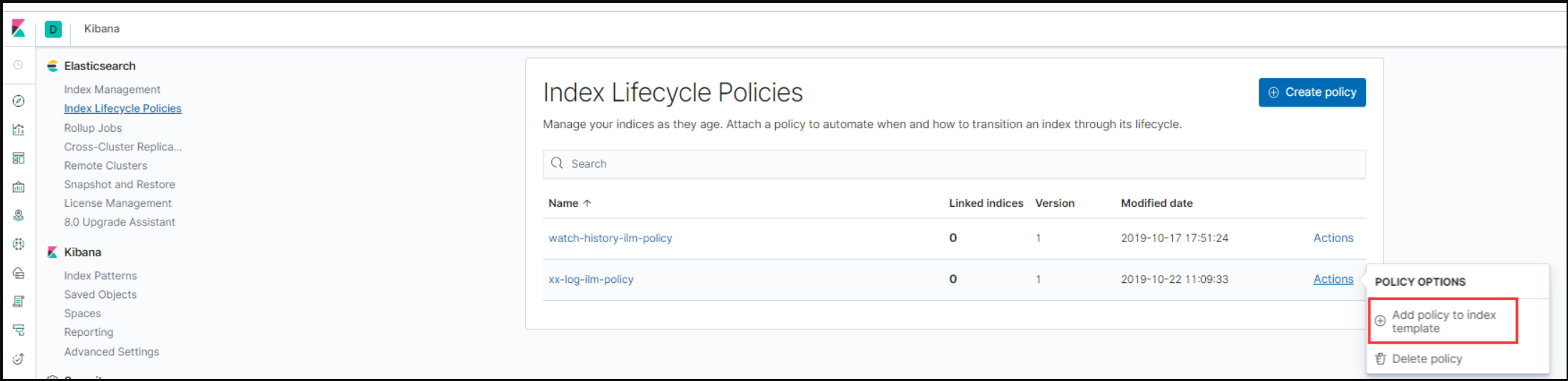
然后把 Index Lifecycle Policy 和 template 关联
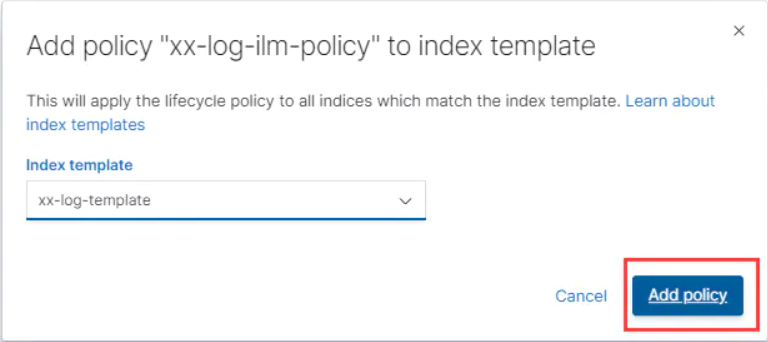
至此新创建的 xx-log* index 会在七天后自动删除
分片(sharding)
一个索引可以存储超出单个结点硬件限制的大量数据。比如,一个具有10亿文档的索引占据1TB的磁盘空间,而任一节点都没有这样大的磁盘空间;或者单个节点处理搜索请求,响应太慢。
为了解决这个问题,ES提供了将索引划分成多份的能力,这些份就叫做 分片。当你创建一个索引的时候,可以指定你想要的分片的数量。每个分片本身也是一个功能完善并且独立的“索引”,这个“索引”可以被放置到集群中的任何节点上。
分片分为主分片 (primary shard) 以及从分片 (replica shard)。主分片会被尽可能平均地 (rebalance) 分配在不同的节点上(例如你有 2 个节点,4 个主分片(不考虑备份),那么每个节点会分到 2 个分片,后来你增加了 2 个节点,那么你这 4 个节点上都会有 1 个分片,这个过程叫 relocation,ES 感知后自动完成)。
从分片只是主分片的一个副本,它用于提供数据的冗余副本,从分片和主分片不会出现在同一个节点上(防止单点故障),默认情况下一个索引创建 5 个主分片(从 7.0.0 开始,默认值是每个索引一个分片。),每个主分片会有一个从分片 (5 primary + 5 replica = 10 个分片)。如果你只有一个节点,那么 5 个 replica 都无法被分配 (unassigned),此时 cluster status 会变成 Yellow。
分片是独立的,对于一个 Search Request 的行为,每个分片都会执行这个 Request。每个分片都是一个 Lucene Index,所以一个分片只能存放 Integer.MAX_VALUE - 128 = 2,147,483,519 个 docs。
分片之所以重要,主要有两方面的原因:
-
允许你水平分割/扩展你的内容容量
允许你在分片(潜在地,位于多个节点上)之上进行分布式的、并行的操作,进而提高性能/吞吐量。至于一个分片怎样分布,它的文档怎样聚合回搜索请求,是完全由ES管理的,对于作为用户的你来说,这些都是透明的。
-
在一个网络/云的环境里,失败随时都可能发生,在某个分片/节点不知怎么的就处于离线状态,或者由于任何原因消失了。这种情况下,有一个故障转移机制是非常有用并且是强烈推荐的。为此目的,ES允许你创建分片的一份或多份拷贝,这些拷贝叫做复制分片,或者直接叫复制。
为了提升访问压力过大是单机无法处理所有请求的问题,Elasticsearch集群引入了副本策略replica。副本策略对index中的每个分片创建冗余的副本,处理查询时可以把这些副本当做主分片来对待(primary shard),此外副本策略提供了高可用和数据安全的保障,当分片所在的机器宕机,Elasticsearch可以使用其副本进行恢复,从而避免数据丢失。
总之,每个索引可以被分成多个分片。一个索引也可以被复制0次(意思是没有复制)或多次。一旦复制了,每个索引就有了主分片(作为复制源的原来的分片)和复制分片(主分片的拷贝)之别。分片和复制的数量可以在索引创建的时候指定。在索引创建之后,你可以在任何时候动态地改变复制数量,但是不能改变分片的数量。
默认情况下,ES中的每个索引被分片5个主分片和1个复制,这意味着,如果你的集群中至少有两个节点,你的索引将会有5个主分片和另外5个复制分片(1个完全拷贝),这样的话每个索引总共就有10个分片。一个索引的多个分片可以存放在集群中的一台主机上,也可以存放在多台主机上,这取决于你的集群机器数量。主分片和复制分片的具体位置是由ES内在的策略所决定的
ES内部分片处理机制
逆向索引
与传统的数据库不同,在Elasticsearch中,每个字段里面的每个单词都是可以被搜索的。如teacher:“zls,bgx,lidao,oldboy,alex”在搜索关键字oldboy时,所有包含oldboy的文档都会被匹配到Elasticsearch的这个特性也叫做全文搜索。
为了支持这个特性,Elasticsearch中会维护一个叫做“invertedindex”(也叫逆向索引)的表,表内包含了所有文档中出现的所有单词,同时记录了这个单词在哪个文档中出现过。
例:当前有4个文档
txt1:“zls,bgx,lidao”
txt2:“zls,oldboy,alex”
txt3:“bgx,lidao,oldboy”
txt4:“oldboy,alex“
那么Elasticsearch会维护下面一个数据结构表:
| Term | txt1 | txt2 | txt3 | txt4 |
|---|---|---|---|---|
| zls | Y | Y | ||
| bgx | Y | Y | ||
| lidao | Y | Y | ||
| oldboy | Y | Y | Y | |
| alex | Y | Y |
随意搜索任意一个单词,Elasticsearch只要遍历一下这个表,就可以知道有些文档被匹配到了。
逆向索引里面不止记录了单词与文档的对应关系,它还维护了很多其他有用的数据。如:每个文档一共包含了多少个单词,单词在不同文档中的出现频率,每个文档的长度,所有文档的总长度等等。这些数据用来给搜索结果进行打分,如搜索zls时,那么出现zls这个单词次数最多的文档会被优先返回,因为它匹配的次数最多,和的搜索条件关联性最大,因此得分也最多。
逆向索引是不可更改的,一旦它被建立了,里面的数据就不会再进行更改。这样做就带来了以下几个好处:
- 没有必要给逆向索引加锁,因为不允许被更改,只有读操作,所以就不用考虑多线程导致互斥等问题。
- 索引一旦被加载到了缓存中,大部分访问操作都是对内存的读操作,省去了访问磁盘带来的io开销。
- 因为逆向索引的不可变性,所有基于该索引而产生的缓存也不需要更改,因为没有数据变更。
- 使用逆向索引可以压缩数据,减少磁盘io及对内存的消耗。
分片的存储
写索引过程
ES 集群中每个节点通过路由都知道集群中的文档的存放位置,所以每个节点都有处理读写请求的能力。
在一个写请求被发送到某个节点后,该节点即为协调节点,协调节点会根据路由公式计算出需要写到哪个分片上,再将请求转发到该分片的主分片节点上。假设 shard = hash(routing) % 4 = 0 ,则过程大致如下:
- 客户端向 ES1节点(协调节点)发送写请求,通过路由计算公式得到值为0,则当前数据应被写到主分片 S0 上。
- ES1 节点将请求转发到 S0 主分片所在的节点 ES3,ES3 接受请求并写入到磁盘。
- 并发将数据复制到两个副本分片 R0 上,其中通过乐观并发控制数据的冲突。一旦所有的副本分片都报告成功,则节点 ES3 将向协调节点报告成功,协调节点向客户端报告成功。
存储原理
索引的不可变性
写入磁盘的倒排索引是不可变的,优势主要表现在:
- 不需要锁。因为如果从来不需要更新一个索引,就不必担心多个程序同时尝试修改,也就不需要锁。
- 一旦索引被读入内核的文件系统缓存,便会留在哪里,由于其不变性,只要文件系统缓存中还有足够的空间,那么大部分读请求会直接请求内存,而不会命中磁盘。这提供了很大的性能提升。
- 其它缓存(像filter缓存),在索引的生命周期内始终有效。它们不需要在每次数据改变时被重建,因为数据不会变化。
- 写入单个大的倒排索引,可以压缩数据,较少磁盘 IO 和需要缓存索引的内存大小。
当然,不可变的索引有它的缺点:
- 当对旧数据进行删除时,旧数据不会马上被删除,而是在
.del文件中被标记为删除。而旧数据只能等到段更新时才能被移除,这样会造成大量的空间浪费。 - 若有一条数据频繁的更新,每次更新都是新增新的标记旧的,则会有大量的空间浪费。
- 每次新增数据时都需要新增一个段来存储数据。当段的数量太多时,对服务器的资源例如文件句柄的消耗会非常大。
- 在查询的结果中包含所有的结果集,需要排除被标记删除的旧数据,这增加了查询的负担。
段(Segment)的引入
ES 的整体存储架构图

在全文检索的早些时候,会为整个文档集合建立一个大索引,并且写入磁盘。只有新的索引准备好了,它就会替代旧的索引,最近的修改才可以被检索。这无疑是低效的。
因为索引的不可变性带来的好处,那如何在保持不可变同时更新倒排索引?
答案是,使用多个索引。不是重写整个倒排索引,而是增加额外的索引反映最近的变化。每个倒排索引都可以按顺序查询,从最老的开始,最后把结果聚合。
这就引入了段 (segment):
- 新的文档首先写入内存区的索引缓存,这时不可检索。
- 时不时(默认 1s 一次),内存区的索引缓存被 refresh 到 Filesystem cache(同时清空内存区的索引缓存),成为一个新的段(segment)并被打开,这时可以被检索。
- 新的段提交,写入磁盘,提交后,新的段加入提交点,缓存被清除,等待接收新的文档。
分片下的索引文件被拆分为多个子文件,每个子文件叫作段, 每一个段本身都是一个倒排索引,并且段具有不变性,一旦索引的数据被写入硬盘,就不可再修改。
段被写入到磁盘后会生成一个提交点,提交点是一个用来记录所有提交后段信息的文件。一个段一旦拥有了提交点,就说明这个段只有读的权限,失去了写的权限。相反,当段在内存中时,就只有写的权限,而不具备读数据的权限,意味着不能被检索。
ElasticSearch 每次 refresh 一次都会生成一个新的 segment 文件,这样下来 segment 文件会越来越多。那这样会导致什么问题呢?因为每一个 segment 都会占用文件句柄、内存、cpu资源,更加重要的是,每个搜索请求都必须访问每一个segment,这就意味着存在的 segment 越多,搜索请求就会变的更慢。
每个 segment 是一个包含正排(空间占比90~95%)+ 倒排(空间占比5~10%)的完整索引文件,每次搜索请求会将所有 segment 中的倒排索引部分加载到内存,进行查询和打分,然后将命中的文档号拿到正排中召回完整数据记录。如果不对segment做配置,就会导致查询性能下降
那么 ElasticSearch 是如何解决这个问题呢?
ElasticSearch 有一个后台进程专门负责 segment 的合并,定期执行 merge 操作,将多个小 segment 文件合并成一个 segment,在合并时被标识为 deleted 的 doc(或被更新文档的旧版本)不会被写入到新的 segment 中。
合并完成后,然后将新的 segment 文件 flush 写入磁盘;然后创建一个新的 commit point 文件,标识所有新的 segment 文件,并排除掉旧的 segement 和已经被合并的小 segment;然后打开新 segment 文件用于搜索使用,等所有的检索请求都从小的 segment 转到 大 segment 上以后,删除旧的 segment 文件,这时候,索引里 segment 数量就下降了。如下图:

所有的过程都不需要干涉,es会自动在索引和搜索的过程中完成,合并的segment可以是磁盘上已经commit过的索引,也可以在内存中还未commit的segment:合并的过程中,不会打断当前的索引和搜索功能。
segment的merge对性能的影响
segment 合并的过程,需要先读取小的 segment,归并计算,再写一遍 segment,最后还要保证刷到磁盘。可以说,合并大的 segment 需要消耗大量的 I/O 和 CPU 资源,同时也会对搜索性能造成影响。所以 Elasticsearch 在默认情况下会对合并线程进行资源限制,确保它不会对搜索性能造成太大影响。
默认情况下,归并线程的限速配置 indices.store.throttle.max_bytes_per_sec 是 20MB。对于写入量较大,磁盘转速较高,甚至使用 SSD 盘的服务器来说,这个限速是明显过低的。对于 ELK Stack 应用,建议可以适当调大到 100MB或者更高。设置方式如下:
或者不限制:
PUT /_cluster/settings
{
"transient" : {
"indices.store.throttle.type" : "none"
}
}
手动强制合并 segment
ES 的 API 也提供了命令来支持强制合并 segment,即 optimize 命令,它可以强制一个分片 shard 合并成 max_num_segments 参数指定的段数量,一个索引它的segment数量越少,它的搜索性能就越高,通常会optimize 成一个 segment。
但需要注意的是,optimize 命令是没有限制资源的,也就是你系统有多少IO资源就会使用多少IO资源,这样可能导致一段时间内搜索没有任何响应,所以,optimize命令不要用在一个频繁更新的索引上面,针对频繁更新的索引es默认的合并进程就是最优的策略。如果你计划要 optimize 一个超大的索引,你应该使用 shard allocation(分片分配)功能将这份索引给移动到一个指定的 node 机器上,以确保合并操作不会影响其他的业务或者es本身的性能。
但是在特定场景下,optimize 也颇有益处,比如在一个静态索引上(即索引没有写入操作只有查询操作)是非常适合用optimize来优化的。比如日志的场景下,日志基本都是按天,周,或者月来索引的,旧索引实质上是只读的,只要过了今天、这周或这个月就基本没有写入操作了,这个时候就可以通过 optimize 命令,来强制合并每个shard上索引只有一个segment,这样既可以节省资源,也可以大大提升查询性能。
optimize 的 API 如下:
POST /logstash-2014-10/_optimize?max_num_segments=1
segment 性能相关设置
1、查看某个索引中所有 segment 的驻留内存情况:
curl -XGET 'http://ip:port/_cat/segments/index_name1?v&h=shard,segment,size,size.memory'
查看merge情况
GET /_cat/indices/?s=segmentsCount:desc&v&h=index,segmentsCount,segmentsMemory,memoryTotal,mergesCurrent,mergesCurrentDocs,storeSize,p,r
2、性能优化:
(1)合并策略:
合并线程是按照一定的运行策略来挑选 segment 进行归并的。主要有以下几条:
index.merge.policy.floor_segment:默认 2MB,小于该值的 segment 会优先被归并。index.merge.policy.max_merge_at_once:默认一次最多归并 10 个 segmentindex.merge.policy.max_merge_at_once_explicit:默认 forcemerge 时一次最多归并 30 个 segmentindex.merge.policy.max_merged_segment:默认 5 GB,大于该值的 segment,不用参与归并,forcemerge 除外
(2)设置延迟提交:
根据上面的策略,也可以从另一个角度考虑如何减少 segment 归并的消耗以及提高响应的办法:加大 refresh 间隔,尽量让每次新生成的 segment 本身大小就比较大。这种方式主要通过延迟提交实现,延迟提交意味着数据从提交到搜索可见有延迟,具体需要结合业务配置,默认值1s;
针对索引节点粒度的配置如下:
curl -XPUT http://ip:port/索引节点名称/_settings -d '{"index.refresh_interval":"10s"}'
(3)对特定字段field禁用 norms 和 doc_values 和 stored:
norms、doc_values 和 stored 字段的存储机制类似,每个 field 有一个全量的存储,对存储浪费很大。如果一个 field 不需要考虑其相关度分数,那么可以禁用 norms,减少倒排索引内存占用量,字段粒度配置 omit_norms=true;如果不需要对 field 进行排序或者聚合,那么可以禁用 doc_values 字段;如果 field 只需要提供搜索,不需要返回则将 stored 设为 false;
近实时搜索--fresh
ES 是怎么做到近实时全文搜索?
磁盘是瓶颈。提交一个新的段到磁盘需要fsync操作,确保段被物理地写入磁盘,即时电源失效也不会丢失数据。但是fsync是昂贵的,严重影响性能,当写数据量大的时候会造成 ES 停顿卡死,查询也无法做到快速响应。
所以fsync不能在每个文档被索引的时就触发,需要一种更轻量级的方式使新的文档可以被搜索,这意味移除fsync。
为了提升写的性能,ES 没有每新增一条数据就增加一个段到磁盘上,而是采用延迟写的策略。
每当有新增的数据时,就将其先写入到内存中,在内存和磁盘之间是文件系统缓存,当达到默认的时间(1秒钟)或者内存的数据达到一定量时,会触发一次刷新(Refresh),将内存中的数据生成到一个新的段上并缓存到文件缓存系统 上,稍后再被刷新到磁盘中并生成提交点。
这里的内存使用的是ES的JVM内存,而文件缓存系统使用的是操作系统的内存。新的数据会继续的被写入内存,但内存中的数据并不是以段的形式存储的,因此不能提供检索功能。由内存刷新到文件缓存系统的时候会生成了新的段,并将段打开以供搜索使用,而不需要等到被刷新到磁盘。
在 Elasticsearch 中,这种写入和打开一个新段的轻量的过程叫做 refresh (即内存刷新到文件缓存系统)。默认情况下每个分片会每秒自动刷新一次。 这就是为什么说 Elasticsearch 是近实时的搜索了:文档的改动不会立即被搜索,但是会在一秒内可见。
也可以手动触发 refresh。 POST /_refresh 刷新所有索引, POST /index/_refresh刷新指定的索引:
PUT /my_logs
{
"settings": {
"refresh_interval": "30s"
}
}
Tips:尽管刷新是比提交轻量很多的操作,它还是会有性能开销。当写测试的时候,手动刷新很有用,但是不要在生产环境下每次索引一个文档都去手动刷新。而且并不是所有的情况都需要每秒刷新。在使用 Elasticsearch 索引大量的日志文件,可能想优化索引速度而不是近实时搜索,这时可以在创建索引时在
settings中通过调大refresh_interval="30s"的值 , 降低每个索引的刷新频率,设值时需要注意后面带上时间单位,否则默认是毫秒。当refresh_interval=-1时表示关闭索引的自动刷新。
持久化
没用fsync同步文件系统缓存到磁盘,不能确保电源失效,甚至正常退出应用后,数据的安全。为了 ES 的可靠性,需要确保变更持久化到磁盘。
虽然通过定时 Refresh 获得近实时的搜索,但是 Refresh 只是将数据挪到文件缓存系统,文件缓存系统也是内存空间,属于操作系统的内存,只要是内存都存在断电或异常情况下丢失数据的危险。
为了避免丢失数据,Elasticsearch添加了事务日志(Translog),事务日志记录了所有还没有持久化到磁盘的数据。
有了事务日志,过程现在如下:
当一个文档被索引,它被加入到内存缓存,同时加到事务日志。不断有新的文档被写入到内存,同时也都会记录到事务日志中。这时新数据还不能被检索和查询。
当达到默认的刷新时间或内存中的数据达到一定量后,会触发一次 refresh:
- 将内存中的数据以一个新段形式刷新到文件缓存系统,但没有fsync;
- 段被打开,使得新的文档可以搜索;
- 缓存被清除。
随着更多的文档加入到缓存区,写入日志,这个过程会继续。
随着新文档索引不断被写入,当日志数据大小超过 512M 或者时间超过 30 分钟时,会进行一次全提交:
- 内存缓存区的所有文档会写入到新段中,同时清除缓存;
- 文件系统缓存通过
fsync操作flush到硬盘,生成提交点; - 事务日志文件被删除,创建一个空的新日志。
事务日志记录了没有flush到硬盘的所有操作。当故障重启后,ES 会用最近一次提交点从硬盘恢复所有已知的段,并且从日志里恢复所有的操作。
在 ES 中,进行一次提交并删除事务日志的操作叫做flush。分片每 30 分钟,或事务日志过大会进行一次flush操作。flush API 也可用来进行一次手动flush,POST/_flush针对所有索引有效,POST /index/_flush则指定的索引:
通常很少需要手动flush,通常自动的就够了。
总体的流程大致如下:
Translog设置
translog中的数据只有在fsync和提交时才会被持久化到磁盘。在硬件失败的情况下,在translog提交之前的数据都会丢失。
默认情况下,如果index.translog.durability被设置为async的话,Elasticsearch每5秒钟同步并提交一次translog。或者如果被设置为request(默认)的话,每次index,delete,update,bulk请求时就同步一次translog。更准确地说,如果设置为request, Elasticsearch只会在成功地在主分片和每个已分配的副本分片上fsync并提交translog之后,才会向客户端报告index、delete、update、bulk成功。
可以动态控制每个索引的translog行为:
- index.translog.sync_interval :translog多久被同步到磁盘并提交一次。默认5秒。这个值不能小于100ms
- index.translog.durability :是否在每次index,delete,update,bulk请求之后立即同步并提交translog。接受下列参数:
- request :(默认)fsync and commit after every request。这就意味着,如果发生崩溃,那么所有只要是已经确认的写操作都已经被提交到磁盘。
- async :在后台每sync_interval时间进行一次fsync和commit。意味着如果发生崩溃,那么所有在上一次自动提交以后的已确认的写操作将会丢失。
- index.translog.flush_threshold_size :当操作达到多大时执行刷新,默认512mb。也就是说,操作在translog中不断累积,当达到这个阈值时,将会触发刷新操作。
- index.translog.retention.size :translog文件达到多大时执行执行刷新。默认512mb。
- index.translog.retention.age :translog最长多久提交一次。默认12h。
合并段
由于自动刷新流程每秒会创建一个新的段 ,这样会导致短时间内的段数量暴增。而段数目太多会带来较大的麻烦。每一个段都会消耗文件句柄、内存和 cpu 运行周期。更重要的是,每个搜索请求都必须轮流检查每个段然后合并查询结果,所以段越多,搜索也就越慢。
ES 通过后台合并段解决这个问题。小段被合并成大段,再合并成更大的段。这时旧的文档从文件系统删除的时候,旧的段不会再复制到更大的新段中。合并的过程中不会中断索引和搜索。
段合并在进行索引和搜索时会自动进行,合并进程选择一小部分大小相似的段,并且在后台将它们合并到更大的段中,这些段既可以是未提交的也可以是已提交的。
合并结束后老的段会被删除,新的段被 flush 到磁盘,同时写入一个包含新段且排除旧的和较小的段的新提交点,新的段被打开可以用来搜索。
合并大的段会消耗很多 IO 和 CPU,如果不检查会影响到搜素性能。默认情况下,ES 会限制合并过程,这样搜索就可以有足够的资源进行。
日志
慢日志
Search Slow Log(查询慢日志)
分片级慢查询日志,允许将慢查询记录到专用的日志文件中
可以在执行query阶段和fetch阶段设置阈值,例如:

上面所有的设置项都是动态设置的,而且是按索引设置的。(PS:也就是说,是针对某一个索引设置的)
默认情况下,是禁用状态(设置为-1)
级别(warn, info, debug, trace)可以控制哪些日志级别的日志将会被记录
注意,日志记录是在分片级别范围内完成的,这意味着只有在特定的分片中执行搜索请求的慢日志才会被记录。
日志文件配置默认在log4j2.properties
Index Slow Log(索引慢日志)
和前面的慢查询日志类似,索引慢日志文件名后缀为_index_indexing_slowlog.log
日志和阈值配置与慢查询类似,而且默认日志文件配置也是在log4j2.properties
下面是一个例子:

参考
标签:index,--,索引,详解,Elasticsearch,分片,文档,segment,ES From: https://www.cnblogs.com/Insa/p/17011899.htmlhttps://juejin.cn/post/6844903849786867720 从原理到应用,Elasticsearch详解(下)
https://blog.csdn.net/weixin_44558760/article/details/89095770 ELKstack学习【第02篇】Elasticsearch内部分片及分片处理机制介绍
https://blog.csdn.net/zhenwei1994/article/details/94013059 ES基本介绍
https://www.jianshu.com/p/cc06f9adbe82 【ES】ElasticSearch 深入分片
https://developer.aliyun.com/article/707279 干货 | Elasticsearch索引生命周期管理探索
https://www.jianshu.com/p/217144c71724 ES中的索引生命周期管理
https://blog.csdn.net/tanga842428/article/details/60953579 Elasticsearch中setting,mapping,分片查询方式
Elasticsearch之settings和mappings(图文详解)
https://juejin.cn/post/6971974348202573854 教你在 Kubernetes 中快速部署 ES 集群
https://blog.csdn.net/u010824591/article/details/78614505 ES集群监控总结
elasticsearch系列二:索引详解(快速入门、索引管理、映射详解、索引别名)
https://blog.csdn.net/a745233700/article/details/117953198 Elasticsearch搜索引擎:ES的segment段合并原理