目前市面上有很多日志框架,不同的项目依赖不同的框架,到最后我们的项目里就会有很多日志框架
历史
先来梳理一下市面上的日志框架。
-
log4j 日志实现
1996年推出,Apache 曾经建议SUN把log4j收入JDK中。
-
JUL(Java Util Logging) 日志实现
2002年由SUN推出,想要跟log4j比一比
-
JCL(Jakarta Commons Logging)日志门面
2002年Apache推出,为日志框架提供了统一的接口。
-
SLF4J(Simple Logging Facade for Java)日志门面
2005年log4j的原作者推出,因为出的晚,为了兼容目前市面上所有的日志实现,顺便推出了各种桥接包
-
logback 日志实现
log4j的原作者推出
-
log4j2 日志门面(log4j2-api)+实现(log4j2-core)
Apache 推出的logback的竞品,具有logback的全部功能。
-
jboss-logging 日志门面
redhat推出的,能自动检测类路径下的日志实现,自动适配。
https://docs.jboss.org/hibernate/orm/current/topical/html_single/logging/Logging.html
关系梳理
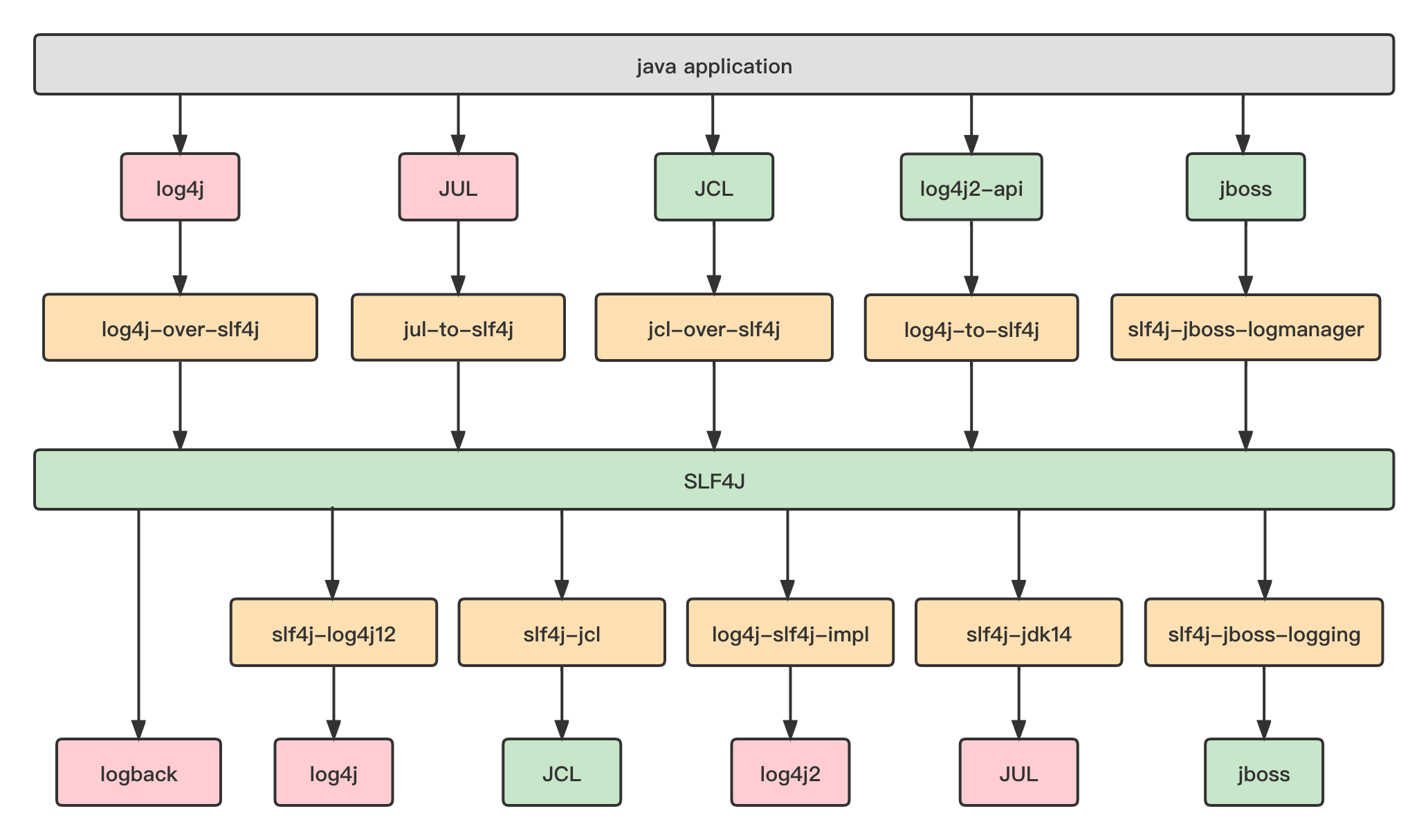
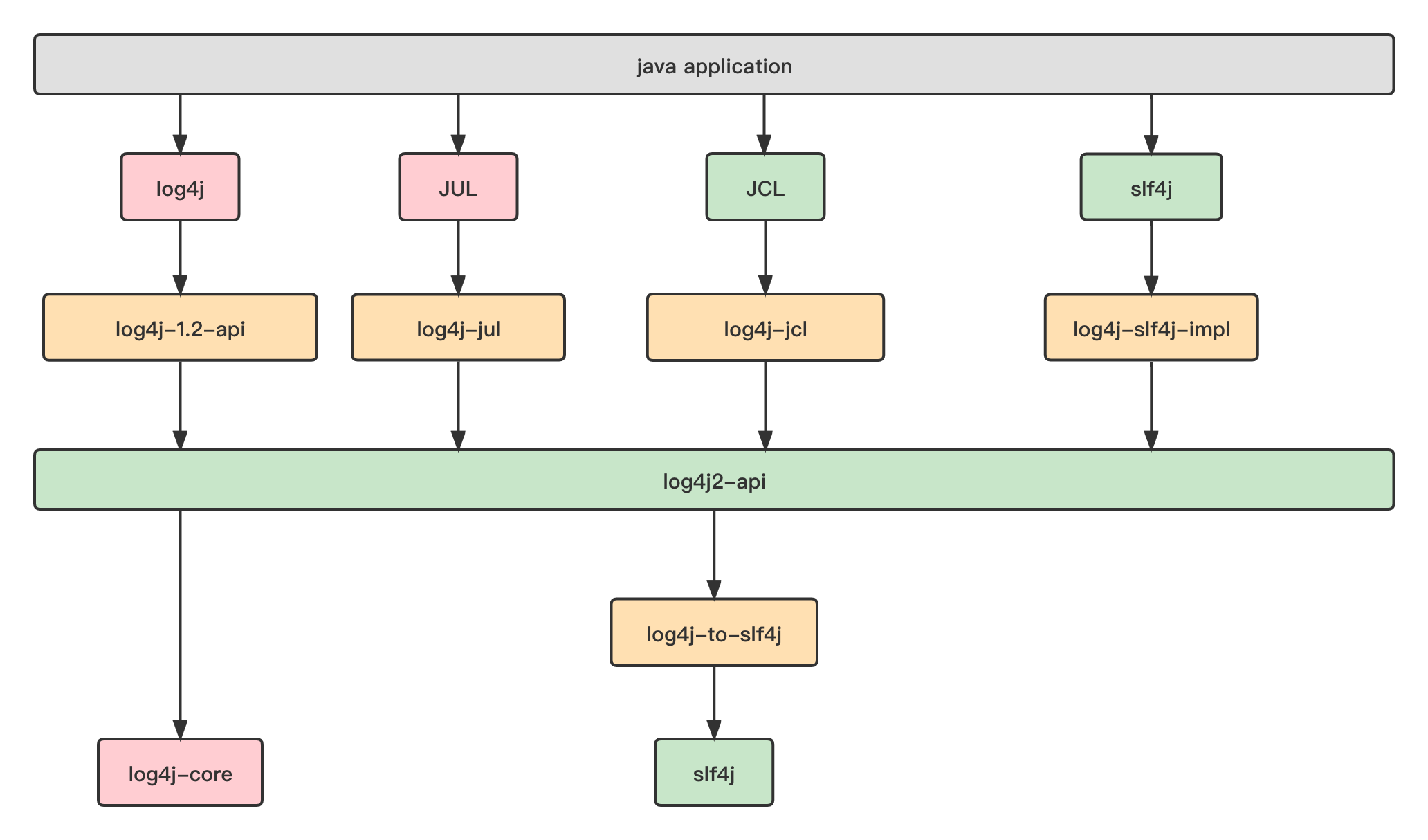
日志依赖最佳实践
-
保证项目里只有一个日志门面和实现
项目中有多个实现的话,不仅配置麻烦(每个实现都有不一样的配置文件),而且使用起来混乱,可能出现不一样的接口使用不同的日志框架的问题。
-
将日志实现的依赖设置为
Optional和runtime scope;日志门面设置为Optional。我们项目中有那么多日志依赖就是因为没有设置为
Optional,导致的依赖传递。设置成
runtime后,写代码的时候就不能直接调用日志实现的API了,避免直接调用。
LOG4J2介绍
异步性能强大
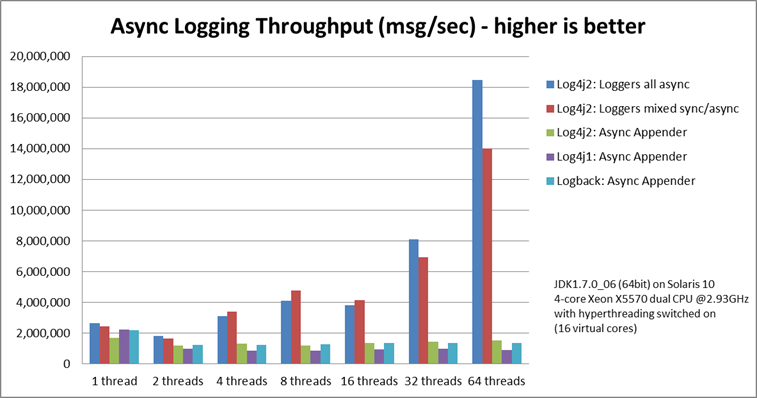
零 GC(Garbage-free)
不会导致 GC。各种 Message 对象,字符串数组,字节数组全部复用不重复创建。
更高性能 I/O 写入的支持
提供了一个 MemoryMappedFileAppender,I/O 部分使用 MemoryMappedFile 来实现,可以得到很高的 I/O 性能。
内存映射文件是一种允许Java程序直接从内存访问的特殊文件。通过将整个文件或者文件的一部分映射到内存中、操作系统负责获取页面请求和写入文件,应用程序就只需要处理内存数据,这样可以实现非常快速的IO操作。用于内存映射文件的内存在Java的堆空间以外。Java中的java.nio包支持内存映射文件,可以使用MappedByteBuffer来读写内存
使用 String.format 的形式格式化参数
log4j-api除了提供了slf4j提供的支持{}参数占位符的接口外,还提供了 String.format 的形式:
logger.debug("Logging in user %s with birthday %s", user.getName(), user.getBirthdayCalendar());
logger.debug("Logging in user %1$s with birthday %2$tm %2$te,%2$tY", user.getName(), user.getBirthdayCalendar());
logger.debug("Integer.MAX_VALUE = %,d", Integer.MAX_VALUE);
logger.debug("Long.MAX_VALUE = %,d", Long.MAX_VALUE);
不过这些接口属于log4j-api,需要使用log4j-api做门面。同时还需要使用LogManager.getFormatterLogger来获取logger,而不是LogManager.getLogger。
不过普通的logger中也提供了一个printf()方法,实现上面的效果:
logger.printf(Level.INFO, "Logging in user %1$s with birthday %2$tm %2$te,%2$tY", user.getName(), user.getBirthdayCalendar());
“惰性”打日志(lazy logging)
为了在低日志级别下不浪费系统资源,一般都需要:
if(logger.isDebugEnabled()){
logger.debug("入参报文:{}",JSON.toJSONString(policyDTO));
}
log4j2提供了在低日志级别下更优雅的输出方式:
//debug(String message, Supplier<?>... paramSuppliers);
logger.debug("入参报文:{}",() -> JSON.toJSONString(policyDTO));
slf4j在2.0.0也提供了类似的方法:
//fluent API
logger.atDebug().addArgument(() -> t16()).log(msg, "Temperature set to {}. Old temperature was {}.", oldT);
日志打印的几个建议
-
选择合适的日志级别
-
fatal:致命错误,会影响服务运行状态的错误。一般用不到。
-
error:影响到程序、当前请求正常运行的异常情况。
如果捕获了异常需要记录完整的错误堆栈;
如果抛出了异常就不要记录error日志,由调用方处理。
-
warn:不应该出现但是不影响程序、当前请求正常运行的异常情况。
-
info:系统运行信息,记录排查问题的关键信息,如调用时间、出参入参、业务逻辑的变化等等;
-
debug:用于开发DEBUG的,关键逻辑里面的运行时数据;
-
trace:最详细的信息,基本不用。
-
-
记录方法的入参和出参
-
选择合适的日志格式
-
在条件分支的各个分支都打印日志
-
日志级别比较低时,进行日志开关判断

log4j2有支持lambda表达式的懒加载模式:
if (logger.isTraceEnabled()) { logger.trace("Some long-running operation returned {}", expensiveOperation()); }可以改为:
logger.trace("Some long-running operation returned {}", () -> expensiveOperation());slf4j目前不支持。
-
不能直接使用日志实现中的 API,而是使用日志门面中的API。

-
建议使用参数占位{},而不是用+拼接

log4j2支持跟
String.format()一样的格式化方式:logger.debug("Integer.MAX_VALUE = %,d", Integer.MAX_VALUE); -
用[]来分隔日志输出中的参数
log.info("获取用户[{}]的用户信息时出错",userName); -
使用异步的方式来输出日志
为什么?因为打印日志是将日志输出到文件,受限于硬盘的性能,输出到文件是很浪费时间的
同步阻塞IO(Blocking IO)
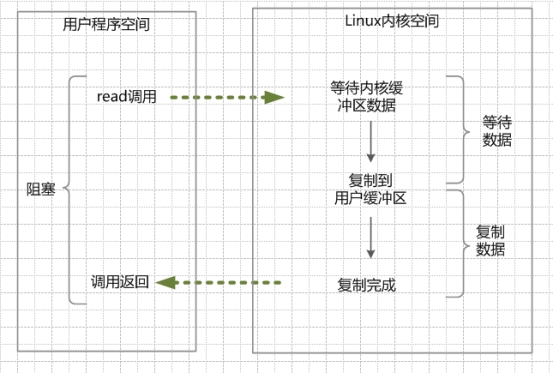
同步非阻塞NIO(None Blocking IO)
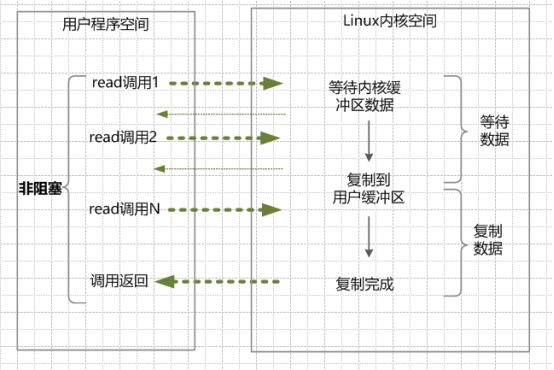
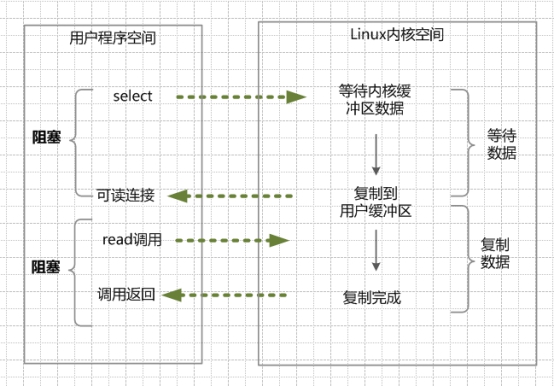
IO多路复用模型(I/O multiplexing)
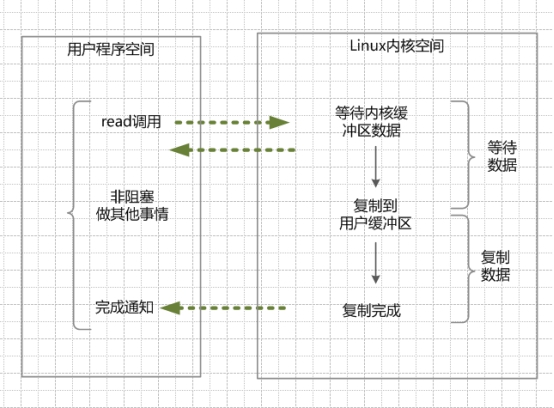
异步IO模型(asynchronous IO)
-
记录异常的时候要同时输出所有错误信息。
try { //业务逻辑 } catch (Exception e) { logger.error('你的程序有异常啦',e); } -
日志文件分离,使用
RollingFileAppender -
不要重复打印日志

-
不要使用JSON序列化
