RP idea
当时出愿的时候研究计划书的随笔,当时没有接触过AL+label annotation,只知道AL,然后下意识把俩个领域联系起来了,没想到这两个领域联系已经有好几年成熟的研究体系了XD
Brain Storming
-
人群计数 + HCI
-
手动调节识别区域。来提高识别精度
比如圈起来。然后可以分块resize
挺多这种应用的 -
可以手动设置密度等级。来应用不同的网络
低密度,中密度,高密度
-
-
标签辅助 + HCI + CV
- 不同层次的label来帮助业余工作人员标注数据集
- 用空间防止,手动分类来帮助标注
- 用两个标签来帮助标注:high confident,low confident
- 自己的idea:除了两个标签以外,还可以拿一个label表示最不可能是....。
-
主动学习 active learning
感觉这个方向可以很好的把CV和HCI结合起来
通过DL方法来提高label的用处,然后利用HCI方法来帮助工作人员label 图像
这样可以最大程度上的利用 样本 以及标签的用处
比如这个图。我想标注一个狗种类分类的数据集。然后人做的事情,就是选择 是否为狗 - 是哪种狗? 这两件事。然后分别有两个识别精确度。我们可以用主动学习,来选择哪种图片利于哪种识别模型图片
具体确定方向
-
Active Learning + Assist Labelling
描述:五十岚老师实验室有一篇论文是,为了提高标注效率,工作人员标注的时候,可以让他选2个label。一个high一个low confidence
然后结合主动学习这个技术,如果,一个没标注的数据集,当吐出一张图片给工作人员标注的时候
可以先经过一个预训练好的网络
然后网络生成各个label的概率。然后按概率从大到小展示给工作人员。 以此为依据来帮助标注理论依据是 :如果有很多label,工作人员标注的时候,如果对这个不太熟悉的话。,需要时间来回忆label是什么。比如说什么什么种类的dog,cat
如果先经过一个网络的话。就可以让工作人员更快的找到自己识别的label
以此来提高效率,以及精确度
知识体系
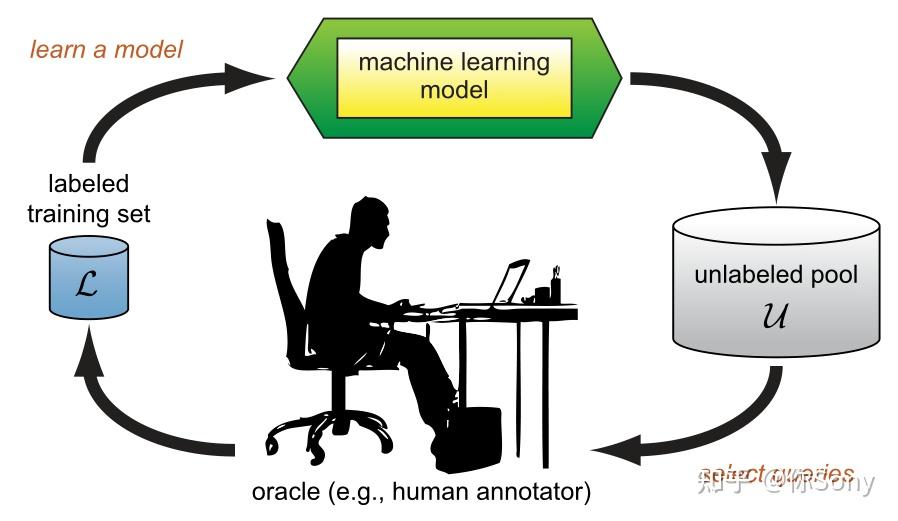
Active learning
在主动学习框架中,最重要的就是如何设计一个查询策略来判断样本的价值,即是否值得被oracle标注。而样本的价值并不是一成不变的,它不仅与样本自身有关,还和任务和模型等因素有关。一个简单的例子,在猫狗二分类问题中,一张长得像猫的狗的照片,对分类模型的训练往往是有价值,因为它难以分辨。但是,同样是这张照片,出现在动植物二分类问题中,就变得不那么重要了,因为模型想分辨它并不难。
查询策略:
- 不确定性采样 (Uncertainty Sampling)*
算法只需要查询最不确定的样本给oracle标注,通常情况下,模型通过学习不确定性强的样本的标签能够迅速提升自己的性能 - 多样性采样 (Diversity Sampling) *
是从数据的分布考虑的常用策略。算法根据数据分布确保查询的样本能够覆盖整个数据分布以保证标注数据的多样性。 - 预期模型改变(Expected Model Change) *
EMC通常选择对当前模型改变最大、影响最大的样本给oracle标注,一般来说,需要根据样本的标签才能反向传播计算模型的改变量或梯度等。 - 委员会查询 (Query-By-Committee)
QBC是利用多个模型组成的委员会对候选的数据进行投票,即分别作出决策,最终他们选择最有分歧的样本作为最有信息的数据给oracle标注。
经典方法:
- Entropy
可直接根据预测的概率分布计算熵值,选择熵值最大的样本来标注。 - BALD
...
图像分类算法
VGG Net、ResNet、ResNeXt、SE-Net