
l 采集网站
【场景描述】采集收视率排行数据。
【源网站介绍】收视率排行网提供收视率排行,收视率查询,电视剧收视率,综艺节目收视率和电视台收视率信息。
【使用工具】前嗅ForeSpider数据采集系统
【入口网址】http://www.tvtv.hk/archives/category/tv
【采集内容】
采集收视率排行网上省级卫视收视率数据,采集字段:标题、发布时间、排行内容。
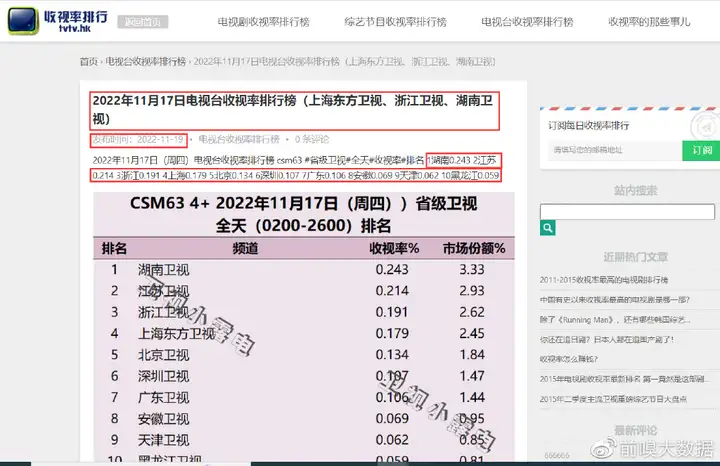
【采集效果】
如下图所示:
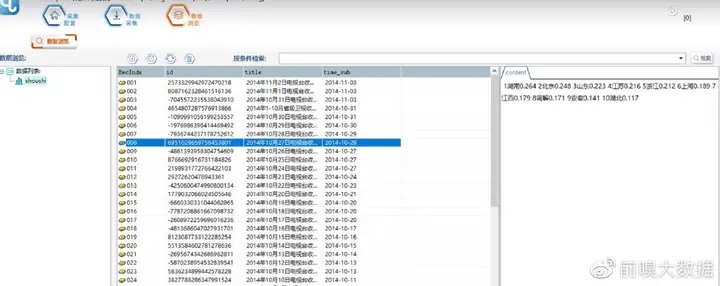
l 思路分析
配置思路概览:

l 配置步骤
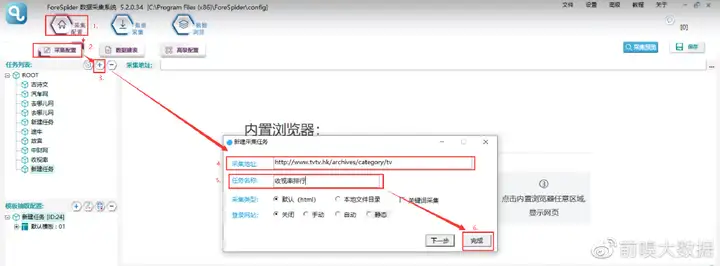
一.新建采集任务
选择【采集配置】,点击任务列表右上方【+】号可新建采集任务,将采集入口地址填写在【采集地址】框中,【任务名称】自定义即可,点击下一步。
二. 模板配置
1. 翻页链接采集配置
①查找翻页链接及其规律
在入口地址页内打开“F12”,按如下步骤找到翻页地址,并复制刷新后的翻页链接地址
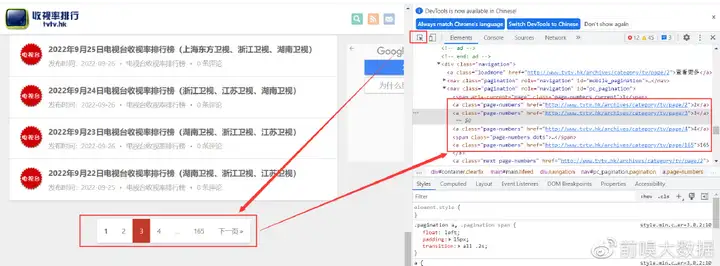
对比观察翻页链接的规律观察:随着翻页变化,页码数与请求网址(Requestrian URL)中“page/”后的数字相关。所以,其规律为:http://www.tvtv.hk/archives/category/tv/page/+翻页页码
找到翻页链接位置及其规律就可以对应去编写脚本。
②脚本的创建与编写
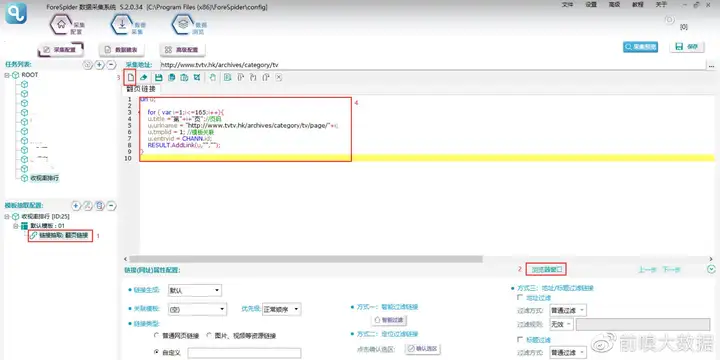 【脚本的创建与编写】
【脚本的创建与编写】
脚本文本:
url u;
for ( var i=1;i<=165;i++){
u.title ="第"+i+"页";//页码
u.urlname = "http://www.tvtv.hk/archives/category/tv/page/"+i;
u.tmplid = 1; //模板关联
u.entryid = CHANN.id;
RESULT.AddLink(u,"","");
}
③查看采集预览
查看采集预览,并将链接粘贴到浏览器验证一下是否采集正确。
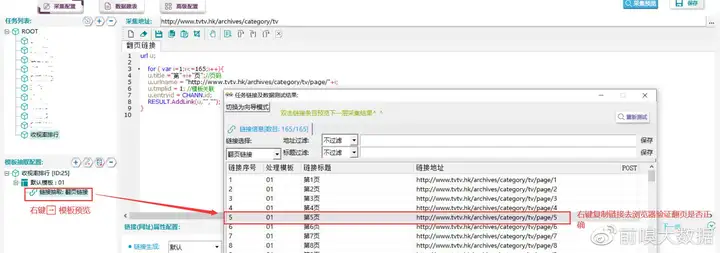 【采集预览】
【采集预览】
2. 列表链接抽取配置
①添加链接抽取,更名为列表链接
②点击脚本窗口
③新建脚本
④编写列表链接抽取脚本
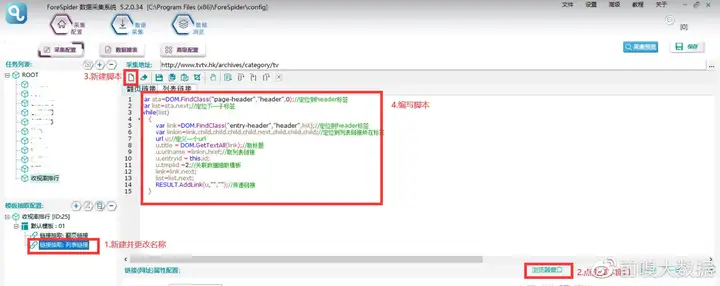
脚本文本:
var sta=DOM.FindClass("page-header","header",0);//定位到header标签
var list=sta.next;//定位下一子标签
while(list) {
var link=DOM.FindClass("entry-header","header",list);//定位到header标签
var linkin=link.child.child.child.child.next.child.child.child;//定位到列表链接所在标签
url u;//定义一个url
u.title = DOM.GetTextAll(link);//取标题
u.urlname =linkin.href;//取列表链接
u.entryid = this.id;
u.tmplid =2;//关联数据抽取模板
link=link.next;
list=list.next;
RESULT.AddLink(u,"","");//传递链接
}
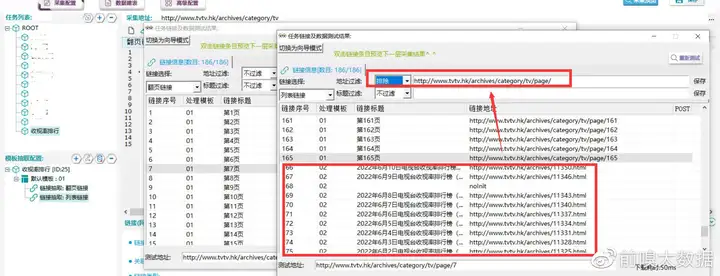
⑤据观察发现,列表链接规律为:http://www.tvtv.hk/archives/而翻页链接规律为:http://www.tvtv.hk/archives/category/tv/page/此处则可以用地址过滤排除翻页链接,如图;然后复制任意一个列表链接到浏览器打开验证
3. 数据抽取
①新建模板、添加数据抽取
如下新建模板并添加数据抽取,在示例地址框内输入上一步复制的列表链接
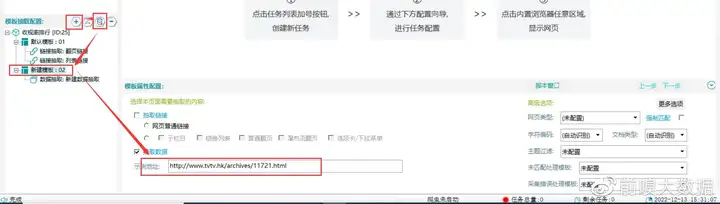 【新建模板、添加数据抽取】
【新建模板、添加数据抽取】
②数据表结构创建
如下在表结构内创建出所需采集的字段
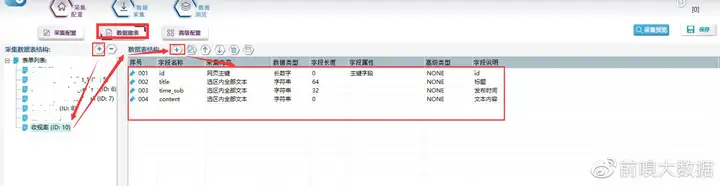 【创建表结构】
【创建表结构】
③关联表单
数据抽取关联数据结构表单
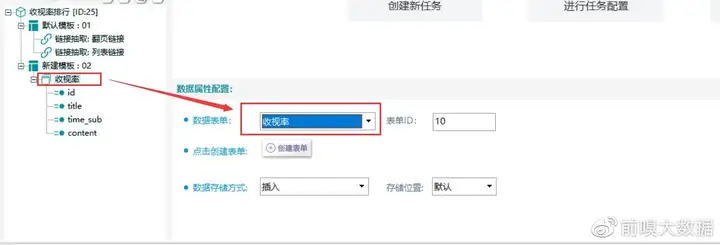 【关联表单】
【关联表单】
④创建并编写数据抽取脚本
如下创建脚本,并根据网页结构编写数据抽取脚本
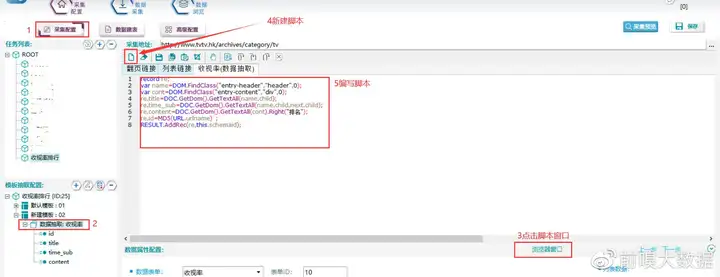 【脚本的创建与编写】
【脚本的创建与编写】
脚本文本:
record re;//定义一个record记录集
var name=DOM.FindClass("entry-header","header",0);//定位到header标签
var cont=DOM.FindClass("entry-content","div",0);//定位到div标签
re.title=DOC.GetDom().GetTextAll(name.child);//取标题文本
re.time_sub=DOC.GetDom().GetTextAll(name.child.next.child);//取时间文本
re.content=DOC.GetDom().GetTextAll(cont).Right("排名");//取排名文本
re.id=MD5(URL.urlname) ;//id
RESULT.AddRec(re,this.schemaid);//输出结果
⑤查看采集预览
查看采集预览,并核对一下内容是否采集正确。
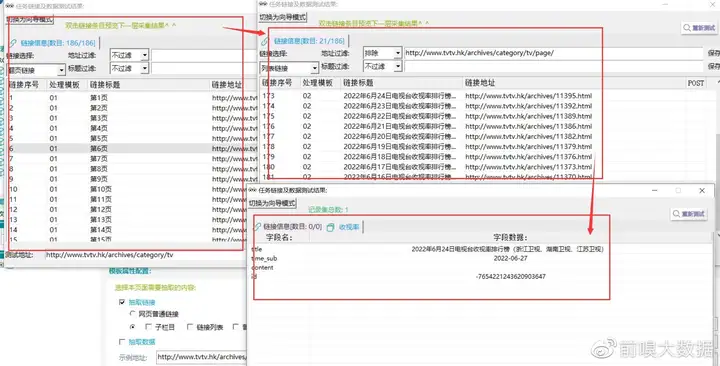 【采集预览】
【采集预览】
l 采集步骤
三、数据采集
1.建立数据表单:
选择【数据建表】,点击【表单列表】中该模板的表单,在【关联数据表】中选择【创建】,表名称自定义,这里命名为【shoushilv】(注意命名不能用数字、文字和特殊符号),点击【确定】。创建完成,勾选数据表,并点击右上角保存按钮。
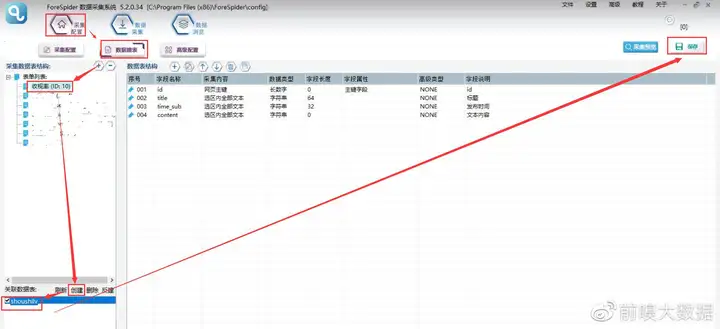 【建立关联数据表】
【建立关联数据表】
2.开始采集
选择【数据采集】,勾选任务名称,点击【开始采集】,则正式开始采集。
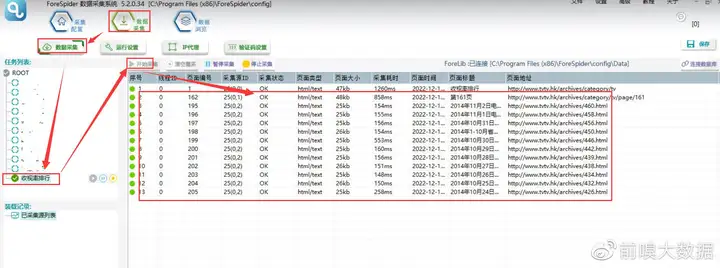 【开始采集】
【开始采集】
3.导出数据
采集结束后,可以在【数据浏览】中,选择数据表查看采集数据,并可以导出数据。
 【数据浏览】
【数据浏览】
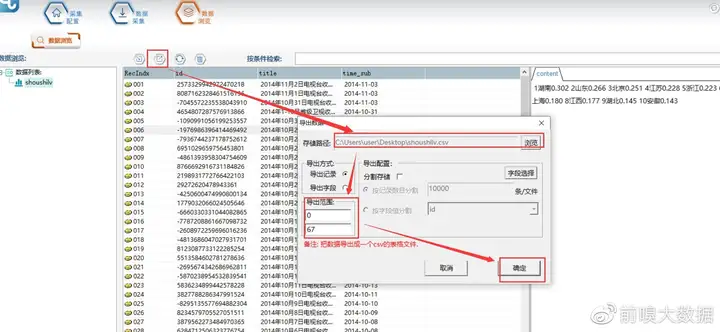 【数据导出】
【数据导出】
4.导出的文件打开如下图所示:
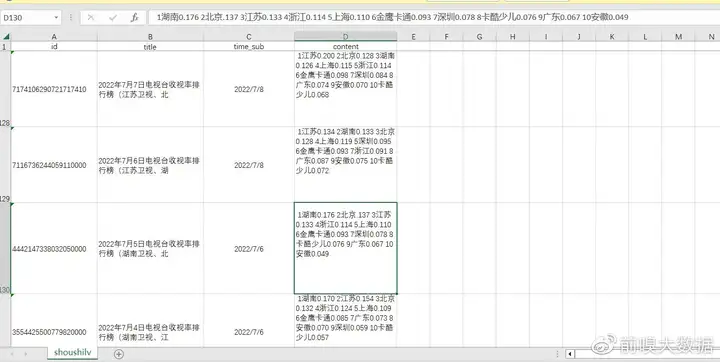 【查看导出数据】
【查看导出数据】
本教程仅供教学使用,严禁用于商业用途!
标签:翻页,收视率,爬虫,采集,从零开始,child,数据,链接 From: https://www.cnblogs.com/forenose/p/16986279.html