DeepFM
目录推荐系统通常由物料->召回->粗排->精排->重排->机制几个阶段构成,其中精排阶段的主要工作为CTR预估(预估用户点击某推荐内容的概率)。DeepFM模型目前仍然是国内各个大厂推荐系统精排阶段常用的base model,在性能和效果方面都有不错的表现。DeepFM模型是Wide & Deep模型的升级版。DeepFM模型与Wide&Deep模型类似,包含浅层模型和深层模型两部分,主要的不同点是Wide&Deep模型的浅层结构为LR,DeepFM的浅层模型结构为FM,FM模型结构相比于LR模型结构有自动学习交叉特征的能力,避免了LR模型结构中大量的人工特征工作。
一、模型介绍
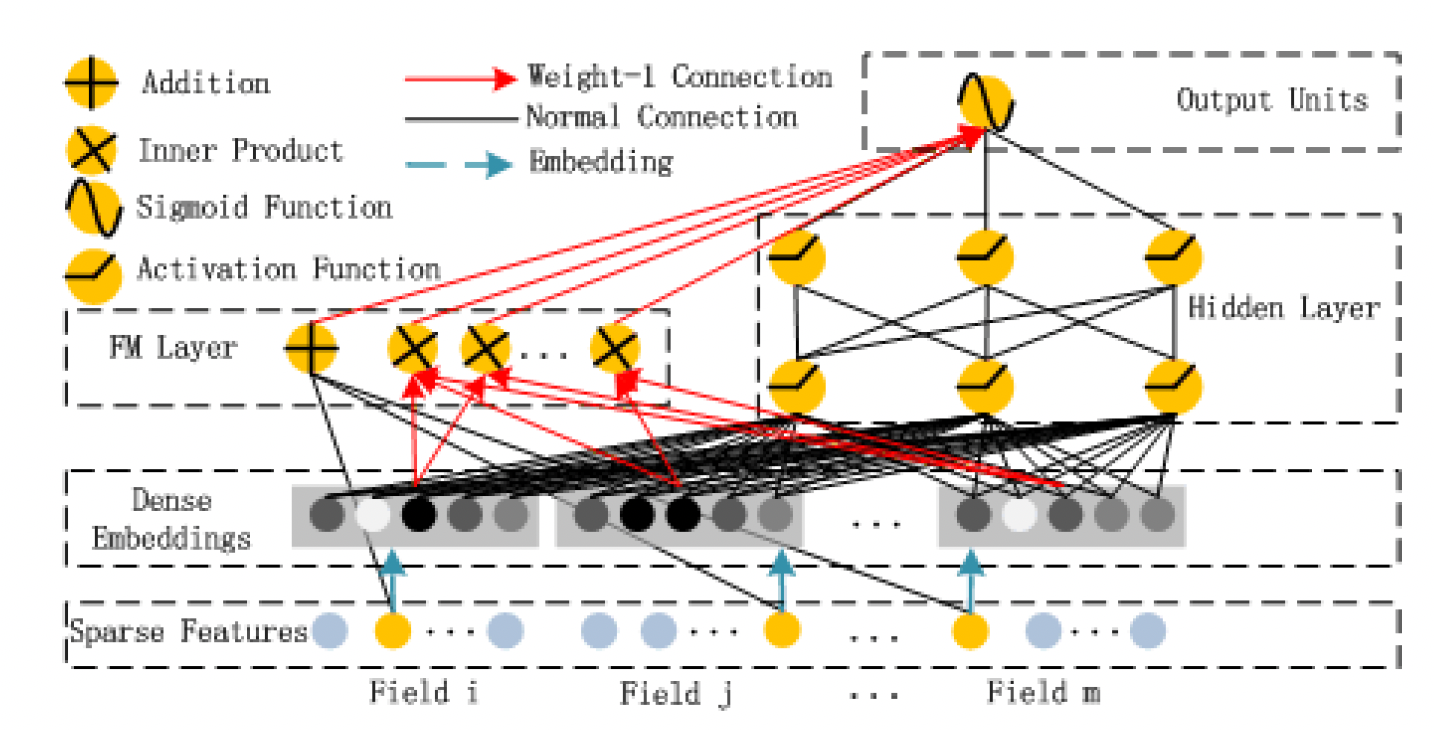
DeepFM模型结构包含FM和DNN两部分,其中:
- FM部分主要用来抽取低阶特征(通常是抽取一阶特征和二阶交叉特征),DNN部分主要用来抽取高阶特征。
- FM和DNN部分共享输入向量特征。
- 模型联合训练
模型预估结果可表示为:

二、FM部分
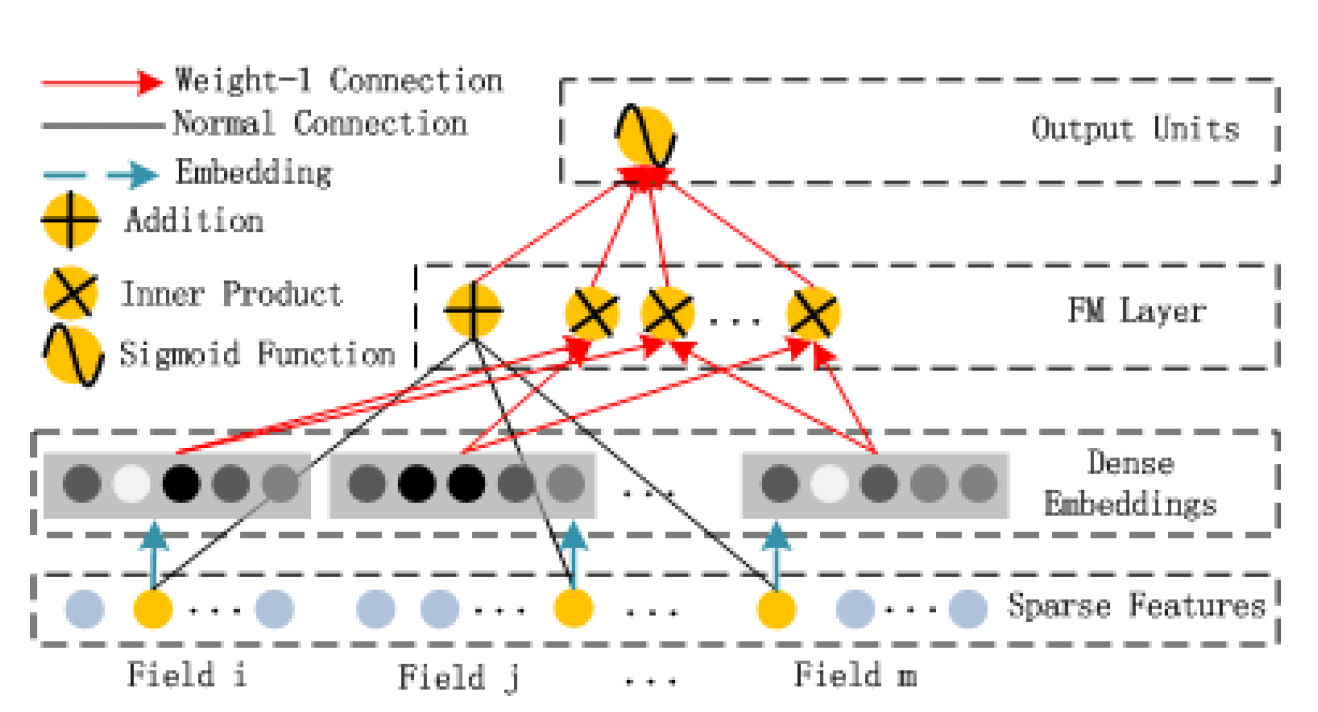
FM部分主要用来抽取低阶特征(通常是抽取一阶特征和二阶交叉特征),数据集中非常稀疏甚至是从来没出现过的交叉特征也能通过FM部分学习到。

三、DNN部分
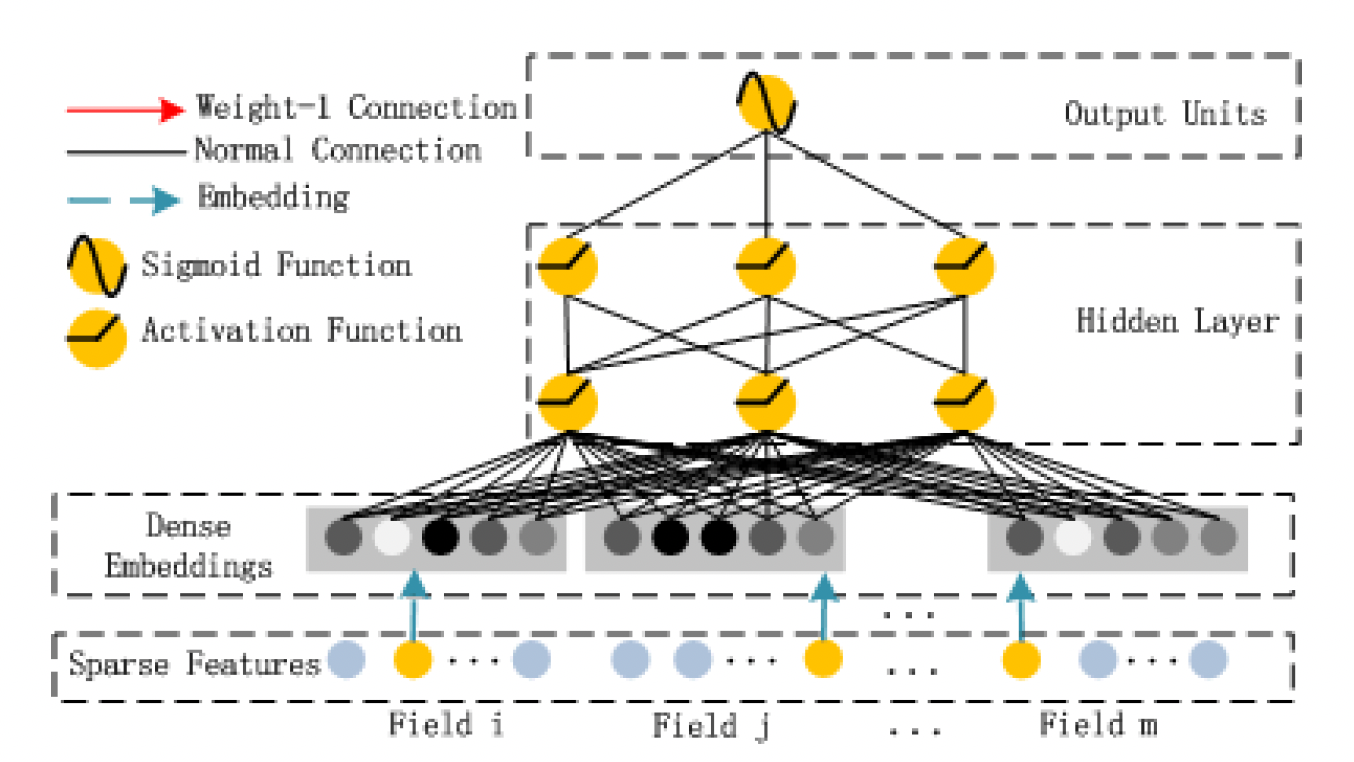
这一部分是简单的前馈神经网络部分,比较常见的做法是非连续型特征经过embedding层转化为稠密型向量特征,拼接上连续型特征一起做为这一部分的输入。
四、DeepFM代码示例
DeepFM的实现方式形式不唯一,但基本都大同小异,重点是要包含一阶特征和二阶交叉特征的实现。可以参考:https://github.com/zxxwin/tf2_deepfm。
Criteo数据集下载,可关注公众号『后厂村搬砖工』,发送cirteo即可。

# encoding=utf-8
import numpy as np
import pandas as pd
from tensorflow.keras.layers import *
import tensorflow.keras.backend as K
import matplotlib.pyplot as plt
import tensorflow as tf
from tensorflow.keras.models import Model
from tensorflow.keras.utils import plot_model
from sklearn.preprocessing import LabelEncoder
train_data = pd.read_csv('./data/criteo_train_sample.csv', sep='\t')
names = ["L"] + ["I{}".format(i) for i in range(1, 14)] + ["C{}".format(i) for i in range(1, 27)]
print(len(names))
print(names)
train_data.columns = names
print(train_data.shape)
print(train_data.head())
cols = train_data.columns.values
print(cols)
dense_feats = [f for f in cols if f[0] == "I"]
sparse_feats = [f for f in cols if f[0] == "C"]
print(dense_feats)
print(sparse_feats)
def process_dense_feats(data, feats):
"""Process dense feats.
"""
d = data.copy()
d = d[feats].fillna(0.0)
for f in feats:
d[f] = d[f].apply(lambda x: np.log(x+1) if x > -1 else -1)
return d
def process_sparse_feats(data, feats):
"""Process sparse feats.
"""
d = data.copy()
d = d[feats].fillna("-1")
for f in feats:
# LabelEncoder是用来对分类型特征值进行编码,即对不连续的数值或文本进行编码
# fit(y): fit可看做一本空字典,y可看作要塞到字典中的词
# fit_transform(y):相当于先进行fit再进行transform,即把y塞到字典中去以后再进行transform得到索引值
label_encoder = LabelEncoder()
d[f] = label_encoder.fit_transform(d[f])
return d
data_dense = process_dense_feats(train_data, dense_feats)
data_sparse = process_sparse_feats(train_data, sparse_feats)
total_data = pd.concat([data_dense, data_sparse], axis=1)
print(data_dense.head(5))
print(data_sparse.head(5))
print(total_data.head(5))
total_data['label'] = train_data['L']
# =====================
# dense 特征一阶特征
# =====================
# 构造 dense 特征的输入
dense_inputs = []
for f in dense_feats:
_input = Input([1], name=f)
dense_inputs.append(_input)
# 将输入拼接到一起,方便连接 Dense 层
concat_dense_inputs = Concatenate(axis=1)(dense_inputs) # ?, 13
# 然后连上输出为1个单元的全连接层,表示对 dense 变量的加权求和
fst_order_dense_layer = Dense(1)(concat_dense_inputs) # ?, 1
# 这里单独对每一个 sparse 特征构造输入,目的是方便后面构造二阶组合特征
sparse_inputs = []
for f in sparse_feats:
_input = Input([1], name=f)
sparse_inputs.append(_input)
# =====================
# sparse 特征一阶特征
# =====================
sparse_1d_embed = []
for i, _input in enumerate(sparse_inputs):
f = sparse_feats[i]
voc_size = total_data[f].nunique()
# 使用 l2 正则化防止过拟合
reg = tf.keras.regularizers.l2(0.5)
_embed = Embedding(voc_size, 1, embeddings_regularizer=reg)(_input)
# 由于 Embedding 的结果是二维的,因此如果需要在 Embedding 之后加入 Dense 层,则需要先连接上 Flatten 层
_embed = Flatten()(_embed)
sparse_1d_embed.append(_embed)
# 对每个 embedding lookup 的结果 wi 求和
fst_order_sparse_layer = Add()(sparse_1d_embed)
linear_part = Add()([fst_order_dense_layer, fst_order_sparse_layer])
# =====================
# sparse 特征二阶交叉特征
# =====================
# embedding size
k = 8
# 只考虑sparse的二阶交叉
sparse_kd_embed = []
for i, _input in enumerate(sparse_inputs):
f = sparse_feats[i]
voc_size = total_data[f].nunique()
reg = tf.keras.regularizers.l2(0.7)
_embed = Embedding(voc_size, k, embeddings_regularizer=reg)(_input)
sparse_kd_embed.append(_embed)
# 将所有sparse的embedding拼接起来,得到 (n, k)的矩阵,其中n为特征数,k为embedding大小
concat_sparse_kd_embed = Concatenate(axis=1)(sparse_kd_embed) # ?, n, k
# 先求和再平方
sum_kd_embed = Lambda(lambda x: K.sum(x, axis=1))(concat_sparse_kd_embed) # ?, k
square_sum_kd_embed = Multiply()([sum_kd_embed, sum_kd_embed]) # ?, k
# 先平方再求和
square_kd_embed = Multiply()([concat_sparse_kd_embed, concat_sparse_kd_embed]) # ?, n, k
sum_square_kd_embed = Lambda(lambda x: K.sum(x, axis=1))(square_kd_embed) # ?, k
# 相减除以2
sub = Subtract()([square_sum_kd_embed, sum_square_kd_embed]) # ?, k
sub = Lambda(lambda x: x*0.5)(sub) # ?, k
snd_order_sparse_layer = Lambda(lambda x: K.sum(x, axis=1, keepdims=True))(sub) # ?, 1
# =====================
# DNN部分
# =====================
flatten_sparse_embed = Flatten()(concat_sparse_kd_embed) # ?, n, k
fc_layer = Dropout(0.5)(Dense(256, activation='relu')(flatten_sparse_embed)) # ?, 256
fc_layer = Dropout(0.3)(Dense(256, activation='relu')(fc_layer)) # ?, 256
fc_layer = Dropout(0.1)(Dense(256, activation='relu')(fc_layer)) # ?, 256
fc_layer_output = Dense(1)(fc_layer) # ?, 1
output_layer = Add()([linear_part, snd_order_sparse_layer, fc_layer_output])
output_layer = Activation("sigmoid")(output_layer)
model = Model(dense_inputs + sparse_inputs, output_layer)
print(model.summary())
model.compile(optimizer="adam",
loss="binary_crossentropy",
metrics=["binary_crossentropy", tf.keras.metrics.AUC(name='auc')])
# 划分训练集与测试集
# train_data = total_data.loc[:5000-1]
# valid_data = total_data.loc[5000:]
train_data = total_data.loc[:990000-1]
valid_data = total_data.loc[990000:]
# 拆分训练集dense特征、sparse特征、label
train_dense_x = [train_data[f].values for f in dense_feats]
train_sparse_x = [train_data[f].values for f in sparse_feats]
train_label = [train_data['label'].values]
print(train_label)
# 划分测试集dense特征、sparse特征、label
val_dense_x = [valid_data[f].values for f in dense_feats]
val_sparse_x = [valid_data[f].values for f in sparse_feats]
val_label = [valid_data['label'].values]
print(val_label)
model.fit(
train_dense_x + train_sparse_x,
train_label,
epochs=5,
batch_size=256,
validation_data=(val_dense_x+val_sparse_x, val_label),
)
Epoch 1/5
WARNING:tensorflow:AutoGraph could not transform <function Model.make_train_function.<locals>.train_function at 0x13820fb00> and will run it as-is.
Please report this to the TensorFlow team. When filing the bug, set the verbosity to 10 (on Linux, `export AUTOGRAPH_VERBOSITY=10`) and attach the full output.
Cause: 'arguments' object has no attribute 'posonlyargs'
To silence this warning, decorate the function with @tf.autograph.experimental.do_not_convert
3868/3868 [==============================] - ETA: 0s - loss: 24.3636 - binary_crossentropy: 0.5277 - auc: 0.7015WARNING:tensorflow:AutoGraph could not transform <function Model.make_test_function.<locals>.test_function at 0x16f378a70> and will run it as-is.
Please report this to the TensorFlow team. When filing the bug, set the verbosity to 10 (on Linux, `export AUTOGRAPH_VERBOSITY=10`) and attach the full output.
Cause: 'arguments' object has no attribute 'posonlyargs'
To silence this warning, decorate the function with @tf.autograph.experimental.do_not_convert
3868/3868 [==============================] - 224s 57ms/step - loss: 24.3636 - binary_crossentropy: 0.5277 - auc: 0.7015 - val_loss: 0.5689 - val_binary_crossentropy: 0.4877 - val_auc: 0.7490
Epoch 2/5
3868/3868 [==============================] - 224s 58ms/step - loss: 0.5913 - binary_crossentropy: 0.4968 - auc: 0.7379 - val_loss: 0.5939 - val_binary_crossentropy: 0.4835 - val_auc: 0.7539
Epoch 3/5
3868/3868 [==============================] - 218s 56ms/step - loss: 0.6126 - binary_crossentropy: 0.4959 - auc: 0.7392 - val_loss: 0.6226 - val_binary_crossentropy: 0.4894 - val_auc: 0.7475
Epoch 4/5
3868/3868 [==============================] - 220s 57ms/step - loss: 0.6161 - binary_crossentropy: 0.4953 - auc: 0.7401 - val_loss: 0.6059 - val_binary_crossentropy: 0.4857 - val_auc: 0.7517
Epoch 5/5
3868/3868 [==============================] - 222s 57ms/step - loss: 0.6174 - binary_crossentropy: 0.4954 - auc: 0.7402 - val_loss: 0.6208 - val_binary_crossentropy: 0.4872 - val_auc: 0.7508