写在之前
prometheus 配置文件大体框架有以下几个部分:
data:
prometheus.yml: | #
rule_files:
- etc/prometheus/rules.yml
alerting:
alertmanagers:
- static_configs:
- targets: ["localhost:9093"]
global:
scrape_interval: 15s
scrape_timeout: 10s
evaluation_interval: 1m
scrape_configs:
- job_name: 'kubernetes-node'
....
rules.yml: |
groups:
- name: example
rules:
- alert: kubernetes-apiserver打开句柄数>1000
...
- name: 物理节点状态-监控告警
rules:
- alert: 物理节点cpu使用率
...
包括两个文件:prometheus配置文件(prometheus.yaml)和 规则文件 (rules.yml)。
Prometheus配置文件,主要配置加载规则文件的路径,报警服务器的连接配置、全局配置、和抓取目标服务器的配置信息,这里会主要讲解抓取规则。
规则文件这里通过分组的形式进行监控,在监控页面也可以很好的展示;
prometheus 配置文件中global
| Global | 含义 |
| scrape_interval: 15s | 收集目标数据的时间间隔,可以使用全局配置,也可以基于某个Job_name配置,默认为15秒, |
| scrape_timeout: 10s | 目标采集超时时间,默认为10秒; |
| evaluation_interval: 1m | 报警状态更新间隔时间,默认1分钟; |
上面说的报警状态,主要有三个,第一篇文章中有提到,这里加深下理解,再次给出。
| 告警状态 | 功能 |
| pending | 警报通知已经被激活,但低于配置的持续时间,这里的持续时间即rule里的FOR字段设置的时间,在此状态下,不发送报警通知 |
| firing | 警报通知已经发送,而且超出设置的持续时间,该状态下发送报警通知 |
| inactive | 正常状态,既不是pending也不是firing的时候状态即inactive |
prometheus 服务发现方式
Prometheus 默认是采用Pull的方式拉取指标数据,那么它是如何知道拉取哪些目标服务的指标数据呢?其实就是通过配置 scrape_configs来定义各种Job来实现目标服务发现的,配置一个job_name后,这个指定的名称就会在Prometheus UI界面 Targets中显示出来,那么我们监控的目标有很多,尤其是Pod、Service这些经常变动的,我们又应该如何来配置管理 呢,下面我们来看Prometheus 中服务发现几种方式:
| Prometheus 服务发现 | 含义 |
| dns_sd_configs | 基于DNS 服务发现; |
| file_sd_configs | 基于文件服务发现; |
| static_configs | 静态服务发现,这个很好理解,比如我们的kube-apiserver、kube-controller-manager、kube-scheduler、Etcd等这些资源相对固定,不会经常性的发生变化,每当有新的目标需要监控时,需要手动配置监控目标服务; |
| kubernetes_sd_configs | 基于Kubernetes的服务发现,比如Pod、Service,这种也叫基于API的动态服务发现; |
| consul_sd_configs | 使用第三方组件Consul ,完成动态服务发现,Prometheus 一直监视consul服务,当发现在consul中注册的服务有变化,prometheus就会自动把注册到consul中的目标资源的变化同步到Prometheus的Targets中来; |
基于API的服务发现:kubernetes_sd_configs
Prometheus 集成了 Kubernetes 的自动服务发现,通过 kube-apiserver 提供的5种模式API来动态服务发现,它们分别是:基于 Node、Service、Pod、Endpoints以及基于ingress的服务发现;
下面给出 Kubernetes 服务发现的实例,这里会使用大量的 relabel_configs 标签,它主要是重新修改标签,它仅仅是对采集过来的指标进行二次处理,我们要什么、不要什么、如何替换等,把以__meta__、__address__、__scheme__或者以__metrics_path__开头的这些元数据标签进行动态的修改、更新、添加、删除操作;
relabel_configs action动作有如下几种:
| relabel_configs action动作 | 含义 |
| replace | 根据regex来去匹配source_labels标签上的值,并将并将匹配到的值写入target_label中,其实就是替换; |
| keep | 只是收集匹配到regex的源标签source_labels,而会丢弃没有匹配到的所有标签,用于选择保留哪些标签; |
| drop | 丢弃匹配到regex的源标签,而会收集没有匹配到的所有标签,用于排除,与keep相反; |
| labeldrop | 使用regex表达式匹配标签,符合规则的标签将从target实例中移除; |
| labelkeep | 使用regex表达式匹配标签,仅收集符合规则的target,不符合匹配规则的不收集; |
| labelmap | 根据regex的定义去匹配Target实例所有标签的名称,并且以匹配到的内容为新的标签名称,其值作为新标签的值; |
几种动作中提到的几个术语解析:
source_labels:字面意思是源标签,没有经过relabel处理之前的标签名;
target_label:目标标签,通过action动作处理之后的新的标签名;
regex:正则表达式,用于匹配源标签值使用的;
replacement:replacement指定的替换后的标签(target_label)对应的数值;
scheme: https、http等代表获取指标数据时使用的协议类型;
prometheus WebUI targets中的endpoints组成:
__scheme__://__address__/__metrics__path__
__scheme__,默认是http,不特别指明,就是http;
__address__,不特别说明也是抓取到源标签中的指标值;
__metrics__path__,默认是/metrics,除非特别指明;
Node 服务发现
主要监控Node节点的指标数据
- job_name: 'kubernetes-node'
kubernetes_sd_configs:
- role: node
relabel_configs:
- source_labels: [__address__]
regex: '(.*):10250'
replacement: '${1}:9100'
target_label: __address__
action: replace
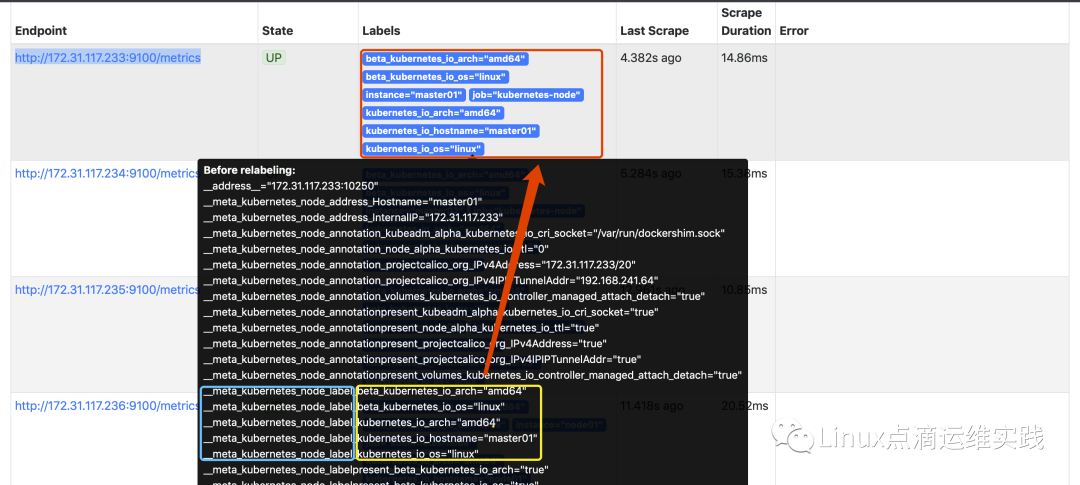
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
job_name 是为监控的目标定义一个标识名称,显示在WebUI界面的Targets中;
kubernetes_sd_configs 代表这是基于kubernetes API进行的动态服务发现方式;
role 指的是使用哪种类型的API,上面已经说过基于5种不同类型API来实现动态服务发现,这里指的是node;
relables_configs 重新修改标签的配置,
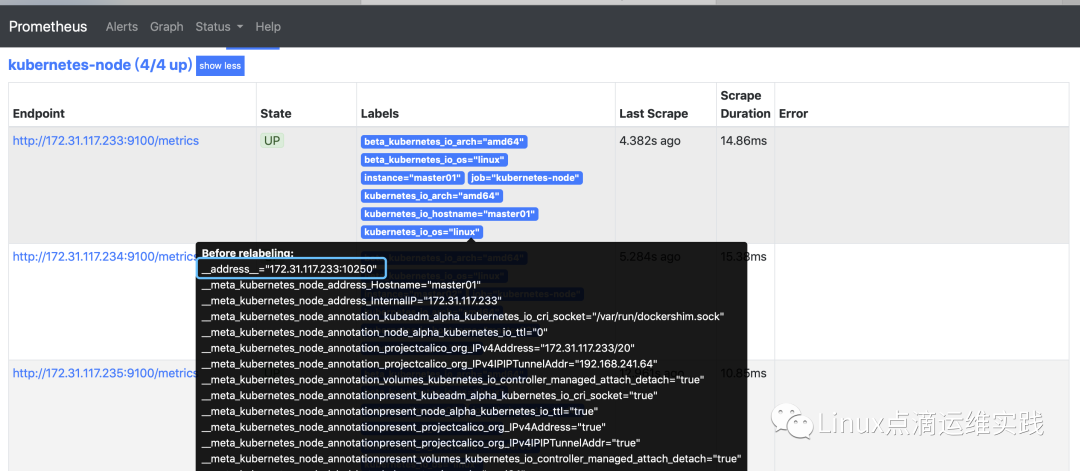
source_labels:__address__="172.31.117.233:10250";
reges: 正则表达式,用于匹配源标签值使用的,这里源标签值是172.31.117.233:10250,通过正则表达式(.*):10250,匹配出来的结果是172.31.117.233;
replacement:替换后标签对应的值172.31.117.233:9100,其实就是 WebUI中Endpoint的数据;
action:replace即替换动作;
labelmap:__meta_kubernetes_node_label_(.+),根据regex的定义去匹配Target实例所有标签的名称,并且以匹配到的内容为新的标签名称,其值作为新标签的值,其实新的标签值即是 WebUI 界面中显示的;
API Server服务发现
- job_name: 'kubernetes-apiserver'
kubernetes_sd_configs:
- role: endpoints
scheme: https
tls_config:
ca_file: var/run/secrets/kubernetes.io/serviceaccount/ca.crt
bearer_token_file: var/run/secrets/kubernetes.io/serviceaccount/
token
relabel_configs:
- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_
service_name, __meta_kubernetes_endpoint_port_name]
action: keep
regex: default;kubernetes;https
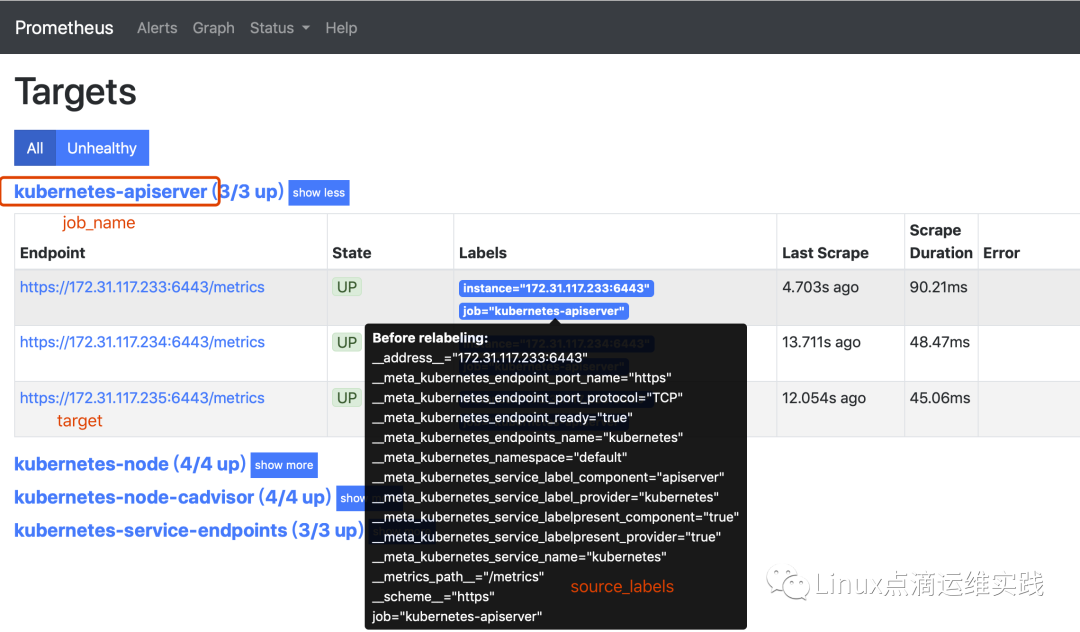
job_name 在WebUI中 Targets中显示的名称;
kubernetes_sd_configs 代表这是基于kubernetes API进行的动态服务发现方式;
role,指的是使用哪种类型的API,上面已经说过基于5种不同类型API来实现动态服务发现,这里指的是endpoints,这里也有一些默认的配置;
scheme,抓取数据时使用的协议类型为https;
tls_config和bearer_token_file,都是使用https进行获取数据使用的认证文件;
source_lables,动态服务发现kube-apiserver时,根据源标签进行一次过滤,把符合的target先过滤出来;
reges,根据正则去过滤哪个源标签被匹配出来,再结合keep动作,它能唯一的表示出是我们监控的对象;
action,keep就是保留符合正则表达式的targets,并显示出来;
node-cadvisor 动态服务发现
主要是监控容器的指标数据;
- job_name: 'kubernetes-node-cadvisor'
kubernetes_sd_configs:
- role: node
scheme: https
tls_config:
ca_file: var/run/secrets/kubernetes.io/serviceaccount/ca.crt
bearer_token_file: var/run/secrets/kubernetes.io/serviceaccount/
token
relabel_configs:
- action: labelmap
regex: __meta_kubernetes_node_label_(.+)
- target_label: __address__
replacement: kubernetes.default.svc:443
- source_labels: [__meta_kubernetes_node_name]
regex: (.+)
target_label: __metrics_path__
replacement: /api/v1/nodes/${1}/proxy/metrics/cadvisor
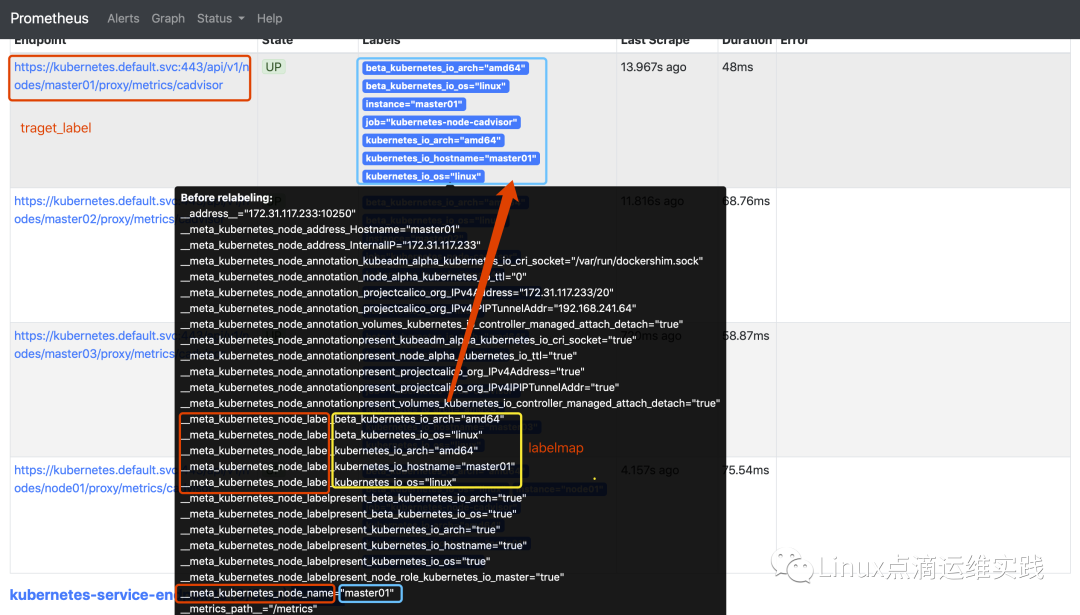
job_name,在WebUI中 Targets中显示的名称;
kubernetes_sd_configs 代表这是基于kubernetes API进行的动态服务发现方式;
role 指的是使用哪种类型的API,上面已经说过基于5种不同类型API来实现动态服务发现,这里指的是node;
scheme,抓取数据时使用的协议类型为https;
tls_config和bearer_token_file,都是使用https进行获取数据使用的认证文件;
source_labels,通过regex 匹配出来 master01,把__metrics_path__默认值 metrics 替换成replacement成/api/v1/nodes/${1}/proxy/metrics/cadvisor,这里的$1由master01再次替换,
target_label,__address__它直接replacement 替换成kubernetes.default.svc:443;
Service 动态服务发现
要想让service自动服务发现,必须在注解中声明prometheus.io/port: "9153"和prometheus.io/scrape: "true",默认是9153端口,可以不声明,但prometheus.io/scrape必须声明,还有一个前提你后面Pod 需要暴露了/metrics接口,否则也监控不到;
- job_name: 'kubernetes-service-endpoints'
kubernetes_sd_configs:
- role: endpoints
relabel_configs:
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape]
action: keep
regex: true
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scheme]
action: replace
target_label: __scheme__
regex: (https?)
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__address__, __meta_kubernetes_service_annotation_prometheus_io_port]
action: replace
target_label: __address__
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
- action: labelmap
regex: __meta_kubernetes_service_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: kubernetes_namespace
- source_labels: [__meta_kubernetes_service_name]
action: replace
target_label: kubernetes_name
job_name,在WebUI中 Targets中显示的名称;
kubernetes_sd_configs 代表这是基于kubernetes API进行的动态服务发现方式;
role 指的是使用哪种类型的API,上面已经说过基于5种不同类型API来实现动态服务发现,这里指的是node;
__meta_kubernetes_service_annotation_prometheus_io_scrape,这个标签为true的过滤出来;
__meta_kubernetes_service_annotation_prometheus_io_path,如果指定了拉取指标数据的接口,把原来的__metrics_path__ 替换掉;
labelmap,保留哪些标签显示在prometheus WebUI中;
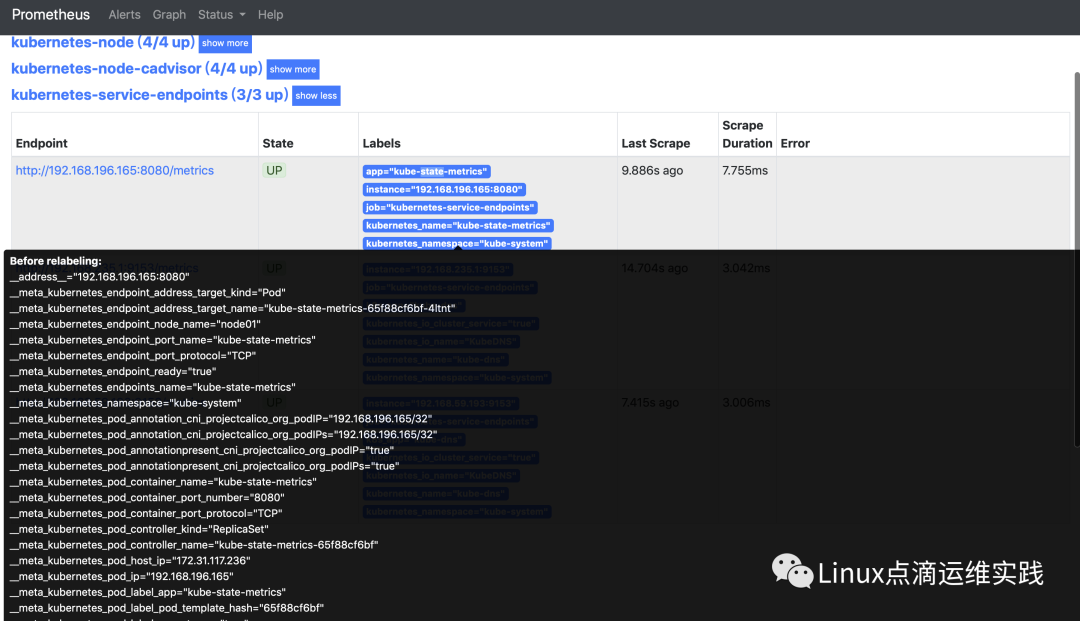
Pod 动态服务发现
Pod要想动态的服务发现,必须在定义Pod的时候,使用annotations:声明prometheus.io/scrape: 'true',否则创建的Pod不会被自动服务发现,还有一个前提你使用的镜像需要暴露了/metrics接口,否则也监控不到;
- job_name: kubernetes-pods
kubernetes_sd_configs:
- role: pod
relabel_configs:
- action: keep
regex: true
source_labels:
- __meta_kubernetes_pod_annotation_prometheus_io_scrape
- action: replace
regex: (.+)
source_labels:
- __meta_kubernetes_pod_annotation_prometheus_io_path
target_label: __metrics_path__
- action: replace
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
source_labels:
- __address__
- __meta_kubernetes_pod_annotation_prometheus_io_port
target_label: __address__
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
- action: replace
source_labels:
- __meta_kubernetes_namespace
target_label: kubernetes_namespace
- action: replace
source_labels:
- __meta_kubernetes_pod_name
target_label: kubernetes_pod_name
这里的规则不作介绍和之前大同小异,要想让 Pod 自动服务发现,就需要暴露metrics接口;
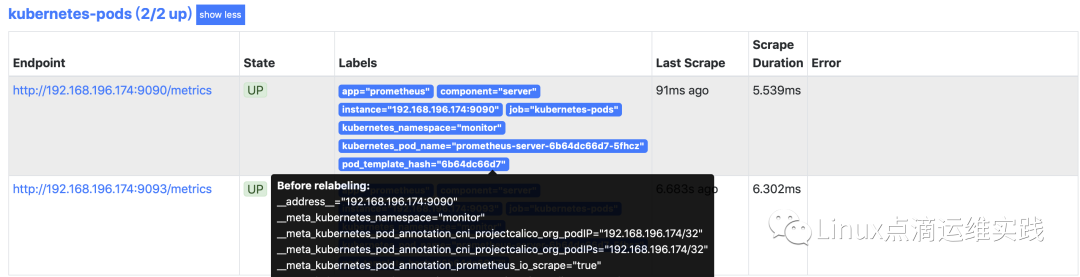
基于静态配置的服务发现:static_configs
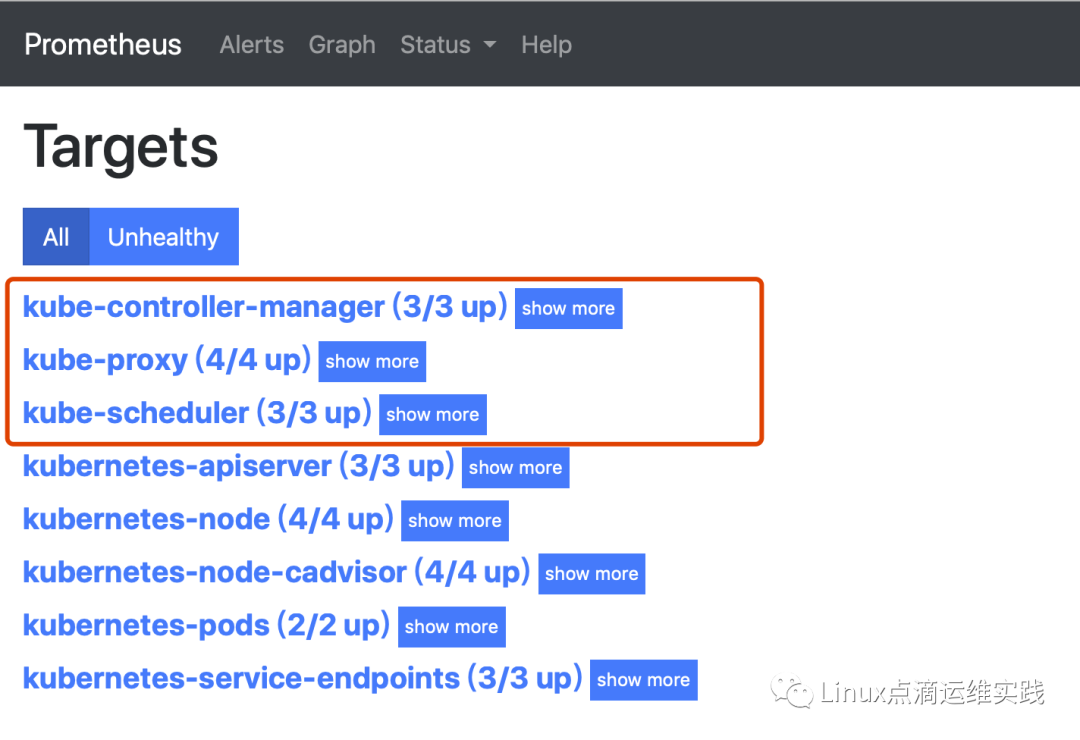
kube-scheduler/controller-manager/proxy静态服务发现
- job_name: 'kube-scheduler'
scrape_interval: 5s
static_configs:
- targets: ['172.31.117.233:10251','172.31.117.234:10251','172.31.117.235:10251']
- job_name: 'kube-controller-manager'
scrape_interval: 5s
static_configs:
- targets: ['172.31.117.233:10252','172.31.117.234:10252','172.31.117.235:10252']
- job_name: 'kube-proxy'
scrape_interval: 5s
static_configs:
- targets: ['172.31.117.233:10249','1172.31.117.234:10249','1172.31.117.235:10249','1172.31.117.236:10249']
静态配置相对简单,直接添加targets即可,以列表的形式,这里需要注意一个问题,由于集群是使用kubeadm安装的,kube-proxy监听的是127.0.0.1:10249,无法正常监控,需要修改
[root@master01 monitor]# kubectl edit cm kube-proxy -n kube-system
默认metricsBindAddress : "",监听在127.0.0.1:10249

需要先把之前的kube-proxy删除,然后它会自动重建Pod,此时即可监听0.0.0.0:10249
[root@master01 monitor]# kubectl get pods -n kube-system|grep kube-proxy
kube-proxy-5zs9d 1/1 Running 0 33h
kube-proxy-b28fj 1/1 Running 0 33h
kube-proxy-btmlh 1/1 Running 1 33h
kube-proxy-ct7vd 1/1 Running 0 33h
[root@master01 monitor]# kubectl get pods -n kube-system|grep kube-proxy|gawk '{print $1}'
kube-proxy-5zs9d
kube-proxy-b28fj
kube-proxy-btmlh
kube-proxy-ct7vd
[root@master01 monitor]# for i in `kubectl get pods -n kube-system|grep kube-proxy|gawk '{print $1}'`
> do
> kubectl delete pods $i -n kube-system
> done
pod "kube-proxy-5zs9d" deleted
pod "kube-proxy-b28fj" deleted
pod "kube-proxy-btmlh" deleted
pod "kube-proxy-ct7vd" deleted
[root@master01 monitor]# kubectl get pods -n kube-system|grep kube-proxy
kube-proxy-5xh5r 1/1 Running 0 22s
kube-proxy-ccp4w 1/1 Running 0 29s
kube-proxy-swmw9 1/1 Running 0 17s
kube-proxy-vkz78 1/1 Running 0 20s
[root@master01 monitor]#
监控情况截图
etcd服务发现
由于集群采用了 https 的方式访问 etcd 集群,如果想监控etcd的话,也需要使用证书,我们这边使用 secret 资源类型,让 Prometheus 挂载此证书;
[root@master01 monitor]# kubectl create secret generic etcd-certs --from-file=/etc/kubernetes/ssl/etcd/etcd.pem --from-file=/etc/kubernetes/ssl/etcd/etcd-key.pem --from-file=/etc/kubernetes/ssl/ca/ca.pem -n monitor
secret/etcd-certs created
[root@master01 monitor]#
修改prometheus-alertmanager-deployment.yaml文件添加如下标注配置
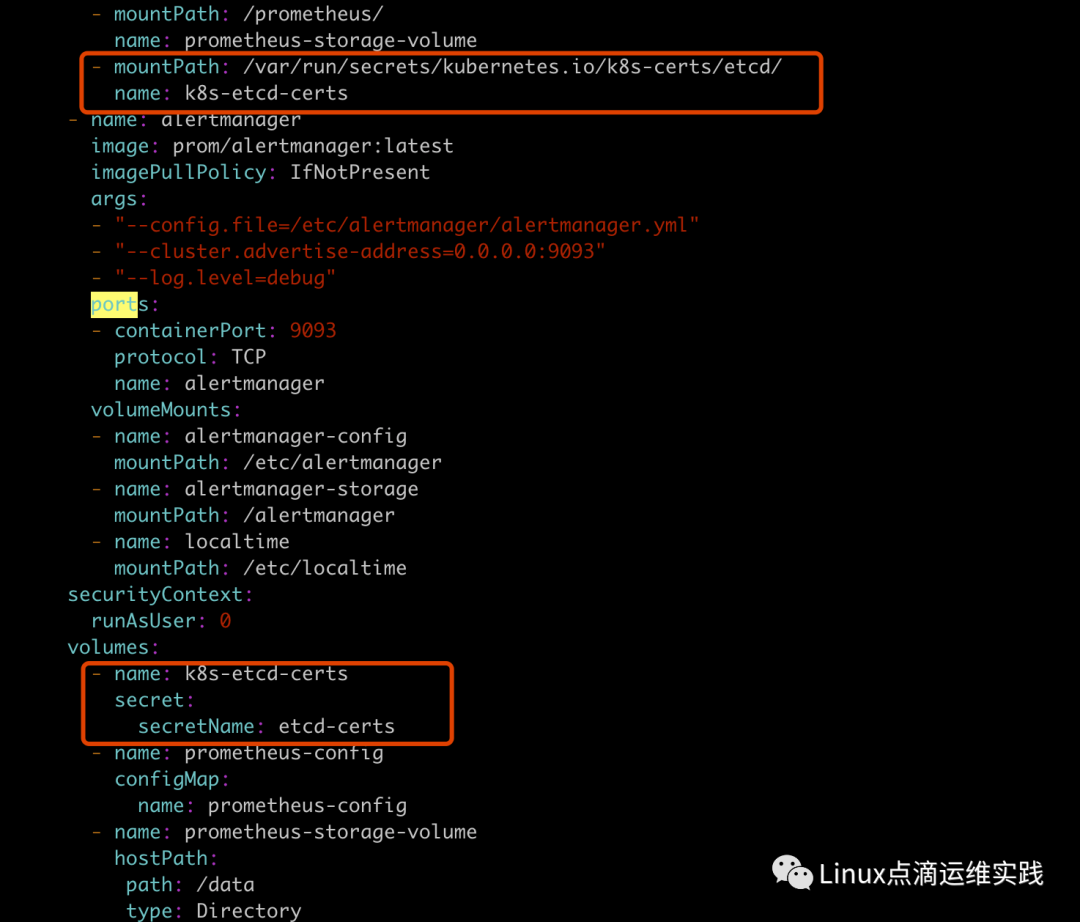
添加Etcd 静态监控配置
- job_name: 'k8s-etcd'
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/k8s-certs/etcd/ca.pem
cert_file: /var/run/secrets/kubernetes.io/k8s-certs/etcd/etcd.pem
key_file: /var/run/secrets/kubernetes.io/k8s-certs/etcd/etcd-key.pem
scrape_interval: 5s
static_configs:
- targets: ['172.31.117.233:2379','172.31.117.234:2379','172.31.117.235:2379']
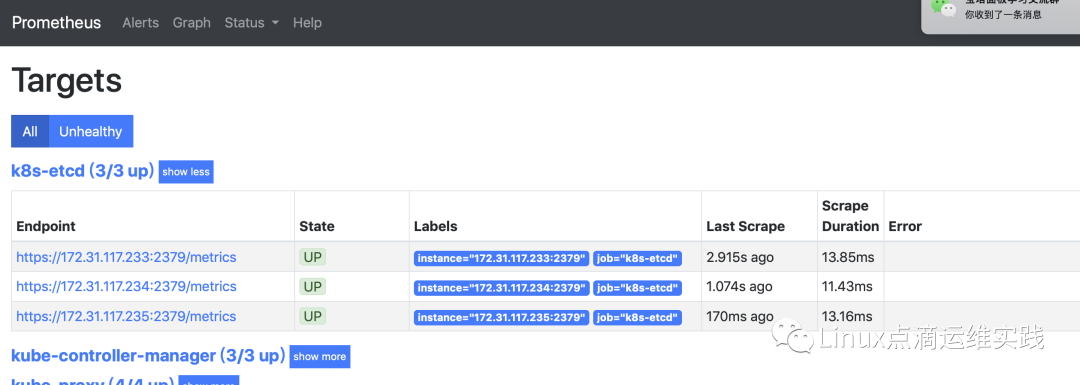
监控如图
Prometheus常用启动参数
| 配置参数 | 说明 |
| - --config.file=/etc/prometheus/prometheus.yml | 配置文件路径 |
| - --storage.tsdb.path=/prometheus | 存储路径,默认在data目录下 |
| - --storage.tsdb.retention=720h | 数据保留时间 |
| - --web.enable-admin-api | 控制对admin HTTP API的访问,其中包括删除时间序列等功能 |
| - --web.enable-lifecycle | 热加载 reload操作,如果不生效,删除重建; |
| - --web.max-connections=512 | 默认最大连接数 |
| - --alertmanager.timeout=10s | 报警信息发送给alertmanager的超时时间 |
| - --query.timeout=2m | 查询超时间 |
| - --query.max-concurrency=20 | 并发查询数,prometheus的默认采集指标中有一项,prometheus_engine_queries_concurrent_max可以拿到最大查询并发数及查询情况 |
总结
主要总结 Prometheus 监控抓取的配置规则,尤其是relabel_configs的使用,这个是Prometheus 配置监控目标的重点,详细说明了node、pod、service、kube-apiserver的动态服务发现方式及配置文件详解,又列举了kube-controller-manager、kube-scheduler和etcd静态配置服务发现的方式,基于文件和DNS的服务发现,用的不多,先不总结,最后总结了Prometheus常用启动参数。
标签:__,kubernetes,标签,011relabel,prometheus,详解,configs,kube From: https://www.cnblogs.com/itcomputer/p/16933648.html