来自 https://zhuanlan.zhihu.com/p/356274590
当我们在做数据分析或者数据挖掘的时候难免会遇到需要合并多个表格的情况,在pandas中要连接表格的姿势非常之多,合适的场景下先择合适的方案将加快我们数据处理的过程。
以下案例均为实际数据处理场景中遇到的问题简化而来。
注意:在所有的数据处理文章中,我并不会讲解函数的所有参数,也不会深入讲解函数的原理,如果想了解该函数更详细的内容建议阅读官方文档
merge
合并维度相同的表
假设有如下两个表格df1和df2,其中A列表示不同的学生,B列和C列表示改学生对应的科目的成绩,现在需要将两个表格进行合并得到每位学生的平均成绩。
import pandas as pd
df1 = pd.DataFrame({
"A": ["a", "b", "c", "d", "e", "f"],
"B": [56, 18, 67, 98, 66, 82]
})
df2 = pd.DataFrame({
"A": ["f", "d", "e", "c", "a", "b"],
"C": [78, 47, 90, 81, 46, 79]
})df1、df2数据如下
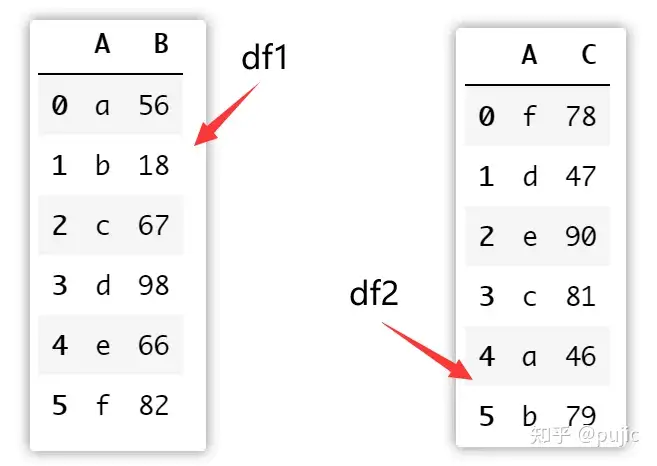
因为这个问题不只是一个简答的堆叠或绑定,这是一个合并排序的过程,所以需要使用pandas中的merge函数
pd.merge(df1, df2, on="A").mean(axis=1)计算结果如下

结算结果明显是一个Series,但是通过缩影来找值实在是不方便,我希望可以直接出现人名对应着成绩的数据形式
先将结果的值赋给一个变量
s = pd.merge(df1, df2, on="A").mean(axis=1)然后设置索引的值
s.index = df1['A']那么我还想给s设置一个name因为可能还需要和其他表的数据进行合并进行计算
s.name = "平均成绩"merge函数有一个参数how,指的是合并(连接)的方式:inner(内连接),left(左外连接),right(右外连接),outer(全外连接),默认为inner。
- inner只返回两个表中连接字段相等的行
- left返回包括左表中的所有记录和右表中连接字段相等的行
- outer和inner相反,right和left相反
合并维度不同的表
如果我们需要计算B、C科目的平均成绩,但是如果C科目成绩小于60的同学计算平均成绩的时候不考虑C科目的平均成绩。这样的情况下我们最好是不要先进行表的合并操作,虽然可以先将表合并后再按C科目的成绩进行计算,但是这样会多出很多的Python代码,因为pandas是C写的Python库,所以在操作数据的时候能不用Python中的语法就不要使用,我们可以先对df中的数据进行筛选,然后合并后计算的工作pandas自己就帮我们完成了
import pandas as pd
df1 = pd.DataFrame({
"A": ["a", "b", "c", "d", "e", "f"],
"B": [56, 18, 67, 98, 66, 82]
})
df2 = pd.DataFrame({
"A": ["f", "d", "e", "c", "a", "b"],
"C": [78, 47, 90, 81, 46, 79]
})
df2 = df2[df2["C"]>60]df1、df2数据如下
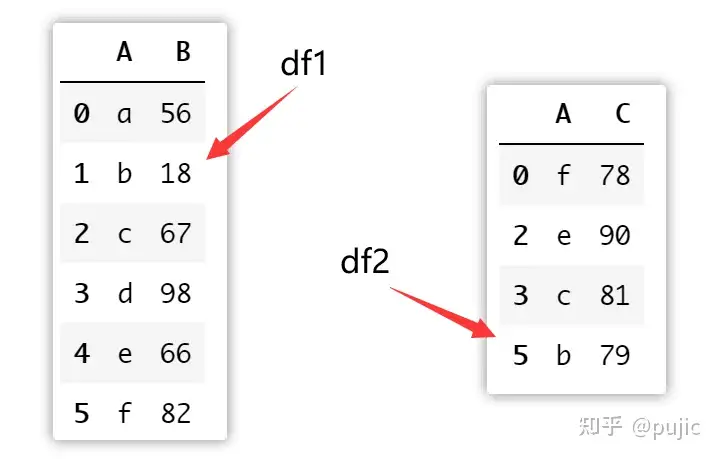
pd.merge(df1, df2, on="A")连接结果如下
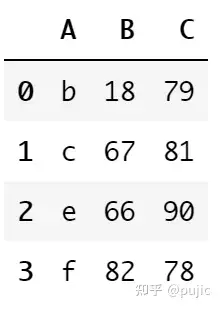
得到的结果维度丢失了,这种情况下直接使用merge是有问题的,因为merge默认连接方式是inner,所以只能返回A字段相等的行,所以需要使用left
pd.merge(df1, df2, on="A", how="left")连接结果如下
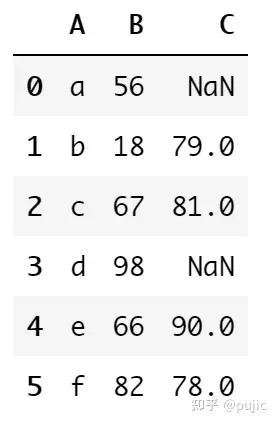
然后我们就可以直接求均值了,因为pandas够聪明,在计算均值的时候如果有值,那么这个值就不会被带入计算
pd.merge(df1, df2, on="A", how="left").mean(axis=1)计算结果如下图

以多个列为基准进行合并
以多个列为基准进行合并,那么只需要将merge函数的on参数值指定为列表
import pandas as pd
df1 = pd.DataFrame({
"A": ["a", "b", "c", "d", "e", "f"],
"B": [97, 98, 99, 100, 101, 102],
"C": [56, 18, 67, 98, 66, 82]
})
df2 = pd.DataFrame({
"A": ["f", "d", "e", "c", "a", "d"],
"B": [102, 122, 101, 99, 97, 100],
"D": [78, 47, 90, 81, 46, 79]
})
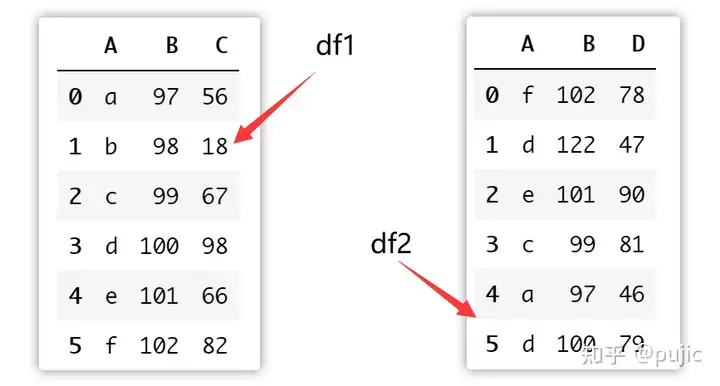
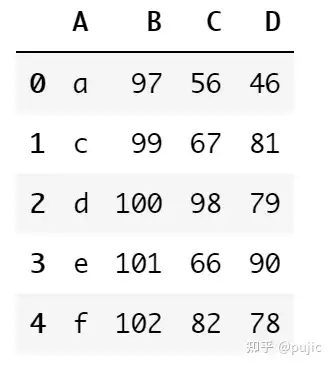
以上面的表格为例,要合并df1和df2,并且要df1和df2中的A、B列能够对上,其实就是一个合并筛选数据的操作,因此合并方式默认为inner就可以
pd.merge(df1, df2, on=["A", "B"])
concat
纵向合并
在https://mp.weixin.qq.com/s/A76oeBfjuUCNuVhQgAzSgA一文中就涉及了表格的合并操作,这种合并相当于堆叠,concat函数中要连接的表格需要放到序列中
改变一下数据,现在是想要像df1中补充数据
import pandas as pd
df1 = pd.DataFrame({
"A": ["a", "b", "c", "d", "e", "f"],
"B": [56, 18, 67, 98, 66, 82]
})
df2 = pd.DataFrame({
"A": ["g", "h", "i", "j", "k", "l"],
"B": [78, 47, 90, 81, 46, 79]
})
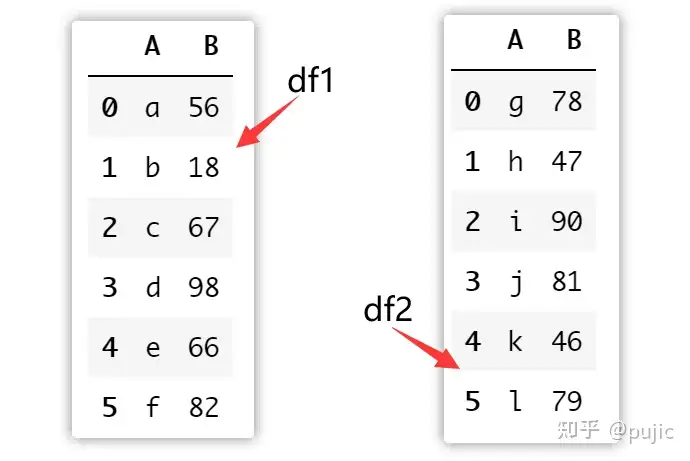
这时候需要将这两个表进行合并,很显然是进行上下合并的,这时候我们就需要使用concat函数进行合并
pd.concat([df1, df2])
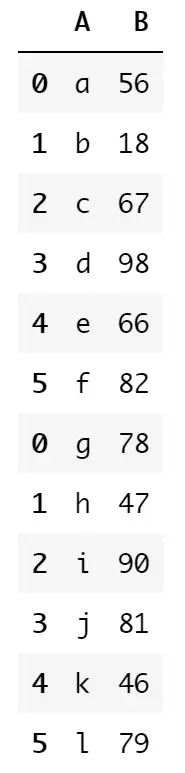
concat函数默认是在纵向进行合并,但是合并之后发现有一个问题,index的顺序是不对的,在我们纵向合并表格的时候并不会有什么影响,但是这个问题在一些情况下是需要解决的,关于索引的问题后面会讲解。
横向合并
有时候我们需要按索引横向合并两个表格的数据
import pandas as pd
df1 = pd.DataFrame({
"A": [1, 2, 3, 4, 5, 6],
"B": [1, 2, 3, 4, 5, 6]
})
df2 = pd.DataFrame({
"C": [1, 2, 3, 4, 5, 6],
"D": [1, 2, 3, 4, 5, 6]
})
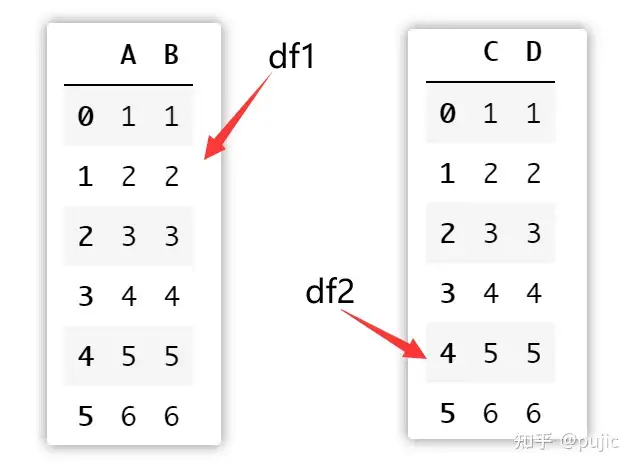
pd.concat([df1, df2], axis=1)
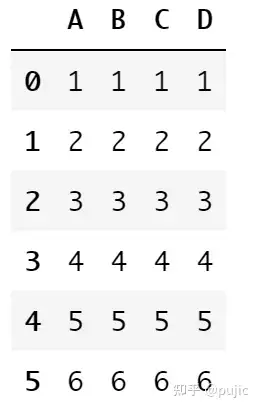
此时是在索引相同的情况,如果索引不同呢?有时候需要合并的数据是我们筛选出来的时候,不同的表格的索引大概率就是不同的
import pandas as pd
df1 = pd.DataFrame({
"A": [1, 2, 3, 4, 5, 6],
"B": [1, 2, 3, 4, 5, 6]
})
df2 = pd.DataFrame(
{
"C": [1, 2, 3, 4, 5, 6],
"D": [1, 2, 3, 4, 5, 6]
},
index=range(1, 7)
)
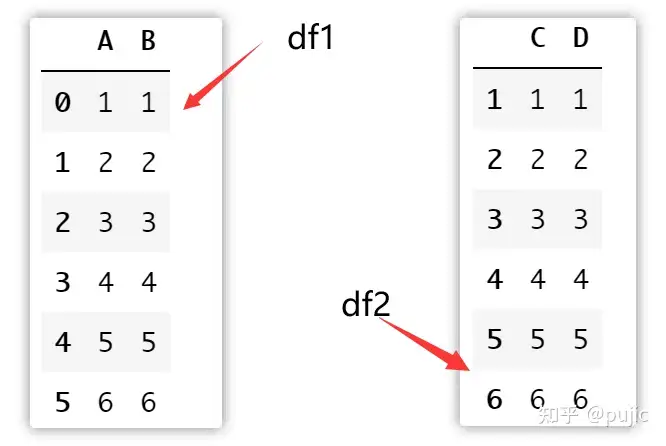
再次用concat合并表格
pd.concat([df1, df2], axis=1)
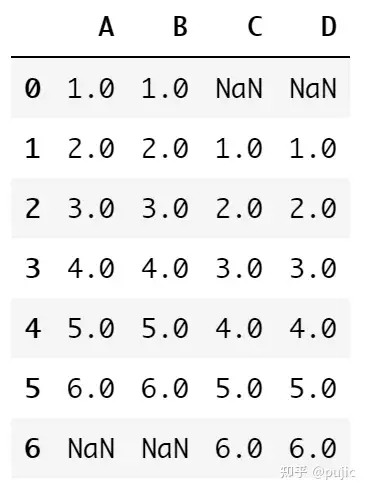
那么这时候表格就错位了,此时我们可以通过重置索引的方式解决
- 赋值index属性
python df2.index = range(df2.shape[0])
- reset_index方法重置索引。reset_index方法有一个
drop参数,表示是否删除原索引,默认为False,如果是False那么原来的索引将会并入DataFrame中
python df2.reset_index() df2.reset_index(drop=True)

上面重置索引的两种方法已经能够解决绝绝大部分问题,至于其他设置索引的方法就不介绍了,笔者常用方法就这两种
注意:concat用来合并DataFrame和Series都是可以的,而且合并对象中的元素并不是只能两个,这里就不过多讲解
append
append的用法就比较简单了,大多数情况下是用来像原有的表中追加数据的,这个追加只能是纵向的追加,因为DataFrame的结构定位是类似于关系型数据库的纵向表格(当然有的时候也会横向进行操作)
使用concat中追加成绩的案例
import pandas as pd
df1 = pd.DataFrame({
"A": ["a", "b", "c", "d", "e", "f"],
"B": [56, 18, 67, 98, 66, 82]
})
df2 = pd.DataFrame({
"A": ["g", "h", "i", "j", "k", "l"],
"B": [78, 47, 90, 81, 46, 79]
})
df1.append(df2)如果要重置索引,可以直接设置ignore_index参数的值为True
df1.append(df2, ignore_index=True)

总结
- merge:需要按照某列或者多列进行合并的时候使用
- concat:需要简单粗暴的进行合并的时候使用(最常用)
- append:只适用于追加数据的时候使用(不常用,大多数情况还是使用concat)